
2. Project Workflow
2.1 Introduction
This chapter focuses on the workflow of executing data science tasks as one-offs versus tasks that will eventually make up components in production systems. We’ll present a few diagrams of common workflows and propose combining two as a general approach. At the end of this chapter you should understand where they fit in an organization that uses data-driven analyses to fuel innovation. We’ll start by giving a little more context about team structure. Then, we’ll break down the workflow into several steps: planning, design/preprocessing, analysis, and action. These steps often blend together and are usually not formalized. At the end, you’ll have gone from the concept of a product, like a recommender system or a deep-dive analysis, to a working prototype or result.
At that stage, you’re ready to start working with engineers to have the system implemented in production. That might mean bringing an algorithm into a production setting automating a report, or something else.
We should say that as you get closer to feature development, your workflow can evolve to look more like an engineer’s workflow. Instead of prototyping in a Jupyter Notebook on your computer, you might prototype a model as a component of a microservice. This chapter is really aimed at getting a data scientist oriented with the steps that start them toward building prototypes for models.
When you’re prototyping data products, it’s important to keep in mind the broader context of the organization. The focus should be more on testing value propositions than on perfect architecture, clean code, and crisp software abstractions. Those things take time, and the world changes quickly. With that in mind, we spend the remainder of this chapter talking about the agile methodology and how data products should follow that methodology like any other piece of software.
2.2 The Data Team Context
When you’re faced with a problem that you might solve with machine learning, usually many options are available. You could make a fast, heuristic solution involving very little math that you could produce in a day and move on to the next project. You could take a smarter approach and probably achieve better performance. The cost is your time and the loss of opportunity to spend that time working on a different product. Finally, you could implement the state of the art.
That usually means you’d have to research the best approach before even beginning coding, implement algorithms from scratch, and potentially solve unsolved problems with how to scale the implementation.
When you’re working with limited resources, as you usually are in small organizations, the third option usually isn’t the best choice. If you want a high-quality and competitive product, the first option might not be the best either. Where you fall along the spectrum between the get-it-done and state-of-the-art approaches depends on the problem, the context, and the resources available. If you’re making a healthcare diagnosis system, the stakes are much higher than if you’re building a content recommendation system.
To understand why you’ll use machine learning at all, you need a little context for where and how it’s used. In this section, we’ll try to give you some understanding of how teams are structured, what some workflows might look like, and practical constraints on machine learning.
2.2.1 Embedding vs. Pooling Resources
In our experience, we’ve seen two models for data science teams. The first is a “pool of resources” where the team gets a request and someone on the team fulfills it. The second is for members of the team to “embed” with other teams in the organization to help them with their work.
In the first “pool of resources” approach, each request of the team gets assigned and triaged like with any project. Some member of the team executes it, and if they need help, they lean on someone else. A common feature of this approach is that tasks aren’t necessarily related, and it’s not formally decided that a single member of the team executes all the tasks in a certain domain or that a single member should handle all incoming requests from a particular person. It makes sense to have the same person answer the questions for the same stakeholders so they can develop more familiarity with the products and more rapport with the stakeholders. When teams are small, the same data scientist will tend to do this for many products, and there’s little specialization.
In the “embedded” approach, a data scientist works with some team in the organization each day, understanding the team’s needs and their particular goals. In this scenario, the understanding of problems and the approaches are clear as the data scientist is exposed to them day to day. This is probably the biggest contrast between the “embedded” and “pool of resources” approaches. Anecdotally, the former is more common than the latter in small organizations. Larger organizations tend to have more need and resources for the latter.
This chapter has a dual focus. First we’ll discuss the data science project life cycle in particular, and then we’ll cover the integration of the data science project cycle with a technical project life cycle.
2.2.2 Research
The steps to develop a project involving a machine learning component aren’t really different from those of an engineering project. Planning, design, development, integration, deployment, and post-deployment are still the steps of the product life cycle (see Figure 2.1).

Figure 2.1 The stages of a product’s life cycle
There are two major differences between a typical engineering product and one involving a data science component. The first is that with a data science component, there are commonly unknowns, especially in smaller teams or teams with less experience. This creates the need for a recursive workflow, where analysis can be done and redone.
The second major difference is that many if not most data science tasks are executed without the eventual goal of deployment to production. This creates a more abridged product life cycle (see Figure 2.2).

