
The previous chapter demonstrated how to use a variety of C++ SIMD intrinsic functions to implement algorithms that performed calculations using floating-point arrays and matrices. In this chapter, you will learn how to implement some common signal processing and image processing methods using SIMD arithmetic. The chapter begins with a brief primer section that discusses signal processing fundamentals and the mathematics of convolutions. This is followed by a section that explains how to implement a 1D discrete convolution using C++ SIMD intrinsic functions. Chapter 6 concludes with an exploration of image processing algorithms that exploit 2D discrete convolutions and SIMD techniques.
Chapter 6 accentuates a specific application domain where appropriate use of AVX2 and SIMD programming techniques significantly accelerates algorithm performance. The topics and source code examples presented in this chapter are slightly more specialized and perhaps a bit more complicated than those discussed in previous chapters. If your SIMD programming interests reside elsewhere, you can either skim this chapter or skip ahead to the next one.
Convolution Primer
A convolution is a mathematical operation that blends an input signal with a response signal to produce an output signal. Convolutions are used extensively in a wide variety of scientific and engineering applications. Many signal processing and image processing methods are founded on convolution theory. In this section, you will learn the essentials of convolution mathematics. The purpose of this section is to provide just enough background math to understand this chapter’s source code examples. Numerous books have been published that explain convolution, signal processing, and image processing theory in significantly greater detail. Appendix B contains a list of references that you can consult for additional information regarding these topics.
Convolution Math: 1D
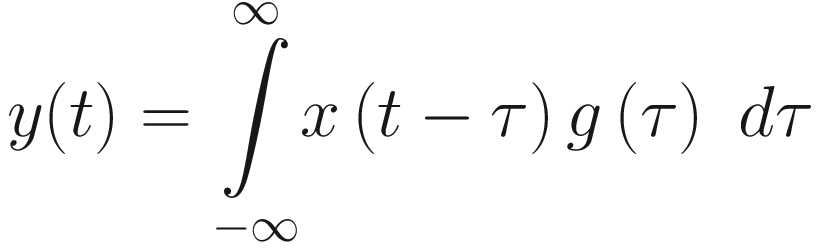
where y represents the output signal. The notation x ∗ g is commonly used to denote the convolution of signals (or functions) x and g.
![$$ yleft[i
ight]=sum limits_{k=-M}^Mxleft[i-k
ight]gleft[k
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484279182/9781484279182__9781484279182__files__images__519226_1_En_6_Chapter__519226_1_En_6_Chapter_TeX_Equb.png)
where i = 0, 1, ⋯, N − 1 and M = floor(Ng/2). In the preceding equations, N denotes the number of elements in the input and output signals, and Ng symbolizes the number of elements in the response array. The ensuing discussions and source code examples in this chapter assume that Ng is an odd integer greater than or equal to three. If you examine the 1D discrete convolution equation carefully, you will notice that each element of the output signal array y is computed using a straightforward sum-of-products calculation that encompasses the input signal x and the response signal g. These types of calculations are easy to implement using FMA arithmetic as you have already seen.

Raw data signal (top plot) and its smoothed counterpart (bottom plot)

Calculation of 1D discrete convolution output signal element
Convolution Math: 2D

![$$ yleft[i,j
ight]=sum limits_{k_1=-M}^Msum limits_{k_2=-M}^Mxleft[i-{k}_1,j-{k}_2
ight] gleft[{k}_1,{k}_2
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484279182/9781484279182__9781484279182__files__images__519226_1_En_6_Chapter__519226_1_En_6_Chapter_TeX_Equd.png)

