
CHAPTER 6: HACKING WINDOWS® AND UNIX
Having fun
Ethical hacking is exploring, learning and discovery. It is the art of questioning, experimenting and persistence. An ethical hacker loves to learn; they are not interested in doing damage or harming another organization or individual, but rather looking for what new things may be found around the corner, under the rock, or beside the pathway. The opposite are criminals or crackers, people that are seeking their own profit, satisfying their ego or exacting revenge. It is important to remember that we should never do anything just to do damage or harm another person or organization. It is good to learn and experiment, but it must be with the mind to improve systems, networks, performance, functionality and usability. Many of the tools we use are free and were created as open source products by people from all over the world. These people work together to push each other to develop better and better products, and yet never withhold the benefits of their discoveries from others or try to make a profit from their work. Over the next few pages, we will examine many of the tools and features discovered by hackers, but we must remember to always use these with care and only within authorized boundaries. Since we are working to prevent an attacker from gaining entry to our systems, we must be aware of the methods and objectives of an attacker that is trying to compromise our systems, networks and applications.
Common hacking initiatives
Keystroke loggers
Keystroke loggers do exactly what their name says: they capture keystrokes. A keystroke logger will record everything a person types – including user IDs, passwords, banking data and e-mails – and provide it to the person that installed the keystroke logger.
Keystroke loggers can be either hardware or software. Many hardware-based devices will plug into a serial or USB port, or be placed in the middle of the connection between the keyboard and the desktop. They will gather and store information until retrieved and read by the person that placed them. These can be very difficult to detect, since not many people are inclined to crawl under their desks to check their keyboard cables or what is plugged into the USB ports on the back of their machines on a daily basis. Software-based keystroke loggers can be even more difficult to detect without using some form of detection software that would notice the presence of the logging application. Since software-based units can be installed and monitored remotely, they are a favorite of many criminal groups attempting to commit identity theft or fraud. As seen in the earlier discussion on spyware, some companies will use keystroke loggers to monitor user behaviors.
Password cracking
The next typical target for a malicious attacker is user accounts with passwords. Perhaps the attacker has already managed to gather the user accounts during the earlier footprinting and enumeration phase, and now all the attacker needs to do is determine the passwords used for those user IDs. In some cases, the attacker may also have downloaded a copy of the password file with the hashed password values for each user password. In the end, the challenge for the attacker is to gain access – and using a legitimate user account is often the easiest way to gain that access.
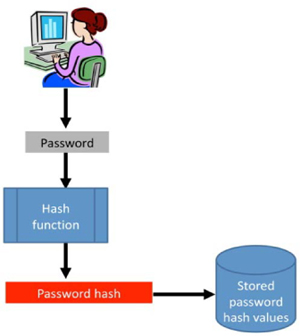
When a user logs into a Windows® system, the user password is hashed and stored as a hash value in a password file (a SAM or AD file). A hash is a value that is computed from the password that was entered by the user using a hashing algorithm (such as MD4). The hashing function is a one-way function – the hash is generated from the password, but the hash itself cannot be reverse-engineered back to learn what the original input password was. The challenge for the attacker is to learn what password value to enter that would produce the same hash value that is stored in the password file.
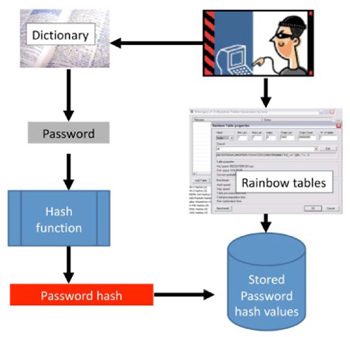
Dictionary and rainbow table attacks
The attacker may use several methods and several different tools to attack user accounts. Beyond just capturing passwords through keystroke loggers or intercepting them when sniffing (eavesdropping) on a network, the attacker may simply try all possible password values. This is called a brute-force attack, and it is the reason that most password entry systems will only allow a few possible entries before locking out the account. Another type of attack is to select a list of common words that people may have chosen as their password and try to access a user account using those as the password entries. This is called a dictionary attack. Some of the common dictionary attack tools will use common words from several languages and substitute letters for other symbols (A for @, e for 3, h for 4, 0 for O, etc.) When a user selects a simple password, password-cracking tools can break that password quite easily.
