
8.2 TCP and UDP as End User Transport Layer Protocols
In Chapter 3, user plane protocol stacks for the mobile network system were presented, showing how end user services are delivered. Due to its simplicity, versatility and efficiency, the TCP/IP protocol suite is now the dominant technology that is used by Internet based applications and services. The high data rate and low latency provided by the evolved radio access systems enable the migration of these services and applications to mobile environments; user traffic over the mobile backhaul is dominantly TCP/IP based.
Popular applications cover a wide range of services with specific QoS requirements such as voice (Skype™), web browsing, web-mail (Gmail™, Yahoo™ mail), instant messaging (MSN™, GoogleTalk™), social networking (Facebook™, MySpace™, LinkedIn™), image and video listing (Flickr™, Picasa™), micro-blogging (Twitter™), video sharing (Youtube™), on-line encyclopedia (Wikipedia™), virtual map and navigation (Google™ Maps), peer-to-peer (BitTorrent™), online gaming (WoW™), on-demand Internet streaming media (Netflix™), Internet radio, etc.
The TCP/IP protocol suite is a four-layer system consisting of the application (HTTP, FTP, e-mail, etc.), transport (TCP, UDP), network (IP, routing protocols, ICMP, etc.) and link layers (Ethernet, etc.). The role of the transport layer is to provide transport service to the application layer above, i.e., a flow of data between two equipments (UEs, UEs and servers, etc.). The two dominant transport layer protocols, TCP and UDP are specialized to serve two distinct, well defined sets of applications. TCP, which provides a reliable connection oriented service (despite the fact the IP protocol as such is unreliable) is used by data applications such as FTP, HTTP, e-mail, etc., requiring error free delivery of the whole data sent from one terminal to the other, whereas UDP, which transfers the data from one end to the other without any guarantee regarding reliable delivery is well suited for real time applications such as VoIP and VoD or for gaming and supporting short queries such as DNS lookup at web page download.
8.2.1 UDP
The UDP protocol provides a simple, connectionless, datagram based, unreliable transport service. UDP packets are referred to as datagrams. The UDP layer sends the data generated and handed over by the application without further delay and without any guarantee that the data will ever reach its destination or that the delivery of datagrams will be in order. The UDP header (refer to Figure 4.21 in Chapter 4) carries the source and destination port numbers, a checksum and information on the length of the UDP datagram. Based on the source and destination port numbers, the receiver is able to de-multiplex the incoming UDP datagrams and to deliver them to the corresponding application.
Data transfer over UDP does not require connection setup at the transport layer; however, the application is allowed to set up a connection for transferring data, for example VoIP is UDP based, where the connection set-up is done by specialized protocols such as SIP. UDP also allows point-to-multipoint communication. These characteristics of the UDP protocol make it suitable for real time applications (VoIP, VoD, etc.) where the timely delivery of data is more important than error free communication and over-delayed packets are dropped.
Another common use of UDP is when short queries are issued to network servers (for example DNS lookup).
8.2.2 TCP
TCP offers a connection oriented, point-to-point, full-duplex and reliable service for data transfer over the Internet or over any IP based network that is by nature an unreliable media. The data sent in one packet is always referred to as segment. Before data transfer, the TCP connection must be established with the connection set up protocol (three-way handshake, see Figure 8.4), whereas after all the data has been transferred the connection has to be closed separately with the connection termination protocol.
Figure 8.4 Client originated TCP connection set-up: three-way handshake.

During the three-way handshake, the two endpoints involved in the communication exchange information about the port numbers through which the communication will be performed, the initial sequence number (required for the reliable communication), the advertised window size that indicates the amount of data the endpoints can receive (this prevents buffer overrun) and the maximum segment size (MSS)-included as an option field to the TCP header – that an endpoint will be able to send/receive (required to define the best size for the TCP segments).
The header of each TCP segment contains the source and destination port numbers that identify the sending and receiving application. (The header is illustrated in Figure 4.23 in Chapter 4). These port numbers together with the source and destination IP addresses in the IP header of the packet carrying the TCP segment uniquely identify the TCP connection, which is referred to as a socket in the networking API. The connection is full-duplex as both endpoints can send and receive data.