Figure 2.2 The independent life cycle of a data science task
The Field Guide to Data Science [1] explains that four steps comprise the procedure of data science tasks. Figure 2.2 shows our interpretation.
Here are the steps:
Build domain knowledge and collect data.
Preprocess the data. This involves cleaning out sources of error (e.g., removing outliers), as well as reformatting the data as needed.
Execute some analyses and draw conclusions. This is where models are applied and tested.
Do something with the result. Report it or refine the existing infrastructure.
2.2.3 Prototyping
The workflows we’ve outlined are useful for considering the process of data science tasks independently. These steps, while linear, seem in some ways to mirror the general steps to software prototyping as outlined in “Software Prototyping: Adoption, Practice and Management”[2]. Figure 2.3 shows our interpretation of these steps.

Figure 2.3 The life cycle of a software prototype
Planning: Assess project requirements.
Implementation: Build a prototype.
Evaluation: Determine whether the problem is solved.
Completion: If the needs are not satisfied, re-assess and incorporate new information.
2.2.4 A Combined Workflow
Sometimes these tasks are straightforward. When they take some time and investment, a more rigorous focus on process becomes crucial. We propose the typical data science track should be considered as being like a typical prototyping track for engineering projects. This is especially useful when the end goal is a component in a production system. In situations where data science influences engineering decisions or products that are brought to production, you can picture a combined product life cycle, as in Figure 2.4.
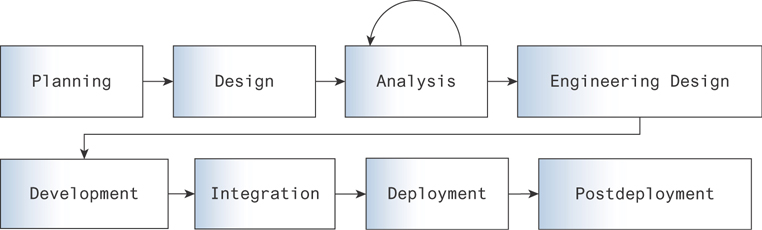
Figure 2.4 The combined product life cycle of an engineering project dependent on exploratory analysis
This approach allows data scientists to work with engineers in an initial planning and design phase, before the engineering team takes lessons learned to inform their own planning and design processes with technical/infrastructural considerations taken fully into account. It also allows data scientists to operate free of technical constraints and influences, which could otherwise slow progress and lead to premature optimization.
2.3 Agile Development and the Product Focus
Now that you understand how prototyping works and the product life cycle, we can build a richer context around product development. The end goal is to build a product that provides value to someone. That might be a product that performs a task, like translating langugages for travelers or recommending articles to read on your morning commute. It might be a product that monitors heart rates for patients after surgery or tracks people’s fitness as they work toward personal milestones. Common to each of these products is a value proposition.
When you’re building a new product, you have a value proposition in mind. The issue is that it’s likely untested. You might have good reason to believe that the proposition will be true: that users are willing to pay $1 for an app that will monitor their heart rate after surgery (or will tolerate some number of ads for a free app). You wouldn’t be building it in the first place if you didn’t believe in the value proposition. Unfortunately, things don’t always turn out how you expect. The whole purpose of AB tests is to test product changes in the real world and make sure reality aligns with our expectations. It’s the same with value propositions. You need to build the product to see whether the product is worth building.
To manage this paradox, we always start with a minimum viable product, or MVP. It’s minimal in the sense that it’s the simplest thing you can possibly build while still providing the value that you’re proposing providing. For the heart rate monitor example, it might be a heart rate monitor that attaches to a hardware device, alerts you when you’re outside of a target range, and then calls an ambulance if you don’t respond. This is a version of an app that can provide value in the extra security. Any more features (e.g., providing a fancy dashboard, tracking goals, etc.), and you’re going beyond just testing the basic value proposition. It takes time to develop features, and that is time you might invest in testing a different value proposition! You should do as little work as possible to test the value proposition and then decide whether to invest more resources in the product or shift focus to something different.
Some version of this will be true with every product you build. You can look at features of large products as their own products. Facebook’s Messenger app was originally part of the Facebook platform and was split into its own mobile app. That’s a case where a feature literally evolved into its own product. Everything you build should have this motivation behind it of being minimal. This can cause problems, and we have strategies to mitigate them. The cycle of software development is built around this philosophy, and you can see it in the concept of microservice architecture, as well as the “sprints” of the product development cycle. These leads us to the principles of the agile methodology.
