
10
MESSAGE DIGEST ALGORITHM 5
BAYZID ASHIK HOSSAIN
Contents
10.1 General Properties and Vulnerabilities
10.3.1 Add Padding Bits behind the Input Message
10.3.2 Add a 64-Bit Binary String That Is the Representation of the Message’s Length
10.3.3 Initialize Four 32-Bit Values
10.3.4 Compress Every 512-Bit Block
10.3.5 Generate the 128-Bit Output
Keywords
Authentication check
Hash function
Integrity check
Message digest
A message digest algorithm such as MD5 is also known as a hash function or a cryptographic hash function. It takes a message as input and generates a fixed-length output in response, which is generally less than the length of the input message. The output is known as a hash value or message digest. A message digest is also known as a compact digital signature for an arbitrarily long stream of binary data [1]. MD5 was first designed by Professor Ronald Rivest of MIT in 1991 to substitute former hash function MD4. When investigative work showed that MD5’s predecessor MD4 was likely to be in secure, MD5 was designed to be a secure replacement. MD5 has been consumed in a wide range of security applications. It is also frequently used to check data reliability.
10.1 General Properties and Vulnerabilities
When cryptographers tend to design a message digest algorithm, they try to make the algorithm fulfill the following properties:
• It should be one-way. It is hard to get the original message given the message digest.
• It would be hard to find another input message that produces identical output when both input and output are given.
• The algorithm should be collision resistant. It would be computationally not feasible to find two messages that generate equivalent message digests. This property is not similar to the second property. It is easier to attack on this property than on the second property.
• Pseudorandomness should be satisfied by the message digest.
When all of the above properties are fulfilled, we call the algorithm a collision-resistant message digest algorithm. It is unknown whether a collision-resistant message digest algorithm can exist at all.
In 1996, a weakness was found in the procedure of MD5. While it was not a clearly fatal weakness, cryptographers began recommending other algorithms, such as SHA-1, which has since been found to be vulnerable as well. In 2004, it was revealed that MD5 is also not collision resistant, and it is not suitable for applications that rely on properties similar to Secure Sockets Layer (SSL) certificates or digital signatures [3]. Moreover, flaws were discovered in MD5 during the same year, making further use of the algorithm for security purposes questionable; specifically, a number of researchers described how to create a pair of files that share the same MD5 checksum. Further progress was made in breaking MD5 throughout the years 2005, 2006, and 2007. During December 2008, a group of researchers used this technique to fake SSL certificate validity, and the CMU Software Engineering Institute currently says that MD5 “should be considered cryptographically broken and inappropriate for further use” [7], and most applications owned by the U.S. government now use the SHA-2 family of hash functions [8].
10.2 Design Principle
MD5 follows a design principle proposed by Merkle and Damgård. Its basic scheme is to build hash in a block-wise style. In a word, MD5 is composed of two phases: padding phase and compression phase. During the padding phase, some extra bits (1 to 512 bits) are appended to the input message. The result bits are compatible to 448 mod 512. After that the length of the initial message is transformed to a 64-bit binary string (if the length is greater than 264, the lower 64 bits are used) and these 64 bits are added to the tail of the message as well. So, the padding phase ends with a bit stream that may consist of one or more 512-bit blocks. During the compression phase, a compression function is used on each 512-bit block and generates a 128-bit output. The previous output is always involved in the calculation of the next round.
10.3 Algorithm Description
MD5 processes a variable-length message into a fixed 128-bit output. The input message is fragmented into chunks of 512-bit blocks (sixteen 32-bit words); the message is padded so that its length could be divisible by 512. The padding works by adding a single bit 1 to the end of the message first. This is followed by appending as many zeros (0’s) as are required to bring the length of the message up to 64 bits less than a multiple of 512 (448 mod 512). The remaining bits are filled up with 64 bits, which represents the length of the original message, modulo 264. The algorithm operates on a 128-bit state, separated into four 32-bit words, represented here as h0, h1, h2, and h3. These are set to positive fixed constants. After that the main algorithm uses each 512-bit message block in turn to alter the state. The processing of a message block consists of four analogous stages, which are termed as rounds, where each round is composed of 16 similar operations based on a nonlinear function F, modular addition, and left rotation. Hence, there are three kinds of operations in MD5:bit-wise Boolean operation, modular addition, and cyclic shift operation. All three operations are very fast on 32-bit machines, which make MD5 quite fast.
