
In the previous chapter, you were introduced to the fundamentals of x86-64 assembly language programming. You learned how to use elementary instructions that performed integer addition, subtraction, multiplication, and division. You also acquired valuable knowledge regarding memory addressing modes, condition codes, and assembly language programming syntax. The chapter that you are about to read is a continuation of the previous chapter. Topics discussed include scalar floating-point arithmetic, compares, and conversions. This chapter also provides additional details regarding the Visual C++ calling convention including volatile and nonvolatile registers, stack frames, and function prologues and epilogues.
Scalar Floating-Point Arithmetic
Besides its SIMD capabilities, AVX also includes instructions that perform scalar floating-point operations including basic arithmetic, compares, and conversions. Many modern programs use AVX scalar floating-point instructions instead of legacy SSE2 or x87 FPU instructions. The primary reason for this is that most AVX instructions employ three operands: two nondestructive source operands and one destination operand. The use of nondestructive source operands often reduces the number of register-to-register transfers that a function must perform, which yields more efficient code. In this section, you will learn how to code functions that perform scalar floating-point operations using AVX. You will also learn how to pass floating-point arguments and return values between a C++ and assembly language function.
Single-Precision Arithmetic
Example Ch12_01
In Listing 12-1, the header file Ch12_01.h includes declaration statements for the functions ConvertFtoC_Aavx() and ConvertCtoF_Aavx(). Note that these functions require a single argument value of type float. Both functions also return a value of type float. The file Ch12_01.cpp includes a function named ConvertFtoC() that performs test case initialization for ConvertFtoC_Aavx() and displays the calculated results. File Ch12_01.cpp also includes the function ConvertCtoF(), which is the Celsius to Fahrenheit counterpart of ConvertFtoC().
The assembly language code in Ch12_01_fasm.asm starts with a .const section that defines the constants needed to convert a temperature value from Fahrenheit to Celsius and vice versa. The text real4 is a MASM directive that allocates storage space for single-precision floating-point value (the directive real8 can be used for double-precision floating-point values). Following the .const section is the code for function ConvertFtoC_Aavx(). The first instruction of this function, vmovss xmm1,[r4_32p0] (Move or Merge Scalar SPFP1 Value), loads the single-precision floating-point value 32.0 from memory into register XMM1 (more precisely into XMM1[31:0]). A memory operand is used here since AVX does not support using immediate operands for scalar floating-point constants.
Per the Visual C++ calling convention, the first four floating-point argument values are passed to a function using registers XMM0, XMM1, XMM2, and XMM3. This means that upon entry to function ConvertFtoC_Aavx(), register XMM0 contains argument value deg_f. Following execution of the vmovss instruction, the vsubss xmm2,xmm0,xmm1 (Subtract Scalar SPFP Value) instruction calculates deg_f - 32.0 and saves the result in XMM2[31:0]. Execution of vsubss does not modify the contents of source operands XMM0 and XMM1. However, this instruction copies bits XMM0[127:32] to XMM2[127:32] (other AVX scalar arithmetic instructions also perform this copy operation). The ensuing vmovss xmm1,[r4_ScaleFtoC] loads the constant value 0.55555556 (or 5 / 9) into register XMM1. This is followed by a vmulss xmm0,xmm2,xmm1 (Multiply Scalar SPFP Value) instruction that computes (deg_f - 32.0) * 0.55555556 and saves the result (i.e., the converted temperature in Celsius) in XMM0. The Visual C++ calling convention designates register XMM0 for floating-point return values. Since the return value is already in XMM0, no additional vmovss instructions are necessary.
Double-Precision Arithmetic
Example Ch12_02


Stack layout and argument registers at entry to CalcDistance_Aavx()
The final two letters of many x86-AVX arithmetic instruction mnemonics denote the operand type. You have already seen the instructions vaddss and vaddsd, which perform scalar single-precision and double-precision floating-point addition. In these instructions, the suffixes ss and sd denote scalar single-precision and double-precision values, respectively. X86-AVX instructions also use the mnemonic suffixes ps and pd to signify packed single-precision and double-precision values. X86-AVX instructions that manipulate more than one data type often include multiple data type characters in their mnemonics.
