
In the previous eight chapters, you learned critical programming details about AVX, AVX2, and AVX-512. You also discovered how to create SIMD calculating functions that exploited the computational resources of these x86 instruction set extensions. This chapter focuses on supplemental x86 C++ SIMD programming topics. It begins with a source code example that demonstrates utilization of the cpuid instruction and how to exercise this instruction to detect x86 instruction set extensions such as AVX, AVX2, and AVX-512. This is followed by a section that explains how to use SIMD versions of common C++ math library routines.
Using CPUID
It has been mentioned several times already in this book, but it bears repeating one more time: a program should never assume that a specific instruction set extension such as FMA, AVX, AVX2, or AVX-512 is available on its host processor. To ensure software compatibility with both current and future x86 processors, a program should always use the x86 cpuid instruction (or an equivalent C++ intrinsic function) to verify that any required x86 instruction set extensions are available. An application program will crash or be terminated by the host operating system if it attempts to execute a nonsupported x86-AVX instruction. Besides x86 instruction set extensions, the cpuid instruction can also be directed to obtain supplemental feature information about a processor. The focus of this section is the use of cpuid to detect the presence of x86 instruction set extensions and a few basic processor features. If you are interested in learning how to use cpuid to detect other processor features, you should consult the AMD and Intel programming reference manuals listed in Appendix B.
Example Ch09_01
Before examining the source code in Listing 9-1, a few words regarding x86 registers and cpuid instruction usage are necessary. A register is a storage area within a processor that contains data. Most x86 processor instructions carry out their operations using one or more registers as operands. A register can also be used to temporarily store an intermediate result instead of saving it to memory. The cpuid instruction uses four 32-bit wide x86 registers named EAX, EBX, ECX, and EDX to query and return processor feature information. You will learn more about x86 processor registers in Chapter 10.
Prior to using the cpuid instruction, the calling function must load a “leaf” value into the processor’s EAX register. The leaf value specifies what information the cpuid instruction should return. The function may also need to load a “sub-leaf” value into register ECX before using cpuid. The cpuid instruction returns its results in registers EAX, EBX, ECX, and EDX. The calling function must then decipher the values in these registers to ascertain processor feature or instruction set availability. It is often necessary for a program to use cpuid multiple times. Most programs typically exercise the cpuid instruction during initialization and save the results for later use. The reason for this is that cpuid is a serializing instruction. A serializing instruction forces the processor to finish executing all previously fetched instructions and perform any pending memory writes before fetching the next instruction. In other words, it takes the processor a long time to execute a cpuid instruction.
Listing 9-1 begins with the definition of a simple C++ structure named CpuidRegs , which is located in file Cpuid__.h. This structure contains four uint32_t members named EAX, EBX, ECX, and EDX. Source code example Ch09_01 uses the CpuidRegs structure to hold cpuid instruction leaf and sub-leaf values. It also uses CpuidRegs to obtain and process the information returned from cpuid.
The next file in Listing 9-1 is named Cpuid__.cpp. The first function in this file, Cpuid__(), is a wrapper function that hides implementation differences between Windows and Linux. This function uses C++ compiler preprocessor definitions to select which cpuid intrinsic function, __cpuidex (Windows) or __get_cpuid_count (Linux), to use. The other function in Cpuid__.cpp is named Xgetbv__() . This is a wrapper function for the x86 xgetbv (Get Value of Extended Control Register) instruction. Function Xgetbv__() obtains state information from the processor that indicates whether the host operating system has enabled support for AVX, AVX2, or AVX-512.
Following Cpuid__.cpp in Listing 9-1 is a file named CpuidInfo.h. This file contains the declaration of class CpuidInfo. Class CpuidInfo begins with the declaration of a subclass named CacheInfo. As implied by its name, CpuidInfo::CacheInfo includes a public interface that provides information about the processor’s on-chip memory caches. Following the declaration of CpuidInfo::CacheInfo are the private data values for class CpuidInfo. These values maintain the data that is returned by various executions of the cpuid instruction.
Class CpuidInfo also includes a public interface that a program can use to obtain information returned by the cpuid instruction. The type CpuidInfo::FF defines symbolic names for x86 instruction set extensions that are commonly used in application programs. Note that the public function CpuidInfo::GetFF() requires a single argument value of type CpuidInfo::FF. This function returns a bool value that signifies whether the host processor (and host operating system) supports the specified instruction set extension. Class CpuidInfo also includes other useful public member functions. The functions CpuidInfo::GetProcessorBrand() and CpuidInfo::GetProcessorVendor() return text strings that report processor brand and vendor information. The member function CpuidInfo::GetCacheInfo() obtains information about the processor’s memory caches. Finally, the member function CpuidInfo::LoadInfo() performs one-time data initialization tasks. Calling this function triggers multiple executions of the cpuid instruction.
