
We have now got a fair understanding of what overfitting means when it comes to machine learning modeling. Just to reiterate, when the model learns the noise that has crept into the data, it is trying to learn the patterns that take place due to random chance, and so overfitting occurs. Due to this phenomenon, the model's generalization runs into jeopardy and it performs poorly on unseen data. As a result of that, the accuracy of the model takes a nosedive.
Can we combat this kind of phenomenon? The answer is yes. Regularization comes to the rescue. Let's figure out what it can offer and how it works.
Regularization is a technique that enables the model to not become complex to avoid overfitting.
Let's take a look at the following regression equation:
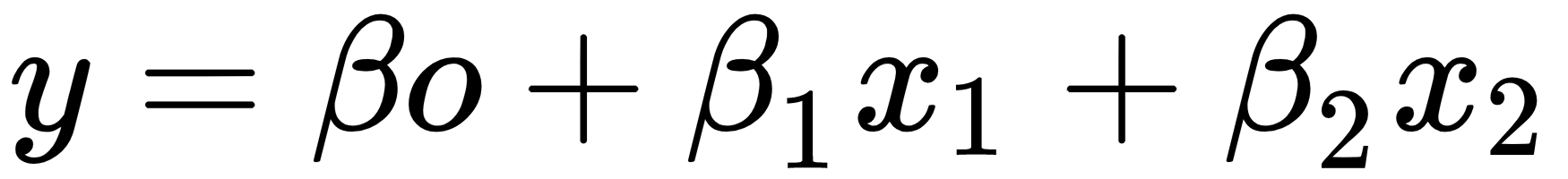
The loss function for this is as follows:

The loss function would help in getting the coefficients adjusted and retrieving the optimal one. In the case of noise in the training data, the coefficients wouldn't generalize well and would run into overfitting. Regularization helps get rid of this by making these estimates or coefficients drop toward 0.
Now, we will cover two types of regularization. In later chapters, the other types will be covered.