Sequence numbering is used to facilitate in order delivery of segments, to identify duplicate reception of the same data and is used as a reference when correctly received data is acknowledged. Each TCP segment is sent with a sequence number. Acknowledgements are sent only for correctly received data; the source is not explicitly notified about missing or erroneously received data. Data is retransmitted if it is not acknowledged in time or is considered to be lost based on the received acknowledgements. With an acknowledgement, all the correctly received data up to the missing TCP segment is acknowledged (cumulative acknowledgement). TCP has efficient congestion control mechanisms that operate based on the assumption that packet losses are always due to congestion as in wired networks it is very unlikely that a packet is discarded due to bit errors. However, this assumption is not valid in case of the WCDMA or LTE air interface.
8.2.3 TCP Congestion Control
The first TCP implementations had no congestion control mechanisms until it was recognized that this would cause congestion collapse or sustained overload with a high packet drop ratio. Therefore, the first congestion control algorithm, referred to as Tahoe, was introduced in 1988 [4].
Nowadays, the TCP congestion control algorithm is the dominant end-to-end mechanism to control congestion on the Internet. The main scope of the TCP congestion control [5] is to apply efficient techniques whenever packet loss is detected or assumed in order to allow the system to recover and at the same time to guarantee efficient resource usage and data transfer.
There are several TCP versions that differ by the applied congestion control mechanisms. The most common version is TCP New Reno [6] that has the following congestion control elements: the Congestion Window (cwnd), the Additive Increase and Multiplicative Decrease (AIMD) mechanism that controls the value of the cwnd (i.e., the maximum amount of in-transit data in octets between the two endpoints) and the Slow-Start, Congestion Avoidance, Fast Retransmit and Fast Recovery algorithms. These mechanisms are those that the source can use in order to provide reliable and efficient data transfer.
An established TCP connection starts sending data in Slow-Start mode: the sender initiates the data transfer by setting the size of the cwnd to the MSS and sending the first segment. The size of the cwnd is increased by one MSS each time the reception of a segment is acknowledged by the receiver. This means that during the Slow-Start, the size of the cwnd is doubled every round trip time, i.e., its increase is exponential, as illustrated in Figure 8.5. The amount of data the sender is allowed to transmit is limited by the minimum of the cwnd and the advertised window.
Figure 8.5 Example of Slow-Start.

The exponential increase is continued until a predefined threshold (the slow-start threshold) is reached, a loss is detected or timeout occurs. When the slow-start threshold is reached, the TCP connection enters Congestion Avoidance mode. In this mode, the cwnd is increased additively with one MSS per each round trip time which is a much less aggressive increase mechanism than the one used during Slow-Start. The increase of the cwnd is continued until packet loss is detected. The receiver acknowledges the correctly received data with acknowledgements (ACKs) containing the sequence number of the TCP segment it is expecting to receive next.
In case of a loss, the receiver will be able to send an ACK only if a consecutive segment is correctly received. If that happens, the receiver notifies the source about the missing segment by sending an ACK with the sequence number of the first missing segment. This ACK is referred to as a duplicate ACK as it acknowledges the same segment as the ACK sent as a response to the last correctly received segment. Duplicate ACKs are sent without delay in order to assist the proper operation of the source.
Loss is detected by the sender when it receives multiple duplicate ACKs (ACKs with the same sequence number). A packet is considered to be lost when three duplicate ACKs are received, i.e., four consecutive ACKs acknowledging the same data. Upon this event, the packet that is considered to be lost (the one with the sequence number indicated by the duplicate ACKs) is retransmitted immediately. This procedure is called Fast Retransmit and depicted in Figure 8.6.
Figure 8.6 Triple duplicate ACKs followed by Fast Retransmit.
