
Appendix C
A Case Study on Machine Learning Application: Grouping Similar Service Requests and Classifying a New One
In the previous two appendices, we have discussed how R and Python can be used to create the machine learning algorithms. We also talked about different sets of libraries available for easy deployment of machine learning. With that perspective, let’s now see how machine learning is used in real life to solve a business problem, which otherwise would have taken significant manual effort.
C.1 BUSINESS CASE
In a telecom service center, the operators are responsible for providing the technical resolution to the problems that the customers face. Recently, due to huge surge in telecom user base, the service center of Newtel Infocomm is facing a huge challenge in dealing with the increase in service request volume. Newtel has two options – either it can increase the number of operators, thus increasing the operating cost substantially. Alternatively, it can explore if technology can help to solve the problem, without much additional cost, and thus help it remain profitable. The service center of Newtel engaged Global Tech (GT), a company known for providing state-of-the-art machine learning solutions to solve customer problems. After careful review of the problem and the underlying root cause, GT come up with a Machine Learning solution, briefly highlighted below.
C.2 SOLUTION APPROACH
GT observed that there are many service requests coming to Newtel service centers, which are repetitive in nature in terms of the type of problem. This was evident from the text of the service requests. Also, in most of the cases, there are some standard steps that the customer needs to follow to get the issue resolved. So, GT experts inferred, that buckets of service requests can be created through machine learning algorithm based on the past service requests. For each bucket, a set of corresponding standard resolutions can be associated. Whenever a new service request comes to Newtel service center, another machine learning algorithm should identify the bucket to which the new request should be tagged to, pull out the corresponding standard resolution, and send it to the customer. All these will happen without any human intervention. So, additional call volumes can be handled without any additional personnel in place. This will significantly reduce the additional manpower requirement leading to an impact on operating cost and profitability.
In the solution provided by GT, service requests in the repository were clustered using a combination of text analytics of select descriptive fields, time taken to resolve each request, and a user-selected categorical variable. The specific text analytics technique chosen was Word2Vector and the clustering technique was DBSCAN. For text classification to classify the new service request to one of the buckets created, Cosine Similarity algorithm was used. Let’s review the technical solution in some more details.
(I) Getting Python ready
Algorithm:
- Load required libraries of Python. These sets of libraries are needed to load data, perform computations and display output. Some of the important libraries are
- Pandas—Data analysis library
- numpy—array processing library in Python
- nltk.data and nltk.corpus—Natural language processing library
- import genism—for text analytics and clustering we will be converting word to vector. Word2vec function implemented by genism is useful here
- from gensim.models import word2vec
- from gensim.models.keyedvectors import KeyedVectors
- matplotlib.pyplot—To visualize the clusters
- from sklearn.cluster import DBSCAN—For clustering
- from sklearn.metrics.pairwise import cosine_similarity—To compute service request description similarity
Sample code snippet

(II) Data load
Algorithm:
Based on the source of data, like spreadsheet or csv dump of service requests or a direct access to service request database, load the data into the program in form of array of strings. The csv file containing the data set is available as online material for this book. The structure of the file is given below:

Code snippet

(III) Filtering for the assignment groups listed by the business users. This will ensure that the clusters are created as per business units.
Algorithm:
Identify the information from the data set that can help in making the data categorization or the clustering easy. In our example, we will use the service center’s assignment group or department as the driver for clustering. Below is some example of the assignment groups that can categorize the service requests.

Code snippet


(IV) Text analytics to create the training data for machine learning algorithm.
Algorithm:
- Create training data by averaging vectors for the words in the SR.
- Calculate the average feature vector for each one and return a 2D numpy array.
- This array set is now your training data for running the clustering.
Code snippet


(IV) Running the clustering
Algorithm:
DBSCAN algorithm is used for this clustering which will take the density-based clustering approach. The position of vectors created above are checked and the high-density areas are taken as a new cluster whereas clusters are separated by low-density areas.
Code snippet

The cluster that is generated as the result of DBSCAN is shown in Figure C.1. The estimated number of clusters: 14 and Silhouette Coefficient: 0.367

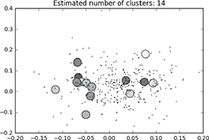
FIG. C.1 Clustering output
(V) New SR assigned to correct bucket – Cosine similarity function
Algorithm:
- Create the vector from the description text of the SR using word2vec function
- Calculate the similarity score for the vector using the cosine_similarity function
- Find the cluster the service request is assigned to, based on the max similarity score, averaged across all service requests in the cluster
- If no cluster is found matching this SR vector, then this SR is unlike any in the training repository and is not assigned to any cluster
Code snippet

C.3 OUTCOME
The service request processing of Newtel Infocomm has been automated now. GT has used machine learning technique to achieve the automation. As a part of the solution, the unlabeled service requests have been grouped into logical clusters using the DBSCAN algorithm. Also, whenever any new service request arrives, the cosine similarity algorithm finds out the relevant bucket for it so that some predefined, standard resolution can be sent automatically to the customer. There can be more such ways to solve this same business problem, as well as many scenarios which can be addressed through this same approach. So, look out for real-life business problems and think about automating the resolutions thorough intelligent use of machine learning.