

CHAPTER
4
Oracle Replication (GoldenGate)
In previous chapters the discussion has revolved around the many different aspects of data integration that can be accomplished from a database perspective. Oracle GoldenGate is another tool that can be used or incorporated into the data integration process. What is Oracle GoldenGate exactly?
Oracle GoldenGate is high-performance heterogeneous software for capturing and applying changed data in real time between different platforms. With the heterogeneous nature of Oracle GoldenGate, organizations can leverage many different solutions for data integration purposes. The most common use-case is the unidirectional architecture, which provides a mechanism for organizations to perform data analytics, application migrations, or near-zero-downtime migrations. These unidirectional solutions are great for data integration because they provide the foundational approaches to more complex use-cases in terms of consolidation and data distribution.
The benefit of using Oracle GoldenGate with the data integration process is seen not only with its ability to capture, route, and apply changed data, but also in the ease with which it can be used to transform that changed data to fit a wide range of applications. This capability to transform captured data in flight is beneficial to the data integration process. The benefits include the following:
![]() Mapping source or target metadata between environments
Mapping source or target metadata between environments
![]() Using Oracle GoldenGate to generate files to be used by native database loaders such as Oracle SQL*Loader
Using Oracle GoldenGate to generate files to be used by native database loaders such as Oracle SQL*Loader
![]() Writing flat files using Oracle GoldenGate
Writing flat files using Oracle GoldenGate
![]() Using API interfaces for Oracle GoldenGate
Using API interfaces for Oracle GoldenGate
This chapter is about the various ways Oracle GoldenGate can be used to capture, transform, and provide data for data integration purposes. Many different options can be used within Oracle GoldenGate for manipulating data. Before we can dive into these different approaches for manipulating data, gaining a basic understanding of the Oracle GoldenGate use-cases and architecture is critical.
Oracle GoldenGate Use-Cases
For data integration purposes, a few different architectures can be leveraged to provide valuable information to a downstream site. In many cases, these use-cases revolve around database migration, database consolidation, or data distribution. In these use-cases, data is captured, transferred, and then applied to a target system where the data can then be used as a single source of truth.
Unidirectional Use-Case
The unidirectional use-case is the most common when talking about data integration. This architecture supports the ability to migrate from one database to another, consolidate distributed systems down to a single source of truth, or allow for subsets of data to be distributed to smaller database locations. Figure 4-1 provides a conceptual view of what unidirectional architecture looks like.
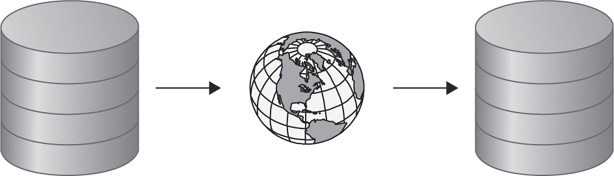
FIGURE 4-1. Oracle GoldenGate unidirectional architecture (high level)
The unidirectional architecture is great for near-zero-downtime migrations of databases. Often, this is the architecture approach that organizations start with to get off of older platforms and scale out to faster, newer platforms with a near-zero-downtime outage. This is due to the robustness and flexibility in the Oracle GoldenGate architecture. This flexibility allows for Oracle GoldenGate to be expanded for data integration purposes into other architectures, such as consolidation and data distribution.
Consolidation Use-Case
The consolidation use-case is used mostly when an organization wants to take multiple databases and “consolidate” them down into a single source of truth. This approach is mostly used in data warehousing environments and for reporting purposes. The architecture for this use-case is similar to the unidirectional architecture; the only difference is that the target database is accepting data from multiple sources. Figure 4-2 provides a conceptual view of this architecture.
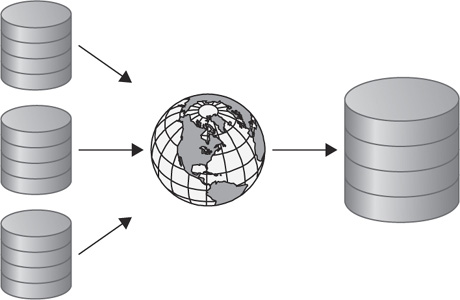
FIGURE 4-2. Oracle GoldenGate consolidation architecture (conceptual)
Data Distribution Use-Case
The opposite of the consolidation use-case is the data distribution use-case. This use-case is used when an organization wants to distribute subsets of data to smaller databases or remote office locations. The subsetting of data is where data integration becomes critical with this architecture. Knowing how to split the data for different sites is necessary to make this architecture work. Later in the chapter, we’ll discuss how to use functions to allow data to be split while in transit. Figure 4-3 provides a conceptual view of this architecture.
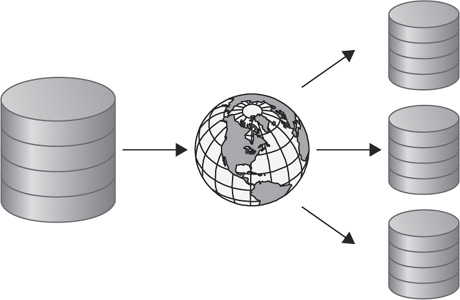
FIGURE 4-3. Oracle GoldenGate data distribution architecture (conceptual)
Near-Zero-Downtime Migration
Another use-case similar to the unidirectional use-case is the near-zero-downtime migration. This use-case is often used to move an organization from different versions of Oracle Database or other heterogeneous environments to Oracle while ensuring operational integrity. Then, when ready, the organization can take a much smaller outage window and move critical business applications over to the new database platform.
The architecture for this use-case is what can be termed a “hybrid” architecture between unidirectional and bidirectional. This is because unidirectional replication is used to migrate the database, yet a return stream of data is used to ensure that data captured in the new environment is captured and sent back to the old environment (not applied) in case the migration fails. Figure 4-4 provides a conceptual view of this architecture.

