
Modern computers and modern smartphones have several CPUs able to work in parallel. You probably think of several apps running at the same time, but there is more to concurrency; you can have several “actors” do work in parallel in one app, noticeably speeding up program execution. I deliberately say “actors” because simply saying that several CPUs work in parallel only covers part of the story. In fact, software developers prefer to think of threads, which are program sequences that can potentially run independent of each other. Which CPU actually runs a thread is left to the process scheduling managed by the operating system. We adopt that thread notion and by that abstract from operation system process handling and hardware execution internals.
Within one app, having several threads running concurrently is commonly referred to as multithreading. Multithreading has been a prominent part of Java for years now, and you can find Java’s relevant interfaces and classes inside packages java.lang and java.util.concurrent and subpackages. These are also included within Kotlin for Android. However, Kotlin has its own idea about multithreading and introduces a technique called coroutines. You can use both features, and in this chapter we discuss both of them.
Basic Multithreading the Java Way
Without any further preparation, when you start a Kotlin (or Java) app the program gets run in the main thread. However, you can define and start other threads that can be worked through concurrently while the main thread is running.
Note
The Java multithreading classes are automatically available to Kotlin in an Android development environment.
If you don’t explicitly specify the start parameter to read false, the Thread.start() function gets called immediately after thread creation.
If you set isDaemon to true, a running thread will not prevent the runtime engine from shutting down when the main thread has finished its work. In an Android environment, however, undaemonized threads will not make an app continue being active when the system decides to shut down or suspend an app, so this flag has no noticeable implications for Android.
Specifying a separate class loader is an advanced feature you can use if you want the thread to use a class loader different from the system class loader. In this book we don’t talk about class loading issues; usually you can safely ignore class loading issues in an Android environment.
Specifying a separate name for your thread helps troubleshooting if problems arise. The thread’s name could show up in log files.
Specifying a priority gives the system a hint for how a thread should be prioritized in relation to other threads. Values range from Thread.MIN_PRIORITY to Thread.MAX_PRIORITY. The default value is Thread.NORM_PRIORITY. For your first experiments you don’t have to be concerned with this value.
The block contains statements that get executed when the thread runs. The thread() function always exits immediately no matter what the block does and how long it runs.
Here we let one thread alter a list every 10 milliseconds, and another thread print the list to the logging console.
It basically says that we are iterating through a list while it is being modified by another thread, and this is the problem: We have a list data inconsistency if we let several threads at the same time modify a list’s structure and iterate through it.
Another issue that comes up when we talk about multithreading is that we need to find a clever way to synchronize threads. For example, one thread needs to wait for another thread to finish some work before it can start running.
These two issues—data consistency and synchronization—make multithreading kind of an art, and until now no final universal solution has been found. That is why, concerning multithreading, new ideas are constantly born and several approaches exist at the same time, all with mutual advantages and disadvantages over the others.
Here the synchronized(l) blocks in all threads accessing the list make sure that no thread accessing the list can enter the code inside synchronized while another thread is inside any other synchronized block for the same list. Instead the thread that arrives first makes all the other threads wait until it has finished its synchronized block.
where the synchronization makes sure that it is safe to let multiple threads work on both l1 and l2.
Now the instructions after thr1.join() only start after thread thr1 has finished its work.
