
1
Object-Oriented Programming Basics
LEARNING OBJECTIVES
At the end of this chapter, you should be able to understand
Programming concepts.
Software development paradigms.
OOP paradigms and extendibility features offered by OOP languages.
1.1 Introduction
In order to solve a problem, you need to know the “method/procedure” or you need to have the “know-how”. In computer parlance, we call this an algorithm. An algorithm or a program is a sequence of steps to be followed, which leads to a desired output. The sequence of steps can be called a procedure, and, in turn, a group of procedures can be termed as a program. For solving a simple problem, a sequence of steps is sufficient, but if the problem is complex, a programming environment that includes well-integrated and cohesive programming elements, constructs and data structures is required. A paradigm can be thought of as a style of programming, which involves elements such as functions, data and data structures. Several programming paradigms have been used successfully. The structured programming paradigm with C as implementing language, in which the programmer breaks down the task to be accomplished into subtasks and specifies a step-by-step procedure or algorithm to achieve this task, has been very successful and popular amongst programmers, owing largely to its reusable components in the form of procedural calls and its ability to manipulate memory and thus handle hardware integration.
Low productivity of programmers, due to factors such as changing user needs, complexity of projects and non-availability of extensibility and reuse features, causes projects never to be completed on time. Even if they are completed and implemented, they are of little use. A structured programming environment with limited reuse facility afforded by procedure call and lack of extensibility features, i.e. inability to derive new data types from existing ones, is not optimally suited to handle challenges thrown by complex projects such as fast-paced hardware and software changes. Object-oriented programming (OOP) promises extensive reusability features through inheritance, library functions in the form of standard template library (STL), etc. C++ is one of the most powerful OOP languages that supports both structured as well as OOP paradigms.
1.2 Programming Concepts
Prior to the invention of C and C++, programming languages could be broadly categorized as follows:
High-level languages such as FORTRAN, Cobol and Pascal, catered to programmers with friendly features such as English-like coding languages. In these languages, the code written by programmers is compiled and converted into an object code. The implementation and hardware details such as addresses are hidden from the users. Hence users can code the application software for scientific and business communities. Cobol is a language widely used in the business world. FORTRAN and Pascal, on the other hand, are languages that are used by the scientific communities.
Low-level languages such as assemblers require extensive knowledge of hardware, addressing mechanisms and operating systems. Accordingly, these types of languages are used by experts, academicians and system developers. Most of the interfaces involving hardware integration with software are written using these languages.
Middle-level languages such as C. These languages combine the strengths of both high-level and low-level languages.
- Code is almost English like. It is easy to understand and write programs in this language.
- It has the ability to handle hardware as many of its commands support the direct handling of underlying hardware such as memory and hardware devices.
- Both business programming and scientific calculations can be easily handled.
1.3 Programming Paradigms
Paradigm is a style of programming language. It is only a style and NOT a language. It is the manner in which programming elements such as functions, objects and variables are exploited to produce the desired output.
1.3.1 Structured Programming Paradigm
Procedure-oriented programming such as C uses procedure calls. The main task is divided into subtasks with inputs and functions to achieve the desired result. The data is forwarded to procedures through arguments. In this paradigm, the procedure is important and the data is shared by procedures.
Algorithm or program or procedure is a sequence of steps to be followed, which when followed leads to a desired output. A group of procedures can be termed as a program. A procedure is also known as a routine, subroutine, function or method. A program or a procedure under execution can call any other procedure.
Accordingly, using the procedure-oriented language, the programmer breaks down the task to be accomplished into subtasks and specifies a step-by-step procedure or algorithm to achieve this task. A procedure-oriented language like C provides the statements to code the procedure specified by the task. Procedure-oriented languages have several advantages, as follows:
- Modular: Each subtask can be developed as a module. A module takes arguments as inputs and delivers outputs as return values.
- A module which is independent and uses standalone codes avoids coding pitfalls such as GOTO and Jump and thereby makes it easy to maintain the code.
- Reusability is ensured. The module can be called by any other module during execution. All reusable codes can be maintained as libraries.
