
Sometimes you’d like to do aggregation where a row is included in multiple rows of the output, for example, being counted multiple times or having the value added multiple times. An example of this is hierarchical data, where you want for every row to find the count of all the children in the tree – not just immediate children but also grandchildren and their children and so on, all the way down to the leaves of the tree.
It means that a given row is counted in the result for the parent, but also counted again in the result of the grandparent, and so on. It can look similar to subtotals created with group by and rollup, but with the hierarchy, you don’t know how many levels down it goes, so you cannot simply use rollup.
One way I can solve this is using the after match skip to next row clause of match_recognize. Of course it could be used for other aggregates than count, but count is easy to understand, and once you know the technique, you can do the others easily.
Hierarchical tree of employees

The employees table with a self-referencing foreign key
A classic hierarchical query of employees
For a simple hierarchy like this, I tend to use the Oracle proprietary connect by query instead of the recursive subquery factoring I showed in Chapter 4. One of the things that are easier with connect by is, for example, the order siblings by I use here – that is more awkward to code with recursive subquery factoring.
It’s different persons, but you’re likely to have seen a very similar output using scott.emp somewhere. And this query will form the basis for the rest of the SQL I’ll show in this chapter.
Counting subordinates of all levels
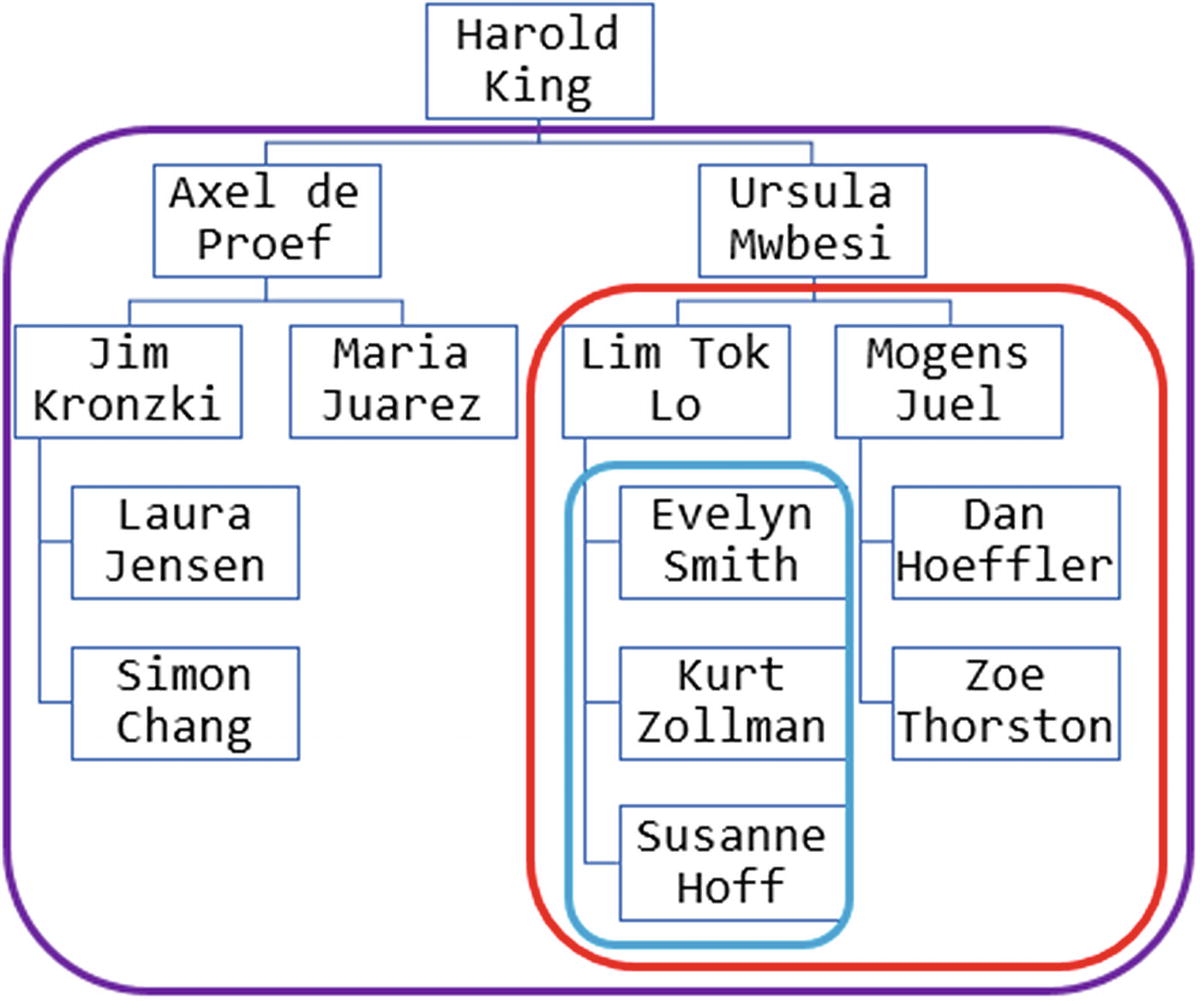
Organization diagram with some of the subtrees marked
Counting the number of subordinates
The output is just what I’m after, but I’ve accessed the same rows of the tables multiple times – like Simon Chang that has been accessed four times: once in the scalar subquery for each of the three people above him in the tree and then once in the main query when it got to him in the tree. Also every time a leaf node in the tree was accessed, the database queried if there was anyone below him/her, so the four times Simon was accessed also incurred four lookups if he had subordinates.
