
1
Machine Learning Architecture and Framework
Nilanjana Pradhan* and Ajay Shankar Singh
School of Computer Science and Engineering, Galgotias University, Greater Noida, Uttar Pradesh, India
Abstract
Machine Learning is one of the fastest developing fields in computer science with wide range of applications. The machine learning architecture involves lot of complexity. The machine learning architecture will implement learning algorithm in the application engine which will perform the predictions, perform various complex queries in database and finally use analytics tools to produce predictions based on application areas. An effective machine learning architecture helps in designing better data centers, promote human welfare, solving critical system failures. A good architecture will cover all important risks involved with data privacy and security areas. In order to set up an effective machine learning architecture the problem area must be well defined. Training data (text, images, audio, video, structured data, user generated content etc.) must be collected for machine learning development process. In most cases data are incorrect and useless. The quality of the data matters in building and effective ML system. Good data visualization, data filtering, encryption tools and analytics tools are required. The machine learning system must be tested with test data. The model must get validated. In business domain ML algorithms are implemented on business processes, business services, people, skills, culture, risk management, partners, business functions, business organization.
Keywords: Machine learning, analytics, encryption, prediction, algorithm
1.1 Introduction
Machine learning is a branch of AI in which we require large volume of data and analyze those data with efficient algorithm. It aims at extracting knowledge or patterns from a large volume of observations. In supervised learning the observations contains data which trains the machine learning system to recognize certain rules.
ML systems recognize patterns from input data and predict or classify an object. In reinforcement learning, given evaluations help in distinguishing the situation. Examples are various types of ML applications which make a computer capable of playing games or drive vehicles. Machine learning emerged from artificial intelligence; however it focuses more on cognitive learning. AI attempts to model human function and intelligence which helps to resolve various problems. An important aspect of ML that makes it particularly appealing in terms of business is that it does not require as much explicit programming in advance to acquire intelligent insight. This ability uses various learning algorithms that simulate some human intelligence. Once data is collected and prepared for machine learning, algorithms are selected, modeled and interpreted [1]. Every learning system progresses through various learning iterations on its own to reveal hidden business value from data. Machine learning does not require too much of advance programming. Large amount of raw data is required coupled with high computing power on the execution platform to perform all the computations required for learning. However programming is still required for the application of machine learning, especially if it is applicable to automation.
The fundamental of ML involves large volumes of information data for the learning procedure. This information could emerge out of an assortment of sources, for example, venture frameworks, centralized server databases, and IoT edge gadgets. IT may be organized or unstructured in nature. Extremely high volumes of information are frequently nourished into machine since more information regularly yields better bits of knowledge. In this computerized business time, different sources and volumes of data are detonating. Learning in ML is commonly utilized for business reason for existing is either directed or unaided. In these classifications, be that as it may, there is a wide range of sorts of calculations and ML schedules, which are utilized to achieve different goals.
There are various eager learning methods which start computing before receiving new test data. They generally depend more on upfront evaluation of training data in order to predict without the need for new data. As a result, eager learning methods tend to spend more time on processing the training data. Another kind of learning method known as lazy learning method delays processing and data evaluation until it is fed with new test data. Machine learning is used to provide results that are either predictive, i.e. provide forecasts, or prescriptive, i.e. suggests recommended actions. Various data sets and feature regions are required for investigation using machine learning algorithm [1]. This yield information is by and large put away for examination and conveyed as reports and encouraged as contribution to other venture applications or frameworks.
The large volume of data that are collected from IoT sensors and other new information sources is increasing the capabilities of businesses to evaluate them and retrieve value and insights from them. Machine learning can relatively quickly and efficiently evaluate these mountains of data; many businesses are capturing the opportunity to discover the hidden insights that could deliver a competitive edge.
1.2 Machine Learning Algorithms
As of late individuals crosswise over various controls are exploring artificial intelligence to enhance their professional work. Artificial intelligence is used by economists to foresee future market costs in order to make a benefit. In restorative science [1], computer based intelligence is utilized to arrange whether a tumor is harmful or not. In meteorology AI is used for weather prediction. AI is used by human resource recruiters to analyze the résumé of applicants which helps in finding out if the applicant meets the minimum criteria for job. To achieve all these application of AI we need to implement machine learning algorithms. Every machine learning enthusiast begins with learning various ML algorithms and then moves toward building the ML architecture for various applications.