Compares
Example Ch12_03
Status Flags Set by vcomis[d|s]
Condition | RFLAGS.ZF | RFLAGS.PF | RFLAGS.CF |
|---|---|---|---|
XMM0 > XMM1 | 0 | 0 | 0 |
XMM0 == XMM1 | 1 | 0 | 0 |
XMM0 < XMM1 | 0 | 0 | 1 |
Unordered | 1 | 1 | 1 |
Condition Codes Following Execution of vcomis[d|s]
Relational Operator | Condition Code | RFLAGS Test Condition |
|---|---|---|
XMM0 < XMM1 | Below (b) | CF == 1 |
XMM0 <= XMM1 | Below or equal (be) | CF == 1 || ZF == 1 |
XMM0 == XMM1 | Equal (e or z) | ZF == 1 |
XMM0 != XMM1 | Not Equal (ne or nz) | ZF == 0 |
XMM0 > XMM1 | Above (a) | CF == 0 && ZF == 0 |
XMM0 >= XMM1 | Above or Equal (ae) | CF == 0 |
Unordered | Parity (p) | PF == 1 |
It should be noted that the status flags shown in Table 12-1 are set only if floating-point exceptions are masked (the default state for Visual C++ and most other C++ compilers). If floating-point invalid operation or denormal exceptions are unmasked (MXCSR.IM = 0 or MXCSR.DM = 0) and one of the compare operands is a QNaN, SNaN, or denormal, the processor will generate an exception without updating the status flags in RFLAGS.
Conversions
Example Ch12_04
Near the top of Listing 12-4 is the definition of a union named Uval . Source code example Ch12_04 uses this union to simplify data exchange between the C++ and assembly language code. Following Uval is an enum named CvtOp, which defines symbolic names for the conversions. Also included in file Ch12_04.h is the enum RC. This type defines symbolic names for the floating-point rounding modes. Recall from the discussions in Chapter 10 that the MXCSR register contains a two-bit field that specifies the rounding method for floating-point operations (see Table 10-4).
Also shown in Listing 12-4 is the file Ch12_04.cpp. This file includes the driver function ConvertScalars(), which performs test case initialization and streams results to std::cout. Note that each use of the assembly language function ConvertScalar_Aavx() requires two argument values of type Uval , one argument of type CvtOp, and one argument of type RC.
Assembly language source code files often employ the equ (equate) directive to define symbolic names for numerical expressions. The equ directive is somewhat analogous to a C++ const definition (e.g., const int x = 100;). The first noncomment statement in Ch12_04_fasm.asm, MxcsrRcMask equ 9fffh, defines a symbolic name for a mask that will be used to modify bits MXCSR.RC. This is followed by another equ directive MxcsrRcShift equ 13 that defines a shift count for bits MXCSR.RC.
Immediately following the two equate statements is the definition of a macro named GetRC_M. A macro is a text substitution mechanism that enables a programmer to represent a sequence of assembly language instructions, data, or other statements using a single text string. Assembly language macros are typically employed to generate sequences of instructions that will be used more than once. Macros are also frequently exercised to factor out and reuse code without the performance overhead of a function call.
Macro GetRC_M emits a sequence of assembly language instructions that obtain the current value of MXCSR.RC. The first instruction of this macro, vstmxcsr dword ptr [rsp+8] (Store MXCSR Register State), saves the contents of register MXCSR on the stack. The reason for saving MXCSR on the stack is that vstmxcsr only supports memory operands. The next instruction, mov r10d,[rsp+8], copies this value from the stack and loads it into register R10D. The ensuing instruction pair, shr r10d,MxcsrRcShift and and r10d,3, relocates the rounding control bits to bits 1:0 of register R10D; all other bits in R10D are set to zero. The text endm is an assembler directive that signifies the end of macro GetRC_M.
Following the definition of macro GetRC_M is another macro named SetRC_M. This macro emits instructions that modify MXCSR.RC. Note that macro SetRC_M includes an argument named RcReg. This is a symbolic name for the general-purpose register that contains the new value for MXCSR.RC. More on this in a moment. Macro SetRC_M also begins with the instruction sequence vstmxcsr dword ptr [rsp+8] and mov eax,[rsp+8] to obtain the current contents of MXCSR. It then employs the instruction pair and RcReg,3 and shl RcReg,MxcsrRcShift. These instructions shift the new bits for MXCSR.RC into the correct position. During macro expansion, the assembler replaces macro argument RcReg with the actual register name as you will soon see. The ensuing and eax,MxcsrRcMask and or eax,RcReg instructions update MXCSR.RC with the new rounding mode. The next instruction pair, mov [rsp+8],eax and vldmxcsr dword ptr [rsp+8] (Load MXCSR Register State), loads the new RC control bits into MXCSR.RC. Note that the instruction sequence used in SetRC_M preserves all other bits in the MXCSR register.

