
In this chapter, we’ll cover two final critical concepts, as we discuss asynchronous operations and using multiple database contexts in our solutions.
At the end of this chapter, we’ll have seen how we can implement the database layer while leveraging the power of multiple cores in our computers. We’ll also have taken a look at how it is possible to use more than one database context in our solutions.
Asynchronous operations
The first concept we need to talk about is working with asynchronous operations. To this point, we’ve done everything with all methods being synchronous. However, in most practical applications, we’ll be leveraging the power of asynchronous programming.
Multithreaded programming
As our computer architectures changed from being processor speed oriented as the metric of superiority to processor speed plus core count oriented, multithreaded programming became much more popular and much more important in our day-to-day work.
The main problem with multithreaded programming is that it is difficult. There are many issues to consider before diving into multithreaded programming. Race conditions lead to your asynchronous code executing processes or methods out of order. Thread pools run out of available threads and can still cause pieces of your program to become unresponsive. In a worst-case scenario, threads get locked in an infinite loop and your entire application becomes unresponsive.
Because of the overall difficulty of asynchronous programming, the original rate of adoption was not that high. In fact, the main use prior to the TaskParallelLibrary (TPL) being introduced for most developers was likely just to keep desktop forms from appearing to be locked while processes ran in the background after pressing a button. I even wrote a blog post in 2009 on how to use events, delegates, and threads to avoid running into that specific problem.
Because of the difficulty of multithreaded programming, and the various technical problems associated with it, the .Net Framework was expanded to make our lives a whole lot better.
Async, await, and the TaskParallelLibrary
In the .Net world, async and await keywords first showed up in the .Net 3.0 Framework, but didn’t become widely adopted and useable until the TaskParallelLibrary (TPL) was introduced in .Net 4.
The TPL gave all of us the ability to specify the Task operations with return types that we have come to rely on in our asynchronous code. With the TPL, we can also rely on the fact that issues with concurrency are handled correctly. For example, using the await operator or requesting to get the result of a parallel operation gives us the assurance that our code will not continue to execute until the threaded operation has completed.
Responsive solutions for the end user
To put this more into perspective, think of websites from the early 2000s through about 2010. Perhaps you’ve even heard the term Web 2.0. Prior to Web 2.0 and other initiatives that happened at the end of the 2000s into the 2010s, websites were mostly one user doing one thing for themselves, or essential duties that they would perform, or were just simple, static files. Web 2.0 really grasped the idea that there should be multiple users interacting in the same systems and that each user should see information in real time.
With Web 2.0, it was more common to expect your changes to be immediately reflected to other users of the same system. This led to new approaches to web services and a movement into REST APIs, as well as things like the AjaxControlToolkit and SignalR, to provide an ability to abstract programmers from having to work directly with websockets. In the end, real-time dashboards as part of partial pages were able to immediately display results to the end user. Where a single-threaded approach would need to load all of the page data and then render it, and also get all of the page data from the server to re-render even the smallest changes, Web 2.0 essentially moved us to having multithreaded web pages with various portions responding to different threads and no longer having to reload the whole page to see a simple change on one metric.
All of this brings us to the place where we want to land for our database as well. If you create a dashboard that requires ten different pieces of information from the database, you don’t want the database calls to stop the page from working, and you don’t want the page to wait to respond until all ten different calls have completed.
By placing our database calls into asynchronous operations, our web solutions can also remain asynchronous, and the overall responsiveness of the site appears to be much better, even if there are still calls that bottleneck the process.
Asynchronous database operations
With the TPL and the ability to define a return type that is based on a threaded operation, we can leverage our processor architecture. Using async and await with our operations obfuscates the need to do the heavy lifting of multithreading ourselves, and we can get to a much more responsive solution with less concern about the underlying issues involved with multithreading.
Programming the database operations to also happen in an asynchronous manner thereby gives us the full power to leverage the TPL and the async and await keywords.
In other words, by using asynchronous database operations, we’ll get to keep programming as if we are working with commands in a synchronous manner, while leveraging the power of our multiple-core processors and the underlying multithreading that is available to us. Utilizing asynchronous database operations ultimately helps us to keep our applications responsive while querying the database in the most efficient manner possible.
Basic asynchronous syntax
Without going into a lot of detail here, setting our methods to use asynchronous operations is very straightforward. We will cover all of this in detail in our first activity later in this chapter.
Rework all methods to be async Task operations
Change all database calls to happen with the built-in async abilities of EF
Refactor any queries that don’t work as written in an asynchronous pattern
Use the async/await pattern throughout the application
Show how to execute an async operation from a synchronous context
Multiple database contexts
In most applications, a single database context can handle your needs. However, while it is not necessary and should ultimately be used with caution, there will be times when using multiple contexts can be beneficial.
