

CHAPTER
7
Data Cleansing
Information is only as good as the source, and having incomplete or inaccurate data can lead to incorrect information. Not only does this not provide the details that are needed, but there might be issues in integrating the data. In the previous chapters we discussed methods to integrate data to make it useful; however, the quality of the data also needs to be considered.
Data quality defines the successfulness of an integration. Being able to provide consistent and complete data that is integrated with other systems for a “big picture” view will show the value of data. The data quality process might already be part of the overall business process, but it might just be needed for specific data integrations.
The reason for data integrations might just be that they are part of a solution for better data quality. Integrating data from different sources can help with the data cleansing in providing more details around the data, as well as providing a direction for data cleansing based on the additional information in other systems. Data integration involves more than just collecting the information in a source for consumption, but is also an essential tool for data quality. In this chapter, we look at the aspects of having to cleanse data for better integrations and using data integrations to assist in the process of providing higher data quality.
What Is Data Cleansing?
Data cleansing is the process of validating, correcting, and completing data to provide reliable information and completed records of data. Raw data might have characters, spaces, and other values that do not normally belong in there. When data is being loaded, validation steps perform some of the data scrubbing and data cleansing activities. There might be data that is not completed, and either filtering out the records or providing the needed additional information is also part of the data cleansing process.
Customer and client data is needed information in several business processes, and this might be data that is manually entered or pulled from another system. Either way, the data might have incomplete addresses or typos from the entry process. Customer data and addresses could have business rules around them to make sure they are correct for shipping and billing, and there might be reports generated if data is incomplete and needs follow-up to make sure all the detail is available. Having the data entered and then going through a process to cleanse the data will provide the right information in the system. Reference data is another set of data that should go through data cleansing steps to make sure this information is consistent and complete when it is supplied to other environments. The steps in the process of providing complete and accurate data include applying the business rules and correcting the data; this is what is meant by data cleansing, and will be discussed later in this chapter.
Does data cleansing mean data quality? Not necessarily. The quality of the data might mean different things to different data owners. Data that is incomplete or provides only certain specific details might be sufficient for one of the business processes, but would be completely lacking for sharing. For that particular data owner, it might not be a priority to have another source using the data. Even though that might sound a little selfish, the originating source of the data might be one main reason for not sharing the information. We will discuss this topic later when we talk about data sources, but for now just realize that data quality can mean different things to different groups.
Data quality can be considered the accuracy, consistency, and completeness of the data. Also, a time aspect of the information (that is, whether the data is current and reliable) can fall under data quality issues. Not all the quality problems that arise might be part of the data integration, and one might be able to integrate data even if it is stale. Whether that is the data and information needed is a different question.
Data cleansing involves scrubbing the data, detecting whether the data is accurate, and then correcting the data. Data cleansing is a process that can be part of the overall data quality plan and processes, and it can also be part of a data integration plan.
So, why are we concerned with data cleansing and data quality? If we are specifically looking at the data from the viewpoint of integrations, then this limits the scope. We have to understand that the business is going to have expectations concerning the quality of the data, and might develop a process as part of the input and loading of the data. The quality of the data determines how complete and accurate the data is, which in turn makes the integration process easier. If processes are already in place for correcting the data, then as the data integrations uncover additional discrepancies, there will need to be workflows back into the existing cleansing processes. If these processes don’t exist, or if new areas are showing incomplete or inaccurate data, additional workflows need to be developed to handle the data cleansing process that will support the overall data quality.
Master Data Management
This all might be starting to sound like master data management (MDM), and in most aspects it is. Master data management is the process, standard, and governance around the different sets of the company’s data. MDM might be for reference data and core entities, which can be the foundational information or data that supports the business model. This data is consistent and can be managed and reported. Sets of master data have attributes and identifiers that define them and make them manageable across the enterprise.
If this is starting to sound like a much bigger process than just cleaning up a little bit of data, that’s because it is. The current data integration and data cleansing might not be ready for a true MDM process and governance; however, this might be the first step toward developing a way to provide these consistencies in source, type of data, and data quality. Putting an MDM with procedures and process in place takes several teams working together. The business needs to agree on data definitions as they relate to the business and how the data is to be used. The data steward is concerned about the data work flow so that it provides the most consist data sets and sources. And technology is there to support these processes and to aid in understanding the tools and how to implement them effectively so that the business and data stewards can take care of the data and provide high-quality information.
Master data management might be a current data practice in the environment; in that case, data quality and cleansing happen as part of this process. Depending on the maturity of the MDM, additional processes around data integrations and cleansing might be needed to augment the existing process—and if tools are available that can perform these tasks better, then those should be investigated as options to improve the process and provide the expected data.
Developing data cleansing processes might lead to an MDM strategy. As you can tell, an MDM strategy involves a high level of detail for managing and governing the different data entities in the company, and the processes around data quality, cleansing, and integrating are tools in this strategy. Even if you’re not completely there with MDM, be careful, because developing solid processes around integration and cleansing will lead you down the path to MDM—which would be a good thing.
Mentioning master data management in a data integration book is important because it is a strategy that provides a reason to perform data integrations. MDM is an overall strategy that can help with data cleansing and integrations, but it is not the focus of this book. Data cleansing is always a necessary part of MDM, and the processes are valuable in this way and can support and lead to an MDM solution. The data cleansing and quality processes can be employed for refining, improving, and cleansing all types of data (not just master data) as part of a data strategy. These processes are an important aspect of understanding the value of data quality, cleansing, and integrating. The processes that follow focus on the data quality and cleansing.
Process
Data cleansing is part of the data integration process, but it is part of the even bigger data quality process. Unfortunately, the data cleansing process cannot always be solved via tools, but there are tools that make the process easier. Validating data starts with data coming into the system. There should be controls around the integrity of the data coming in from the different sources. Data stewards should be the ones monitoring and validating the processes because they can confirm the information that is coming out of the system. The data stewards can use the technology and tools to work through the issues and problems of inconsistent and missing data.
Data cleansing is a business process first, and parts of this process can be implemented by technical processes using tools. The process is focused on the data flows, which includes establishing data context, assessing data, evolving business rules, cleansing data, and monitoring data. Figure 7-1 shows the steps in this process.

FIGURE 7-1. Data quality steps
The first step in improving data quality is to establish the data context. It is important to understand the landscape of where the data is coming from before starting corrective actions. If the source or where the data is stored and processed isn’t completely understood, activities here can be redundant or incomplete solutions. There should be documents about the data, such as data models, a data dictionary, process flows, system documentation, and even data governance policies that come from MDM strategies.