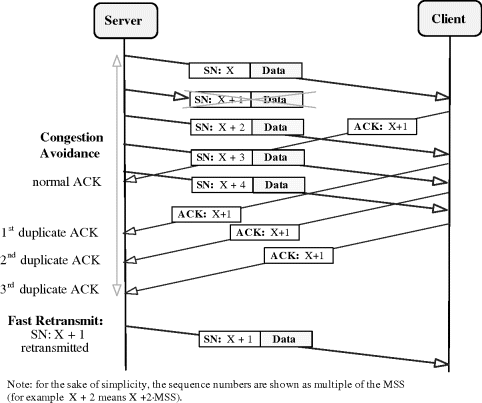
After the Fast Retransmit, the sender enters Fast Recovery state. Not executing the retransmission immediately after the first duplicate ACK helps the system avoid retransmission due to reordering of TCP segments. Triple duplicate ACKs indicate to the source (in addition to the fact that one segment is possibly lost) that the connection can still transfer data, therefore there is no point in drastically reducing the rate of the connection. Accordingly, at Fast Recovery, the slow-start threshold is set to one half of the minimum of the current value of the cwnd and the receiver's advertised window and then the cwnd is set to the slow-start threshold plus three times the maximum segment size (this is called window inflation). The cwnd is incremented by one segment after the reception of each duplicate ACK and if the value of the cwnd (and advertised window) allows, a new segment is transmitted. The connection stays in Fast Recovery state until an ACK acknowledging all previously unacknowledged segments is received. Upon the reception of this ACK, the connection enters Congestion Avoidance mode with cwnd reset to the slow-start threshold (this is called window deflation). In case of a partial acknowledgement (i.e., when only part of the segments sent before entering into Fast Recovery are acknowledged), the first unacknowledged segment is retransmitted.
Figure 8.7 Schematic diagram of the window growth function of CUBIC.
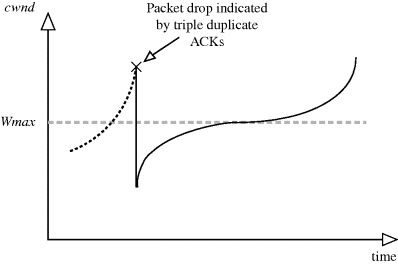
Figure 8.8 Classifier/conditioner [20].

For each segment sent, the sender maintains an associated retransmission timeout timer (RTO) which defines the time when an ACK is expected from the receiver. The value of the timer is estimated based on the round trip time measurements. In case a timeout occurs, i.e., no ACK is received before the timer expires, the segment is retransmitted; the slow-start threshold is set to the maximum of the following two values: two times the MSS and half of the actual cwnd value; the cwnd is set to MSS; the RTO timer value is doubled and the TCP connection enters Slow-Start. After each unsuccessful attempt to transmit the segment, the RTO timer value is doubled until it reaches 64 seconds. This procedure is referred to as exponential backoff.
As discussed, the first TCP version with congestion control was TCP Tahoe that incorporates the Slow-Start, Congestion Avoidance and Fast Retransmit mechanisms. When triple duplicate ACKs are received, the source retransmits the missing segment, sets its cwnd to one MSS and enters Slow-Start. This is not efficient in case of a transient packet loss as the rate of the source is unnecessarily reduced.
TCP Reno implements a simpler version of the Fast Recovery algorithm where after three duplicate ACKs the missing segment is retransmitted. The source will leave the Fast Recovery state when an ACK acknowledging new data is received, i.e., TCP Reno is able to retransmit only one missing segment per round trip time as the exit criteria does not mandate the reception of a full acknowledgement (i.e., for each segment sent before entering into Fast Retransmit/Fast Recovery). In case only one segment was lost, the new ACK will acknowledge the whole amount of data, whereas in case of multiple losses some but not all the segments are acknowledged. This is called partial acknowledgement.
TCP CUBIC [7] is the default congestion control algorithm of the TCP stack used in Linux and Android kernels. It was introduced in order to handle the TCP efficiency problem observed in case of high speed long distance networks. These networks have large bandwidth delay product which determine the required amount of in-transit packets between the source and destination in order to achieve high utilization of resources.