Basic Multithreading the Java Way
Construct/Function | Description |
|---|---|
thread(...) | Creates and possibly starts a thread. Parameters are: • start: Immediately start the thread after construction. Default: true. • isDaemon: If true, a running thread will not prevent the runtime engine from shutting down when the main thread has finished its work. Has no effect in Android. Default: false. • contextClassLoader: Specify a different class loader. Default is null, which signifies the system class loader. For Android you usually go with the default. • name: The name of the thread. Shows up in log files. Default: Use a default string with consecutive numbering. • priority: Specifying a priority gives the system a hint for how a thread should be prioritized in relation to other threads. Possible values: Between Thread.MIN_PRIORITY and Thread.MAX_PRIORITY, with Thread.NORM_PRIORITY being the default. • block: Contains the thread’s code. If you don’t need any special parameters you just write thread { [thread_code] }. |
synchronized( object1, object2, ...) { } | The block inside the { } gets entered only if no other thread currently executes in a synchronized block with at least one of the same objects in its parameter list. Otherwise the thread will be put in a waiting state until the other relevant synchronized blocks have finished their work. |
Thread.sleep(millis: Long) | Makes the current thread wait for the specified number of milliseconds. Can be interrupted, in which case the statement terminates immediately and an InterruptedException gets thrown. |
Thread.sleep(millis: Long, nanos:Int) | Same as Thread.sleep(Long), but makes the function additionally sleep nanos nanoseconds. |
thread.join() | Makes the current thread wait until thread thread has finished its work. |
thread.interrupt() | The current thread interrupts thread thread. The interrupted thread gets terminated and throws an InterruptedException. The interrupted thread must support interruption. It does so by invoking interruptible methods like Thread.sleep() or by periodically checking its own Thread.interrupted flag to see whether it is supposed to exit. |
@Volatile var varName = ... | Only for class or object properties. Marks the backing field (the data behind the property) as volatile. The runtime engine (Java virtual machine) makes sure that updates to volatile variables get immediately communicated to all threads. Otherwise the cross-thread state under the circumstances might be inconsistent. The performance overhead is smaller compared to synchronized blocks. |
Any.wait() | Only from inside a synchronized block. Suspends the synchronization such that other threads can continue their work. At the same time, it makes this thread wait for an unspecified time, until notify() or notifyAll() gets called. |
Any.wait( timeout:Long ) | Same as wait(), but waits at most for the specified number of milliseconds. |
Any.wait( timeout:Long, nanos:Int ) | Same as wait(), but waits at most for the specified number of milliseconds and nanoseconds. |
Any.notify() | Only from inside a synchronized block. Wakes up one of the waiting threads. The waiting thread starts to work once the current thread leaves its synchronized block . |
Any.notifyAll() | Only from inside a synchronized block. Wakes up all of the waiting threads. The waiting threads start to work once the current thread leaves its synchronized block. |
For all other functions of class java.lang.Thread, consult the API documentation.
Advanced Multithreading the Java Way
Scattering synchronized blocks and join functions throughout your code poses a couple of problems: First, it makes your code hard to understand; understanding multithreaded state handling is anything but easy for nontrivial programs. Second, having several threads and synchronized blocks might end up in a deadlock: Some thread A waits for thread B while thread B is waiting for thread A. Third, writing too many join functions for gathering the threads’ calculation results might result in too many threads just waiting, thwarting the advantages of multithreading. Fourth, using synchronized blocks for any collection handling might also end up in too many threads just waiting.
At some point in the history of Java’s evolution, advanced higher level multithreading constructs were introduced, namely the interfaces and classes inside the java.util.concurrent package and subpackages. Without claiming completeness in this section, we cover some of these constructs, because they are also included within Kotlin and you can use them to any extent you wish.
Special Concurrency Collections
CopyOnWriteArrayList: A list implementation where any mutation operations happen on a fresh copy of the complete list. At the same time, any iteration uses exactly the state of the list it had when the iterator got created, so a ConcurrentModificationException cannot happen. Copying the complete list is costly, so this implementation usually helps only where reading operations vastly outnumber writing operations. In such cases, however, no synchronized blocks are needed for thread safety.
CopyOnWriteArraySet: A set implementation where any mutation operations happen on a fresh copy of the complete set. What we said earlier for CopyOnWriteArrayList also holds for CopyOnWriteArraySet instances.
ConcurrentLinkedDeque: A thread-safe Deque where iteration operations are weakly consistent, meaning read elements reflect the deque’s state at some point at or since the creation of the iterator. No ConcurrentModificationException will be thrown.
