
Lots of data have a date range for validity – when is or was the event or price or whatever active. Schedules, prices, discounts, versioning, audit trails, the list is endless.
It’s common to want to merge rows (at least in report output) where the date ranges are right after one another or even overlapping. For example, you may have a production schedule for your assembly line having three rows with adjoining date ranges – producing the same product for three different sales orders. For production planning, you may want to output this as a single row with the total date range and the sum of the quantities you need to produce.
There can be many other examples of this – in this chapter I’ll show you an example of merging job hire periods with the match_recognize clause.
Job hire periods
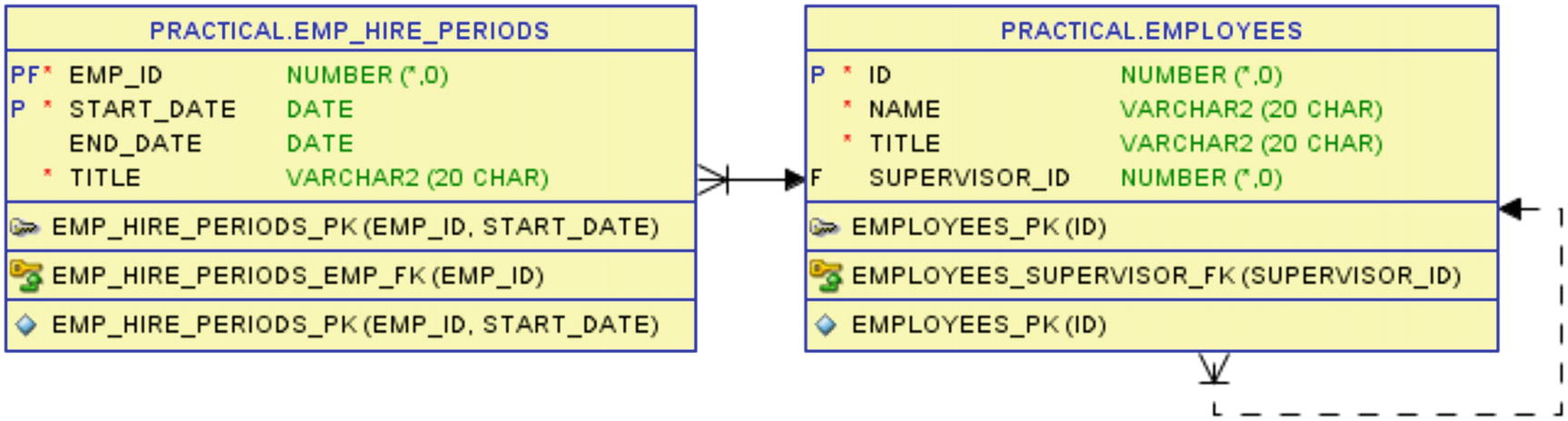
The table of periods that employees have been hired for a given job
A null value in end_date means the employee currently works at that function.
When an employee stops working for Good Beer Trading Co, end_date is filled.
If the employee is rehired, a new row is inserted.
By promotion or change in job function, end_date is filled, and a new row is inserted with the new title.
An employee can have more than one function at the same time, so the date ranges may overlap.
The start_date is included in the date range and the end_date is excluded from the date range – often written as a [start_date, end_date[ half-open interval.
You may find the last rule less than intuitive, but I’ll get back shortly with an explanation of why this is a good idea.
A closed interval [start, end] is start <= x <= end, while an open interval ]start, end[ is start < x < end. The half-open interval is then either ]start, end] or (as in this case) [start, end[.