Single sign on (SSO)
The most common reason I can conceive that you would want to have multiple database contexts would be in a company where you have a suite of applications and you want to provide custom sign-on capabilities to users (outside of Azure AD or an on-premises Active Directory).
In this solution, rather than require your users register for all of your applications, you can have an SSO solution where once a user is registered with one of your applications, the same user and password combination can be used for all of them.
It’s certainly true that you could replicate the data in the tables for user management across all of your applications with a background process . However, if all applications connect to and use the same database for identity, you can do much less work and have much less of a chance for error.
Business units
Another solution that might lend itself to multiple contexts would be a situation where you want to separate units within your corporation into their own database solutions while providing a single application to interact with the data.
For example, consider a large banking corporation that has units of work around accounting practices, customer management, financial investment operations, marketing, insurance, lending, and collections.
In this corporation, certain employees would likely need access to pieces of information in all units, such as a customer account with balance and perhaps payment and balance history in combination with mortgage and credit card information. Other business unites might only need access to one or two of the pieces of information. For example, marketing employees might only need access to customer name and address information. Furthermore, some information might be entirely confidential, and, due to regulations, knowing that information could lead to a potential violation of federal law (such as a fairness in lending act), so it may be critical to keep a clear separation of concerns to provide boundaries that cannot be circumvented.
When a case such as this exists, you’ll likely need to expose certain shared data across line-of-business applications, or you may need to have directly created contexts to leverage only the parts of each system that should be accessible. Again, the choice here is which is better for your company – from background jobs to sync your data on some time interval to direct immediate access to the most valid dataset that you can provide, the choices and implementations will be your responsibility as the developer.
Multiple contexts require a bit more work
If our solution is going to use multiple contexts, there are a few things we’ll need to be aware of.
The first thing to be certain to address is the injection of the context and the creation of the context at startup. Most applications will inject their context at startup, but you’ll be required to also include any additional contexts. Using the additional contexts also generally requires a shared library that can leverage the shared contexts.
The second critical piece of information that is important when working with multiple contexts is the knowledge of the commands to run in the package manager console. With a single context, a simple add-migration or update-database command can be run at will. Once you have introduced a second context into the solution, the PMC will need you to explicitly specify which context to use when running these commands.
Finally, using multiple contexts requires that everyone is on the same page as to the standards and approaches used in unit testing and interface segregation. While you could get by without this, it will be nice to know that any library developed around a context is fully unit and integration tested. Additionally, if there are security concerns, the ability to get just a read-only version of the context without much work should be readily available.
Putting it into practice
We’ve now done a good deal of talking about asynchronous operations and the database, as well as using multiple contexts.
For the remainder of the chapter, we’ll work through these scenarios to see what it takes to get set up, as well as learn about how to work with commands and code when making asynchronous calls or trying to add or update the database from the code-first approach to database development.
Activity 1401: Asynchronous database operations
In our first activity, we are going to rework our inventory database library to use asynchronous operations.
Leveraging async and await
The main purpose of this activity is to give us the ability to implement calls that rely on the async/await pattern. By doing this, we should be able to free up our applications to continue processing as well as optimize the performance of our own database operations to leverage the power of multithreading without all the heavy lifting.
As mentioned previously, there will be a few things we have to refactor, and the changes will ripple up all the way to our program. This also means we’ll have to refactor our tests. In the end, this solution will be much more like what we’ll encounter in any real-world application going forward.
Step 1: Steps
To begin, grab a copy of the Activity1401_AsynchronousDatabaseOperations_Starter.zip files, extract them, build the project, double-check your connection string, and make sure that you have the InventoryManager database set up. Run an update-database command to make sure the migrations are up to date on your machine. Additionally, you could run an add-migration command to ensure that you don’t have any pending changes. Assuming there are none, you could then just run the remove-migration command to clean up the empty migration. If you have pending changes, consider just updating the database to match the current solution using the update-database command.
Alternatively, you could just continue using your InventoryManager solution that you’ve been building through the previous chapters in this book, with your code in the same state as it was at the end of Chapter 13.
Step 2: Begin at the database level
To make the changes work, we’re going to have to touch most of the layers in some way or another, including the tests. We’ll start by reworking all of the database calls and move up the layers from there. Along the way, we’ll see how to make calls with async/await, as well as see the ability to run from a synchronous method when we get to the program.