1.2.1 Regression
Regression is actually a method of building predictive model. This algorithm is mainly used for forecasting a predictive analysis. Here a set of predictor variables predicts an outcome, i.e. dependent variable. Regression estimates the relationship between one dependent and one independent variable and determines the strength of predictors and effect of forecasting. Various kinds of regressions are linear regression, multiple regression, logistic regression, ordinal regression, multinomial regression, and discriminant regression [2].
In the above figure the x hub speaks to autonomous variable and y— pivot speaks to subordinate variable. The dots represent the various observations. We need to minimize the error, i.e. the difference between estimated value and the actual value.
1.2.2 Linear Regression
One of the most well known algorithms in machine learning is linear regression. Machine learning helps in reducing the error of a predictive model resulting in making most accurate predictions. One of the examples of both statistical algorithm and machine learning algorithm is linear regression. Linear regression which is a linear model establishes a linear relationship between input variables and a single output variable [2]. If there are multiple input variables it is known as multiple linear regression. In simple regression problem the model is represented by
where x represents the input data and y represents the output or predict and m and c are the variables which the model will try to learn.
In multivariable regression the model will use the following equation to learn
where the variables x, y, z will represent distinct pieces of information for every observation. The prediction function helps in estimating the sales of a given company in comparison to the expenditure on television advertisement. Linear regression assumes that, independent variable (X) and dependent variable (Y) have a linear relationship between them. At each value of X, Y is distributed normally. For each value of X variance of Y is similar and all observations are independent.
1.2.3 Support Vector Machine
Support vector machine (SVM) is one of the popular machine learning algorithms. A hyperplane in an N-dimensional space (N—the quantity of highlights) that particularly classifies data points is discovered with the help of this algorithm [3].
1.2.4 Linear Classifiers
Linear classifiers are very simple with easy computational methods using linear functions. It divides the feature space into two different regions as shown in Figure 1.1 and Figure 1.2 with the help of classifier margin. The classifier margin can be in two dimensional or three dimensional space. The characteristic of the object is mainly presented as feature vector.
The classifier margin of a linear classifier and the width of the boundary can be incremented before hitting a data point. It helps in separating two data sets of different class. It is generally drawn in between data sets of two different classes. The specific distance from the decision boundary to the closest data point confirms the margin of the classifier. The SVM where data points are classified by linear classifier is the simplest kind of SVM and is called LSVM [3].

Figure 1.1 Linear classifier.

Figure 1.2 Linear classifier for SVM.
Source: https://towardsdatascience.com/a-friendly-introduction-to-support-vector-machines-svm-925b68c5a079.

Figure 1.3 Linear classifier with hyperplane in SVM.
Source: https://towardsdatascience.com/a-friendly-introduction-to-support-vector-machines-svm-925b68c5a079.
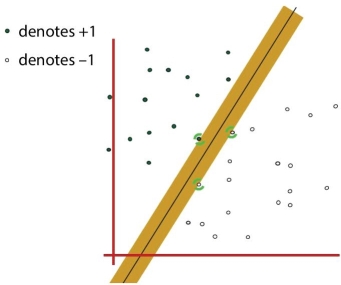
Figure 1.4 Linear classifier for SVM with wider hyperplane.
Source: https://towardsdatascience.com/a-friendly-introduction-to-support-vector-machines-svm-925b68c5a079.
The position and orientation of the hyperplane are influenced by the support vectors which are the data points located close to the hyperplane is represented in Figure 1.3 and Figure 1.4. The margin of the classifier is maximized by these support vectors. The position of the hyperplane will change if we delete the support vectors. One of the well known classification problems with machine learning is overfitting or overtraining. This happens when we are unable to classify unseen examples correctly and we have learned the training data very well. In this condition the classifier fits the training data rigidly. It does not work well on the test data. It is one of the causes of poor performance of any machine learning model [3].
In nonlinear SVM as shown in Figure 1.5, the input features can be mapped to higher dimensional feature space as represented in Figure 1.6 where they become separable [3]. Figure 1.7 represents hyperplane and support vectors in higher dimension.

Figure 1.5 Non-linear SVMs: Feature spaces.
Source: https://towardsdatascience.com/a-friendly-introduction-to-support-vector-machines-svm-925b68c5a079.

Figure 1.6 Non linear SVM where features are converted into higher dimension.
Source: https://towardsdatascience.com/a-friendly-introduction-to-support-vector-machines-svm-925b68c5a079.

Figure 1.7 Hyperplanes and support vectors.