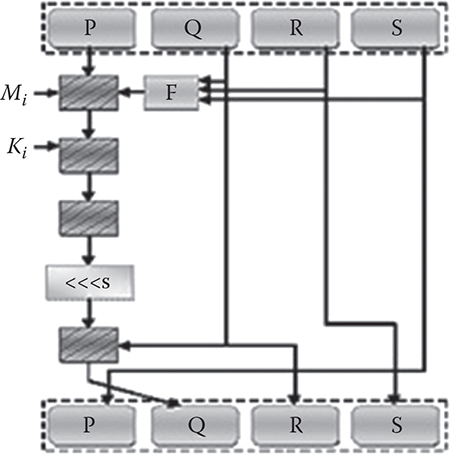
Figure 10.1 Operational model of MD5.
MD5 consists of 64 of these operations, stated in Figure 10.1, grouped in four rounds of 16 actions. F is a function that is nonlinear in nature; in each round one function is used. Mi denotes a 32-bit block of the message input, and Ki denotes a 32-bit constant.
The algorithm of MD5 can be described in five steps:
Add padding bits behind the input message.
Add a 64-bit binary string that is the representation of the message’s length.
Initialize four 32-bit values.
Compress every 512-bit block.
Generate the 128-bit output.
10.3.1 Add Padding Bits behind the Input Message
This step is to elongate the initial message and make its length congruent to 448 mod 512. First, a single bit 1 is appended to the message. Then, a series of 0 bits are appended so that length (the padded message) ≡ 448 mod 512. For example, suppose the initial message has 1000 bits. Then, this step will add 1 bit 1 and 471 bits 0. As another example, consider a message with just 448 bits. As the algorithm does not check whether the primary length is congruent to 448 mod 512, 1 bit 1 and 511 bits 0 will be appended to the message. As a result, the padding bits’ length is at least 1 and at most 512.
new_len = initial_len+1;
while((new_len% 64) ! = 56){
new_len++;
}
msg = new uint8_t[new_len+8];
10.3.2 Add a 64-Bit Binary String That Is the Representation of the Message’s Length
Consideration should be paid to the meaning of the 64-bit binary string. One should not regard it as the first 64 bits of the initial message. It is the binary representation of the length of the preliminary message. For example, assume the message length is 1000 bits. Its 64-bit binary representation would be 0x00000000000003E8. If the message is very lengthy, larger than 264, only the lower 64 bits of its binary representation are used.
msg[initial_len] = 0x80;//append the "1" bit; most
significant bit is "first"
for (offset = initial_len + 1; offset <new_len;
offset++)
msg[offset] = 0;
10.3.3 Initialize Four 32-Bit Values
These four 32-bit variables stated below would be used to compute the message digest. In the Implementation 1 section, these variables are mentioned as h0, h1, h2, and h3 and their initial values are
h0 = 0x67452301;
h1 = 0xefcdab89;
h2 = 0x98badcfe;
h3 = 0x10325476;
10.3.4 Compress Every 512-Bit Block
Four supplementary functions will be defined such that each function takes an input of three 32-bit words and produces a 32-bit word output [2].
F (X, Y, Z) = XY or not (X) Z
G (X, Y, Z) = XZ or Y not (Z)
H (X, Y, Z) = X xor Y xor Z
I (X, Y, Z) = Y xor (X or not (Z))
In each bit position, F acts as a condition such that if X, then Y; otherwise, Z. The function F might have been defined using addition instead of or since XY and not (X) Z will never have 1’s in the same bit position. The functions G, H, and I are similar to the function F, which performs in bit-wise parallel to produce its output from the bits of X, Y, and Z so that the corresponding bits of X, Y, and Z are independent and unbiased. Therefore, each bit of G (X, Y, Z), H (X, Y, Z), and I (X, Y, Z) will be independent and unbiased [2].