All stakeholders, source system application managers, business folk, and data analysts have to be involved in building the knowledge about the data context and the data governance policies. Building this knowledge and these policies is a non-technical exercise and requires the input from the invested parties.
The second step is to assess the data. Many measurements and comparisons can be used to assess the quality. A combination of customized business rules and measurements are needed for a complete assessment. Measurements should be over a couple of areas to be able to validate the data. Measure on a field-by-field basis for completeness, uniqueness, validity, and other field values. There should be a consistency to the relationships and business rules applied between different fields. This measures the attribute data dependencies within the table. Also, measure the integrity between tables. The relationships need to be confirmed with the correct foreign keys, and identifying the disconnected data between tables will show the level of data quality.
Evolving business requirements is the third step. As things are learned from the data profile and the gathered measurements, business requirements need to be revisited. This is an on-going process. This includes assessing the data and environment and then measuring and checking the processes and business rules that define the organization. This does go beyond the standard metrics and requires special focus to learn more about the current state of your data and what needs to be done to enhance and improve the process. The reliability of the data depends on maintaining these rules and continuously improving them. Most of the data quality tools have built-in knowledge repositories that manage these rules and allow for modifications and a feedback loop for the business requirements. This will be part of the tools discussion later in the chapter.
Step four is cleansing the data. The data environment is assessed and business rules are updated so that the data corrections can begin. Cleansing the data for current issues can be done using a couple different methods: manual and automated. Manual updates are normally for a small set of data and one-off corrects. These updates go record by record via a GUI or application to correct the data. Backend updates and edits are also possible using queries directly on the database. Mass updates are possible through this method when obvious and well-defined changes are needed. The changes must be validated because going to the backend might possibly introduce new issues. As with most database environments, there is also a hybrid of the manual and automated processes. The analysis is part of the automated process, but might require the manual step of reviewing and executing the cleansing step. This could also move the cleansing step to the data warehouse and just let the data be loaded. Depending on the results of the analysis, it might make sense to cleanse the data in the source. So even with the tools and the discovery of data issues, other decisions might need to be made to take care of the data at the source, or later in the process. Additional business rules might be needed around where the data should be cleansed. This adds complexity to the process, and may require the use of tools to manually adjust the process.
Another method involves the use of a data cleansing tool. Tools can provide additional controls and filtering information to assess gaps and issues that come from business requirements. A tool should have a knowledge repository to store the business rules. The knowledge repository can hold the rules for comparison against other systems and for further development. These rules in the repository should also be reused for data cleansing by applying the rules. Cleansing data might be done during a transformation or conversion to standardize the data. This method can perform data transformations and conversions into a new system. Using matching requirements or even data integrations can cleanse the data and provide a quality solution at the enterprise level.
The data cleansing process should not just look at the current state but should also focus on preventing future data errors. Proactive cleansing standards can eliminate the root cause of the data errors. Repetitive cleansing efforts can be reduced by accurately identifying the root cause and improving the process long term. This provides the most value to data quality to enhance the process and going back to the data context, if necessary, to cleanse it at the source. Data issues that are found need to be corrected in a timely mater, but it is especially important to set the proactive cleansing standards.
Monitor quality is the final step. How else would you get to the proactive data cleansing if there’s no monitoring feature available for the process. In monitoring the quality, future errors can be minimized, the cleansing of existing data can be verified, and the improvement of the data quality can be measured. Data quality scorecards and dashboards should reflect that, and they can be aligned with the efforts of data governance and master data management strategies. Business is always changing, and we already discussed that the business rules should be updated; data is not static either. After performing data cleansing, you need to understand the changes in the data and the process via monitoring. The trends and information provided by monitoring offer a full picture of data quality. Drill-down capabilities should be available for viewing the actual data errors as well as to show the charts and graphs of the data quality.
The process is a continuous cycle for working through the different sets of data that will need to be constantly monitored and verified against the current rules. Then even the business rules need to be validated to make sure the process meets them. The data steward should be the one confirming the process and doing the monitoring because, depending on the maturity of the steps, more issues might arise and more cleanup of data and adjustment of the rules might be needed until there is a consistent output of data.
Figure 7-2 shows where in the process data cleansing can take place. There are different levels of data cleansing, and information is needed at each of the steps. The data is gathered, and at step one (cleansing), the source data can be scrubbed. Before all the data gets loaded, it can be checked for completeness, and other reference data can be used to verify and add the correct information. Scripts can be used to remove spaces, unwanted characters, or duplicates. Other rules can be applied through regular expressions to clean up the data at this stage. Default values can be put into place to complete the data, and constraints can be used to confirm that the data is accurately being inserted at this point.
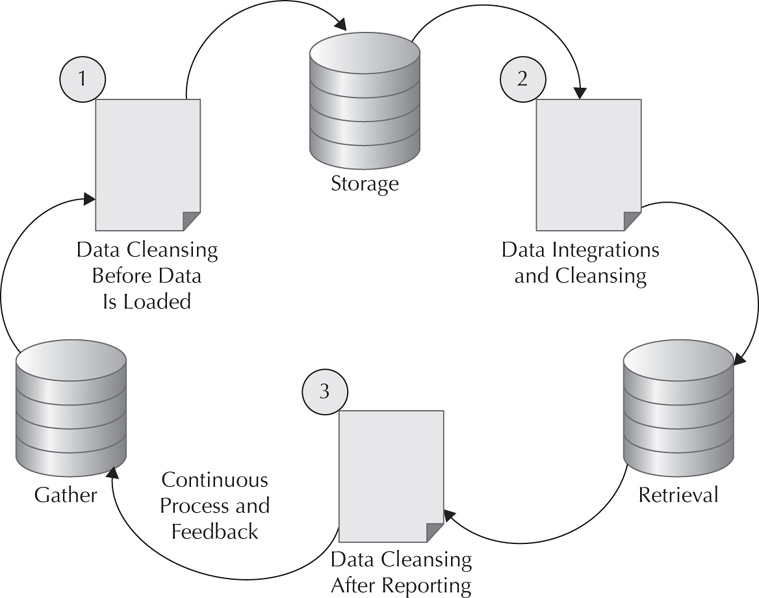
FIGURE 7-2. Steps for data cleansing
In step two (storage), the data is already in the store or database. It can be queried, and easier ways to join against other data sources are available. Duplicates can be removed from queries as well. Information about the data can be collected to help verify where the records needing change can be found. Records that are incomplete can be moved to another table for further analysis. This stage might be where data integrations play an even bigger part because information is available as a source. Here, the integrations can expose missing data and include additional sources to provide the details for the missing information. After the data is augmented by the integrations and additional cleanup via business rules comparison is completed, the information is ready for analysis.
