
Chapter 11. Transactions and concurrency
- Defining database and system transaction essentials
- Controlling concurrent access with Hibernate and JPA
- Using nontransactional data access
In this chapter, we finally talk about transactions: how you create and control concurrent units of work in an application. A unit of work is an atomic group of operations. Transactions allow you to set unit of work boundaries and help you isolate one unit of work from another. In a multiuser application, you may also be processing these units of work concurrently.
To handle concurrency, we first focus on units of work at the lowest level: database and system transactions. You’ll learn the APIs for transaction demarcation and how to define units of work in Java code. We’ll talk about how to preserve isolation and control concurrent access with pessimistic and optimistic strategies.
Finally, we look at some special cases and JPA features, based on accessing the database without explicit transactions. Let’s start with some background information.
- There are new lock modes and exceptions for pessimistic locking.
- You can set a lock mode, pessimistic or optimistic, on a Query.
- You can set a lock mode when calling EntityManager#find(), refresh(), or lock(). A lock timeout hint for pessimistic lock modes is also standardized.
- When the new QueryTimeoutException or LockTimeoutException is thrown, the transaction doesn’t have to be rolled back.
- The persistence context can now be in an unsynchronized mode with disabled automatic flushing. This allows you to queue modifications until you join a transaction and to decouple the EntityManager usage from transactions.
11.1. Transaction essentials
Application functionality requires that several things be done in one go. For example, when an auction finishes, the CaveatEmptor application must perform three different tasks:
1. Find the winning bid (highest amount) for the auction item.
2. Charge the seller of the item the cost of the auction.
3. Notify the seller and successful bidder.
What happens if you can’t bill the auction costs because of a failure in the external credit-card system? The business requirements may state that either all listed actions must succeed or none must succeed. If so, you call these steps collectively a transaction or unit of work. If only a single step fails, the entire unit of work must fail.
11.1.1. ACID attributes
ACID stands for atomicity, consistency, isolation, durability. Atomicity is the notion that all operations in a transaction execute as an atomic unit. Furthermore, transactions allow multiple users to work concurrently with the same data without compromising the consistency of the data (consistent with database integrity rules). A particular transaction should not be visible to other concurrently running transactions; they should run in isolation. Changes made in a transaction should be durable, even if the system fails after the transaction has completed successfully.
In addition, you want correctness of a transaction. For example, the business rules dictate that the application charges the seller once, not twice. This is a reasonable assumption, but you may not be able to express it with database constraints. Hence, the correctness of a transaction is the responsibility of the application, whereas consistency is the responsibility of the database. Together, these transaction attributes define the ACID criteria.
11.1.2. Database and system transactions
We’ve also mentioned system and database transactions. Consider the last example again: during the unit of work ending an auction, we might mark the winning bid in a database system. Then, in the same unit of work, we talk to an external system to bill the seller’s credit card. This is a transaction spanning several (sub)systems, with coordinated subordinate transactions on possibly several resources such as a database connection and an external billing processor.
Database transactions have to be short, because open transactions consume database resources and potentially prevent concurrent access due to exclusive locks on data. A single database transaction usually involves only a single batch of database operations.
To execute all of your database operations inside a system transaction, you have to set the boundaries of that unit of work. You must start the transaction and, at some point, commit the changes. If an error occurs (either while executing database operations or when committing the transaction), you have to roll back the changes to leave the data in a consistent state. This process defines a transaction demarcation and, depending on the technique you use, involves a certain level of manual intervention. In general, transaction boundaries that begin and end a transaction can be set either programmatically in application code or declaratively.
11.1.3. Programmatic transactions with JTA
In a Java SE environment, you call the JDBC API to mark transaction boundaries. You begin a transaction with setAutoCommit(false) on a JDBC Connection and end it by calling commit(). You may, at any time while the transaction is in progress, force an immediate rollback with rollback().
In an application that manipulates data in several systems, a particular unit of work involves access to more than one transactional resource. In this case, you can’t achieve atomicity with JDBC alone. You need a transaction manager that can handle several resources in one system transaction. JTA standardizes system transaction management and distributed transactions so you won’t have to worry much about the lower-level details. The main API in JTA is the UserTransaction interface with methods to begin() and commit() a system transaction.
JTA provides a nice abstraction of the underlying resource’s transaction system, with the added bonus of distributed system transactions. Many developers still believe you can only get JTA with components that run in a Java EE application server. Today, high-quality standalone JTA providers such as Bitronix (used for the example code of this book) and Atomikos are available and easy to install in any Java environment. Think of these solutions as JTA-enabled database connection pools.
You should use JTA whenever you can and avoid proprietary transaction APIs such as org.hibernate.Transaction or the very limited javax.persistence.EntityTransaction. These APIs were created at a time when JTA wasn’t readily available outside of EJB runtime containers.
In section 10.2.1, we promised to look at transactions again with a focus on exception handling. Here is the code, this time complete with rollback and exception handling.
Listing 11.1. Typical unit of work with transaction boundaries
Path: /examples/src/test/java/org/jpwh/test/simple/SimpleTransitions.java

The most complicated bit of this code snippet seems to be the exception handling; we’ll discuss this part in a moment. First, you have to understand how the transaction management and the EntityManager work together.
The EntityManager is lazy; we mentioned in the previous chapter that it doesn’t consume any database connections until SQL statements have to be executed. The same is true for JTA: starting and committing an empty transaction is cheap when you haven’t accessed any transactional resources. For example, you could execute this empty unit of work on a server, for each client request, without consuming any resources or holding any database locks.
When you create an EntityManager, it looks for an ongoing JTA system transaction within the current thread of execution. If the EntityManager finds an ongoing transaction, it joins the transaction by listening to transaction events. This means you should always call UserTransaction#begin() and EntityManagerFactory#create-EntityManager() on the same thread if you want them to be joined. By default, and as explained in chapter 10, Hibernate automatically flushes the persistence context when the transaction commits.
If the EntityManager can’t find a started transaction in the same thread when it’s created, it’s in a special unsynchronized mode. In this mode, JPA won’t automatically flush the persistence context. We talk more about this behavior later in this chapter; it’s a convenient feature of JPA when you design more complex conversations.
If code in a transaction reads data but doesn’t modify it, should you roll back the transaction instead of committing it? Would this be faster? Apparently, some developers found this to be faster in some special circumstances, and this belief has spread through the community. We tested this with the more popular database systems and found no difference. We also failed to discover any source of real numbers showing a performance difference. There is also no reason a database system should have a suboptimal cleanup implementation—why it shouldn’t use the fastest transaction cleanup algorithm internally.