FIGURE 4-4. Oracle GoldenGate near-zero-downtime migration (conceptual)
So far the discussion has resolved around the conceptual architectures of the use-cases used for data integration with Oracle GoldenGate. All the architectures discussed are built off of the simple architecture of unidirectional data replication. Let’s dig a bit deeper into the unidirectional architecture and identify what exactly is needed to make these architectures work.
Oracle GoldenGate Architecture
Oracle GoldenGate consists of three basic processes regardless of the direction in which they are configured. These processes consist of a capture (extract) process, a data pump (extract) process, and an apply (replicat) process. In between these processes are files called trail files that aid in the movement of the data. Figure 4-5 provides a conceptual look at how Oracle GoldenGate is configured for a unidirectional architecture.

FIGURE 4-5. Oracle GoldenGate unidirectional
As illustrated in Figure 4-5, we have a capture process, trail files (local), a data pump process, and then trail files (remote) and an apply process. These processes all play a critical part in the data integration process when Oracle GoldenGate is used for replicat data. Table 4-1 provides a breakdown of what each of these processes does.

TABLE 4-1. Oracle GoldenGate Processes
As we go through this chapter, the processes outlined in Table 4-1 will be discussed as to how we can use them for data integration. Let’s take a closer look at each of these processes now.
Capture (Extract) Process
For data integration purposes, the capture (extract) process is critical for capturing changed data from source systems. The capture process is used to extract data directly from the source and write the changed data captured to the local trail files. For Oracle databases, the capture process extracts data from the online redo log or from the archive logs (if configured). For other database platforms, the capture process extracts from similar transaction logs. The data that is captured is captured in real time, chronologically, when data is committed. In order to ensure that all the data is captured, the database needs to be configured to ensure that every transaction is captured as it is applied to the source database.
In order for the capture process to capture all the data as it is applied, the database needs to be configured to capture every change as it happens. The changes required are performed at the database layer; these changes ensure that supplemental logging and force logging are enabled for the database. Once these changes are made, they can be verified by looking at the supplemental_log_data_min and force_logging columns of the V$DATABASE view. The query shown in Listing 4-1 can be used to ensure that an Oracle database has these options turned on.
![]()
Listing 4-1 Check Oracle Database Logging Options
![]()