Step three (retrieval) is another place for data stewards to access their reports and to check whether the data is as expected. There can be validations along with analytics, and these show the last opportunity to clean the data. Additional filters can be used in this stage to help with the quality checks before the data goes out for analysis and mining. As the data comes along this path, each stage is going to expose possible areas for data cleansing, but the costs for having already loaded data and the costs of handling the data quality issues later in the process are going to increase.
Standards
Standards are defined as part of the data integration process and are also set up for validation during the data cleansing part. Standards can also come under the master data management strategy, but most importantly they should be part of the role of the data steward. Standards help put the proper constraints around the data, determine whether defaults are needed, indicate formats for the data, and could also include details about the reference data required. Standards allow you to set up automated processes to cleanse the data.
Standards should include these dimensions for data quality: accuracy, uniqueness, consistency, completeness, conformity, and integrity. Accuracy should reflect the reality or the trusted source of truth. Uniqueness is simply identifying duplicate information and making the data values for the attribute unique. The tags around the data should be consistently defined so that the name is understood across the enterprise. It is important to have a standard around the data meaning and what the data is intended for. This needs to be clearly defined and agreed upon so that it can be used appropriately by all processes, systems, and business units.
Using standards to define what data is mandatory determines the completeness of the data. This can be defined at each step of the process, and the business rules can confirm whether the data is complete enough. Conformity defines information standards that should be followed by attributes, such as state abbreviations. Finally, the dimension of integrity ensures that foreign keys are used to refer to the core data; this prevents duplications and helps with the completeness of the data to ensure it exists.
Data stewards can use the process that defines how the data is to be cleansed to update the business rules and the standards used for data quality. Defining the aforementioned dimensions will standardize the data quality for the process.
Table 7-1 details the field standards for matching and validating data. It checks for uniqueness, completeness if the field is needed, or for matching based on the values allowed. These same data standards will help with cleansing the data.
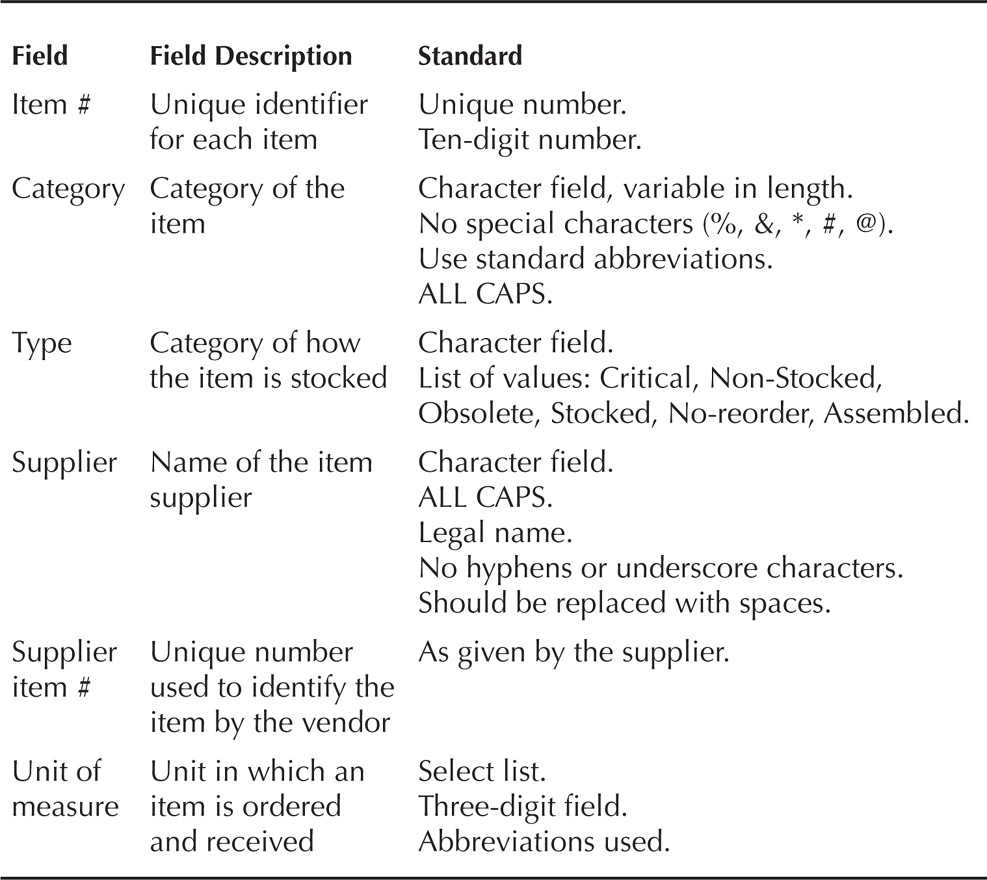
TABLE 7-1. Example of Field Naming for Standards
Standards can even be definitions of what the data is supposed to be and the descriptions of what the values mean, with possible matching with other data. Metadata should also have standards so that columns have enough meaning for data integrations to be performed and so that enough of the column detail for current data can be understood. Consistency doesn’t apply just to the data, but also the metadata and the definitions around the data. Using names that are not consistent or mean different things to various teams results in the standard not being followed. If the standard is not understood by the business and needs to be part of the processes used by everyone, then it should be agreed upon by all parties. The stakeholders and the ones managing these processes should participate together in defining standards. The data steward has the responsibility of validating these standards and confirming with everyone involved to ensure they are meeting the business needs.
When Standards Don’t Work
When not all of the different areas of the business agree, standards are not going to help with the data quality and data cleansing. Different values will always be coming in or used in the process incorrectly. Even if data stewards are owning their information and set the standard without considering other situations or other meanings, it might not be a standard that can be utilized by everyone. As discussed previously with the steps for reviewing and modifying the process based on knowledge base and standards, if these areas don’t agree, using automated processes will be difficult. Clean-up processes will be ongoing as changes happen to definitions and the standards. This information can be used to clean up standards for consistency in the environment. Pull the data stewards together to discuss and flush out the meanings. Make agreed-upon definitions part of the data model and catalog to be able to share the intended use of the data. If data differs or doesn’t have the same intended use, make a different definition for that data set and maintain both sets to keep the value of the information.