- Strong modularity and reusability features afforded by C make it the most suitable language platform to develop complex programs and projects.
A procedure-oriented language is also known as a “structured language” because it allows procedure calls, which in turn allows a programmer to break the main task into subtasks and execute each subtask through procedure calls.
1.3.2 C: A Workhorse that Works Well
The C language was developed by Dennis Ritchie of Bell Laboratories in 1972 for the UNIX operating system. It had originally been developed as a system programming language, but it soon caught the imagination of application developers and became the industry standard.
C code is compiled into a machine code using a straightforward compiler and hence does not need much run-time support. Hence, C found acceptance and popularity amongst assembler programmers for their system programming requirements.
C is an almost machine-independent language. A compiled code on a machine can run on several different platforms. The salient features of C are as follows:
- All executable codes are included in functions only. Inputs are through arguments and outputs are through return values.
- All parameters are passed either as pass by value or by reference using pointers.
- Structures allow heterogeneous data to be grouped into one single data unit.
- Memory access through pointers.
- Library routines for IO, string manipulation, and mathematical calculations.
Thus, a structured programming language like C has been able to satisfy all programmers, with its ease of programming, reusable features through procedure calls and ability to deal with hardware integration.
Then why do we need to learn objective-oriented programming?
1.3.3 Where is the Problem?
Problems arise due to fast-paced changes. Changes occur at such a rapid rate that projects and programs developed based on inputs at a particular instance or time are no longer valid. Thus, the project developed is confined to the shelves of a departmental library, never to be implemented.
This is especially true for software projects, wherein the latest software programming paradigms and hardware are required.
User requirements change during the development of project. In a complex project, changes in user requirements imply rework.
The US Department of Defense (DoD) has found out that a majority of the projects are out of date and cannot be implemented.
1.3.3.1 Complexity of Problems
Initially, computers were being exploited for basic business computing such as for payrolls, student or employee records, and scientific calculations. These are all simple algorithms involving input, process and output and could easily be handled by structured programming.
The complexity of problems, however, has grown rapidly and modern-day software projects involve multilayer inputs and communication with local and distant processors, networks, etc.
1.3.3.2 User's Needs
Analysis, design and development are scheduled after a thorough study of user requirements during the initial stages of project implementation. It is correct to state that requirements are specifications that decide every stage of software design and development. Hence they are “frozen” before commencing the development phase.
But on the ground, it is important for operational managers, e.g. airport operations managers, to implement changes to ensure the smooth functioning of day-to-day operations at airports. Thus, it is only natural for them to expect these latest changes to be incorporated in the software being developed.
There go your initial estimates! Developers have to rework the design, depending on the nature of changes sought.
It is estimated that rework due to changes constitute about 40% of time and effort estimations and have a significant effect on project overruns.
1.3.3.3 Low Productivity
Extensibility and reuse are two features that make a programmer productive. In C, we have struct and unions as user-defined data types. The facility to define new data types based on already-defined ones is not available.
Changes brought in result in changes in several procedures and often result in recompiling the source.
Extension of the data type through inheritance is not possible. Programmers have to be content with procedure calls.
1.3.4 Object-oriented Programming Paradigm
Object-oriented programming such as C++ uses objects and interaction amongst them through invoking member functions. The features include data hiding, data abstraction, encapsulation, inheritance and polymorphism.
With the advent of UNIX and communication hardware and software from 1969 onwards, the complexity of both hardware and software increased and software project development could not keep pace. As a result, the quality of programs suffered.
The developers at Bell Laboratories and the DoD started to look at alternative paradigms wherein reusability and extensibility was a strong feature. Further, the specifications laid insisted on data primacy rather than process primacy.
The object in OOP paradigms contains member data and all functionality within itself to achieve the desired result. The class and the object of the class carry their own operators to achieve a particular functionality. For example, an object may carry an overloaded operator, >>, to achieve input operations. Objects communicate with other objects by passing messages.
Salient Features of the OOP Paradigm
- Data primacy and not procedure primacy.
- A task is divided into objects.
- Each object is an independent machine with its own data structure and member function in its own memory location.
- Methods and data are tied together in an object.
