
9
Bias Adjustment Methods
9.1 Introduction
Ideally all RCTs included in a meta-analysis or network meta-analysis will have been conducted with a high standard of methodological rigour on exactly the target population we are interested in making treatment recommendations and decisions for. In practise, however, this is unlikely to be the case, and the results of individual trials may provide biased estimates of the relative treatment effects that we would expect to see in the target population of interest. Bias arises as a result of effect-modifying mechanisms, in other words interactions between relative treatment effects and trial-level variables that have not been accounted for.
As in Chapter 8, we distinguish between two types of interaction effect, those that threaten the external validity of a trial and those that threaten the internal validity. Where effect modifiers have been measured and reported, covariate adjustment using meta-regression techniques may be used to adjust for bias caused by issues to do with external validity (Chapter 8). In this chapter we focus on interaction effects due to deficiencies in the way the trial was conducted or reported, which threaten internal validity (Rothman et al., 2012). Here, the trial delivers a biased estimate of the treatment effects in the target population for the trial, defined by that trial’s inclusion/exclusion criteria. Typically, biases due to lack of internal validity are considered to vary randomly in size over trials, but do not necessarily have a zero mean. The clearest examples are the biases associated with markers of methodological rigour such as lack of allocation concealment of the randomisation process, or lack of double-blinding; these have been shown to be associated with larger treatment effects than trials without such markers (Schulz et al., 1995; Wood et al., 2008). Other examples include publication bias, where the chance of publication depends on the effect estimate and its ‘statistical significance’, and missing data where the response on treatment is linked to whether an individual is lost to follow-up.
Note that pairwise or network meta-analyses can suffer from biases due to problems with both internal and external validity, where the trial delivers a biased estimate of the treatment effect in the target population for the trial, which may not be the same as the target population of interest for the decision. Where there are loops in a network meta-analysis, biases may manifest as inconsistency, and methods for bias adjustment may resolve issues with inconsistency (Chapter 7).
Confronted by trial evidence where there is some doubt about the internal validity of some of the trials, investigators have had two options: they can restrict attention to studies at low risk of bias or they can include all trials, at both low and high risk of bias, in a single analysis. Both options have disadvantages: the first ignores what may be a substantial proportion of the evidence, while the second risks delivering a biased estimate of the treatment effect. Recently, methods have been developed to allow a third option: bias adjustment.
The aim of bias adjustment is to transform estimates of treatment effect that are thought to be biased relative to the desired effect in the target population, into unbiased estimates. It is therefore essential to have in mind a target population for decision-making, which should have been specified in advance of conducting literature searches to identify evidence for the meta-analysis or network meta-analysis. Bias adjustment is appropriate when the evidence available, or at least some of the evidence, provides potentially biased estimates of the target parameter, due to issues with internal validity, external validity or both.
We present three different methods that have been proposed: adjustment and down-weighting of evidence at risk of bias based on external data to account for internal biases; estimation of bias associated with markers of risk of internal bias within a network meta-analysis; and adjustment for internal and/or external biases based on expert opinion or other evidence. It is necessary in all cases to take into account the uncertainty in external data or prior opinions that are used. The fourth approach to bias adjustment is to use meta-regression methods for covariate adjustment to address issues with external validity. Meta-regression methods have already been presented in Chapter 8, and we refer the reader to that chapter for details on covariate adjustment. The four different bias adjustment methods are summarized in Box 9.1.
All the ideas presented in this chapter can be applied to the general network meta-analysis models (Chapters 2 and 4), and methods for model criticism (Chapter 3) can be applied directly.
9.2 Adjustment for Bias Based on Meta-Epidemiological Data
Schulz et al. (1995) compared the results from RCTs rated at ‘low risk of bias’ with RCTs rated at ‘high risk of bias’ according to certain indicators of lack of internal validity: lack of allocation concealment or lack of double-blinding. Their dataset included over 30 meta-analyses, in which both high and low risk of bias trials were present (known as a meta-epidemiological database). Their results suggested the relative treatment effect in favour of the newer treatment was, on average, higher in the high risk of bias studies. The effect was large, with odds ratios in favour of the newer treatment on average about 1.6 times higher. Savovic et al. (2012a, 2012b) extended this work by combining evidence from seven such meta-epidemiological databases, removing overlaps, resulting in a dataset of 234 unique meta-analyses containing 1973 trials. They found a modest, yet significant, effect that odds ratio estimates seemed to be exaggerated in trials with inadequate or unclear (vs adequate) random sequence generation (ratio of odds ratios, 0.89, 95% CrI (0.82, 0.96); in trials with inadequate or unclear (vs adequate) allocation concealment (ratio of odds ratios, 0.93, 95% CrI (0.87, 0.99); and in trials with lack of or unclear double-blinding (vs double-blinding) (ratio of odds ratios, 0.87, 95% CrI (0.79–0.96)). These effects were mainly driven by trials with ‘subjective’ outcomes, where effects were stronger than for mortality and other objective outcomes.