Application of a low-pass filter using a 2D discrete convolution

Calculation of a 2D discrete convolution output signal element

Example of a separable 2D convolution kernel and its corresponding 1D convolution kernels
![$$ yleft[i,j
ight]=sum limits_{k_1=-M}^Msum limits_{k_2=-M}^Mxleft[i-{k}_1,j-{k}_2
ight] {g}_1left[{k}_1
ight] {g}_2left[{k}_2
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484279182/9781484279182__9781484279182__files__images__519226_1_En_6_Chapter__519226_1_En_6_Chapter_TeX_Eque.png)
![$$ yleft[i,j
ight]=sum limits_{k_1=-M}^M{g}_1left[{k}_1
ight]left[sum limits_{k_2=-M}^Mxleft[i-{k}_1,j-{k}_2
ight] {g}_2left[{k}_2
ight]
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484279182/9781484279182__9781484279182__files__images__519226_1_En_6_Chapter__519226_1_En_6_Chapter_TeX_Equf.png)
1D Convolutions
Example Ch06_01
Listing 6-1 begins with the file Ch06_01.h, which includes the function declarations for this example. Note that the function declarations use type std::vector<float> for the various signal arrays. The next file in Listing 6-1 is Ch06_01.cpp and includes the function Convolve1D_F32() . This function uses a function template named GenSignal1D() to generate a synthetic input signal. The source code for GenSignal1D() is not shown in Listing 6-1 but included in the download software package. The variable std::vector<float> kernel contains response signal coefficients that implement a simple low-pass filter. Function Convolve1D_F32() also invokes the 1D discrete convolution functions Convolve1D_F32_Cpp(), Convolve1D_F32_Iavx2(), and Convolve1DKs5_F32_Iavx2(). Following execution of these functions, Convolve1D_F32() saves the signal array data to the specified file.
The first function in file Ch06_01_fcpp.cpp is named Convolve1D_F32_Cpp(). This function is a direct implementation of the 1D discrete convolution equation using standard C++ statements. Note that the for-loop index variables in Convolve1D_F32_Cpp() are declared using the data type indx_t , which is defined in MiscTypes.h. Type indx_t is a signed integer whose size (32 or 64 bits) is platform dependent. Signed integer index variables are employed in this chapter’s convolution calculating functions since this corresponds to the summation indices used in the discrete convolution equations.
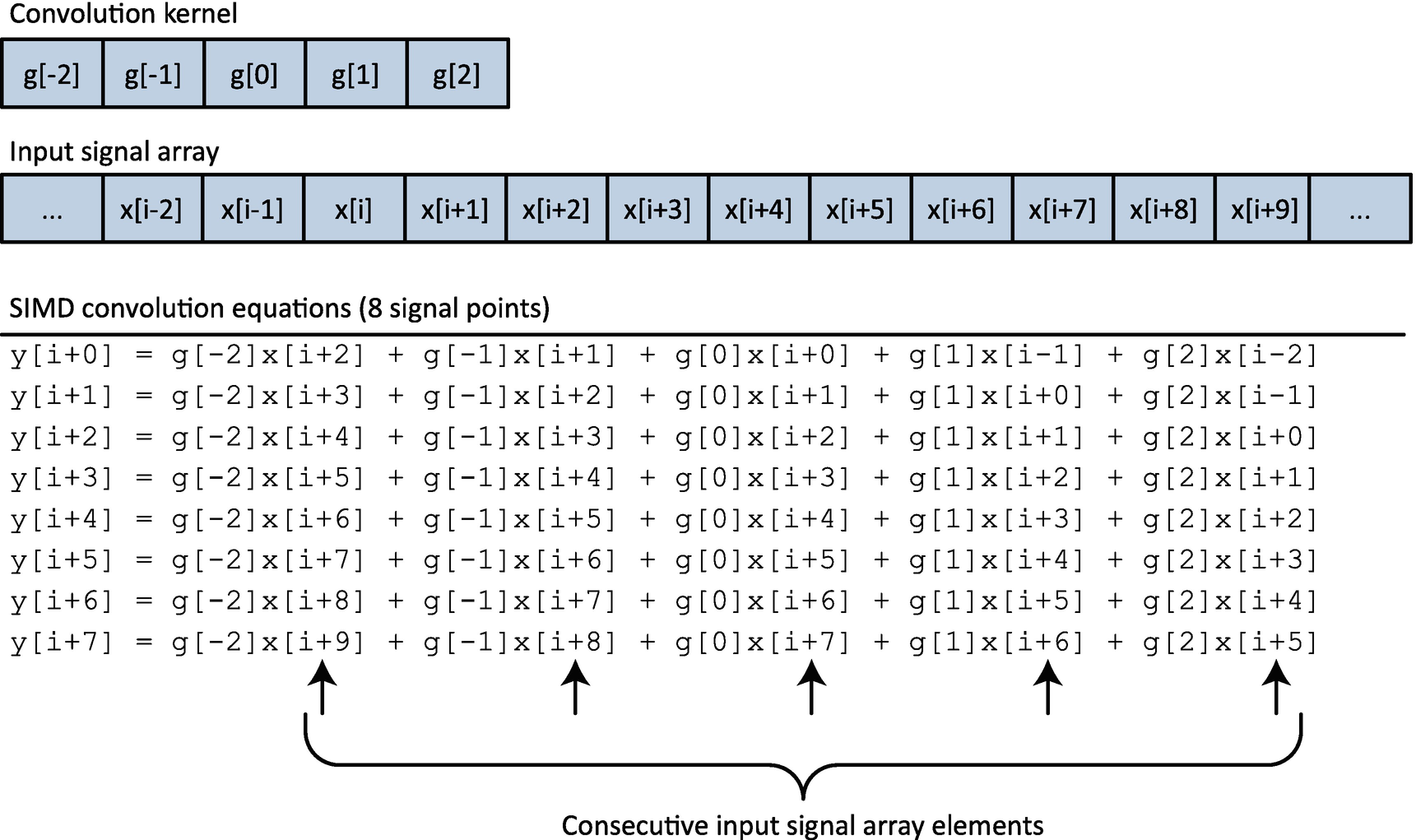
SIMD 1D discrete convolution equations for a five-element convolution kernel
When performing a 1D discrete convolution using SIMD arithmetic, function Convolve1D_F32_Iavx2() must ensure that it does not attempt to access any elements beyond the boundaries of the input and output signal arrays. The first if code block in the while-loop verifies that a sufficient number of input signal elements are available to calculate output signal elements y[i:i+7]. If enough elements are available, the for-loop performs its calculations using the equations shown in Figure 6-6. The second if code block handles the case when there are enough input signal elements to calculate x[i:i+3]. The final else code block uses scalar arithmetic to process any residual signal elements. Note that all three code blocks in the while-loop perform unaligned load and store operations since it is impossible to guarantee that any set of consecutive input or output signal array elements will be aligned on a particular boundary.
1D Discrete Convolution (Single-Precision) Execution Times (Microseconds)
CPU | Convolve1D_F32_Cpp() | Convolve1D_F32_Iavx2() | Convolve1DKs5_F32_Iavx2() |
