
Chapter 7
Implementing Popular Interview Algorithms
This chapter looks at some popular questions used in interviews. Although these questions will probably not come up in the exact form presented here, they serve as a good introduction to the level and approach that interviewers take.
Many of the questions here have been taken from the website Interview Zen, (www.interviewzen.com) where they have been used in real interviews for real developers.
When you are asked in an interview to write or develop an algorithm, you should be focusing on how efficient the algorithm is. Efficiency can take several forms: The running time of an algorithm is usually the main point of focus, but it is also important to consider the space an algorithm uses. Quite often, you will need to strike a balance between these two depending on your requirements.
A common method for describing the efficiency of an algorithm is called Big O Notation. This is used to describe how an algorithm reacts to a change to its input.
An algorithm with O(n) is said to have linear complexity: As the size of the input, n, increases, the performance of the algorithm increases by a proportional amount.
An O(n2) complexity is said to be quadratic: if you tripled the size of the input, the algorithm would take nine times longer to run. As you would expect, quadratic, or worse, exponential (O(nn)) algorithms should be avoided where possible.
Implementing FizzBuzz
Write an algorithm that prints all numbers between 1 and n, replacing multiples of 3 with the StringFizz, multiples of 5 with Buzz, and multiples of 15 with FizzBuzz.
This question is extremely popular, and definitely one of the most used on Interview Zen. The implementation should not be too hard, and is shown in Listing 7-1.
Listing 7-1: A simple implementation of the “FizzBuzz” interview question
public static List<String> fizzBuzz(final int n) {
final List<String> toReturn = new ArrayList<>(n);
for (int i = 1; i <= n; i++) {
if(i % 15 == 0) {
toReturn.add("FizzBuzz");
} else if (i % 3 == 0) {
toReturn.add("Fizz");
} else if (i % 5 == 0) {
toReturn.add("Buzz");
} else {
toReturn.add(Integer.toString(i));
}
}
return toReturn;
}The one catch is to check for the FizzBuzz case before the others, because values divisible by 15 are also divisible by 3 and 5. You would miss this if you checked the 3 and 5 cases first.
Interviewers often look for examples of code reuse, and logical abstraction. Listing 7-1 does not do this particularly well.
It should be possible to provide an abstraction over the different cases for Fizz, Buzz, and FizzBuzz. This would allow for the different cases to be easily tested in isolation, and even changed to return different words for different values, should you wish. This is shown in Listing 7-2.
Listing 7-2: Abstraction with FizzBuzz
public static List<String> alternativeFizzBuzz(final int n) {
final List<String> toReturn = new ArrayList<>(n);
for (int i = 1; i <= n; i++) {
final String word =
toWord(3, i, "Fizz") + toWord(5, i, "Buzz");
if(StringUtils.isEmpty(word)) {
toReturn.add(Integer.toString(i));
}
else {
toReturn.add(word);
}
}
return toReturn;
}
private static String toWord(final int divisor,
final int value,
final String word) {
return value % divisor == 0 ? word : "";
}
When the toWord method does not return a match, it returns an empty String. This allows you to check for 3 and 5 together: if a number is divisible by 3 but not 5, then the 5 case will return an empty String, and so Fizz will be concatenated with an empty String. When a number is divisible by 15, that is, divisible by both 3 and 5, then Fizz will be concatenated with Buzz, giving FizzBuzz.
A check is still required to see if either check was successful: An empty String denotes neither check was divisible.
Write a method that returns a Fibonacci sequence from 1 to n.
Demonstrating the Fibonacci Sequence
The Fibonacci sequence is a list of numbers, where the next value in the sequence is the sum of the previous two. The sequence defines that the first number is zero, and the next is one.
Such an algorithm will have a method signature like:
public static List<Integer> fibonacci(int n)That is, given a value n, the method will return a list, in order, of the Fibonacci sequence to n. The method can be static, because it does not rely on any object state or an instance to be constructed.
The parameter has one main constraint: n must be greater than or equal to zero. Due to the definition of the sequence, there is also some efficiency that can be applied when the parameter is 0, 1, or 2. If the parameter is zero, return an empty list. If the parameter is 1, return a list containing a solitary zero, and if the parameter is 2, you can return a list containing 0 and 1 in that order.