Expansion of macros GetRC_M and SetRC_M
Function ConvertScalar_Aavx() uses argument value cvt_op and a jump table to select a conversion code block. This construct is akin to a C++ switch statement. Immediately after the ret instruction is a jump table named CvtOpTable. The align 8 statement that appears just before the start of CvtOpTable is an assembler directive that instructs the assembler to align the start of CvtOpTable on a quadword boundary. The align 8 directive is used here since CvtOpTable contains quadword elements of labels defined in ConvertScalar_Aavx(). The labels correspond to code blocks that perform a specific numerical conversion. The instruction jmp [CvtOpTable+rax*8] transfers program control to the code block specified by cvt_op, which was copied into RAX. More specifically, execution of the jmp [CvtOpTable+rax*8] instruction loads RIP with the quadword value stored in memory location CvtOpTable + rax * 8.
AVX Scalar Floating-Point Conversion Instructions
Instruction Mnemonic | Description |
|---|---|
vcvtsi2ss | Convert 32- or 64-bit signed integer to SPFP |
vcvtsi2sd | Convert 32- or 64-bit signed integer to DPFP |
vcvtss2si | Convert SPFP to 32- or 64-bit signed integer |
vcvtsd2si | Convert DPFP to 32- or 64-bit signed integer |
vcvtss2sd | Convert SPFP to DPFP |
vcvtsd2ss | Convert DPFP to SPFP |
Scalar Floating-Point Arrays
Example Ch12_05
Listing 12-5 begins with the definition of assembly language function CalcMeanF32_Aavx(). The first code block of this function verifies that n >= 2 is true. Following validation of n, CalcMeanF32_Aavx() uses a vxorps xmm0,xmm0,xmm0 (Bitwise Logical XOR of Packed SPFP Values) instruction to set sum = 0.0. The next instruction, mov rax,-1, initializes loop index variable i to -1. Each iteration of Loop1 begins with an inc rax instruction that calculates i += 1. The ensuing instruction pair, cmp rax,r8 and jae CalcM, terminates Loop1 when i >= n is true. The vaddss xmm0,xmm0,real4 ptr [rdx+rax*4] instruction computes sum += x[i]. Following the calculation of sum, CalcMeanF32_Aavx() converts n to a single-precision floating-point value using the AVX instruction vcvtsi2ss xmm1,xmm1,r8. The next two instructions, vdivss xmm1,xmm0,xmm1 and vmovss real4 ptr [rcx],xmm1, calculate and save mean.
Function CalcStDev_Aavx() uses a similar for-loop construct to calculate the standard deviation. Inside Loop1, CalcStDev_Aavx() calculates sum_squares using the AVX instructions vsubss, vmulss, and vaddss . Note that argument value mean was passed in register XMM3. Following execution of Loop1, CalcStDev_Aavx() calculates the standard deviation using the instructions dec r8 (to calculate n - 1), vcvtsi2ss , vdivss, and vsqrtss.
Calling Convention: Part 2
The source code presented thus far has informally discussed various aspects of the Visual C++ calling convention. In this section, the calling convention is formally explained. It reiterates some earlier elucidations and introduces new requirements that have not been discussed. A basic understanding of the calling convention is necessary since it is used extensively in subsequent chapters that explain x86-AVX SIMD programming using x86-64 assembly language.
As a reminder, if you are reading this book to learn x86-64 assembly language programming and plan on using it with a different operating system or high-level language, you should consult the appropriate documentation for more information regarding the particulars of that calling convention.
Visual C++ 64-Bit Volatile and Nonvolatile Registers
Register Group | Volatile Registers | Nonvolatile Registers |
|---|---|---|
General-purpose | RAX, RCX, RDX, R8, R9, R10, R11 | RBX, RSI, RDI, RBP, RSP, R12, R13, R14, R15 |
Floating point and SIMD | XMM0–XMM5 | XMM6–XMM15 |
On systems that support AVX or AVX2, the high-order 128 bits of registers YMM0–YMM15 are classified as volatile. Similarly, the high-order 384 bits of registers ZMM0–ZMM15 are classified as volatile on systems that support AVX-512. Registers ZMM16–ZMM31 and their corresponding YMM and XMM registers are also designated as volatile and need not be preserved. The legacy x87 FPU register stack is classified as volatile. All control bits in RFLAGS and MXCSR must be preserved across function boundaries. For example, assume function Foo() changes MXCSR.RC prior to performing a floating-point calculation. It then needs to call the C++ library function cos() to perform another calculation. Function Foo() must restore the original contents of MXCSR.RC before calling cos().