- External functions cannot access data.
- Objects can send messages to another cooperating object.
1.4 History and Development of Object-oriented Languages
Smalltalk was the first OOP language to be developed. Currently C++, Java and C# are the languages that use OOP paradigms and are industry favourites.
1.4.1 C++
C++ was developed by Bjarne Stroustrup in 1979 at Bell Laboratories. C++ is a sequel to the C language, with additional features. These features include virtual functions, function name and operator loading, references, and free space memory along with several features on reusability and extendibility through inheritance, templates, etc. Exception handling and a well-developed standard template library are two of the most advanced features available in C++.
1.4.2 Java
Java was developed by James Gosling at Sun Microsystems in 1995. It is similar to C & C++. The main advantage of Java is that it is hardware independent. Any code is compiled into bytecodes. The bytecode compiled is stored in a class file that can run on any Java virtual machine (JVM).
JVM takes the bytecode and converts it into an object code, which in turn is used by a local machine to run and produce the desired result.
Java 1.0 was released in 1995. Sun Microsystems called it “Write Once, Run Anywhere”. Indeed, with most of the browsers such as IE explorer and Netscape Navigator supporting Java 1.0, Java soon became the industry standard. Java applets that can run on web browsers became popular too. In 1998, Sun Microsystems released Java 2 with specialized configurations to suit different types of platforms, such as J2EE for enterprise applications, JEME for mobile computations and J2SE for standard editions. These have been renamed JavaEE, JavaME and JavaSE, respectively.
1.4.3 C#
C# was developed by Anders Hejlsberg for Microsoft. It combines the best features of existing OOP programming languages of C++ and Java. It has been developed as a powerful and versatile programming language that is fully object oriented.
1.5 Software Development Methodologies
Software development is an engineering activity involving initiation, analysis, design, development, and implementation and delivery phases. The principles and guidelines for developing projects using software engineering (SE) practices are enshrined by the SE branch of engineering.
What is a methodology? A methodology can be considered as a style of solving an SE (project) problem from the best practices prescribed by the SE domain. For example, we can adopt structured analysis and design (popularly known as SAD in earlier times), which relies on procedure-oriented languages such as C, Pascal, etc.
Alternatively, we can also adopt object-oriented analysis and design (OOAD), wherein objects comprising member data and member function achieve the desired output through interaction amongst them.
1.6 Need for Objects
In OOP paradigms, data structures that manipulate data and functions that use data are not separate. OOP combines both of these into a single thing, also known as object.
Objects bind the data and the functions that operate on the data together by a concept called encapsulation, thereby avoiding unauthorized data access and maintaining tighter control over data.
Object is a run-time instance and communicates with other objects by passing arguments and thereby achieves the result. Indeed, objects and communication between objects is the methodology adopted by object-oriented programs.
1.7 Object-oriented Language Features
OOP style can be of two types, i.e. object-based programming and object-oriented programming. In OOP paradigms, object is primacy.
1.7.1 Object-based Programming
To qualify as an object-based language, a language must support the following features:
- Data encapsulation
- Data hiding
- Operator overloading
- Initialization and automatic clearing of objects after use
1.7.2 Object-oriented Programming
In addition to the object-based features mentioned above, OOPs must support extensive reusability and extendibility features such as:
In the succeeding sections, we study the basics of OOP language features. C++ and
Java are the most powerful OOP languages that support both structured as well as OOP paradigms.
1.8 Definition of OOP Language Classes and Objects
Look around. You will notice several objects (things) such as pens, tables, laptops, students, etc. Figure 1.1 shows objects of students in a class. Each thing has attributes, also called characteristics, like colour, height, weight, age, etc. The attributes belong to the objects. For example, an object called student can have attributes like name, number, marks, grades, etc. Attributes are also called the state of an object. Most objects have their own behaviour. For example, an object called student can have behaviours like, play, sing, learn, etc.