NOTE
Supplemental logging and force logging are specific to the Oracle database. Other databases that Oracle GoldenGate supports (heterogeneous) will have different requirements. Consult specific database documentation if required.
If the results from the query return as “NO,” then the database needs to have supplemental logging and force logging enabled. Once these options are enabled, the database ensures that all transactions and changed values are captured before passing them to the local trail file.
Force Loggings/Supplemental Logging
The database settings that need to be enabled to ensure data capture are required by Oracle GoldenGate. The force logging option ensures that all transactions and loads are captured, overriding any storage or user settings that may be to the contrary. Using force logging ensures that no data is left out of the extract configuration. Supplemental logging takes the logging a bit further by ensure that all row-chaining information, if it exists, is captured to the redo logs for updates that occur during transactions.
Capturing additional data for each transaction that is committed in the source system inherently lends to an increase in redo log sizes and a possible decrease in performance of writes to these files. In order to keep a system functioning as expected, increasing the size of the redo logs will help the performance of the system over time. Exactly what size the redo log files should grow to varies between environments.
Data Pump (Extract) Process
If you’re using Oracle GoldenGate for data integration purposes, the data pump process may or may not be needed. Having an understanding of what the data pump process is will help you in deciding when to use it during the data integration process.
The data pump process is an extract process like the capture process discussed previously; the main difference between these two extracts is that the data pump can be used to ship the trail files to the target in the architecture. Besides the shipping of the trail files, the data pump can be configured to add relative information on what is happening within the environment as the data is passed through the data pump.
Apply (Replicat) Process
At this point, the apply process reads the trail files that have been created by the capture process and shipped to the target system by the data pump process. When the apply process reads the trail files, the changed data within the trail file is applied to the target database in the same chronological order in which it was captured. This ensures that the data is applied in the correct order so there are no database errors with primary keys, foreign keys, or unique key constraints.
Viewing the apply process from the data integration angle, you can use the apply process to perform an initial load of data from a flat file. The ability to read flat file formats using the apply process is beneficial for the data integration processes. Flat files will come in many different formats, and being able to read these formats is critical to the data integration process.
With the ability to support applying data either in real time using the apply process or by reading data in from flat files, it is valuable to understand when to use each approach. In most architectures, using the apply process to read directly from the trail files is the most efficient way of applying data. The trail files provide a relative byte address (RBA) that allows you to identify where in the apply process the transactions are located. When you use the apply process to apply flat files, via initial loads, the replicat is only running while the flat file is being read. The initial load process is an all-or-nothing type of process. If errors occur in the loading process, the process needs to be restarted after the problem has been resolved.
With either approach, the apply process is critical in the data integration process to ensure that data is loaded where expected.
Trail File
In any Oracle GoldenGate configuration, the glue that binds all these processes is the trail file. The two types of trail files are the local trail file and the remote trail file. The local trail file is associated with the capture process; it is used to store the changed data captured in chronological order for shipping across the network. The remote trail file is similar to the local trail; however, in most cases the trail file is renamed for tracking purposes on the target side.
Trail files also keep track of what data is stored in each file by using relative byte addresses. These addresses are pointers within the trail files to help identify the start and end of the transaction. The RBAs can also be used to estimate the size of the transaction and how long it will take to apply to the target system.
NOTE
Trail files are binary text files that can be read using the LogDump utility for troubleshooting purposes.
Now that we have discussed the components of the Oracle GoldenGate architecture, let’s take a look at what can be achieved with using Oracle GoldenGate.
Transforming Data on the Fly with Oracle GoldenGate
Up until this point, we have discussed the conceptual architectures of Oracle GoldenGate for data integration and the components need to make Oracle GoldenGate work in these architectures. Now let’s take a look at how we can use Oracle GoldenGate to transform data through the Oracle GoldenGate environment.
Oracle GoldenGate provides a utility with the core product for changing the table structure while the data is actively replicated. This utility is called Definition Generator, or DEFGEN for short. The Definition Generator utility allows for definition files to be created that support the defining of the table metadata structure on either the source or target side of the replication process. In this section, we will take a look at how to use the DEFGEN utility to map the source table to the target table.
When you are replicating data using Oracle GoldenGate, the assumption made is that the metadata matches on both sides (source and target) of the replication environment. In some situations this assumption is incorrect and cannot be made. When this happens, the relationship between source and target metadata needs to be mapped to ensure successful replication. This is where using the DEFGEN utility will ensure successful integration of data on the target side.
NOTE
The DEFGEN utility is installed in the Oracle GoldenGate home directory.
Configure DEFGEN
Like anything in Oracle GoldenGate, before it can be used it needs to be configured. In order to configure a source-side mapping with the DEFGEN utility, you need to create a parameter file. The following steps will create a parameter file called defgen.prm:
1. From GGSCI, edit a parameter file called defgen:
![]()
2. Edit the parameter file with the parameters needed:

3. Save and close the file.
4. Exit GGSCI.
After saving the parameter file, you will be ready to run the DEFGEN utility to generate the definition file needed to ensure mapping of the source columns to the columns on the target side.
Parameters that can be used in the parameter file for generating a definition file can be found in Table 4-2.

TABLE 4-2. Parameters for DEFGEN
Running DEFGEN
After the parameter file has been saved, the next thing is to run the DEFGEN utility to create the definition file. To run DEFGEN, make sure that you are in the home directory for Oracle GoldenGate. The utility is run with the parameters defined in Table 4-3.

TABLE 4-3. Parameters for DEFGEN Run
The command to run the DEFGEN utility to create the definition file needed is fairly simple. Listing 4-2 provides an example of running the command using relative paths.
![]()
Listing 4-2 Running DEFGEN Utility

After the definition file has been generated, the file needs to be copied over to the target system and specified in the replicat parameter file. To copy the definition file to the target system, you can use any FTP or SCP utility, as long as the transfer is done in binary mode. This ensures that the file is copied correctly between any platforms.
NOTE
The definition file should be copied in binary mode to avoid any unexpected characters being placed in the file by the FTP utility.
Once the definition file is copied to the target system, you can associate the file with the replicat parameter file by using the SOURCEDEFS parameter. Listing 4-3 provides a look at how a replicat parameter file would look with the definition file defined.
![]()
Listing 4-3 Replicat Parameter File with Definition File Defined

After you configure the replicat to use the definition file, data can be mapped between source and target without any errors. Notice in Listing 4-3 that the MAP statement has an extract option after Oracle GoldenGate is told where the target table is. DEF is an option for the MAP parameter; it is used to tell the replicat to use the definition file specified. When you use a definition file, the table metadata can be different between source and target systems. This makes the process of integrating data between different systems easier and more flexible.
Using Oracle GoldenGate to Create Flat Files
When the requirements for data integration entail that data be placed into flat files for ingestion by other tools, Oracle GoldenGate can meet this challenge. Starting with Oracle GoldenGate 12c, the flat file and Java Messaging Service options have been integrated into the core product. For now, we will focus on the flat file option of Oracle GoldenGate.
NOTE
In previous versions of Oracle GoldenGate (11g and earlier), there was a separately installed flat file for the application. These files can be obtained from https://edelivery.oracle.com.
Types of Flat Files
Oracle GoldenGate can generate two types of flat files as output files. The first of these files is known as a delimiter separated values (DSV) file. The second is known as a length separated values (LSV) file. The Oracle GoldenGate Extract process can generate both types of files.
Delimiter Separated Values Files
Delimiter separated values (DSV) files contain data from the source database that is formatted into a flat file separated by a delimiter value. This value is typically a comma, but can be any value defined by the user. An example of a DSV file would be a flat file that contains company data for employees. A DSV file would look something like this:
![]()
We will take a look at how to write data out to a DSV-formatted file in the next section.
Length Separated Values File
Just like a delimiter separated value file, a length separated values (LSV) file contains data separated by a specified length. The length of the data determines the space between the values in the record. An example of this would be an employee record, where each column is a fixed length—for example, LAST_NAME, char(30). An LSV file would look something like this:
![]()
We will take a look at how to generate an LSV file in the next section.
Generating Flat Files
Now that you know what kind of files you can generate using Oracle GoldenGate, what options do you have available to create these types of flat files? The parameters that can be used for flat files are listed in Table 4-4. These parameters generate flat files in a mixture of different formats. We will focus on the basic type of flat file that can be generated using the FORMATASCII options.