Welton et al. (2009a) suggest an approach that uses all the data, but simultaneously adjusts and down-weights the evidence from studies assessed as being at high risk of bias. For a pairwise meta-analysis, the model for the studies at low risk of bias is the standard model introduced in Chapter 4:
For the studies at high risk of bias, the assumption is that each trial provides information not on δi2, but on a ‘biased’ parameter ![]() , where the trial-specific bias terms βi2 are drawn from a random effects distribution, with a mean b0 representing the expected bias, and a between-trial variance κ2. Thus, for the trials at high risk of bias:
, where the trial-specific bias terms βi2 are drawn from a random effects distribution, with a mean b0 representing the expected bias, and a between-trial variance κ2. Thus, for the trials at high risk of bias:

Prior distributions for the mean bias, b0, and between-trial variance in bias, κ2, can be obtained from a Bayesian analysis of an external dataset, for example, from collections of meta-analyses (Schulz et al., 1995; Savovic et al., 2010; Savovic et al., 2012a, 2012b). The same model as set out by equations (9.1) and (9.2) is used for the meta-epidemiological analysis, but with an additional level of hierarchy to reflect between meta-analysis variations in mean bias. The resulting model estimates provide a prediction for b0 and κ2 in a new meta-analysis that is considered exchangeable with the meta-analyses in the meta-epidemiology database. In this way prior distributions can then be put on b0 and κ2 to form a prior distribution for study-specific biases in equation (9.2), which simultaneously adjusts for and down-weights treatment effects for risk of bias in the new meta-analysis. Savovic et al. (2012a, 2012b) fitted this model to their meta-epidemiological database to obtain the ratio of odds ratios given previously. They also provide prior distributions for the bias in a new trial and mean bias in a new meta-analysis by outcome type and by risk of bias indicator.
This analysis hinges critically on whether the study-specific biases in the dataset of interest can be considered exchangeable with those in the meta-epidemiological data used to provide the prior distributions used for adjustment and in particular whether they would be considered exchangeable by all the relevant stakeholders in the decision (Welton et al., 2009a). It is already clear that the degree of bias is dependent on the nature of the outcome measure, being greater with subjective (patient- or physician-reported) outcomes, and virtually undetectable with all-cause mortality and other objective outcome measures (Wood et al., 2008; Savovic et al., 2012a, 2012b). Furthermore, there is now evidence that there are differences between clinical areas in the magnitude of biases (Savovic et al., 2012a), suggesting that sets of prior distributions tailored for particular outcome types and disease conditions, as reported by Savovic et al. (2012a), are required. There has also been some work on how multiple indicators of risk of bias might interact (Savovic et al., 2012a), which suggest that the effects may be less than additive, although this result is very uncertain because it is difficult to obtain enough power to estimate interaction effects, even in very large datasets.
Despite concerns about exchangeability of a new meta-analysis with previous meta-analyses, one might take the view that any reasonable bias-adjusted analysis is likely to give a better reflection of the true parameters than an unadjusted analysis. Welton et al. (2009a) suggest that, even when there are doubts about a particular set of values for the bias distribution, investigators may wish to run a series of sensitivity analyses to show that the presence of studies at high risk of bias, with potentially overoptimistic results, is not having an impact on the decision.
In principle the same form of bias adjustment could be extended to other types of bias, such as novel agent effects, industry sponsor effects or small-study effects, or to mixtures of RCTs and observational studies. Each of these extensions, however, depends on detailed and far-ranging analyses of very large meta-epidemiological datasets, which have not yet been performed. There is no reason why prior distributions from meta-epidemiological studies cannot be applied to network as well as pairwise meta-analyses; however, a key challenge in doing so is in defining the direction in which a bias is expected to act, especially in studies comparing active treatments (see Section 9.3 for more details) as it may not be clear which treatment may be favoured in studies at high risk of bias. Savovic et al. (2012a) excluded trials where it was not clear in which direction the bias would act; otherwise biases between studies may ‘cancel out’, leading to an underestimate of the mean bias in a meta-analysis. Chaimani et al. (2013b) report results from a network meta-epidemiological study, where a collection of network meta-analyses are analysed to estimate bias resulting from indicators of risk of bias. The relationship between treatment effects and study precision (small-study effects, see Section 9.3.4) was also considered. However, they restrict attention to ‘star networks’ (i.e., those where all treatments have been compared with a common comparator) so that the direction in which the bias might act could be assumed to be against the common comparator. They found that imprecise studies were associated with large treatment effects.
9.3 Estimation and Adjustment for Bias in Networks of Trials
We turn next to a method that removes the difficulties associated with the strong ‘exchangeability’ assumptions required if using meta-epidemiological data to adjust for bias. Instead, the parameters of the bias distribution, b0 and variance κ2, are estimated internally, within the dataset of interest without recourse to external data. The method also sets out how the bias model in equations (9.1) and (9.2) can be extended from pairwise to network meta-analysis.
Imagine a set of trials, some of which are at ‘high’ and some at ‘low’ risk of bias according to an indicator of risk of bias due to issues with internal validity. In a pairwise meta-analysis, one can always use trials categorised in this way to estimate the size of bias and – with enough data – the variability in bias across studies. However, estimating the bias distribution adds nothing to our knowledge of the true treatment effect: the studies at high risk of bias provide information on the bias distribution, while those at low risk of bias provide information on the relative treatment effect. We might just as well have restricted the analysis to the low risk of bias studies alone in the first place. In other words in a pairwise meta-analysis there are not sufficient degrees of freedom to borrow strength from biased data to adjust treatment effects.