In order for standards to work, the data owners need to agree. If there is a similar data source or a data source that is needed in a particular group and that group doesn’t have access to the data or details about the data, gaps and inconsistencies can be produced with the data. Data stewards should work to make the data definition clear, and validate that it fits with the business needs. Being willing to assess the process and definition can provide additional information about the data and provide consistent attributes across the board.
Another issue with standards are outliers. If these fuzzy areas don’t fit standards, how do they fit into the data cleansing process? This data might be new or something that has changed, or even the standard may have changed. If the mapping for cleaning up this data doesn’t fit with the standard, it gets just as fuzzy as the data.
The changes outside of the process might be changes to the data layout or they might data type changes. Even with standards, the external changes will not meet what is expected. Just like the data layout, another example might be missing values, because NULL values are not being handled or there are gaps in the time series data. It might not even be changes to the process but a failure of a particular step in the process. What needs to be done when these changes happen? Because of the monitoring and gathering information about the data context, these changes are captured in the first place. After discovery, these should lead to improvements in the process. Defining the new standard and process depends on deciding if this is going to be the new behavior, how it changed, or whether different data sets are coming into the process. Review and document the standard and change. It might need to be manually edited or at least reviewed to figure out how to fit it back into the normal process. If it doesn’t fit back into the normal process, create a new one to incorporate the changes. Besides having to include changes, it is possible that the process cannot continue because of errors (for example, foreign key constraints). The non-standard data that is encountered will have to be handled and verified. This might actually include adding data for reference and not just cleansing data at the source for this process to continue. Additional reference data might be needed to avoid issues with cleansing the data, but the monitoring will help identify this data and the options to improve the process or improve the reference data needed.
Governing Data Sources
As one of the first steps in data cleansing and ensuring data quality, it is important to understand the data context. This includes information about the data, the model, process flows, and so on. Defining the process flows and flows of data should also help define the data sources. Understanding the source of the data is key. Did it come from another source? Was it manually entered? Did it get imported as part of batch process? How about ETL (extract, transform, and load) processes? These are all good questions to be asking about the source of data, including understanding the process of how the data was loaded or entered. Another thought about the data source is, what is the purpose of the source of data?
For the source of the data, it is important to understand what is available, and then how to map it with the standards. If the source of the data is a copy of a copy (or even just a copy), it might have its own issues with data quality, and a more trustworthy source of data should be used before you spend time and energy cleansing the copy of the data. The trustworthiness of the data also depends on the data steward and the standards that have been implemented around the data source. The data should have integrity checks, process management around data entry, duplication removal, and detection for field values. This goes back to the purpose of the data and understanding why the data is there and if it is available. Some sources are not meant to be shared because of the restrictive purpose of the data to solve a very specific issue. These sources might only be provided with a filter and/or not have a completed set of data. If the source is incomplete and has filters, it will not prove to be useful for the business or other solutions.
Discussions are important between data stewards to ensure that data sources can be used for the data integrations and the data cleansing processes. The contract that’s formed to be able to have a consistent source of data minimizes the amount of data cleanup that needs to happen.
A source of data might be reference data, such as address or standard product information. The reference data can then be used to help with matching and completing data information to keep it consistent. Another source of data might be application data that does not have foreign key constraints or internal consistency. Integrity problems at the source will cause issues and errors in using the data for integrations or with other systems, but these might go unnoticed at the source because of the application management of the data. The cleansing of this data at the source will be beneficial for other uses of the data as well as for the application at the source. Recognizing data models with the proper use of constraints and loading processes to enforce data integrity will produce useful sources of data.
Understanding the sources of the data for data integrations is also important, as well as learning what should be mapped to provide a good view of the joined data. Using copies of copies doesn’t get to the golden source of data. The golden source of data references the good copy, the main source, or the copy of the data closest to the source of data. This golden source could possibly have already been cleansed based on the business rules for loading the data, and now it is available for use by other sources. Focus should be on the golden source of data to make sure that it is valid and complete to be able to provide the data that is needed.
Figure 7-3 shows what detail and information should be available around the data context or data source of the system. System documents should provide these details about the data source, including the purpose and any definitions to make it clear what the source is being used for. The process and policies provide the additional detail needed to see how the data is already being handled. Again, getting to the golden source of data and using that to either supplement the new source of information or use as a data integration source will provide more consistent and complete data than a copy of a copy.
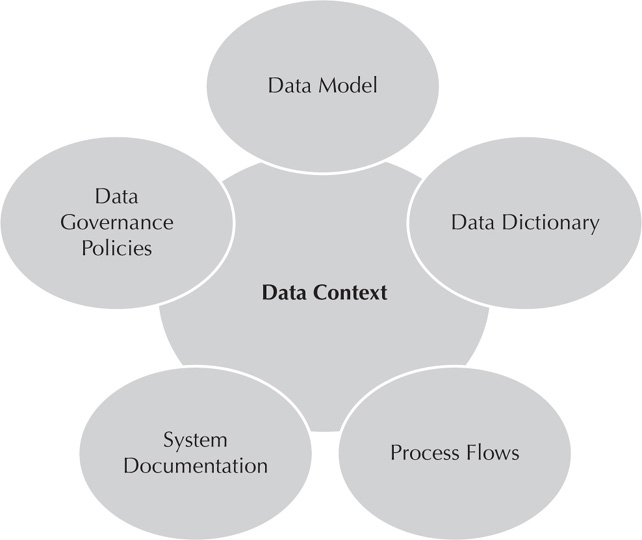
FIGURE 7-3. Data context
Not only do copies make some of the cleansing difficult, but changing data sources adds difficulties as well. You need to be prepared for changing source data and existing workarounds. Despite analyzing and building scripts to clean the existing data sets, new issues can still arise as data owners and users try to work around issues separately from the data cleansing efforts. There might be a need to see a side-by-side comparison of the raw data and the cleansed data.
It seems to make sense to use the most complete and verified data source for any data integrations. If this source has another data steward, it might be difficult to perform data cleansing on the actual source for data integrations or other data needs. The data steward of that data source would need to be brought in for that purpose. Just like with needing to change the information about other data sources in a timely manner, it might be possible to create a mapping table with the needed details. Another way to clean up data is to add the needed attributes or the mappings to a combined data source. If you are adding attributes to the data, they will need to be included in the business rules and then reviewed for changes and monitored.
