
Part II
Core Java
This part concentrates on fundamentals of Java, which are relevant for any Java interview, independent of the specifics of any job application.
Chapter 8
Java Basics
This chapter covers the main elements of the Java ecosystem, including the core parts of the language, specific conventions to follow, and the use of core libraries. In any interview, as a bare minimum, an interviewer would expect you to thoroughly understand these topics. Any questions similar to the ones here should be seen as introductory, and would usually be used early in an interview session, or perhaps even used as pre-interview screening questions.
The Primitive Types
Name some of Java’s primitive types. How are these handled by the JVM?
The basic types in Java such as boolean, int, and double are known as primitive types. The JVM treats these differently from reference types, otherwise known as objects. Primitives always have a value; they can never be null.
When you are defining a variable for ints and longs, the compiler needs to be able to differentiate between the two types. You do this by using the suffix L after long values. The absence of L implies an int. The L can be either in upper- or lowercase, but it is recommended to always use uppercase. This way, anyone reading your code can easily tell the difference between the L and the number 1! This is also used with floats and doubles: floats can be defined with F, and doubles with D. The suffix is optional for doubles; its omission implies a double. Table 8-1 shows the primitive types and their sizes.
Table 8-1: Primitive Types and Their Sizes
| Primitive | Size (bits) |
| boolean | 1 |
| short | 16 |
| int | 32 |
| long | 64 |
| float | 32 |
| double | 64 |
| char | 16 |
Be aware that char is unsigned. That is, the range of values a char can take is from 0 to 65,535, because chars represent Unicode values.
If a primitive type is not set to a value when a variable is defined, it takes a default value. For boolean values, this is false. For the others, this is a representation of zero, such as 0 for ints or 0.0f for floats.
The compiler can promote values to their appropriate type when necessary, as shown in Listing 8-1.
Listing 8-1: Implicit upcasting to wider types
int value = Integer.MAX_VALUE;
long biggerValue = value + 1;With the exception of chars, the compiler can automatically use a wider type for a variable, because it is not possible to lose any precision, for instance, when stepping up from an int to a long, or a float to a double. The reverse is not true. When trying to assign a long value to an int, you must cast that value. This tells the compiler this is actually what you intend, and you are happy to lose precision, as shown in Listing 8-2.
Listing 8-2: Explicit downcasting to narrower types
long veryLargeNumber = Long.MAX_VALUE;
int fromLargeNumber = (int) veryLargeNumber;Only in the rarest of cases would you actually want to downcast. If you find yourself downcasting variables regularly, you are probably not using the correct type.
Why is there no positive equivalent for Integer.MIN_VALUE?
The storage of the binary values of short, int, and long use a representation in memory called Two’s Complement. For zero and positive binary numbers, Table 8-2 shows that the notation is as you would expect.
Table 8-2: Binary Representation of Positive Numbers
| Decimal Representation | Binary Representation |
| 0 | 0000 0000 |
| 1 | 0000 0001 |
| 2 | 0000 0010 |
In Two’s Complement notation, the negative equivalent of a positive value is calculated by applying a binary NOT and then adding 1.
If Two’s Complement is an unfamiliar or new concept, it may seem a little alien. It may even appear counter-intuitive, because negation now requires two instructions. The one main advantage to a Two’s Complement representation is that there is only one value for zero: There is no concept of a “negative zero.” This, in turn, means the system can store one extra negative value.
The most negative number available to be stored, according to Table 8-3, has a most significant bit of 1, and all remaining bits are zeros. Negating this by flipping all bits (0111 1111), and then adding one (1000 0000) brings you back to the original value; there is no positive equivalent! If it were necessary to make this value positive, you would have to use a wider type, such as a long, or possibly the more complex reference type of BigInteger, which is effectively unbounded.
If you try to perform a calculation that will result in a value larger than Integer.MAX_VALUE, or lower than Integer.MIN_VALUE, then only the least significant 32 bits will be used, resulting in an erroneous value. This is called overflow. Try this yourself—create a small unit test that adds one to Integer.MAX_VALUE, and see what the result is.
Listing 8-3 is a useful investigation, showing you cannot use an int to represent the absolute value of Integer.MIN_VALUE.
Table 8-3: Binary Representation of Some Negative Numbers
| Decimal Representation | Binary Representation |
| -1 | 1111 1111 |
| -2 | 1111 1110 |
| ... | |
| -127 | 1000 0001 |
| -128 | 1000 0000 |
Listing 8-3: Attempting to find the absolute value of the most negative int
@Test
public void absoluteOfMostNegativeValue() {
final int mostNegative = Integer.MIN_VALUE;
final int negated = Math.abs(mostNegative);
assertFalse(“No positive equivalent of Integer.MIN_VALUE”, negated > 0);
}This particular quirk is something to bear in mind if you are ever asked to implement a method for calculating the absolute value of an int, or indeed anything involving negative numbers.
Using Objects
What is a Java object?
An object can be defined as a collection of variables, which when viewed collectively represents a single, complex entity, and a collection of methods providing operations relevant to that entity. Concisely, objects encapsulate state and behavior.
After primitive types, all other variables in the Java programming language are reference types, better known as objects. Objects differ from primitives in many ways, but one of the most important distinctions is that there is a notation for the absence of an object, null. Variables can be set to null, and methods can return null too. Attempting to call a method on a null reference throws a NullPointerException. Listing 8-4 illustrates a NullPointerException being thrown. Exceptions are covered in more depth in the “Handling Exceptions” section later in this chapter.
Listing 8-4: Dealing with NullPointerExceptions
@Test(expected = NullPointerException.class)
public void expectNullPointerExceptionToBeThrown() {
final String s = null;
final int stringLength = s.length();
}Objects are reference types. What exactly does this mean? With primitive types, when declaring a variable, int i = 42, this is being assigned to a location in memory, with the value 42. If, later in the program, another variable is assigned to hold the value currently represented by i, say, int j = i, then another location in memory has been assigned to that same value. Subsequent changes to i do not affect the value of j, and vice versa.
In Java, a statement such as new ArrayList(20), requests an area in memory to store that data. When that created object is assigned to a variable, List myList = new ArrayList(20), then it can be said that myList points to that memory location. On the surface, this appears to act the same as a primitive type assignment, but it is not. If several variables are assigned to that same created object, known as an instance, then they are pointing to the same memory location. Making any changes to one instance will be reflected when accessing the other. Listing 8-5 shows this in action.