For indirect comparisons and network meta-analysis, if we assume that the mean and variance of the study-specific biases are the same for each treatment comparison, then it is possible to simultaneously estimate the treatment effects and the bias effects in a single analysis. This will produce treatment effects that are based on the entire body of data, including studies at both high and low risk of bias, and also adjusted for bias (Dias et al., 2010c). Furthermore, the consistency equations (equation (2.9)) provide further degrees of freedom to allow us to jointly estimate and adjust for bias. The model is exactly the same as in Section 9.2, where equations (9.1) and (9.2) are combined to give
with xi = 1 if study i is considered to be at risk of bias and zero otherwise and βik is the trial-specific bias of the treatment in arm k relative to the treatment in arm 1 of trial i. Note that equation (9.3) is a more general form of the meta-regression model introduced in equation (8.1), without the requirement of consistency of the regression coefficients, βik. We assume that the study-specific biases are exchangeable:
with between-study variance in bias, κ2, and where the mean bias ![]() depends on the treatment comparison being made between arm k and arm 1 in study i. In order to be able to estimate the bias parameters, we will need to make some simplifying assumptions on the mean biases
depends on the treatment comparison being made between arm k and arm 1 in study i. In order to be able to estimate the bias parameters, we will need to make some simplifying assumptions on the mean biases ![]() for each pair of treatments k1 and k2. One possibility is that the mean bias is the same for all active treatments that are compared with a standard or placebo treatment (‘active vs placebo’ trials) so that
for each pair of treatments k1 and k2. One possibility is that the mean bias is the same for all active treatments that are compared with a standard or placebo treatment (‘active vs placebo’ trials) so that ![]() . Note this is equivalent to the ‘exchangeable, related, treatment-specific interactions’ case introduced in equation (8.5).
. Note this is equivalent to the ‘exchangeable, related, treatment-specific interactions’ case introduced in equation (8.5).
It is less clear what to assume about bias in trials that make comparisons between active treatments. One approach might be to assume a mean bias of 0, based on the assumption that the mean bias against placebo is the same for the two active treatments, and so it should cancel out when compared head to head, based on the consistency of regression coefficients of covariates. However, such consistency may not be reasonable. For example, it may be the case that average bias is always in favour of the newer treatment (‘optimism bias’), and we require a model to reflect this novel agent bias (Song et al., 2008; Salanti et al., 2010). Another approach might be to propose a separate mean bias term for active versus active comparisons (Dias et al., 2010c) so that ![]() .
.
9.3.1 Worked Example: Fluoride Therapies for the Prevention of Caries in Children
Dias et al. (2010c) present bias adjustment models in a network meta-analysis of fluoride therapies to prevent the development of caries in children (Salanti et al., 2009). There are 130 trials of which one was a four-arm trial, three were three-arm trials, and the remaining were two-arm trials. The treatments are coded: 1 = No Treatment, 2 = Placebo, 3 = Toothpaste, 4 = Rinse, 5 = Gel and 6 = Varnish. The network is presented in Figure 9.1. The outcome available from each trial arm is the mean increase in number of caries, yik, for a given number of patients at risk, nik, from which we can derive the total number of additional caries, ![]() . Follow-up time, timei, varied between the trials.
. Follow-up time, timei, varied between the trials.
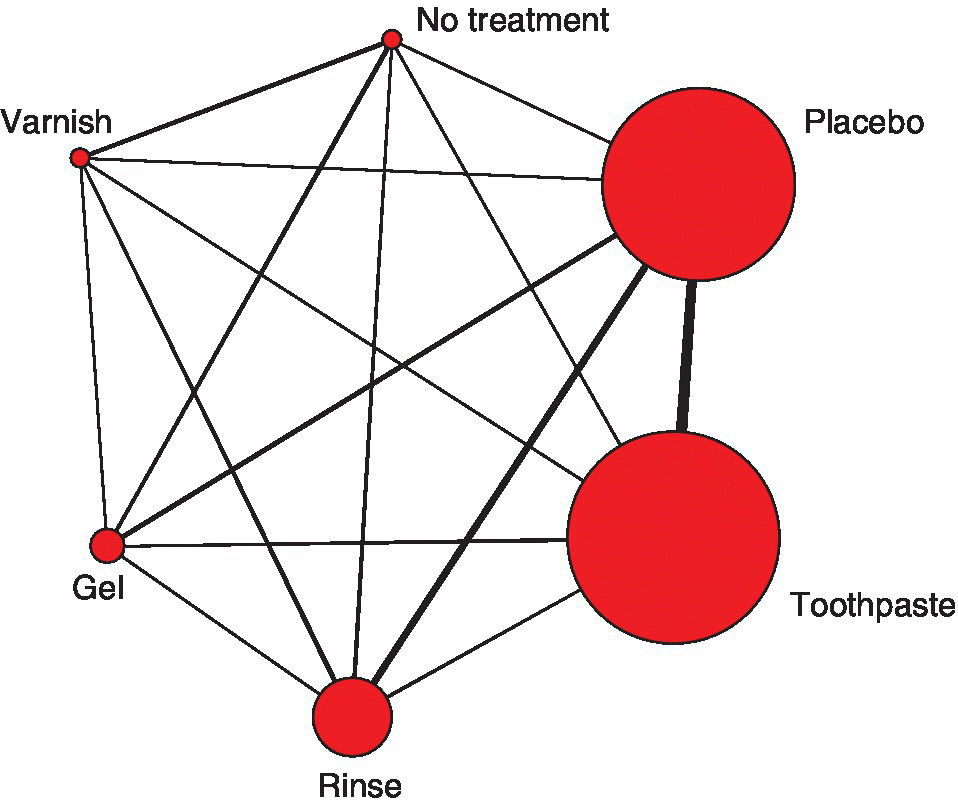
Figure 9.1 Fluoride example: network of treatment comparisons (drawn using R code from Salanti (2011)). The thickness of the lines is proportional to the number of trials making that comparison and the width of the bubbles is proportional to the number of patients randomised to each treatment (Salanti et al., 2009).