Reworking the interface causes a number of expected build errors
We can use the errors to work out the problems going forward as a road map. We already know that we changed the interface that is implemented by two classes. The next step is to rework the two implementations. Do not select “implement interface,” or you’ll get a number of duplicated methods. Instead, let’s fix the methods and the code that goes with them.
In the InventoryDatabaseRepo, begin by fixing the method signatures to match the methods in the interface. This is done by once again wrapping the return types with Task<T> or setting the return type to Task when the method is void. Additionally, each method needs to be declared as an async method. For example, the public List<GetItemsForListingDto> GetItemsForListingFromProcedure(...) method becomes public async Task<List<GetItemsForListingDto>> GetItemsForListingFromProcedure(...).
Make sure to add the using statement for System.Threading.Tasks.
After fixing all the signatures, a number of errors will be created. We’ll now walk through each method and fix the internal code.

Methods that are asynchronous expect to await within the method
While you can have an async method that does not have an await operation in it and still have valid execution, the warning here is to remind you that you made an asynchronous method without an await operation. We want to await the database call. To do this, we need to make a couple of changes.
Next, let’s fix the GetItemsForListingLinq method . This fix will be more involved. Because of the way this query is built and because of the database encryption we have implemented, we have to get the list back sooner than would be ideal. Making this method asynchronous will force us to rework the ordering a bit as well.
This change will allow us to get the list in an asynchronous manner and then we have to do the ordering. The IOrderedEnumerable will not work asynchronously as the code is written, so, while not ideal, at least we got the limited results with the query. If we wanted, we could get the query as an AsyncEnumerable, which would allow for async enumeration of the results, but here we’ll just fetch the results with the await operation and then order the resulting list in memory.

The reworked GetItemsForListingLinq method is now asynchronous

The IOrderedEnumerable does not allow a ToListAsync() operation
For the UpdateItem method , we need to make a couple of similar changes. Add await to the call to get Items, and also change the FirstOrDefault call to SingleOrDefaultAsync.
To complete this portion of the activity, we need to also refactor the Dapper implementation.
To do this, once again change all the method signatures on each method to match the asynchronous changes as defined in the interface. Most of these methods are unimplemented, so we can just leave them. They will have a green squiggly line indicating that they do not implement an await operator, but that will not break the compiler or the program execution, even if the method had other synchronous code in it.

The InventoryDatabaseDapperRepo class with methods changed to implement asynchronous operations. For brevity, method bodies are not shown in the image but do exist in the code
To complete the code changes in the InventoryDatabaseDapperRepo, we need to fix the two methods that are implemented. Beginning with ListCategoriesAndColors, change the code for the first var result = _connection.Query... to var result = await _connection.QueryAsync<dynamic>(sql);.

Errors in the BusinessLayer and in the integration tests now exist
Step 3: Update the integration tests to use asynchronous database operations
Now that our database layer is fully updated, we need to begin the next layer of fixes by first fixing the integration tests and making sure they still work as expected.
Open the InventoryManagerIntegrationTests class file in the IntegrationManagerTests project.