Listing 8-5: Several variables referencing the same instance in memory
@Test
public void objectMemoryAssignment() {
List<String> list1 = new ArrayList<>(20);
list1.add(“entry in list1”);
assertTrue(list1.size() == 1);
List list2 = list1;
list2.add(“entry in list2”);
assertTrue(list1.size() == 2);
}What effect does the final keyword have on object references?
The final keyword works in exactly the same way for objects as it does for primitive types. The value is set on variable definition, and after that, the value stored in that memory location cannot change. As previously discussed, variable definition and memory allocation are quite different between primitives and objects. Although the object reference cannot change, the values held within that object can change, unless they themselves are final. Listing 8-6 explores the final keyword.
Listing 8-6: The final keyword on object references
@Test
public void finalReferenceChanges() {
final int i = 42;
// i = 43; <- uncommenting this line would result in a compiler error
final List<String> list = new ArrayList<>(20);
// list = new ArrayList(50); <- uncommenting this line will result in an error
assertEquals(0, list.size());
list.add("adding a new value into my list");
assertEquals(1, list.size());
list.clear();
assertEquals(0, list.size());
}How do the visibility modifiers work for objects?
The visibility modifiers control access to the encapsulated state of the class and the methods controlling the instance’s behavior. A variable encapsulated within an object, or a method on that object, can have its visibility restricted by one of four definitions as shown in Table 8-4.
Remember that private member variables are available only to that class, not even to any subclasses: Private variables are deemed to be necessary for only that type and no other.
One common misconception about the private modifier is that private means a variable is only accessible to the instance. In reality, any other instance of that same type can access private member variables.
Table 8-4: Visibility Modifiers
| Visibility | Modifier | Scope |
| Least | private | Visible to any instance of that same class, not to subtypes |
| <none> | Visible to any class in the same package | |
| protected | Visible to any subclasses | |
| Most | public | Visible anywhere |
Listing 8-7 shows two cases of accessing private member variables of the same type, but a different instance. Most reputable integrated development environments (IDEs) will provide assistance in generating correct hashCode and equals methods: Usually these will be accessing the private member variables of the other instance when determining equality.
Listing 8-7: Accessing private member variables
public class Complex {
private final double real;
private final double imaginary;
public Complex(final double r, final double i) {
this.real = r;
this.imaginary = i;
}
public Complex add(final Complex other) {
return new Complex(this.real + other.real,
this.imaginary + other.imaginary);
}
// hashCode omitted for brevity
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Complex complex = (Complex) o;
if (Double.compare(complex.imaginary, imaginary) != 0) return false;
if (Double.compare(complex.real, real) != 0) return false;
return true;
}
}
@Test
public void complexNumberAddition() {
final Complex expected = new Complex(6, 2);
final Complex a = new Complex(8, 0);
final Complex b = new Complex(-2, 2);
assertEquals(a.add(b), expected);
}For methods and variables, what does static mean?
Static methods and variables are defined as belonging to the class and not specifically to an instance. They are common to all instances, and are usually accessed through the class name rather than a specific instance.
Listing 8-8 shows that class member variables can be manipulated either from an instance or by referencing the class itself. It is only recommended to access static methods and variables through the class name, because access through an instance can lead to confusion: Other programmers unfamiliar with the class definition may expect it to be a member of the instance, and will experience strange behavior in other instances after modifying the value.
Listing 8-8: Accessing class member variables
public class ExampleClass {
public static int EXAMPLE_VALUE = 6;
}
@Test
public void staticVariableAccess() {
assertEquals(ExampleClass.EXAMPLE_VALUE, 6);
ExampleClass c1 = new ExampleClass();
ExampleClass c2 = new ExampleClass();
c1.EXAMPLE_VALUE = 22; // permitted, but not recommended
assertEquals(ExampleClass.EXAMPLE_VALUE, 22);
assertEquals(c2.EXAMPLE_VALUE, 22);
}What are polymorphism and inheritance?
Polymorphism and inheritance are two of the core idioms of object-oriented development.
Polymorphism allows you to make a definition for a certain type of behavior, and have many different classes implement that behavior. Inheritance allows you to derive the behavior and definition of a class from a superclass.
When defining a new class, it is possible to inherit definitions and state from a previously defined class, and then add new specific behavior, or override behavior for the new type.
From Listing 8-9, the Square class inherits from Rectangle (you can say a square is-a rectangle). For the Square definition, the specific variables storing the length of the sides have been reused, and the Square type is enforcing that the width and height are the same.
Listing 8-9: Creating shapes using inheritance
public class Rectangle {
private final int width;
private final int height;
public Rectangle(final int width, final int height) {
this.width = width;
this.height = height;
}
public int area() {
return width * height;
}
}
public class Square extends Rectangle {
public Square(final int sideLength) {
super(sideLength, sideLength);
}
}Considering the is-a relationship defined previously, polymorphism can be thought of as using a subclass when a superclass has been asked for. The behavior of the subclass will remain, but the user of the polymorphic type is none the wiser.
Listing 8-10 explores the use of the Square and Rectangle classes with polymorphism. As far as the ArrayList is concerned, it is only dealing with Rectangles; it does not understand, nor does it need to understand, the difference between a Rectangle and a Square. Considering a Squareis-aRectangle, the code works fine. Had any specific methods been defined on the Square class, these would not have been available to any users of the rectangles list, because that method is not available on the Rectangle class.
Listing 8-10: Use of polymorphism with the Java collections
@Test
public void polymorphicList() {
List<Rectangle> rectangles = new ArrayList<>(3);
rectangles.add(new Rectangle(5, 1));
rectangles.add(new Rectangle(2, 10));
rectangles.add(new Square(9));
assertEquals(rectangles.get(0).area(), 5);
assertEquals(rectangles.get(1).area(), 20);
assertEquals(rectangles.get(2).area(), 81);
}Explain how some of the methods on the Object class are used when overridden.
Every class running on a JVM inherits from java.lang.Object, and thus, any non-final public or protected method can be overridden.
The method equals(Object other) is used for testing that two references are logically equal. For collection classes, such as java.util.TreeSet or java.util.HashMap, these classes make use of an object’s equals method to determine if an object already exists in the collection. The implementation of equals on Object compares the memory location of the objects, meaning that if two objects have the same memory location, they are actually the same object, so they must be equal. This is usually not much use, nor is it intended for testing equality, so overriding the method is a must for any need for testing equality.
The rule for hashCode is that two equal objects must return the same value. Note that the reverse is not required: that if two objects return the same hashCode, they are not necessarily equal. This is a nice feature to have, but not required: The more variance in the hashCode between different instances, the more distributed those instances will be when stored in a HashMap. Note that hashCode returns an int—this means that if unequal hashCodes meant unequal objects, there would only be a maximum of 232 unique variations of a specific instance. This would be quite a limitation, especially for objects like Strings!