Reproduced with permission of Elsevier.
The total additional number of caries has a Poisson likelihood with mean equal to the rate of development of caries, λik, multiplied by the person time at risk, ![]() (equation (4.4)). The network meta-analysis model is put on the log rate scale
(equation (4.4)). The network meta-analysis model is put on the log rate scale ![]() , and the bias model is as given in equations (9.3) and (9.4). Dias et al. (2010c) explored two models for the bias. In the first (model 1), it is assumed that there is no bias in active versus active comparisons, and the mean bias is the same for all of the active versus inactive comparisons (no treatment and placebo). Note that both treatments 1 and 2 are considered non-active treatments in this example, so that in model 1:
, and the bias model is as given in equations (9.3) and (9.4). Dias et al. (2010c) explored two models for the bias. In the first (model 1), it is assumed that there is no bias in active versus active comparisons, and the mean bias is the same for all of the active versus inactive comparisons (no treatment and placebo). Note that both treatments 1 and 2 are considered non-active treatments in this example, so that in model 1:

In the second (model 2), it is assumed that there is bias in all treatment comparisons with a common mean bias for active versus active comparisons and a separate common mean bias for active versus inactive comparisons:

The code for model 1 is given in the following (available in Ch9_RE_Po_Fluorbias1.odc and the data in Ch9_FluorData.xlsx).
WinBUGS code for bias adjustment model 1, with common mean bias in active versus no treatment or placebo trials, and 0 mean bias in active versus active trials. Matrix C[i,k] indicates whether comparison is 1 = Placebo versus No Treatment, 2 = Active versus No Treatment, 3 = Active versus Placebo, 4 = Active versus Active. Vector bias[i] indicates a study at high risk of bias on a given marker.
The full code with data and initial values is presented in the online fileCh9_RE_Po_Fluorbias1.odc.
# Poisson likelihood, log link# Random effects model for multi-arm trials, with bias adjustment (model 1)model{ # *** PROGRAM STARTSfor(i in 1:ns){ # LOOP THROUGH STUDIESw[i,1] <- 0 # adjustment for multi-arm trials is zero for control armbeta[i,1] <- 0 # no bias term in baseline armdelta[i,1] <- 0 # treatment effect is zero for control armmu[i] ~ dnorm(0,.0001) # vague priors for all trial baselinesfor (k in 1:na[i]){ # LOOP THROUGH ARMSr[i,k] <- n[i,k]*y[i,k] # total caries = (no. of patients) * (mean no. caries)theta[i,k] <- lambda[i,k]*n[i,k]*time[i] # failure rate * exposurer[i,k] ~ dpois(theta[i,k]) # Poisson likelihoodlog(lambda[i,k]) <- mu[i] + delta[i,k] + beta[i,k] * bias[i] # linear predictor# Deviance for Poissondev[i,k] <- 2*((theta[i,k]-r[i,k]) + r[i,k]*log(r[i,k]/theta[i,k]))}resdev[i] <- sum(dev[i, 1:na[i]]) # summed residual deviance contribution for this trialfor (k in 2:na[i]){ # LOOP THROUGH ARMS# model for bias parameter betabeta[i,k] ~ dnorm(mb[i,k], Pkappa)mb[i,k] <- A[C[i,k]]# trial-specific RE distributionsdelta[i,k] ~ dnorm(md[i,k], taud[i,k])md[i,k] <- (d[t[i,k]] - d[t[i,1]]) + sw[i,k] # mean of RE distributions (with multi-arm trial correction)taud[i,k] <- tau *2*(k-1)/k # precision of RE distributions (with multi-arm trial correction)w[i,k] <- delta[i,k] - d[t[i,k]] + d[t[i,1]] # adjustment for multi-arm RCTssw[i,k] <-sum(w[i,1:k-1])/(k-1) # cumulative adjustment for multi-arm trials}}totresdev <- sum(resdev[]) # Total Residual Devianced[1] <- 0 # treatment effect is zero for reference treatmentfor (k in 2:nt){d[k] ~ dnorm(0,.0001) } # vague priors for basic parameterssd.d ~ dunif(0,10) # vague prior for between-trial SDvar.d <- pow(sd.d,2)tau <- 1/var.d# mean bias: assumptionsA[1] <- 0 # NT v PlA[2] <- b # NT v AA[3] <- b # Pl v AA[4] <- 0 # A v A# bias model prior for variancekappa ~ dunif(0,10)kappa.sq <- pow(kappa,2)Pkappa <- 1/kappa.sq# bias model prior for meanb ~ dnorm(0,.0001)# all pairwise differencesfor (c in 1:(nt-1)) {for (k in (c+1):nt) {lhr[c,k] <- d[k]-d[c]log(hr[c,k]) <- lhr[c,k]}}} # *** PROGRAM ENDS
For model 2 (available in Ch9_RE_Po_Fluorbias2.odc), the only changes required to the code are
# mean bias: assumptions (NT=no treatment, Pl=placebo, # A=active)A[1] <- 0 # NT v PlA[2] <- b[1] # NT v AA[3] <- b[1] # Pl v AA[4] <- b[2] # A v A# bias model prior for meanfor (j in 1:2){b[j] ~ dnorm(0,.0001)}
and the initial values for b need to be given as a vector with two values.