This step uses a 64-element table T [1, …, 64] constructed from the sine function. Let T[i] denote the ith element of the table, which is equal to the integer part of 4294967296 times abs (sin(i)), where i is in radians. After that, it performs four rounds of hashing for each 16-word block [2]:
for(j = 0;j<64;j++)
k[j] = fabs(sin(j+1)*pow(2,32));
For processing each 16-word block, do the following operation:
offset = 0;
do{
//break chunk into sixteen 32-bit words
w[j], 0 j 15
for (i = 0; i< 16; i++)
w[i] = to_int32(msg + offset + i*4);
a = h0;
b = h1;
c = h2;
d = h3;
for(i = 0; i<64; i++) {
if (i< 16) {
f = (b & c) | ((~b) & d);
g = i;
} else if (i< 32) {
f = (d & b) | ((~d) & c);
g = (5*i + 1)% 16;
} else if (i< 48) {
f = b ^ c ^ d;
g = (3*i + 5)% 16;
} else {
f = c ^ (b | (~d));
g = (7*i)% 16;
}
temp = d;
d = c;
c = b;
b = b + LEFTROTATE((a + f + k[i] +
w[g]), r[i]);
a = temp;
}
h0 + = a;
h1 + = b;
h2 + = c;
h3 + = d;
offset + = 64;
}while(offset<new_len);
10.3.5 Generate the 128-Bit Output
Finally, the message digest is produced by doing h0 append h1 appendh2 append h3.
to_bytes(h0, digest);
to_bytes(h1, digest + 4);
to_bytes(h2, digest + 8);
to_bytes(h3, digest + 12);
10.4 An Example
Input message: The quick brown fox jumps over the lazy dog.
Message before adding the padding bits:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 01101011 00100000
01100010 01110010 01101111 01110111 01101110
00100000 01100110 01101111 01111000 00100000
01101010 01110101 01101101 01110000 01110011
00100000 01101111 01110110 01100101 01110010
00100000 01110100 01101000 01100101 00100000
01101100 01100001 01111010 01111001 00100000
01100100 01101111 01100111
Message after adding the padding bits:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 01101011 00100000
01100010 01110010 01101111 01110111 01101110
00100000 01100110 01101111 01111000 00100000
01101010 01110101 01101101 01110000 01110011
00100000 01101111 01110110 01100101 01110010
00100000 01110100 01101000 01100101 00100000
01101100 01100001 01111010 01111001 00100000
01100100 01101111 01100111 10000000 00000000
00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000
00000000 01011000 00000001 00000000 00000000
00000000 00000000 00000000 00000000
MD5 operations (which contain 64 rounds):
Round [1]:
h0: 01110110 01010100 00110010 00010000
h1: 10000100 00010001 11010100 11010111
h2: 10001001 10101011 11001101 11101111
h3: 11111110 11011100 10111010 10011000
Round [2]:
h0: 11111110 11011100 10111010 10011000
h1: 01001001 10000100 11000111 11111100
h2: 10000100 00010001 11010100 11010111
h3: 10001001 10101011 11001101 11101111
Round [3]:
h0: 10001001 10101011 11001101 11101111
h1: 01011100 10010010 01001111 00110000
h2: 01001001 10000100 11000111 11111100
h3: 10000100 00010001 11010100 11010111
.
.
.
Round [63]:
h0: 00011111 00001101 00010100 00001000
h1: 01101101 11111011 01100010 10011100
h2: 11001100 01001111 11100111 11000101
h3: 10011101 11101101 00110111 00110110
Round [64]:
h0: 10011101 11101101 00110111 00110110
h1: 10101110 01111111 11101000 10010010
h2: 01101101 11111011 01100010 10011100
h3: 11001100 01001111 11100111 11000101
Final output: 9e107d9d372bb6826bd81d3542a419d6.