The four test methods are changed to become asynchronous tests
Make sure to add the using statement for System.Threading.Tasks so that the code will compile.
In the each of the four methods identified in Figure 14-7, simply find any calls to the _dbRepo objects and add the await operator to allow for the methods to operate asynchronously. For example, in TestListInventory, change var items = _dbRepo.ListInventory(); to var items = await _dbRepo.ListInventory();
There should be four calls to await added to the test project when this is completed:
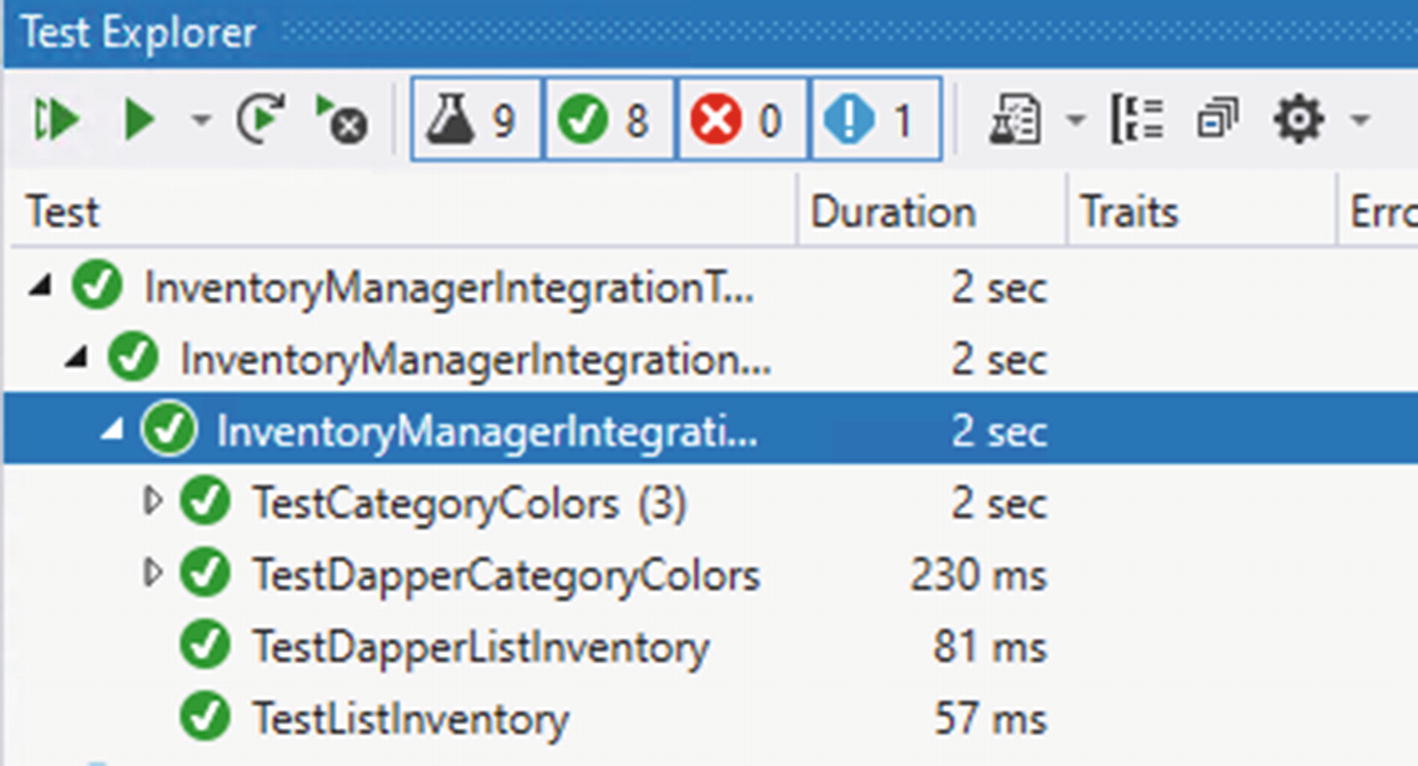
The integration tests should all be passing at this point
Step 4: Update the business layer
The next step in refactoring our code is to refactor the business layer. This will be a fairly easy and quick operation, now that the deeper database layer is already refactored and validated to be working via the integration tests.
Make sure to also update any calls in other methods to the ListInventory method to include an await operator, i.e., var items = await ListInventory(); such as in the GetItemsPipeDelimitedString method.