TABLE 4-4. Extract Parameters to Write Flat Files
In order to generate a flat file using the FORMATASCII parameter, the capture (extract) process needs to have a unique parameter file. This capture parameter file is slightly different from a normal capture parameter file. The following example will write a flat file in the default delimiter separated values format. Keep in mind that this will be written to a text-based file instead of a trail file.

Once the parameter file has been created, the only thing left to do is to add the extract and start the process. Once the process is started, the extracted data will be written to the file specified in the desired format. After the file is written, the flat file can be used by any external data integration utility, such as Oracle Data Integrator, or a basic text editor to view and manipulate the data in the file.
NOTE
The other parameters listed in Table 4-4 will generate data in flat files either as SQL statements that can be run against a database or as XML that can be used for business applications.
All of these options are designed to ensure that the data captured can be easily integrated—either by text, SQL, or XML—into other systems. Let’s take a look at how an extract is configured to provide these outputs.
The megabytes clause for the EXTFILE parameter is used to tell Oracle GoldenGate how big the flat file is allowed to grow to.
Generating an ASCII-Formatted File
You can use the FORMATASCII parameter to send transactions to a flat file rather than the normal canonical formatted trail file. By using this option, you can output transactions to a compatible flat file format that can be used with most business integration tools that can read ASCII-formatted files. Although this option provides a way to enable integration to other utilities, a few limitations must be kept in mind when you are using flat file options. Do not use FORMATASCII in the following cases:
![]() The data will be processed by the replicat process.
The data will be processed by the replicat process.
![]() FORMATSQL or FORMATXML is being used.
FORMATSQL or FORMATXML is being used.
![]() The data contains large objects (LOBs).
The data contains large objects (LOBs).
![]() You are extracting from an IBM DB2 subsystem.
You are extracting from an IBM DB2 subsystem.
![]() Data Definition Language support is enabled in Oracle GoldenGate.
Data Definition Language support is enabled in Oracle GoldenGate.
![]() PASSTHRU mode is enabled for a data pump process.
PASSTHRU mode is enabled for a data pump process.
Depending on your purpose for using FORMATASCII or any of the other formatting options, it may be necessary to create a separate extract instead of updating the existing extract process.
Listing 4-4 shows an example of how the extract file needs to be configured to enable writing to an ASCII-formatted file on the source side.
![]()
Listing 4-4 Extract Parameter File to Write ASCII Formats

Looking at Listing 4-4, you can see that we have an ASCII-formatted file located in the dirdat directory of the Oracle GoldenGate 12c home. When we review extracted transactions in the ASCII file, by default the transaction is delimited by commas (see Listing 4-5).
![]()
Listing 4-5 ASCII-Formatted File Output

Reviewing the data in the ASCII file in Listing 4-5, it is clear that commas separate the transactions; however, a single character that is not part of the transaction precedes each line of the file. These characters indicate what types of transactions are in the file. Just as a canonical trail file indicates that a record is a before or after image of the transaction, these are shown in the ASCII file. The values shown in this ASCII file indicate that there are two before images: one is an insert and the other is an update. Table 4-5 provides a detailed explanation of how to identify these transactions.

