
Chapter 16 Tuning eDirectory
Other than running eDirectory on a fast CPU, using lots of RAM, using fast disk drives in RAID configuration, and so on, there are also a few noteworthy tricks you can perform from a software perspective to enhance eDirectory’s performance without spending additional money. Because Novell’s LDAP server uses eDirectory as the back-end database, its performance can be affected by eDirectory’s (for example, memory management [cache settings], indexes, replica placement, and search limits).
Certain portions of eDirectory are already configured to take advantage of the presence of multiple processors in the operating environments. The core directory, security, encryption, and LDAP modules are multiprocessor enabled. The following sections discuss the cache settings and indexes in depth. But first, this chapter takes a brief look at replication latency.
eDirectory uses a slow-but-sure convergence algorithm to replicate changes from a replica server to its peers in a replication ring. A replica server can manage only a single Directory Information Base (DIB), but a DIB may contain replicas of multiple partitions. Replication uses a batch update mechanism. The period for which changes are accumulated in a replica server is adjustable, from only a few seconds to a few hours, but it defaults to 30 minutes for NDS 6 and 60 minutes for NDS 7 and higher; this is known as the “heartbeat” interval.
Changes to attributes (such as password) that are flagged Sync Immediate will be scheduled for immediate synchronization. A background thread that would yield or postpone its operation if a request for a Create, Modify, or Delete operation were received handles synchronization operations. This causes a delay, or latency, in replication. Fortunately, in many instances, partitioning can minimize this delay.
You can partition a tree such that update operations are spread across multiple partitions. Placing these volatile partitions on different servers helps to minimize the peak update load because the partitions are now distributed. For example, if a tree has three containers that are volatile (whose subordinate objects undergo modifications frequently), you should isolate each container into a partition and place the partitions on separate servers. The larger the peak update rate, the smaller the replica ring; but bear in mind that a ring should be designed with at least two servers (three is recommended) for fault tolerance reasons. If the entire server farm is front-ended by a load-balancing switch, you should configure the switch to direct all requests to the primary servers (ones holding the Master replicas) and fail over to the secondary.
NOTE
The By Server synchronization method (discussed in the “Multithreaded Synchronization” section in Chapter 6, “Understanding Common eDirectory Processes”) may also help reduce the replication latency by outbounding multiple partitions to multiple unique servers at one time.
In versions of directory services (DS) prior to 7.55, any caching done was mainly based on NetWare’s caching of the various database files (for example, *.NDS files). However, DS 7.55 and later versions of DS.NLM included the ability of caching DS objects in memory, which increases performance.
Versions 7.55 and greater of DS.NLM will, upon loading, calculate the cache limit based on the amount of free memory (cache buffers) that the server currently has. In these versions, DS determines three values: MaxMemory, which is the amount of free memory at the time; MemoryLimit, which is equal to 20% of MaxMemory; and BackoffPoint, which is 80% of MemoryLimit. For instance, on a server with 200MB of available memory at DS.NLM load time, MemoryLimit is set to 40MB (20% of 200MB) and BackoffPoint is 32MB (80% of 40MB).
As objects are being referenced, they are cached in memory. When the cache size reaches the BackoffPoint value, DS.NLM replaces the oldest objects in the cache with new objects that are coming in. Also, a cache cleaning service is scheduled to actually free up the memory within the cache that represents the oldest objects. If memory cannot be allocated for the cache, DS.NLM immediately schedules the cache cleaning service.
When required, you can manually configure DS.NLM for a lower or higher value for MemoryLimit; the BackoffPoint value cannot be changed and will always be 20% of whatever value you set MemoryLimit to be. You use the SET DSTRACE command to set the limit, as follows:
SET DSTRACE=!Mvalue_in_MB
For example, SET DSTRACE=!M64 will permanently configure DS.NLM (the value is stored in the database and so is persistent between server restarts) to set the MemoryLimit to 64MB instead of the 20% of MaxMemory value. Therefore, the value for BackoffPoint will be 80% of 64MB, or 51MB. This will give you enough cache for approximately 13,000 objects.
TIP
Do not be concerned if there are 100,000 objects in the tree but your server can only cache 13,000 objects. Remember that the cached objects represent the number of objects being accessed within the same time period (meaning that Objects A and B are both being used within seconds of each other). A good estimate to target for would be to cache 5% of the total objects in the tree.
Novell recommends that no more than 40% of available memory be used for DS caching if the server is an application server. However, if the server is used for DS exclusively, up to 80% may be used.
Instead of caching the whole NDS object, NDS 8 employed block caching from the beginning. The block (or page) cache is used to increase the performance of reading a block of data from the DS database. Before accessing a block from the database, NDS/eDirectory searches the block cache stored in memory for the requested block of data. If it is found, a cache hit occurs, and the data can be retrieved from memory rather than from disk. If the data is not found in the block cache, a cache fault occurs, and the record must be retrieved from disk. The record is then added to the block cache to prevent subsequent cache faults on the same block of data.
NOTE
The default database block size is 4KB. However, at times you might find that the block size is 5KB on Windows servers. You can check the block size on your server by selecting Agent Configuration, Database Cache in NDS iMonitor. You can see how to change the database block size in the “Changing Database Block Size” section, later in this chapter.
You can specify an upper block cache limit to regulate the amount of memory that eDirectory uses for the cache. The default block cache limit is 8MB of RAM. Using the SET DSTRACE command on the NetWare server console can change the hard limit of this cache size. For example, the following command permanently increases the database cache limit to 80MB:
SET DSTRACE=!MB83886080
WARNING
You can also use SET DSTRACE=!MKB_in_hex to increase the database cache limit. As discussed in the previous section, in NDS 7, the value for the SET DSTRACE command is in megabytes. In NDS 8, however, the expected value is in kilobytes and in hexadecimal notation. Consequently, administrators who are familiar with NDS 7 frequently make the error of entering the wrong value in NDS 8 and higher environments. For example, when trying to specify a cache limit of 64MB, an administrator might wrongly use the command SET DSTRACE=!M64, which allocates only 100KB of memory for eDirectory caching. (The correct command is SET DSTRACE=!M10000.) Because of this easy confusion, we suggest that you always use the !MB option instead of the !M one.
Instead of using the DSTRACE command, you can manually create a text file named _NDSDB.INI in the SYS:\_NETWARE directory and put in a line like the following:
cache=83886080
WARNING
Be careful that you don’t put any whitespace around the = sign. Whitespace prevents the value from being set.
To maximize the amount of memory available for DS, Novell suggests using the following formula to calculate the maximum amount of memory needed:
MemoryForDSDIB = (SizeOfDIBSet + (SizeOfDIBSet × 4))
where SizeOfDIBSet equals the number of megabytes for all NDS.* files found in the DIB directory; this excludes any of the stream files, such as login scripts.
You should check the calculated amount of memory the database might need to see whether it exceeds the Novell-recommended 40% limit (for an application server; 80% for a dedicated DS server) by dividing MemoryForDSDIB by the total server memory and multiplying that amount by 100. If the result does exceed the limit, you might want to adjust the multiplier of 4 down to 2 (do not go below 2 on this multiplier). If you still exceed the limit, you should either get more memory or you can expect some performance degradation to occur.
Entry caching was added starting with NDS 8.73 and for eDirectory 8.5 and later. The entry (or record) cache contains logical entries in the eDirectory tree rather than physical blocks of records from the eDirectory database. While traversing the database, eDirectory searches the entry cache stored in memory for the next requested entry. If the entry is found, a cache hit occurs, and the data can be retrieved from memory rather than from disk. If the data is not found in the entry cache, a cache fault occurs, and the entry record must be retrieved from the block cache (and from disk, if the required block is not in the block cache). The record is then added to the entry cache to prevent subsequent cache faults on the same entry record.