Always commit your transaction and roll back if the commit fails. Having said that, the SQL standard includes the statement SET TRANSACTION READ ONLY. We recommend that you first investigate whether your database supports this and see what the possible performance benefits are, if any.
The transaction manager will stop a transaction when it has been running for too long. Remember that you want to keep database transactions as short as possible in a busy OLTP system. The default timeout depends on the JTA provider—Bitronix, for example, defaults to 60 seconds. You can override this selectively, before you begin the transaction, with UserTransaction#setTransactionTimeout().
We still need to discuss the exception handling of the previous code snippet.
11.1.4. Handling exceptions
If any EntityManager call or flushing the persistence context during a commit throws an exception, you must check the current state of the system transaction. When an exception occurs, Hibernate marks the transaction for rollback. This means the only possible outcome for this transaction is undoing all of its changes. Because you started the transaction, it’s your job to check for STATUS_MARKED_ROLLBACK. The transaction might also still be STATUS_ACTIVE, if Hibernate wasn’t able to mark it for rollback. In both cases, call UserTransaction#rollback() to abort any SQL statements that have been sent to the database within this unit of work.
All JPA operations, including flushing the persistence context, can throw a RuntimeException. But the methods UserTransaction#begin(), commit(), and even rollback() throw a checked Exception. The exception for rollback requires special treatment: you want to catch this exception and log it; otherwise, the original exception that led to the rollback is lost. Continue throwing the original exception after rollback. Typically, you have another layer of interceptors in your system that will finally deal with the exception, for example by rendering an error screen or contacting the operations team. An error during rollback is more difficult to handle properly; we suggest logging and escalation, because a failed rollback indicates a serious system problem.
Hibernate throws typed exceptions, all subtypes of RuntimeException that help you identify errors:
- The most common, HibernateException, is a generic error. You have to either check the exception message or find out more about the cause by calling getCause() on the exception.
- A JDBCException is any exception thrown by Hibernate’s internal JDBC layer. This kind of exception is always caused by a particular SQL statement, and you can get the offending statement with getSQL(). The internal exception thrown by the JDBC connection (the JDBC driver) is available with getSQLException() or getCause(), and the database- and vendor-specific error code is available with getErrorCode().
- Hibernate includes subtypes of JDBCException and an internal converter that tries to translate the vendor-specific error code thrown by the database driver into something more meaningful. The built-in converter can produce JDBC-ConnectionException, SQLGrammarException, LockAcquisitionException, DataException, and ConstraintViolationException for the most important database dialects supported by Hibernate. You can either manipulate or enhance the dialect for your database or plug in a SQLExceptionConverterFactory to customize this conversion.
Some developers get excited when they see how many fine-grained exception types Hibernate can throw. This can lead you down the wrong path. For example, you may be tempted to catch a ConstraintViolationException for validation purposes. If you forget to set the Item#name property, and its mapped column is NOT NULL in the database schema, Hibernate will throw this exception when you flush the persistence context. Why not catch it, display a (customized depending on the error code and text) failure message to application users, and let them correct the mistake? This strategy has two significant disadvantages.
First, throwing unchecked values against the database to see what sticks isn’t the right strategy for a scalable application. You want to implement at least some data-integrity validation in the application layer. Second, exceptions are fatal for your current unit of work. But this isn’t how application users will interpret a validation error: they expect to still be inside a unit of work. Coding around this mismatch is awkward and difficult. Our recommendation is that you use the fine-grained exception types to display better-looking (fatal) error messages, not for validation. For example, you could catch ConstraintViolationException separately and render a screen that says, “Application bug: someone forgot to validate data before sending it to the database. Please report it to the programmers.” For other exceptions, you’d render a generic error screen.
Doing so helps you during development and also helps any customer-support engineer who has to decide quickly whether it’s an application error (constraint violated, wrong SQL executed) or whether the database system is under load (locks couldn’t be acquired). For validation, you have a unifying framework available with Bean Validation. From a single set of rules in annotations on entities, Hibernate can verify all domain and single-row constraints at the user interface layer and can automatically generate SQL DDL rules.
You now know what exceptions you should catch and when to expect them. One question is probably on your mind: what should you do after you’ve caught an exception and rolled back the system transaction? Exceptions thrown by Hibernate are fatal. This means you have to close the current persistence context. You aren’t allowed to continue working with the EntityManager that threw an exception. Render an error screen and/or log the error, and then let the user restart the conversation with the system using a fresh transaction and persistence context.
As usual, this isn’t the whole picture. Some standardized exceptions aren’t fatal:
- javax.persistence.NoResultException—Thrown when a Query or TypedQuery is executed with getSingleResult() and no result was returned from the database. You can wrap the query call with exception-handling code and continue working with the persistence context. The current transaction won’t be marked for rollback.
- javax.persistence.NonUniqueResultException—Thrown when a Query or TypedQuery is executed with getSingleResult() and several results were returned from the database. You can wrap the query call with exception handling code and continue working with the persistence context. Hibernate won’t mark the current transaction for rollback.
- javax.persistence.QueryTimeoutException—Thrown when a Query or TypedQuery takes too long to execute. Doesn’t mark the transaction for rollback. You may want to repeat the query, if appropriate.
- javax.persistence.LockTimeoutException—Thrown when a pessimistic lock couldn’t be acquired. May occur during flushing or explicit locking (more on this topic later in this chapter). The transaction isn’t marked for rollback, and you may want to repeat the operation. Keep in mind that endlessly hammering on a database system that is already struggling to keep up won’t improve the situation.
Notably absent from this list is javax.persistence.EntityNotFoundException. It can be thrown by the EntityManager#getReference() and refresh() methods, as well as lock(), which you’ll see later in this chapter. Hibernate may throw it when you try to access the reference/proxy of an entity instance and the database record is no longer available. It’s a fatal exception: it marks the current transaction for rollback, and you have to close and discard the persistence context.
Programmatic transaction demarcation requires application code written against a transaction demarcation interface such as JTA’s UserTransaction. Declarative transaction demarcation, on the other hand, doesn’t require extra coding.
11.1.5. Declarative transaction demarcation
In a Java EE application, you can declare when you wish to work inside a transaction. It’s then the responsibility of the runtime environment to handle this concern. Usually you set transaction boundaries with annotations on your managed components (EJBs, CDI beans, and so on).
You can use the older annotation @javax.ejb.TransactionAttribute to demarcate transaction boundaries declaratively on EJB components. You can find examples in section 18.2.1.
You can apply the newer and more general @javax.transaction.Transactional on any Java EE managed component. You can find an example in section 19.3.1.