Source: https://towardsdatascience.com/a-friendly-introduction-to-support-vector-machines-svm-925b68c5a079.
1.2.5 SVM Applications
In many real world problems we apply SVM algorithm and it is based on supervised learning algorithms and hence it classifies unrecognized data. Following are some of the application areas of SVM [3].
- Text and hypertext categorization
- Face recognition
- Image classification
- It is used in bioinformatics for protein classification and cancerous cell classification.
- Character recognition of handwritten words
- Disease prediction
1.2.6 Naïve Bayes Classification
Naïve Bayes classifier is a probabilistic machine learning model which is based on Bayes theorem. If there are several thousand data points and few variables naïve Bayes classifier can be used. The various real time applications of naïve Bayes classifier are:
- Spam classification—predicts whether an email is spam or not
- In medical science it helps to predict whether a patient suffers from a specific disease.
- Forecasting of climatic conditions
- Digit recognition
- Sentiment analysis
- Recommendation systems
According to naïve Bayes assumption all features are independent given the class label Y. Following equation denotes naïve Bayes model:

After selecting Naïve Bayes classifier we need to train it with some data.
1.2.7 Random Forest
The kind of classifier that is composed of many decision trees is random forest. Tin Kam Ho of Bell Labs first proposed random forest and the term came from random decision forests. Decision trees which are considered as individual learners are combined to form random forest and are commonly used for data exploration. CART or classification and regression tree is one type of decision tree. It divides feature space into sets of disjoint rectangular regions and it is greedy, top-down binary, recursive partitioning [4].
The random forest is one of the algorithms which give correct classification results and efficiently runs on large databases. There are thousands of input variables which it can handle without data deletion. The variables which are important for classification are estimated by it. An internal unbiased estimate of the generalization error is generated as the forest building progresses. It helps in maintaining accuracy as it has an effective method for estimating missing data in case a large volume of data is missing [4].
1.2.8 K-Nearest Neighbor (KNN)
The entire data set is used as training set instead of splitting the data set into a training set and test set in case of KNN algorithm. The KNN algorithm traverses the entire data set to find the k-nearest instances to the new instance in order to find a new instance. For K number of instances the total mean and mode of the outcomes are calculated for a classification problem where the value of K is user specified. Euclidean distance and Hamming distance methods are used for calculating the similarity between instances.
1.2.9 Principal Component Analysis (PCA)
Principal component analysis (PCA) is utilized to investigate information effectively and make representation by diminishing the quantity of factors. By catching the greatest difference in the information and arranging it into another framework are called “chief parts” is achieved.
In PCA every segment is a direct mix of the first factors and is symmetrical to each other. Connection between these segments is zero and they are symmetrical to one another [5].
The course of the greatest inconsistency in the information is caught by the main principal component. All the progressive principal components (PC3, PC4, etc) catch the rest of the fluctuation while it is uncorrelated with the past segment [5].
1.2.10 K-Means Clustering
K-means algorithm is an unsupervised learning which involves unaided realizing which is utilized when we have unclear classes of information. This calculation targets discovering bunches in the information. Variable N means the quantity of clusters. The calculation iteratively doles out data point to one of N clusters [6].
Clustering is a technique used to perform statistical data analysis in various fields. The centroids of the K clusters in K-means clustering are utilized to mark new information. Each information point is relegated to a solitary group. Clustering enables you to look and break down the clustering that has developed naturally [6].
Every single centroid of a cluster is an accumulation of highlights which characterize the subsequent gatherings. Looking at the centroid highlight loads can be utilized to subjectively translate what sort of gathering each bunch speaks to.
1.3 Business Use Cases
The K-means clustering algorithm is used to discover clusters which have not been unequivocally assigned the information. This can be utilized to affirm business presumptions about what kinds of clusters exist or to recognize obscure clusters in complex informational indexes. When the algorithm has been run and the clusters are portrayed, any new data can be adequately consigned to the right clusters [6].