The reason for the relationship between hashCode and equals is in the way collection classes such as java.util.HashMap are implemented. As discussed in Chapter 5, the data structure backing a HashMap is some sort of table, like an array or a List. The hashCode value is used to determine which index in the table to use. Because the hashCode returns an int, this means that the value could be negative, or perhaps a value larger than the size of the table. Any HashMap implementation will have to manipulate this value to a meaningful index for the table.
Like equals, hashCode also uses the memory location to generate the hashCode value on the Object class. This means that two separate instances that are logically equal will be in different memory locations, and therefore will not return the same hashCode.
The behavior of Set in Listing 8-11 is not performing as expected. The set does not know how to compare the Person objects properly, because Person does not implement equals. This can be fixed by implementing an equals method, which compares the name string and the age integer.
Listing 8-11: Breaking Sets due to poor implementation
public class Person {
private final String name;
private final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return name.hashCode() * age;
}
}
@Test
public void wrongSetBehavior() {
final Set<Person> people = new HashSet< >();
final Person person1 = new Person("Alice", 28);
final Person person2 = new Person("Bob", 30);
final Person person3 = new Person("Charlie", 22);
final boolean person1Added = people.add(person1);
final boolean person2Added = people.add(person2);
final boolean person3Added = people.add(person3);
assertTrue(person1Added && person2Added && person3Added);
// logically equal to person1
final Person person1Again = new Person("Alice", 28);
// should return false, as Alice is already in the set
final boolean person1AgainAdded = people.add(person1Again);
// But will return true as the equals method has not been implemented
assertTrue(person1AgainAdded); assertEquals(4, people.size());
}Given the relationship between hashCode and equals, the golden rule is: Whenever overriding hashCode or equals, you MUST override both methods. In fact, IDEs such as IntelliJ or Eclipse do not allow you to auto-generate one method without the other.
Even though equal objects must return the same hashCode, the reverse is not true. Listing 8-12 is a legal implementation of hashCode.
Listing 8-12: Overriding hashCode()
@Override
public int hashCode() {
return 42;
}This approach, however, is not advisable. As you now know, HashMaps (and therefore HashSets, which are backed by HashMaps) use the hashCode method as an index to the table storing the references. Should unequal objects have the same hashCode, then both are stored at that index, using a LinkedList data structure.
If you were to have every object return the same hashCode, and those are stored in a HashMap, then the performance of your HashMap has degraded to that of a linked list: All values will be stored in the same row of the HashMap implementation. Any search for a particular value will traverse all the values, testing each one by one for equality.
Java’s Arrays
How are arrays represented in Java?
The most important thing to remember about arrays in Java is that they are objects. They can be treated as objects. It is possible (though not very useful) to call toString() on arrays, or use them in a polymorphic sense, such as holding arrays in a container of Objects, illustrated in Listing 8-13.
Listing 8-13: Treating arrays as objects (I)
@Test
public void arraysAsObjects() {
Map<String, Object> mapping = new HashMap<>();
mapping.put("key", new int[] {0, 1, 2, 3, 4, 5});
assertTrue(mapping.get("key") instanceof (int[]));
}Because arrays are objects, this means arrays are passed by reference, so anything holding a reference to that array can mutate it in some way. Listing 8-14 demonstrates this. This can be a cause of great confusion, especially when the references are being mutated in completely separate areas of the code, or even different threads.
Listing 8-14: Treating arrays as objects (II)
@Test
public void arrayReferences() {
final int[] myArray = new int[] {0, 1, 2, 3, 4, 5};
int[] arrayReference2 = myArray
arrayReference2[5] = 99;
assertFalse(myArray[5] == 5);
}Working with Strings
How are Strings held in memory?
One of the great advantages to working with Java is that all of the library implementations are available to view and inspect. Looking at the implementation of String in Java 1.7 in Listing 8-15 is not a great surprise. The value represented by the String is held as an array of chars.
Listing 8-15: String definition
public final class String implements
java.io.Serializable,
Comparable<String>,
CharSequence {
private final char[] value;
... The String class is so core to the Java language, and is so widely used, that although it is simply a defined class in a Java library, the JVM and the compiler treats Strings in special ways under certain circumstances. String can almost be treated as a primitive type.
When creating a String literal, it is not necessary, or even advisable, to call new. At compile time, String literals—that is, any characters between a pair of quotations—will be created as a String.
The two Strings created in Listing 8-16 are the same, and can be treated as the same value in any running program. Looking at the construction of helloString2 first, when the compiler sees the sequence of characters ",H,e,...,!,", it knows that this is to create a String literal of the value enclosed in the quotes.
Listing 8-16: String creation
@Test
public void stringCreation() {
String helloString1 = new String("Hello World!");
String helloString2 = "Hello World!";
assertEquals(helloString1, helloString2);
}When helloString1 sees the characters in quotes, it also makes a String object for that value. This String literal is enclosed in a constructor, so that is passed to whatever the constructor does. As you will see, Strings are immutable, so this constructor can take a copy of the value passed. But the String(char[]) constructor will make a full copy of that array. Most IDEs will generate a warning when attempting to pass a String literal to a String constructor—it is just not necessary.
Is it possible to change the value of a string?
On inspection of the methods on String, all the methods that appear to mutate the String actually return a String instance themselves.
Although the code in Listing 8-17 isn’t exactly surprising, it does highlight the important behavior of Strings: The value of the String can never change. It is immutable.
Listing 8-17: Changing String values
@Test
public void stringChanges() {
final String greeting = "Good Morning, Dave";
final String substring = greeting.substring(4);
assertTrue(substring.equals("Good"));
assertFalse(greeting.equals(substring));
assertTrue(greeting.equals("Good Morning, Dave"));
}The listing shows that the “mutable” methods, such as substring (used in the listing), or others like replace or split, will always return a new copy of the string, changed appropriately.
Safe in the knowledge that the value represented by an instance can never change, immutability gives many advantages. Immutable objects are thread-safe: They can be used in many concurrent threads, and each thread is confident that the value will never change. No locking or complex thread coordination is necessary.
String is not the only immutable class in the standard Java library. All of the number classes, such as Integer, Double, Character, and BigInteger, are immutable.
What is interning?
Following the String literal and immutable discussions, literals get even more help and special treatment from the JVM at run time. When the class is loaded by the JVM, it holds all the literals in a constants pool. Any repetition of a String literal can be referenced from the same constant in the pool. This is known as String interning.