TABLE 4-5. Record Indicators in ASCII Files
NOTE
A Before (B) image is an image of the captured data before the data is changed. An After (A) image is an image of the same transaction after the data has been changed. These two images provide a way for Oracle GoldenGate to track what is updated and roll back if needed. Compressed updates (V) are updates that Oracle GoldenGate has extracted from the source database in a compressed format. In a compressed format, more data can be stored in the extracted record.
Using Oracle GoldenGate to Create Native Database Loader Files
The Oracle GoldenGate flat file options can be used to create data files that are used with native database loaders such as Oracle SQL*Loader. This capability provides flexibility between the heterogeneous environments that Oracle GoldenGate supports. Oracle GoldenGate can write out three basic formats for usage by these native database-loading tools. These formats support Oracle SQL*Loader, XML, and SQL; these options are listed in Table 4-6.

TABLE 4-6. Supported Format Parameters
In order for database-loading utilities such as Oracle SQL*Loader and Oracle Data Integrator to ingest data, that data has to be in a formatted flat file. To ensure that the extract outputs the captured data in the format desired, you need to configure the extract parameter file. Let’s take a look at how an extract parameter file should be formatted to provide the output expected.
NOTE
The placement of these extract parameters will have an effect on all extract files and trail files listed after them.
Extracting for Database Utility Usage
Now that you understand how to write data to a flat file using the FORMATASCII option, it can be extended to enable length separated values (LSV) files. One way to extend the FORMATASCII option is for use with Oracle SQL*Loader. By providing an option for SQLLOADER after the FORMATASCII parameter, you can enable the extract to write LDV-formatted data. Listing 4-6 provides an example of the parameter that shows how the flat file extract created earlier can be modified to enable writing for SQLLOADER.

After the extract is started, the output is extracted in a length separated value format for Oracle SQL*Loader to use (see Listing 4-7).
![]()
Listing 4-7 LDV/SQL*Loader Formatted Output

Using Oracle GoldenGate to generate flat files for different business applications or database-load utilities can greatly save time when you need data in different formats and systems. Yet, this is only the beginning of data integration with Oracle GoldenGate.
Oracle GoldenGate User Exit Functions
Another option Oracle GoldenGate provides for data integration is the “user exit” functions, which are custom routines that are written in C and called during capture (extract) or apply (replicat) processing. A called user exit interacts with a UNIX shared object or a Microsoft Windows DLL during processing, thus allowing custom processing of transactions. Any custom-built user exit has to support four basic exit functions. A summary of these functions is located in Table 4-7.

TABLE 4-7. User Exit Functions
Oracle provides a good number of sample cases of using user exit functions with the core Oracle GoldenGate product. The examples can be found under the directory $OGG_HOME/UserExitsExamples. Again, remember that user exit functions use C programs to interact between Oracle GoldenGate and the host operating system.
Testing Data with Oracle GoldenGate
With any data integration process, it is important to test the data coming in or being transformed. Oracle GoldenGate provides functions that allow data to be tested while in flight from the source system to the target system. These functions are executed on a column basis. Table 4-8 provides a summary of these functions for quick reference.