View joining the hire periods with the employees
The hire periods data
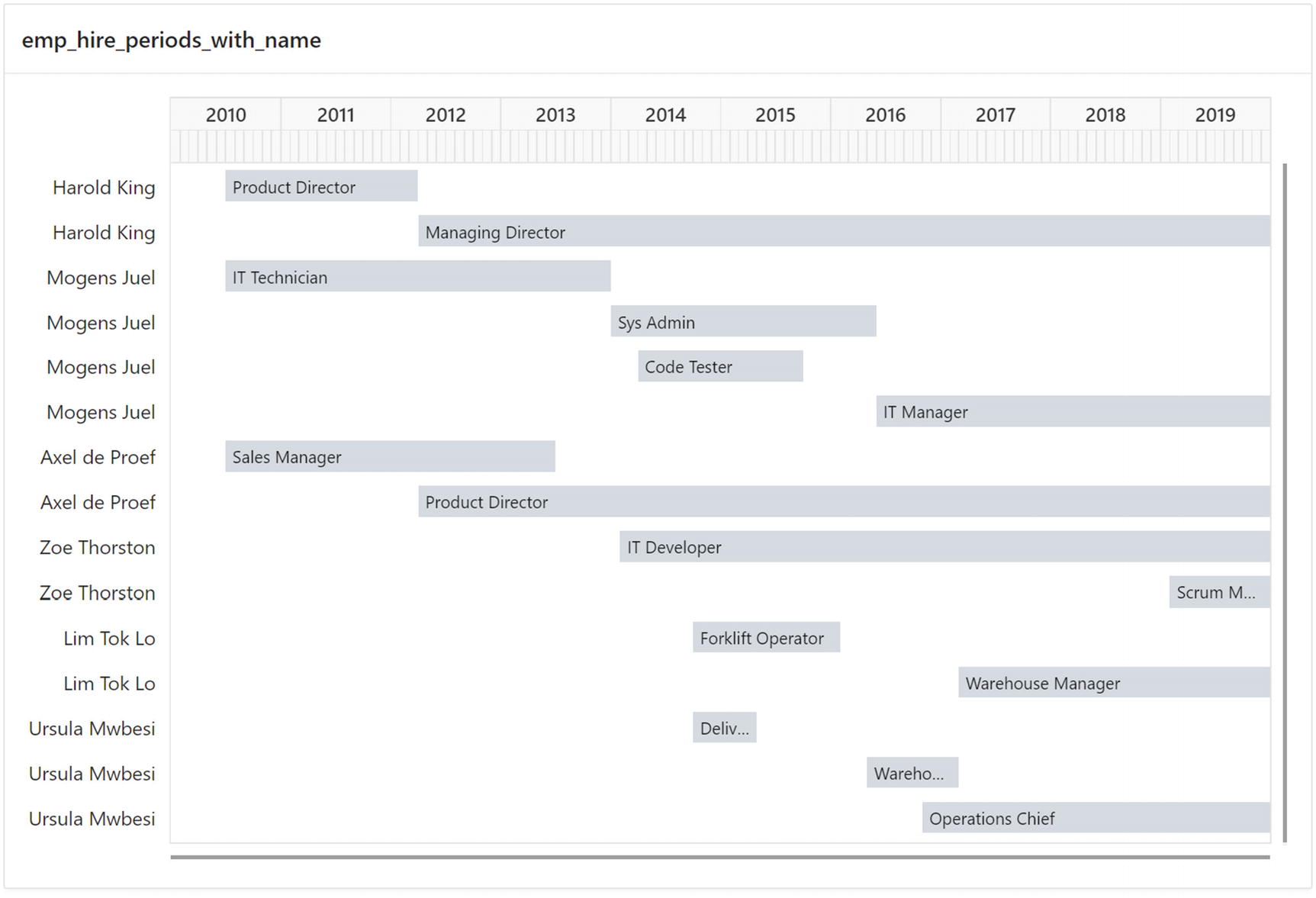
Visualizing the data helps see the overlaps
You’ll notice that because I use the half-open interval I mentioned before, employees changing jobs have a start_date on the new job that is equal to the end_date of the old job. Why didn’t I use closed intervals instead, so Harold King was product director from 2010-07-01 to 2012-03-31 – both dates included?
