
In the previous sections, we learned the basics of HTML, CSS, and XPath. To scrape real-world web pages, the problem now becomesa question of writing the proper CSS or XPath selectors. In this section, we introduce some simple ways to figure out working selectors.
Suppose we want to scrape all available R packages at https://cran.rstudio.com/web/packages/available_packages_by_name.html. The web page looks simple. To figure out the selector expression, right-click on the table and select Inspect Element in the context menu, which should be available in most modern web browsers:

Then the inspector panel shows up and we can see the underlying HTML of the web page. In Firefox and Chrome, the selected node is highlighted so it can be located more easily:

The HTML contains a unique <table> so we can directly use table to select it and use html_table() to extract it out as a data frame:
page <- read_html("https://cran.rstudio.com/web/packages/available_packages_by_name.html")
pkg_table <- page %>%
html_node("table") %>%
html_table(fill = TRUE)
head(pkg_table, 5)
## X1
## 1
## 2 A3
## 3 abbyyR
## 4 abc
## 5 ABCanalysis
## X2
## 1 <NA>
## 2 Accurate, Adaptable, and Accessible Error Metrics for Predictive
Models
## 3 Access to Abbyy Optical Character Recognition (OCR) API
## 4 Tools for Approximate Bayesian Computation (ABC)
## 5 Computed ABC Analysis
Note that the original table has no headers. The resulted data frame uses default headers instead and the first row is empty. The following code is written to fix these problems:
pkg_table <- pkg_table[complete.cases(pkg_table), ]
colnames(pkg_table) <- c("name", "title")
head(pkg_table, 3)
## name
## 2 A3
## 3 abbyyR
## 4 abc
## title
## 2 Accurate, Adaptable, and Accessible Error Metrics for Predictive
Models
## 3 Access to Abbyy Optical Character Recognition (OCR) API
## 4 Tools for Approximate Bayesian Computation (ABC)
The next example is to extract the latest stock price of MSFT at http://finance.yahoo.com/quote/MSFT. Using the element inspector, we find that the price is contained by a <span> with very long classes that are generated by the program:
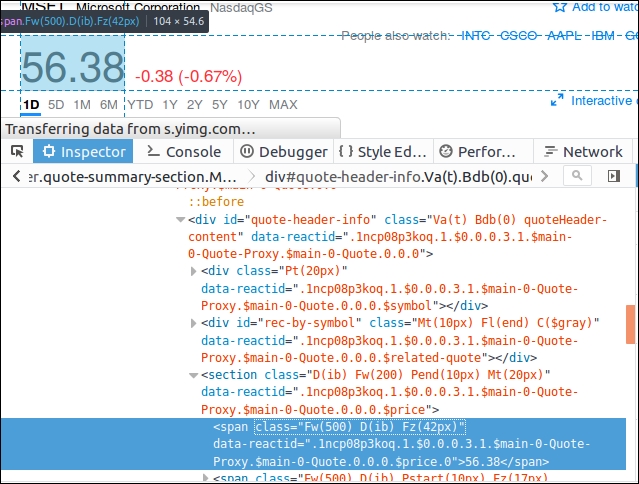
Looking several levels up, we can find a path, div#quote-header-info > section > span, to navigate to this very node. Therefore, we can use this CSS selector to find and extract the stock price:
page <- read_html("https://finance.yahoo.com/quote/MSFT")
page %>%
html_node("div#quote-header-info > section > span") %>%
html_text() %>%
as.numeric()
## [1] 56.68
On the right side of the web page, there is a table of corporate key statistics:

Before extracting it out, we again inspect the table and its enclosing nodes, and try to find a selector that navigates to this table:

It is obvious that the <table> of interest is enclosed by a <div id="key-statistics". Thus we can directly use #key-statistics table to match the table node and turn it into a data frame:
page %>%
html_node("#key-statistics table") %>%
html_table()
## X1 X2
## 1 Market Cap 442.56B
## 2 P/E Ratio (ttm) 26.99
## 3 Diluted EPS N/A
## 4 Beta 1.05
## 5 Earnings Date N/A
## 6 Dividend & Yield 1.44 (2.56%)
## 7 Ex-Dividend Date N/A
## 8 1y Target Est N/A
With similar techniques, we can create a function that returns the company name and price given a stock ticker symbol (for example, MSFT):
get_price <- function(symbol) {
page <- read_html(sprintf("https://finance.yahoo.com/quote/%s", symbol))
list(symbol = symbol,
company = page %>%
html_node("div#quote-header-info > div:nth-child(1) > h6") %>%
html_text(),
price = page %>%
html_node("div#quote-header-info > section > span:nth-child(1)") %>%
html_text() %>%
as.numeric())
}
The CSS selectors are restrictive enough to navigate to the right HTML nodes. To test this function, we run the following code:
get_price("AAPL")
## $symbol
## [1] "AAPL"
##
## $company
## [1] "Apple Inc."
##
## $price
## [1] 104.19
Another example is scraping top R questions at http://stackoverflow.com/questions/tagged/r?sort=votes, shown as follows:

With a similar method, it is easy to find out that the question list is contained by a container whose id is questions. Therefore, we can load the page and select and store the question container with #questions:
page <- read_html("https://stackoverflow.com/questions/tagged/r?sort=votes&pageSize=5")
questions <- page %>%
html_node("#questions")
To extract the question titles, we take a closer look at the HTML structure behind the first question:

It is easy to find out that each question title is contained in <div class="summary"><h3>:
questions %>%
html_nodes(".summary h3") %>%
html_text()
## [1] "How to make a great R reproducible example?"
## [2] "How to sort a dataframe by column(s)?"
## [3] "R Grouping functions: sapply vs. lapply vs. apply. vs. tapply vs. by vs. aggregate"
## [4] "How to join (merge) data frames (inner, outer, left, right)?"
## [5] "How can we make xkcd style graphs?"
Note that <a class="question-hyperlink"> also provides an even easier CSS selector that returns the same results:
questions %>%
html_nodes(".question-hyperlink") %>%
html_text()
If we are also interested in the votes of each question, we can again inspect the votes and see how they can be described with a CSS selector:

Fortunately, all vote panels share the same structure and it is quite straightforward to find out their pattern. Each question is contained in a <div> with the question-summary class in which the vote is in a <span> with the .vote-count-post class:
questions %>%
html_nodes(".question-summary .vote-count-post") %>%
html_text() %>%
as.integer()
## [1] 1429 746 622 533 471
Similarly, the following code extracts the number of answers:
questions %>%
html_nodes(".question-summary .status strong") %>%
html_text() %>%
as.integer()
## [1] 21 15 8 11 7
If we go ahead with extracting the tags of each question, it becomes a bit tricky because different questions may have different numbers of tags. In the following code, we first select the tag containers of all questions and extract the tags in each container by iteration.
questions %>%
html_nodes(".question-summary .tags") %>%
lapply(function(node) {
node %>%
html_nodes(".post-tag") %>%
html_text()
}) %>%
str
## List of 5
## $ : chr [1:2] "r" "r-faq"
## $ : chr [1:4] "r" "sorting" "dataframe" "r-faq"
## $ : chr [1:4] "r" "sapply" "tapply" "r-faq"
## $ : chr [1:5] "r" "join" "merge" "dataframe" ...
## $ : chr [1:2] "r" "ggplot2"
All the preceding scraping happens in one web page. What if we need to collect data across multiple web pages? Suppose we visit the page of each question (for example, http://stackoverflow.com/q/5963269/2906900). Notice that there is an info box on the up-right. We need to extract such info boxes of each question in list:

Inspecting tells us #qinfo is the key of the info box on each question page. Then we can select all question hyperlinks, extract the URLs of all questions, iterate over them, read each question page, and extract the info box using that key:
questions %>%
html_nodes(".question-hyperlink") %>%
html_attr("href") %>%
lapply(function(link) {
paste0("https://stackoverflow.com", link) %>%
read_html() %>%
html_node("#qinfo") %>%
html_table() %>%
setNames(c("item", "value"))
})
## [[1]]
## item value
## 1 asked 5 years ago
## 2 viewed 113698 times
## 3 active 7 days ago
##
## [[2]]
## item value
## 1 asked 6 years ago
## 2 viewed 640899 times
## 3 active 2 months ago
##
## [[3]]
## item value
## 1 asked 5 years ago
## 2 viewed 221964 times
## 3 active 1 month ago
##
## [[4]]
## item value
## 1 asked 6 years ago
## 2 viewed 311376 times
## 3 active 15 days ago
##
## [[5]]
## item value
## 1 asked 3 years ago
## 2 viewed 53232 times
## 3 active 4 months ago
Besides all these, rvest also supports creating an HTTP session to simulate page navigation. To learn more, read the rvest documentation. For many scraping tasks, you can also simplify the finding of selectors by using the tools provided by http://selectorgadget.com/.
There are more advanced techniques of web scraping such as dealing with AJAX and dynamic web pages using JavaScript, but they are beyond the scope of this chapter. For more usage, read the documentation for the rvest package.
Note that rvest is largely inspired by Python packages Robobrowser and BeautifulSoup. These packages are more powerful and thus popular in web scraping in some aspects than rvest. If the source is complex and large in scale, you might do well to learn to use these Python packages. Go to https://www.crummy.com/software/BeautifulSoup/ for more information.