10.5 Implementation 1
#include<stdio.h>
#include<cstring>
#include<cmath>
#include<iostream>
#include<cstdlib>
#include<bitset>
#include <climits>
using namespace std;
#define KEY 64
#define SIZE 1000
#define LEFTROTATE(x, c) (((x) << (c)) |
((x) >> (32 - (c))))
class cryptography{
uint32_t k[KEY];
int j;
public:
voidto_bytes(uint32_t val, uint8_t *bytes);
uint32_t to_int32(const uint8_t *bytes);
void MD_5(const uint8_t *initial_msg,
size_tinitial_len, uint8_t *digest);
};
template<typename T>
voidshow_binrep(const T &a)
{
const char* beg = reinterpret_cast<const char*>(&a);
const char* end = beg + size of(a);
while(beg ! = end)
std::cout<<std::bitset<CHAR_BIT>(*beg++) << ' ';
std::cout<< ' ';
}
void cryptography::to_bytes(uint32_t val,
uint8_t *bytes)
{
bytes[0] = (uint8_t) val;
bytes[1] = (uint8_t) (val>> 8);
bytes[2] = (uint8_t) (val>> 16);
bytes[3] = (uint8_t) (val>> 24);
}
uint32_t cryptography::to_int32(const uint8_t *bytes)
{
return (uint32_t) bytes[0] | ((uint32_t) bytes[1] << 8)
| ((uint32_t) bytes[2] << 16) | ((uint32_t)
bytes[3] << 24);
}
void cryptography::MD_5(const uint8_t *initial_msg,
size_tinitial_len,
uint8_t *digest) {
for(j = 0;j<64;j++)
k[j] = fabs(sin(j+1)*pow(2,32));
//r specifies the per-round shift amounts
const uint32_t r[] = {7, 12, 17, 22, 7, 12, 17, 22, 7,
12, 17, 22, 7, 12, 17, 22, 5, 9, 14, 20, 5, 9, 14,
20, 5, 9, 14, 20, 5, 9, 14, 20, 4, 11, 16, 23, 4,
11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 6, 10, 15,
21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21};
//Thesevars will contain the hash
uint32_t h0, h1, h2, h3;
//Message (to prepare)
uint8_t *msg = NULL;
size_tnew_len, offset;
uint32_t w[16];
uint32_t a, b, c, d, i, f, g, temp;
//Initialize variables - simple count in nibbles:
h0 = 0x67452301;
h1 = 0xefcdab89;
h2 = 0x98badcfe;
h3 = 0x10325476;
//Pre-processing:
//append "1" bit to message
//append "0" bits until message length in bits
448 (mod 512)
//append length mod (2^64) to message
new_len = initial_len+1;
while((new_len% 64) ! = 56){
new_len++;
}
msg = new uint8_t[new_len+8];
memcpy(msg, initial_msg, initial_len);
msg[initial_len] = 0x80;//append the "1" bit; most
significant bit is "first"
for (offset = initial_len + 1; offset <new_len;
offset++)
msg[offset] = 0;//append "0" bits
//append the len in bits at the end of the buffer.
to_bytes(initial_len*8, msg + new_len);
//initial_len>>29 = = initial_len*8>>32, but avoids
overflow.
to_bytes(initial_len>>29, msg + new_len + 4);
//binary representation of the message after
padding
/*
for (inti = 0; i< new_len+8; i++) {
show_binrep(msg[i]);
}
*/
cout<<endl;
//Process the message in successive 512-bit chunks:
//for each 512-bit chunk of message:
offset = 0;
do{
//break chunk into sixteen 32-bit words w[j],
0 j 15
for (i = 0; i< 16; i++)
w[i] = to_int32(msg + offset + i*4);
//Initialize hash value for this chunk:
a = h0;
b = h1;
c = h2;
d = h3;
//Main loop:
for(i = 0; i<64; i++) {
if (i< 16) {
f = (b & c) | ((~b) & d);
g = i;
} else if (i< 32) {
f = (d & b) | ((~d) & c);
g = (5*i + 1)% 16;
} else if (i< 48) {
f = b ^ c ^ d;
g = (3*i + 5)% 16;
} else {
f = c ^ (b | (~d));
g = (7*i)% 16;
}
temp = d;
d = c;
c = b;
b = b + LEFTROTATE((a + f + k[i] + w[g]), r[i]);
a = temp;
/*
cout<<"Round: ["<<i+1<<"]"<<endl;
cout<<"h0: ";
show_binrep(a);
cout<<' '<<"h1: ";
show_binrep(b);
cout<<' '<<"h2: ";
show_binrep(c);
cout<<' '<<"h3: ";
show_binrep(d);
cout<<endl;
*/
}
//Add this chunk's hash to result so far:
h0 + = a;
h1 + = b;
h2 + = c;
h3 + = d;
offset + = 64;
}while(offset<new_len);
//cleanup
deletemsg;
//var char digest[16] : = h0 append h1 append h2
append h3