Although there is some redundancy between the block and entry caches, each cache is designed to boost performance for different operations. The block cache is most useful for update operations, whereas the entry cache is most useful for operations that browse the eDirectory tree by reading through entries, such as name resolution operations. Both the block and entry caches are useful in improving query performance. The block cache speeds up index searching, and the entry cache speeds up the retrieval of entries referenced from an index. (eDirectory indexes are discussed later in this chapter.)
NOTE
eDirectory caches information for the entire block—which may be more than that asked for in the block cache. However, it will cache only the entry information asked for in entry cache. Stream files (such as login scripts) are only cached on demand and are cached in the file system cache and not in the eDirectory cache.
For instance, if eDirectory is asked for an octet attribute that is only 4 bytes in size, it will cache the entire block, usually 4KB, in the block cache. However, only the entry husk (which includes the entry’s ID), not the entire entry, and attribute asked for are placed in the entry cache. (An entry husk is similar to a pointer in that it carries only enough information to link it to the real object.)
With an entry cache and a block cache, the total available memory for caching is shared between the two caches. The default is an equal division (50% each). To maintain the amount of block cache available in versions of NDS prior to 8.73, you need to double the total cache size for eDirectory (because of the entry cache you now have). If you use the cache to boost LDIF-import performance, for example, you can either double the total cache size or change the default cache settings (as discussed later in this chapter).
The more blocks and entries that can be cached, the better the overall performance will be. The ideal configuration is to cache the entire database in both the entry and block caches. However, this is usually not possible especially when you have extremely large databases. Generally, the rule of thumb is to try to get as close to a 1:1 ratio of block cache to DIB set size as possible. For the entry cache, you should try to get close to a 1:2 or 1:4 ratio. For the best performance, you should exceed these ratios where possible.
eDirectory provides two methods for controlling cache memory consumption: a dynamically adjusting limit (Dynamic Adjust mode) and a hard memory limit (Hard Limit mode). The Hard Limit mode is the method that versions of eDirectory prior to 8.5 use to regulate memory consumption. You set a hard memory limit by specifying one of the following:
![]() A fixed number of bytes
A fixed number of bytes
![]() A percentage of total physical memory
A percentage of total physical memory
![]() A percentage of available physical memory
A percentage of available physical memory
When a hard memory limit is specified in percentages, it is translated to a fixed number of bytes based on the amount of memory at the time the setting is made.
The Dynamic Adjust mode causes eDirectory to periodically adjust its memory consumption in response to the change in memory usage by other processes. You specify the limit as a percentage of available physical memory. Using this percentage, eDirectory recalculates a new memory limit at fixed intervals. The new memory limit will be the percentage of physical memory available at the time.
Along with this percentage, you can set maximum and minimum thresholds. Such a threshold is the number of bytes that eDirectory will adjust to. It can be set as either the number of bytes to use or the number of bytes to leave available. The minimum threshold default is 16MB, and the maximum threshold default is 4GB.
If the minimum and maximum threshold limits are not compatible with one another, the minimum threshold limit is followed. For example, suppose you specified the following settings:
![]() Minimum threshold: 8MB
Minimum threshold: 8MB
![]() Percentage of available physical memory to use: 75%
Percentage of available physical memory to use: 75%
![]() Maximum threshold: Keep 10MB available
Maximum threshold: Keep 10MB available
When eDirectory adjusts its cache limit, there is 16MB of available physical memory. eDirectory calculates a new limit of 12MB (75% of 16MB). eDirectory then checks to see whether the new limit falls within the range of the minimum and maximum thresholds. In this example, the maximum threshold requires that 10MB remain available, so eDirectory lowers the limit to 6MB (leaving 10MB available). However, the minimum threshold is 8MB, so eDirectory resets the final limit to 8MB.
You can specify upper limits for the block cache and the entry cache separately. If no previously permanent cache settings are found when the DS agent (DSA) starts up, the cache defaults to a hard limit of 16MB for the first 10 minutes. Because the DSA usually loads when a server is restarted, this default behavior allows other applications to load and request system resources first. After 10 minutes, the behavior (by default) switches to Dynamic Adjust mode, based on the amount of available memory.
With the dynamically adjusting limit, you can also specify the interval length at which the memory limit is recalculated. The default interval is 15 seconds.
NOTE
The shorter the recalculation interval, the more the memory consumption is based on current conditions. However, shorter intervals are not necessarily better because the percentage recalculation will create more memory allocation and freeing.
If the server does not have a replica, and no dynamic adjustments are specified, a hard memory limit of 16MB (with 8MB for the block cache and 8MB for the entry cache) is used. On the other hand, if the server contains one or more replicas, the default Dynamic Adjust mode uses a limit of 51% of available memory, with a minimum threshold of 8MB and a maximum threshold of keeping 24MB available to the operating system (that is, total available memory minus 24MB).
WARNING
Novell’s tuning guides recommend very large caches (four times the DIB size). On machines with gigabytes of RAM, this is likely to lead to instability if it is not capped to 2GB. At the time of this writing, eDirectory is a 32-bit process that has a 4GB limit in its virtual address space. If you set the cache to 2GB or more, during peaks of high activity, the address space may exceed the operating system limits for a 32-bit process and lead to its abrupt termination (and result in core dumps or abends). On Linux 2.4 kernels, the process may run out of virtual address map entries and freeze.
When you’re working on high-end tree deployments, you should set the cache to an absolute figure of 1.5GB or less. You should not use dynamic or hard settings.
You can use either the Hard Limit mode or the Dynamic Adjust mode, but you can only use one at a time because the two are mutually exclusive. The last method selected will always replace any prior settings. As discussed in the following sections, there are three ways you can set the cache limits:
![]() By using the
By using the _NDSDB.INI file
![]() By using the
By using the SET DSTRACE command
![]() By using NDS iMonitor
By using NDS iMonitor
At startup, eDirectory looks for the _NDSDB.INI file in the directory where DIB files are stored. This file is a simple text file that can be created or modified with any text editor.
NOTE
The _NDSDB.INI file is read only when eDirectory starts up. Therefore, any changes made after eDirectory is running will not take effect until the eDirectory module has been restarted. On the other hand, no restart is necessary if the changes were made via DSTrace or NDS iMonitor.
Cache settings made via DSTrace and NDS iMonitor will automatically be populated in the _NDSDB.INI file.
The following is the syntax for cache memory settings for eDirectory:
cache=option1,option2,option3,...
WARNING
Do not include any whitespace on either side of the = sign or between the options. Whitespace prevents the value from being set.
NOTE
None of the commands and options in _NDSDB.INI are case-sensitive, and they can be specified in any order.
This command sets a hard memory limit or dynamically adjusting limit. Multiple (optional) options may be specified, in any order, separated by commas. These are the allowable options:
![]()
DYN or HARD—This option specifies to use a dynamically adjusting limit or a hard limit.
![]()
cache_in_bytes—If just a number is specified, it is taken as the upper cache limit for the Hard Limit mode.
![]()
%:percentage—This option specifies the percentage of available or physical memory to use for cache. (The default is 51%.)
![]()
AVAIL or TOTAL—This option indicates whether the specified percentage value is based on the available physical memory or on total physical memory. (The default is AVAIL.)
![]()
MIN:bytes—This option specifies the minimum number of bytes to use. (The default is 8388608, or 8MB.)
![]()
MAX:bytes—This option specifies the maximum number of bytes to use.
![]()
LEAVE:bytes—This option specifies the minimum number of bytes to leave. (The default is 25165824, or 24MB.)
NOTE
The MIN, MAX, and LEAVE values are ignored for a dynamically adjusting limit. Dynamic Adjust mode always bases its calculation on the available physical memory.
The following example sets a dynamically adjusting cache limit of 60% of available memory, with a minimum of 16MB:
cache=DYN,%:60,MIN:16711680
The following example sets a hard memory limit of 75% of available physical memory, with a minimum of 32MB:
cache=HARD,%:75,MIN:33423360,AVAIL
The following example sets a hard memory limit of 24MB:
cache=25165824
In addition to the cache settings, there are two settings that control the dynamic adjust interval and the interval at which the cache cleaner background process runs:
![]()
CacheAdjustInterval=seconds—The default is 15 seconds.