This is a flexible algorithm that can be used for a clustering. A few examples of use cases are:
- Behavioral division
- Segmentation of historical sales data
- Segmentation of exercises on application, site, or stage
- Define interests dependent personas
- Create profiles dependent on action observing
- Inventory order
- Group stock with deals action
- Group stock with assembling measurements
- Sorting sensor estimations
- Detection of various types of movements with the help of sensors
- Grouping of pictures
- • Segregation of various types of sound
- Identify cluster identification in wellbeing checking
- Detecting bots or abnormalities
- Separate legitimate action clusters from bots
- Group substantial movement to tidy up anomaly discovery
Note that these segments of the design guide to a large number of the ML stages (see Figure 1.8) examined in the past area—for instance, getting, handling and demonstrating information, and afterward executing ML schedules and sending the outcomes. An all out big business ML design, containing every one of the highlights above, presumably won’t be fundamental when simply beginning with ML. From the get-go, experts may buy a little scale ML platform to suit a special use case, and buy off-the-rack apparatuses to help a littler scale, “ML Lite” (lightweight) design appropriate for early use cases. After some time, they can iteratively fabricate, scale and bind together this into an “ML Enterprise” design that can efficiently bolster numerous use cases. The accompanying segments investigate the distinctive real segments of this design in more detail [7].
For data acquisition in the information obtaining segment of the ML design, information is gathered from an assortment of sources and arranged for ingestion for ML information handling stage as shown in the above figure. This segment of the engineering is significant on the grounds that ML frequently starts with the accumulation of high volumes of information from an assortment of potential sources, for example, ERP databases, centralized servers or instrumented gadgets that are a piece of an IOT framework [7].
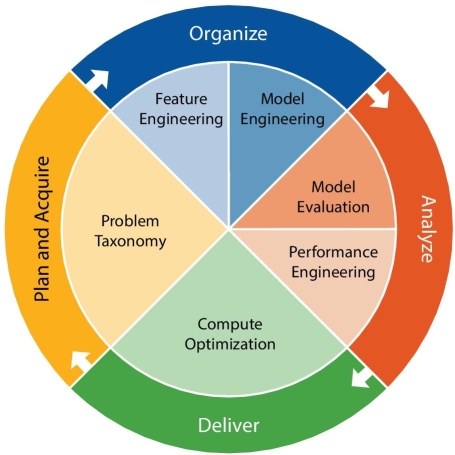
Figure 1.8 Continuous ML model and control framework
(Source: Sapp, C. E. Preparing and architecting for machine learning. Gartner Technical Professional Advice, p 18).
Information Processing/Integration: In the information handling part of the design, the place information is sent for the development reconciliation and handling required to set up the information for ML execution. This may incorporate modules to play out any information change, standardization, and cleaning encoding steps that are important. Likewise, whenever regulated learning is utilized, information should have test determination steps performed to get ready arrangements of information for preparing [7].
Processing throughput is required here and you may execute a Lambda design. Moreover, you may use memory preparing for rapid handling. Different decisions for incorporating information in this layer may incorporate whether to utilize an independent information joining application or a mix stage as an administration (iPaaS). Highlight analysis of the information ingested for preparing may incorporate highlights that are excess or superfluous. Along these lines, specialized experts must empower the capacity to choose and examine a subset of the information so as to lessen preparing time, or to improve the model. Much of the time, highlight examination is a piece of test choice. In any case, it is critical to feature this subcomponent so as to change information that may damage security conditions or advance exploitative expectations. To battle security and moral concerns, clients should concentrate on expelling highlights from being utilized in the model. It is a decent standard to separate however much information as could be expected from sources when they are accessible. This is on the grounds that it is hard to anticipate which information fields are valuable. Acquiring duplicates of generation information sources can be intense and subject to stringent change control. In this way, it is smarter to get a superset of the information that is accessible and after that limit the information really utilized in the model using database [7]. In the event that during improvement it turns out to be evident that further information ends are required, at that point it is conceivable to just unwind the see criteria, and the additional information is promptly accessible. Capacity is cheap, and this makes the procedure substantially more light-footed. Information planning instruments are regularly used to perform highlight examination and choice. We should search for apparatuses that help self-administration information arrangement so as to furnish information science groups and designers with the capacity to control information to help ML calculations or models. Administration will assume a noteworthy job in the segment of your design. Moreover, consider verifying the learning and classification parts of your engineering to guarantee security or moral contemplations aren’t ruptured through antagonistic ML [7]. Information Modeling: The demonstrating bit of the engineering is that the place calculations are chosen and adjusted to address the issue that will be inspected in the execution stage (see Figure 1.9). For instance, if the learning application will include bunch investigation, information grouping calculations will be a piece of the ML information model utilized here. On the off chance that the figuring out how to be performed is administered, information preparing calculations will be included also.
Execution ML algorithms can be very nondeterministic, and they may yield sudden practices, contingent upon preparing and information arrangement. Specialized experts must structure for nondeterminism by empowering flexible figure situations. Think about the open cloud as one of those versatile situations.