//(Output is in little-endian)
to_bytes(h0, digest);
to_bytes(h1, digest + 4);
to_bytes(h2, digest + 8);
to_bytes(h3, digest + 12);
}
int main() {
charmsg[SIZE] = "The quick brown fox jumps over the
lazy dog";
inti;
uint8_t msg_digest[16];
cout<<msg<<endl<<endl;
cryptographycp;
cp.MD_5((uint8_t*)msg, strlen(msg), msg_digest);
/*
for (inti = 0; i<strlen(msg); i++) {
show_binrep(msg[i]);
}
*/
cout<<endl<<endl;
for (i = 0; i< 16; i++){
printf("%2.2x", msg_digest[i]);
}
printf(" ");
return 0;
}
10.6 Implementation 2 [5,6]
/* MD5
Converted to C++ class by Frank Thilo ([email protected]) for bzflag (http://www.bzflag.org). Based on: md5.h and md5.c reference implementation of RFC 1321.
Copyright (C) 1991–1992, RSA Data Security, Inc. Created 1991. All rights reserved.
License to copy and use this software is granted provided that it is identified as the “RSA Data Security, Inc. MD5 Message-Digest Algorithm” in all material mentioning or referencing this software or this function.
License is also granted to make and use derivative works provided that such works are identified as “derived from the RSA Data Security, Inc. MD5 Message-Digest Algorithm” in all material mentioning or referencing the derived work.
RSA Data Security, Inc. makes no representations concerning either the merchantability of this software or the suitability of this software for any particular purpose. It is provided “as is” without express or implied warranty of any kind.
These notices must be retained in any copies of any part of this documentation or software.
*/
#include <cstring>
#include <iostream>
#include <cstdio>
using namespace std;
class MD5{
public:
typedef unsigned intsize_type;//must be 32bit
MD5();
MD5(const string& text);
void update(const unsigned char *buf, size_type length);
void update(const char *buf, size_type length);
MD5&finalize();
stringhexdigest() const;
friendostream& operator<<(ostream&, MD5 md5);
private:
voidinit();
typedef unsigned char uint1;// 8bit
typedef unsigned int uint4; //32bit
enum {blocksize = 64};//VC6 won't eat a const static
int here
void transform(const uint1 block[blocksize]);
static void decode(uint4 output[], const uint1
input[], size_typelen);
static void encode(uint1 output[], const uint4
input[], size_typelen);
bool finalized;
uint1 buffer[blocksize];//bytes that didn't fit in
last 64 byte chunk
uint4 count[2]; //64bit counter for number of bits
(lo, hi)
uint4 state[4]; //digest so far
uint1 digest[16];//the result
//low level logic operations
static inline uint4 F(uint4 x, uint4 y, uint4 z);
static inline uint4 G(uint4 x, uint4 y, uint4 z);
static inline uint4 H(uint4 x, uint4 y, uint4 z);
static inline uint4 I(uint4 x, uint4 y, uint4 z);
static inline uint4 rotate_left(uint4 x, int n);
static inline void FF(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac);
static inline void GG(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac);
static inline void HH(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac);
static inline void II(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac);
};
string md5(const string str);
//F, G, H and I are basic MD5 functions.
inline MD5::uint4 MD5::F(uint4 x, uint4 y, uint4 z) {
returnx&y | ~x&z;
}
inline MD5::uint4 MD5::G(uint4 x, uint4 y, uint4 z) {
returnx&z | y&~z;
}
inline MD5::uint4 MD5::H(uint4 x, uint4 y, uint4 z) {
returnx^y^z;
}
inline MD5::uint4 MD5::I(uint4 x, uint4 y, uint4 z) {
return y ^ (x | ~z);
}
//rotate_left rotates x left n bits.
inline MD5::uint4 MD5::rotate_left(uint4 x, int n) {
return (x << n) | (x >> (32-n));
}
//FF, GG, HH, and II transformations for rounds 1, 2,
3, and 4.