ConcurrentLinkedQueue: A thread-safe Queue implementation. What was said for the ConcurrentLinkedDeque earlier concerning thread safety also holds for this class. No ConcurrentModificationException will be thrown.
ConcurrentSkipListSet: A thread-safe Set implementation . Iteration operations are weakly consistent, meaning read elements reflect the set’s state at some point at or since the creation of the iterator. No ConcurrentModificationException will be thrown. Other than the type specification the API documentation suggests, the elements must implement the Comparable interface.
ConcurrentSkipListMap: A thread-safe Map implementation . Iteration operations are weakly consistent, meaning read elements reflect the map’s state at some point at or since the creation of the iterator. No ConcurrentModificationException will be thrown. Other than the type specification the API documentation suggests, the keys must implement the Comparable interface.
Locks
as a Lock implementation.
The name reentrant lock comes from the lock’s ability to be acquired by the same thread several times, so a thread would not fall into a waiting state when it already has acquired the lock via lock.lock() and tries to acquire the same lock again before an unlock() happens.
A different lock interface is called ReadWriteLock. Compared to a normal Lock it has the ability to distinguish between read and write operations. This could be helpful in cases where several threads would be able to use variables in a read-only manner without any problem, whereas writing must block read operations and in addition must be confined to a single thread. A corresponding implementation reads ReentrantReadWriteLock. Its usage details are available in the API documentation.
Atomic Variable Types
The work of thread A therefore got lost entirely. This effect is commonly referred to as thread interference.
The updating of c by virtue of synchronized now can no longer be influenced by other threads. However, we might have a different solution. If we had a variable type that handles modification and retrieval in an atomic manner, without the chance of another thread interfering and destroying consistency, we could reduce the overhead a synchronized imposes. Such atomic data types do exist, and they are called AtomicInteger, AtomicLong, and AtomicBoolean. They are all from the java.util.concurrent.atomic package.
Note
The package java.util.concurrent.atomic has a few more atomic types that are for special use cases. Have a look at the documentation if you are interested.
Executors, Futures, and Callables
Callable
This is something that can be invoked, possibly by another thread, and returns a result.
Runnable
This one is not in package java.util.concurrent, but in package java.lang. It is something that can be invoked, possibly by another thread. No result is returned.
Executors
This is an important utility class for, among other things, obtaining ExecutorService and ScheduledExecutorService implementations.
ExecutorService
This is an interface for objects that allows invoking Runnables or Callables and gathering their results.
ScheduledExecutorService
This is an interface for objects that allows invoking Runnables or Callables and gathering their results. The invocation happens after some delay, or in a repeated manner.
Future
This is an object you can use to fetch the result from a Callable.
ScheduledFuture
This is an object you can use to fetch the result from a Callable submitted to a ScheduledExecutorService.
- 1.
Use one of the functions starting with new from the singleton object Executors to get an ExecutorService or ScheduledExecutorService. Save it in a property; for our purposes we call it srvc or schedSrvc.
- 2.
For registering tasks that need to be done concurrently, use any of the functions starting with invoke or submit for srvc, or any of the functions starting with schedule for schedSrvc.
- 3.
Wait for termination, as signaled by suitable functions from ExecutorService or ScheduledExecutorService, or by the Futures or ScheduledFutures you might have received in the previous step.
As you can see, these interfaces, classes, and functions mainly orchestrate threads and their calculation results. They do not control the usage of shared data; for that you need to follow the techniques presented in the preceding sections.
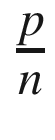 = π/4 or π = 4 ·
= π/4 or π = 4 · 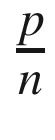 (see Figure 18-1).