For any other value of n, you can build the list one value at a time, simply adding the last two values in the list, starting with a list containing 0 and 1. Listing 7-3 shows a working, iterative approach.
Listing 7-3: An iterative Fibonacci sequence
public static List<Integer> fibonacci(int n) {
if (n < 0) {
throw new IllegalArgumentException(
"n must not be less than zero");
}
if (n == 0) {
return new ArrayList<>();
}
if (n == 1) {
return Arrays.asList(0);
}
if (n == 2) {
return Arrays.asList(0, 1);
}
final List<Integer> seq = new ArrayList<>(n);
seq.add(0);
n = n - 1;
seq.add(1);
n = n - 1;
while (n > 0) {
int a = seq.get(seq.size() - 1);
int b = seq.get(seq.size() - 2);
seq.add(a + b);
n = n - 1;
}
return seq;
}By decreasing the value of n each time a value is added, once n has reached zero, you have added enough values to the list. Retrieval of the previous two values in the array is guaranteed not to throw an ArrayIndexOutOfBoundsException, because you always start with a list containing at least two values.
You can write a simple unit test to verify that the algorithm works, as shown in Listing 7-4.
Listing 7-4: Testing the Fibonacci sequence
@Test
public void fibonacciList() {
assertEquals(0, fibonacci(0).size());
assertEquals(Arrays.asList(0), fibonacci(1));
assertEquals(Arrays.asList(0, 1), fibonacci(2));
assertEquals(Arrays.asList(0, 1, 1), fibonacci(3));
assertEquals(Arrays.asList(0, 1, 1, 2), fibonacci(4));
assertEquals(Arrays.asList(0, 1, 1, 2, 3), fibonacci(5));
assertEquals(Arrays.asList(0, 1, 1, 2, 3, 5), fibonacci(6));
assertEquals(Arrays.asList(0, 1, 1, 2, 3, 5, 8), fibonacci(7));
assertEquals(Arrays.asList(0, 1, 1, 2, 3, 5, 8, 13), fibonacci(8));
}You should test that a negative parameter would throw an exception, too.
Write a method that returns the nth value of the Fibonacci sequence.
This is a variation on the previous question. Rather than returning the whole Fibonacci sequence, this method only returns the value at position n. This algorithm would likely have a method signature like this:
public static int fibN(int n)Passing the value 0 would return 0; 1 would return 1; 2 would return 1; and so on.
A particularly naïve implementation could call the method developed in the previous question, and return the last value in the list. This, however, consumes a large amount of memory in creating the list, only to throw all but one value away. If you were to look for the millionth entry, this would take an unacceptable amount of time to run, and would need a lot of memory.
One better approach could be a recursive solution. From the algorithm definition:
Fibonacci(n) = Fibonacci(n – 1) + Fibonacci(n – 2)there are two base cases:
Fibonacci(1) = 1
Fibonacci(0) = 0This recursive definition will make an attractive recursive algorithm, as defined in Listing 7-5.
Listing 7-5: A recursive algorithm for finding the nth Fibonacci number
public static int fibN(int n) {
if (n < 0) {
throw new IllegalArgumentException(
"n must not be less than zero");
}
if (n == 1) return 1;
if (n == 0) return 0;
return (fibN(n - 1) + fibN(n - 2));
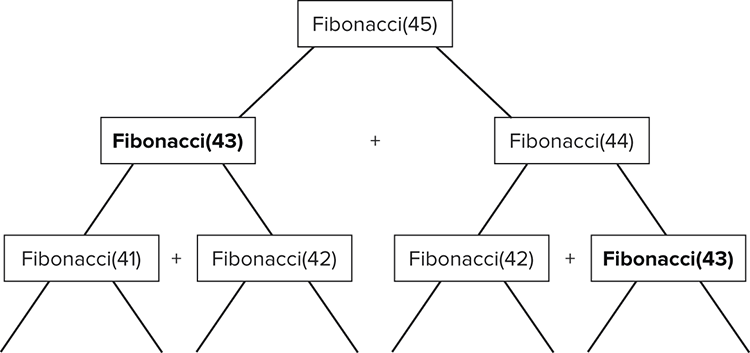
}As elegant as this solution appears, it is extremely inefficient. If you were calculating, for instance, the 45th value, this is made from the sum of Fibonacci(43) and Fibonacci(44). Fibonacci(44) itself is made from the sum of Fibonacci(42) and Fibonacci(43). This algorithm would calculate Fibonacci(43) on both occasions here, and this would happen many times throughout the whole calculation. This is more apparent in Figure 7-1.