//Rotation is separate from addition to prevent
re-computation.
inline void MD5::FF(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac) {
a = rotate_left(a+ F(b,c,d) + x + ac, s) + b;
}
inline void MD5::GG(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac) {
a = rotate_left(a + G(b,c,d) + x + ac, s) + b;
}
inline void MD5::HH(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac) {
a = rotate_left(a + H(b,c,d) + x + ac, s) + b;
}
inline void MD5::II(uint4 &a, uint4 b, uint4 c,
uint4 d, uint4 x, uint4 s, uint4 ac) {
a = rotate_left(a + I(b,c,d) + x + ac, s) + b;
}
//default constructor, just initailize
MD5::MD5()
{
init();
}
//nifty shortcut ctor, compute MD5 for string and
finalize it right away
MD5::MD5(const string &text)
{
init();
update(text.c_str(), text.length());
finalize();
}
void MD5::init()
{
finalized = false;
count[0] = 0;
count[1] = 0;
//load magic initialization constants.
state[0] = 0x67452301;
state[1] = 0xefcdab89;
state[2] = 0x98badcfe;
state[3] = 0x10325476;
}
//decodes input (unsigned char) into output (uint4).
Assumes len is a multiple of 4.
void MD5::decode(uint4 output[], const uint1 input[],
size_typelen)
{
for (unsigned inti = 0, j = 0; j <len; i++, j + = 4)
output[i] = ((uint4)input[j]) | (((uint4)input[j+1])
<< 8) |
(((uint4)input[j+2]) << 16) | (((uint4)input[j+3])
<< 24);
}
//encodes input (uint4) into output (unsigned char).
Assumes len is
//a multiple of 4.
void MD5::encode(uint1 output[], const uint4 input[],
size_typelen)
{
for (size_typei = 0, j = 0; j <len; i++, j + = 4) {
output[j] = input[i] & 0xff;
output[j+1] = (input[i] >> 8) & 0xff;
output[j+2] = (input[i] >> 16) & 0xff;
output[j+3] = (input[i] >> 24) & 0xff;
}
}
//apply MD5 algorithm on a block
void MD5::transform(const uint1 block[blocksize])
{
uint4 a = state[0], b = state[1], c = state[2],
d = state[3], x[16];
decode (x, block, blocksize);
/* Round 1 */
FF (a, b, c, d, x[0], 7, 0xd76aa478);/* 1 */
FF (d, a, b, c, x[1], 12, 0xe8c7b756);/* 2 */
FF (c, d, a, b, x[2], 17, 0x242070db);/* 3 */
FF (b, c, d, a, x[3], 22, 0xc1bdceee);/* 4 */
FF (a, b, c, d, x[4], 7, 0xf57c0faf);/* 5 */
FF (d, a, b, c, x[5], 12, 0x4787c62a);/* 6 */
FF (c, d, a, b, x[6], 17, 0xa8304613);/* 7 */
FF (b, c, d, a, x[7], 22, 0xfd469501);/* 8 */
FF (a, b, c, d, x[8], 7, 0x698098d8);/* 9 */
FF (d, a, b, c, x[9], 12, 0x8b44f7af);/* 10 */
FF (c, d, a, b, x[10], 17, 0xffff5bb1);/* 11 */
FF (b, c, d, a, x[11], 22, 0x895cd7be);/* 12 */
FF (a, b, c, d, x[12], 7, 0x6b901122);/* 13 */