Naturally, because the constants in this pool can be referenced from any running class in the JVM, which could easily run into the thousands, the immutable nature of Strings is an absolute necessity.
The String intern pool is not just open to compile-time String literals; any String instance can be added to this pool with the intern() method. One valid use for String interning could be when parsing a large amount of data from a file or a network connection, and that data could contain many duplicates. Imagine something like a large banking statement, which could contain many credits or debits from a single party, or many similar actions such as multiple purchases of the same product over time. If these entities are interned when they are read, there will only be one unique instance taking up memory inside the JVM. The equals method on the String class also checks if the two compared instances are the same reference in memory, which makes the comparison much faster if they are the same.
Be aware that the intern() method does not come for free: Although the Strings are not stored on the heap, they do need to be stored somewhere, and that’s the PermGen space (covered in Chapter 10). Also, liberal use of intern(), if the constant pool had, say, several million entries, can affect the runtime performance of the application due to the cost of lookups for each entry.
The String constant pool is an implementation of the Flyweight Pattern, and similar occurrences of this pattern exist within the standard Java libraries. For instance, Listing 8-18 illustrates that the method Integer.valueOf(String) will return the same instance of the Integer object for values between –128 and 127.
Listing 8-18: The Flyweight Pattern in the Java libraries
@Test
public void intEquality() {
// Explicitly calling new String so the instances
// are in different memory locations
final Integer int1 = Integer.valueOf(new String("100"));
final Integer int2 = Integer.valueOf(new String("100"));
assertTrue(int1 == int2);
}By using an equality check, this code makes sure these objects refer to the same instance in memory. (JUnit’s Assert.assertSame() could do that here, but assertTrue() with == makes this absolutely explicit.)
Understanding Generics
Explain how to use generics with the Collections API.
Generics are also known as parameterized types. When you use generics with the collections classes, the compiler is being informed to restrict the collection to allow only certain types to be contained.
The code in Listing 8-19 is perfectly legal: It’s adding Strings to a List instance, and accessing Strings from that same instance. When calling get, the object needs to be cast to a String. The get method returns an Object, because List is polymorphic; the List class needs to be able to deal with any type possible.
Listing 8-19: Use of a list without generics
private List authors;
private class Author {
private final String name;
private Author(final String name) { this.name = name; }
public String getName() { return name; }
}
@Before
public void createAuthors() {
authors = new ArrayList();
authors.add(new Author("Stephen Hawking"));
authors.add(new Author("Edgar Allan Poe"));
authors.add(new Author("William Shakespeare"));
}
@Test
public void authorListAccess() {
final Author author = (Author) authors.get(2);
assertEquals("William Shakespeare", author.getName());
}Because the list is not constrained to allow only instances of the Author class, the code in Listing 8-20 is allowed, possibly a simple mistake for a developer to make.
Listing 8-20: Erroneously using a list without generics
@Test
public void useStrings() {
authors.add("J. K. Rowling");
final String authorAsString = (String) authors.get(authors.size() - 1);
assertEquals("J. K. Rowling", authorAsString);
}There is no constraint on the type of instance used in the list. You can probably spot several issues with the code. Is it an absolute certainty that only these types will be in the list? If not, then a ClassCastException will be thrown at run time. The cast itself is messy, boilerplate code.
By using generics, any potential exceptions at run time are moved to actual compiler errors. These are spotted much earlier in the development life cycle, which, in turn, leads to faster fixes and cleaner code. Listing 8-21 shows this.
Listing 8-21: Using generics
private List<Author> authors;
private class Author {
private final String name;
private Author(final String name) { this.name = name; }
public String getName() { return name; }
}
@Before
public void createAuthors() {
authors = new ArrayList<>();
authors.add(new Author("Stephen Hawking"));
authors.add(new Author("Edgar Allan Poe"));
authors.add(new Author("William Shakespeare"));
}
@Test
public void authorListAccess() {
final Author author = authors.get(2);
assertEquals("William Shakespeare", author.getName());
}The cast for access has disappeared, and reading this code feels more natural: “Get the third author from the list of authors.”
The authors instance is constrained to take only objects of type Author. The other test, useStrings, now doesn’t even compile. The compiler has noticed the mistake. Making this test use an Author class rather than a String is an easy fix.
All of the classes in the collections API make use of generics. As you have seen, the List interface and its implementations take one type parameter. The same goes for Sets. As you should expect, Maps take two type parameters: one for the key and one for the value.
Generic types can be nested, too. It is legal for a Map to be defined as HashMap<Integer, List<String>>: a HashMap that has an Integer as its key, mapped to Lists of type String.
Amend the given Stack API to use generics.
Imagine Listing 8-22 was required to use generics.
Listing 8-22: An API for stack manipulation
public class Stack {
private final List values;
public Stack() {
values = new LinkedList();
}
public void push(final Object object) {
values.add(0, object);
}
public Object pop() {
if (values.size() == 0) {
return null;
}
return values.remove(0);
}
}Implementations of a stack are very popular in interviews. They have a relatively small set of operations, usually push, pop, and perhaps peek. Stacks are easily implemented using the Java collections API; no extra libraries are necessary. Take a moment to make sure you understand why a LinkedList is used here—would an ArrayList have worked too? What is the difference?
For the given implementation, this is a fully functioning stack, although it has not been developed for use with generics. If suffers from all the issues discussed in the previous question.
To migrate this class to use generics, you can use the compiler as your guide. First, the Stack class must be declared to take a parameterized type:
public class GenericStack<E> {
...E is the parameterized type variable. Any symbol could have been used. E here stands for “element,” mirroring its use in the collections API.
The contained List can now use this generic type:
private final List<E> values;This immediately throws up a compiler error. The push method takes Objects, but now it needs to take objects of type E:
public void push(final E element) {
values.add(0, element);
}Changing values to List<E> also threw up a compiler warning in the Stack constructor. When creating the valuesLinkedList, this should be parameterized too:
public GenericStack() {
values = new LinkedList<E>();
}One change the compiler was not aware of is a change to the pop method. The last line of the pop method, values.remove(0), now returns a value of type E. Currently, this method returns Object. The compiler has no reason to error or even to throw up a warning, because Object is a supertype of all classes, regardless of what E is. This can be changed to return the type E:
public E pop() {
if (values.size() == 0) {
return null;
}
return values.remove(0);
}How does type variance affect generics?