It might seem easier to use closed intervals, so you can simplify your code a little by using between instead of >= and < – but there’s a problem. The date datatype can contain not only whole dates but also hours, minutes, and seconds. That means that with a closed interval end_date of 2012-03-31, Harold King would not be hired anymore at 1 second past midnight, and the entire day of March 31st, he would be out of a job until rehired April 1st at midnight.
“Easy,” you say, “just put an end_date of 2012-03-31 23:59:59, and all is well.” But is it? Possibly it’ll be OK, but what if you need to switch to a timestamp datatype in the future and support fractional seconds? (Probably not the case for hire periods, but you can easily imagine other use cases for this.)
By using half-open intervals instead for your date ranges, you will never have the problem that Harold King in principle is not hired for a short time (a day, a second, a microsecond – no matter how small, with the closed interval, there will always be a piece of time that is not covered by the ranges).
The start_date is the exact moment from which the row starts being active.
The end_date is the exact moment from which the row is no longer active (i.e., it ends being active immediately before that moment).
This thought process might have been helped by choosing column names like active_from and inactive_from, but the notion of start and end is just so commonly used that I’m doing the same.
Oracle itself has realized the usefulness of half-open intervals when they introduced temporal validity in version 12.1. So let me use this as a good opportunity for a brief detour and show you how temporal validity works. Afterward I’ll get back to the date range merging.
Temporal validity
Table defined with temporal validity
The interesting bit is line 8, which is the period for clause for defining temporal validity on the table.
In the parentheses, I’ve specified the two columns that contain the start and end point of the half-open interval. (These can be date or timestamp columns.) Both columns are allowed to be nullable; it is just for this use case I have set start_date to be not null as a job period will always have a specific starting point, whereas end_date allows nulls, because this means the job is still current.
If you do not specify the two columns, the database auto-creates two hidden columns to contain the interval. Normally I prefer to create the columns myself and specify them, but it might be handy if you have a use case where those who query are not interested in the actual interval, just whether the row is valid at a specific point in time or not.
Querying hire periods table as of a specific date
In the from clause lines 7–9, I can use an as of syntax very similar to flashback queries, with the table in line 7, the as of specification in line 8, and the table alias in line 9.
The query with as of is internally rewritten by the database into a regular where clause with suitable >= and < predicates; it is just easier to get it right with as of. Also the database treats it as a type of constraint – it will not let you insert data with an end_date that is before start_date.
This little aside showed you briefly how temporal validity can make things easier, and if you do use temporal validity, you’ll also automatically get the benefits of the half-open intervals. Now I’ll get back to the range merging, which you can do with or without temporal validity.
Merging overlapping ranges

Expected results after merging overlapping and adjoining date ranges
I am now going to attempt solving this with match_recognize. To demonstrate trying out different approaches and changing the logic along the way, I will first show some attempts that do not quite work, leading up to a working solution in the end.
Attempts comparing to the previous row
Comparing start_date to end_date of the previous row
My simple definition in line 21 states that a row is overlapping or adjoining if the start_date is smaller than or equal to the end_date of the previous row. A match is then found by the pattern in line 17 of any row followed by zero or more adjoining or overlapping rows.
But the output of, for example, Mogens Juel is not completely merged; there should have been a single row only for him with four jobs. The problem is that when I order his rows by start_date, the Code Tester and IT Manager rows are compared and not overlapping. A comparison like this to the previous row fails to discover that both rows are adjoining or overlapping to Sys Admin.
With the changed ordering, the first attempt at finding a match for Mogens Juel will try to compare the IT Technician row with the Code Tester row and fail to find an overlap.
No matter which ordering I choose, I cannot get all the overlaps in a single match by simply comparing a row to the previous row. I need a different way to handle this.
Better comparing to the maximum end date
Looking more closely on the rows of Mogens Juel in Figure 19-2, I decide that a better approach would be to compare the start_date of a row with the highest end_date that I have found so far in the match.