FF (d, a, b, c, x[13], 12, 0xfd987193);/* 14 */
FF (c, d, a, b, x[14], 17, 0xa679438e);/* 15 */
FF (b, c, d, a, x[15], 22, 0x49b40821);/* 16 */
/* Round 2 */
GG (a, b, c, d, x[1], 5, 0xf61e2562);/* 17 */
GG (d, a, b, c, x[6], 9, 0xc040b340);/* 18 */
GG (c, d, a, b, x[11], 14, 0x265e5a51);/* 19 */
GG (b, c, d, a, x[0], 20, 0xe9b6c7aa);/* 20 */
GG (a, b, c, d, x[5], 5, 0xd62f105d);/* 21 */
GG (d, a, b, c, x[10], 9, 0x2441453);/* 22 */
GG (c, d, a, b, x[15], 14, 0xd8a1e681);/* 23 */
GG (b, c, d, a, x[4], 20, 0xe7d3fbc8);/* 24 */
GG (a, b, c, d, x[9], 5, 0x21e1cde6);/* 25 */
GG (d, a, b, c, x[14], 9, 0xc33707d6);/* 26 */
GG (c, d, a, b, x[3], 14, 0xf4d50d87);/* 27 */
GG (b, c, d, a, x[8], 20, 0x455a14ed);/* 28 */
GG (a, b, c, d, x[13], 5, 0xa9e3e905);/* 29 */
GG (d, a, b, c, x[2], 9, 0xfcefa3f8);/* 30 */
GG (c, d, a, b, x[7], 14, 0x676f02d9);/* 31 */
GG (b, c, d, a, x[12], 20, 0x8d2a4c8a);/* 32 */
/* Round 3 */
HH (a, b, c, d, x[5], 4, 0xfffa3942);/* 33 */
HH (d, a, b, c, x[8], 11, 0x8771f681);/* 34 */
HH (c, d, a, b, x[11], 16, 0x6d9d6122);/* 35 */
HH (b, c, d, a, x[14], 23, 0xfde5380c);/* 36 */
HH (a, b, c, d, x[1], 4, 0xa4beea44);/* 37 */
HH (d, a, b, c, x[4], 11, 0x4bdecfa9);/* 38 */
HH (c, d, a, b, x[7], 16, 0xf6bb4b60);/* 39 */
HH (b, c, d, a, x[10], 23, 0xbebfbc70);/* 40 */
HH (a, b, c, d, x[13], 4, 0x289b7ec6);/* 41 */
HH (d, a, b, c, x[0], 11, 0xeaa127fa);/* 42 */
HH (c, d, a, b, x[3], 16, 0xd4ef3085);/* 43 */
HH (b, c, d, a, x[6], 23, 0x4881d05);/* 44 */
HH (a, b, c, d, x[9], 4, 0xd9d4d039);/* 45 */
HH (d, a, b, c, x[12], 11, 0xe6db99e5);/* 46 */
HH (c, d, a, b, x[15], 16, 0x1fa27cf8);/* 47 */
HH (b, c, d, a, x[2], 23, 0xc4ac5665);/* 48 */
/* Round 4 */
II (a, b, c, d, x[0], 6, 0xf4292244);/* 49 */
II (d, a, b, c, x[7], 10, 0x432aff97);/* 50 */
II (c, d, a, b, x[14], 15, 0xab9423a7);/* 51 */
II (b, c, d, a, x[5], 21, 0xfc93a039);/* 52 */
II (a, b, c, d, x[12], 6, 0x655b59c3);/* 53 */
II (d, a, b, c, x[3], 10, 0x8f0ccc92);/* 54 */
II (c, d, a, b, x[10], 15, 0xffeff47d);/* 55 */
II (b, c, d, a, x[1], 21, 0x85845dd1);/* 56 */
II (a, b, c, d, x[8], 6, 0x6fa87e4f);/* 57 */
II (d, a, b, c, x[15], 10, 0xfe2ce6e0);/* 58 */
II (c, d, a, b, x[6], 15, 0xa3014314);/* 59 */
II (b, c, d, a, x[13], 21, 0x4e0811a1);/* 60 */
II (a, b, c, d, x[4], 6, 0xf7537e82);/* 61 */
II (d, a, b, c, x[11], 10, 0xbd3af235);/* 62 */
II (c, d, a, b, x[2], 15, 0x2ad7d2bb);/* 63 */
II (b, c, d, a, x[9], 21, 0xeb86d391);/* 64 */
state[0] + = a;
state[1] + = b;
state[2] + = c;
state[3] + = d;
//Zeroize sensitive information.