Different indicators of risk of bias, xi, can be explored (Dias et al., 2010c). Here we consider ![]() if allocation concealment is inadequate or unclear and
if allocation concealment is inadequate or unclear and ![]() if allocation concealment is adequate. The first point to note is that convergence for these models is very slow, so long burn-in periods are necessary. Inference should be based on large samples post burn-in.
if allocation concealment is adequate. The first point to note is that convergence for these models is very slow, so long burn-in periods are necessary. Inference should be based on large samples post burn-in.
Table 9.1 shows the results from models 1 and 2. Both of these models give similar model fit according to the posterior mean residual deviance, which is also similar to that obtained from a model without any bias adjustment (278.3). Also, the estimated mean bias terms are close to 0. This suggests that there is no evidence that studies with inadequate or unclear allocation concealment produce results that are different to those with adequate allocation concealment. However, there is some evidence of lack of fit, with a posterior mean residual deviance of approximately 278 compared with 270 data points. Dias et al. (2010c) explored this further using the studies where allocation concealment was rated as unclear. Instead of assuming that these studies were at high risk of bias, they introduced a probability that each unclear study was at high risk of bias. This allows each unclear study to be classified as being either adequate or inadequate based on the predicted probability of being at risk of bias, rather than assuming all unclear studies to be at high risk of bias. See Dias et al. (2010c) for details on how to download the WinBUGS code. Fitting this model gave a posterior mean residual deviance of 274.6 for both models 1 and 2, and the between-study standard deviation falls to 0.12 with 95% CrI (0.10, 0.15). The estimated mean bias for active versus inactive comparisons (placebo or no treatment) was −0.19 with 95% CrI (−0.36, −0.02) for model 1, suggesting that trials with high risk of bias due to allocation concealment (when unclear studies are modelled to have a probability of being at risk of bias) have a tendency to overestimate treatment effects relative to placebo or no treatment. The parameter estimates are on a log rate ratio scale, which translates to an estimated rate ratio of exp(−0.19) = 0.83 for studies at high risk of bias compared with those at low risk of bias. Model 2 gave very similar results, and the estimated mean bias for active versus active comparisons was 0 with 95% CrI (−0.65, 0.57). The model with no active versus active bias (model 1) was therefore preferred on the basis of parameter estimates and model fit. Note that model 1, where the unclear studies have a probability of being at high risk of bias, estimates a mean bias with a credible interval that does not contain 0 (suggesting evidence of bias), whereas when all unclear studies are assumed to be at high risk of bias, we do not find evidence of bias. This is due to a small number of the unclear studies being classified at high risk of bias, whereas the majority of unclear studies are classified as being at low risk of bias by the model. When all are assumed high risk, then the bias effect is masked due to this apparent misclassification.
Table 9.1 Fluoride example: posterior summaries for the bias model using allocation concealment rated as inadequate or unclear as an indicator of high risk of bias.
| Parameter | Model 1, no active vs active bias | Model 2, including active vs active bias |
| Mean bias for active vs placebo or no treatment, b1 | −0.01 (−0.106, 0.094) | −0.01 (−0.114, 0.147) |
| Mean bias for active vs active, b2 | NA | 0.39 (0.145, 0.614) |
| Between-study standard deviation in bias, κ | 0.10 (0.012, 0.200) | 0.11 (0.017, 0.196) |
| Placebo vs no treatment, d2 | −0.22 (−0.358, −0.087) | −0.18 (−0.320, −0.049) |
| Toothpaste vs no treatment, d3 | −0.50 (−0.670, −0.332) | −0.47 (−0.652, −0.291) |
| Rinse vs no treatment, d4 | −0.50 (−0.668, −0.328) | −0.46 (−0.652, −0.283) |
| Gel vs no treatment, d5 | −0.48 (−0.648, −0.321) | −0.47 (−0.652, −0.295) |
| Varnish vs no treatment, d6 | −0.61 (−0.807, −0.424) | −0.78 (−1.007, −0.556) |
| Between-study standard deviation in treatment effects, σ | 0.19 (0.130, 0.245) | 0.18 (0.124, 0.235) |
| Posterior mean residual deviancea | 278.2 | 277.9 |
Results are shown for (i) model 1 where a common mean bias term is assumed for the active versus placebo or no-treatment comparisons and a zero mean bias for active versus active comparisons and (ii) model 2 where a common mean bias is assumed for active versus active comparisons that may be different to the common mean bias assumed for active versus placebo or no treatment. Results shown are posterior means and 95% credible intervals and treatment effects are interpreted as log rate ratios.
a Compare to 270 data points. Values much larger than this indicate some lack of fit. The posterior mean residual deviance in a model with no bias adjustment is 278.3.
