
Amazon DynamoDB is a fully managed serverless database service that you can use to provision tables, create indexes, and store data. It has extremely scalable performance and supports event-driven programming models. DynamoDB is often referred to as the petabyte storage database because its performance scales consistently and predictably, no matter how much data you load in. Like S3, writes to the database are replicated to three availability zones within a region, and you can specify in your queries whether you want a strongly or eventually consistent read operation.
One of the core premises of using DynamoDB is that you can focus on running your business instead of being distracted by having to feed and water your database.
DynamoDB tables are structured into the following concepts
- Items (1)
- Attributes (2)
- Values (3)
- Keys (4)
The following is an example of our photo-metadata table. I've highlighted the concepts from the preceding list:
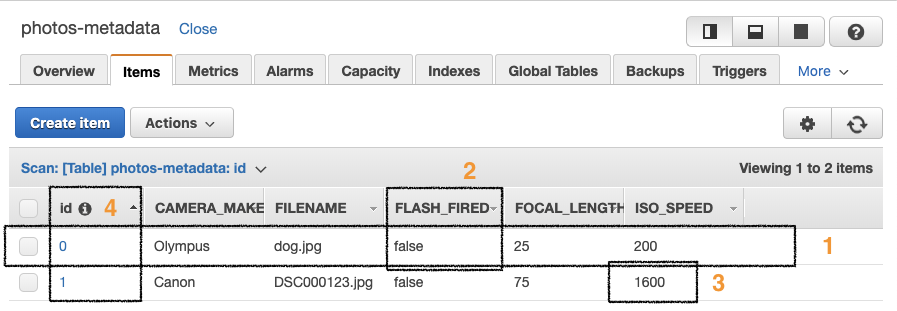
An item can be considered as an entry or row, such as an RDMS database. An attribute is one particular field. The benefit of a NoSQL database is that the data can be unstructured and not follow a defined schema. This means that each item within a table can have a different set of attributes.
An important thing to get right is the partition key and sort key. Let's take a look at these in more detail:
- The partition key is a mandatory piece of information that uniquely identifies an item. It is also used to help distribute the data using an internal hashing function under the hood. The details get complex quite quickly, so I recommend that, if you have tables that will grow to over 10 GB, you should consider doing further investigation into choosing the right partition key.
- The sort key is an optional key that you can set that allows you to run smarter queries. Both the partition key and sort key make up a composite primary key that is sorted by the sort key.
You can also have an alternative partition and sort key by using a Global Secondary Index (GSI). This is an index that is updated asynchronously when changes happen to the table. The GSI is inherently eventually consistent because of the asynchronous nature of the update. This means that when a table is updated, there will be a lag time before the GSI receives the propagated update. Your application should be designed to handle situations where it might not receive the most up to date data from a query to the GSI.
The use cases we will look at in the next section follow the fundamental ideas of the event-driven pattern, where an update to a database table will trigger some compute to happen. After that, we will learn how to save data to a table using the SDK.