Another type of attack is based on pre-computed password hashes. These tables, called “rainbow tables” consist of entire lists of password hashes and the input values that would generate those hash values. Once the attacker has a copy of the password file, they can simply compare the stored hash values with the hash values in the rainbow table. A match on the hash would tell the attacker which input would generate that same hash. This type of attack is more difficult if the system uses a salt value (an extra input that is added to the password before hashing) together with the input password when generating the password hash.
Defeating data theft
One of the most serious attacks an organization can suffer is the theft of sensitive data – such as credit card values, personally identifiable information (PII) or trade secrets. Theft of portable media is one of the most common ways an organization can lose sensitive data. The impact of a stolen laptop, for example, is equal to much more than just the cost of the laptop itself – it is the value of the data that was on the laptop that matters most. Loss of sensitive data may pose a large liability through financial penalties or damage to the reputation of the organization. One report by the security company Kensington documented that nearly half of all attacks against an organization originate from a laptop stolen from that organization.
A necessary security measure is to encrypt the data stored on the hard drive of the laptop or on any other portable storage media, including USB flashdrives.
Full disk encryption will automatically encrypt all the data stored on the hard drive. This makes it computationally infeasible for a person that gains access to a lost or stolen drive from being able to recover the data that is on the drive.
The deployment of hard drive encryption must ensure that the system will only boot up to a pre-boot security screen. If the system boots up to a normal screen, then it is possible for the attacker to steal the encryption key from RAM.
Protecting against unauthorized access
The most effective protection for a system is to ensure that only authorized personnel are able to gain access to the system and that, once on the system, the user is only granted the correct level of access needed for them to perform their job duties. This is the practice of the principles of “least privilege” and “need to know.”
The principle of access control is based on the Identification, Authentication, Authorization, Accounting (IAAA) model.
Identification
Being able to identify a user or process that is requesting access to the system is integral to the protection of the system from unauthorized use. The challenge is in correctly identifying a user that is logging in, which is especially difficult when the user is logging in remotely over an untrusted network. The first principle must be to ensure that every user is uniquely identified – there must be no shared user IDs – and to ensure that a user ID is only provided to a user through a defined and well-managed process. Various studies have alleged that over half of the user IDs on corporate systems are set up incorrectly or are for personnel that no longer need them. Just like an open port on a firewall, every user ID that is left open is a potential point of attack.
Authentication
To authenticate is to validate or verify that the person presenting the user ID is who they say they are. The purpose of authentication is to prevent one person from using another person’s user ID. There are three primary methods of authentication: asking what you know (knowledge), what you have (ownership), and what you are (biometrics). We also see node authentication where access is limited to a predefined MAC address, IP address or CPU serial number.
We are most familiar with knowledge-based authentication through the use of passwords, passphrases, or an answer to a “secret” question (often based on personal history or preferences).
Ownership-based authentication requires possession of a device – a token, smartcard or radio frequency identifier (RFID) chip. Most ownership-based approaches are either synchronous or asynchronous. Synchronous-based systems are based on time or events. The user requesting access must be able to respond to the authentication server with a value generated by their token. The value on the token will change every minute or two, or else will generate a new value every time the token is queried. The authentication server knows the value that should be displayed on the token at any point in time. Other ownership-based systems may require a USB token or serial port device to be plugged into the system, or an access card to be inserted into a reader, before granting access to a user.
Authenticating via characteristics is based on biometrics. Biometric devices are based on the characteristics of a person – their fingerprint, or retina or iris scan – or on behaviors, such as signature or voiceprints, or keystroke dynamics. The management and costs associated with biometric devices, as well as the reluctance of some users to be subject to biometric authentication, means that care must be taken when choosing to deploy a biometric-based system.