Do not call any other functions
Do not modify the contents of register RSP
Do not allocate any local stack space
Do not modify any of the nonvolatile general-purpose or XMM registers
Do not use exception handling
X86-64-bit assembly language leaf functions are easier to code, but they are only suitable for relatively simple computations. A nonleaf function can use the entire x86-64 register set, create a stack frame, or allocate local stack space. The preservation of nonvolatile registers and local stack space allocation is typically performed at the beginning of a function in a code block known as the prologue. Functions that utilize a prologue must also include a corresponding epilogue. A function epilogue releases any locally allocated stack space and restores any prologue preserved nonvolatile registers.
In the remainder of this section, you will examine four source code examples. The first three examples illustrate how to code nonleaf functions using explicit x86-64 assembly language instructions and assembler directives. These examples also convey critical programming information regarding the organization of a nonleaf function stack frame. The fourth example demonstrates how to use several prologue and epilogue macros. These macros help automate most of the programming labor that is associated with a nonleaf function. The source code listings in this section include only the C++ header file and the x86-64 assembly language code. The C++ code that performs test case initialization, argument checking, displaying of results, etc., is not shown to streamline the elucidations. The software download package includes the complete source code for each example.
Stack Frames
Example Ch12_06
Functions that need to reference both argument values and local variables on the stack often create a stack frame during execution of their prologues. During creation of a stack frame, register RBP is typically initialized as a stack frame pointer. Following stack frame initialization, the remaining code in a function can access items on the stack using RBP as a base register.
Near the top of file Ch12_06_fasm.asm are the statements RBP_RA = 24 and STK_LOCAL = 16. The = symbol is an assembler directive that defines a symbolic name for a numerical value. Unlike the equ directive, symbolic names defined using the = directive can be redefined. RBP_RA denotes the number of bytes between RBP and the return address on stack (it also equals the number of extra bytes needed to reference the stack home area). STK_LOCAL represents the number of bytes allocated on the stack for local storage. More on these values in a moment.
Following definition of RBP_RA and STK_LOCAL is the statement SumIntegers_A proc frame, which defines the beginning of function SumIntegers_A(). The frame attribute notifies the assembler that the function SumIntegers_A uses a stack frame pointer. It also instructs the assembler to generate static table data that the Visual C++ runtime environment uses to process exceptions. The ensuing push rbp instruction saves the caller’s RBP register on the stack since function SumIntegers_A() uses this register as its stack frame pointer. The .pushreg rbp statement that follows is an assembler directive that saves offset information about the push rbp instruction in an assembler-maintained exception handling table (see example Ch11_08 for more information about why this is necessary). It is important to keep in mind that assembler directives are not executable instructions; they are directions to the assembler on how to perform specific actions during assembly of the source code.
The sub rsp,STK_LOCAL instruction allocates STK_LOCAL bytes of space on the stack for local variables. Function SumIntegers_A() only uses eight bytes of this space, but the Visual C++ calling convention for 64-bit programs requires nonleaf functions to maintain double quadword (16-byte) alignment of the stack pointer outside of the prologue. You will learn more about stack pointer alignment requirements later in this section. The next statement, .allocstack STK_LOCAL, is an assembler directive that saves local stack size allocation information in the Visual C++ runtime exception handling tables.

Stack layout and registers of function SumIntegers_A() following execution of the prologue
The next code block contains a series of mov instructions that save registers RCX, RDX, R8, and R9 to their respective home areas on this stack. This step is optional and included in SumIntegers_A() for demonstration purposes. Note that the offset of each mov instruction includes the symbolic constant RBP_RA. Another option allowed by the Visual C++ calling convention is to save an argument register to its corresponding home area prior to the push rbp instruction using RSP as a base register (e.g., mov [rsp+8],rcx, mov [rsp+16],rdx, and so on). Also keep in mind that a function can use its home area to store other temporary values. When used for alternative storage purposes, the home area should not be referenced by an assembly language instruction until after the .endprolog directive per the Visual C++ calling convention.