The next file in Listing 9-1 is Ch09_01.cpp. The code in this file demonstrates how to properly use class CpuidInfo. Function main() begins with the instantiation of a CpuidInfo object named ci. The ci.LoadInfo() call that follows initializes the private data members of ci. Note that CpuidInfo::LoadInfo() must be called prior to calling any other public member functions of class CpuidInfo. A program typically requires only one CpuidInfo instance, but multiple instances can be created. Following the ci.LoadInfo() call, function main() calls DisplayProcessorInfo(), DisplayCacheInfo(), and DisplayFeatureFlags(). These functions stream processor feature information obtained during the execution of CpuidInfo::LoadInfo() to std::cout.
The final file in Listing 9-1 is CpuidInfo.cpp. Near the top of this file is the definition of member function CpuidInfo::LoadInfo(). Recall that function main() calls CpuidInfo::LoadInfo() to initialize the private members of CpuidInfo instance ci. During its execution, CpuidInfo::LoadInfo() calls six private member functions named CpuidInfo::LoadInfo0() – CpuidInfo::LoadInfo5(). These functions exercise the previously described functions Cpuid__() and Xgetbv__() to determine processor support for the various x86 instruction set extensions enumerated by CpuidInfo::FF. Listing 9-1 only shows the source code for CpuidInfo::LoadInfo4(), which ascertains processor support for FMA, AVX, AVX2, AVX-512, and several other recent x86 instruction set extensions. Due to their length, the source code for the five other CpuidInfo::LoadInfoX() functions is not shown in Listing 9-1, but this code is included in the download software package.
Function CpuidInfo::LoadInfo4() begins its execution with three calls to Cpuid__(). Note that Cpuid__() requires three arguments: a leaf value, a sub-leaf value, and a pointer to a CpuidRegs structure. The specific leaf and sub-leaf values employed here direct Cpuid__() to obtain status flags that facilitate detection of x86-AVX instruction set extensions. The AMD and Intel programming reference manuals contain additional details regarding permissible cpuid instruction leaf and sub-leaf values.
Following execution of the three Cpuid__() calls, CpuidInfo::LoadInfo4() determines if the host operating system allows an application program to use the xgetbv instruction (or _xgetbv() intrinsic function), which is used in Xgetbv__(). Function Xgetbv__() sets status flags in xgetbv_eax that indicate whether the host operating system has enabled the internal processor states necessary for AVX and AVX2. If m_OsAvxState is true, function CpuidInfo::LoadInfo4() initiates a series of brute-force flag checks that test for AVX, AVX2, FMA, and several other x86 instruction set extensions. Note that each successful test sets a status flag in CpuidInfo::m_FeatureFlags to indicate availability of a specific x86 instruction set extension. These flags are the same ones returned by CpuidInfo::GetFF().
Source code example Ch09_01 illustrates how to code a comprehensive x86 instruction set extension detection class. Code fragments from this example can be extracted to create a streamlined x86 instruction set detection class with fewer detection capabilities (e.g., only AVX, AVX2, and FMA). Finally, it should also be noted that many AVX-512 instructions (and their corresponding C++ SIMD intrinsic functions) can only be used if the host processor supports multiple AVX-512 instruction set extensions. For example, the AVX-512 C++ SIMD intrinsic function _mm256_mask_sub_epi16() will only execute on a processor that supports AVX512F, AVX512BW, and AVX512VL. One programming strategy to overcome the inconvenience of having to test multiple AVX-512 instruction set extensions is to create a single application-level status flag that logically ANDs any required AVX-512 instruction-set-extension status flags into a single Boolean variable. The Intel programming reference manuals listed in Appendix B contain additional information about this topic. Appendix B also contains a list of open-source libraries that you can use to determine x86 processor instruction set availability.
Short Vector Math Library
Many numerically oriented algorithms use standard C++ math library routines such as exp(), log(), log10(), pow(), sin(), cos(), and tan(). These functions carry out their calculations using scalar single-precision or double-precision floating-point values. The Short Vector Math Library (SVML), originally developed by Intel for their C/C++ compilers, contains SIMD versions of most standard C++ math library routines. SVML functions can also be used in application programs that are developed using Visual Studio 2019 or later. In this section, you will learn how to code some SIMD calculating functions that exploit SVML. The first example demonstrates converting an array of rectangular coordinates into polar coordinates. This is followed by an example that calculates body surface areas using arrays of patient heights and weights.