Multi-factor authentication
No single type of authentication is good enough to provide adequate security today. As seen earlier, it can be simple to break passwords, and users are often negligent in protecting passwords or tokens. The solution to this is to use more than one authentication type when granting access. The use of a password (or pin) and a token, or a token and a biometric makes it much more difficult for the attacker to break in. It is important to note that using two of the same type of mechanism (i.e. a token and a smartcard) is considered only single-factor authentication by the payment card industry (PCI).
Authorization
Authorization refers to the rights or permissions a user has on the system once they have been authenticated as a rightful user. Authorization should be set to only allow the minimum level of permission required by the user. A user that only needs read access, should not be granted write access, for example; and a user that is not required to delete files should not be granted that level of privilege.
Accounting
Accounting – sometimes called auditing – is the tracking and logging of the activity on the system. Every activity should be tracked to the user ID of the process that initiated the activity. This will allow an administrator to trace any activity on the system and associate that activity with the correct user. It is important that an attacker or user cannot alter or delete the logs to hide their mistakes or malicious activity.
Access controls
The most central or core concept of security is that security is centered on the principles of access control. Protecting a system, data or an organization is simply controlling who can do what, when and where they can do it, and what they can access. Access controls are made up of technical, physical and administrative (or managerial) controls.
As seen above, access starts with knowing who or what is trying to get onto the system. We can say that the entity that is trying to get access is the “subject.” The subject is active and initiates an access request.
The entity or resource that the subject is attempting to access can be called the “object.” An object provides a service and is passive in that it waits for a request to come from a subject before responding.
The secret is to put in place the rules that will govern how a subject can access an object. Often, the level of access provided will depend on the location of the subject, the group the subject belongs to, the roles or responsibilities of the subject, and the time of day (temporal controls).
Actions of the attacker
Once the attacker has gained access, they will often do several actions to hide their tracks and provide an easy method to break in in the future.
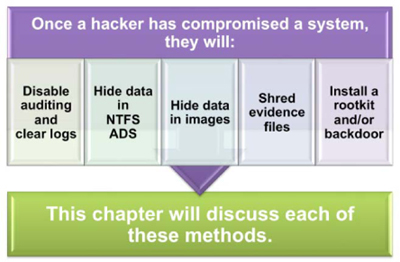
Figure 21: Hiding their tracks
The attacker does not want to be noticed – that would result in the system being repaired, denying them future access. The attacker, therefore, will attempt to hide their tracks and provide themselves an easy way in for the future through a rootkit (see page 101) or backdoor.
Sweeping away the footprints / clearing the logs
The attacker will often take steps to ensure that there is no evidence of their presence left behind. The logs and other records of their presence may be seen by an administrator and alert the organization to the attack. The attacker may attempt to hide their activity by temporarily disabling the logging features on the system, or erasing any evidence that was written to the logs.
To prevent this, the administrator may set the log files to be written to a write-once / read-many device, so that it is not possible for logs entries to be erased.
An attacker will also want to ensure that no evidence of the attack that would be discoverable in a forensics investigation is left on their host machine either To do this, they will shred any files or data that has been saved on their machine, including data or files stored in cache or temporary files.
In launching the attack, an attacker can hide their location through the use of products, such as Tor,® which will route their communications traffic through numerous hosts and make it very difficult for anyone to trace back the true source of the communications. Attackers will also use encrypted sessions to communicate with a target machine, since the encryption will render any firewalls, intrusion detection systems (IDSs) and intrusion prevention systems (IPSs) ineffective.
Hiding data
Attackers also take advantage of many of the tools and features built into operating systems for the benefit of administrators and maintenance. The use of these tools and features for malicious purposes is what we can call a “misuse case.” A misuse case is where a tool or function that was intended for a beneficial purpose is misused for a negative reason. For example, the ping protocol is valuable to the administrator, but has been misused by attackers to conduct network mapping or to launch a denial-of-service attack by misconfiguring the ping protocol to create the “ping of death” attack.