Figure 1.1 Student objects
So when we refer to an object called student, we refer to both attributes (state) and behaviour. Figure 1.2 shows attributes and behaviour. We model an object by a rectangular box, as shown in Figure 1.3. It contains the name at the top, followed by a list of member functions and member data. It is customary to show the member data as private and functions that manipulate these data as public. This is a security feature, enshrined in OOP languages such as C++ as data hiding and encapsulation, to prevent unauthorized access to objects’ data by external functions.
Figure 1.2 Object: member data and functions

Figure 1.3 Object model
How do we represent the object?
1.8.1 Attributes and Behaviours of Objects
There may be several instances of an object. For example, an object called student as shown above can have 60 instances, implying that there are 60 students in a class. Therefore, each instance of an object can have its own data, such as its own number, name, marks, attendance, etc. We can thus say that the attributes, i.e. data, of an object are owned by that instance of the object. Hence, attributes are also called states of an object.
All student objects will have the same functionality such as Play(), Learn(), GetData(), PrintData(), etc. Thus, when we say object, we mean attributes and behaviours.
1.8.2 Class
Class: A class is a collection of objects and can also be defined as an array of instances. Figure 1.4 shows student class with three instances. It can also have member functions and member data. Here unlike arrays, a class can have different data types as its elements.
Figure 1.4 Student class with three instances of student object
Class defines abstract, i.e. hidden, characteristics of an object, including attributes and behaviours. A class called student can be viewed as a factory producing instances of object student that have different attributes (i.e. individual data) and a common functionality (i.e. common functions).
Attributes and functions provided by a class are called member data and member functions. In Java, member functions are called methods.
1.8.3 Encapsulation
By now we understand that object means attributes and functionality. Class can contain several instances of an object.
We also understand that in object-oriented programming, it is a data primacy language, i.e. data is important and functions are not important. As per memory mapping used by C++ and other OOP languages, data is stored in data areas such as stack and free space, functions are stored in code areas and there is a need to maintain strict control over the accessing of data by functions.
OOP languages achieve this control by using the encapsulation feature. Encapsulation is a binding member data and calling function together with security classification, so that no unauthorized access to data takes place.
1.8.3.1 Security or Access Privileges
C++ and Java depend heavily on access specifiers to maintain data integrity. The security access specifiers are public, private, and protected.
- Public: Member functions and data, if any, declared as public can be accessed outside the class member functions.
- Private: Member data declared as private can only be accessed within the class member functions and data is hidden from outside.
- Protected: Member data and member functions declared as protected is private to outsiders and public to descendants of the class in inheritance relationship. You will learn more about this in the inheritance chapter under C++ and the Java chapter that follow.
Encapsulation can now be defined as:
Binding together the member functions and member data with access specifiers like private, public, and protected into objects by the class.
A class therefore allows us to encapsulate member functions and member data into a single entity called an object.
1.8.4 Data Hiding / Data Abstraction
It is customary to declare all member data as private only. But the data declared as private is hidden and cannot be accessed by anyone. This feature is called data hiding or data abstraction. But how can this be achieved? You can access this only through public member functions. There is no other way. It is comparable to the case where even the chief librarian of a university cannot take home books unless he uses the access card supplied by the library.
1.8.5 Function Overloading
When a single function can do more than one job, overheads of the compiler get reduced. For example, if one wants to compute the area of a circle, the surface area of a football or the surface area of a cylinder, how many functions do we have to write? Normally, three functions. But in OOP languages like C++, one function, overloaded to perform all the three jobs, is sufficient.
Overloaded functions decide which version of the code is to be loaded into primary memory, depending on the argument supplied by the user.
Why is overloading important? Functions have to be compiled and loaded into primary memory. If a function is NOT overloaded, all the functions have to be loaded and linked at the time of compilation. Users may or may not use all the functions loaded, thus wasting the primary memory and making it unavailable to solve complex problems requiring more primary memory.
As an example consider the following overloaded function:
// single argument. Same function name
void FindArea( float r ){ return ( 2*3.14158*r*r ) ; }
// two argument same name. find surface area of the cylinder
void FindArea( float r , float h ){ return ( 4*3.14158*r*h ) ; }
1.8.6 Operator Overloading
Predefined operators such as +, –/, *, etc. are defined and provided by the compiler to work on intrinsic data types such as int, char, double, etc. We have also seen while discussing the concept of function overloading that if a function can perform more than one task, we can call this overloading. This is an efficient way of utilizing the scarce resource like primary memory. Operator overloading also improves the efficiency and throughput of the program by conserving the primary memory of C++.