Understanding the details about the source of data being used will provide information about what the potential areas are for data cleansing and quality. This information should define the data and purpose as well as provide details on how the data is loaded. The records from the golden source of data should already be clean, accurate, and de-duplicated. The golden source of data is the primary source of the data and information. This type of source was discussed in Chapter 1, when we talked about the data integration process, but the cleansing might happen as part of the process and maintenance for the golden source of data. Then when you’re performing the integrations with this golden source, little cleansing is needed because the records are cleansed at the source. When combining sources and pulling in various data sources, you will need to validate that the data still has integrity and doesn’t require any further cleanup.
Data quality tools need to be able to pull in several different sources of data to be part of the data sources available for the integrations. Being able to work with different database platforms and data formats allows for more inputs into the system. Various sources need to be validated and cleansed as part of the process. Not only do the data sources and context need to be considered as part of the tool decision, but being able to integrate with other tools that can provide standards such as MDM tools is also a requirement for the overall master data strategy. Business process management should incorporate ways to include all of the business rules into a system that has a place of record for these rules. The tool should allow for evaluation of the business rules against the data sources. Again this is only possible if the tools can work together. From the evaluation and processes, it will be necessary to change and modify the rules in the tools to improve the overall data quality and standards. One more very important piece of the tool is the ability to monitor, because the data cleansing is an ongoing process, and monitoring the data quality as well as auditing the automated cleanup and data cleansing process provides the information to continuously assess the environment and the data.
Data stewards play a very valuable role in maintaining the data source and providing the business rules around it. The stewards can provide details that assist in the understanding of the data sources and how they should be used. However, sometimes data stewards are not always sure what data they have, or they might not even know what they need to do. They might be concerned about a specific problem or focus on a certain area of the data, which means other pieces of the data might not be complete or valid. Having a party responsible for the data and information in the source is a qualification for having data quality. Data cleansing can take place every time as part of the process, but if there is no owner for the data, the processes cannot be improved or maintained. These data issues will remain a problem. When choosing sources of data, you should also consider the data owner and data steward for the data. Consistent and complete data is going to be provided by the sources that have a responsible party for ensuring that the proper process is in place and that data cleansing occurs. The business owner might push this off onto another group or not want to have the responsibility for working with the data. This is where the data governance or MDM strategy will help. It requires that there be an owner and steward. Any sources without governance should not be considered for integrations because the cleanup effort will be continuous without any validation that is it providing correct data and information.
In the next section of the chapter, we discuss tools and how they provide the needed resources to automate the cleansing and data flows. We also discuss the import tools for the data stewards. Data stewards need to have dashboards and reports about their data in order to have the information easily accessible to make sure everything is in front of them. Access to the data cleansing tools will provide the data stewards with what they need to maintain a reliable source of data that’s consistent, complete, and part of the process for continuous improvement as the business changes and data needs evolve.
Tools for Cleansing
You need to consider several different areas when looking at data cleansing, from data source to integration. We have already discussed different methods for cleansing. Using tools can provide more consistent solutions as well as ways to automate, review, and change the cleansing process. Tools should be evaluated based on the complexity of the business rules and the frequency of changes, as well as whether they meet the monitoring needs and provide ways to improve data quality.
Tools offer ways to build custom scripts and checks to validate the data cleansing process. Manual updates might also be possible if there are one-off issues to fix, and the processes are continuously updated to be proactive about fixing the root source of the data. However, more sophisticated tools provide dashboards and can even store the standards and business rules. Tools assist in the review process and are able to audit the changes that come through to proactively address root issues.
If you’re evaluating tools for data quality that provide data cleansing processes along with business rule management, the features you should look for include functionality around entry controls, rules engines, knowledge base, and monitoring. Additional information might be considered, such as the follow information.
Data domains and mixed platforms are normally in most enterprises now, so tools that can handle the heterogeneous platforms are needed. Tools can be integrated with other products that are already owned and can collectively provide dashboards on the rules, stewardship of the data, and improvements in data quality. Tools should be easy to use, put the details in the right hands (such as data stewards), and get the information to the user to verify the process and functionality.
Oracle Data Integrator (ODI) has already been discussed as a tool for data integrations, but it also has built-in rules for data quality and cleansing. The first step, as shown in Figure 7-4, is to profile the data. This means that the data is analyzed based on the different sources and data stores to detect patterns for comparing the data with expected values. The metadata is used for this comparison to drill down into the data to provide information and assess the data quality. The baseline is included with the profile to include ways to understand actual data values in the system. This is part of the initial design for the integration process. As we already discussed, the first step in determining data quality is to look at the data context, which is done by profiling the data in ODI. The profiling helps to increase the quality of data because the rules can be developed to be used as part of the integration and load processes. The associated risks of the data profiling will show the areas to be concerned with and can be a focus area to implement the rules to repair. This will reduce implementation time when this tool is used as part of the process and is not a one-time activity. It provides the monitoring to go through and assess the ongoing process to ensure that the rules are being followed, and the rules can be adjusted in order for the data to be trusted.

FIGURE 7-4. Oracle Data Integrator Studio: constraints and rules
The rules are set up and applied to the application’s data as part of the load and transform jobs to ensure the integrity and consistency of the data. Data quality rules are added to profile the data.
Rules can be added using the Integrator Studio, such as database constraints, column mappings, and de-duplication of data. Rules can also be pulled directly from the database. So if proper constraints are in place on the database for uniqueness or default values, these rules can be pulled directly into the Oracle Data Integrator. Once the rules are pulled in from the database, new rules can be created.
The types of rules that can be defined here are uniqueness rules and referential integrity rules, including foreign keys and defaults based on the data relationships. Validation rules are also used to enforce consistency at the record level, which provides a mechanism for data completeness with default values and rules around the values in the record. For example, the states for addresses should be looked up to be consistent and the ZIP codes must be provided. Check rules can make sure the email is in the proper format so that a valid email address has been provided.
After the rules are created, they are added for data quality in the ETL process of the ODI. The errors in the data can be handled in four different ways to correct the data issues and provide data cleansing as part of the tool. First, errors can be handled automatically to correct the data. The data cleansing interfaces can be scheduled to run at intervals to correct the data. Second, the tool can accept the incorrect data in case the data needs to be filtered out at another point in the data integration. A third way these errors can be handled involves the invalid data being sent to users in various formats as part of a workflow to correct the invalid records as part of a manual workflow. Finally, the errors can be recycled into the integration procedure to process the data again.