![]()
CacheCleanupInterval=seconds—The default is 15 seconds.
The final setting allows you to control the percentage split between the entry and block caches:
![]()
BlockCachePercent=percent—The percent value indicates how much of the cache will be used for block caching. This needs to be between 0 and 100 (inclusive). A value of 70 means that 70% of cache memory will be used for the block cache, and the remaining 30% for the entry cache. The Default value is 50.
WARNING
Never set the BlockCachePercent value to zero because that would seriously degrade eDirectory performance. Novell also recommends that no more than 75% of the cache memory should be allocated to either the entry cache or the block cache for typical day-to-day operations.
TIP
Novell recommends setting the BlockCachePercent value to between 70% and 90%, depending on the proportion of updates in the total operations. And you should set it to 90% for operations such as bulk creations or deletions; you should set it to 50% if you do not expect too many update bursts.
eDirectory 8.7 introduced a new method for specifying the maximum dirty cache (MaxDirtyCache) and the low dirty cache (LowDirtyCache) for the eDirectory cache. By default, the value of MaxDirtyCache is unlimited (that is, using all of the available eDirectory cache; flush the dirty cache when this limit is reached) and the LowDirtyCache value is set to zero (that is, don’t flush the dirty cache if it is less than this value). Setting the amount of dirty cache at any given instant below a particular value helps to even out the disk writing instead of burdening the checkpoint thread in the forced mode, which essentially writes the whole cache to the disk, thereby creating an I/O bottleneck.
NOTE
A checkpoint occurs when all dirty cache buffers are used and eDirectory must flush them to disk.
Normally, you don’t have to set the MaxDirtyCache and LowDirtyCache values. However, if you are bulk-loading to populate, depopulate, or modify the DS objects, you should set them in the _NDSDB.INI file, as follows:
MaxDirtyCache=value_in_bytes
LowDirtyCache=value_in_bytes
Then you should restart the DSA in order for the settings to take effect. You should make sure to take them out after your bulk-load operation.
WARNING
Novell’s testing suggests that for platforms other than HP/UX, setting MaxDirtyCache and LowDirtyCache is useful only for bulk-loading for less than 1.5 million objects. For higher values, there might be performance degradation if these values are changed from the defaults.
NOTE
There is no “hard value” recommended for the dirty cache settings because they very much depend on the server hardware. On most systems, the MaxDirtyCache value is between 1MB and 10MB, while 20MB may be used for fiber channel storage area networks. On HP/UX, setting MaxDirtyCache to 340MB and LowDirtyCache to 335MB worked well for all scenarios tested.
You can use the following procedure to determine what the MaxDirtyCache setting for your server may be. First, measure the random I/O write speed to the disk. Set the MaxDirtyCache value such that all modified buffers in a 3-minute interval can be flushed to the DIB volume in 10 seconds (10,000 ms) or less. Set the value of LowDirtyCache to about half that of MaxDirtyCache. For example, if the random write speed is 10 ms per block (4KB), you set MaxDirtyCache to (10,000ms × 4KB/10), or 4,000KB. Alternatively, you can use a simple trial-and-error method: You can set the MaxDirtyCache value to 5MB and observe the max update response time during a burst of updates. Then you can adjust this value upward until the response time is acceptable.
The syntax for setting eDirectory cache by using DSTrace is very similar to that used in the _NDSDB.INI file:
SET DSTRACE=!Moption1,option2,option3,...
DSTrace also uses the same list of options as used in _NDSDB.INI, with two exceptions and one addition:
![]()
!MBcache_in_bytes specifies the upper cache limit for the Hard Limit mode.
![]() You cannot adjust
You cannot adjust CacheAdjustInterval, CacheCleanupInterval, BlockCachePercent, or any of the dirty cache parameters via DSTrace. They need to be specified using the _NDSDB.INI file.
![]() By default, cache settings made using DSTrace are automatically written to the
By default, cache settings made using DSTrace are automatically written to the _NDSDB.INI file. The NOSAVE option prevents that. When this option is not specified, the settings are saved.
The following example sets a dynamically adjusting cache limit of 60% of available memory and a minimum of 16MB, and it saves the settings to _NDSDB.INI (because NOSAVE is not specified):
SET DSTRACE=!MDYN,%:60,MIN:16711680
The following example sets a hard memory limit of 75% of available physical memory and a minimum of 32MB, and it does not save the settings to _NDSDB.INI:
SET DSTRACE=!MHARD,%:75,MIN:33423360,AVAIL,NOSAVE
For instance, if the available system cache memory is 100MB, this command will allocate 75MB of that as a hard memory limit.
The following example sets a hard memory limit of 24MB:
SET DSTRACE=!MB25165824
An easier and more user-friendly, but not necessarily the fastest, method to configure cache settings is to use NDS iMonitor. The appropriate settings are made from the Database Cache Configuration page in NDS iMonitor (see Figure 16.1), which is accessed via the Database Cache link under Agent Configuration.
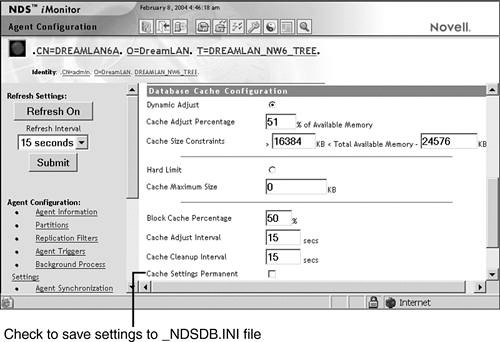
Periodically, you should check the eDirectory cache statistics to ensure that the settings used are effective. You can easily determine the various cache hits and misses (which are generally referred to as cache faults) by looking at the Database Cache statistics information from the Database Cache link under Agent Configuration in NDS iMonitor (see Figure 16.2).

Of particular interest in the cache statistics is the percentage listed next to Requests Serviced from Cache. This number reflects the cache efficiency. The percentage is calculated as (Total Hits) / (Total Hits + Total Faults), where Total Hits is the total for both the block and entry caches. Typically you want to keep this number somewhere in the 90s for best cache efficiency. If this number is below 90%, you might want to look at how much available memory you have in your server and perhaps change the way your cache is allocated (for example, change the percentage of block cache versus entry cache).
By comparing the reported DIB size to the summed maximum size of entry cache and block cache, you can determine how much of the DIB can be cached. The example shown in Figure 16.2 suggests that all of the DIB can be cached because the DIB size is a little over 1MB in size (1,280KB), while the summed maximum cache size is almost 14MB. In this case, you could safely reduce the amount of maximum cache limit and free up the extra RAM for other server processes.
NOTE
Refer to TID #10082323 for a detailed description about the items on the Database Cache page in NDS iMonitor.
TIP
To ensure optimal performance, you should configure your system based on cache hit and cache fault indicators, database size, and memory available. You should not expect to cache the entire database unless you have a small DIB set. You should not expect to see zero cache faults, and you shouldn’t expect the faults to be at zero to have optimal performance in eDirectory.
Versions of NDS prior to NDS 8 relied on a flat-file data store known as Record Manager (RECMAN), which has no real indexing. Anyone with some database experience knows that indexes are essential for efficient and fast database searches. To address this shortcoming, NDS and eDirectory switched away from using a flat-file structure for the data store and now use Flexible Adaptive Information Manager (FLAIM) instead; FLAIM is far more scalable than RECMAN. As a result, NDS 8 and higher allow significantly more information to be held on a single server, without requiring you to partition DS. In addition, database indexes have been introduced to increase performance of any client (including LDAP) accessing the database, especially during attribute value searching.
eDirectory supports the following four types of indexes:
![]() Operational—Operational indexes are required for the proper operation of eDirectory (much like the operational schema definitions) and cannot be modified, suspended, or deleted by administrators. Examples of operational indexes include
Operational—Operational indexes are required for the proper operation of eDirectory (much like the operational schema definitions) and cannot be modified, suspended, or deleted by administrators. Examples of operational indexes include GUID and Obituary.