If we can use these predefined operators to work on user-defined data types such as classes, we would call it operator overloading. For example, consider a predefined operator + and its normal operation
int x = 10, y = 20;
int z = x + y ; // contents of x and y are added and placed in z
Now consider two complex numbers in polar form of representation:
Polar v1(25.0,53.50); // magnitude and angle theta
Polar v2(5.0, 45.00);
If we can write
Polar v3 = v2 + v1;
It means we have overloaded the + operator.
1.9 Extendibility and Reusability of OOP Paradigms
The extendibility and reusability of OOP paradigms are responsible for making the OOP languages versatile and powerful. There are several tools provided by OOP languages to ensure these features:
- Containment
- Inheritance
- Virtual functions and abstract data types (ADTs)
- Standard template libraries (STL)
We will briefly describe the above features in the succeeding sections. Their implementations will be explained in the C++ and Java chapters in Parts 2 and 3.
1.10 Extending / Deriving New Classes
We can derive a new class based on the existing class. This is possible through the inheritance and containment property afforded by OOP languages. Containment is class within a class, i.e. containment ensures all the member functions and member data of a contained class to the class containing the class. Inheritance, on the other hand, provides access to member data and member functions declared as protected to the descendant class.
1.10.1 Containment: Class Within a Class – Container Class
Container class is one of the techniques provided by C++ to achieve reusability of the code. Container class means a class containing another class or more than one class. For example, a computer has a microprocessor in it. Further, a student class can have a data member belonging to a string class. We would then say that a string class is contained in a student class. In other words, it can also be called composition or aggregation of a string class.
The advantage of containment is that we can use a string class within a student class to store the details of name, address, etc. belonging to a string class. Similarly, if we define a class called date with day, month and year information, we can define the object of date within a class called student and define date-related data such as DOB, DOJ, etc. Therefore, composition is a “has” type of relation.
1.10.2 Inheritance and Class Hierarchy
Reusability of a code is one of the strong promises made by C++ and inheritance is the tool selected by C++ to fulfill this promise. The concept of inheritance is not new to us. We inherit property, goodwill and name from our parents. Similarly, our descendants will derive these qualities from us. Refer to the inheritance class hierarchy shown in Figure 1.5.
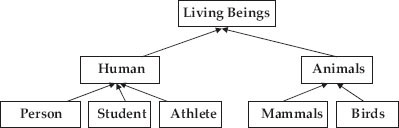
Figure 1.5 Inheritance hierarchy
Humans and animals derive qualities from living beings.
Professionals, students and athletes are derived from humans. We say these three categories have inherited from humans. Class human is called base class and students and athletes are called derived classes. What can be inherited? Both member functions and member data can be inherited.
Have you noticed the direction of the arrow to indicate the inheritance relation? It is pointed upwards as per modelling language specifications.
Inheritance specifies an is type of relation. Observe that a student is a human. Similarly, a mammal is an animal. Human is a base class and student is a derived class. Derivation from base class is the technique to implement the is type of relation. A base class can have more than one derived class.
When do we use inheritance? You inherit so that you can derive all the functionality and member data from base class, and derived class can add its own specialized or individualistic functionality. For example, athlete derives all functionality and attributes of human, and, in addition, adds sports and athletic functionality and attributes on its own.
Inheritance is a powerful tool in the hands of a programmer to define a new class from existing classes.
1.10.3 Single and Multiple Inheritances
Inheritance means the ability to derive a new descendant class from a base class, with additional functionalities.
In Figure 1.6a, we have shown single inheritance, wherein the derived class person inherits from the base class human.
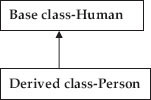
Figure 1.6a Single inheritance
In Figure 1.6b, multilevel inheritance is depicted, wherein student inherits properties from person, which in turn inherits properties from the base class human.