Figure 9.2 shows the estimated log rate ratios from the unadjusted network meta-analysis model (solid lines) and from model 1 where the unclear studies have a probability of being at risk of bias (dashed lines). It can be seen that the main impact of the bias adjustment is to move the treatment effect estimates towards the null effect, suggesting that studies at high risk of bias slightly overestimate treatment effects. This effect is especially strong for varnish, where there were only a few trials making comparisons with placebo or no treatment, all of which had inadequate or unclear allocation concealment. The bias-adjusted results also show that there is evidence of a placebo effect in these trials, likely to be due to the placebo involving brushing or other treatment of the teeth, albeit without fluoride. The bias-adjusted results show that all of the fluoride interventions are similar in effectiveness and are clearly better than no treatment and likely better than placebo. The bias-adjusted analysis also shows that there is no reason to believe varnish is more effective than the other fluoride interventions, as was found in the non-adjusted analysis.

Figure 9.2 Fluoride example: estimated posterior means and 95% credible intervals for log-hazard ratios compared with no treatment for the following: Pl, placebo; T, toothpaste; R, rinse; G, gel; V, varnish. Results from a network meta-analysis model with no bias adjustment shown with diamonds and solid lines. Circles and dotted lines represent results from bias adjustment model 1 with common mean bias term for the active versus placebo or no-treatment comparisons, zero mean bias for active versus active comparisons, a probability of being at risk of bias in studies rated as unclear. The vertical dotted line represents no effect.
9.3.2 Extensions
The method can in principle be extended to include syntheses that are mixtures of trials and observational studies, but this does not appear to have been attempted yet. It can also be extended to any form of ‘internal’ bias. A key advantage of the approach is that it adjusts for bias using only the randomised controlled trials that are included in the network; however there is still low power to estimate bias and results often have a high level of uncertainty. Because the underlying bias models in this section and the previous one are the same, it would be perfectly feasible to combine them to estimate the bias within the network meta-analysis, but using prior distributions based on external evidence. We are not aware that anyone has done this, which is an area for future work. Like the methods described in Section 9.2, these methods may be considered by some as semi-experimental. There is certainly a great need for further experience with applications, and there is a particular need for further meta-epidemiological data on the relationships between the many forms of internal bias that have been proposed (Dias et al., 2010a). However, they appear to represent reasonable and valid methods for bias adjustment and are likely to be superior to no bias adjustment in situations where data are of mixed methodological rigour. At the same time, the method is essentially a meta-regression based on ‘between-study’ comparisons. There is no direct evidence for a ‘causal’ link between the markers of study quality and the size of the effect. It is therefore important to avoid using the method for small datasets and to establish that the results are statistically robust and not dependent on a small number of studies.
In the following text we describe examples of estimation and adjustment for specific types of bias that have been developed.
9.3.3 Novel Agent Effects
Salanti et al. (2010) used a model similar to that described previously to explore the existence of novel agent effects, where relative effects of new treatments are overestimated due to optimism bias (Song et al., 2008), conflicts of interest or other mechanisms. Their model is the same as equation (9.3) but with the bias indicator x depending on treatment arm k as well as study i:
where xik = 1 if the treatment on arm k is newer than the treatment on arm 1 in study i.
Salanti et al. (2010) applied their model to three network meta-analyses of chemotherapy and other non-hormonal systemic treatments for cancer (ovarian, colorectal, and breast cancer), further assuming that the novel agent bias was exchangeable across cancers. They found some evidence of novel agent effects, with hazard ratios for overall survival exaggerated by 6%, 95% CrI (2%, 11%) for newer treatments, although this had little effect on treatment rankings. Note that overall survival is an objective measure, and we would expect to see bigger effects on subjective outcomes (Savovic et al., 2012b). Salanti et al. (2010) assumed that the novel agent effect occurs regardless of other indicators of risk of bias. However, it is possible that effects are stronger in studies at high risk of bias according to other indicators. It would be interesting to extend this model to explore possible interactions.
9.3.4 Small-Study Effects
A particularly interesting application is ‘small-study bias’, where the idea is that the smaller the study, the greater the bias. One possible mechanism that might generate small-study effects is publication bias, where negative findings from small studies are less likely to get published than positive findings, but large studies are likely to get published regardless of the results. This mechanism leads to an overestimation of treatment effect in the smaller studies, due to the ‘missing’ small negative studies. The ‘true’ treatment effect can therefore be conceived as the effect that would be obtained in a study of infinite size. This, in turn, is taken to be the intercept in a regression of the treatment effect against the study variance. This model has the same form as equation (9.3) where xik is set equal to the variance of the relative effect estimate. Moreno et al. (2009a, 2009b) show that, in the context of antidepressants, the bias-adjusted estimate from this approach closely approximates the results found in a simple meta-analysis based on a register of prospectively reported data. Once again, in larger networks, some care would need to be exercised in how to code the direction of bias in ‘active–active’ studies. Chaimani et al. (2013b) found that in their collection of 32 star networks, imprecise studies were associated with larger treatment effects and tended to be those with inadequate conduct.