![]() System—System indexes are required for the proper operation of eDirectory at the database level and cannot be modified, suspended, or deleted by administrators. Examples of system indexes include
System—System indexes are required for the proper operation of eDirectory at the database level and cannot be modified, suspended, or deleted by administrators. Examples of system indexes include Member and Reference.
![]() Auto Added—Auto Added indexes are predefined indexes that are added to the database by eDirectory during the database creation phase. Auto Added indexes are indexes for attributes that are frequently used in queries by applications that access eDirectory.
Auto Added—Auto Added indexes are predefined indexes that are added to the database by eDirectory during the database creation phase. Auto Added indexes are indexes for attributes that are frequently used in queries by applications that access eDirectory. CN is an example of an Auto-added index. In eDirectory 8.7 and above, if any object in the tree has an attribute that has more than 25 values, an Auto Added index for the attribute will be automatically added by the system.
![]() User Defined—User Defined indexes are indexes that have been manually created by the system administrator and are generally used in conjunction with predicate stats for performance-tuning purposes. These indexes can be created, suspended, and deleted as needed.
User Defined—User Defined indexes are indexes that have been manually created by the system administrator and are generally used in conjunction with predicate stats for performance-tuning purposes. These indexes can be created, suspended, and deleted as needed.
TIP
Due to the underlying structure of the eDirectory database, System indexes have faster access times than User indexes.
User-added indexes still increase the performance of LDAP queries, for instance, if the attribute does not meet the criteria to be automatically added. You can use predicate stats (discussed later in this chapter, in the “What Attribute Needs to Be Indexed?” section) to determine which attribute can benefit from a User index.
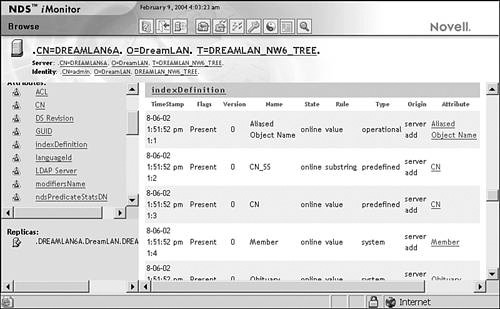
The indexes are defined on a server-by-server basis and are stored in the indexDefinition attribute (syntax type SYN_CI_LIST) of the NCP Server object (see Figure 16.3). Each index on a server applies to the data stored on that server only. Index definitions are not replicated to other servers, but by using ConsoleOne or iManager, you can easily copy an index definition from one server to another server.

Each index is based on one of three types of index matching rules that determine how the index will be matched:
![]() Presence—An index based on the Presence rule simply provides a Boolean value of
Presence—An index based on the Presence rule simply provides a Boolean value of True or False, depending on whether the desired attribute exists. A Presence index optimizes queries with criteria that only involve the presence of an attribute. An example of this type of query is to find all entries with a Login Script attribute.
![]() Value—An index based on the Value rule provides an ordered list of objects based on the value of the specified attributes. A Value index helps with queries in which the criteria involve the entire value or the first part of the value. For example, a Value index helps on both a query to find all entries with a
Value—An index based on the Value rule provides an ordered list of objects based on the value of the specified attributes. A Value index helps with queries in which the criteria involve the entire value or the first part of the value. For example, a Value index helps on both a query to find all entries with a Surname attribute value that is equal to Jensen and a query to find all entries with a Surname attribute value that begins with Jen.
![]() Substring—A Substring index allows for complex searches on characters within the attribute data. A Substring index can be used to optimize queries with criteria that are a subset of a
Substring—A Substring index allows for complex searches on characters within the attribute data. A Substring index can be used to optimize queries with criteria that are a subset of a String value. For example, a query to find all entries with a Surname attribute value that contains der would benefit from this index. The query in this example would return matches for (among others) Derington, Anderson, and Lauder.
Given the large number of possible combinations of attribute data, Substring indexes are costly to create and can require large amounts of resources to keep updated. Therefore, you should keep Substring indexes to a minimum. Indexes based on the Substring rule are by far the most costly index type in eDirectory.
TIP
If your LDAP search performance doesn’t improve after adding a Presence index, you should try using a Value index instead for the same attribute. LDAP will use this index when doing a Presence search.
REAL WORLD
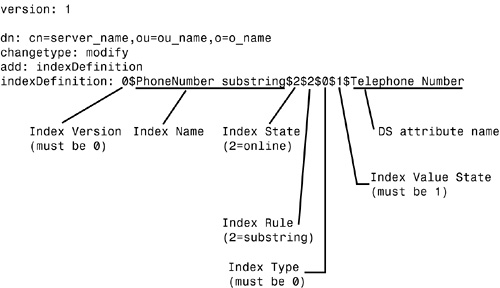
Inside the indexDefinition Attribute
The indexDefinition attribute on the NCP Server object is defined using the SYN_CI_LIST syntax. It is a multivalued attribute. Each value of the attribute holds the following information fields:
![]() Index Version—This field is reserved for future use and has a value of 0.
Index Version—This field is reserved for future use and has a value of 0.
![]() User-defined Index Name—This field is used to identify the index on the Index tab of ConsoleOne. You can define any name that best describes the index (for example, “Group membership” or “Zip code value”). The index name should not contain the
User-defined Index Name—This field is used to identify the index on the Index tab of ConsoleOne. You can define any name that best describes the index (for example, “Group membership” or “Zip code value”). The index name should not contain the $ character because it is used as the delimiter between the data fields within the attribute value. If you use the $ character in the name, you must escape it when working with the indexes via LDAP.
![]() Index State—Possible field values are
Index State—Possible field values are 0 (Suspended), 1 (Bringing Online), 2 (Online), and 3 (Pending Creation). When an index is in the Suspended state, it is not used in queries and is not updated. The Bringing Online state indicates that an index is in the process of being created. The Online state means that the index is up and working. A Pending Creation state means that the index has been defined and is waiting for the background process to begin its operation.
When you’re defining an index using LDAP, you should set this field to 2. The background process automatically changes the state when index building has begun.
![]() Index Rule—Possible field values are
Index Rule—Possible field values are 0 (Value Matching), 1 (Presence Matching), and 2 (Substring Matching).
![]() Index Type—This field indicates whether the index is User-Defined (
Index Type—This field indicates whether the index is User-Defined (0), Auto Added (1)—that is, added on attribute creation—Operational (2)—that is, required for operation—or a System index (3). When you’re defining an index using LDAP, this value should always be set to 0; ConsoleOne automatically sets this field to 0.
![]() Index Value State—eDirectory uses this field to identify the source of the index. Possible values are
Index Value State—eDirectory uses this field to identify the source of the index. Possible values are 0 (Uninitialized), 1 (Added from Server), 2 (Added from Local DIB), 3 (Deleted from Local DIB), and 4 (Modified from Local DIB). Indexes that are predefined or that were added or modified using ConsoleOne are identified with the 2, 3, or 4 values. An index created using LDAP should have this field set to 1.
![]() Attribute Name—This field contains the name of the DS attribute that is being indexed. In many cases, attributes have both a DS name and an LDAP name mapped to it. You should be sure to use the DS name for the attribute. When you create an index by using ConsoleOne or iManager, this is not an issue because you select from the list of known DS attribute names. When you create an index by using LDAP, however, you should make sure to use the appropriate DS attribute name, not the LDAP mapped attribute name. You should be careful to escape any characters that need to be escaped.
Attribute Name—This field contains the name of the DS attribute that is being indexed. In many cases, attributes have both a DS name and an LDAP name mapped to it. You should be sure to use the DS name for the attribute. When you create an index by using ConsoleOne or iManager, this is not an issue because you select from the list of known DS attribute names. When you create an index by using LDAP, however, you should make sure to use the appropriate DS attribute name, not the LDAP mapped attribute name. You should be careful to escape any characters that need to be escaped.