Auditing information is part of the ODI steps for data cleansing so the incorrect data can be handled and reported on. This is part of the continuous monitoring to show that data quality steps are improving and following the business rules defined in the tool. As the monitoring is reviewed, the steps or how the data cleansing is being handled can be adjusted to fix the rules and data. The tool can be used to help develop the standardizations of the data types and quickly configure a package to deploy as another rule as part of the standard for parsing and handling the data cleansing. ODI offers matching and merging functionality to identify matching records to link or to merge matched records based on survivorship rules. The data integration would have the required information about the data and the various sources of the data to provide the matching and merging rules for data cleansing. Some of these are built-in rules for the ODI tool, and having these default (or built-in) rules means that they can be leveraged for higher data quality, help build the standards, and enrich the ETL load with this automated data cleansing as part of the overall process.
When you’re creating data integrations using the ODI tool, the data cleansing can be part of the integration. This simplifies the workflow and provides ways to correct referential issues with data, rules for uniqueness, and matching. Check Knowledge Modules (CKMs) can be used to declare constraints and rules on the ODI models and provide for the checking, reporting, and handling of issues. The standardization can become part of the workflow for the data integration and can automatically cleanse the data. Using matching rule sets and merging capabilities and rule templates help address various issues with the data as part of the integration in ODI.
Having these sets of tools as part of the integration is important, but there are additional tools that can help with the data quality process and ensure improvements in this area. They can even provide standard sets of data such as addresses to ensure correctness based on city, state, and ZIP code information. These standard sets of data are provided as part of the Oracle Enterprise Data Quality tool. Just like the tools that are part of the ODI, this tool can look at data cleansing at the enterprise level and can be used as part of the overall MDM strategy. The Oracle Enterprise Data Quality tool does the analysis to profile the data to understand the information that is being assessed. The parsing and standardizing rules can be deployed to ensure that the data is correct and matches. Records can be identified as being incomplete or not having correct values; they can then be matched with appropriate values or merged to provide a complete set of data for the record. Here is where the standard and data templates can be used to validate the data in the tool. Figure 7-5 shows the Oracle Enterprise Data Quality cleansing process and how the data can be profiled.
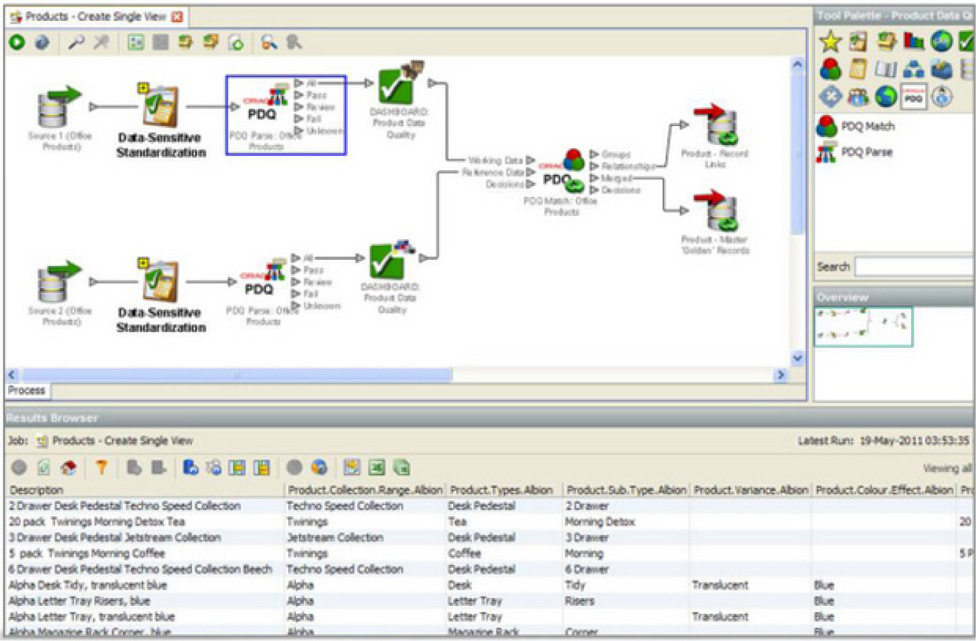
FIGURE 7-5. Oracle Enterprise Data Quality: the cleansing process
Combining the tools to be used together can be an important part of the workflow and can help reduce manual steps in the rules and data cleansing process, which can be automatically performed for better data quality and data integrations. Oracle Enterprise Data Quality can work with Oracle Master Data Management and Oracle Data Integrator to provide an overall tool to drive better data quality. The MDM strategy can then use the standardized information and relevant data quality rules to be referenced by Oracle Enterprise Data Quality products for transformation and data validations.
ODI has rules that can be created as part of the integration and data movement, and Oracle Enterprise Data Quality provides additional matching and merging options with standardized data and can be used with the ETL. Not only can this plug into ODI, but it can be plugged into other ETL systems to enforce rules, perform data cleansing, and correct data issues based on the rule set and business requirements for the data.
Tools are valuable for implementing the data quality workflows and providing automated ways to perform the data cleansing. The important factor in using these tools is to make sure they fit within a process that guarantees a successful data quality plan and that they are part of the continuous process of assessing the data, evolving the business rules, cleansing the data, and monitoring the data to improve the data and business rules around it.
Developing Other Tools
Because data profiling and cleansing are interactive and iterative processes, additional tools might be beneficial to include different mappings and frequencies. These tools might not be able to be automated, and they might require manual checks and entry to include some additional statistics and analysis of the data. Tools such as Excel might have limitations in sharing and being able to audit and provide activity on changes.
Oracle Application Express (APEX) provides a quick and easy way to create forms and update data. APEX is an application framework that allows for rapid development of applications based on database tables. It can create forms and reports from spreadsheets and existing tables in the database. APEX provides a straightforward way to develop forms that can be used in a quick data cleansing application, or it can be used to develop more complex database applications. Several books have been written on APEX, and tutorials can be found in the Oracle Technology Network, but APEX is simple enough to use to be able to create basic forms in a few minutes for data cleansing issues. APEX is available as a free tool to be used for database development with the Oracle database, and you can quickly install it and then use it for creating reports and forms. The advantage of using a framework such as APEX is that it allows for quick development and a way for multiple users to contribute.
The data is probably in a database to begin with, so the next step would be to provide ways to update and change the data as well as to document what has happened and when. APEX can provide some additional reporting on the issues fixed or any issues with the data based on certain conditions. Because the APEX applications leverage the database, the same triggers and constraints are available. You can keep constraints on the data being cleansed and the details around the metadata as well as what data was changed and why.