|---|---|---|---|
Intel Core i7-8700K | 3240 | 411 | 278 |
Intel Core i5-11600K | 2267 | 325 | 221 |
Example Ch06_02
Like many of the source examples presented in earlier chapters, the changes required to transform the single-precision SIMD convolutions functions into double-precision variants are relatively straightforward. In example Ch06_02, the functions Convolve1D_F64_Iavx2() and Convolve1DKs5_F64_Iavx2() use double-precision versions of the C++ SIMD intrinsic functions. Also note that the values for num_simd_elements and num_simd_elements2 have been cut in half to accommodate SIMD arithmetic using double-precision floating-point elements.
1D Discrete Convolution (Double-Precision) Execution Times (Microseconds)
CPU | Convolve1D_F64_Cpp() | Convolve1D_F64_Iavx2() | Convolve1DKs5_F64_Iavx2() |
|---|---|---|---|
Intel Core i7-8700K | 3383 | 956 | 660 |
Intel Core i5-11600K | 2280 | 703 | 503 |
2D Convolutions
In this section, you will study source code examples that carry out 2D discrete convolutions. The first source code example demonstrates a 2D discrete convolution. The code in this example is suitable when performing a 2D discrete convolution using a nonseparable convolution kernel. The second example illustrates a 2D discrete convolution using two 1D discrete convolutions. The code in this example highlights the performance advantages of using dual 1D convolution kernels instead of a single 2D convolution kernel when the 2D kernel is separable.
Nonseparable Kernel
Example Ch06_03
Listing 6-3 opens with the file Ch06_03.h. Near the top of this file is the definition of a structure named CD_2D . This structure holds the input image, output image, and convolution kernel matrices, which are implemented using the C++ STL class std::vector<float>. Structure CD_2D also includes image and kernel size information. Following the definition of structure CD_2D is an enum named KERNEL_ID. The function Init2D() in Ch06_03_misc.cpp employs a KERNEL_ID argument to select a low-pass filter kernel for the convolution functions. In file Ch06_03.cpp, there is a function named Convolve2D_F32() . This function initializes the CD_2D structures, invokes the convolution calculating functions, and saves the final images.
The file Ch06_03_fcpp.cpp begins with the definition of function Convolve2D_F32_Cpp(). This non-SIMD function uses standard C++ statements to perform a 2D discrete convolution using the specified source image and convolution kernel. Note that function Convolve2D_F32_Cpp() employs four nested for-loops to implement the 2D discrete convolution equation that was defined earlier in this chapter.
The SIMD counterpart of function Convolve2D_F32_Cpp() is named Convolve2D_F32_Iavx2(). The code layout of this function is somewhat analogous to the 1D discrete convolution functions you saw earlier in this chapter. In function Convolve2D_F32_Iavx2() , the index variable i in the outer-most for-loop specifies the current image row, and the index variable j in the second-level while-loop specifies the current image column. The first if statement in the while-loop verifies that there are num_simd_elements or more columns remaining in the current row. If true, the two inner for-loops calculate im_des[i][j:j+7] using the appropriate elements from the source image im_src and the convolution kernel im_ker. Note that these C++ code variables correspond to the symbols y, x, and g in the 2D discrete convolution equation.