Now that our ItemsService is updated, we also need to update the ItemsServiceReadOnly to use asynchronous operations.
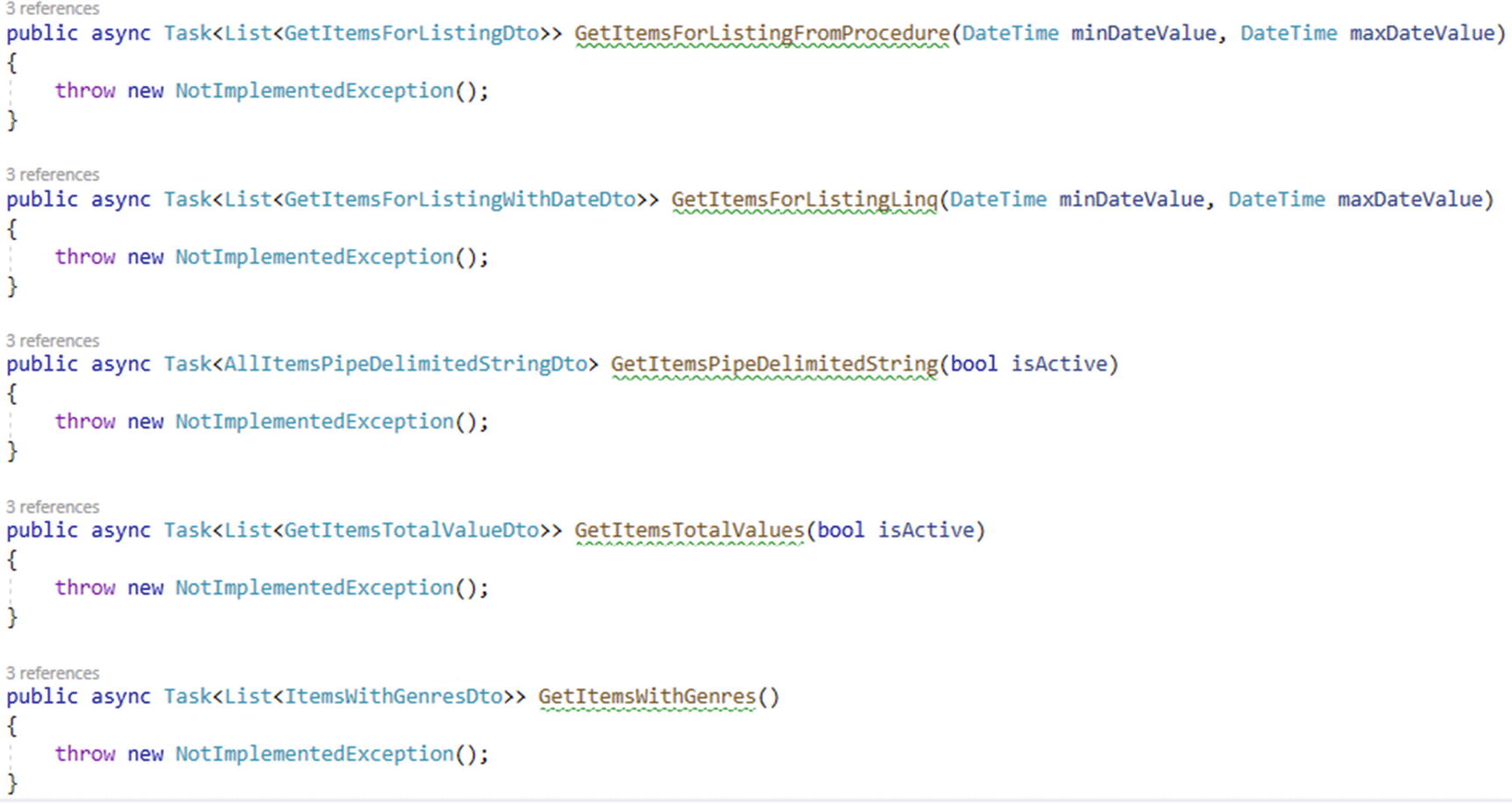
The remaining methods just need the updated signatures for asynchronous operations
This completes our refactoring of the business layer. Rebuild the project to see the next set of errors, which will be in the InventoryManagerUnitTests and the overall program itself.
Step 5: Update the unit tests
Now that the business layer is in place, we need to update the unit tests. Open the InventoryManagerUnitTests file in the InventoryManagerUnitTests project.
There won’t be a lot to change in this project since we just have the one test. For the setup however, we need to do something a bit different. Since we are going to be mocking an asynchronous return, we need to get the _allItems object as the result of a Task. To do this, we can simply use the call Task.FromResult(_allItems).