When a new index is defined or the state of an existing index is changed, the operation does not happen immediately. A background process that runs every 30 minutes checks the index definition values against the current index status and then starts any necessary processes. As a result, indexes are built in the background while the directory is still working. When the index is completed, its status changes to Online automatically, and at that point, the users should notice the performance improvement.
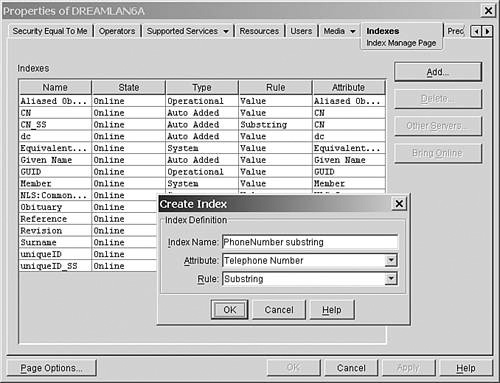
You manage eDirectory indexes by using ConsoleOne or iManager. Because these indexes are associated with the server, in ConsoleOne you access them through the Indexes tab on the Properties page of the NCP Server object. When using iManager, you select eDirectory Maintenance, Index Management, server. Figure 16.4 shows the Create Index dialog box from ConsoleOne. From the Indexes tab in ConsoleOne, you can also change an index’s state between Suspend and Online, delete a User Defined index, or copy an index definition to another server. At the time of this writing, you can use NDS iMonitor only to view the indexes and their states (by selecting Agent Summary, clicking the server name in the Navigator frame, and selecting indexDefinition from the list of attributes), as shown in Figure 16.5.
NOTE
You can also manage the eDirectory indexes by using iManager. In addition, Novell provides a command-line utility called ndsindex for managing eDirectory indexes. In Windows, it is found in NovellNDS, and in Unix, it is in /usr/ldaptools/bin. In NetWare, the utility is NINDEX.NLM, and it is shipped with NetWare 6.5 and later; you can also get a copy of it by downloading the LDAP NDK from Novell DeveloperNet, installing Service Pack 3 for NetWare 6.0, or installing eDirectory 8.7.3.
Other than by using ConsoleOne and iManager, you can define and manage eDirectory indexes via LDAP. The advantage of using LDAP is that an application can define indexes during the installation process. Index definitions can be part of the same LDIF file that applies the required schema extension for the application. The LDIF file shown in Figure 16.6 creates a Substring index (called PhoneNumber substring) for the Telephone Number attribute.
WARNING
Keep in mind the following requirements when creating an eDirectory index via LDAP:
![]() If a
If a $ character is present in the field value, it must be escaped. (To make things easiest, it is best not to use the $ character at all.)
![]() The Index State field (the third field) value must be set to
The Index State field (the third field) value must be set to 2.
![]() The Index Value State field (the sixth field) value must be set to
The Index Value State field (the sixth field) value must be set to 1.
![]() The Attribute Name field (the seventh field) value must specify the DS attribute name, not the LDAP mapped name.
The Attribute Name field (the seventh field) value must specify the DS attribute name, not the LDAP mapped name.
NOTE
You can either use ICE (from within ConsoleOne or from a command line) or the ldapmodify.exe utility included with eDirectory to process an LDIF file.
You can also use LDAP to programmatically change the state of a defined index. You should first query the NCP Server object’s indexDefinition attribute to determine the current Index State value before modifying it. Then you set the Index State field to either 0 to suspend it or 2 to start bringing it online. You should never change the state to either Bringing Online (1) or Pending Creation (3). A background process does this automatically. The following LDIF commands change the state of the PhoneNumber substring index from Online to Suspended:
version: 1
dn: cn=server_name,ou=ou_name,o=o_name
changetype: modify
delete: indexDefinition
indexDefinition: 0$PhoneNumber Substring$2$2$0$1$![]() Telephone Number
Telephone Number
add: indexDefinition
indexDefinition: 0$PhoneNumber Substring$0$2$0$1$![]() Telephone Number
Telephone Number
Although appropriate indexes can significantly improve performance, you should be aware of the cost associated with each index added to the directory. To start with, each addition, deletion, or modification of an entry in the directory causes all indexes affected by the change to be updated. Substring indexes are the most costly (that is, CPU intensive) to create and update, and Presence indexes are the least costly.
The more indexes that exist on a server, the longer the time it takes to perform add, delete, or modify operations. Consequently, indexes should be used judiciously. A secondary side-effect of adding indexes is that each index requires some storage to contain it. Thus, each index adds to the size of the server’s DIB.
TIP
Because each object addition or modification requires touching the defined indexes, having all the indexes active may slow down bulk-addition or bulk-modification of data in the directory. To achieve additional speed during bulk operations, you might first want to suspend some or all of the User Defined indexes, especially the Substring ones. After the operation is completed, you can then bring the indexes online. The indexes will (re-)build in the background and become effective when updating is complete.
So, which attributes should you index? To help make that determination, eDirectory provides the capability to capture search predicate statistics data. Predicate statistics data, often called predicate stats data, is a server-specific history of the objects people search for. You can use predicate stats to identify the most frequently searched for objects and then create indexes to improve the speed of future information access.
NOTE
eDirectory 8.7.3 ships with the following set of predefined indexes that provide basic query functionality:
Aliased Object Name
ldapClasssList
CN
Member
Dc
Obituary
Equivalent to Me
Reference
extensionInfo
Revision
Given Name
Surname
GUID
uniqueID
ldapAttributeList
You can look up the index definitions by using ConsoleOne, iManager, or NDS iMonitor, as discussed earlier in this chapter, in the “Managing eDirectory Indexes” section.
eDirectory internally defines a number of Operational and System indexes (for instance, an index for combined class ID and RDN [ClassID_RDN_IX] and an index for combined parent ID and creation time stamp [ParentID+CTS_IX]). They are not documented, but you can see them referenced in DSTrace (see the “Is Your Query Really Using the Indexes?” section, later in this chapter).
When eDirectory is installed, a special Predicate Stats object is created. The name of the object is the server name, with -PS appended (for example, NETWARE65-PS or WIN2K-NDS-PS). You can create as many objects of this type as you feel necessary, but typically a single object will suffice.
TIP
Although only one Predicate Stats object can be linked with a server at any one time, you can keep multiple Predicate Stats objects for testing of multiple scenarios, for instance.
At the time of this writing, only ConsoleOne can be used to view and manage the predicate stats collected by an NCP Server object. Figure 16.7 shows an example of the ConsoleOne Predicate Data tab.
The Predicate Stats object itself has no configuration option. All its settings are handled through the Predicate Data tab of the NCP Server object.
The following steps describe how to configure the Predicate Stats object and its functionality:
1. In ConsoleOne, right-click the NCP Server object and select Properties from the context menu.
2. Select the Predicate Data tab.
3. Select the Predicate Stats object, using the Browser button if necessary.
4. Click the Properties button to specify the appropriate configuration for the object.
5. Set the update interval, which is the number of seconds to wait before refreshing the data display and writing data to disk. (This updates the ndsPredicateTimeout attribute on the Predicate Stats object.)
6. Click the Advanced button for additional configuration options:
![]() Enable—This option specifies whether the collection process should run in the background or should be turned off. If you turn off data collection (by unchecking the check box), the most recently collected data will either be released from memory (that is, lost) or, if you’ve selected Write to Disk, it will be moved to disk. (This updates the
Enable—This option specifies whether the collection process should run in the background or should be turned off. If you turn off data collection (by unchecking the check box), the most recently collected data will either be released from memory (that is, lost) or, if you’ve selected Write to Disk, it will be moved to disk. (This updates the ndsPredicateState attribute on the Predicate Stats object.)