All other examples in this chapter work in any Java SE environment, without a special runtime container. Hence, from now on, you’ll only see programmatic transaction demarcation code until we focus on specific Java EE application examples.
Next, we focus on the most complex aspect of ACID properties: how you isolate concurrently running units of work from each other.
11.2. Controlling concurrent access
Databases (and other transactional systems) attempt to ensure transaction isolation, meaning that, from the point of view of each concurrent transaction, it appears that no other transactions are in progress. Traditionally, database systems have implemented isolation with locking. A transaction may place a lock on a particular item of data in the database, temporarily preventing read and/or write access to that item by other transactions. Some modern database engines implement transaction isolation with multiversion concurrency control (MVCC), which vendors generally consider more scalable. We’ll discuss isolation assuming a locking model, but most of our observations are also applicable to MVCC.
How databases implement concurrency control is of the utmost importance in your Java Persistence application. Applications inherit the isolation guarantees provided by the database management system. For example, Hibernate never locks anything in memory. If you consider the many years of experience that database vendors have with implementing concurrency control, you’ll see the advantage of this approach. Additionally, some features in Java Persistence, either because you explicitly use them or by design, can improve the isolation guarantee beyond what the database provides.
We discuss concurrency control in several steps. First, we explore the lowest layer: the transaction isolation guarantees provided by the database. After that, you’ll see the Java Persistence features for pessimistic and optimistic concurrency control at the application level, and what other isolation guarantees Hibernate can provide.
11.2.1. Understanding database-level concurrency
If we’re talking about isolation, you may assume that two things are either isolated or not; there is no grey area in the real world. When we talk about database transactions, complete isolation comes at a high price. You can’t stop the world to access data exclusively in a multiuser OLTP system. Therefore, several isolation levels are available, which, naturally, weaken full isolation but increase performance and scalability of the system.
Transaction isolation issues
First, let’s look at several phenomena that may occur when you weaken full transaction isolation. The ANSI SQL standard defines the standard transaction isolation levels in terms of which of these phenomena are permissible.
A lost update occurs if two transactions both update a data item and then the second transaction aborts, causing both changes to be lost. This occurs in systems that don’t implement concurrency control, where concurrent transactions aren’t isolated. This is shown in figure 11.1.
Figure 11.1. Lost update: two transactions update the same data without isolation.

A dirty read occurs if a transaction reads changes made by another transaction that hasn’t yet been committed. This is dangerous because the changes made by the other transaction may later be rolled back, and invalid data may be written by the first transaction; see figure 11.2.
Figure 11.2. Dirty read: transaction A reads uncommitted data from transaction B.

An unrepeatable read occurs if a transaction reads a data item twice and reads different state each time. For example, another transaction may have written to the data item and committed between the two reads, as shown in figure 11.3.
Figure 11.3. Unrepeatable read: transaction A executes two non-repeatable reads.

A special case of an unrepeatable read is the last commit wins problem. Imagine that two concurrent transactions both read a data item, as shown in figure 11.4. One writes to it and commits, and then the second writes to it and commits. The changes made by the first writer are lost. This issue is especially frustrating for users: user A’s changes are overwritten without warning, and B has potentially made a decision based on outdated information.
Figure 11.4. Last commit wins: transaction B overwrites changes made by A.

A phantom read is said to occur when a transaction executes a query twice, and the second result includes data that wasn’t visible in the first result or less data because something was deleted. It need not necessarily be exactly the same query. Another transaction inserting or deleting data between the executions of the two queries causes this situation, as shown in figure 11.5.
Figure 11.5. Phantom read: transaction A reads new data in the second SELECT.

Now that you understand all the bad things that can occur, we can define the transaction isolation levels and see what problems they prevent.
ANSI isolation levels
The standard isolation levels are defined by the ANSI SQL standard, but they aren’t specific to SQL databases. JTA defines exactly the same isolation levels, and you’ll use these levels to declare your desired transaction isolation. With increased levels of isolation come higher cost and serious degradation of performance and scalability:
- Read uncommitted isolation— A system that permits dirty reads but not lost updates operates in read uncommitted isolation. One transaction may not write to a row if another uncommitted transaction has already written to it. Any transaction may read any row, however. A DBMS may implement this isolation level with exclusive write locks.
- Read committed isolation— A system that permits unrepeatable reads but not dirty reads implements read committed isolation. A DBMS may achieve this by using shared read locks and exclusive write locks. Reading transactions don’t block other transactions from accessing a row, but an uncommitted writing transaction blocks all other transactions from accessing the row.
- Repeatable read isolation— A system operating in repeatable read isolation mode permits neither unrepeatable reads nor dirty reads. Phantom reads may occur. Reading transactions block writing transactions but not other reading transactions, and writing transactions block all other transactions.
- Serializable isolation— The strictest isolation, serializable, emulates serial execution, as if transactions were executed one after another, rather than concurrently. A DBMS may not implement serializable using only row-level locks. A DBMS must instead provide some other mechanism that prevents a newly inserted row from becoming visible to a transaction that has already executed a query that would return the row. A crude mechanism is exclusively locking the entire database table after a write, so no phantom reads can occur.
How exactly a DBMS implements its locking system varies significantly; each vendor has a different strategy. You should study the documentation of your DBMS to find out more about its locking system, how locks are escalated (from row-level, to pages, to entire tables, for example), and what impact each isolation level has on the performance and scalability of your system.
It’s nice to know how all these technical terms are defined, but how does that help you choose an isolation level for your application?
Choosing an isolation level
Developers (ourselves included) are often unsure what transaction isolation level to use in a production application. Too high an isolation level harms the scalability of a highly concurrent application. Insufficient isolation may cause subtle, difficult-to-reproduce bugs in an application that you won’t discover until the system is working under heavy load.
Note that we refer to optimistic locking (with versioning) in the following explanation, a concept explained later in this chapter. You may want to skip this section for now and come back to it later when it’s time to pick an isolation level for your application. Choosing the correct isolation level is, after all, highly dependent on your particular scenario. Read the following discussion as recommendations, not dictums carved in stone.
Hibernate tries hard to be as transparent as possible regarding transactional semantics of the database. Nevertheless, persistence context caching and versioning affect these semantics. What is a sensible database isolation level to choose in a JPA application?
First, for almost all scenarios, eliminate the read uncommitted isolation level. It’s extremely dangerous to use one transaction’s uncommitted changes in a different transaction. The rollback or failure of one transaction will affect other concurrent transactions. Rollback of the first transaction could bring other transactions down with it, or perhaps even cause them to leave the database in an incorrect state (the seller of an auction item might be charged twice—consistent with database integrity rules but incorrect). It’s possible that changes made by a transaction that ends up being rolled back could be committed anyway, because they could be read and then propagated by another transaction that is successful!