Other features that are frequently misused by attackers are the alternate data fields associated with other documents – such as the alternate data stream in NTFS® files – in which attackers are able to hide information. It is possible to hide executable programs and other malicious data in a file (such as a document file or text file), so that it is not detectable using normal Windows® tools, such as Internet Explorer.® Malicious individuals will often use this technique to send, from one location to another, data that would only look like a normal file to a person reviewing it. This method is closely related to another activity called “steganography” – a common action used to hide information, rootkits or other malicious activity in music, jpeg or other bitmap files. The user of the steganography tool (of which there are several available as freeware on the Internet) “steals” the least significant bit (LSB) of the bytes in the file and uses those bits to carry their message. It is quite difficult to detect any files that have been used for steganographic communication.
Rootkits
A rootkit provides high-level access to a system (at root level) and would enable the controller of the rootkit to perform nearly any desired function on the target system. An attacker will often attempt to plant a rootkit onto a target system, since that will allow them unregulated access to that system at any time in the future. Once into the compromised system, they virtually “own” the systems and can do whatever actions they desire and remain undetected. Most rootkits are difficult to detect and require a complete rebuild of the system to be eradicated. There are several versions of rootkits that will provide this backdoor into a system.
Focus on UNIX/Linux
No system is impermeable or completely resistant to an attack. Every system has flaws and vulnerabilities that can be exploited by a malicious individual, and UNIX is no exception. (Neither is MAC, but that is a discussion for another time).
The attacks against *NIX systems are similar to those against Windows® systems: password cracking, escalation of privileges and theft of data. Whether the risk is of passwords being cracked in a brute-force attack, or system vulnerabilities being compromised through services that are available on the system, the most effective countermeasures are training, enforcing strong password rules, hardening the system and making sure that all patches have been deployed.
Common flaws in UNIX systems include exploits of file shares, kernel-based programming flaws, and shared libraries. The attacker is able to target any one of these weaknesses as they plan an attack.
Advanced attacks
The key goal of an attacker is to gain control over a system. This is usually accomplished by getting admin- or root-level access to the system and then installing backdoors that will allow the attacker unrestricted access to the system in the future. Many attacks are not simply conducted by brute-force attacks or “hammering away” at the system until something breaks. Instead, the attacks are often the result of a chain of exploits – each exploit opening the door for another potential avenue of attack. We see that many of the successful attacks against major corporations are accomplished through a series of concerted attacks that continue probing until the attacker finally overcomes all the defenses and is granted access to the key assets of the organization. We see that many attacks are focused not on the theft of credit card or other sensitive, personally identifiable information, or just embarrassing the target, but rather concentrate on the theft of corporate data, espionage and compromising trade secrets.
As both the skill level of the attacker and the value of the intellectual property of organizations increase, it becomes more and more important to increase our diligence and watchfulness to ensure that our organizations do not become victims or casualties along the edge of the information highway.
Invalid input
In far too many cases, it is rather simple to attack an application or system, or run a successful pen test. Many applications, operating systems, utilities and communications protocols are easily compromised through improperly input data. We have all heard the expression “garbage in – garbage out” used to describe the data contamination and errors caused by invalid input data, but this is only a small part of the problem. Not putting adequate controls in place to detect and prevent invalid input from users can lead to business interruption, errors and inconvenience. Yet, the danger that such a lack of control presents to business operations is much less significant than the advantage it presents to the attacker. By manipulating data entry, the attacker may be able to gain high-level access to the system or data, posing a risk far beyond that of simple data contamination or business inconvenience.
Database basics
A database acts as a large filing cabinet, but one with many added benefits. If a user wants to retrieve information from a filing cabinet, they must have physical access to it – which often means that several people located in different geographic locations will have their own files. This leads to duplications of information, but also, more seriously, inconsistencies in the data. One data source may be updated, but others will still be left with older versions.
Using a database to store all the data related to a project, customer, or other entity can provide global access and ensure that everyone is working from the same data source. The mechanism that maintains and handles the database is the database management system (DBMS). The DBMS is like a filing clerk that maintains all the data on behalf of the other users. The DBMS is excellent at keeping the data organized and searching and retrieving data when required.
The structure of the database is known as the schema. It describes how the data is defined and organized in terms of field sizes, allowable data values, etc.