Following the home area save operation, the function SumIntegers_A() sums argument values a, b, c, and d. It then saves this intermediate sum to LocalVar1 on the stack using a mov [rbp],r8 instruction. Note that the summation calculation sign-extends argument values a, b, and c using a movsx or movsxd instruction. A similar sequence of instructions is used to sum argument values e, f, g, and h, which are located on the stack and referenced using the stack frame pointer RBP and a constant offset. The symbolic name RBP_RA is also used here to account for the extra stack space needed to reference argument values on the stack. The two intermediate sums are then added to produce the final sum in register RAX.
Using Nonvolatile General-Purpose Registers
Example Ch12_07
Toward the top of the assembly language code is a series of named constants that control how much stack space is allocated in the prologue of function CalcSumProd_A(). Like the previous example, the function CalcSumProd_A() includes the frame attribute as part of its proc statement to indicate that it uses a stack frame pointer. A series of push instructions saves nonvolatile registers RBP, RBX, R12, and R13 on the stack. Note that a .pushreg directive follows each x86-64 push instruction, which instructs the assembler to add information about each push instruction to the Visual C++ runtime exception handling tables.

Stack layout and argument registers following execution of lea rbp,[rsp+STK_LOCAL2] in function CalcSumProd_A()
The next code block contains instructions that initialize several local variables on the stack. These instructions are for demonstration purposes only. Note that the vmovdqa [rbp-16],xmm5 (Move Aligned Packed Integer Values) instruction requires its destination operand to be aligned on a 16-byte boundary. Following initialization of the local variables, the argument registers are saved to their home locations, also just for demonstration purposes.
Function CalcSumProd_A() computes sums and products using the elements of two integer arrays. Prior to the start of the for-loop, the instruction pair test r8d,r8d (Logical Compare) and jle Done skips over the for-loop if n <= 0 is true. The test instruction performs a bitwise logical AND of its two operands and updates the status flags in RFLAGS; the result of the bitwise and operation is discarded. Following validation of argument value n, the function CalcSumProd_A() initializes the intermediate values sum_a (R10) and sum_b (R11) to zero and prod_a (R12) and prod_b (R13) to one. It then calculates the sum and product of the input arrays a and b. The results are saved to the memory locations specified by the caller. Note that the pointers for sum_b, prod_a, and prod_b were passed to CalcSumProd_A() via the stack as shown in Figure 12-4.
Using Nonvolatile SIMD Registers
Example Ch12_08
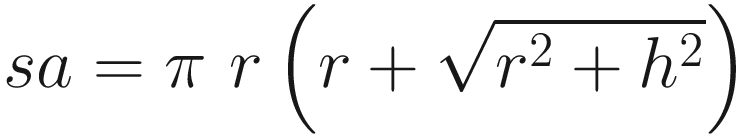
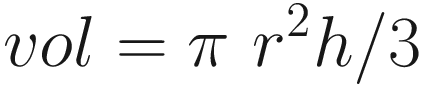

Stack layout and argument registers following execution of vmovdqa xmmword ptr [rbp-STK_LOCAL2],xmm15 in function CalcConeAreaVol_A()
Following the prologue, local variables LocalVar1A and LocalVar1B are accessed for demonstration purposes. Initialization of the registers used by the main processing loop occurs next. Note that many of these initializations are either suboptimal or superfluous; they are performed merely to highlight the use of nonvolatile registers, both general purpose and XMM. Calculation of the cone surface areas and volumes is then carried out using AVX double-precision floating-point arithmetic.
Macros for Function Prologues and Epilogues
The purpose of the three previous source code examples was to explicate the requirements of the Visual C++ calling convention for 64-bit nonleaf functions. The calling convention’s rigid requisites for function prologues and epilogues are somewhat lengthy and a potential source of programming errors. It is important to recognize that the stack layout of a nonleaf function is primarily determined by the number of nonvolatile (both general-purpose and XMM) registers that must be preserved and the amount of local stack space that is needed. A method is needed to automate most of the coding drudgery associated with the calling convention.
Example Ch12_09
In Listing 12-9, the assembly language code begins with the statement include <MacrosX86-64-AVX.asmh>, which incorporates the contents of file MacrosX86-64-AVX.asmh into Ch12_09_fasm.asm during assembly. This file (source code not shown but included in the software download package) contains several macros that help automate much of the coding grunt work associated with the Visual C++ calling convention. Using an assembly language include file is analogous to using a C++ include file. The angled brackets that surround the file name can be omitted in some cases, but it is usually simpler and more consistent to just always use them. Note that there is no standard file name extension for x86 assembly language header files; I use .asmh but .inc is also used.