Second, most applications don’t need serializable isolation. Phantom reads aren’t usually problematic, and this isolation level tends to scale poorly. Few existing applications use serializable isolation in production, but rather rely on selectively applied pessimistic locks that effectively force a serialized execution of operations in certain situations.
Next, let’s consider repeatable read. This level provides reproducibility for query result sets for the duration of a database transaction. This means you won’t read committed updates from the database if you query it several times. But phantom reads are still possible: new rows might appear—rows you thought existed might disappear if another transaction committed such changes concurrently. Although you may sometimes want repeatable reads, you typically don’t need them in every transaction.
The JPA specification assumes that read committed is the default isolation level. This means you have to deal with unrepeatable reads, phantom reads, and the last commit wins problem.
Let’s assume you’re enabling versioning of your domain model entities, something that Hibernate can do for you automatically. The combination of the (mandatory) persistence context cache and versioning already gives you most of the nice features of repeatable read isolation. The persistence context cache ensures that the state of the entity instances loaded by one transaction is isolated from changes made by other transactions. If you retrieve the same entity instance twice in a unit of work, the second lookup will be resolved within the persistence context cache and not hit the database. Hence, your read is repeatable, and you won’t see conflicting committed data. (You still get phantom reads, though, which are typically much easier to deal with.) Additionally, versioning switches to first commit wins. Hence, for almost all multiuser JPA applications, read committed isolation for all database transactions is acceptable with enabled entity versioning.
Hibernate retains the isolation level of your database connection; it doesn’t change the level. Most products default to read committed isolation. There are several ways you can change either the default transaction isolation level or the settings of the current transaction.
First, you can check whether your DBMS has a global transaction isolation level setting in its proprietary configuration. If your DBMS supports the standard SQL statement SET SESSION CHARACTERISTICS, you can execute it to set the transaction settings of all transactions started in this particular database session (which means a particular connection to the database, not a Hibernate Session). SQL also standardizes the SET TRANSACTION syntax, which sets the isolation level of the current transaction. Finally, the JDBC Connection API offers the setTransactionIsolation() method, which (according to its documentation) “attempts to change the transaction isolation level for this connection.” In a Hibernate/JPA application, you can obtain a JDBC Connection from the native Session API; see section 17.1.
We recommend a different approach if you’re using a JTA transaction manager or even a simple JDBC connection pool. JTA transaction management systems, such as Bitronix used for the examples of this book, allow you to set a default transaction isolation level for every connection obtained from the pool. In Bitronix, you can set the default isolation level on startup with PoolingDataSource#setIsolationLevel(). Check the documentation of your data source provider, application server, or JDBC connection pool for more information.
We assume from now on that your database connections are by default in read committed isolation level. From time to time, a particular unit of work in your application may require a different, usually stricter isolation level. Instead of changing the isolation level of the entire transaction, you should use the Java Persistence API to obtain additional locks on the relevant data. This fine-grained locking is more scalable in a highly concurrent application. JPA offers optimistic version checking and database-level pessimistic locking.
11.2.2. Optimistic concurrency control
Handling concurrency in an optimistic way is appropriate when concurrent modifications are rare and it’s feasible to detect conflicts late in a unit of work. JPA offers automatic version checking as an optimistic conflict-detection procedure.
First you’ll enable versioning, because it’s turned off by default—that’s why you get last commit wins if you don’t do anything. Most multiuser applications, especially web applications, should rely on versioning for any concurrently modified @Entity instances, enabling the more user-friendly first commit wins.
The previous sections have been somewhat dry; it’s time for code. After enabling automatic version checking, you’ll see how manual version checking works and when you have to use it.
Enabling versioning
You enable versioning with an @Version annotation on a special additional property of your entity class, as shown next.
Listing 11.2. Enabling versioning on a mapped entity
Path: /model/src/main/java/org/jpwh/model/concurrency/version/Item.java
@Entity public class Item implements Serializable { <enter/> @Version protected long version; <enter/> // ... }
In this example, each entity instance carries a numeric version. It’s mapped to an additional column of the ITEM database table; as usual, the column name defaults to the property name, here VERSION. The actual name of the property and column doesn’t matter—you could rename it if VERSION is a reserved keyword in your DBMS.
You could add a getVersion() method to the class, but you shouldn’t have a setter method and the application shouldn’t modify the value. Hibernate automatically changes the version value: it increments the version number whenever an Item instance has been found dirty during flushing of the persistence context. The version is a simple counter without any useful semantic value beyond concurrency control. You can use an int, an Integer, a short, a Short, or a Long instead of a long; Hibernate wraps and starts from zero again if the version number reaches the limit of the data type.
After incrementing the version number of a detected dirty Item during flushing, Hibernate compares versions when executing the UPDATE and DELETE SQL statements. For example, assume that in a unit of work, you load an Item and change its name, as follows.
Listing 11.3. Hibernate incrementing and checking the version automatically
Path: /examples/src/test/java/orgjpwh/test/concurrency/Versioning.java

- Retrieving an entity instance by identifier loads the current version from the database with a SELECT.
- The current version of the Item instance is 0.
- When the persistence context is flushed, Hibernate detects the dirty Item instance and increments its version to 1. SQL UPDATE now performs the version check, storing the new version in the database, but only if the database version is still 0.
Pay attention to the SQL statements, in particular the UPDATE and its WHERE clause. This update will be successful only if there is a row with VERSION = 0 in the database. JDBC returns the number of updated rows to Hibernate; if that result is zero, it means the ITEM row is either gone or doesn’t have the version 0 anymore. Hibernate detects this conflict during flushing, and a javax.persistence.OptimisticLockException is thrown.
Now imagine two users executing this unit of work at the same time, as shown previously in figure 11.4. The first user to commit updates the name of the Item and flushes the incremented version 1 to the database. The second user’s flush (and commit) will fail, because their UPDATE statement can’t find the row in the database with version 0. The database version is 1. Hence, the first commit wins, and you can catch the OptimisticLockException and handle it specifically. For example, you could show the following message to the second user: “The data you have been working with has been modified by someone else. Please start your unit of work again with fresh data. Click the Restart button to proceed.”
What modifications trigger the increment of an entity’s version? Hibernate increments the version whenever an entity instance is dirty. This includes all dirty value-typed properties of the entity, no matter if they’re single-valued (like a String or int property), embedded (like an Address), or collections. The exceptions are @OneToMany and @ManyToMany association collections that have been made read-only with mappedBy. Adding or removing elements to these collections doesn’t increment the version number of the owning entity instance. You should know that none of this is standardized in JPA—don’t rely on two JPA providers implementing the same rules when accessing a shared database.