2.3.1 The 12 Principles
The agile methodology is described with 12 principles [3].
1. Our highest priority is to satisfy the customer through early and continuous delivery of valuable software. The customer is the person you’re providing value to. That can be a consumer, or it can be the organization you’re working for. The reason you’d like to deliver software early is to test the value proposition by actually putting it in front of the user. The requirement that the software be “valuable” means you don’t work so fast that you fail to test your value proposition.
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage. This principle sounds counterintuitive. When requirements for software change, you have to throw away some of your work, go back to the planning phase to re-specify the work to be done, and then do the new work. That’s a lot of inefficiency! Consider the alternative: the customer needs have changed. The value proposition is no longer satisfied by the software requirements as they were originally planned. If you don’t adapt your software to the (unknown!) new requirements, the value proposition, as executed by your software, will fail to meet the customer’s needs. Clearly, it’s better to throw away some work than to throw away the whole product without testing the value proposition! Even better, if the competition isn’t keeping this “tight coupling” with their stakeholders (or customers), then your stakeholders are at a competitive advantage!
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale. There are a few reasons for this. One of them is for consistency with the last principle. You should deliver software often, so you can get frequent feedback from stakeholders. That will let you adjust your project plans at each step of its development and make sure you’re aligned with the stakeholders’ needs as well as you can be. The time when you deliver value is a great time to hear more about the customer’s needs and get ideas for new features. We don’t think we’ve ever been in a meeting where we put a new product or feature in front of someone and didn’t hear something along the lines of “You know, it would be amazing if it also did... .”
Another reason for this is that the world changes quickly. If you don’t deliver value quickly, your opportunity for providing that value can pass. You might be building a recommender system for an app and take so long with the prototype that the app is already being deprecated! More realistically, you might take so long that the organization’s priorities have shifted to other projects and you’ve lost support (from product managers, engineers, and others) for the system you were working on.
4. Businesspeople and developers must work together daily throughout the project. This principle is an extension of the previous two. Periodically meeting with the stakeholders isn’t the only time to connect the software development process with the context of the business. Developers should at least also be meeting with product managers to keep context with the business goals of their products. These managers, ideally, would be in their team check-ins each day, or at the least a few times per week. This makes sure that not only does the team building the software keep the context of what they’re working on, but the business knows where the software engineering and data resources (your and your team’s time) are being spent.
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done. One sure way to restrict teams from developing things quickly is to have them all coordinate their work through a single manager. Not only does that person have to keep track of everything everyone is working on, but they need to have the time to physically meet with all of them! This kind of development doesn’t scale. Typically, teams will be small enough to share a pizza and have one lead per team. The leads can communicate with each other in a decentralized way (although they do typically all communicate through management meetings), and you can scale the tech organization by just adding new similar teams.
Each person on a team has a role, and that lets the team function as a mostly autonomous unit. The product person keeps the business goals in perspective and helps coordinate with stakeholders. The engineering manager helps make sure the engineers are staying productive and does a lot of the project planning. The engineers write the code and participate in the project planning process. The data scientist answers questions for the product person and can have different roles (depending on seniority) with managing the product’s data sources, building machine learning and statistical tools for products, and helping figure out the presentation of data and statistics to stakeholders. In short, the team has everything they need to work quickly and efficiently together to get the job done. When external managers get too involved in the details of team’s operations, they can end up slowing them down just as easily as they can help.
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation. A lot of communication is done over chat clients, through shared documents, and through email. These media can make it hard to judge someone’s understanding of project requirements as well as their motivation, focus, and confidence for getting it done. Team morale can fluctuate throughout product development. People can tend to err on the side of agreeing to work that they aren’t sure they can execute. When teams communicate face to face, it’s much easier to notice these issues and handle them before they’re a problem.
As a further practical issue, when you communicate over digital media, there can be a lot of other windows, and even other conversations, going on. It can be hard to have a deep conversation with someone when you aren’t even sure if they’re paying attention!
7. Working software is the primary measure of progress. Your goal is to prove value propositions. If you follow the steps we’ve already outlined, then the software you’re building is satisfying stakeholders’ needs. You can do that without implementing the best software abstractions, cleaning up your code, fully documenting your code, and adding complete test coverage. In short, you can take as many shortcuts as you like (respecting the next principle), as long as your software works!