The Unit tests are now passing as expected
All that remains is to fix the main program.
Step 6: Update the Program
To complete the system and allow it to work, we need to update the Program. In this part of the activity, we have all the code turned on and just need to get the calls to work with the new asynchronous code.
One thing that will happen is that there are a number of calls to ListInventory. For this reason, the first thing we should do is create a helper method to get the Inventory List. This will also give us a chance to see how to run an asynchronous piece of code from within a synchronous context.
Make sure to also add the using statement for.
In this code, we see the call to Task.Run(() => ...).Result; That line of code allows us to tell the system to run a command and then use a lambda to inject the asynchronous code to run. Since our method is not asynchronous, we cannot await the result. Therefore, we add the call to .Result at the end of the statement, which tells the system to wait until a result is returned.
Now that we have our common code for getting inventory, let’s fix the rest of the code.
To begin, replace any calls in the code to svc.ListInventory with the new method call to GetInventoryList(svc). There should be six places to replace and the one result that we just created with our new method. For example, the line var inventory = svc.ListInventory(); becomes var inventory = GetInventoryList(svc);.
Using the find and replace tool of ctrl + H, enter the svc.ListInventory() search term and replace all but the new method with GetInventoryList(svc).

A simple find can help validate that we have successfully replaced all six calls to get the items
Rebuild the solution to see further errors. Each issue revolves around the fact that the method went from being synchronous to asynchronous. To fix the rest of the calls, look for a call to the business layer and then initiate the call using the Task.Run syntax learned previously.
In the update multiple items method, set the svc call for two lines of code to use the Task.Run(...) operation. First, find and set svc.InsertOrUpdateItem(updItem) to Task.Run(() => svc.InsertOrUpdateItem(updItem));. Then find and set the svc.InsertOrUpdateItems(allItems) method to Task.Run(() => svc.InsertOrUpdateItems(allItems));.

The Update Multiple Items method is reworked

The Delete Multiple Items method is refactored
Build and run the program. Everything should work as expected now that we have fixed up the code. Figure 14-14 shows the program in action with asynchronous operations.
Remember, if you are having problems getting the program to run, don’t hesitate to just leverage the code in the final version of the files to see the completed version of these reworked method calls.

The Program in action, now completely reworked for asynchronous database operations
This concludes the activity on asynchronous database operations.
Final thoughts on activity 1401
In this first activity for our chapter, we were able to work through getting the database operations into an asynchronous pattern. We started by changing out the lower-level database layer calls to leverage the context with async and await calls.
After working through each layer, we saw how easy it was to refactor the solution for asynchronous operations. In the end, our program remained as a synchronous method, and therefore we used the Task.Run(() => somecode).Result call to get the results of an asynchronous operation from a synchronous context.
In the next activity, we’ll see what it takes to work with multiple contexts and how having the power to work with asynchronous commands can really help a solution be more responsive.
Activity 1402: Multiple database contexts
In our second activity, we are going to leverage a shared database context for single-sign-on solutions to manage user identities. To simplify this operation, we’ll create a new web solution and integrate the inventory context into the solution.
The identity context
To handle the authentication and authorization in a .Net web application, the system allows for the solution to quickly generate all necessary role and user information in the IdentityContext.
If we were going to create a suite of applications, the ideal approach would be to generate out this identity context and place it in its own library which could then be easily leveraged in the console application and other solutions.
For purposes of brevity, I will leave that to you if you desire to do so.
Step 1: Get the files we created in Chapter 6
We created a new web application all the way back in Chapter 6. To complete this activity, we’ll be starting where we left off in that activity. In the event you didn’t complete those activities, you can just get the Activity1402_Multiple_Database_Contexts_Starter.zip files and extract them to use on your local development machine.
You may need to update the connection string in the appSettings.json file , as the default connection for the web app is just going to leverage the localdb. This simulates a situation where you have an application that connects to two different databases on two different servers.
Once up and running, make sure you can register users and log in to validate the fact that we have a prebuilt identity schema in place for managing user authentication and authorization.
Additionally, you’ll need to put a few categories into the category table. This will not be the same as our inventory system, so feel free to enter anything you want.
Since I’m creating the starter pack and activity 0601 was not a long activity, I’m just running with new files. You could do the same if you so desired.
A copy of this script is also available in the Resources folder in the starter pack files.
Step 2: Bring the inventory libraries into the project

Importing existing projects

Adding references to the InventoryBusinessLayer project
The important thing to note is to not forget that you may need to update that connection string to point to the correct local database instance, whether it’s in SQLExpress or SQLDeveloper edition.
Build the solution and run it. There shouldn’t be any issues. If for some reason you get an issue, you may just need to make sure all of your NuGet packages are updated to the latest versions.
Step 3: Add the context to the injection for the web application
With the InventoryManager libraries ready to go, it’s time to inject the context into the project so that we can use it in our web solution.
Locate the Startup.cs file in the web application. Notice the ConfigureServices method. This is where the context injection will be added. Note that there is already a statement to add the DBContext for the ApplicationDbContext – the default context that contains identity.
We need to add another AddDbContext statement, and we need to leverage the connection string that we copied in the previous step.
Copy the lines for services.AddDbContext<....."DefaultConnection")));

Injecting the InventoryDBContext into the solution
Note that there is no reason we must use a different database. As long as the two contexts do not conflict with one another, you can put them both into the same database.
Run the solution to make sure there are no issues. Everything should still work as before.
Step 4: Generate Inventory controllers and views for Items
Now that we’ve brought our InventoryDBContext into the solution, let’s generate some CRUD operations around the Inventory items in the web solution.
Adding a new controller
Use the views and Entity Framework