The reason it does not work is that when a definition condition like line 21 is evaluated, the row is first assumed to be classified adjoin_or_overlap, and then the condition is tested if it is true. Therefore the result of max(end_date) is calculated of all rows of the match so far plus the current row, which does not make sense.
In fact it makes so little sense that when I tested this first attempt, the query gave me either ORA-03113: end-of-file on communication channel or java.lang.NullPointerException depending on database version and which client I use. The database connection was then broken.
Comparing start_date of next row to highest end_date seen so far
I go back to ordering by start_date in line 10.
In line 21, I check if the start_date of the next row is less than or equal to the highest end_date seen so far in the match – including the current row, because the max call will assume the current row is part of the match when it is evaluated. That means that when a row is classified as adjoin_or_overlap, that row should be merged with the next row.
The pattern in line 17 looks for zero or more adjoin_or_overlap rows followed by one single row classified last_row. As that classification is undefined, any row can match it – but since the row before last_row was classified adjoin_or_overlap, I know that the last_row should be merged too.
If I find no adjoin_or_overlap rows, the row will become classified last_row because of the * in line 17 that says that zero adjoin_or_overlap rows are acceptable in the pattern. This means that when a row is not overlapping with any other rows, it will become a match of a single row classified as last_row and thus unmerged be part of the output.
The measure end_date in line 14 is calculated as the largest end_date of the match. Since I am not qualifying the end_date in the max call with either adjoin_or_overlap or last_row, max is applied to all rows of the match no matter what classification the rows got.

Can first row be classified as adjoin_or_overlap?

Can second row be classified as adjoin_or_overlap?

Can third row be classified as adjoin_or_overlap?

Can fourth row be classified as adjoin_or_overlap?

Fourth row classified as last_row and a match has been found
When the fourth row is not adjoin_or_overlap, the pattern in line 17 of Listing 19-6 states that it should be a last_row in order to complete the match. So Figure 19-8 evaluates if the fourth row can be classified last_row or not. As last_row is an undefined classification, it always evaluates to true, and the fourth row is therefore classified as last_row, and the match has been completed.
But I still have a couple of problems with this output.
Firstly several of the employees (including Mogens Juel) have a wrong value in the measure end_date. Those that are still employed should have null (blank) in the end_date column, and in this output that is only true for those with just a single hire period. For those that have had more than one job, the highest non-null end_date is wrongly displayed.
Secondly I notice that Zoe Thorston also has overlapping rows – the problem here is just that the end_date of both rows are null, meaning both rows are current and she has both job functions. With the null values, the simple comparison in line 21 of Listing 19-6 will not be true.
Both of these problems are because I am not handling the null values in end_date. This I will do now.
Handling the null dates
Handling null=infinity for both start and end
In line 10, I make the order by a bit more explicit. If there had been null values in start_date, these would be considered earlier than any other start_date, so I use nulls first to make those rows come first. Similarly null values in end_date are considered later than any other end_date, so I use nulls last to make those rows come last.
In comparisons I cannot simply use a nulls first to consider a null in start_date to be less than any other date, so in line 24, I turn a null into the smallest date possible in the Oracle date datatype.
The aggregate function max ignores null values, so in line 25, I turn a null in end_date into the largest date possible in a date.
To get a correct result in the end_date measure, I do the same nvl inside the max function in line 15. Then if the max results in the largest date, I use nullif in lines 14 and 16 to turn that back into null for output.
This output matches Figure 19-3, the result that I wanted.
Now I cannot merge any further – the rows of this output are all neither overlapping nor adjoining.
Lessons learned
This is just a single example of merging rows with date ranges in a report on employee job history, but it serves as inspiration and lesson to enable you to go ahead and do the same for other data.
The advantages of using half-open intervals for date ranges and how temporal validity can make it easier to query data with such intervals
Using match_recognize to compare maximum values with next row to find overlapping or adjoining ranges and merge them into aggregate rows
Expanding the rules to also handle situations where null indicates infinity
You’ll likely find many places you can use these methods.