(see Figure 18-1).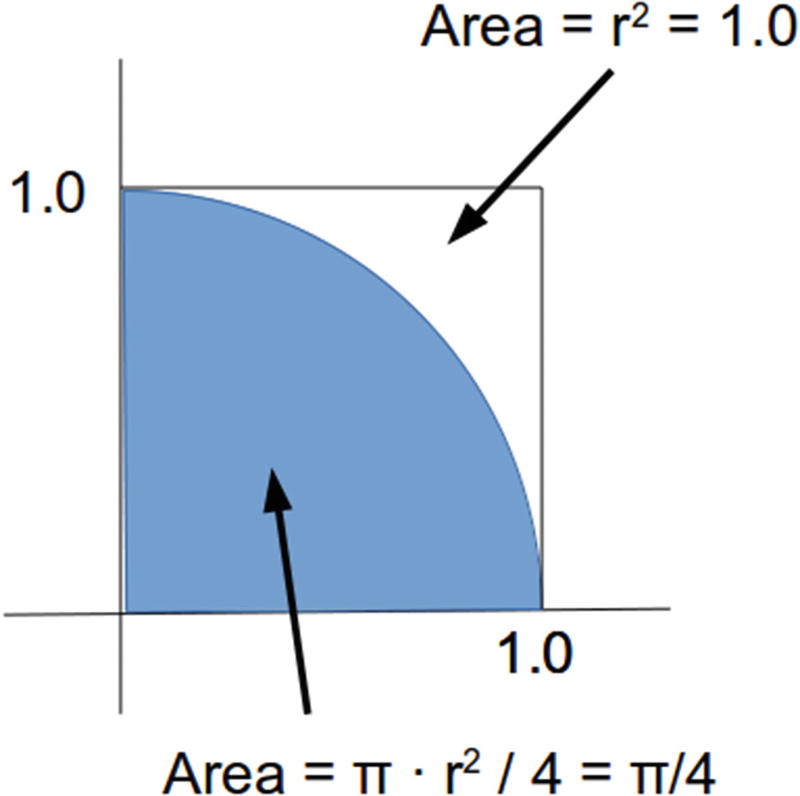
Pi calculation
Note
This is definitely not the cleverest way to calculate π, but it is easy to understand and you can easily distribute the workload among multiple threads.
Any labels, as shown in Figure 18-2.
A TextView with ID @+id/procs next to the Processors label.
An EditText with ID @+id/iters next to the Iterations label. Add attribute android:text="1000000".
An EditText with ID @+id/threads next to the Threads label. Add attribute android:text="4".
A TextView with ID @+id/cumulIters next to the Cumul Iters label.
A TextView with ID @+id/pi next to the Current Pi label.
A TextView with ID @+id/calcTime next to the Calc Time label.
A Button with text CALC and attribute android:onClick="calc".
A Button with text RESET and attribute android:onClick="reset".

Pi user interface
The class has as state the total number of points in points, the number of points inside the quarter unit circle in insideCircle, and the total number of iterations in totalIters.
In onSaveInstanceState() and onCreate() we make sure the state gets saved and restored whenever Android decides to suspend the app.
Also in onCreate() we determine the number of CPUs the device has and write it to the user interface.
Inside reset() , the algorithm gets reinitialized.
Inside report() , we calculate π according to the preceding formula and write it to the user interface.
The multithreading happens inside calc() . We read the number of threads and iterations to use from the user interface, distribute the iteration number evenly among the threads, obtain a thread pool from Executors, define and register the calculation algorithm, and eventually gather the results from all threads.
At the end of calc(), we determine the time needed for the calculation and write it to the user interface.
You can play around with the thread and iteration numbers to see the impact of multithreading. On most devices you should see a noticeable difference between running on one and two or more threads. By the way, pressing the CALC button several times improves the accuracy of the calculated π as the numbers get accumulated.
Exercise 1
Implement the multithreaded π calculation app as described in this section.
Kotlin Coroutines
Kotlin has its own idea of how to handle multithreading. It uses a concept that has been around for a while in older computer languages, coroutines. Here the idea is implemented to write functions that can get suspended and later resumed at certain locations during their inner program flow. This happens in a nonpreemptive way, which means during running a program in a multithreaded way the program flow context doesn’t get switched by the operating system, but rather by language constructs, library calls, or both.