Given the following class hierarchy:
class A {}
class B extends A {}B is a subtype of A. But List<B> is not a subtype of List<A>. Known as covariance, Java’s generics system has no way to model this.
When dealing with generic types, at certain times you may want to accept subtypes of a class. Using the GenericStack class from the previous question, imagine a utility method, which creates a new GenericStack from a List of A:
public static GenericStack<A> pushAllA(final List<A> listOfA) {
final GenericStack<A> stack = new GenericStack<>();
for (A a : listOfA) {
stack.push(a);
}
return stack;
}This compiles and works exactly as expected for Lists of A:
@Test
public void usePushAllA() {
final ArrayList<A> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new A());
}
final GenericStack<A> genericStack = pushAllA(list);
assertNotNull(genericStack.pop());
}
}But when trying to add a List of B, it doesn’t compile:
@Test
public void usePushAllAWithBs() {
final ArrayList<B> listOfBs = new ArrayList<>();
for(int i = 0; i < 10; i++) {
listOfBs.add(new B());
}
final GenericStack<A> genericStack = pushAllA(listOfBs);
assertNotNull(genericStack.pop());
}Although B is a subclass of A, List<B> is not a subtype of List<A>. The method signature of pushAllA needs to change to explicitly allow A, and any subclass of A:
public static GenericStack<A> pushAllA(final List<? extends A> listOfA) {The question mark is called a wildcard, and it is telling the compiler to allow any instance of a class extending A.
What does reified mean?
Essentially, being reified means being available at run time. Java’s generic types are not reified. This means all the type information the compiler uses to check that any implementing code is using generic parameters correctly is not part of the .class file definition.
Listing 8-23 makes use of generics.
Listing 8-23: A simple use of generics
import java.util.ArrayList;
import java.util.List;
public class SimpleRefiedExample {
public void genericTypesCheck() {
List<String> strings = new ArrayList<>();
strings.add("Die Hard 4.0");
strings.add("Terminator 3");
strings.add("Under Siege 2");
System.out.println(strings.get(2) instanceof String);
}
}Decompiling the class file using JAD (a Java decompiler) produces the code in Listing 8-24.
Listing 8-24: Decompiled code from Listing 8-23
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.List;
public class SimpleRefiedExample
{
public void genericTypesCheck() {
ArrayList arraylist = new ArrayList();
arraylist.add("Die Hard 4.0");
arraylist.add("Terminator 3");
arraylist.add("Under Siege 2");
System.out.println(arraylist.get(2) instanceof String);
}
}All type information has been lost. This means that if you were to pull in this list from a class file that had already been compiled, you must assume that it respects the generic parameter information it was compiled with.
You can see from this example that it would be quite simple to construct a small use case where an instance of a List with a generic type is used, but the dynamically loaded instances are of a different type.
Autoboxing and Unboxing
Is it possible for access to a primitive type to throw a NullPointerException?
The correct answer to this question is no, but it can certainly appear so. Take Listing 8-25; there are several points of note here. When assigning intObject to 42, you are attempting to assign the primitive value 42 to an object. This shouldn’t be legal, and before Java 5, this certainly would have produced a compiler error. However, the compiler is using a technique called autoboxing. The compiler knows that the reference type equivalent of int is Integer, and so this is allowed. If the compiler was not aware that these two types were related (as was the case before Java 5), and if a reference to an Integer object was needed, then you would need to manage this manually, either using new Integer(42) or, more efficiently, Integer.valueOf(42).
The reason Integer.valueOf(42) is more efficient is because small values are cached. This was discussed in Chapter 6 on Design Patterns and is known as the Flyweight Pattern.
Listing 8-25: Demonstration of autoboxing and unboxing
@Test
public void primitiveNullPointer() {
final Integer intObject = 42;
assert(intObject == 42);
try {
final int newIntValue = methodWhichMayReturnNull(intObject);
fail("Assignment of null to primitive should throw NPE");
} catch (NullPointerException e) {
// do nothing, test passed
}
}
private Integer methodWhichMayReturnNull(Integer intValue) {
return null;
}
The process of converting from a boxed reference type, such as Float, Integer, or Boolean to their primitive counterparts, float, int, or boolean is called unboxing. Again, this is an operation the compiler provides. However, as you will be very aware by now, whenever working with reference types, you must always be prepared for a reference being null, and this is true for the boxed types. When the compiler converts from Integer to int, it assumes that the value is not null, so should it be null, this will immediately throw a NullPointerException. The initial line of code in the try block assigns the return type of the method, Integer to an int primitive type. In this case, the method always returns null, so when this line is run, a NullPointerException is thrown, because it is not possible to assign null to a primitive type.
This can cause frustration and confusion when trying to debug or fix issues, especially when it is not explicitly clear that boxing and unboxing is happening.
Primitive types cannot be used in generic type definitions—you cannot have a List<int>. In this case, the reference type should be used.
Using Annotations
Give an example of a use of annotations.
Annotations were introduced in Java 5, and the JUnit library made full use of these annotations following the JUnit 4 release.
Listing 8-26 shows how JUnit tests worked prior to JUnit 4. Test suites were written using specific conventions for naming tests, and also steps to run before and after the tests were run. The JUnit runner would inspect any subclass of TestCase compiled tests, using reflection. If it found the method signature public void setUp(), this would be run before each test, and public void tearDown() would be run after. Any public methods with a void return type, and the method name starting with test, would be treated as a test.
Listing 8-26: Anatomy of a JUnit 3 test
public class JUnit3Example extends TestCase {
private int myInt;
public void setUp() {
myInt = 42;
}
public void testMyIntValue() {
assertEquals(42, myInt);
}
public void tearDown() {
myInt = -1;
}
}Mistyping the prefix test, or setUp, or tearDown would result in the tests not running, without any indication why; or worse, the tests would fail.
With the introduction of annotations, this brittle naming convention could be tossed aside, and instead, use annotations to mark the appropriate methods, allowing tests to be more expressive in their definition. Listing 8-27 shows the same test using annotations.
Listing 8-27: Anatomy of a JUnit 4 test
public class Junit4Example {
private int myInt;
@Before
public void assignIntValue() {
myInt = 42;
}
@Test
public void checkIntValueIsCorrect() {
Assert.assertEquals(42, myInt);
}
@After
public void unsetIntValue() {
myInt = -1;
}
}Even if you have no experience with JUnit, it should be quite apparent that using annotations makes for better tests: Methods can have better names, and methods can have multiple annotations. Feasibly, one method could have a @Before and @After annotation on it, eliminating code duplication. For more details on JUnit, see Chapter 9.
What does the @Override annotation give us?