When things break, it’s important to take a retrospective. Always have a meeting to figure out why it happened but without placing blame on any individual. The whole team is responsible when things do or don’t work. Make whatever changes are necessary to make sure things don’t break in the future. That might mean setting a higher standard for test coverage, adding more documentation around certain types of code (like describing input data), or cleaning up your code just a little more.
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely. When you’re working fast, it’s easy for your code to end up messy. It’s easy to write big monolithic blocks of code instead of breaking it up into nice small functions with test coverage on each. It’s easy to write big services instead of microservices with clearly defined responsibilities. All of these things get you to a value proposition quickly and can be great if they’re done in the right context. All of them are also technical debt, which is something you need to fix later when you end up having to build new features onto the product.
When you have to change a monolithic block of code you’ve written, it can be really hard to read through all the logic. It’s even worse if you change teams and someone else has to read through it! It’s the type of problem that can slow progress to a halt if it isn’t kept in check. You should always notice when you’re taking shortcuts and consider at each week’s sprint whether you might fix some small piece of technical debt so it doesn’t build up too much. Remember that you’d like to keep up your pace of development indefinitely, and you want to keep delivering product features at the same rate. Your stakeholders will notice if they suddenly stop seeing you for a while! All of this brings us to the next point.
9. Continuous attention to technical excellence and good design enhances agility. When you have clear abstractions, code can be much more readable. When functions are short, clean, and well-documented, it’s easy for anyone to read and modify the code. This is true for software development as well as for data science. Data scientists in particular can be guilty of poor coding standards: one character variable names, large blocks of data preprocessing code with no documentation, and other bad practices. If you make a habit of writing good code, it won’t slow you down to do it! In fact, it’ll speed up the team as a whole.
10. Simplicity—the art of maximizing the amount of work not done—is essential. Writing a good MVP can be an art. How do you know exactly the features to write to test your value proposition? How do you know what software development best practices you can skip to keep a sustainable pace of development? Which architectural shortcuts can you get away with now and in the long term?
These are all skills you learn with practice and that your manager and team will be good resources for advice. If you’re not sure which product features really test the minimum value proposition, talk to your product manager and your stakeholders. If you’re not sure how sloppy your code can be, talk to a more senior data scientist, or even to an engineer on your team.
11. The best architectures, requirements, and designs emerge from self-organizing teams.
Some things are hard to understand unless you’re working with them directly. The team writing the software is going to have the best idea what architectural changes are going to work the best. This is partly because they know the architecture well and partly because they know their strengths and weaknesses for executing it. Teams communicate with each other and can collaborate without the input of other managers. They can build bigger systems that work together than they could on their own, and when several teams coordinate, they can architect fairly large and complex systems without a centralized architect guiding them.
12. At regular intervals, the team reflects on how to become more effective and then tunes and adjusts its behavior accordingly. While the focus is on delivering value quickly and often and working closely with stakeholders to do that, teams also have to be introspective occasionally to make sure they’re working as well as they can. This is often done once per week in a “retrospective” meeting, where the team will get together and talk about what went well during the past week, what didn’t work well, and what they’ll plan to change for the next week.
These are the 12 principles of agile development. They apply to data science as well as software. If someone ever proposes a big product loaded with features and says “Let’s build this!” you should think about how to do it agilely. Think about what the main value proposition is (chances are that it contains several). Next, think of the minimal version of it that lets you test the proposition. Build it, and see whether it works!
Often in data science, there are extra shortcuts you can take. You can use a worse-performing model while you work on a better one just to fill the gap that the engineers are building around. You can write big monolithic functions that return a model just by copying and pasting a prototype from a Jupyter Notebook. You can use CSV files instead of running database queries when you need static data sets. Get creative, but always think about what you’d need to do to build something right. That might be creating good abstractions around your models, replacing CSV files with database queries to get live data, or just writing cleaner code.
To summarize, there are four points to the Agile Manifesto. Importantly, these are tendencies. Real life is not usually dichotomous. These points really reflect our priorities:
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
2.4 Conclusion
Ideally now you have a good idea of what the development process looks like and where you fit in. We hope you’ll take the agile philosophy as a guide when building data products and will see the value in keeping a tight feedback loop with your stakeholders.
Now that you have the context for doing data science, let’s learn the skills!