One explanation for small-study effects is ‘publication bias’, where studies that show statistically significant findings are more likely to be published and identified in a systematic review. Copas and Shi (2001) present a selection model to explore sensitivity of results to publication bias in pairwise meta-analysis, and these models have been extended to network meta-analysis (Chootrakool et al., 2011; Trinquart et al., 2012; Mavridis et al., 2013, 2014), including networks with loops (Mavridis et al., 2014). Trinquart et al. (2012) have compared the performance of regression and selection bias models applied to published trials on antidepressants, using the US Food and Drug Administration database as a gold standard representing the totality of the evidence. They found that both adjustment methods corrected for publication bias, but more successfully for some drugs than others.
9.3.5 Industry Sponsor Effects
It has been suggested that trials sponsored by industry tend to favour the product of the sponsor (Gartlehner and Fleg, 2010; Gartlehner et al., 2010; Flacco et al., 2015). Naci et al. (2014a) used a meta-regression approach to explore the effects of trials with and without industry sponsorship, in a network meta-analysis of statins for low-density lipoprotein (LDL) cholesterol reduction. They assumed a common mean bias term for all statins relative to placebo and found no evidence of industry sponsor effects in trials of statins for LDL cholesterol reduction. However, there were differences in effectiveness according to the dose of statin given, which may explain why the previous work, not accounting for dose variability, had found an association between treatment effect and industry sponsorship. It appears that the frequently reported tendency of industry trials to report results in favour of the sponsored product (Ioannidis, 2005; Bero, 2014) is due to the choice of comparator rather than bias due to trial conduct, analysis and reporting.
9.3.6 Accounting for Missing Data
Missing outcome data is common in RCTs and can occur for a variety of reasons, many of which can lead to biased effect estimates if not adjusted for (Little and Rubin, 2002). Methods to adjust for missing data in RCTs typically centre around imputation, where other observed variables are used to predict outcomes in those that are missing (Little and Rubin, 2002). The challenge in pairwise and network meta-analysis is that we usually only have summary-level data available and so cannot use imputation methods at the individual level, although methods have been described if individual patient data are available (Burgess et al., 2013). If all of the RCTs included in the meta-analysis have reported effect estimates adjusted for missing data, then these can be combined in meta-analysis; however adjustments need to be made if the missing proportion depends on effect size (Yuan and Little, 2009).
In most meta-analyses we do not have adjusted estimates from the RCTs and so must attempt to account for missing data within the meta-analysis. Higgins et al. (2008b) proposed the informative missingness odds ratio (IMOR) as a measure to adjust for bias arising from missing data on a binary outcome. The IMOR is defined as the odds of an event in the missing individuals divided by the odds of an event in the observed individuals and can depend on study and treatment arm. If the odds of an event is the same for the observed and the missing individuals, then the IMOR = 1 and the data are taken at face value. If the IMOR is not equal to 1, then it can be used to adjust the estimate for that study and arm. White et al. (2008a) suggest using prior information on the IMORs to reflect departures from ‘missing at random’ and explore robustness of results to the prior assumptions in a sensitivity analysis (Higgins et al., 2008b; White et al., 2008a). This approach has been extended to network meta-analysis (Spineli et al., 2013) and also to continuous outcome measures by defining the informative missingness difference of means and the informative missingness ratio of means (Mavridis et al., 2015).
In the absence of any prior information on the missingness mechanism, it is important to reflect the additional uncertainty in effect estimates as a result of the missing data. Gamble and Hollis (2005) proposed down-weighting studies where ‘best-case’ and ‘worst-case’ analyses give wide limits on treatment effect to reflect the uncertainty associated with missing data. Turner et al. (2015a) instead put a flat prior distribution on the probability of an event in the missing individuals to reflect our uncertainty on this.
There have been a few attempts to estimate missingness parameters within a meta-analysis. White et al. (2008b) proposed a 1-stage hierarchical model for the IMORs in an attempt to ‘learn’ about the IMORs from the observed data, although found there was limited ability to do so in a pairwise meta-analysis. Spineli et al. (2013) used a network meta-analysis model to estimate the IMOR but again found that the data were barely sufficient to identify the IMOR parameters. In random treatment effects models, there is almost complete confounding between the random treatment effect and the random IMOR elements. In fixed treatment effects models, particularly when some trials have only small amounts of missing data, then the data are sufficient to identify missingness parameters and ‘learning’ can take place. Turner et al. (2015a) present a general framework for a Bayesian 1-stage estimation for a given definition of the missingness parameter (e.g., IMOR, probability of an event in the missing individuals, etc.) that allows one to select the way missingness is parameterised, facilitating the use of informative prior distributions. They have only applied this to pairwise meta-analysis, but the extension to network meta-analysis is natural, which will provide a greater potential to learn about the missingness parameter, because of the ‘spare’ degrees of freedom generated by the consistency equations. This is an important area for further developments.
9.4 Elicitation of Internal and External Bias Distributions from Experts
Turner et al. (2009) proposed a method to elicit distributions for biases from experts for the purpose of bias adjustment. The method is conceptually the simplest of all bias adjustment methods, applicable to trials and observational studies alike. It is also the most difficult and time-consuming to carry out. One advantage may be that it can be used when the number of trials is insufficient for meta-regression approaches (Chapter 8). Readers are referred to the original publication for details, but the essential ideas are as follows. Each study is considered by several independent experts using a predetermined protocol. The protocol itemizes a series of potential internal and external biases, and each expert is asked to provide information that is used to develop a bias distribution. Among the internal biases that might be considered are selection biases (in observational studies), non-response bias, attrition bias and so on. A study can suffer from both internal and external biases. When this process is complete, the bias information on each study from each assessor is combined into a single bias distribution. The assessor distributions are then pooled mathematically. In the original publication the mean and variance of the bias distributions are statistically combined with the original study estimate and its variance to create what is effectively a new, adjusted estimate of the treatment effect in that study. The final stage is a conventional synthesis, in which the adjusted treatment effects from each study, and their variances, are treated as the data input for a standard pairwise meta-analysis, indirect comparison or network synthesis. The methods in Chapters 2 and 4 can then be applied to the adjusted study-specific estimates.