Setting up the scaffolding operation for Inventory Items
Add the controller and let the scaffolded views be created by default.
Our inventory context is leveraged, but not our service and database layer that we’ve tested. By default, the solution is putting direction operations against the DBContext into the controller.
Let’s run it to validate that things are working the way we would expect. Run the project and navigate to https://localhost:<yourport>/InventoryItems.
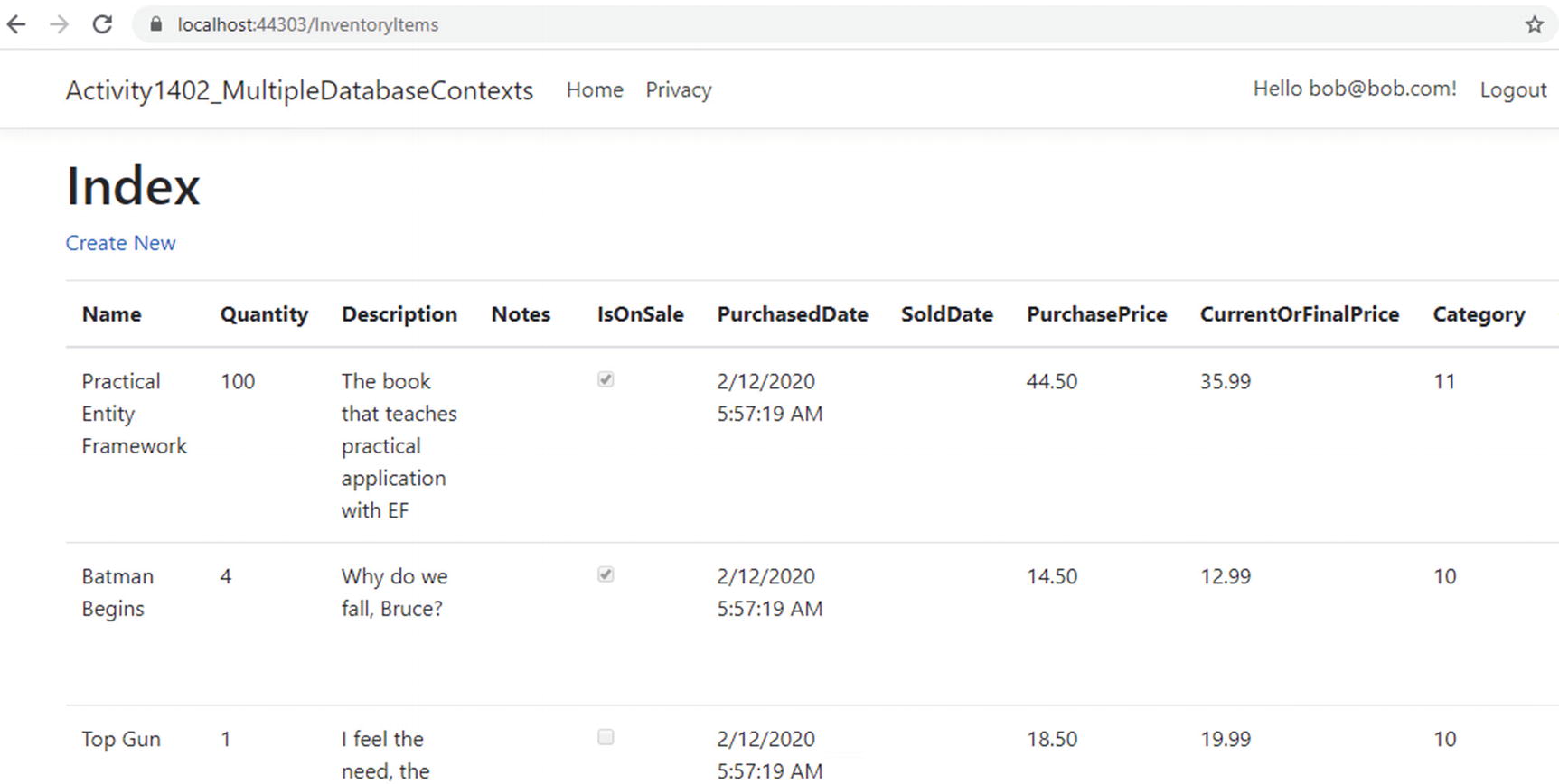
The inventory Items context is wired up as expected
Make sure you can also view, create, edit, and delete items.
This is not a book on web development. Therefore, we aren’t going to spend any time making the web page nicer at this point. Clearly, this page is not production-ready.
A couple of final thoughts. We directly leveraged the context and injected it. To make this solution work more like a production system, it would be a good idea to set up AutoMapper and instantiate it at the services level (like we did for the context, similar to how we set everything up in the console app). Then, in the InventoryItems Controller, instantiate an ItemsService object, and only use that object to get data.
After refactoring to set the ItemsService in the controller, also refactor the views to use the DTO objects instead of the full-blown models.
Finally, you’d want to make sure that your drop-down list shows the CategoryName, not the Id so that the user could know which category they are selecting.
The amount of work it would take to do this is outside of the scope of this activity, but is a worthy endeavor to continue your learning.
Step 5: Add a new model to the web application context, add the migration, and update the database
With the new State model added to the solution, add the State model to the ApplicationDBContext so it can be leveraged in code. Add the line public DbSet<State> States { get; set; } to the ApplicationDbContext. You can add the code anywhere in the class, but I generally stack my properties and then do the constructors and then other methods. For this instance, I put the States DbSet property after the Categories property and before the Constructor.