If several applications access your database, and they don’t all use Hibernate’s versioning algorithm, you’ll have concurrency problems. An easy solution is to use database-level triggers and stored procedures: An INSTEAD OF trigger can execute a stored procedure when any UPDATE is made; it runs instead of the update. In the procedure, you can check whether the application incremented the version of the row; if the version isn’t updated or the version column isn’t included in the update, you know the statement wasn’t sent by a Hibernate application. You can then increment the version in the procedure before applying the UPDATE.
If you don’t want to increment the version of the entity instance when a particular property’s value has changed, annotate the property with @org.hibernate.annotations.OptimisticLock(excluded = true). You may not like the additional VERSION column in your database schema. Alternatively, you may already have a “last updated” timestamp property on your entity class and a matching database column. Hibernate can check versions with timestamps instead of the extra counter field.
Versioning with timestamps
If your database schema already contains a timestamp column such as LASTUPDATED or MODIFIED_ON, you can map it for automatic version checking instead of using a numeric counter.
Listing 11.4. Enabling versioning with timestamps
Path: /model/src/main/java/org/jpwh/model/concurrency/versiontimestamp/Item.java
@Entity public class Item { <enter/> @Version // Optional: @org.hibernate.annotations.Type(type = "dbtimestamp") protected Date lastUpdated; <enter/> // ... }
This example maps the column LASTUPDATED to a java.util.Date property; a Calendar type would also work with Hibernate. The JPA standard doesn’t define these types for version properties; JPA only considers java.sql.Timestamp portable. This is less attractive, because you’d have to import that JDBC class in your domain model. You should try to keep implementation details such as JDBC out of the domain model classes so they can be tested, instantiated, cross-compiled (to JavaScript with GWT, for example), serialized, and deserialized in as many environments as possible.
In theory, versioning with a timestamp is slightly less safe, because two concurrent transactions may both load and update the same Item in the same millisecond; this is exacerbated by the fact that a JVM usually doesn’t have millisecond accuracy (you should check your JVM and operating system documentation for the guaranteed precision). Furthermore, retrieving the current time from the JVM isn’ t necessarily safe in a clustered environment, where the system time of nodes may not be synchronized, or time synchronization isn’t as accurate as you’d need for your transactional load.
You can switch to retrieval of the current time from the database machine by placing an @org.hibernate.annotations.Type(type="dbtimestamp") annotation on the version property. Hibernate now asks the database, with for example call current _timestamp() on H2, for the current time before updating. This gives you a single source of time for synchronization. Not all Hibernate SQL dialects support this, so check the source of your configured dialect and whether it overrides the get-CurrentTimestampSelectString() method. In addition, there is always the overhead of hitting the database for every increment.
We recommend that new projects rely on versioning with a numeric counter, not timestamps. If you’re working with a legacy database schema or existing Java classes, it may be impossible to introduce a version or timestamp property and column. If that’s the case, Hibernate has an alternative strategy for you.
Versioning without version numbers or timestamps
If you don’t have version or timestamp columns, Hibernate can still perform automatic versioning. This alternative implementation of versioning checks the current database state against the unmodified values of persistent properties at the time Hibernate retrieved the entity instance (or the last time the persistence context was flushed).
You enable this functionality with the proprietary Hibernate annotation @org.hibernate.annotations.OptimisticLocking:
Path: modelsrcmainjavaorgjpwhmodelconcurrencyversionallItem.java
@Entity @org.hibernate.annotations.OptimisticLocking( type = org.hibernate.annotations.OptimisticLockType.ALL) @org.hibernate.annotations.DynamicUpdate public class Item { <enter/> // ... }
For this strategy, you also have to enable dynamic SQL generation of UPDATE statements, using @org.hibernate.annotations.DynamicUpdate as explained in section 4.3.2.
Hibernate now executes the following SQL to flush a modification of an Item instance:
update ITEM set NAME = 'New Name' where ID = 123 and NAME = 'Old Name' and PRICE = '9.99' and DESCRIPTION = 'Some item for auction' and ... and SELLER_ID = 45
Hibernate lists all columns and their last known values in the WHERE clause. If any concurrent transaction has modified any of these values or even deleted the row, this statement returns with zero updated rows. Hibernate then throws an exception at flush time.
Alternatively, Hibernate includes only the modified properties in the restriction (only NAME, in this example) if you switch to OptimisticLockType.DIRTY. This means two units of work may modify the same Item concurrently, and Hibernate detects a conflict only if they both modify the same value-typed property (or a foreign key value). The WHERE clause of the last SQL excerpt would be reduced to where ID = 123 and NAME = 'Old Name'. Someone else could concurrently modify the price, and Hibernate wouldn’t detect any conflict. Only if the application modified the name concurrently would you get a javax.persistence.OptimisticLockException.
In most cases, checking only dirty properties isn’t a good strategy for business entities. It’s probably not OK to change the price of an item if the description changes!
This strategy also doesn’t work with detached entities and merging: if you merge a detached entity into a new persistence context, the “old” values aren’t known. The detached entity instance will have to carry a version number or timestamp for optimistic concurrency control.
Automatic versioning in Java Persistence prevents lost updates when two concurrent transactions try to commit modifications on the same piece of data. Versioning can also help you to obtain additional isolation guarantees manually when you need them.
Manual version checking
Here’s a scenario that requires repeatable database reads: imagine you have some categories in your auction system and that each Item is in a Category. This is a regular @ManyToOne mapping of an Item#category entity association.
Let’s say you want to sum up all item prices in several categories. This requires a query for all items in each category, to add up the prices. The problem is, what happens if someone moves an Item from one Category to another Category while you’re still querying and iterating through all the categories and items? With read-committed isolation, the same Item might show up twice while your procedure runs!
To make the “get items in each category” reads repeatable, JPA’s Query interface has a setLockMode() method. Look at the procedure in the following listing.
Listing 11.5. Requesting a version check at flush time to ensure repeatable reads
Path: /examples/src/test/java/org/jpwh/test/concurrency/Versioning.java

- For each Category, query all Item instances with an OPTIMISTIC lock mode. Hibernate now knows it has to check each Item at flush time.
- For each Item loaded earlier with the locking query, Hibernate executes a SELECT during flushing. It checks whether the database version of each ITEM row is still the same as when it was loaded. If any ITEM row has a different version or the row no longer exists, an OptimisticLockException is thrown.
Don’t be confused by the locking terminology: The JPA specification leaves open how exactly each LockModeType is implemented; for OPTIMISTIC, Hibernate performs version checking. There are no actual locks involved. You’ll have to enable versioning on the Item entity class as explained earlier; otherwise, you can’t use the optimistic LockModeTypes with Hibernate.