In a relational database model, the data is stored in relations or tables. The data is grouped using a process called normalization. This ensures that a table only contains data that is properly related.
In most cases, a user cannot access the database directly, so they must use an application instead. This limits what the user can do, but, if it is not properly secured, the application can still be a vector for an attacker to gain access to the database.
The pen tester should know the basics of databases in order to test the security of the database architecture and ensure that no one can make improper changes to the data.
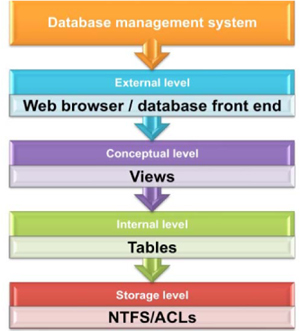
Figure 23: Database architecture
One of the challenges with web-based applications that interface with databases is that much of the processing is performed on the browser of the web client. Any data that is provided by a client can be modified by the client, so adequate controls have to be in place to prevent improper data entry or alteration.
The data in the database is arranged in rows or records and each record may contain many fields of data. Each row of a database may contain a large amount of data (for a customer, for example) and not every user needs to be able to see all of the data in the whole database. For this reason, the application will usually refer to the database using a view. The view is really a filter that restricts the information provided to the user, so that the user cannot even see the data fields where they do not have a “need to know.”
Injection and manipulation
Structured Query Language (SQL) is a common language used to access information from a database. Many attackers target databases using SQL commands in order to provide themselves with access to unauthorized information. A recent audit performed for a major airport found that the airport’s core systems were subject to more than 1000 SQL injection flaws (despite the assurances from the initial application developers that the applications were not vulnerable to SQL injection). The use of SQL injection to expose database contents and compromise a system has been a tool in the attackers’ arsenal for over a decade, and yet there are still many applications in use – and even being built today – that are susceptible to SQL injection-based attacks. A pen tester should always test applications for this vulnerability. Many applications will accept user input – log-in information, for example – and insert that input into a pre-existing SQL statement in the code. The SQL statement is then executed and performs the function intended by the application developer (in this case, allowing the user to log in if they have input the correct log-in information). By inserting invalid data into the user input field, the attacker or pen tester can test whether the application was written to validate the user input prior to executing the SQL statement. If the input is not validated, and the SQL statement is executed, then whatever data the attacker put in that field will be executed. This may present the attacker with the entire contents of the database or access to other information or areas that were never intended by the application developer.

By inserting unauthorized data into the name and password fields, the attacker is able to access the database.
Other injection attacks are made possible by inserting stored procedure or shutdown commands into the SQL statement.
Protecting databases
Protecting a database starts with the same types of protection normally used for other systems and equipment: changing default settings, enforcing strong password rules and disabling unneeded services. This protection should be augmented by setting up a tiered architecture – so that users have to access the data through an application and cannot access a database directly – validating all input to the database, and using parameterized queries that restrict the values that a user can enter into a SQL statement.
A good resource to help protect databases and web applications is the Open Web Application Security Project or OWASP (www.owasp.org).
Format string
The application developer is naturally focused on delivering the required business functionality, and is often unaware of the risks associated with misuse cases (where an attacker could misuse that functionality for their own purposes). The aim of the pen tester is to find any security flaws in the target system that could be exploited by an attacker. To do this, the pen tester will test for misuse cases and not just test the proper function of the system. The pen tester does this by testing applications and any user input fields with strange data – data that would not normally have been input by a proper user – to see if the application has been written to detect and reject such invalid input correctly.
Some programming languages are more vulnerable to invalid input than others, especially those that will do formatting of data automatically. The C programming language is a good example of this. Several functions, such as “printf”, will execute without validating input and may, therefore, be manipulated by an attacker to overwrite other memory areas or corrupt system operations.
Buffer overflows
Buffer overflow attacks have been one of the most common problems found in systems programming over the years. A buffer overflow condition is caused when the data being written into memory exceeds the space allotted to it. This could happen if, for example, an input field that has been set to eight characters in length is filled in with data exceeding eight characters in length by an attacker. If the program does not check the size and content of the data being provided, it may write the input data into memory – putting the first eight characters into the properly allocated memory space, but then continuing to write into the next memory areas and overwriting whatever content was originally there. This becomes especially dangerous when the content being supplied by the attacker overwrites memory pointers or contains executable code.