With the data kept in the database, now the additional steps can be taken to update other systems with the cleansed data or to merge the data with the planned integrations.
The tables can be created from a source of data, even if it is a spreadsheet or some other external form. This might even become part of the load process to make sure the data is current and up to date. The data might even be loaded through external tables or existing database tables, ready to be validated.
After the tables and data are available, the forms and reports can be created on the database in APEX. The following figures walk you through the steps for creating reports and forms in the APEX application.
Figure 7-6 shows the SQL Workshop of APEX, where you can run commands and create any tables needed for editing. In creating a table, you can use additional columns to edit the details and add the information about the columns. The columns can be edited by modifying the object in SQL Workshop or through SQL commands.
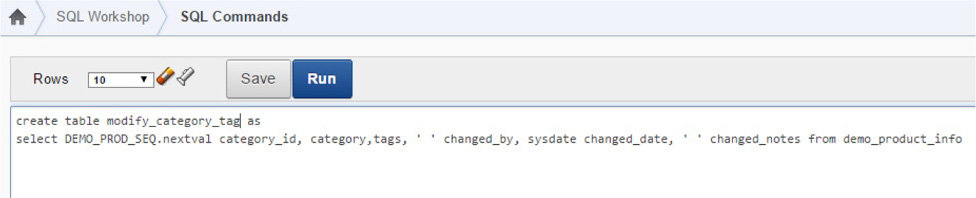
FIGURE 7-6. Creating a table
With the table in place, you can create a report and form, as shown in Figure 7-7. This is a new page, and after you select Tabular Form, a set of screens will launch where you can choose which columns to include in the form and specify what can be edited.
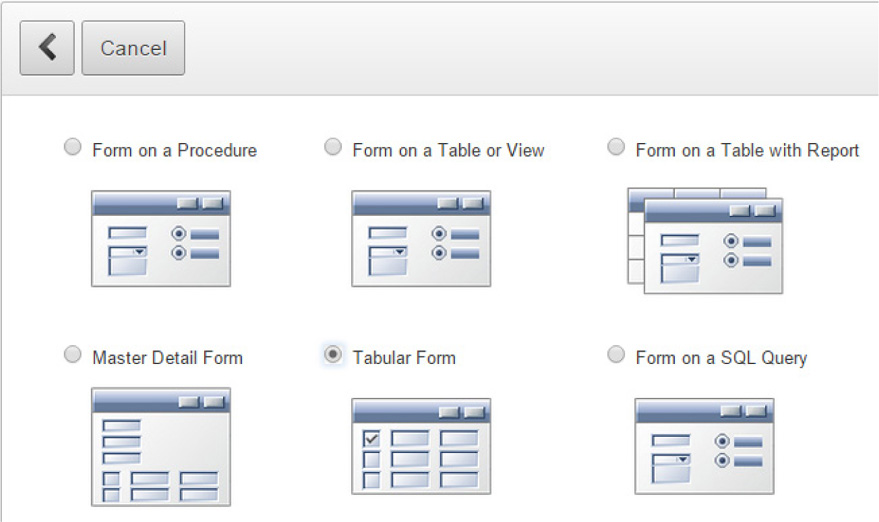
FIGURE 7-7. Creating a new page for the form
Figure 7-8 shows the table, the allowed operations (in this case, just updates), and the columns to be included in the form. As you can see, the APEX framework allows for quick development of the form. After the form is created, you can take steps to refine the form, set it up for easier use, and supply consistencies in editing the data.
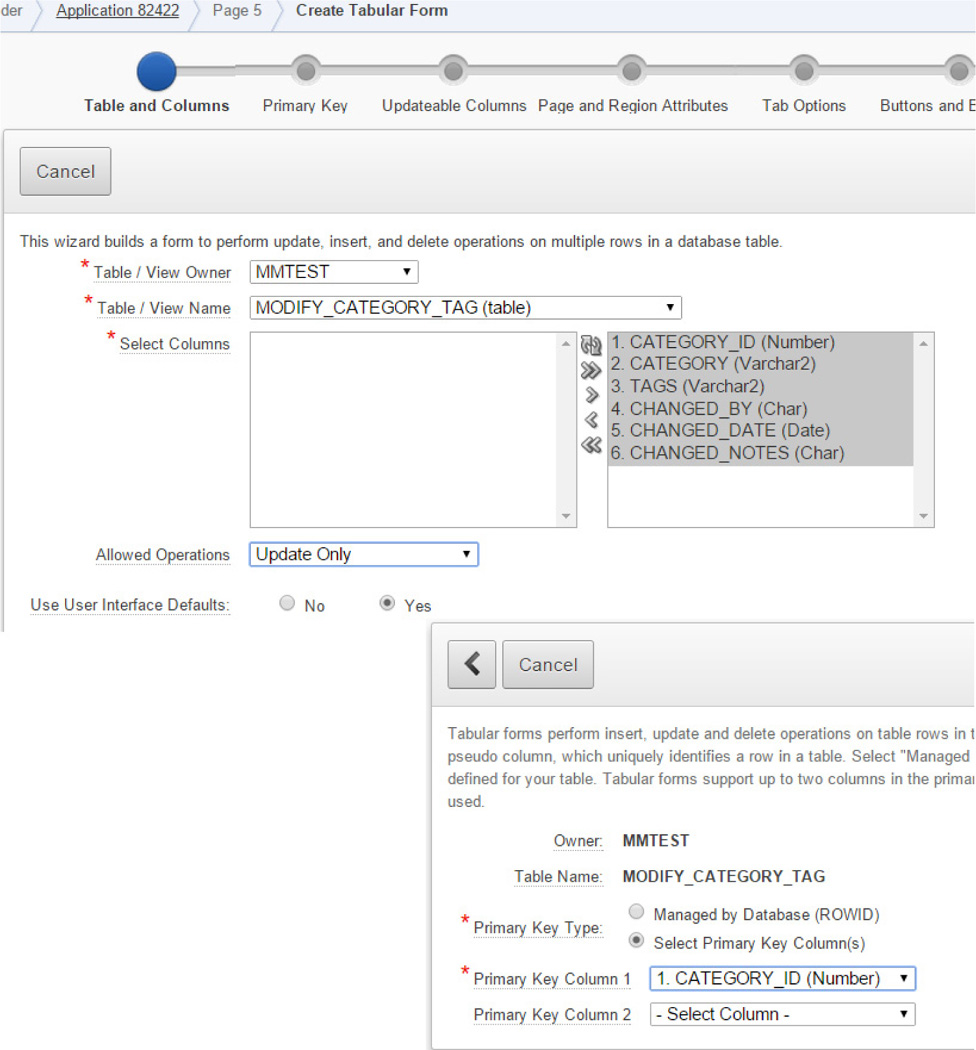
FIGURE 7-8. Creating the form
The form should pull in the columns needed, from the base value to the new value desired. The data doesn’t have to be changed right away; the details are captured in a table so they can be engineered to create a script to update the data at another time, if so desired. The changes are captured, and additional information can be provided about why the data should be what it is and how to change it.