(one line).
Coroutine scope: Any coroutine functionality runs within a coroutine scope. A scope is like a bracket around a multithreading ensemble, and scopes can have a parent scope defining a scope hierarchy. The root of the scope hierarchy can either be the GlobalScope or it can be obtained by the function runBlocking { } where inside the { } block you entered a new blocking scope. The blocking here means that the runBlocking() invocation only finishes after all included scopes finished their work. Because CoroutineScope is an interface, you can also define any class to spawn a coroutine scope. A very prominent example is to have an activity also represent a coroutine scope:
Coroutine context: A CoroutineContext object is a data container associated with a coroutine scope. It contains the objects that are necessary for a coroutine scope to properly do its work. Without any further intervention in a scope hierarchy, scope children inherit the context from their parents.
Global scope: The GlobalScope is a singleton object with a lifetime determined by the application as a whole. Although it is tempting to use the global scope as a basis for the most important coroutines, it is generally not recommended that you use it for the sake of properly structuring the multithreading aspects of your app. Use a dedicated coroutine builder instead.
Job: A job is a task that possibly runs in its own thread.
- Coroutine builder: These are functions that start a coroutine either in a blocking or nonblocking manner. Examples for builders are:
runBlocking() : This defines and runs a blocking coroutine. If runBlocking() gets used inside a coroutine scope, the block defined by runBlocking{ } spawns a new child scope.
launch() : This defines and runs a nonblocking coroutine. It cannot be used outside a coroutine scope. It immediately returns a Job object and runs its block in the background.
async() : This defines and runs a nonblocking coroutine that returns a value. It cannot be used outside a coroutine scope. It immediately returns a Deferred object and runs its block in the background.
coroutineScope() : This creates a new scope with the context inherited from the outer scope, except for a new Job object. It calls the specified block in the new scope.
supervisorScope() : This creates a new scope with a SupervisorJob. It calls the specified block in the new scope. Supervisor jobs are special jobs that can fail independently of each other.
Joining: If you get the result of invoking launch() in a property: val job = launch{ ... }, you can later call job.join() to block the program execution until the job has finished.
Suspending function: The keyword suspend is the only coroutine-related keyword you will find in the Kotlin language. All other coroutine material is available via the coroutines library. You need to add the suspend to functions that you want to be callable from inside a scope and that you want to be able to use with coroutines. For example, suspend fun theFun() { }. Consider the suspend as a coroutine scope forwarder.
Cancellation: Once you have a Job object, you can invoke cancel() on it to signal canceling the job. Note that the job usually doesn’t immediately quit its work, so you have to wait for the actual termination via a join() invocation, or you use cancelAndJoin(). You must ensure the coroutine you want to cancel is cancelable. To meet this aim you can either let the code call a suspending function like yield(), or you can periodically check for the isActive property you automatically have inside a coroutines scope.
Timeout: To explicitly specify a timeout for a block of statements you use
withTimeout(3000L) { // milliseconds... code here}
Coroutine exception handler: Coroutines have their own idea about how to handle exceptions. For example, if you do not provide a separate CoroutineExceptionHandler in the coroutine context, while canceling a job a CancellationException gets thrown, but that is ignored. What you still can do is wrap your code in a try { } finally { } block if you need to perform cleanup actions once a job gets canceled:
runBlocking {val job = launch {try {... do work} finally {... cleanup if canceled}}...job.cancelAndJoin()}Delay: Use delay(timeMillis) to specify a temporary suspension. The API documentation here speaks of a nonblocking suspension, as the thread running behind the coroutines actually is allowed to do other work. After the delay, the program flow can continue with the instructions behind the delay function.
Blocking : You use
runBlocking {...}to initiate a blocking execution of the statements inside the { } block. You usually apply it in the main function of your program to have a first coroutine scope that you can use for coroutines.