Information Acquisition: In the information securing segment of the ML engineering, information is gathered from an assortment of sources and arranged for ingestion for ML information handling stage (see Figure 1.10). This segment of the design is significant on the grounds that ML frequently starts with the accumulation of high volumes of information from an assortment of potential sources, for example, ERP databases, centralized computers or instrumented gadgets that are a piece of an IOT framework.

Figure 1.9 Machine learning architecture
(Source: Sapp, C. E. Preparing and architecting for machine learning. Gartner Technical Professional Advice, p 20).

Figure 1.10 ML architecture: data acquisition
(Source: Sapp, C. E. Preparing and architecting for machine learning. Gartner Technical Professional Advice, p. 21).
1.4 ML Architecture Data Acquisition
Data Processing/Integration: The data processing portion of the architecture is where data is forwarded for the advance integration and processing required to prepare the data for ML execution. This may include modules to perform any data transformation, normalization, and cleaning encoding steps that are necessary. In addition, if supervised learning is used, data will need to have sample selection steps performed to prepare sets of data for training.
Computing throughput is required here and you might choose to implement a Lambda architecture. Additionally, you might choose to use in memory processing for high-speed processing. Different decisions for coordinating information in this layer may incorporate whether to utilize an independent information mix application or a joining stage as an administration (iPaaS).
Feature analysis of the informative data ingested for handling may incorporate highlights that are repetitive or irrelevant. Hence, specialized experts must empower the capacity to choose and dissect a subset of the information so as to lessen preparing time, or to disentangle the model. When in doubt, incorporate examination is a bit of test decision. Regardless, it is extremely important to include this subcomponent so as to change information that may disregard security conditions or advance untrustworthy forecasts. To battle security and moral concerns, clients should concentrate on expelling highlights from being utilized in the model. It is a decent guideline to separate however much information as could reasonably be expected from sources when they are accessible. This is in light of the fact that it is difficult to predict which data fields are useful. Acquiring duplicates of creation information sources can be extreme and dependent upon stringent change control. In this manner, it is smarter to acquire a superset of the information that is accessible and after that limit the information really utilized in the model using databases [7]. On the off chance that during improvement it turns out to be certain that further information ends are required, at that point it is conceivable to just unwind the see criteria, and the additional information is quickly accessible. Capacity is cheap, and this makes the procedure substantially more light-footed.
Data preparation tools are often used to perform feature analysis and selection. We must look for tools that support self-service data preparation in order to provide data science teams and developers with the ability to manipulate data to support ML algorithms or models. Governance will play a major role in the component of your architecture. Additionally, consider securing the learning and classification parts of your architecture to ensure that privacy or ethical considerations aren’t breached through adversarial ML.
The demonstrating bit of the design is that the place calculations are chosen and adjusted to address the issue that will be inspected in the execution stage. For instance, if the learning application will include group investigation, information bunching calculations will be a piece of the ML information model utilized here. In the event that the figuring out how to be performed is directed, information preparing calculations will also be included.
1.5 Latest Application of Machine Learning
The magical touch of machine learning has made our life more comfortable than before. The contribution of science is just undeniable in our everyday life. Effect of science in our life cannot be overlooked. In our regular life we are gaining lot of advantages from Internet. For example we use Google map to travel in unknown roads. We use social networks and blogs to express our thoughts or feelings. Online news portals help us to remain updated about recent news and so on. Our perception of life is becoming more digital and because of various machine learning applications.
1.5.1 Image Identification
Picture acknowledgement is one of the most critical machine learning applications. In advanced picture it helps in distinguishing and recognizing an element or an article. This technology is used in example acknowledgment, face location, face acknowledgment, optical character acknowledgment and numerous more. Machine learning approach for picture acknowledgment is exceptionally powerful. In AI approach for picture acknowledgment, key highlights are separated from the picture and these highlights are sustained as contribution to an AI model.
1.5.2 Sentiment Analysis
Feeling investigation is another AI application which causes us to separate feelings from the content and decides the frame of mind or assessment of the speaker or the author.
The primary worry of assessment investigation is to discover the contemplations of other individuals. On the off chance that somebody gives a negative criticism about the film we have to discover the real idea (positive or negative) from the content and it is the real assignment of assessment investigation. Examination application can be applied to the further application, for example, in audit based site, basic leadership application [8].
The AI approach helps in extracting information from the information. This methodology can utilize enormous information to build up a framework. In AI approach two kinds of learning calculation, regulated and unaided, can be utilized in supposition examination.