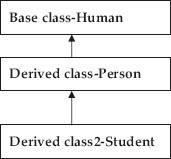
Figure 1.6b Multilevel inheritance
In Figure 1.6c, we have shown the hierarchical inheritance involving one base class and three derived classes.
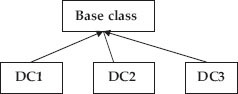
Figure 1.6c Hierarchical inheritance
Figure 1.6d depicts multiple inheritance. In this, the base class is called virtual because a single base class is being used by two derived classes, namely derived class 1 (DC1) and derived class 2 (DC2). Further, you can see that derived class 3 (DC3) inherits from both DC2 and DC3. This type of inheritance is also called hybrid inheritance as there is a single derived class DC3 from two base classes DC1 and DC2.
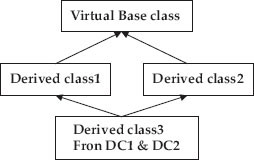
Figure 1.6d Multiple/hybrid inheritance
1.11 Virtual Functions
In the inheritance relation, the derived class gets access to protected member data through public accessory functions, thereby achieving an important object-oriented programming facility called code reusability.
But what about object to base class using the member functions belonging to a derived class? This feature facilitates object to base class to execute any one of the derived class functions, depending on the users’ choice at run time.
This means that object to base class is provided with a bridge to the selected derived class function and hence it can execute the function. The bridge is made available when we declare a virtual function in the base class and when the derived class overrides the base class function.
If a function is declared as a virtual function in base class, we can execute an overriding function with the same name in the derived class with a pointer to base class. A pointer to base class is provided by a virtual function.
In summary, we can say that from base class we can execute any function with the same name as that of a virtual function in the base class, depending on the users’ choice at run time.
1.12 Run-time Polymorphism and Dynamic Data Binding
Inheritance solves the problem of reusability, i.e. a derived class can access all the data members and function members of a base class that are declared as protected.
We have also learnt that a derived class can override the functions defined in a base class.
Further, we have seen while dealing with virtual functions that with a pointer to base class we can call the derived class object.
Combining the above two features of OOP languages like C++ gives us a powerful tool, called run-time polymorphism and dynamic binding.
What this feature means to a programmer is that with a pointer to base class, we can decide at run time to call particular derived classes overriding a function. In other words, we can bind the overriding function from several of the derived classes with a pointer to base class. In the previous section, we have seen the working of virtual functions with which we can achieve binding of derived class functions with a pointer to base class.
1.13 Class as Abstract Data Type (ADT)
A class in object-oriented languages can also be called abstract data type (ADT). The features of OOP languages such as run-time polymorphism and dynamic binding allow us to define a base class with virtual functions with no implementation (called pure virtual functions) or with dummy functionality just to indicate to the user that implementation is by derived class. These classes are called ADTs because they hide the implementation.
Refer again to Figure 1.7. We will declare a base class (ADT) called shape. You will appreciate shape has no definite shape, no definite area or perimeter, and no specific draw routine. Shape will hence declare virtual functions with only names and no implementation details.
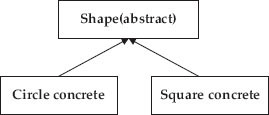
Figure 1.7 Abstract Data Type (ADT)
We will derive classes like circle and square and provide the solid implementation of these virtual functions. Solid means that all virtual functions will be implemented in each of the derived classes.
1.14 Standard Template Library (STL)
One way to describe object-oriented programming is a programmer's ability to use library facility through language. C++ has much developed standard library in the form of stream IO library that provides extensive functionality for input and output.
STL is the most significant addition to the library provided by C++. Using the module in STL, a programmer can write code using data structures and algorithm implementations provided in the STL. Vectors, lists, queues, maps, etc. are some of the implementations of STL. We have presented a detailed description and procedures to exploit templates and STL in Chapter 16. Templates and STL are considered to be the most significant and important OOP features of C++. They are indeed tools of C++ to enhance the programmer's productivity. The basic idea is that if you use already developed code, albeit by a manufacturer or a third-party supplier, you are using the reuse feature of OOP.