Input signal and convolution kernel elements required to calculate an output element in a 2D discrete convolution
2D Discrete Convolution (Single-Precision) Execution Times (Microseconds)
CPU | Convolve2D_F32_Cpp() | Convolve2D_F32_Iavx2() |
|---|---|---|
Intel Core i7-8700K | 89569 | 11241 |
Intel Core i5-11600K | 75609 | 9266 |
Separable Kernel
Example Ch06_04
In Listing 6-4, the header file Ch06_04.h begins with the definition of a structure named CD_1Dx2 . This structure holds the data that is used by the convolution calculating functions. There are two noteworthy differences between the structure CD_1Dx2 and the structure CD_2D that was used in the previous example. First, structure CD_1Dx2 includes a third image buffer named m_ImTmp. This temporary buffer holds the result of the first 1D discrete convolution. The second notable change is that structure CD_1Dx2 contains two 1D convolution kernels, m_Kernel1Dx and m_Kernel1Dy, instead of a single 2D discrete convolution kernel. Not shown in Listing 6-4 are files Ch06_04_misc.cpp and Ch06_04.cpp. These files contain the functions that perform data structure initialization, image loading and saving, etc., and are very similar to the ones used in example Ch06_03. They are, of course, included in the software download package.
The first function in file Ch06_04_fcpp.cpp, Convolve1Dx2_F32_Cpp() , implements the dual 1D discrete convolution using standard C++ statements. Note that Convolve1Dx2_F32_Cpp() performs its convolutions using two separate code blocks. The first code block contains three nested for-loops that execute a 1D convolution using the x-axis of source image buffer im_src. The results of this convolution are saved to the temporary image buffer im_tmp. The second code block in function Convolve1Dx2_F32_Cpp() performs a 1D convolution using the y-axis of im_tmp. The result of this 1D convolution is saved to the output image buffer im_des.
2D Discrete Convolution (Single-Precision) Execution Times (Microseconds)
CPU | Convolve1Dx2_F32_Cpp() | Convolve1Dx2_F32_Iavx2() |
|---|---|---|
Intel Core i7-8700K | 21568 | 3623 |
Intel Core i5-11600K | 14395 | 2467 |
In source code file Ch06_05.cpp, changing max_d = 1 to max_d = 0 yields only a small number of pixel value discrepancies.
Summary
C++ SIMD Intrinsic Function Summary for Chapter 6
C++ SIMD Function Name | Description |
|---|---|
_mm_fmadd_sd, _ss | Scalar fused-multiply-add |
_mm_load_sd, _ss | Load scalar floating-point element |
_mm_mul_pd, _ps | Packed floating-point multiplication |
_mm_mul_sd, _ss | Scalar floating-point multiplication |
_mm_set1_pd, _ps | Broadcast floating-point value |
_mm_setzero_pd, _ps | Set packed floating-point elements to zero |
_mm_store_sd, _ss | Store scalar floating-point element |