if (condition) {
// code for condition == true
return valueIfTrue;
}
// more code for condition == false
return valueIfFalse;
By caching any calculated results, only unknown Fibonacci numbers would be calculated on a particular run. The results can be stored locally in a map. Listing 7-6 shows an improved approach to Listing 7-5.
Listing 7-6: Caching previously computed Fibonacci numbers
private Map<Integer, Integer> fibCache = new HashMap<>();
public int cachedFibN(int n) {
if (n < 0) {
throw new IllegalArgumentException(
"n must not be less than zero");
}
fibCache.put(0, 0);
fibCache.put(1, 1);
return recursiveCachedFibN(n);
}
private int recursiveCachedFibN(int n) {
if (fibCache.containsKey(n)) {
return fibCache.get(n);
}
int value = recursiveCachedFibN(n - 1) + recursiveCachedFibN(n - 2);
fibCache.put(n, value);
return value;
}Note here that the recursive method was split into a separate method, to detach the calculation from the setup of the map. Listing 7-7 shows a small unit test to measure the decrease in calculation time due to this optimization.
Listing 7-7: Measuring the performance increase
@Test
public void largeFib() {
final long nonCachedStart = System.nanoTime();
assertEquals(1134903170, fibN(45));
final long nonCachedFinish = System.nanoTime();
assertEquals(1134903170, cachedFibN(45));
final long cachedFinish = System.nanoTime();
System.out.printf(
"Non cached time: %d nanoseconds%n",
nonCachedFinish - nonCachedStart);
System.out.printf(
"Cached time: %d nanoseconds%n",
cachedFinish - nonCachedFinish);
}At the time of writing, it produced the following output:
Non cached time: 19211293000 nanoseconds
Cached time: 311000 nanosecondsQuite an improvement: from 19 seconds to 0.000311 seconds.
When the result of a method call is cached to save recalculating the result again later, this is called memoization.
The Big O Notation for the original implementation to calculate the nth Fibonacci number, is O(nn), and thus is extremely inefficient; too inefficient for anything useful than very low values of n. The memoized implementation has O(n), with the additional stipulation that it must store each value between 0 and n.
Demonstrating Factorials
Write a factorial implementation that does not use recursion.
A factorial method would be another good candidate for using recursion. The general algorithm for a factorial is:
Factorial(n) = n Factorial(n – 1)If you decide not to implement this in a recursive fashion, you can simply loop up to n, keeping track of the value to return, as shown in Listing 7-8.
Listing 7-8: An iterative implementation of a factorial
public static long factorial(int n) {
if (n < 1) {
throw new IllegalArgumentException(
"n must be greater than zero");
}
long toReturn = 1;
for (int i = 1; i <= n; i++) {
toReturn *= i;
}
return toReturn;
}Be aware that with factorials the calculated value grows large extremely quickly, which is why this method returns a long. You could even make a case for returning a BigInteger instance here. BigInteger objects have no upper bound; they allow for numerical integer values of any size.
Implementing Library Functionality
Given a list of words, produce an algorithm that will return a list of all anagrams for a specific word.
An anagram is a word that, when the letters are rearranged, produces another word. No letters can be removed or taken away.
A first attempt at writing an algorithm for this question could be something like the following pseudocode:
given a word a, and a list of words ws
given an empty list anagrams
for each word w in ws:
if (isAnagram(w, a)) add w to anagrams
return anagrams
method isAnagram(word1, word2):
for each letter letter in word1:
if (word2 contains letter):
remove letter from word2
continue with the next letter
else return false
if (word2 is empty) return true
else return falseThis pseudocode would definitely work. It examines each word in the given list and compares that word to the one to check. If all the letters match and there are no more, or fewer letters, it’s a match.