The cwnd of the TCP versions with additive increase during congestion avoidance, e.g., after a congestion event, is not able to reach this value fast enough. Some connections last for a shorter time than the time that would be required to reach the bandwidth delay product. TCP CUBIC solves this problem by replacing the linear growth function with a cubic function. When a loss is detected, the regular Fast Retransmit, Fast Recovery mechanisms are executed; the cwnd is reduced by a factor (with default value of 0.2); the window size before loss is recorded. This window size (Wmax) is considered to be the saturation point. As shown in Figure 8.7, until Wmax is reached, the cwnd growth is according to the concave portion of the cubic function that has its plateau at Wmax. The concave growth is followed by a convex increase after Wmax is reached. This growth function ensures that the saturation point is reached in a short time, the cwnd is kept almost constant around Wmax and finally that the cwnd is carefully increased in case no loss is detected. The cwnd growth depends on the elapsed time (t) from the last congestion control event (i.e., a Fast Recovery), this promotes fairness among competing connections as each can have approximately the same cwnd size even in case of different round trip times. The algorithm estimates the window size that TCP Reno would reach within the elapsed time (t) and sets cwnd to this value in case this is above the one calculated with the cubic function. This is the TCP friendly region of the CUBIC algorithm.
Compound TCP [10] is a congestion control algorithm developed for Windows (since Vista and Server 2008). It maintains a special cwnd that consists of two components: one that is increased in the same way as in TCP Reno and a delay based window that is increased when the network is underutilized, i.e., the delay is small, and decreased when the experienced delay grows, i.e., when congestion builds up. The algorithm tries to maintain the value of the cwnd (i.e., the sum of the two components) constant as much as possible.
The TCP congestion control mechanism has several limitations such as the reliance on packet loss in order to detect congestion, the inaccuracy of the delay or round trip time estimation and their inability to distinguish between possible reasons for packet drops. The latter triggers unnecessary congestion control actions when a drop is not due to congestion, which happens in wireless environments when a packet is dropped due to bit errors, mobility, etc. This deteriorates the performance of TCP over mobile networks as discussed in detail in the next section.
In order to allow the congestion control algorithm to take actions before a packet drop, i.e., to slow down the transmission rate before the network nodes are forced to drop packets, the Explicit Congestion Notification (ECN, RFC 3168) was introduced. The ECN mechanism sets notification bits in the IP header when congestion is detected, a solution that enables the two endpoints to reduce the rate of the connection.
One possibility to improve the delay and round trip time measurement is to apply the TCP timestamp option (RFC1323) by attaching a timestamp to each TCP segment. Based on the timestamp, the source can have an accurate round trip time measurement and RTO timer value estimation.
8.2.4 TCP Over Wireless
The various TCP versions discussed so far are all based on the assumption that bit errors and thus data discards due to erroneous receptions are extremely rare and the reason for packet loss is always network congestion. In mobile environments, the requirement of efficient TCP operation raises several issues as packet losses are frequently caused by bit errors occurring on the air interface. As the TCP source is not able to differentiate between the packet losses caused by bit errors and those caused by congestion, it will erroneously reduce the rate of the connection in case of bit errors too as if there was congestion. The solutions described in this section are examples from a wide range of proposals regarding TCP optimization. In practice, this type of proposals would need to be supported in the TCP/IP stack of the terminal and also commonly in TCP/IP SW on the servers, etc (depending on the proposal in question).
The fact that TCP was developed and optimized for transmission over wired links can become a serious issue whenever TCP based traffic is transmitted over wireless links. UMTS and LTE radio layer features such as Automatic Repeat-reQuest (ARQ) and Hybrid ARQ (HARQ) have been introduced in order to handle air interface errors via retransmission of the missing data. Air interface imperfections are not the only sources of packet loss as the radio conditions are changing due to user mobility: handovers, sudden coverage holes (transient coverage problems) and network asymmetry (in LTE, UL coverage might disappear near cell edges while DL coverage still exists) might result in packet loss as well.