The @Override annotation is an extremely useful compile-time check. It is an instruction to the compiler that a superclass method is being overridden. If there is no matching method signature on any superclass, this is an error and should not compile.
In general, it is a great way to make sure you don’t make mistakes when overriding methods.
public class Vehicle {
public String getName() {
return "GENERIC VEHICLE";
}
}
public class Car extends Vehicle {
public String getname() {
return "CAR";
}
}It appears that getName() has been overridden to return something slightly more descriptive, but the code:
Car c = new Car();
System.out.println(c.getName());will actually print GENERIC VEHICLE. The method in class Car has a typo: It is getname() rather than getName(). All identifiers in Java are case-sensitive. Trying to track down bugs like this can be extremely painful.
Annotating the attempt at overriding getName() with @Override would have flagged a compiler error. This could have been fixed immediately.
As always, you should be using a professional-grade IDE, and leaning on it for as much help as possible. Both IntelliJ and Eclipse provide wizard dialog boxes for overriding methods, allowing you to pick exactly which method you want to override. These wizards will add the @Override annotation for you, making it very hard to get this wrong.
Naming Conventions
When interviewers look at sample code, whether from a test or a candidate’s sample code, perhaps from Github or a similar site, they often look for the quality of the code, from the use of the final keyword to the conventions used in variable naming. IDE support for naming conventions is excellent, and there are few, if any, reasons not to follow these conventions. They make the code much more legible to a colleague or interviewer.
Classes
Classes always start with a capital letter, and are CamelCase:
- Boolean
- AbstractJUnit4SpringContextTests
- StringBuilder
Variables and Methods
Variables and methods always start with a lowercase letter, and are camelCase too:
- int myInteger = 56;
- public String toString();
Constants
static final instance variables can never change, and are therefore constant. The convention for constants is to be all uppercase, with any breaks between words represented by an underscore:
- public static final int HTTP_OK = 200;
- private static final String EXPECTED_TEST_RESPONSE = "YES";
One element of debate is how to represent acronyms properly with camel casing. The most accepted variant is to capitalize the first letter, and lowercase the rest, such as HttpClient or getXmlStream().
This isn’t even consistent within the Java’s own standard libraries. For example, HttpURLConnection uses both styles in one class name!
It is this author’s opinion that the capitalized first letter approach is favorable: It is much easier to see where the acronym ends and the next word begins. With many IDEs nowadays, it is possible to search for classes merely by entering the first letter of each word in the camel case.
Handling Exceptions
Describe the core classes in Java’s exception hierarchy.
Figure 8-1 illustrates the exception hierarchy, with examples of each type.
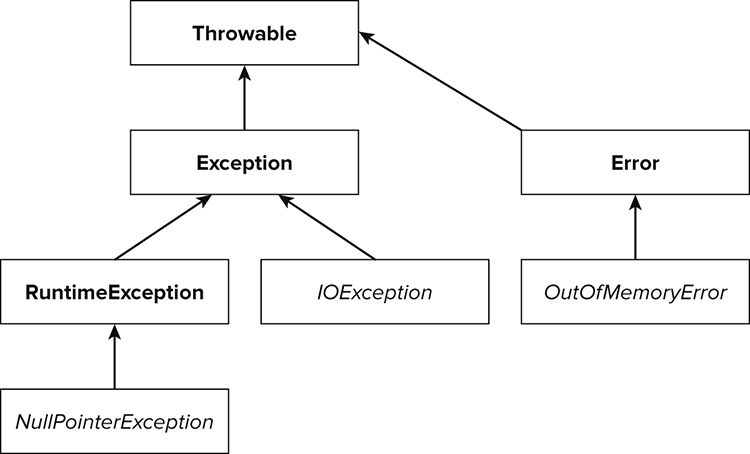
Any class that can be thrown extends from Throwable. Throwable has two direct subclasses: Error and Exception. As a rule, it is usually the responsibility of the programmer to address and fix Exceptions where necessary. Errors are not something you can recover from, such as an OutOfMemoryError or a NoClassDefFoundError.
Exceptions themselves are split into two definitions: An exception is either a runtime exception or a checked exception. A runtime exception is any subclass of RuntimeException. A checked exception is any other exception.
When using a method (or constructor) that may throw a checked exception, that exception must be explicitly defined on the method definition. Any caller to the code must be prepared to handle that exception, by either throwing it back to any caller of that method, or surrounding the method call in a try/catch/finally block, and deal with the exceptional case appropriately.
Are runtime exceptions or checked exceptions better?
Another area of great debate is whether checked or runtime exceptions are better. Arguments certainly exist for both sides.
With checked exceptions, you are being explicit to any user of your code about what could possibly go wrong. When writing a method that may throw a checked exception, be as explicit as possible. A method definition such as public String getHostName() throws Exception does not give much clue to what may go wrong. If it were defined as public String getHostName() throws UnknownHostException, the client code would know what may go wrong, and it also would give some more insight as to how exactly the method works.
With runtime exceptions, defining the exception on the method, rethrowing the exception, or using a try/catch/finally block are all optional. As a general rule, RuntimeExceptions are exceptions that a diligent programmer should already have mitigated: problems such as accessing an array index value larger than the size of the array—ArrayIndexOutOfBoundsException—or trying to call methods on a null reference—NullPointerException.
When defining an API and deciding whether to use runtime or checked exceptions, this author’s opinion is to favor runtime exceptions and be explicit in any documentation as to what exactly may be thrown to any clients calling that method. Using try/catch/finally blocks adds a significant amount of boilerplate code to even the simplest of method calls, and makes life very difficult for any future maintainer of the code. Just examine any non-trivial use of JDBC, and you will often see try/finally blocks inside try/catch/finally blocks. Modern languages such as Scala have stepped away from checked exceptions, and have only runtime exceptions.
What is exception chaining?
When catching an exception to deal with an error case, it is entirely possible you would want to rethrow that exception, or even throw an exception of a different type.
Reasons to do this include “laundering” an exception from a checked exception to a runtime one, or perhaps performing some logging of the exception and then rethrowing it. When throwing a previously caught exception, it is advisable to throw a new exception and add a reference on that new exception. This technique is called exception chaining.
This mindset is the same for throwing a new exception within a catch block. Add a reference to the old exception in the new exception’s constructor.
The reason for doing this is that these exception chains are extremely valuable for debugging should the exception not be handled at all, and the stack trace make it all the way to the application console.
The chains are referenced in the stack trace by a “caused by” line. This refers to the original exception prior to being wrapped in a new exception or rethrown.