This algorithm is very inefficient. For a list of length m, and an average word length of n, the algorithm scans each word n times, one for each letter to check. This is measured as O(m n!), which is simply O(n!), because as n grows large, it will dominate the performance over m. Each letter in each word must be scanned for each letter in the word to check against. With a small amount of preparation, it is possible to slash the running time of this algorithm.
Every word can be thought to have an “algorithm signature.” That is, for all anagrams of a given word, they will all have the same signature. That signature is simply the letters of the word rearranged into alphabetical order.
If you store each word in a map against its signature, when you are presented with a word you calculate its signature and return the map entry of the list of words indexed at that signature. Listing 7-9 shows this implementation.
Listing 7-9: An efficient anagram finder
public class Anagrams {
final Map<String, List<String>> lookup = new HashMap<>();
public Anagrams(final List<String> words) {
for (final String word : words) {
final String signature = alphabetize(word);
if (lookup.containsKey(signature)) {
lookup.get(signature).add(word);
} else {
final List<String> anagramList = new ArrayList<>();
anagramList.add(word);
lookup.put(signature, anagramList);
}
}
}
private String alphabetize(final String word) {
final byte[] bytes = word.getBytes();
Arrays.sort(bytes);
return new String(bytes);
}
public List<String> getAnagrams(final String word) {
final String signature = alphabetize(word);
final List<String> anagrams = lookup.get(signature);
return anagrams == null ? new ArrayList<String>() : anagrams;
}
}The alphabetize method creates the signature for use in storing the word, and also for lookup when querying for any anagrams. This method makes use of the sorting algorithm in Java’s standard library, which was covered in Chapter 4 if you want to write a sort yourself.
The trade-off here is that you need to take time to preprocess the list into the different buckets of anagrams, and you will also need extra storage space. However, lookup times will drop from a potential O(n!) to O(1) for a list of length m with an average word length of n. It is O(1) because the hash function is able to directly locate the list of anagrams stored in the map. Don’t forget, there is the overhead to create the lookup in the first place, so the whole lookup algorithm has a Big O Notation of O(m).
Write a method to reverse a String.
In Java, a String is immutable, so once it has been constructed it is not possible to change the contents. So when you are asked to reverse a String, you are actually being asked to produce a new String object, with the contents reversed:
public static String reverse(final String s)One approach to reversing a String is to iterate over the contents in reverse, populating a new container such as a StringBuilder as you go, as shown in Listing 7-10.
Listing 7-10: Reversing a String using a StringBuilder
public static String reverse(final String s) {
final StringBuilder builder = new StringBuilder(s.length());
for (int i = s.length() - 1; i >= 0; i--) {
builder.append(s.charAt(i));
}
return builder.toString();
}This approach, while fine, does require a large amount of memory. It needs to hold the original String and the StringBuilder in memory. This could be problematic if you were reversing some data of several gigabytes in size.
It is possible to reverse the String in place, by loading the whole String instance into a StringBuilder, traversing the characters from one end, and swapping with the character the same length away from the other end of the String. This only requires one extra character of memory to facilitate the swapping of characters. Listing 7-11 shows this.
Listing 7-11: Reversing a String in place
public static String inPlaceReverse(final String s) {
final StringBuilder builder = new StringBuilder(s);
for (int i = 0; i < builder.length() / 2; i++) {
final char tmp = builder.charAt(i);
final int otherEnd = builder.length() - i - 1;
builder.setCharAt(i, builder.charAt(otherEnd));
builder.setCharAt(otherEnd, tmp);
}
return builder.toString();
}A common mistake with this approach is to traverse the whole String, rather than stopping halfway. If you traverse the whole String, you switch each character twice, and it returns to its original position! Simple errors like this can be easily mitigated with a small number of unit tests.
How do you reverse a linked list in place?
Following from String reversal, it is also possible to reverse a generic linked list in place. Given a linked list class definition:
public class LinkedList<T> {
private T element;
private LinkedList<T> next;
public LinkedList(T element, LinkedList<T> next) {
this.element = element;
this.next = next;
}
public T getElement() {
return element;
}
public LinkedList<T> getNext() {
return next;
}
}This recursive class definition takes other LinkedList instances, and assumes null to represent the end of the list.