![]() Display Value Text—This option determines whether the data display will be abbreviated or complete. The abbreviated display provides enough information to determine which predicates are good candidates for indexes. For instance, with Display Value Text selected, the predicate stats data displays one entry for the search
Display Value Text—This option determines whether the data display will be abbreviated or complete. The abbreviated display provides enough information to determine which predicates are good candidates for indexes. For instance, with Display Value Text selected, the predicate stats data displays one entry for the search surname=Smith and another entry for surname=Jones. However, if the option is not selected, the prior two queries will be displayed as two instances of the surname== predicate. (This updates the ndsPredicateUseValues attribute on the Predicate Stats object.)
![]() Write to Disk—This option determines storage location of predicate data, either always in memory or moving from memory to disk—saved to the
Write to Disk—This option determines storage location of predicate data, either always in memory or moving from memory to disk—saved to the ndsPredicate attribute of the Predicate Stats object—as specified in Update Interval. (This updates the ndsPredicateFlush attribute on the Predicate Stats object.)
7. Click OK to update the Predicate Stats object configuration.
For testing purposes, you can shorten the refresh Update Interval setting and perform a few find operations by using ConsoleOne. This will generate some data to populate the Predicate Data tab display.
You can change the settings of the Predicate Stats object via its Other Edit tab instead of going through the NCP Server object’s Predicate Data tab.
WARNING
The in-memory buffer has no upper limit, so if most predicates are unique, it is possible to use up all of a server’s available memory.
WARNING
The predicate statistics functionality is not intended to be run all the time that the directory is in operation. Collecting these statistics affects performance of the server, and lengthy accumulation of statistics can result in large databases.
In order to view the predicate statistics from ConsoleOne, the Write to Disk setting must be selected. Each time the internal table is flushed to the ndsPredicate attribute of the selected Predicate Stats object, the values in the table are compared to the predicates held by the object. If the values are the same, the count is simply updated to reflect the new instance of that predicate. If the internal table holds new predicates, they are added as values to the object.
TIP
If ConsoleOne refuses to display any statistics after you have properly configured the Predicate Stats object, you can turn on DSTrace on the server to see whether it is reporting any -649 (Insufficient Buffer) errors when trying to load the predicate statistics table. If it is, then this is the reason you are unable to view the statistics—the server is low on memory.
If you decide to change the statistics display mode by toggling the Display Value Text check box, it is recommended that you first turn statistics collection off, clear out all the old statistics values, change the display mode setting, and then turn statistics collection back on.
TIP
You may have noticed that the Predicate Data tab does not have an option to clear the data from the Predicate Stats object. To clear the old values, you can delete the ndsPredicate attribute from the Predicate Stats object.
Entries in the Predicate Data tab list are sorted by the number of times they have been used. The list may be a little difficult to read because it shows internal search information as well as user query information.
TIP
Sometimes the full predicate does not fit in the display window. To expand it, you can use a mouse to drag the right column width marker farther to the right. You can then use the horizontal scrollbar to see more of the predicate information.
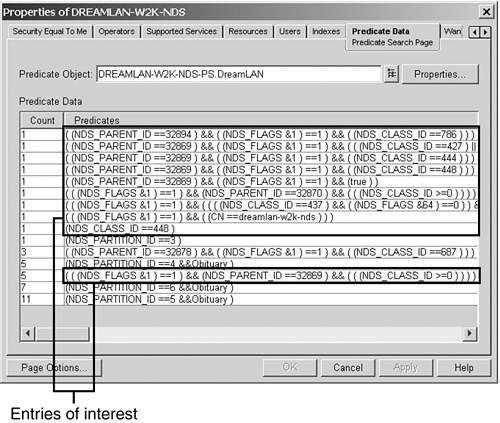
Figure 16.8 shows a number of entries that may be helpful in determining what attribute may warrant an index. The following three entries are examples of what to look for when deciding what indexes may be required:
(((NDS_FLAG&1)==1)&&((((NDS_CLASS_ID==437)&&![]() ((NDS_FLAGS&64)==0)...
((NDS_FLAGS&64)==0)...
(((NDS_FLAG&1)==1)&&((CN==dreamlan-w2k-nds)))
(((NDS_FLAG&1)==1)&&(NDS_PARENT_ID==32869)&&![]() (((NDS_CLASS_ID>=0))))
(((NDS_CLASS_ID>=0))))
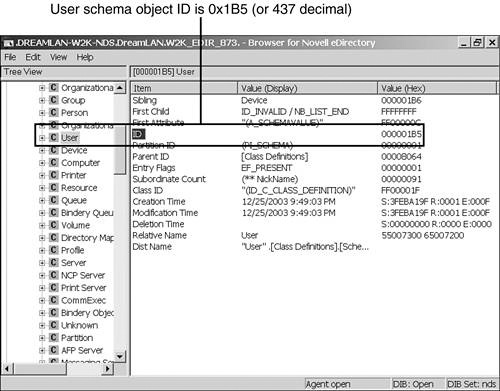
The first sample entry shows that the query used the filter NDS_CLASS_ID==437. This indicates that a search was performed on an object class whose (schema) entry ID value is 437 decimal (1B5 in hex). To find out what object class has an ID of 437, you need to use DSBrowse to perform a find based on the ID. Figure 16.8 shows that the User class schema definition has an entry ID of 1B5.
TIP
When you have the class ID, it is very easy to locate the classname. In DSBROWSE.NLM, you select Object Search, enter the class ID (in hex) into the ID field under Object Information, and press F10 to start the search.
For DSBrowse in Windows, you switch to the DIB Browser view. Then you right-click [Schema Root] under Entries, Go to Record ID. Next, you enter the class ID in the Record Number field, select Entry for the Record type, and click OK to start the search.
WARNING
Bear in mind that entry IDs are server specific. Therefore, on a different server, the schema entry ID for the User class will have a different value.
If you are seeing a high count value (meaning many searches using that filter) for NDS_CLASS_ID==437, you should check to see whether the same predicate search includes any attribute names, such as “search in all User objects whose Department attribute value is Sales.” If the answer is yes, the specified attribute names are potential candidates for indexing. Otherwise, creating an index for just the Object Class attribute may be useful; refer to the “General Guidelines for Using Indexes” section, later in this chapter, for more information.
The second predicate data entry example shows that the search was for a particular CN, an NCP Server object (dreamlan-w2k-nds). In more than 80% of the searches, specific object names (CN) are used. For example, “Show me all values in the ACL attribute for user Chelsea.” When you have many objects in the tree, indexing CN is an excellent idea—and that’s why CN is one of the predefined indexes. The other 20% of searches would include queries such as “Show me all the objects that have a Location value of New York City,” where the CN index is not used.
The third example shows that the filter NDS_PARENT_ID==32869 was used. This indicates that the search is either looking for a DS container (whose parent container’s entry ID is 32869 decimal or 0x8065 hexadecimal), objects in this container, or objects in this container and its subordinate containers. However, the parent ID here refers to the entry ID of the partition root object of the partition where the search is targeted. Using DSBrowse or NDS iMonitor, you can determine the name of the container based on the entry ID, thus the partition in question. Although this information does not help you to decide what attribute needs to be indexed, it does suggest whether you should put a replica of that partition on this server.
NOTE
The LDAP server discussion in Chapter 2, “eDirectory Basics,” mentions that there would be network traffic implications, depending on whether the LDAP server is configured for chaining or referral. If your predicate stats show that there are many queries—unfortunately, you can’t tell whether the searches are made via LDAP—on this server for objects in a partition that it is not hosting, you need to consider either placing a replica on it to reduce tree-walking or reconfigure the application to query a different server that does hold a replica of interest.
The following are a few points to keep in mind when working with predicate stats:
![]() Do not leave the predicate statistics function running all the time. Collecting predicate stats affects performance of the server, and lengthy accumulation of statistics can result in a large DIB.