Hibernate doesn’t batch or otherwise optimize the SELECT statements for manual version checking: If you sum up 100 items, you get 100 additional queries at flush time. A pessimistic approach, as we show later in this chapter, may be a better solution for this particular case.
The “get all items in a particular category” query returns item data in a ResultSet. Hibernate then looks at the primary key values in this data and first tries to resolve the rest of the details of each Item in the persistence context cache—it checks whether an Item instance has already been loaded with that identifier. This cache, however, doesn’t help in the example procedure: if a concurrent transaction moved an item to another category, that item might be returned several times in different ResultSets. Hibernate will perform its persistence context lookup and say, “Oh, I’ve already loaded that Item instance; let’s use what we already have in memory.” Hibernate isn’t even aware that the category assigned to the item changed or that the item appeared again in a different result. Hence this is a case where the repeatable-read feature of the persistence context hides concurrently committed data. You need to manually check the versions to find out if the data changed while you were expecting it not to change.
As shown in the previous example, the Query interface accepts a LockModeType. Explicit lock modes are also supported by the TypedQuery and the NamedQuery interfaces, with the same setLockMode() method.
An additional optimistic lock mode is available in JPA, forcing an increment of an entity’s version.
Forcing a version increment
What happens if two users place a bid for the same auction item at the same time? When a user makes a new bid, the application must do several things:
1. Retrieve the currently highest Bid for the Item from the database.
2. Compare the new Bid with the highest Bid; if the new Bid is higher, it must be stored in the database.
There is the potential for a race condition in between these two steps. If, in between reading the highest Bid and placing the new Bid, another Bid is made, you won’t see it. This conflict isn’t visible; even enabling versioning of the Item doesn’t help. The Item is never modified during the procedure. Forcing a version increment of the Item makes the conflict detectable.
Listing 11.6. Forcing a version increment of an entity instance
Path: /examples/src/test/java/org/jpwh/test/concurrency/Versioning.java

- find() accepts a LockModeType. The OPTIMISTIC_FORCE_INCREMENT mode tells Hibernate that the version of the retrieved Item should be incremented after loading, even if it’s never modified in the unit of work.
- The code persists a new Bid instance; this doesn’t affect any values of the Item instance. A new row is inserted into the BID table. Hibernate wouldn’t detect concurrently made bids without a forced version increment of the Item.
- You use a checked exception to validate the new bid amount. It must be greater than the currently highest bid.
- When flushing the persistence context, Hibernate executes an INSERT for the new Bid and forces an UPDATE of the Item with a version check. If someone modified the Item concurrently or placed a Bid concurrently with this procedure, Hibernate throws an exception.
For the auction system, placing bids concurrently is certainly a frequent operation. Incrementing a version manually is useful in many situations where you insert or modify data and want the version of some root instance of an aggregate to be -incremented.
Note that if instead of a Bid#item entity association with @ManyToOne, you have an @ElementCollection of Item#bids, adding a Bid to the collection will increment the Item version. The forced increment then isn’t necessary. You may want to review the discussion of parent/child ambiguity and how aggregates and composition work with ORM in section 7.3.
So far, we’ve focused on optimistic concurrency control: we expect that concurrent modifications are rare, so we don’t prevent concurrent access and detect conflicts late. Sometimes you know that conflicts will happen frequently, and you want to place an exclusive lock on some data. This calls for a pessimistic approach.
11.2.3. Explicit pessimistic locking
Let’s repeat the procedure shown in the section “Manual version checking” with a pessimistic lock instead of optimistic version checking. You again summarize the total price of all items in several categories. This is the same code as shown earlier in listing 11.5, with a different LockModeType.
Listing 11.7. Locking data pessimistically
Path: /examples/src/test/java/org/jpwh/test/concurrency/Locking.java

- For each Category, query all Item instances in PESSIMISTIC_READ lock mode. Hibernate locks the rows in the database with the SQL query. If possible, wait 5 seconds if another transaction holds a conflicting lock. If the lock can’t be obtained, the query throws an exception.
- If the query returns successfully, you know that you hold an exclusive lock on the data and no other transaction can access it with an exclusive lock or modify it until this transaction commits.
- Your locks are released after commit, when the transaction completes.
The JPA specification defines that the lock mode PESSIMISTIC_READ guarantees repeatable reads. JPA also standardizes the PESSIMISTIC_WRITE mode, with additional guarantees: in addition to repeatable reads, the JPA provider must serialize data access, and no phantom reads can occur.
It’s up to the JPA provider to implement these requirements. For both modes, Hibernate appends a “for update” clause to the SQL query when loading data. This places a lock on the rows at the database level. What kind of lock Hibernate uses depends on the LockModeType and your Hibernate database dialect.
On H2, for example, the query is SELECT * FROM ITEM ... FOR UPDATE. Because H2 supports only one type of exclusive lock, Hibernate generates the same SQL for all pessimistic modes.
PostgreSQL, on the other hand, supports shared read locks: the PESSIMISTIC_READ mode appends FOR SHARE to the SQL query. PESSIMISTIC_WRITE uses an exclusive write lock with FOR UPDATE.
On MySQL, PESSIMISTIC_READ translates to LOCK IN SHARE MODE, and PESSIMISTIC_ WRITE to FOR UPDATE. Check your database dialect. This is configured with the getReadLockString() and getWriteLockString() methods.
The duration of a pessimistic lock in JPA is a single database transaction. This means you can’t use an exclusive lock to block concurrent access for longer than a single database transaction. When the database lock can’t be obtained, an exception is thrown. Compare this with an optimistic approach, where Hibernate throws an exception at commit time, not when you query. With a pessimistic strategy, you know that you can read and write the data safely as soon as your locking query succeeds. With an optimistic approach, you hope for the best and may be surprised later, when you commit.
Pessimistic database locks are held only for a single transaction. Other lock implementations are possible: for example, a lock held in memory, or a so-called lock table in the database. A common name for these kinds of locks is offline locks.
Locking pessimistically for longer than a single database transaction is usually a performance bottleneck; every data access involves additional lock checks to a globally synchronized lock manager. Optimistic locking, however, is the perfect concurrency control strategy for long-running conversations (as you’ll see in the next chapter) and performs well. Depending on your conflict-resolution strategy—what happens after a conflict is detected—your application users may be just as happy as with blocked concurrent access. They may also appreciate the application not locking them out of particular screens while others look at the same data.