Coroutine dispatcher: An instance of a CoroutineDispatcher is part of the coroutine context you find in the property coroutineContext of each scope.
runBlocking {val ctx:CoroutineContext =coroutineContext...}
Structured concurrency: This describes the dependencies of job concurrency characteristics mirrored in a structure depicted by a hierarchy of { ... } constructs . Kotlin’s coroutines strongly favor a structured concurrency style of setting up concurrency.
Channel: Channels provide a means to communicate a data stream between coroutines. As of Kotlin version 1.3, this API is considered experimental. Check the official documentation to learn about the current state of this API.
Actor: An actor is both a coroutine launcher and a channel endpoint. As of Kotlin version 1.3, this API is considered experimental. Check the official documentation to learn about the current state of this API.
The following paragraphs outline basic and advanced coroutine usage patterns.
Basic Coroutines
In the block: suspend CoroutineScope.() -> T you can see the block runs inside an object that extends CoroutineScope. Such a CoroutineScope is an interface with a val named coroutineContext of type CoroutineContext. See later for details about the context.
Caution
Interfaces can have vals. We didn’t mention this feature in the object orientation introductory chapters, and during the runtime engine evolution it was primarily introduced for technical reasons. Here it gets used to make coroutines handling easier. Using vals and vars in your app’s interfaces is discouraged though, because variables usually belong to implementation aspects, not to declaration aspects, which is what interfaces are for. Use variables in interfaces with caution!
runBlocking { ... }
This enters a new blocking scope. Blocking here means the runBlocking() invocation will only return after all activities inside the { ... } lambda finished their work. The runBlocking() can be started from inside and outside a coroutine scope, although using it from inside a coroutine scope is discouraged. In both cases a fresh context is created that includes using the currently running thread for the job.
runBlocking(context:CoroutineContext) { ... }
This is the same as runBlocking(), but with a base context as given by the parameter.
GlobalScope
Use of this is discouraged. Use this singleton object if you want to use a scope that is tied to the application itself and its life cycle. You can, for example, use GlobalScope.launch{ ... } or GlobalScope.async{ ... }. Normally you should start from a runBlocking{ ... } instead. Not explicitly using GlobalScope improves the structuring of your app.
coroutineScope { ... }
This creates a new coroutine scope that inherits the context from the outer coroutine scope; that is, the scope in which the coroutineScope() gets invoked. However, it overwrites the job and uses its own job derived from the contents of its lambda function parameter (the content of { ... }). This function can only be called from inside a scope. Using coroutineScope() is a prominent example for structured concurrency: Once any child inside the { ... } fails, all the rest of the children will fail as well and eventually the whole coroutineScope() will fail.
supervisorScope { ... }
This is the same as coroutineScope(), but lets its child scopes run independent of each other. In particular, if any of the children get canceled, the other children and the supervisor scope do not get canceled.
launch { ... }
This defines a background job. The launch() invocation returns immediately while the background job defined by the { ... } lambda starts doing its work in the background. The launch() returns an instance of class Job. You can use the join() function from Job to wait for the job to finish.
async { ... }
This is the same as launch(), but allows for the background job to produce a result. For this aim launch() returns an instance of class Deferred. You can use its await() function to retrieve the result; of course, this implies waiting for the job to have finished.
Implement CoroutineScope
In any of your classes, you can implement class CoroutineScope: class MyClass : CoroutineScope { ... }. The problem with this approach is that, because CoroutineScope is just an interface, we need to implement the coroutine functionality by filling the coroutine context with sensible objects. A simple way to do that is using delegation: class MyClass : CoroutineScope by MainScope() { ... }, which delegates all coroutine builders to a MainScope object. That one is particularly useful for user interfaces. Once this is done we can freely use builders like launch() and async() , and also control functions like cancel(), from anywhere inside MyClass.
The start parameter can be used to tweak the way the coroutine starts. See the API documentation for details (enter “CoroutineStart” in Android Studio, then press Ctrl+B).