1.5.3 News Classification
Another benchmark utilization of an AI is news order. Because of this in present days the volume of data has duplicated colossally on the web. Since each individual have his individual intrigue or decision along these lines, to pick or assemble a bit of suitable data turns into a major test to the clients.
1.5.4 Spam Filtering and Email Classification
Machine learning algorithms are executed in order to characterize email and channel the spam naturally. One of the popular technologies called multi-layer recognition is utilized to channel the spam. The standard based spam separating has a few disadvantages to channel the spam while spam sifting utilizing the ML approach is increasingly effective.
1.5.5 Speech Recognition
Expressed words are changed into content with the help of speech recognition. It is called programmed discourse acknowledgment, PC discourse acknowledgment or discourse to content. This field is profited by the headway of ML approach and huge information.
At present, all business reason speech recognition frameworks utilize an ML way to deal with perceiving the discourse. Why? The speech recognition framework utilizing ML approach is superior to the discourse acknowledgment framework utilizing a customary technique.
This is because, in an ML approach, the framework is prepared before it goes for the approval.
Fundamentally, the ML programming of discourse acknowledgment works in two learning stages:
- Before the product buy
- After the client buys the product
1.5.6 Detection of Cyber Crime
Machine Learning algorithm is widely used in cyber security to prevent online misinterpretation. This extensive ML application decreases the misfortune and amplifies the benefit. Utilizing Machine learning in this application is much more beneficial than any other traditional rule based system.
1.5.7 Classification
A powerful classifier framework can be built by using machine learning approach and eventually fabricate a compact model which improve its productivity.
Each occurrence in an informational collection utilized by the ML algorithm is spoken to utilizing a similar arrangement of highlights. These occasions may have a known mark; this is known as the ML algorithm. Supervised and unsupervised are two varieties of the ML methodologies that are utilized for problems related to classification.
1.5.8 Author Identification and Prediction
The unlawful utilization of online resources for inappropriate or illicit purposes has increased with the quick development of the Internet and has turned into a noteworthy worry for society. For this respect, creator distinguishing proof is required. Author recognizable proof additionally is known as initiation ID. The creator distinguishing proof framework may utilize an assortment of fields, for example, criminal equity, the scholarly community, and humanities. The way toward saying something dependent on the past history is known as prediction. It very well may be climate forecast, traffic prediction and many more. A wide range of estimates should be possible utilizing an ML approach.
1.5.9 Services of Social Media
Do you ever consider how they utilize the Artificial Intelligence and Machine learning to deal with your social record? For instance, Facebook consistently sees your exercises like with whom you talk, your preferences, working environment, and study place. Furthermore, AI/ML consistently acts dependent on experience. Along these lines, Facebook gives you a proposal dependent on your exercises.
1.5.10 Medical Services
AI techniques and devices are utilized broadly in the territory of medicinal related issue, as an occurrence to recognize an infection, treatment arranging, restorative related research, and expectation of the ailment circumstance. Utilizing AI based programming in the social insurance issue gets a leap forward in restorative science.
1.5.11 Recommendation for Products and Services
Assume that we obtained a few things from an online shop a few days prior. Two or three days after, you will see that the related shopping sites or administrations are suggested for you.
Internet based life is utilizing the AI way to make alluring and awesome highlights, for example individuals you may know, recommendation, and response alternatives for their clients. These highlights are only a result of the AI procedure.
1.5.11.1 Machine Learning in Education
Instructors can utilize machine learning to check the amount of exercises that understudies can devour, how they are adapting to the exercises educated and whether they are viewing it as a lot to expend. Obviously, this enables the instructors to enable their understudies to get a handle on the exercises.
1.5.11.2 Machine Learning in Search Engine
Web indexes depending on machine learning to improve their administrations is no mystery today. Actualizing these, Google has presented some astounding administrations, for example, voice acknowledgment, picture search and some more. How they concoct additionally fascinating highlights is the thing that the truth will surface eventually.
1.5.11.3 Machine Learning in Digital Marketing
This is the place machine learning can help fundamentally. AI permits an increasingly applicable personalization. Consequently, organizations can cooperate and draw in with the client. Refined division centers around the fitting client at the ideal time, additionally with the privilege message. Organizations have data which can be utilized to get familiar with their conduct. Nova uses machine learning to compose deal messages that are customized. It realizes which messages performed better in the past and likewise recommends changes to the business messages.