This being a recursive definition, it makes sense to use a recursive algorithm to reverse the list. You would expect a method to perform the reversal to have a signature like the following:
public static <T> LinkedList<T> reverse(final LinkedList<T> original)This may look like it is returning a new copy of the elements in the original list, but actually, it is returning a reference to the last element in the structure, with next pointing to the LinkedList instance that was originally immediately before that.
The base case for this algorithm is when the next reference is null. If you have a one-element list, reversing that list is simply the same list.
The recursive step for this algorithm is to remove the link to the next element, reverse that next element, and then set the next element’s own next to be the current element—the original parameter. Listing 7-12 shows a possible implementation.
Listing 7-12: Reversing a linked list recursively
public static <T> LinkedList<T> reverse(final LinkedList<T> original) {
if (original == null) {
throw new NullPointerException("Cannot reverse a null list");
}
if(original.getNext() == null) {
return original;
}
final LinkedList<T> next = original.next;
original.next = null;
final LinkedList<T> othersReversed = reverse(next);
next.next = original;
return othersReversed;
}Figure 7-2 shows a linked list constructed in the unit test in Listing 7-13.

Listing 7-13: Testing the linked list reversal
@Test
public void reverseLinkedList() {
final LinkedList<String> three = new LinkedList<>("3", null);
final LinkedList<String> two = new LinkedList<>("2", three);
final LinkedList<String> one = new LinkedList<>("1", two);
final LinkedList<String> reversed = LinkedList.reverse(one);
assertEquals("3", reversed.getElement());
assertEquals("2", reversed.getNext().getElement());
assertEquals("1", reversed.getNext().getNext().getElement());
}How do you test if a word is a palindrome?
A palindrome is a word, or phrase, that when the letters are reversed, the spelling is the same. Some examples include, “eve,” “level,” or, ignoring the space, “top spot.”
An algorithm to check for palindromes is similar to that for reversing a String, although you need to take non-letter characters into account. Listing 7-14 is an example.
Listing 7-14: A palindrome checker
public static boolean isPalindrome(final String s) {
final String toCheck = s.toLowerCase();
int left = 0;
int right = toCheck.length() - 1;
while (left <= right) {
while(left < toCheck.length() &&
!Character.isLetter(toCheck.charAt(left))) {
left++;
}
while(right > 0 && !Character.isLetter(toCheck.charAt(right))) {
right--;
}
if (left > toCheck.length() || right < 0) {
return false;
}
if (toCheck.charAt(left) != toCheck.charAt(right)) {
return false;
}
left++;
right--;
}
return true;
}This implementation comprises two pointers: one looking at the left half of the String, and one looking at the right. As soon as the pointers cross, the check is complete.
By ignoring any characters that are not letters, each pointer needs to be individually checked until it is pointing to the next letter in the String. A successful comparison between two characters does not automatically imply the word is a palindrome, because another pair of letters may not match. As soon as one comparison fails, you know that the String does not read the same in reversed form.
If you do care about Strings being exactly the same in reverse, taking all punctuation into account, Listing 7-15 shows a much simpler approach using the reverse method from Listing 7-10.
Listing 7-15: A strict palindrome checker
public static boolean strictPalindrome(final String s) {
return s.equals(reverse(s));
}You can reuse your reverse method, leading to a one-line method: The fewer lines of code you need to write, the fewer places you can introduce bugs. Assuming the reverse method is fully tested, writing unit tests for this method will be very, very simple.
Write an algorithm that collapses a list of Iterators into a single Iterator.
Such an algorithm would have a signature like the following:
public static <T> Iterator<T> singleIterator(
final List<Iterator<T>> iteratorList)The Iterator interface has the following definition:
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}This algorithm will implement the Iterator interface, creating a new implementation that will treat the underlying list of Iterators as a single Iterator.
You will use the Iterators one at a time, and once one has been exhausted, you move on to the next Iterator.
The hasNext method can be a particular red herring, because when your current Iterator has been exhausted, it will return false, but you may still have Iterators to consume. Once all Iterators have been consumed, this method will return false.