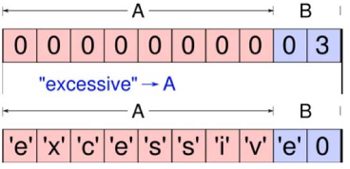
In this example, we can see that the memory allocated to the field “A” was set to eight characters, but the input provided to the system (the word “excessive”) is nine characters in length. This caused field “B” to be changed from its correct value of “03” to a new value of “e0.” The program is most likely to fail or process incorrectly, since it may not know how to process an alphabetic value in a numeric field.
Verifying that an application or system will not accept invalid inputs is one of the most important parts of a pen test. The tester must try all types of valid and invalid input to ensure that an attacker cannot cause the system to fail or be compromised through manipulation of input data. The test should try various input styles as well. For example, data could be input in Unicode (instead of in ASCII characters), the same values could be input in different ways (canonicalization), or alternate character sets of languages could be used.
Fuzzing
When testing an application, the pen tester will frequently use techniques, such as “fuzzing,” to test the ranges accepted and the application’s ability to handle unexpected input values. Fuzzing is the use of inexact data, incomplete data, and data that is outside of expected ranges to test whether an application can resist and handle invalid input.
Memory management
As seen in the discussion on buffer overflows, exploiting memory management is one of the most popular angles of attack that can be used against many operating systems. Memory is allocated in two forms: heap and stack. As data is moved into memory, it requires pointers and links to other memory areas. If an attacker can manipulate their input data to overwrite those pointers or links, they may cause their input data to execute as if it was a part of the original program commands located in those memory spaces.
Error handling
A common approach for attackers is to intentionally cause an error or exception to a process. It is common to find that the error handling process used by the developer will provide information that may enable an attacker to adjust or tune their attack to be more effective. This error handling approach is usually chosen by the application developer in order to allow them to identify the cause of an error and facilitate the correction of the problem. However, the attacker benefits from the information provided, as well. For this reason, any error handling code should be masked by using error codes or by just providing generic information.
Source code review
A pen test may include a review of the source code for the applications used by the organization. This type of review requires both a specialized skill set that many pen testers may not have and access to the source code itself – not always possible with vendor-supplied programs or to external pen testing teams.
A source code review looks at the actual program code itself to identify flaws in the program logic or bugs in the code itself.
Ideally, the first review of the source code will have been conducted during the design and development phases of the Systems (or Software) Development Life Cycle (SDLC®). As applications mature, changes are made to applications or system configurations, the threat environment evolves, and the operational world and user environment adjusts, it is important to review the programs to ensure that they remain secure, that the controls are operating correctly, and that the system continues to be resistant to attack.
A source code review examines the code for improper error handling, buffer overflow conditions, logic flaws and efficiency. The reviewer should approach the source code review from both a use-case (testing what the program was intended to do) and a misuse-case perspective (assessing the attack surface area, the possible points of attack or misuse, etc.). The review should especially focus on program areas that handle sensitive data and ensure that security controls – such as encryption, authentication and logging – are working correctly.
All of the following should be considered in data validation:
• Weak validation is the reason most attacks are successful. Make sure the application is validating the data for:
• Type
• Format
• Length
• Range
• Valid business values.
• Data should be validated before constructing SQL statements.
• It should be validated that output does not contain scripting characters.
Log files
Logs are detective controls and, as such, cannot prevent an attack. But they can do two things:
1. Deter an attack if the attacker knows that their activity will be noticed
2. Aid in the investigation of a possible attack or mistake by a user.
It is not uncommon to find that log files are one of the most overlooked and ineffective security controls available to an organization. Frequently, organizations store copious amounts of data in log files and then never review it. Another mistake is to store the wrong data – most of which is of little use when an attack happens.