This methodology (Turner et al., 2009) in its full form requires considerable time and care to execute. The key idea of replacing a potentially biased study estimate with an adjusted estimate based on expert opinion regarding bias is one that can be carried out in many ways and with a degree of thoroughness that is commensurate with the sensitivity of the overall analysis to the parameters in question. There is an important conceptual difference between this approach and the others discussed in this chapter. As we noted in the previous section, under some circumstances data on treatment effects in unbiased studies can provide indirect information on the biases in other studies. However, this does not happen if the bias information is used in effect to ‘adjust’ the data. A slight modification of the Turner et al. (2009) method would be to combine the original data and the bias distributions in a single MCMC simulation under the consistency model. This is an exciting area for further development.
9.5 Summary and Further Reading
RCTs may produce biased estimates of treatment effect in the population we are interested in making treatment recommendations for, if there are interactions between treatment effects and trial characteristics that are unaccounted for. A distinction is made between bias resulting from issues with internal and external validity of an RCT. Methods to deal with issues with external validity include meta-regression to adjust for bias due to difference in covariates between trial and decision populations and adjustment for bias using prior distributions elicited from experts. Methods to deal with issues of internal validity include use of external information, such as collections of previous meta-analyses, to adjust and down-weigh evidence rated at high risk of bias, estimation of bias within a network meta-analysis and adjustment for bias using prior distributions elicited from experts or other sources. Markers of lack of internal validity that have been explored include issues with the randomisation procedure, whether there is adequate concealment of the allocation of individuals to treatments, lack of blinding or double-blinding, novel agent effects, small-study effects (including publication bias), industry sponsor effects and missing outcome data. Bias adjustment methods in meta-analysis are still evolving and should be considered as exploratory. However, we would argue that an attempt to adjust for bias will lead to more valid results than simply ignoring it. Bias adjustment models should at least be conducted as a sensitivity analysis, alongside analyses that omit studies at high risk of bias.
A general model for heterogeneity that encompasses bias due to both internal and external validities can be found in Higgins et al. (2009), but it is seldom possible to determine what the causes of heterogeneity are or how much is due to true variation in clinical factors and how much is due to other unknown causes of biases.
In theory, the methods described here for bias adjustment could be applied to generalised evidence synthesis (Prevost et al., 2000; Welton et al., 2012), where both RCT and observational evidence are pooled. In particular the method of eliciting prior distributions for bias due to issues with internal and external validity has been applied to a mixture of RCT and observational studies (Turner et al., 2009).
9.6 Exercises
- 9.1 For the fluoride example, fit the bias adjustment model 1 (zero bias in active vs active comparisons) and model 2 (common mean bias in active vs active trials) using the risk of bias indicator:
 if allocation concealment is inadequate or the trial is not double blind, and
if allocation concealment is inadequate or the trial is not double blind, and 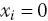 otherwise. The data are available in Ch9_FlourData.xlsx in the tab ‘FluorData_allocORblind’. You can use the code given in Ch9_RE_Po_Fluorbias1.odc and Ch9_RE_Po_Fluorbias2.odc, making changes to the data. Compare the posterior mean residual deviance with that from the model with no bias adjustment (178.3) and look at estimates of mean bias. Is there any evidence of bias according to this indicator for
otherwise. The data are available in Ch9_FlourData.xlsx in the tab ‘FluorData_allocORblind’. You can use the code given in Ch9_RE_Po_Fluorbias1.odc and Ch9_RE_Po_Fluorbias2.odc, making changes to the data. Compare the posterior mean residual deviance with that from the model with no bias adjustment (178.3) and look at estimates of mean bias. Is there any evidence of bias according to this indicator for
- Active versus active comparisons?
- Active versus placebo or no treatment?
- 9.2 *For the fluoride example, fit the bias adjustment model 1 (zero mean bias in active vs active comparisons) using the risk of bias indicator:
 if allocation concealment is inadequate, and
if allocation concealment is inadequate, and  otherwise, using an informative prior distribution for
otherwise, using an informative prior distribution for  , and
, and  (based on (Savovic et al., 2012a), assuming a subjective outcome). You will need to adjust the code available in Ch9_RE_Po_Fluorbias1.odc to add in the informative prior distribution (the data and initial values are unchanged). Remember that WinBUGS parameterises the normal distribution using the precision (=1/(0.12) here). How does adding in the informative prior distributions change the results?
(based on (Savovic et al., 2012a), assuming a subjective outcome). You will need to adjust the code available in Ch9_RE_Po_Fluorbias1.odc to add in the informative prior distribution (the data and initial values are unchanged). Remember that WinBUGS parameterises the normal distribution using the precision (=1/(0.12) here). How does adding in the informative prior distributions change the results?