Listing 7-16 shows the constructor for a ListIterator class, along with the hasNext method.
Listing 7-16: Creating an Iterator of Iterators
public static class ListIterator<T> implements Iterator<T> {
private final Iterator<Iterator<T>> listIterator;
private Iterator<T> currentIterator;
public ListIterator(List<Iterator<T>> iterators) {
this.listIterator = iterators.iterator();
this.currentIterator = listIterator.next();
}
@Override
public boolean hasNext() {
if(!currentIterator.hasNext()) {
if (!listIterator.hasNext()) {
return false;
}
currentIterator = listIterator.next();
hasNext();
}
return true;
}
... // see below for the remaining implementationThe class holds two fields: the complete Iterator of Iterators, and the current Iterator.
When the hasNext method is called, it checks to see if the current Iterator has any more elements. If so, the method simply returns true. If it is false, the method checks to see if the Iterator of Iterators has any more elements. If that, too, is exhausted, there are no more elements at all.
If the Iterator of Iterators does have more elements, then the currentIterator is set to the next iterator, and the hasNext method is called recursively. This means that the currentIterator reference could potentially advance several iterators before finding one where the hasNext method returns true, but the recursion will take care of that.
For the next and remove methods on the Iterator interface, these too pose problems. It is possible for the current Iterator to be exhausted, and therefore calling next would return a NoSuchElementException, but one of the following Iterators does have elements. Before calling next, the currentIterator reference needs to be updated. The code to update the currentIterator reference to the correct reference was written in the hasNext method, so you can simply call hasNext, and ignore the result. It is exactly the same for the remove method: Simply update the currentIterator reference before actually calling remove. Listing 7-17 shows the implementation.
Listing 7-17: The next and remove methods for the Iterator of Iterators
@Override
public T next() {
hasNext();
return currentIterator.next();
}
@Override
public void remove() {
hasNext();
currentIterator.remove();
}Listing 7-18 shows a sample unit test to verify the implementation.
Listing 7-18: Testing the Iterator of Iterators
@Test
public void multipleIterators() {
final Iterator<Integer> a = Arrays.asList(1, 2, 3, 4, 5).iterator();
final Iterator<Integer> b = Arrays.asList(6).iterator();
final Iterator<Integer> c = new ArrayList<Integer>().iterator();
final Iterator<Integer> d = new ArrayList<Integer>().iterator();
final Iterator<Integer> e = Arrays.asList(7, 8, 9).iterator();
final Iterator<Integer> singleIterator =
Iterators.singleIterator(Arrays.asList(a, b, c, d, e));
assertTrue(singleIterator.hasNext());
for (Integer i = 1; i <= 9; i++) {
assertEquals(i, singleIterator.next());
}
assertFalse(singleIterator.hasNext());
}Using Generics
Write a method that replicates a list of Integers, with 1 added to each element.
On examination, this question appears trivially easy, as shown in Listing 7-19.
Listing 7-19: Adding one to a list of numbers
public static List<Integer> addOne(final List<Integer> numbers) {
final ArrayList<Integer> toReturn = new ArrayList< >(numbers.size());
for (final Integer number : numbers) {
toReturn.add(number + 1);
}
return toReturn;
}Even adding a parameter to the method to allow you to add a different value rather than 1 is just as simple. But what if the question is modified to allow you to perform any operation on each element in the list?
Providing any client code with the facility to perform any operation can be particularly powerful. To allow any Integer operation, you can define a new interface, IntegerOperation, which has one method, taking an Integer, and returning an Integer:
public interface IntegerOperation {
Integer performOperation(Integer value);
}An implementation of this to add one would simply be as follows:
public class AddOneOperation implements IntegerOperation {
@Override
public Integer performOperation(Integer value) {
return value + 1;
}
}Listing 7-20 modifies the original addOne method to accept the IntegerOperation interface, and gives it a more appropriate name.
Listing 7-20: Performing any Integer operation on a list
public static List<Integer> updateList(final List<Integer> numbers,
final IntegerOperation op) {
final ArrayList<Integer> toReturn = new ArrayList<>(numbers.size());
for (final Integer number : numbers) {
toReturn.add(op.performOperation(number));
}
return toReturn;
}Listing 7-21 shows a unit test, with an anonymous implementation of IntegerOperation.