Figure 7-9 shows the form and the columns that can be modified based on the user who is connected to the database. With this information in the database, updates are nice and clean and can be run through at the time the form is updated or later. Activity reporting is also available in APEX. This provides a simple way to have multiple users make data changes, justify why they wanted these changes, and track the edits, which can be run either immediately or later after all the information as been gathered.
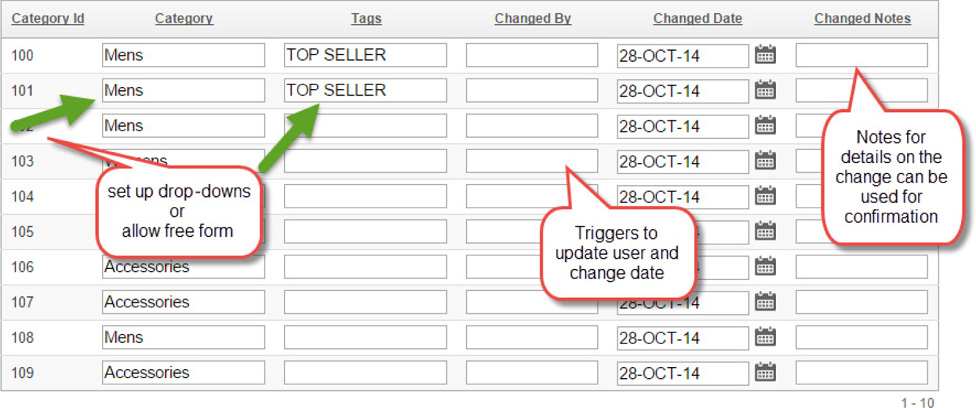
FIGURE 7-9. APEX form
This process doesn’t only happen with data, but also for the metadata issues. If there are disagreements between the business units, they need to work through those issues and make sure there is a place to capture the opinions and facts about why, for example, a column name should be changed. In a previous section we had discussed column names and how the business units might disagree about their naming standard. A form on the column names can help verify and modify the column names and again capture information on why a source and standard should be used. It is important to have a tool to capture that change and report back on the activity. The tool should also capture a few other columns that are needed, as shown in Figure 7-10. The capture of the additional information will also help accountability in maintaining the column and the data-specific reasons for those who logged into the application. The data stewards and owners would be able to pull in everyone’s feedback to review and thus have more thorough discussions instead of spending too much time in this area of cleanup that should happen on the database server.
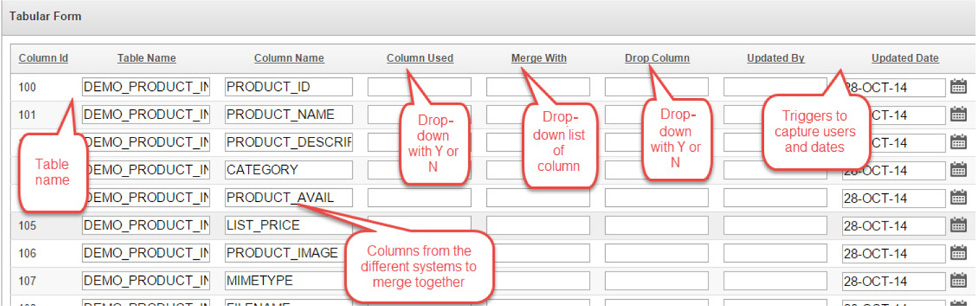
FIGURE 7-10. Metadata changes in APEX
APEX applications definitely require additional information to implement completely but the setup process is simple. The application can discover and display the data and database information, and be installed on a database server. Using tables for the underlying data in a database proves to be very useful in sharing and integrating the data changes. The use of APEX over Excel makes it simpler for multiple users to log their activity and collaborate on the different data sets and metadata around the data cleansing process and thus provide higher data quality.
If we look at the data quality framework and dimensions, we see that even tools like APEX can provide a simplified solution for most areas, including aligning the business, identifying anomalies, evolving business rules, as well as correcting, preventing, monitoring and reviewing all the information to ensure a continuous process.
Summary
Data quality is a driving factor for data cleansing. Even though data integrations might be the reason we are looking at data cleanup efforts, the overall data quality improvement effort is going to make the process for integrating data more efficient and produce consistent data to meet the business information needs. It will also raise the acceptance level and therefore the adoption rate for the data warehouse in the enterprise, which in turn helps ensure future funding and use.
To really dive into a data cleansing effort, the data sources need to be understood and agreed upon as part of the process. The context of the data is important for finding out the areas that might have strong or weak sources of information. Gathering the information from the data model, data dictionary, and governance documents provides the basis for the meaning of the data and a first look into the quality. From the context of the data, assessing the data would be the next step. Validation of the values and measurements for the data attributes, relationships, and dependencies play into what business rules need to be set up in order to perform the data cleansing. Business rules are always evolving and they change with the information that comes through the system. New sources or new needs require that rules change or additional rules be developed. Data sources are created based on the rules that are available, then the process of cleaning the data can occur. Data cleansing should occur on current data to correct the current issues and fix any data errors, but time should be taken to identify the root cause of any data issues to improve the data quality. Proactively eliminating any data issues to prevent future data errors will minimize the need for big data cleanup efforts and will provide a more seamless approach to data integrations.
Data quality is an ongoing and iterative process. Data will always need to be monitored and updated as a part of a data quality and cleansing effort. As an organization grows and data evolves, the need to review the processes becomes even more important.
Implementing a strong data cleansing process enables the business to efficiently minimize ongoing data quality issues and quickly correct existing errors in data sources. These data sources will then support productive data integrations and migrations of data to meet business needs and provide the business with data that is of value.
Having data owners, stewards, and stakeholders involved in the data quality and cleansing process is important for the sake of consistency. The consent and collaboration of all data stakeholders will allow for higher data quality, guarantee that the appropriate data cleansing steps are in place to handle the data fixes at the right sources, and ensure the correctness of the data for enterprise use.