1.5.11.4 Machine Learning in Healthcare
This application appears to stay an interesting issue throughout the previous three years. There are a few promising new businesses of this industry as they are outfitting their exertion with an emphasis on social insurance. These incorporate Nervanasys (obtained by Intel), Ayasdi, Sentient, and Digital Reasoning System among others.
PC vision is the most noteworthy supporters in the field of machine learning, which uses profound learning. It’s a functioning human service application for ML Microsoft’s InnerEye activity that begun in 2010 and is presently chipping away at a picture analytic device.
1.6 Future of Machine Learning
People have endeavored to develop machines post-industrialization which work like a human. Self driven machines have changed various business standards and one of the most prominent gifts to humankind is a thinking machine. Self-driving vehicles, propelled accomplices, mechanical handling plant staff, and canny urban zones have shown that sagacious machines are possible in the progressing years. Man-made insight has changed most industry sections like retail, creating, support, restorative administrations, and media and continues assaulting new locales.
In view of current innovation patterns and methodical movement machine learning is moving toward maturity. It will consistently stay a necessary piece of AI, enormous or little. ML expects expanded significance in business applications. The significance of ML is expanding and there is a likelihood that the innovation presents a cloud technology which is referred to as “machine learning-as-a-service.” ML algorithms will be empowered by machine learning algorithms to adapt ceaselessly depending on the data which developed over the web. Equipment merchants upgrade CPU capacity to encourage ML information handling and it’s a major surge in this procedure. Equipment sellers will be used to overhaul their machines in order to improve the forces of ML. Machine learning will help machines to comprehend setting and significance of data [9].
Quantum AI calculations have the capacity of changing the field of AI. For example, these calculations can utilize the upsides of quantum calculation to improve the capacities of old style techniques in AI. If quantum PCs are facilitated into AI, it could incite speedier planning of data, which could stimulate the ability to join information and draw bits of learning— and that is what’s coming up for us. Quantum-filled structures will give a much snappier and even more solid computation to both directed and solo figuring. The extended introduction will open shocking AI capacities, which probably won’t have been recognized using old style PCs.
Psychological administrations include a great deal of AI SDKs, APIs, and organizations, which empower designers to consolidate clever limits into their applications. With such administrations, designers can empower their applications to finish various commitments, for instance, vision affirmation, talk distinguishing proof, and talk understanding. As this development is continuing to propel, we are most likely going to watch the improvement of significantly keen applications that can logically talk, hear, see, and even reason with their condition. Subsequently, designers will more likely than not develop all the more enthralling and discoverable applications that can feasibly unravel customers’ needs established on trademark correspondence techniques.
AI calculations are used to offer proposals to customers and entice them to complete certain exercises. With such calculations, you can consolidate the information in a data and make reasonable conclusions, for instance, a person’s favorable circumstances.
Machine learning algorithms enable computers to understand the importance of information.
A prepared client of ML systems shares his bits of knowledge into the universe of ML, recommending that all these patterns are fast approaching in the domain of ML.
Utilization of Various Technologies in ML: The development of the Internet of things has profited machine learning from multiple points of view. The utilization of various mechanical techniques to accomplish better learning is as of now is in sync with machine learning algorithms; later on increasingly “shared learning” by using various innovations is obvious.
Customized Computing Environment: Developers will approach API packs to structure and convey “increasingly savvy application.” In a way, this exertion is much the same as “helped programming.” Through these API units, designers will effortlessly insert facial, discourse, or vision-acknowledgment highlights into their frameworks.
The processing speed of ML algorithms in higher-dimension vector handling will significantly be upgraded by quantum computing which will result in the victory in the domain of ML. Higher profit in business will occur with the progress of ML in future. ML-empowered administrations of things to come will turn out to be progressively precise and significant. For instance, the recommendation engines of things to come will be undeniably increasingly applicable and more like an individual client’s close to home inclinations and tastes. A fast gathering of the most striking innovation patterns for 2018 is the result of innovative machine learning trends. Gartner’s Top 10 Technology Trends of 2017 entireties up the all-plaguing computerized fever as the presence of individuals, machines, and business forms in a brought together framework.
The research and development in AI and ML lead to digital security which have taken ML algorithm to the following degree of realizing, which recommends that the security-driven ML use cases to come will be set apart for their speed and exactness. The entire research pattern is accessible in machine learning, artificial intelligence and the future of cyber security. Data scientists and digital security specialists may come closer because of this developing pattern to accomplish regular programming improvement.