Listing 8-28 shows how to create a chained exception. The exception instance in the catch block is chained to the new IllegalStateException instance, by passing that reference to the constructor of the IllegalStateException.
Listing 8-28: Handling chained exceptions
public class Exceptions {
private int addNumbers(int first, int second) {
if(first > 42) {
throw new IllegalArgumentException("First parameter must be small");
}
return first + second;
}
@Test
public void exceptionChaining() {
int total = 0;
try {
total = addNumbers(100, 25);
System.out.println("total = " + total);
} catch (IllegalArgumentException e) {
throw new IllegalStateException("Unable to add numbers together", e);
}
}
}All standard Java library exceptions can take a throwable as a constructor parameter, and should you ever create any new Exception classes, make sure you adhere to this.
When this (admittedly contrived) test is run, it demonstrates that the IllegalStateException was indeed caused by the first parameter to addNumbers being too high:
java.lang.IllegalStateException: Unable to add numbers together
at com.wiley.acinginterview.chapter08.Exceptions.exceptionChaining(Exceptions.java:23)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
<Exeption truncated>
...
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:120)
Caused by: java.lang.IllegalArgumentException: First parameter must be small
at com.wiley.acinginterview.chapter08.Exceptions.addNumbers(Exceptions.java:9)
at com.wiley.acinginterview.chapter08.Exceptions.exceptionChaining(Exceptions.java:20)
... 26 moreHad the exceptions not been chained, and the code inside the try block much larger, trying to work out where the original exception had been thrown from could have been a time-wasting chore.
If you ever see an exception being thrown in a catch block, and it does not chain the original exception, add a reference there and to that original exception. You’ll thank yourself later!
What is a try-with-resources statement?
Java 7 introduced some syntactic sugar for the try/catch/finally statement. If a class implements the AutoCloseable interface, you do not need to worry about closing any resources, which is shown in Listing 8-29.
Listing 8-29: try-with-resources
@Test
public void demonstrateResourceHandling() {
try(final FileReader reader = new FileReader("/tmp/dataFile")) {
final char[] buffer = new char[128];
reader.read(buffer);
} catch (IOException e) {
// .. deal with exception
}
}Before try-with-resources was introduced, the reader instance would have had to be explicitly closed, which itself could have caused an exception, or unspecified behavior if the close failed, or even if the close was forgotten altogether.
The AutoCloseable interface specifies one method, close(), and this is called after the try block, as if it were in the finally part of the block.
Using the Standard Java Library
The APIs available as part of the standard Java library cover a wide range of domains, from database access to optimized sorting and searching algorithms, from concurrency APIs to two user interface frameworks.
Why do fields that are private also need to be marked as final to make them immutable?
If you had a final class with no accessible setters, and all fields were private, you could be inclined to think that the class is immutable, such as that in Listing 8-30.
Listing 8-30: An almost-immutable class
public final class BookRecord {
private String author;
private String bookTitle;
public BookRecord(String author, String bookTitle) {
this.author = author;
this.bookTitle = bookTitle;
}
public String getAuthor() {
return author;
}
public String getBookTitle() {
return bookTitle;
}
}Unfortunately this is not the case. The fields can still be manipulated using the Reflection API. Reflection has the ability to access and mutate all fields, regardless of their visibility. The final modifier instructs the JVM that no modifications are allowed on that field at all. Though it may seem slightly underhanded to allow access to state that has genuinely been marked as inaccessible to the outside world, there actually are a few legitimate cases. With Spring’s Inversion of Control container, private fields with an @Autowired annotation have these fields set when the container is initializing at run time.
Listing 8-31 shows how you can mutate private fields from outside of a class definition.
Listing 8-31: Mutating private fields with the Reflection API
@Test
public void mutateBookRecordState() throws NoSuchFieldException,
IllegalAccessException {
final BookRecord record = new BookRecord("Suzanne Collins",
"The Hunger Games");
final Field author = record.getClass().getDeclaredField("author");
author.setAccessible(true);
author.set(record, "Catching Fire");
assertEquals("Catching Fire", record.getAuthor());
}Unless you are writing your own framework, very few reasons exist to change the value of a private field, especially in classes you own or that are under your control.
Which classes do all other collections API classes inherit from?
The framework can be broadly split into three main definitions: Sets, Lists, and Maps. Take another look at Chapter 5 if you need a refresher on how these collections work. There is also the specialized interface of Queue, which provides simple operations for adding, removing and examining queued elements. The ArrayList class is both a List and a Queue.The Java Collections framework is contained in the package java.util. All single-element collections implement the Collection interface, which specifies some very broad methods, such as clear() for removing all elements and size() for determining how many entries are in the collection. Map implementations do not implement Collection. Instead, Java prefers a distinction between mappings and collections. Of course, Collections and Maps are intricately linked: the Map interface contains the methods entrySet(), keySet(), and values, giving access to the Map components as Collections.
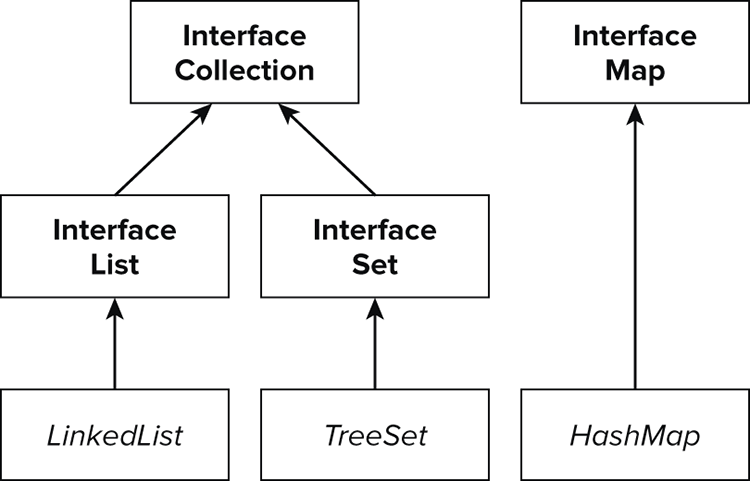
Figure 8-2 shows the collections hierarchy, and where some common implementations fit in.
What is a LinkedHashMap?
A LinkedHashMap has a confusing name—is it a HashMap? Linked in what way?
A LinkedHashMap has all the properties of a HashMap—that is, quick lookup on a key index—but it also preserves the order of entry into the map. Listing 8-32 demonstrates how to use a LinkedHashMap.