The async() function has the same default parameters as launch(), so you can also tweak the async() startup characteristics.
Running the code, the logs will show this:
The outer runBlocking() introduces a root in the coroutine scope hierarchy.
The runBlocking() only returns if all its children finish their work or a cancellation of their work occurs.
If a CancellationException gets thrown (uncomment the throw to see that happen), it gets transported up the scope hierarchy and consequentially 15 will not be reached.
Both async() and launch() introduce asynchronicity (concurrency); they return immediately while their { ... } lambdas do their work in the background.
The job1.join() and deferr1.await() synchronize the background jobs; both wait for the corresponding job to finish.
Coroutine Context
coroutineContext[Job]
This retrieves the Job instance that holds the instructions of which the coroutine consists.
coroutineContext[CoroutineName]
Optionally, this retrieves the name of the coroutine. You can specify the name via coroutineContext + CoroutineName("MyFancyCoroutine") as the first parameter of a coroutine builder (e.g., launch() or async()) invocation.
coroutineContext[CoroutineExceptionHandler]
This is an optional dedicated exception handler. We’ll talk about exceptions later.
coroutineContext[ContinuationInterceptor]
This internal item holds the object that is responsible for correctly continuing a coroutine after it was suspended and resumes its work.
In the same way, you can alter or redefine other context elements.
What a delay() Does
At first glance the delay(timeMillis:Long) function has the same use as the basic Thread.sleep(millis:Long) function from the Java way of using concurrency: Let the program flow wait for some time before it can continue with the instructions after the delay() or sleep() statement. However, there is a major difference between the two: The function Thread.sleep() actually blocks the current thread and lets other threads do their work, whereas delay() calls a suspending function that does not block the current thread but instead schedules a resumption of the program flow after the specified time elapses.
From a use-case view you use both for the same purpose: to continue with the program flow only after the specified time has elapsed. Knowing that for coroutines the thread does not get blocked, however, helps to tailor concurrency for maximum stability and performance.
What Is a Suspending Function?
A suspending function is a function that might or might not execute immediately or be suspended once invocation starts, and then eventually ends. It does not block a thread, even when it or parts of it are suspended.
Internally the suspend keyword leads to adding a hidden parameter for the coroutine context.
Waiting for Jobs
Dispatching work to several concurrently acting coroutines is one part of the story. First, if the coroutines calculated something, after the coroutines do their work we need to make sure we can gather the results before we continue with the program flow. Second, we must make sure the program as a big state machine is in a consistent state before we can continue doing more work after the coroutines finish. Here we are talking about result gathering and concertation or synchronization.
Again the await() function invocations suspend the program flow until the Deferreds finish their work. Again, the coroutine children of the async jobs also will have finished their work.
Here you must have made sure, though, that the Deferred actually finished its calculation, otherwise you’ll get an IllegalStateException. You can read the isCompleted property to check whether a Deferred or a Job has completed.
The join will happen automatically.
Canceling Coroutines
Inside a canceled job, any invocation of a suspend function will lead to the job finishing its execution. An example is delay(); inside the delay() function a cancellation check will occur and if the job was canceled, the job will immediately quit.
If there are no suspend function calls or not enough of them, you can use the yield() function to initiate such a cancellation check.
Inside your code you can regularly check whether the isActive property gives false. If this is the case, you know the job was canceled and you can finish the job execution.
which combines those two.
What a cancellation leads to concerning the coroutine scope hierarchy is discussed in the section “Exception Handling” later in this chapter.
Timeouts
Dispatchers
Dispatchers.Default
This is the default dispatcher used if the context does not yet contain a dispatcher. It uses a thread pool with at least two threads, and the maximum number of threads is the number of CPUs the current device has minus 1. You can, however, overwrite that number by writing System.setProperty( "kotlinx.coroutines.default.parallelism", 12 ) early in your app (before any coroutine gets built).