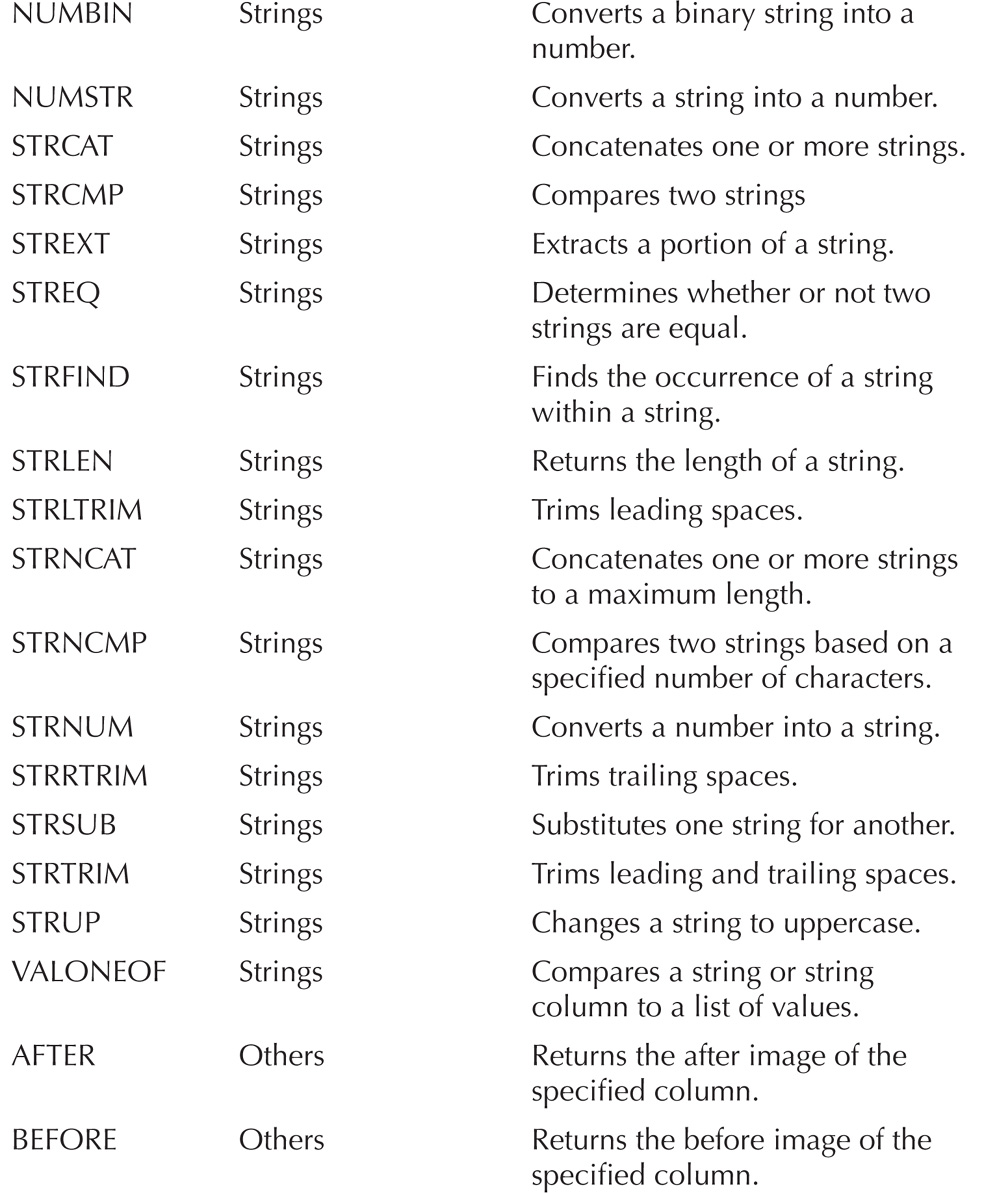
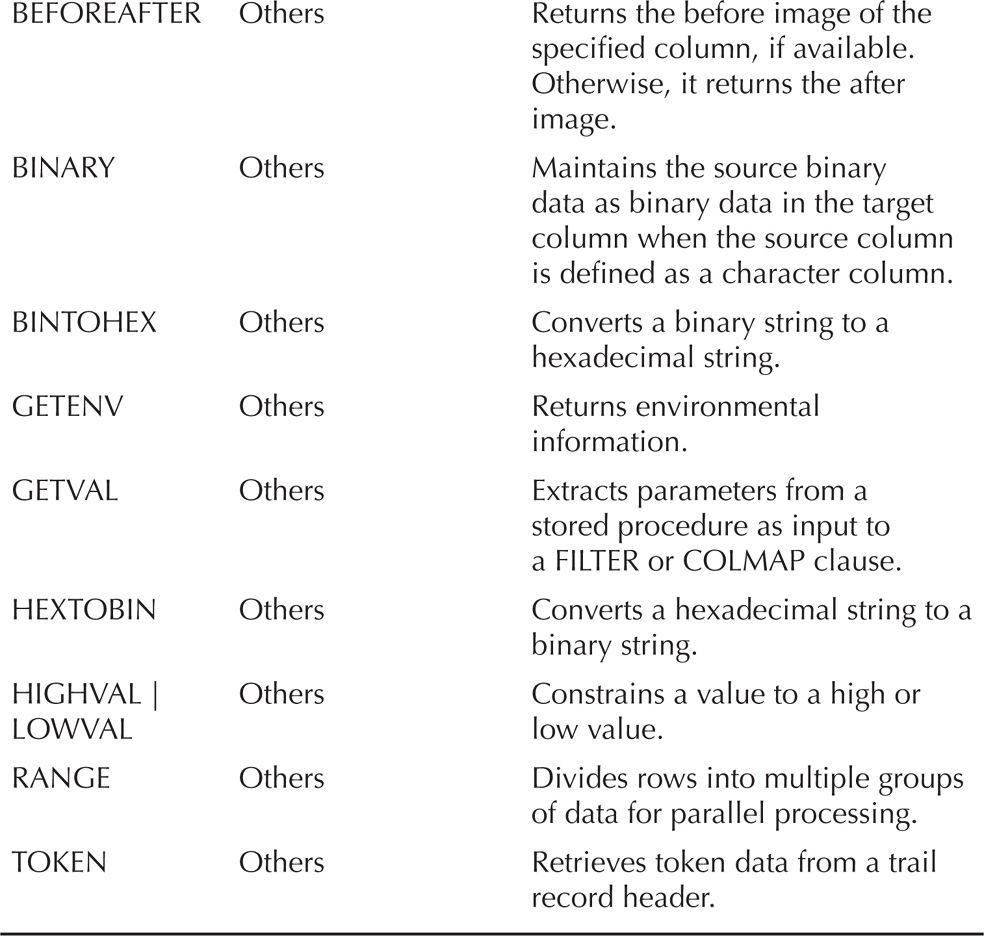
TABLE 4-8. Summary of Functions
As you can tell, a lot of functions can be used. Many of these functions fit into six different categories. Every category can help in identifying what is happening with the data. Let’s take a look at a few different functions.
Changing Data Using @IF
When testing data, you’ll find the functions in the performance-testing category helpful because you can change data while it is in flight. One such function is the @IF function. This function operates just like a normal programing if statement. The @IF function works by returning one of two values based on a defined condition.
NOTE
The @IF function can be used with other conditional arguments to test one or more exceptions.
In order to understand how the @IF functions works, take a look at the following syntax:
![]()
To use the @IF function, we need to enable the apply process to evaluate the data and make changes as required based on the values of the function. In order to do this, the MAP clause of the apply process parameter file needs to be updated. Listing 4-8 provides an example of a parameter file using the @IF function.
![]()
Listing 4-8 Replicat Using @IF Function