You can configure how long the database will wait to obtain the lock and block the query in milliseconds with the javax.persistence.lock.timeout hint. As usual with hints, Hibernate might ignore it, depending on your database product. H2, for example, doesn’t support lock timeouts per query, only a global lock timeout per connection (defaulting to 1 second). With some dialects, such as PostgreSQL and Oracle, a lock timeout of 0 appends the NOWAIT clause to the SQL string.
We’ve shown the lock timeout hint applied to a Query. You can also set the timeout hint for find() operations:
Path: /examples/src/test/java/org/jpwh/test/concurrency/Locking.java
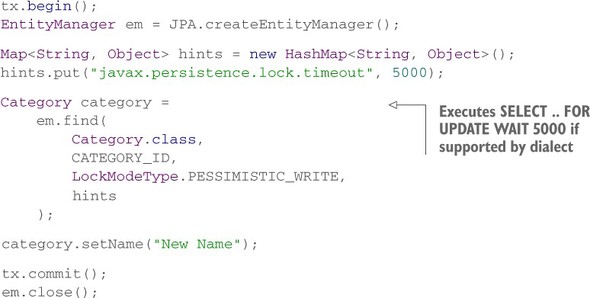
When a lock can’t be obtained, Hibernate throws either a javax.persistence.LockTimeoutException or a javax.persistence.PessimisticLockException. If Hibernate throws a PessimisticLockException, the transaction must be rolled back, and the unit of work ends. A timeout exception, on the other hand, isn’t fatal for the transaction, as explained in section 11.1.4. Which exception Hibernate throws again depends on the SQL dialect. For example, because H2 doesn’t support per-statement lock timeouts, you always get a PessimisticLockException.
You can use both the PESSIMISTIC_READ and PESSIMISTIC_WRITE lock modes even if you haven’t enabled entity versioning. They translate to SQL statements with database-level locks.
The special mode PESSIMISTIC_FORCE_INCREMENT requires versioned entities, however. In Hibernate, this mode executes a FOR UPDATE NOWAIT lock (or whatever your dialect supports; check its getForUpdateNowaitString() implementation). Then, immediately after the query returns, Hibernate increments the version and UPDATE (!) each returned entity instance. This indicates to any concurrent transaction that you have updated these rows, even if you haven’t so far modified any data. This mode is rarely useful, mostly for aggregate locking as explained in the section “Forcing a version increment.”
These are older lock modes from Java Persistence 1.0, and you should no longer use them. LockModeType.READ is equivalent to OPTIMISTIC, and LockModeType.WRITE is equivalent to OPTIMISTIC_FORCE_INCREMENT.
If you enable pessimistic locking, Hibernate locks only rows that correspond to entity instance state. In other words, if you lock an Item instance, Hibernate will lock its row in the ITEM table. If you have a joined inheritance mapping strategy, Hibernate will recognize this and lock the appropriate rows in super- and sub-tables. This also applies to any secondary table mappings of an entity. Because Hibernate locks entire rows, any relationship where the foreign key is in that row will also effectively be locked: The Item#seller association is locked if the SELLER_ID foreign key column is in the ITEM table. The actual Seller instance isn’t locked! Neither are collections or other associations of the Item where the foreign key(s) are in other tables.
With exclusive locking in the DBMS, you may experience transaction failures because you run into deadlock situations.
JPA 2.0 defines the PessimisticLockScope.EXTENDED option. It can be set as a query hint with javax.persistence.lock.scope. If enabled, the persistence engine expands the scope of locked data to include any data in collection and association join tables of locked entities. At the time of writing, Hibernate doesn’t implement this feature.
11.2.4. Avoiding deadlocks
Deadlocks can occur if your DBMS relies on exclusive locks to implement transaction isolation. Consider the following unit of work, updating two Item entity instances in a particular order:
tx.begin(); EntityManager em = JPA.createEntityManager(); <enter/> Item itemOne = em.find(Item.class, ITEM_ONE_ID); itemOne.setName("First new name"); <enter/> Item itemTwo = em.find(Item.class, ITEM_TWO_ID); itemTwo.setName("Second new name"); <enter/> tx.commit(); em.close();
Hibernate executes two SQL UPDATE statements when the persistence context is flushed. The first UPDATE locks the row representing Item one, and the second UPDATE locks Item two:
![]()
A deadlock may (or it may not!) occur if a similar procedure, with the opposite order of Item updates, executes in a concurrent transaction:
![]()
With a deadlock, both transactions are blocked and can’t move forward, each waiting for a lock to be released. The chance of a deadlock is usually small, but in highly concurrent applications, two Hibernate applications may execute this kind of interleaved update. Note that you may not see deadlocks during testing (unless you write the right kinds of tests). Deadlocks can suddenly appear when the application has to handle a high transaction load in production. Usually the DBMS terminates one of the deadlocked transactions after a timeout period and fails; the other transaction can then proceed. Alternatively, depending on the DBMS, the DBMS may detect a deadlock situation automatically and immediately abort one of the transactions.
You should try to avoid transaction failures, because they’re difficult to recover from in application code. One solution is to run the database connection in serializable mode when updating a single row locks the entire table. The concurrent transaction has to wait until the first transaction completes its work. Alternatively, the first transaction can obtain an exclusive lock on all data when you SELECT the data, as shown in the previous section. Then any concurrent transaction also has to wait until these locks are released.
An alternative pragmatic optimization that significantly reduces the probability of deadlocks is to order the UPDATE statements by primary key value: Hibernate should always update the row with primary key 1 before updating row 2, no matter in what order the data was loaded and modified by the application. You can enable this optimization for the entire persistence unit with the configuration property hibernate.order_updates. Hibernate then orders all UPDATE statements it executes in ascending order by primary key value of the modified entity instances and collection elements detected during flushing. (As mentioned earlier, make sure you fully understand the transactional and locking behavior of your DBMS product. Hibernate inherits most of its transaction guarantees from the DBMS; for example, your MVCC database product may avoid read locks but probably depends on exclusive locks for writer isolation, and you may see deadlocks.)
We didn’t have an opportunity to mention the EntityManager#lock() method. It accepts an already-loaded persistent entity instance and a lock mode. It performs the same locking you’ve seen with find() and a Query, except that it doesn’t load the instance. Additionally, if a versioned entity is being locked pessimistically, the lock() method performs an immediate version check on the database and potentially throws an OptimisticLockException. If the database representation is no longer present, Hibernate throws an EntityNotFoundException. Finally, the EntityManager#refresh() method also accepts a lock mode, with the same semantics.
We’ve now covered concurrency control at the lowest level—the database—and the optimistic and pessimistic locking features of JPA. We still have one more aspect of concurrency to discuss: accessing data outside of a transaction.