Machine Learning algorithm may change the application-improvement markets of tomorrow because of which it is difficult to overlook the worldwide effect “man-made intelligence washing” in the present business market.
Toward the start of industrial revolution, simulated intelligence and ML have mutually been given a similar significance as the disclosure of power. These outskirts advances, much the same as power, have introduced another period in the historical backdrop of information technology.
Business and industry areas are controlled by ML framework. These advancements are step by step achieving transformative changes crosswise in different parts of industry.
Step by step, human specialists and machines will work together to convey improved results. Propelled machines will be relied upon to convey exact and auspicious discovery of patient conditions and the experts will be able to concentrate on more patients.
The most recent advancements like blockchain are affecting India’s capital markets and are examined by computer based intelligence and machine learning. Blockchain is utilized to anticipate developments in the market and to identify misrepresentation by capital showcase administrators. Man-made intelligence innovations not just give chances to more up to date plans of action in the money related market but also harden the AI technologist’s situation in the business-venture biological system. The tedious assignments in a normal DBA framework give chance to AI advancements to mechanize procedures and undertakings. The present DBA is engaged with cutting edge instruments.
1.7 Conclusion
The following are some imminent trends in machine learning field: Machine learning uses multiple technologies. Machine learning is benefitted by IOT in various ways. Multiple technologies help to achieve better learning. In this way we can achieve better “collaborative learning.” In personalized computing environment API kits are accessible by the developers to design and deliver exceptional “intelligent application.” Facial, speech, or vision-recognition features are embedded systems with intelligent API kits by developers. In high-dimensional vector processing the speed of execution of machine learning algorithms will be greatly enhanced by quantum computing and will be the next scope in the domain of ML research [10]. Higher business outcomes will be obtained using unsupervised machine learning algorithms. In the future, ML enabled services will become more accurate and relevant. Inside a significant number of programming bundles, machine learning and artificial intelligence (AI) and related advancements will be available crosswise over numerous enterprises, and will become part of our day by day lives by 2020.
Shockingly, however the guarantee of new income has pushed programming entrepreneurs to put resources into AI advancements, actually most associations don’t have talented staff to grasp AI. A certain note of caution in numerous industry reviews on machine learning and its effect on ventures is that product sellers should initially concentrate potential business profits by machine learning and understanding the business-client needs. In various capacities of tech-empowered arrangements many trust deficiencies that exist today will disappear in the next 10 years. Another strong purpose behind standard clients is that various AI fueled applications customers are confronting to defeat the trust obstruction after some time. The Citizen Data Science people group will prepare for another innovation request world with more presentation and more access to mechanical answers for their day by day business.
Competitive business agents can be created using AI and ML techniques while advances like the Cloud carry nimbleness to business procedures, and hence influence business results.
References
- 1. Alpaydin, E., Introduction to machine learning, pp. 200–300, MIT press, Cambridge, Massachusetts, 2009.
- 2. Harrell, F.E., Ordinal logistic regression, in: Regression modeling strategies, pp. 311–325, Springer Series in Statistics, Springer International Publishing, Switzerland, 2015.
- 3. Meyer, D. and Wien, F.T., Support vector machines. Interface Libsvm Package e1071, 28, pp. 1–8, 2015.
- 4. Liaw, A. and Wiener, M., Classification and regression by random Forest. R News, 2, 3, 18–22, 2002.
- 5. Jolliffe, I., Principal component analysis, pp. 1094–1096, Springer, Berlin, Heidelberg, 2011.
- 6. Guojon, G. and Michael., K.P., K-means clustering with outlier removal. Pattern Recognit. Lett., 90, 8–14, 2017.
- 7. Sapp, C.E., Preparing and architecting for machine learning. Gartner Tech. Prof. Adv., 1–37, 2017.
- 8. Kharde, V. and Sonawane, P., Sentiment analysis of twitter data: a survey of techniques. arXiv preprint arXiv:1601.06971, 139, 5–15, 2016.
- 9. S. Tanaka and M. Kori, Data acquisition device, data acquisition method and computer readable medium, U.S. Patent Application No.10289719., Washington, DC: U.S. Patent and Trademark Office, 2019.
- 10. Wang, W. and Siau, K., Artificial Intelligence, Machine Learning, Automation, Robotics, Future of Work and Future of Humanity: A Review and Research Agenda. J. Database Manage. (JDM), 30, 1, 61–79, 2019.
Note
- * Corresponding author: [email protected]