1.15 OOPS – Object-oriented Programming and Systems
From our long experience of teaching undergraduate and post-graduate students, it has been our experience that students are good programmers but lack adequate exposure to become good project team members or leads. Where does the problem lie?
Students need to be taught to think object-oriented programming and systems (OOPS) skills right from step 1. In this section, we explain the terms and terminologies connected to analysis and design using object-oriented technologies and the use of UML (Unified Modelling Language).
We have already discussed objects in detail. Objects are things you see everywhere around you, like pens, students, etc. There are living objects and inanimate objects. We have also understood that objects have attributes, also called member data, and behaviour, also called member functions.
In an object-oriented design (OOD) model, objects have a class relationship, i.e. objects having the same functionality characteristics are grouped into a class. A class allows us to encapsulate member functions and member data into a single entity called an object.
Objects communicate with other objects by invoking functions and passing arguments to the functions.
Classes have relationships with other classes. These relationships are called associations.
There are also inheritance relationships, using which we can define new classes from existing classes. There are also multiple inheritance relationships.
We have also learnt that virtual functions coupled with inheritance gives us a powerful tool like a run-time polymorphism and allows us to define ADTs and interfaces. Thus, we can decouple interface and implementation.
Programming in C language revolves around functions. Invoke functions and get the desired results. In OOP methodology, the desired result is achieved by passing messages between objects, i.e. the objects communicate by invoking functions and passing arguments amongst themselves.
We can define all classes required to execute a large project into a single working space. This space can be called a package. Once included in the package, we can use all declarations of classes into other programs and projects, thus ensuring reusability of the code.
1.16 Object-oriented Analysis and Design (OOAD)
In order to prepare a solution, we must first understand the system. To understand the system we need to model the system. Only then can we can ensure programs and projects run as desired. So whenever a problem is non-trivial and difficult to understand, we model the system to study the system behaviour.
In order to understand the system, user specifications are prepared by users and experts. The specifications are simple statements of problems in English. We need to analyse the specifications and follow object-oriented analysis and design principles. The best way to analyse and design non-trivial and complex systems is through modelling by using UML.
UML is a graphical and pictorial language used for analysis and design methodologies. It is called unified because it unifies all earlier object-oriented methodologies enunciated by three of the founding fathers of object-oriented technologies, Grady Booch, James Rambaugh and Ivar Jacobson. UML was founded by a consortium of industries such as HP, IBM, Oracle, etc. under the aegis of a controlling group called Object Management Group (OMG). We will introduce all these concepts in the succeeding chapters under OOPS.
In the next chapter, we will deal with concepts involved in object modelling and UML.
1.17 Summary
- Structured programming involves invoking functions and thereby solving the problem.
- A class allows us to encapsulate member functions and member data into a single entity called an object.
- Classes have relationships with other classes. These relationships are called associations.
- The main advantage of Java is that it is hardware independent. Any code is compiled into bytecodes. The bytecode compiled is stored in a class file that can run on any JVM.
- JVM takes the bytecode and converts it into an object code, which in turn is used by a local machine to run and produce the desired result.
- OOP styles can be of two types, i.e. object-based programming and object-oriented programming. In OOP paradigms, object is primacy.
- To qualify as an object-based language, a language must support the following features: data encapsulation, data hiding, operator overloading, and initialization and automatic clearing of objects after use.
- OOP must support the extensive reusability and extendibility features such as all object-based properties, inheritance, dynamic binding, and extensive and well-defined STL.
- Each object has attributes (states) and behaviours. Attributes are also called the states of an object.
- Class: A collection of objects. A class defines the abstract, i.e. hidden, characteristics of an object including attributes and behaviours.
- Encapsulation is a binding member data and calling function together with security classification to ensure that no unauthorized access to data takes place.
- A class allows us to encapsulate member functions and member data into a single entity called an object.
- Function overloading is the same function name but with different numbers or with different types of arguments.
- A container class means a class containing another class or more than one class. In other words, it can also be called composition or aggregation.
- In an inheritance type of relationship, we can derive a new class from existing classes.