memset(x, 0, size of x);
}
//MD5 block update operation. Continues an MD5
message-digest
//operation, processing another message block
void MD5::update(const unsigned char input[],
size_type length)
{
//compute number of bytes mod 64
size_type index = count[0]/8% blocksize;
//Update number of bits
if ((count[0] + = (length << 3)) < (length << 3))
count[1]++;
count[1] + = (length >> 29);
//number of bytes we need to fill in buffer
size_typefirstpart = 64 - index;
size_typei;
//transform as many times as possible.
if (length > = firstpart)
{
//fill buffer first, transform
memcpy(&buffer[index], input, firstpart);
transform(buffer);
//transform chunks of blocksize (64 bytes)
for (i = firstpart; i + blocksize< = length;
i + = blocksize)
transform(&input[i]);
index = 0;
}
else
i = 0;
//buffer remaining input
memcpy(&buffer[index], &input[i], length-i);
}
//for convenience provide a verson with signed char
void MD5::update(const char input[], size_type length)
{
update((const unsigned char*)input, length);
}
//MD5 finalization. Ends an MD5 message-digest
operation, writing the
//the message digest and zeroizing the context.
MD5& MD5::finalize()
{
static unsigned char padding[64] = {
0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
};
if (!finalized) {
//Save number of bits
unsigned char bits[8];
encode(bits, count, 8);
//pad out to 56 mod 64.
size_type index = count[0]/8% 64;
size_typepadLen = (index < 56) ? (56 - index) :
(120 - index);
update(padding, padLen);
//Append length (before padding)
update(bits, 8);
//Store state in digest
encode(digest, state, 16);
//Zeroize sensitive information.
memset(buffer, 0, size of buffer);
memset(count, 0, size of count);
finalized = true;
}
return *this;
}
//return hex representation of digest as string
string MD5::hexdigest() const
{
if (!finalized)
return "";
charbuf[33];
for (inti = 0; i<16; i++)
sprintf(buf+i*2, "%02x", digest[i]);
buf[32] = 0;
return string(buf);
}
ostream& operator<<(ostream& out, MD5 md5)
{
return out << md5.hexdigest();
}
string md5(const string str)
{
MD5 md5 = MD5(str);
return md5.hexdigest();
}
int main(intargc, char *argv[])
{
cout<< "md5 of 'grape': "<< md5("grape") <<endl;
return 0;
}
10.7 Conclusion
Message digest algorithms such as MD5 are mainly used in implementing a digital signature, which requires all of the general properties mentioned above. However, the property requirement may vary based on which application is using this algorithm. An application may depend on some or all of the properties of the MD5. For example, some applications use the one-way property of an MD5. Because of its property of pseudorandomness, MD5 is also used to be part of the mechanism for random number generation. MD5 digests have been widely used in the software industry to provide some assurance that a transferred file has arrived unbroken. For example, file servers often provide a precomputed MD5 (known as md5sum) checksum for the files so that a user can match the checksum of the downloaded file and verify the integrity [4]. Most Unix-based operating systems’ distribution package includes MD5 sum utilities. MD5 is also available to Windows operating system users. They may install a Microsoft utility or use third-party applications. This type of checksum is also utilized by Android ROMs (read-only memories). Compared to other digest algorithms, MD5 is simple and easy to implement. It performs very fast on a 32-bit machine. It is inferred that the difficulty of coming up with two messages having the identical message digest is on the order of 264 operations, and the difficulty of coming up with any message having a given message digest is on the order of 2128 operations.
References
1. MD5, Command Line Message Digest Utility, http://www.fourmilab.ch/md5/.
2. Li, J. MD5 Message Digest Algorithm. Computer Science Department, San Jose State University.
3. MD5, Wikipedia, http://en.wikipedia.org/wiki/MD5.
4. MD5 Sum, Wikipedia, http://en.wikipedia.org/wiki/Md5sum.
5. A Portable, Fast, and Free Implementation of the MDS Message-Digest Algorithm (RFC 1321), http://openwall.info/wiki/people/solar/software/public-domain-source-code/md5.
6. C++ MD5 Function, Zedwood, http://www.zedwood.com/article/cpp-md5-function.
7. CERT Vulnerability Note VU#836068. Retrieved February 8, 2014, from Kb.cert.org.
8. NIST.gov—Computer Security Division—Computer Security Resource Center. Retrieved from csrc.nist.gov.