Rectangular to Polar Coordinates

Specification of a point using rectangular and polar coordinates

![$$ heta = atan2left(frac{y}{x}
ight) mathrm{where} heta =left[-pi, pi
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484279182/9781484279182__9781484279182__files__images__519226_1_En_9_Chapter__519226_1_En_9_Chapter_TeX_Equb.png)
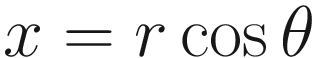

Example Ch09_02
Listing 9-2 starts with the file Ch09_02.h. Note that the function declarations in this file use arguments of type std::vector<float> for the various coordinate arrays. The next file in Listing 9-2, Ch09_02_misc.cpp, contains assorted functions that perform argument checking and vector initialization. Also shown in Listing 9-2 is the file Ch09_02.cpp. This file contains a function named ConvertRectToPolar(), which performs test case initialization. Function ConvertRectToPolar() also exercises the SIMD rectangular to polar coordinate conversion function and streams results to std::cout. The polar to rectangular counterpart of function ConvertRectToPolar() is named ConvertPolarToRect() and is also located in file Ch09_02.cpp.
The next file in Listing 9-2, SimdMath.h, defines several inline functions that perform common math operations using SIMD arguments of type __m256 or __m256d. Note that this file includes preprocessor definitions that enable different code blocks for Visual C++ and GNU C++. The Visual C++ sections emit SVML library function calls since these are directly supported in Visual Studio 2019 and later. The GNU C++ sections substitute simple for-loops for the SVML functions since SVML is not directly supported. If you are interested in using SVML with GNU C++ and Linux, you should consult the Intel C++ compiler and GNU C++ compiler references listed in Appendix B.
The final file in Listing 9-2, Ch09_02_fcpp.cpp, begins with the definitions of functions ConvertRectToPolarF32_Cpp() and ConvertPolarToRectF32_Cpp(). These functions perform rectangular to polar and polar to rectangular coordinate conversions using standard C++ statements and math library functions. The next function, ConvertRectToPolarF32_Iavx(), performs rectangular to polar coordinate conversions using AVX and C++ SIMD intrinsic functions. Following argument validation, ConvertRectToPolarF32_Iavx() employs _mm256_set1_ps() to create a packed version of the constant 180.0 / M_PI for radian to degree conversions. The first for-loop in ConvertRectToPolarF32_Iavx() uses C++ SIMD intrinsic functions that you have already seen. Note the use of atan2_f32x8(), which is defined in SimdMath.h. This function calculates eight polar coordinate angle components. The second for-loop in ConvertRectToPolarF32_Iavx() process any residual coordinates using standard C++ math library functions.
Body Surface Area
Body Surface Area Equations
Method | Equation |
|---|---|
DuBois and DuBois | BSA = 0.007184 × H0.725 × W0.425 |
Gehan and George | BSA = 0.0235 × H0.42246 × W0.51456 |
Mosteller |
|
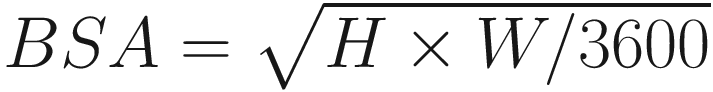
Example Ch09_03
The first file in Listing 9-1, Ch09_03.h, includes the requisite function declarations for this example. Note that the BSA calculating functions require arrays of type std::vector<double> for the heights, weights, and BSAs. File Ch09_03_misc.cpp contains functions that validate arguments and initialize test data vectors. In function CheckArgs(), note that the size of array bsa must be three times the size of array ht since the results for all three BSA equations are saved in bsa. The function CalcBSA(), located in file Ch09_03.cpp, allocates the test data vectors, invokes the BSA calculating functions, and displays results.
BSA Execution Times (Microseconds), 200,000 Heights and Weights
CPU | CalcBSA_F64_Cpp() | CalcBSA_F64_Iavx() |
|---|---|---|
Intel Core i7-8700K | 19628 | 3173 |
Intel Core i5-11600K | 13347 | 2409 |
Summary
In this chapter, you learned how to exercise the cpuid instruction to ascertain availability of x86 processor extensions such as AVX, AVX2, and AVX-512. The AMD and Intel programming reference manuals listed in Appendix B contain additional information regarding proper use of the cpuid instruction. You are strongly encouraged to consult these guides before using the cpuid instruction (or an equivalent C++ intrinsic function) in your own programs.
The SVML includes hundreds of functions that implement SIMD versions of common C++ math library routines. It also includes dozens of other useful SIMD functions. You can obtain more information about SVML at https://software.intel.com/sites/landingpage/IntrinsicsGuide/#!=undefined&techs=SVML.