In a world of regulation and privacy legislation, it is the responsibility of the organization to prove that their controls over data confidentiality and integrity are adequate and meeting the requirements of the regulations16. The logs should provide a historical record of all activity on the system – especially when it concerns access or changes to sensitive data.
The following is a list of questions and issues to consider when conducting a log file review:
• Are all login attempts being logged? Both successful and unsuccessful attempts should be logged.
• Is logging centralized? Using a centralized approach encourages consistency and code re-use.
• What is being logged?
• Is sensitive information being logged and, if so, what protection measures are in place to prevent the log files from disclosure?
• Does the log file allow scripting tags to be written? Cross-site scripting should be avoided.
• Are the logs protected from being erased or overwritten?
• Are the log files large enough to prevent application failure in case they are subject to flooding?
Authentication
Protecting systems from errors, abuse, and compromise starts with ensuring that only the correct people are on the system, and that they can only perform authorized actions once they have been granted access. As seen earlier, this involves the following steps: entity identification (determining who or what is requesting access); authentication (validating or verifying that the entity is who they say they are); authorization (controlling what rights, privileges and permissions a user has once they are on the system); and accounting (logging and recording all activity on the system and associating that activity with the entity that performed it).
As was also seen earlier, there are three primary methods of authenticating an entity requesting access: by confirming something they know, something they have, or something they are. Unfortunately, all three of these methods are subject to compromise – they can be defeated or bypassed by an attacker that can steal a password or token, or copy a biometric value. Therefore, it is necessary to use a combination of authentication techniques in order to validate the identity of the entity. This is called multi-factor authentication. The pen tester should ensure that this is in place on the target system. Any system that is only using single-factor authentication is susceptible to unauthorized access.
Account lockout
If an entity requests access (attempts to log in) to a system, they must be able to provide the correct response to the authentication mechanism – a password, smartcard or biometric signature, for example. If they do not respond correctly, the system should deny entry. It will, however, usually provide the applicant with an error code and an opportunity to answer again. Users frequently mistype or forget passwords, or read a CAPTCHA value incorrectly; in other instances, the biometric device may fail to authenticate the applicant correctly (commonly known as a “type one” error, or a “false reject rate”). Once a person has tried, unsuccessfully, to log in multiple times, it may be evident that the entity requesting access is not the person they claim to be – that they are attempting to masquerade or spoof their identity and gain unauthorized access. After the entity has tried to log in multiple times, the system should lock out the account and prevent any further log-in attempts from that account until it can be verified that only the correct person is attempting to use it. The question, however, is: what is an acceptable human error rate, and how would it compare with that of a brute-force attack? Should the system lock the account after one invalid password entry, or let the person attempt three, four or five times? The level or threshold at which action is taken to lock the account is called the “clipping level.” An error rate below the threshold is discarded or clipped off, but once the threshold has been crossed, action is taken.
Case study: Attack on a Chinese bank17
The entire text of this attack can be found at the link provided.
A classic attack on a bank’s authentication system was seen several years ago, when an attacker was able to execute a script against the bank’s online application that allowed the attacker to log in to other users’ accounts and transfer the money out of their accounts. The attacker knew that the clipping level for the bank’s online log-in would only permit a few log-in attempts to an account before locking out the account. However, the system did not detect or react to a user that would attempt to log in using a different account number each time. The attacker selected a common word that was likely to be used by several people as their log-in password, and then wrote a script to try that password against all the user accounts on the system. The attacker found that five people had used that password as their online banking password and transferred their money to other accounts he had set up. He then withdrew the money from ATMs and various branches of the bank.
Some of the reasons for this attack being successful were:
• Poor session management, which locked an account after five unsuccessful attacks, but allowed a person to attempt multiple access attempts, as long as different account numbers were used
• Client-side authentication only, which allowed the attacker to modify some of the security controls being passed from the client to the server
• Single-factor authentication, which did not require any further verification from the entity requesting access.
Configuration management
Configuration files should also be checked for sensitive information, such as default user or password settings, and session management and other hardcoded data.