11.3. Nontransactional data access
A JDBC Connection is by default in auto-commit mode. This mode is useful for executing ad hoc SQL.
Imagine that you connect to your database with an SQL console and that you run a few queries, and maybe even update and delete rows. This interactive data access is ad hoc; most of the time you don’t have a plan or a sequence of statements that you consider a unit of work. The default auto-commit mode on the database connection is perfect for this kind of data access—after all, you don’t want to type begin transaction and end transaction for every SQL statement you write and execute. In auto-commit mode, a (short) database transaction begins and ends for each SQL statement you send to the database. You’re working effectively in nontransactional mode, because there are no atomicity or isolation guarantees for your session with the SQL console. (The only guarantee is that a single SQL statement is atomic.)
An application, by definition, always executes a planned sequence of statements. It seems reasonable that you therefore always create transaction boundaries to group your statements into units that are atomic and isolated from each other. In JPA, however, special behavior is associated with auto-commit mode, and you may need it to implement long-running conversations. You can access the database in auto-commit mode and read data.
11.3.1. Reading data in auto-commit mode
Consider the following example, which loads an Item instance, changes its name, and then rolls back that change by refreshing.
Listing 11.8. Reading data in auto-commit mode
Path: /examples/src/test/java/org/jpwh/test/concurrency/NonTransactional.java

- No transaction is active when you create the EntityManager. The persistence context is now in a special unsynchronized mode; Hibernate won’t flush automatically.
- You can access the database to read data; this operation executes a SELECT, sent to the database in auto-commit mode.
- Usually Hibernate flushes the persistence context when you execute a Query. But because the context is unsynchronized, flushing doesn’t occur, and the query returns the old, original database value. Queries with scalar results aren’t repeatable: you see whatever values are in the database and given to Hibernate in the ResultSet. This also isn’t a repeatable read if you’re in synchronized mode.
- Retrieving a managed entity instance involves a lookup during JDBC result-set marshaling, in the current persistence context. The already-loaded Item instance with the changed name is returned from the persistence context; values from the database are ignored. This is a repeatable read of an entity instance, even without a system transaction.
- If you try to flush the persistence context manually, to store the new Item#name, Hibernate throws a javax.persistence.TransactionRequiredException. You can’t execute an UPDATE in unsynchronized mode, because you wouldn’t be able to roll back the change.
- You can roll back the change you made with the refresh() method. It loads the current Item state from the database and overwrites the change you made in memory.
With an unsynchronized persistence context, you read data in auto-commit mode with find(), getReference(), refresh(), or queries. You can load data on demand as well: proxies are initialized if you access them, and collections are loaded if you start iterating through their elements. But if you try to flush the persistence context or lock data with anything but LockModeType.NONE, a TransactionRequiredException will occur.
So far, auto-commit mode doesn’t seem very useful. Indeed, many developers often rely on auto-commit for the wrong reasons:
- Many small per-statement database transactions (that’s what auto-commit means) won’t improve the performance of your application.
- You won’t improve the scalability of your application: a longer-running database transaction, instead of many small transactions for every SQL statement, may hold database locks for a longer time. This is a minor issue, because Hibernate writes to the database as late as possible within a transaction (flush at commit), so the database already holds write locks for a short time.
- You also have weaker isolation guarantees if the application modifies data concurrently. Repeatable reads based on read locks are impossible with auto-commit mode. (The persistence context cache helps here, naturally.)
- If your DBMS has MVCC (for example, Oracle, PostreSQL, Informix, and Firebird), you likely want to use its capability for snapshot isolation to avoid unrepeatable and phantom reads. Each transaction gets its own personal snapshot of the data; you only see a (database-internal) version of the data as it was before your transaction started. With auto-commit mode, snapshot isolation makes no sense, because there is no transaction scope.
- Your code will be more difficult to understand. Any reader of your code now has to pay special attention to whether a persistence context is joined with a transaction, or if it’s in unsynchronized mode. If you always group operations within a system transaction, even if you only read data, everyone can follow this simple rule, and the likelihood of difficult-to-find concurrency issues is reduced.
So, what are the benefits of an unsynchronized persistence context? If flushing doesn’t happen automatically, you can prepare and queue modifications outside of a transaction.
11.3.2. Queueing modifications
The following example stores a new Item instance with an unsynchronized EntityManager:
Path: /examples/src/test/java/org/jpwh/test/concurrency/NonTransactional.java

- You can call persist() to save a transient entity instance with an unsynchronized persistence context. Hibernate only fetches a new identifier value, typically by calling a database sequence, and assigns it to the instance. The instance is now in persistent state in the context, but the SQL INSERT hasn’t happened. Note that this is only possible with pre-insert identifier generators; see section 4.2.5.
- When you’re ready to store the changes, join the persistence context with a transaction. Synchronization and flushing occur as usual, when the transaction commits. Hibernate writes all queued operations to the database. Merged changes of a detached entity instance can also be queued:
Path: /examples/src/test/java/org/jpwh/test/concurrency/NonTransactional.java

Hibernate executes a SELECT in auto-commit mode when you merge(). Hibernate defers the UPDATE until a joined transaction commits.
Queuing also works for removal of entity instances and DELETE operations:
Path: /examples/src/test/java/org/jpwh/test/concurrency/NonTransactional.java

An unsynchronized persistence context therefore allows you to decouple persistence operations from transactions. This special behavior of the EntityManager will be essential later in the book, when we discuss application design. The ability to queue data modifications, independent from transactions (and client/server requests), is a major feature of the persistence context.
Hibernate offers a Session#setFlushMode() method, with the additional Flush-Mode.MANUAL. It’s a much more convenient switch that disables any automatic flushing of the persistence context, even when a joined transaction commits. With this mode, you have to call flush() explicitly to synchronize with the database. In JPA, the idea was that a “transaction commit should always write any outstanding changes,” so reading was separated from writing with the unsynchronized mode. If you don’t agree with this and/or don’t want auto-committed statements, enable manual flushing with the Session API. You can then have regular transaction boundaries for all units of work, with repeatable reads and even snapshot isolation from your MVCC database, but still queue changes in the persistence context for later execution and manual flush() before your transaction commits.
11.4. Summary
- You learned to use transactions, concurrency, isolation, and locking.
- Hibernate relies on a database’s concurrency-control mechanism but provides better isolation guarantees in a transaction, thanks to automatic versioning and the persistence context cache.
- We discussed how to set transaction boundaries programmatically and handle exceptions.
- You explored optimistic concurrency control and explicit pessimistic locking.
- You saw how to work with auto-commit mode and an unsynchronized persistence context outside of a transaction, and how to queue modification.