Listing 8-32: Usage of a LinkedHashMap
@Test
public void showLinkedHashmapProperties() {
final LinkedHashMap<Integer, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put(10, "ten");
linkedHashMap.put(20, "twenty");
linkedHashMap.put(30, "thirty");
linkedHashMap.put(40, "forty");
linkedHashMap.put(50, "fifty");
// works like a map
assertEquals("fifty", linkedHashMap.get(50));
// Respects insertion order
final Iterator<Integer> keyIterator = linkedHashMap.keySet().iterator();
assertEquals("ten", linkedHashMap.get(keyIterator.next()));
assertEquals("twenty", linkedHashMap.get(keyIterator.next()));
assertEquals("thirty", linkedHashMap.get(keyIterator.next()));
assertEquals("forty", linkedHashMap.get(keyIterator.next()));
assertEquals("fifty", linkedHashMap.get(keyIterator.next()));
// The same is not true for HashMap
final HashMap<Integer, String> regularHashMap = new HashMap<>();
regularHashMap.put(10, "ten");
regularHashMap.put(20, "twenty");
regularHashMap.put(30, "thirty");
regularHashMap.put(40, "forty");
regularHashMap.put(50, "fifty");
final ArrayList hashMapValues = new ArrayList<>(regularHashMap.values());
final ArrayList linkedHashMapValues = new ArrayList<>(linkedHashMap.values());
// the lists will have the same values, but in a different order
assertFalse(linkedHashMapValues.equals(hashMapValues));
}
Why was HashMap introduced when Hashtable already existed?
The Collections framework and the collections interfaces (Collection, Map, List, and so on) first appeared in the 1.2 release, but the Hashtable class, and the list-equivalent Vector, has been part of Java since its initial release. These classes were not written with a framework in mind. When the Collections framework was included, Hashtable was retrofitted to match the Collection interface.
The Hashtable class is synchronized, which, though effective for parallel work, provides a significant performance hit due to this overhead for any single-threaded work. HashMap is not synchronized, so the developer has the power to tailor the use of this class to any particular concurrent needs. It is advisable, for any serious use of a Map interface in a parallel environment, to make use of ConcurrentHashMap (introduced in Java 5). See Chapter 11 for more details.
Looking Forward to Java 8
What new features are to be expected in Java 8?
At the time of writing, two key new features in Java 8 are default implementations on interfaces, and lambdas.
It is now possible to define a default implementation on interfaces. Any implementer of an interface does not need to provide an implementation if the default is sufficient, such as in Listing 8-33.
Listing 8-33: Java 8 interfaces
public interface Java8Interface {
void alpha();
int beta default { return 6; };
String omega final { return "Cannot override"; };
}As well as a default implementation, interfaces can have a final implementation too. This now works in a very similar way to abstract classes.
The past few years have seen an explosion of new languages that are capable of being compiled into code that is runnable on the JVM. Some of these languages, such as Scala and Groovy, have lambdas—that is, functions that are treated as first-class citizens; they can be passed into other functions and methods as variables. Lambdas are anonymous functions, such as the example in Listing 8-34. A lambda can be used in any situation where an interface with only one method is required. They are written inline, in place of a full interface implementation. Note the new syntax: parameters, an arrow, and then the method body.
Listing 8-34: Lambdas in Java 8
public void run() {
List<Integer> ints = new ArrayList<>();
ints.add(1);
ints.add(2);
ints.add(3);
List<Integer> newInts = new ArrayList<>();
ints.forEach(i -> { newInts.add(i+10); });
for(int i = 0; i < ints.size(); i++) {
assert ints.get(i) + 10 == newInts.get(i);
}
assert ints.size() == newInts.size();
System.out.println("Validated");
}The List interface, or more specifically, the Iterable interface, has had a new method added: forEach. Had a default implementation not been allowed on interfaces, this would have needed to be added to every implementation of Iterable—not only in the standard Java library, but all third-party code too!
The parameter to forEach is an instance of the new interface Consumer. This interface has one method, accept, which has a void return type, and it takes one parameter. Because there is only one method, a lambda can be used here. When forEach is called, the parameter to the method is an instance of Consumer, and the parameter to that method is the same type as that of the list. The list is iterated over, and each element is passed to the implementation of Consumer. Consumer returns void, so the lambda cannot return anything to the calling method. Here, the lambda takes each element, adds ten, and puts that value in a new List instance. The Java 4 assert keyword is being used here to check that, first, the original List has not been modified in any way; second, that the new List has the correct values in it; and third, that there are no extra elements in either List.
For another take on lambdas, see the appendix.
The most important thing to take away from this is that the Java landscape is always changing, and these implementation details may change before Java 8 is released. It is extremely important to keep on top of what is happening in the industry, not just with Java releases.
Summary
Many of the questions and discussions covered in this chapter should be familiar to you, especially if you have a few years’ experience working with Java and the JVM. Hopefully while reading this chapter you have experimented and run the code. If not, try it now. Change the variables, and see what effect it has on the tests. Make the tests pass again based on your changes.
It really is important that you understand this chapter; everything else in this book and in an interview situation will assume this is well understood, and will build on the concepts here.
The topics covered here are not exhaustive. While running these examples, if you have areas you don’t understand, use the unit tests to try out hypotheses, and take advantage of many of the useful resources on the Internet to see if others have asked similar questions. Have discussions with your peers and colleagues—learning from those around you is often the most productive and useful.
If you are not using an IDE, now is the time to start. More and more interviewers today expect you to write real code on a real computer using real tools. If you already know how to use an IDE presented to you in an interview, this can help you with a lot of the heavy lifting: filling in getters and setters, providing practical hashCode and equals, to name but a few. But IDEs also provide great refactoring tools, which are extremely helpful for making large-scale changes in a time-pressured situation like a coding test. If IDEs are unfamiliar to you in an interview situation, you will lose a lot of time fighting against the tool to write your code.
Make sure you are familiar with the Collections framework. Open up their implementations in an IDE (most have the Java library source automatically loaded). Look at how common code is implemented—hashCode on the primitives’ reference type equivalents (Boolean.hashCode() is interesting); look at how HashSet is implemented in terms of HashMap. See how many object-oriented patterns you can find.
But most of all, do not treat this chapter, or this book, as a quick fix, how-to guide for beating a Java interview. By implementing best practices, and receiving peer review of your code and practices, you will learn and improve. There will be less chance of you falling foul to a tricky corner-case in an interview. Experience is key.
Chapter 9 focuses on JUnit, the unit test library. Writing unit tests can often be a way to stand out and impress an interviewer, as not every candidate, surprisingly, will write unit tests.