There are several products available to the tester to facilitate a source code review, but these tools are not a substitute for manual verification. A tool is excellent for finding simple coding flaws – unexecuted code, poor validation, etc, but is not effective at finding complex logic flaws or some types of injection attacks. Therefore, it is always preferable to deploy a combination of tools and conduct a manual review to audit source code and application logic.
Key learning points
This chapter dealt with many of the steps undertaken by an attacker to defeat the security control over a system – and, therefore, the topics that a pen tester must be aware of and test for when conducting a thorough pen test.
Key points covered include:
• Hacking versus pen testing: objectives and methods
• Keystroke loggers: software and hardware
• Password cracking: rainbow tables and dictionary attacks
• Protecting personally identifiable information (PII)
• Identification, Authentication, Authorization, Accounting (IAAA)
• Erasing and clearing logs
• Use and misuse case models
• Hiding data: alternate data streams and steganography
• Invalid inputs: canonicalization, buffer overflows, injection
• Memory management: heap versus stack
• Error and exception handling: verbose error code
• Logging activity
• Configuration review.
Questions
1. A pen test is designed to:
a) Simulate the same type of activity as an attack
b) Identify and repair any problems within a target system / application
c) Ensure compliance with regulations or legislation
d) Publicly expose any flaws or errors in the system configuration.
Answer: A
B is incorrect – a pen test does not fix the problems, it detects and reports on them. C is incorrect – publicly exposing any flaws or errors in the system configuration is the job of the compliance audit. D is incorrect – a pen test is confidential and only reports to the client organization.
2. A password cracking tool that uses predetermined hash values is a:
a) Dictionary attack
b) Canonicalization attack
c) Hash injection attack
d) Rainbow table.
Answer: D
Answer A uses common words; B and C are made up.
3. Which of the following is an example of personally identifiable information (PII)?
a) Name
c) Health data
d) Education.
Answer: C
None of the other answers are considered to be PII.
4. Authorization should be based on:
a) Multi-factor validation of identity
b) Recording and tracking all activity on a system
c) The principles of “need to know” and “least privilege”
d) Ensuring that all users are uniquely registered on the system.
Answer: C
Answer A is authentication, answer B is accounting, and answer D is identification.
5. Error messages should always be:
a) Detailed enough to permit troubleshooting
b) Logged in a centrally managed database
c) Protected from being overwritten or erased
d) Generic, so as to not disclose data to an attacker.
Answer: D
Answer A is incorrect; a verbose error may provide an advantage to an attacker. Answer B is incorrect; errors need not be centrally recorded – activity logs may be centrally recorded. Answer C is incorrect; this relates to logs, not error messages.
6. Steganography is a method of:
a) Hiding data in music or picture files
b) Protecting sensitive data
c) Protecting the integrity of data through the creation of a computed hash value
d) Manipulating input data.
Answer: A
Answer B is incorrect – encryption is used to protect sensitive data. Answer C is incorrect – this is hashing. Answer D is incorrect – this is an injection attack.
7. A memory buffer overflow attack attempts to:
a) Put more data in an input field than the field was designed to contain
b) Prevent memory pointers from linking to the wrong programs
c) Put SQL data into an input data field
d) Flood a memory stack with SYN requests.
Answer: A
Answer B is incorrect – a buffer overflow may corrupt memory pointers. Answer C is incorrect – this is an SQL injection attack. Answer D is incorrect – a SYN flood attack floods a network, not a memory stack.
8. A source code review should be done following implementation because:
a) This is the most effective time to review source code
b) Changes to applications need to be reviewed to ensure the security configuration is still effective
c) Tools can only work on code once it is implemented
d) Errors in the business logic are easiest to detect once the system is operational.
Answer: B
The source code review should be done first – during design and development – but repeated once the system is implemented, in order to ensure that the security controls are still working correctly. The other answers are all correct when doing a source code review earlier in the SDLC process.
16 www.bcauditor.com/pubs/2010/report7/paris-system-community-care-services-access-and-security.
17 www.isaca.org/Journal/Past-Issues/2007/Volume-5/Pages/A-Hacker-Breaks-In-Lessons-Learned-From-a-True-Story1.aspx.