Do not leave the predicate statistics function running all the time. Collecting predicate stats affects performance of the server, and lengthy accumulation of statistics can result in a large DIB.
![]() Each object addition or modification requires that the defined indexes be updated. Therefore, having all the indexes active may slow down bulk-addition or bulk-modification of data in the directory. You may first want to suspend all the User Defined indexes. After the operation is completed, you can bring them back online. The indexes will (re-)build in the background and become effective when updating is complete.
Each object addition or modification requires that the defined indexes be updated. Therefore, having all the indexes active may slow down bulk-addition or bulk-modification of data in the directory. You may first want to suspend all the User Defined indexes. After the operation is completed, you can bring them back online. The indexes will (re-)build in the background and become effective when updating is complete.
![]() Because
Because Predicate Stats objects are replicated, you might want to define a partition that exists only on the server being tuned and store the objects there so they are not unnecessarily replicated to other servers.
![]() Not all entries reported in the predicate stats are useful. Many of them are results of background processes running, and you should not let them distract you. You should focus mainly on the entries that include attributes.
Not all entries reported in the predicate stats are useful. Many of them are results of background processes running, and you should not let them distract you. You should focus mainly on the entries that include attributes.
![]() Reading and interpreting predicate stats is not straightforward. Before you start using predicate stats in earnest, you should run a few sample queries and examine the resulting predicates. Knowing what the “questions” were makes it easier to understand the data.
Reading and interpreting predicate stats is not straightforward. Before you start using predicate stats in earnest, you should run a few sample queries and examine the resulting predicates. Knowing what the “questions” were makes it easier to understand the data.
When the server receives a search request, the query is evaluated and broken into a combination of mini-terms. Each of these mini-terms (or tokens, as they are called in text string parsing parlance) becomes a search predicate. One index is selected as being optimal for each predicate. The indexed attribute is used to create the initial result pool for that predicate, and then the other predicate criteria are applied to form the final set. Result sets from the different predicates are then merged to form the final result set.
The complete rules for how an index is selected are complex and generally uninteresting to most people. The following are some simple guidelines to consider when working with eDirectory indexes:
![]() The search predicates that show up in the statistics screen do not necessarily represent the database’s optimization of the query. These values are only to be used as indicators of the attributes that are most commonly referenced.
The search predicates that show up in the statistics screen do not necessarily represent the database’s optimization of the query. These values are only to be used as indicators of the attributes that are most commonly referenced.
![]() Although it is possible, and often tempting, to create an index on the
Although it is possible, and often tempting, to create an index on the Object Class attribute, the effectiveness of the index depends very much on the type of data you are using. For example, if your tree has two million users and five printers defined, an Object Class index makes sense when you are searching for printers but would not gain you any performance benefit if you were searching for users.
![]() If the number of objects matching a search filter approaches a high percentage of the number of objects in the tree, query performance may be better if no index is used.
If the number of objects matching a search filter approaches a high percentage of the number of objects in the tree, query performance may be better if no index is used.
![]() Substring indexes are the most costly type of index to maintain, so the presence of several Substring indexes can severely affect add, delete, and modify performance. You should use Substring indexes sparingly.
Substring indexes are the most costly type of index to maintain, so the presence of several Substring indexes can severely affect add, delete, and modify performance. You should use Substring indexes sparingly.
![]() Value indexes on large string or octet string attributes may not provide the desired performance improvement. eDirectory truncates indexed string values at 32 bytes and indexed octet string values at 49 bytes. When a query includes a value that is larger than the truncation value (say, a string that is 40 bytes long), the index can only be used to generate a possible result set. Each object in the possible set must then be read and evaluated to make sure it fits the criteria.
Value indexes on large string or octet string attributes may not provide the desired performance improvement. eDirectory truncates indexed string values at 32 bytes and indexed octet string values at 49 bytes. When a query includes a value that is larger than the truncation value (say, a string that is 40 bytes long), the index can only be used to generate a possible result set. Each object in the possible set must then be read and evaluated to make sure it fits the criteria.
![]() Although indexes enhance search performance, each additional index adds to the update time for a new object; this is especially true for Substring indexes. Therefore, for massive bulk-loading operations, you should consider suspending User Defined indexes, especially the Substring indexes, during the operation.
Although indexes enhance search performance, each additional index adds to the update time for a new object; this is especially true for Substring indexes. Therefore, for massive bulk-loading operations, you should consider suspending User Defined indexes, especially the Substring indexes, during the operation.
![]() Defining an index for each attribute within a query rarely provides performance benefits. Complex search filters are broken down to predicates during the filter evaluation, and eDirectory uses only one index per predicate. The DSA selects one optimal index per complex search and then applies the other filter criteria to the results pulled from the index. Therefore, if you see a predicate searching for four attributes, there is no need to create four indexes—unless they are also used by other predicates.
Defining an index for each attribute within a query rarely provides performance benefits. Complex search filters are broken down to predicates during the filter evaluation, and eDirectory uses only one index per predicate. The DSA selects one optimal index per complex search and then applies the other filter criteria to the results pulled from the index. Therefore, if you see a predicate searching for four attributes, there is no need to create four indexes—unless they are also used by other predicates.
![]() Queries containing
Queries containing ! in the expression do not use indexes. The reason for this is that objects where the attribute is not defined are also returned in the result set.
![]() Queries that contain a greater-than-or-equal-to specification (
Queries that contain a greater-than-or-equal-to specification (>=) use an index, but queries containing less-than-or-equal-to (<=) do not. As is the case with ! queries, a <= query assumes that all objects that don’t contain the attribute match the query.
![]() If a query includes multiple predicates on the same indexed attribute that are concatenated together, query performance is generally better if the more specific predicate is given before the less specific predicate because eDirectory uses the index attribute on the first predicate only. For example, if you are trying to find users who belongs to both the
If a query includes multiple predicates on the same indexed attribute that are concatenated together, query performance is generally better if the more specific predicate is given before the less specific predicate because eDirectory uses the index attribute on the first predicate only. For example, if you are trying to find users who belongs to both the GW Support group and Support group, this search filter:
((groupMembership=="GW Support")&&
(groupMembership=="Support"))
performs better than the following query:
((groupMembership=="Support")&&
(groupMembership=="GW Support"))
because the first filter has the more specific predicate, GW Support, listed first.
Indexes are not miracle solutions to all query-based performance bottlenecks. They can greatly help improve search speeds if the applications can take advantage of them, such as by formulating and structuring the search filters to the way eDirectory works. But how can you find out after creating all the necessary indexes whether the still-not-so-speedy search response time is due to the applications or a system bottleneck somewhere else?
DSTrace provides much information to many eDirectory internal processes, and it can help you again in this situation. By setting the Record Manager filter for tracing, you can see which index was picked for a particular query.
NOTE
As discussed in the “Server Tools” section in Chapter 7, “Diagnostic and Repair Tools,” there are two implementations of DSTrace on NetWare servers: the built-in SET DSTRACE command and the DSTRACE NLM command. In order to view the RECMAN information, you need to use the NLM implementation.
On Windows servers, the RECMAN filter in DSTrace is called Storage Manager (StrMan) instead.
The following example shows a ConsoleOne query that is looking for the x121Address attribute by doing a find for the attribute. Notice that the boldfaced message indicates that no index was used to perform the query:
[02/10/2004 06:24:07.96] StrMan : Iter #c31e00 query
((Flags&1)==1) && ((((x121Address$549A$.Flags&8)==8) &&
x121Address$549A$.Flags&8)))
[02/10/2004 06:24:07.96] StrMan : Iter #c31e00 NO INDEX USED
[02/10/2004 06:24:07.96] StrMan : Iter #c31e00 first
( ID_INVALID)
NOTE
The ID_INVALID message indicates that the search found no matching objects. Otherwise, an entry ID (EID) value will be displayed.