Generic stack layout for a nonleaf function
Function CalcBSA_A() computes body surface areas (BSA) using the same equations that were used in example Ch09_03 (see Table 9-1). Following the include statement in Listing 12-9 is .const section that contains definitions for the various floating-point constant values used in the BSA equations. The line extern pow:proc enables the use of the external C++ library function pow(). Following the CalcBSA_A proc frame statement, the macro CreateFrame_M emits assembly language code that initializes the stack frame. It also saves the specified nonvolatile general-purpose registers on the stack. Macro CreateFrame_M requires several parameters including a prefix string and the size in bytes of StkSizeLocal1 and StkSizeLocal2 (see Figure 12-6). Macro CreateFrame_M uses the specified prefix string to generate symbolic names that can be employed to reference items on the stack. It is somewhat convenient to use a shortened version of the function name as the prefix string, but any file-unique text string can be used. Both StkSizeLocal1 and StkSizeLocal2 must be evenly divisible by 16. StkSizeLocal2 must also be less than or equal to 240 and greater than or equal to the number of saved XMM registers multiplied by 16.
The next statement makes use of the SaveXmmRegs_M macro to save the specified nonvolatile XMM registers to the XMM save area on the stack. This is followed by the EndProlog_M macro, which signifies the end of the function’s prologue. At this point, register RBP is configured as the function’s stack frame pointer. It is also safe to use any of the saved nonvolatile general-purpose or XMM registers.
The code block that follows EndProlog_M saves argument registers RCX, RDX, R8, and R9 to their home locations on the stack. Note that each mov instruction includes a symbolic name that equates to the offset of the register’s home area on the stack relative to the RBP register. The symbolic names and the corresponding offset values were automatically generated by the CreateFrame_M macro. The home area can also be used to store temporary data instead of the argument registers, as mentioned earlier in this chapter.
Initialization of the processing for-loop variables occurs next. Argument value n in register R8D is checked for validity and then saved on the stack as a local variable. Several nonvolatile registers are then initialized as pointer registers. Nonvolatile registers are used to avoid register reloads following each call to the C++ library function pow(). Note that the pointer to array bsa2 is loaded from the stack using a mov r15,[rbp+BSA_OffsetStackArgs] instruction. The symbolic constant BSA_OffsetStackArgs also was automatically generated by the macro CreateFrame_M and equates to the offset of the first stack argument relative to the RBP register. A mov rbx,[rbp+BSA_OffsetStackArgs+8] instruction loads argument bsa3 into register RBX; the constant 8 is included as part of the source operand displacement since bsa3 is the second argument passed via the stack.
The Visual C++ calling convention requires the caller of a function to allocate that function’s home area on the stack. The sub rsp,32 instruction performs this operation for function pow(). The ensuing code block calculates BSA values using the equations shown in Table 9-1. Note that registers XMM0 and XMM1 are loaded with the necessary argument values prior to each call to pow(). Also note that some of the return values from pow() are preserved in nonvolatile XMM registers prior to their actual use.
If the discussions of this section have left you feeling a little bewildered, don’t worry. In this book’s remaining chapters, you will see an abundance of x86-64 assembly language source code that demonstrates proper use of the Visual C++ calling convention and its programming requirements.
Summary
X86 Assembly Language Instruction Summary for Chapter 12
Instruction Mnemonic | Description |
|---|---|
call | Call procedure/function |
lea | Load effective address |
setcc | Set byte if condition is true; clear otherwise |
test | Logical compare (bitwise logical AND to set RFLAGS) |
vadds[d|s] | Scalar floating-point addition |
vcvtsd2ss | Convert scalar DPFP value to SPFP |
vcomis[d|s] | Scalar floating-point compare |
vcvts[d|s]2si | Convert scalar floating-point to signed integer |
vcvtsi2s[d|s] | Convert signed integer to scalar floating-point |
vcvtss2sd | Convert scalar SPFP to scalar DPFP |
vdivs[d|s] | Scalar floating-point division |
vldmxcsr | Load MXCSR register |
vmovdqa | Move double quadword (aligned) |
vmovdqu | Move double quadword (unaligned) |
vmovs[d|s] | Move scalar floating-point value |
vmuls[d|s] | Scalar floating-point multiplication |
vsqrts[d|s] | Scalar floating-point square root |
vstmxcsr | Store MXCSR register |
vsubs[d|s] | Scalar floating-point subtraction |
vxorp[d|s] | Packed floating-point bitwise logical exclusive OR |