- Inheritance means the ability to derive a new descendant class from a base class, with additional functionalities.
- If a function is declared as a virtual function in a base class, we can execute an overriding function with the same name in the derived class with a pointer to base class. A pointer to base class is provided by a virtual function.
- A class in object-oriented languages can also be called an ADT.
- The features of OOP languages such as run-time polymorphism and dynamic binding will allow us to define a base class with virtual functions with no implementation (called pure virtual functions) or with dummy functionality just to indicate to the user that implementation is by a derived class. These classes are called ADTs because they hide the implementation.
- Encapsulation means binding data and code. When run-time polymorphism is being used, it is best to polymorphically decouple the encapsulation to prevent discrete code modules from interacting with each other.
- A base class overridden function is automatically hidden and can be called explicitly by referring to the base class function.
Exercise Questions
Objective Questions
- C++ supports
- Structured programming
- Object-oriented programming
- Both A and B
- None of these
- C++ has been developed by
- Gosling
- Bjarne Stroustrup
- Rambaugh
- Grady Booch
- Java has been developed by
- Gosling
- Bjarne Stroustrup
- Rambaugh
- Grady Booch
- Java is
- Hardware independent
- Software independent
- Language independent
- Firmware independent
- Java virtual machine (JVM)
- Converts source code to object code
- Converts source code to bytecode
- Converts bytecode to object code
- None of these
- C# has been developed by
- Anders Hejlsberg
- Bjarne Stroustrup
- Rambaugh
- Grady Booch
- In OOP paradigms, a task is
- Divided into functions
- Divided into objects
- Divided into subtasks
- Divided into classes
- OOP paradigm is
- Data primacy
- Procedure primacy
- Task primacy
- Object primacy
- The following is not part of an object-based programming paradigm
- Data encapsulation
- Data hiding
- Operator overloading
- Inheritance
- Member data declared as private
- Can be accessed by an outside class
- Can be accessed only by inside class member functions
- Can be accessed by descendant class members
- None of these
- Member data declared as protected
- Can be accessed by an outside class
- Can be accessed only by inside class member functions
- Can be accessed by descendant class member functions
- None of these
- i
- i and ii
- ii and iii
- i, ii and iii
- Containment is a(n)
- Has type of relation
- Is type of relation
- Has-is type of relation
- None of these
- Containment is also called
- Inheritance
- Aggregation
- Composition
- Class within a class
- i
- i and ii
- i and ii
- ii, iii and iv
- Inheritance is a(n)
- Has type of relation
- Is type of relation
- Has-is type of relation
- None of these
- Object-oriented programming achieves results by
- Invoking functions
- Objects invoking functions and passing messages between objects
- Functions invoking objects
- None of these
- Classes having relationship with other classes are called
- Inheritance
- Association
- Link
- Mapping
- UML stands for
- United Modelling Language
- Unified Modelling Language
- US Modelling Language
- None of these
- UML unifies the approach
- Structured analysis and design and OOAD
- Models of Jacobson and Rambaugh
- Models of Rambaugh, Jacobson and Grady Booch
- a and c
Short-answer Questions
- What is structured programming?
- What is object oriented programming?
- What is object-based programming?
- Distinguish between object and class.
- What is encapsulation?
- Explain data hiding.
- Why are classes called abstract data type?
- What is message passing in OOP paradigms?
- Explain containment.
- Distinguish between function overloading and operator overloading.
- Explain the features of run-time polymorphism and dynamic binding.
- What are virtual functions?
- What is UML?
- What does the term unified in UML mean to you?
Long-answer Questions
- What are the salient features of OOP paradigms?
- Distinguish between object-based programming and object-oriented programming. (OOP style can be of two types, i.e. object-based programming and object-oriented programming. In OOP paradigms, object is primacy.)
- Explain inheritance and class hierarchy.
- Distinguish between different types of inheritance.
- Why are virtual functions useful?
- Explain STL in C++.
Solutions to Objective Questions
- c
- b
- a
- a
- c
- a
- b
- a
- d
- b
- c
- a
- d
- b
- b
- b
- b
- c