In Listing 4-8, we are saying to check the price column of the data coming in to see if the value is greater than 100. If the value is greater than 100, then round the price to 1000; otherwise, leave the price as the value being replicated.
By using conditional checking within Oracle GoldenGate, you can evaluate and change data as it is replicated between environments. Performing these conditional checks during replication enables you (or an administrator) to quickly make changes to data as needed without spending a lot of time scrubbing it beforehand.
Summary
In this chapter we discussed Oracle GoldenGate and highlighted some of the features that can be used in the data integration process. These features are found in many different areas of the Oracle GoldenGate tool; they enable Oracle GoldenGate to provide a flexible and reliable way of moving and transforming data across platforms. To what end can Oracle GoldenGate be used in a data integration scenario? There appears to be no end in sight, making it one of the best data integration tools around.
The flexibility of Oracle GoldenGate places it in a great position for future data integration roles. So much so, Oracle has indicated that Oracle GoldenGate is now the replication tool for future releases of Oracle Database. In addition to being the replication tool for the Oracle Database, Oracle GoldenGate can be coupled with tools such as Oracle Data Integrator to promote faster integration of data across diverse platforms. By using Oracle GoldenGate as a fundamental tool for any extracted, loaded, and transformed (ELT) process, a business can greatly increase its decision-making processes and become more agile in the process.