In addition to packet loss caused by air interface problems and mobility, TCP might experience performance degradation due to unpredictable delays, i.e., sudden change of the TCP round trip time: due to the forwarding of TCP segments over X2 (LTE), ARQ and HARQ retransmissions or due to different circumstances (longer transmission path, larger buffer, higher load) after a successful handover. TCP retransmissions can be triggered by out of sequence delivery of data in case of handovers and network asymmetry. In these cases, the efficiency of data transfer is limited, the RTO timer of the TCP might expire, triggering TCP slow start that will result in long recovery times (the recovery time is the time required to reach the throughput experienced before the problem occurred) for the TCP sources.
The limited battery capacity of the mobile devices requires efficient data transfer in wireless environments that currently TCP is not able to provide. TCP efficiency is a major issue also from a resource usage point of view as the air interface and the microwave links are scarce resources compared to the high capacity wired links.
The TCP efficiency problem over the radio interface has resulted in a multitude of candidate solutions. One possible classification divides them into two groups: network supported solutions and end-to-end solutions. Network supported solutions require extra functionality at the network side whereas the end-to-end solutions are transparent to the underlying network.
Network side solutions (Snooping Protocols, Split TCP solutions, etc.) are based on the idea of implementing extra functionalities at given network nodes. The functionality intercepts the TCP segments of a given connection and performs actions with them on behalf of the receiver in order to prevent congestion control actions whenever packet loss is not due to congestion. These solutions may benefit from the immediate information about the air interface imperfections, therefore their ideal location is at the eNBs (LTE) or RNCs (WCDMA/HSPA). In case of handovers, the information on the status of the intercepted connection must be exchanged between the involved nodes that might result in increased handover latency especially in case of LTE, a fact that justifies the placement of the extra functionality in the gateway nodes.
Snooping protocols hide the air interface from the transport (TCP) layer without violating the end-to-end semantics of the connection.
In case of the Snoop Protocol [11], the packets of the connection are intercepted, copied by the Snoop module (located at the eNB or RNC). Copies of the packets are stored until an acknowledgement is received. Triple duplicate ACKs are discarded followed by a retransmission of the missing segment. WTCP [12] improves the Snoop Protocol by measuring the round trip time over the air interface with the help of the TCP timestamp option. This measurement is used to manipulate the sender in such a way that retransmission timeouts are avoided.
TCP SACK-Aware Snoop Protocol [13] uses the functionality provided by the TCP SACK (selective acknowledgement) (RFC2018) option. SACK reduces the amount of the retransmitted data as the receiver can inform the source in case non-continuous blocks of segments have been received. The Snoop module retransmits the missing segments indicated by the duplicate ACKs or the blocks of missing segments indicated by the selective ACKs.
Split TCP solutions divide the TCP connection into two (or more) separate connections. The node at which the connection is split, i.e., the interfacing node is referred to as the proxy. Packets are intercepted, buffered and acknowledged to the source by the proxy. The simplest solution is to create two TCP connections (Indirect-TCP [15]) in order to isolate the air interface and to handle the air interface problems with a shorter TCP connection.
A more sophisticated solution is to use Radio Network Feedback containing information on the instantaneous channel quality or available bandwidth when the window size of the connection between the proxy and the UE is calculated [16].
Instead of requiring and relying on extra functionalities at the network equipments, end-to-end solutions require specialized mechanisms at the sender and receiver that are able to handle both congestion and air interface error caused packet losses. This approach maintains the end-to-end semantics of the connection.
The negative impact on the connection performance caused by handovers, i.e., the timeouts due to temporary disconnection is handled by the Freeze TCP [17] by enabling the UE to send a zero window advertisement (ZWA) to the sender before the handover is executed. Upon receiving the ZWA, the sender enters in persist mode and stops sending data to the receiver. The data transfer is resumed when upon reconnection, the UE sends a non zero window advertisement to the sender. This mechanism prevents timeouts and cwnd shrinkage due to handovers and allows the sender to continue the data transfer with the cwnd value it had before handover.
TCP-Westwood [18] proposes a sender side enhancement that allows the estimation of the available bandwidth by monitoring the rate of the ACKs. Congestion window and slow start threshold are set to this value when the sender recalculates them as a result of a detected congestion event (triple duplicate ACKs or timeout).