The following example is a ConsoleOne query for a list of NCP Server objects in the tree. Notice that the highlighted message indicates that the ClassID_RDN_IX index, an internal eDirectory index, was used to perform the query:
[02/10/2004 06:23:03.89] StrMan : Iter #6d74ee0 query
((Flags&1)==1) && (((ClassID==448) && ((Flags&64)==0)))
[02/10/2004 06:23:03.89] StrMan : Iter #6d74ee0
index = ClassID_RDN_IX
[02/10/2004 06:23:03.89] StrMan : Iter #6d74ee0 first
( eid=32871)
Using the information provided by DSTrace along with the predicate stats provides you with some good tools for pinpointing possible bottlenecks in search performance.
As mentioned earlier in this chapter, the default eDirectory database block size is 4KB. For performance reasons, you might need to change the block size (either larger or smaller) in order to match the physical disk block size. You cannot change the database block size after the DIB files are created, but you can override the default value during eDirectory installation so a different block size is used. You do this by placing a blocksize command in the _NDSDB.INI file:
blocksize=bytes
You need to manually create the _NDSDB.INI file and place it in the directory where eDirectory expects it:
|
Platform |
Location |
|
NetWare |
|
|
Windows |
|
|
Unix |
|
For example, suppose you are installing eDirectory on a Windows 2000 server and want to set the database block size to 10KB. First, you create the _ndsdb.ini file with the line blocksize=10240 in it and put the file in C:NovellNDSDIBFiles before you start the eDirectory installation. After eDirectory has been installed, you can verify the database block size by using iMonitor, as shown in Figure 16.9.
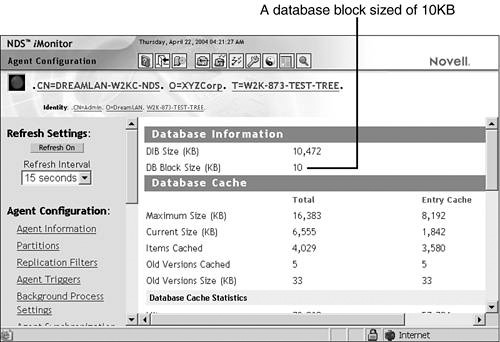
Keep in mind that for best performance, the file system block size should match the size of the database block size or be in multiples thereof.
Performance tuning of any software application is a complex job. It requires you to have an understanding of various components and subsystems of the software and knowledge of operating system and other system resources, such as file system, memory, storage media, and bandwidth. eDirectory is no exception. Previous sections in this chapter cover many eDirectory-specific tuning tricks. There are also some operating system–specific performance enhancements you can make on Unix systems, and they are covered in the following sections.
TIP
If you are looking for a tool to help you tune a Unix system, SarCheck may be of use to you. It is a Unix performance analysis and tuning tool for most Sun Solaris, HP-UX, AIX, SCO, and Linux (in beta, at the time of this writing) systems that produces recommendations and explanations with supporting graphs and tables. Visit www.sarcheck.com/index.htm for more information.
TIP
On high-end Solaris servers with many processors, it is better to create processor sets of not more than four and bind an instance of ndsd to the set. ndsd can then exploit warm on-chip caches to speed up operations.
Rather than go into the details for each supported Unix operating system, which would take a considerable amount of space, we refer you to Novell’s eDirectory documentation and its whitepaper on eDirectory performance tuning for Linux and Unix systems (www.novell.com/products/edirectory/whitepapers.html) for specifics. The following sections describe the salient points that are common to the supported Unix operating systems.
eDirectory can dynamically adjust its cache limit to regulate memory consumption in response to the memory demand of other processes. The limit is calculated as a percentage of available physical memory at set intervals. Although this works well for NetWare and Windows servers, it is not recommended for Linux and Unix platforms. Large differences in memory usage patterns and memory allocators do not allow for optimal performance of eDirectory on these operating systems.
On Unix systems (including Linux, unless otherwise specified), the free available memory reported by the operating system will be less than that for other operating systems because of the way the operating system uses free memory for internal caching of file system blocks, frequently run programs, libraries, and so on. In addition to this memory allocation, libraries on Unix normally do not return the freed memory back to the operating system. For these reasons, it is best to employ the Hard Limit mode and allocate a fixed amount of RAM to the eDirectory cache.
NOTE
On Unix/Linux, the operating system tries to cache file system blocks in its internal buffer cache. You should tune the operating system to flush this internal buffer cache as fast as possible—and even bypass it completely, if possible. If bypassing the internal cache is not an option, you should not specify more than 50% to 75% of the total physical memory for the eDirectory cache.
eDirectory uses an internal pool of threads to service client requests and internal operations. This thread pool avoids the overhead of starting or stopping a new thread for every request. Maximum performance is achieved by using the minimum number of threads required to service the requests. The lower the number of threads, the fewer system resources are required to manage them. eDirectory 8.7 and later automatically use a lower number of threads and start or stop threads as needed. This delivers optimum performance in most cases; however, it may need to be tuned to handle sudden heavy client loads.
You can place four parameters in the /etc/nds.conf file to help with tuning the thread requirements:
![]()
n4u.server.active-interval controls when a new thread is started. A thread is considered busy on another job if it does not return to the thread pool within the time interval (in milliseconds) specified by the parameter. This parameter is scaled based on the number of processors available on the machine and can be increased to its maximum value (25,000) to get the maximum performance.
![]()
n4u.server.idle-threads specifies the minimum number of threads (regardless of activity) in the thread pool. The value of this parameter should be based on the average client load in order to minimize the time required to produce new threads during normal client activity.
![]()
n4u.server.start-threads specifies the number of threads that get created and placed in the thread pool when eDirectory starts. The value of this parameter should be based on the average client load in order to minimize the time required to produce new threads during normal client activity.
![]()
n4u.server.max-threads specifies the maximum number of threads to be created. Each thread uses about 200KB of memory when performing heavy searches. The value of this parameter should be based on the maximum number of simultaneous clients that need to be serviced, along with the following recommendations:
![]() eDirectory requires a minimum of 16 threads for its internal operations.
eDirectory requires a minimum of 16 threads for its internal operations.
![]() There should be one Monitor thread for every 255 LDAP client connections.
There should be one Monitor thread for every 255 LDAP client connections.
![]() There should be one Worker thread for every four concurrent clients that need to be serviced.
There should be one Worker thread for every four concurrent clients that need to be serviced.
![]() There should be eight threads for every processor configured to service client search requests.
There should be eight threads for every processor configured to service client search requests.
The default value for this parameter is 64, and a value of 128 is sufficient in most cases, except when the server is serving a very large number of clients concurrently.
As with the case of a disk subsystem and its configuration, the choice of the file system can significantly influence the performance of bulk updates; search performance is less affected because of the rather aggressive caching in eDirectory. One of the great things about Unix systems is the diverse choice of file systems that is available. Each has its own strengths and weaknesses, depending on your requirement. This is also one of the “bad” things about Unix: There are too many different file systems to choose from.
NOTE
There are complete books, not just chapters, written about Unix/Linux file systems. If you are interested in more information, take a look here: www.linuxshelf.com/servlet/books?category=filesystem.
If it’s available for your Unix operating system, Novell recommends using the VERITAS file system with a block size of 4KB (the eDirectory database block size) because it can give significantly improved performance over “standard” Unix file systems. For HP-UX, Novell recommends that you use the JFS (VxFS) partition for storing the DIB directory. The default database block size of 4,096 bytes provides better performance for HP-UX.
NOTE
The VERITAS file system is a quick-recovery, journaling file system that is similar in some ways to Novell’s NSS implementation. You can find more information about the VERITAS file system at www.veritas.com/products/category/ProductDetail.jhtml?productId=filesystem.
This chapter concentrates on performance tuning for an eDirectory tree, using eDirectory indexes and predicate stats data. Some noteworthy tricks are presented that you can use from a software perspective to enhance eDirectory’s performance without spending additional money. Performance can be affected by many elements of eDirectory, including memory management (cache settings), indexes, replica placement, and search limits.