Dispatchers.Main
This is a dispatcher tied to user interface processing. For Android, if you want to use the main dispatcher, you must add library kotlinx-coroutinesandroid to the dependencies section inside build.gradle. If you route your coroutines structure likeclass MyClass :CoroutineScope by MainScope(){...}the Dispatchers.Main gets used automatically.
Dispatchers.IO
This is a dispatcher especially tailored for blocking IO functionality. It is similar to the Dispatchers.Default dispatcher, but if necessary creates up to 64 threads.
newSingleThreadContext("MyThreadName)"
This starts a dedicated new thread. You should finish using it by applying close() at the end or otherwise store the instance returned by the newSingleThreadContext() function call at some global place for reuse.
Dispatchers.Unconfined
This is not for general use. An unconfined dispatcher is a dispatcher that uses the surrounding context’s thread until the first suspending function gets called. It resumes from the first suspending function in the thread that got used there.
Exception Handling
For CancellationException exceptions and launch(): Remember that cancellation exceptions occur when you explicitly invoke cancel() on a Job element. If a CancellationException gets thrown, it will lead to a quitting of the current coroutine, but not to a quitting of any of the parents; they will just ignore it. The hierarchy’s root coroutine will just as well ignore the exception, so outside the coroutine machinery such an exception will not be detected.
For CancellationException exceptions and async(): Other than for launch(), a cancellation of a Deferred job by invoking cancel() on the Deferred element will not lead to the exception being ignored. Instead, we must react on the exception, which will show up in the await() function.
For TimeoutCancellationException exceptions: If a timeout in a withTimeout( timeMillis:Long ) { ... } happens, a TimeoutCancellationException gets thrown. This is a subclass of CancellationException and receives no special treatment, so what is true for normal cancellation exceptions holds for timeouts as well.
Any other exception: Normal exceptions lead to an immediate quitting of any running job in the coroutines hierarchy, and will also be thrown by the root coroutine. If you expect such an exception, you must, for example, wrap a root runBlocking() into a try-catch clause. You can, of course, add try-catch clauses inside the jobs to catch such exceptions early.
The runBlocking() does not forward the cancellation exception to the outside world. This exception thus is a somewhat “expected” exception.
Label X1 gets reached immediately after A. This is not a surprise, as all launch() invocations lead to background processing.
Labels B and C get reached shortly after A, because other than background processing startup, no delays are specified.
Label I gets reached 1 second later, because of the delay(1000L) immediately in front of it. At that time the delay after label C has almost passed by. A few milliseconds later D and E get reached.
While label E gets reached, the delay after X1 has not yet passed by completely, but half a second later X2 gets reached and we fire a cancellation on job l111. At that time we are in the middle of the delay(1000L) after E.
Because of the cancellation, the delay after E is quit immediately and job l111 prematurely exits. Labels F and G thus never get reached.
The parent coroutines of l111 continue with their work, they just ignore the cancellation of job l111. That is why a little later label H gets reached.
Label X3 happens before H. We know that runBlocking() continues its work while any noncanceled child is still running. Job l111 was canceled, but neither job l11 nor l1 have been canceled, so both H and I get reached.
Here we can see both the parent job l11 and its children (job l111) get canceled; labels F, G, and H never get reached.
Exercise 2
In the preceding example, remove the cancel() statement and instead add a timeout of 0.5 seconds to the delay() immediately after label E. What do you expect? Will the logging differ from the logging with the cancel() statement?
Note that despite it starting with a capital letter, the CoroutineExceptionHandler() actually is a function invocation. There is also an interface using the same name CoroutineExceptionHandler if you want to write a class for handling exceptions.
Such an exception handler only handles exceptions that do not otherwise get caught by the coroutines. We know that for launch() jobs a CancellationException does not get transported up the coroutines hierarchy; in this case and for this particular exception type, the exception handler does not get invoked either.
A supervisor leads to all coroutines handling their exceptions independent of each other. No child will, however, live longer than its parent.