Can’t add a migration when there are multiple contexts
Trying to run the migration in this situation generates an error due to having multiple contexts in the solution. To remedy that, the suggestion is to use the -Context flag . In EF6, we leveraged the -ConfigurationTypeName flag.
One other important note here. When using multiple database contexts, you should make sure they are in different namespaces, and then when you reference them, use the fully qualified name, including the namespace. This will ensure the correct migrations are associated with the correct contexts.
When the command add-migration <name> -Context <NameSpace>.<ClassName> is used, the migration generates as expected.
Now we just need to run update-database, right? You probably guessed by now that just running update-database will have the same problem as add-migration. Instead, run the command update-database -Context Activity1402_MultipleDatabaseContexts.Data.ApplicationDbContext.
If we wanted, we could generate the controller and views for the State model to see that it works as expected in the database. Additionally, we could go on to add more entities to the InventoryManager system . In that case, the database for the InventoryManager would reflect the migrations.
When running the update-database command, it is not as important to fully qualify with the namespace, because the program is not generating anything but is executing. In the preceding command, we could have simply run the command update-database -context ApplicationDbContext.
In the rare instance that you are using multiple contexts against the same database, just remember that you can’t have conflicts in naming between the two contexts. Once one of them has a model that is leveraged, named States, for example, the other one would not be able to add it since they both exist in the same database. However, when multiple databases are used in conjunction with contexts, then the model names do not need to be unique and can be reused, such as Item was reused in both of our contexts for this activity.
Final thoughts on activity 1402
In this second activity for our chapter, we were able to see what it would take to leverage multiple database contexts in the same solution.
The main takeaway is that it is possible, and this opens the door for sharing data across solutions, such as sharing the user identity management portion of a suite of solutions within one database context that can be shared.
Additionally, using multiple contexts opens the door to both sharing the same database and having separate implementations, perhaps even across vendors. There is nothing stopping us from having one context connecting to SQL Server and another to Oracle.
The real difference in the way we have to work when using multiple contexts is that we have to remember to explicitly name the context in the PMC as we run commands. The command in .Net Core is simple: -Context. The command in EF6 was a bit less intuitive and was named -ConfigurationTypeName .
In general, working with multiple contexts should be discouraged, but it is not impossible. There is added complexity that comes into play with multiple contexts. However, there are definite benefits in clear boundaries between things like users and application data, as well as potential segregation of business units.
Final thoughts for this chapter
In this chapter, we’ve covered a couple of very critical aspects of working with Entity Framework in our applications.
Perhaps we should have talked about asynchronous operations earlier in the book, perhaps not. Even so, using asynchronous operations will likely be the normal solution that you encounter in your day-to-day work. The benefits of leveraging multithreading without having to wire up and manage the underlying code are extremely useful.
Having our database operations working in an async/await pattern allows us to write our solutions in a more responsive manner. By using async and await, we can still write our code in a synchronous manner and not have to worry about concurrency or race conditions.
We also talked about another common issue when we discussed using multiple contexts. In most cases, as mentioned previously, I would recommend staying away from multiple contexts. That being said, it is still entirely possible for us to use this approach and beneficial in certain situations.
In our second activity for the chapter, we were able to leverage multiple contexts to prove that an application can use both an identity context that is shared among solutions and other database contexts as well. By having all of this in place, we can make a suite of applications that can easily share data. We can also segregate certain parts of our exposed surface so that users only get the access they need to specific pieces of data.
In the next and final chapter of our book, we’ll discuss the changes that are coming with .Net 5 and likely are in place by the time you are reading this book. As EF has continued to evolve, our lives have gotten substantially better. The latest version of the .Net Framework/.Net Core architecture is a recombination of each platform into one platform to rule them all - .Net 5.