Listing 7-21: Testing the updateList method
@Test
public void positiveList() {
final List<Integer> numbers = Arrays.asList(4, 7, 2, -2, 8, -5, -7);
final List<Integer> expected = Arrays.asList(4, 7, 2, 2, 8, 5, 7);
final List<Integer> actual =
Lists.updateList(numbers, new IntegerOperation() {
@Override
public Integer performOperation(Integer value) {
return Math.abs(value);
}
});
assertEquals(expected, actual);
}This IntegerOperation implementation makes all values in the list positive.
The power of abstracting this operation should be clear. The updateList method has the ability to do anything to a list of Integers, such as ignoring whatever the value in the list is and replacing it with a constant, or even something more exotic such as printing the value to the console, or making a call to a URL with that number.
It would be even better if the updateList could be even more abstract; currently it only works with Integers. What if it could work with a list of any type, and return a list of a different type?
Take the following interface:
public interface GenericOperation<A, B> {
B performOperation(A value);
}This interface uses Java generics on the method performOperation to map the value passed into a different type, such as turning a String parameter into an Integer:
public class StringLengthOperation
implements GenericOperation<String, Integer> {
@Override
public Integer performOperation(String value) {
return value.length();
}
}Listing 7-22 shows an implementation mapping the list from one of a certain type into a list of another.
Listing 7-22: Mapping a list into a different type
public static <A, B> List<B> mapList(final List<A> values,
final GenericOperation<A, B> op) {
final ArrayList<B> toReturn = new ArrayList<>(values.size());
for (final A a : values) {
toReturn.add(op.performOperation(a));
}
return toReturn;
}Listing 7-23 shows how you can use this in conjunction with the StringLengthOperation class.
Listing 7-23: Testing the list mapping functionality
@Test
public void stringLengths() {
final List<String> strings = Arrays.asList(
"acing", "the", "java", "interview"
);
final List<Integer> expected = Arrays.asList(5, 3, 4, 9);
final List<Integer> actual =
Lists.mapList(strings, new StringLengthOperation());
assertEquals(expected, actual);
}Providing a generic abstraction such as this is something that functional languages, such as Scala provide within the language itself. Treating a function as a value, such as a String or an Integer allows them to be passed directly to functions. For more information about this, the appendix looks at Scala, and how to use functions as values.
Summary
The final question in this chapter shows that even remarkably simple questions can often expand into longer discussions, and this is often an approach taken in face-to-face interviews. Interviewers will start with simple questions, and will probe deeper and deeper to try to find the extent of your knowledge.
To prepare for answering questions in interviews, try to find some programming exercises to do at home. The questions in this chapter are some of the more popular questions taken from Interview Zen, but other common programming questions are some of the core computer science topics, such as sorting and searching, and algorithms around data structures, such as lists and maps.
This chapter has attempted to strike a balance between recursive and iterative implementations. Often, a recursive approach can appear simpler, and perhaps more elegant, although this comes at a price. Particular algorithms that perform a high number of recursive calls can throw a StackOverflowException, and may even be slower in performance over their iterative counterparts due to the extra setup in stack allocation for calling a method.
Tail recursivecalls can sometime be optimized into iterative approaches. Tail recursion is when the recursive step is the final step of the method: The compiler can replace the stack variables for the current method with those for the next method call, rather than creating a new stack frame. The JVM itself cannot handle this directly, but some compilers can do this for Java and other JVM-supported languages.
Regardless of a recursive or iterative implementation, always consider the performance of your algorithm. Many algorithms asked in interviews may have a simple, yet inefficient answer, and a more effective approach may become clearer with a little thought.
The reason for interviewers asking questions like the ones in this chapter is to examine your ability to write legible, reusable, clean code. There are plenty of other sources around for refactoring and writing code that is testable. Speaking with colleagues, and performing active code reviews is a great way to take feedback from anything you have written and to lean on the experience of others.
The next section of the book looks at core Java topics, covering the basics of the language and its libraries, as well as focusing strongly on unit testing.