All in all, it is a lot of repetitive work for the database. But luckily I have a way to reduce that amount of work.
Counting with row pattern matching
Counting subordinates with match_recognize
I’m using a with clause for clarity as I taught you in Chapter 3.
Inside the with clause lines 5–10 is an inline view containing the basic hierarchical query I’ve already shown you in the previous listings. Notice the order by in line 10 is inside the inline view.
I place it in an inline view so that I can use rownum in line 3 (outside the inline view) and save it as column alias rn. I need to preserve the hierarchical ordering created by the inline view when I do my row pattern matching – this allows me to do so.
Building my match_recognize clause, I start by defining in line 32 that a row that has a higher level than the starting row of the pattern is classified as higher – meaning that when it has a higher level, then it is a child/grandchild/greatgrandchild/… of the starting row (i.e., a subordinate).
Of course, not everybody in the entire row set with a higher level is a subordinate – only those consecutive rows with a higher level that follow the row itself. Once I reach someone with the same level (or lower), then I am no longer within the subtree I want. I solve this in the pattern in line 29 by looking for a strt row (which is undefined and therefore can be any row) followed by zero or more higher rows – when a row is reached that is no longer classified higher, the match stops.
In line 26, I’ve specified one row per match, and the employee I’m interested in outputting data from is the strt row, so I’m using strt columns in the measures in lines 21–24.
In line 25, I’m doing a count on how many higher rows were in the match. If I just did a plain count(*), I’d be including the strt row, but on that row anything I qualify with higher will be null, so counting higher.lvl gives me a count only of the higher rows, which is the count of subordinates that I want.
With after match skip to next row in line 27, I’m specifying that once it has finished with a match of one strt row and zero or more higher rows, it should move to the next row that follows after the strt row. This is the part that makes rows be counted more than once – I’ll explain in detail shortly.
That’s all clear, right? Well, I’ll dive a little more into the details to clarify why it works.
A few words on why you’d consider using the long and somewhat convoluted Listing 22-3 instead of the short and clear Listing 22-2.
I tested this on an employee table where I had 14001 employees in it.
The scalar subquery method used about 11 seconds, nearly half a million consistent gets, and over 37000 sorts, due to a full table scan and many, many index range scans for the connect by processing.
The match_recognize method used less than half a second, 55 consistent gets, and four (four!) sorts, with just a single full table scan.
Your mileage will vary, of course, so test it yourself.
The details of each match
Inspecting the details with all rows per match
The match_number() function in line 28 is a consecutive numbering of the matches found. Without it, I couldn’t tell which rows in the output belongs together as part of each match.
The classifier() function shows what the row has been classified as according to the pattern and define clauses – in this case showing whether a row is strt or higher.
When column names are not qualified, values of the current row in the match are used, no matter what classifier they have. When I qualify the column names with the classifier strt and higher in lines 30 and 31, I get the values from the last of the rows with that classifier.
Aggregate functions like count in lines 32 and 33 can be running or final. In Listing 22-3, it did not matter, since I used one row per match, but here it does matter, so I output both to show the difference. Line 32 defaults to running (aka rolling count) which gives a result similar to an analytic function with a window of rows between unbounded preceding and current row, while line 33 with final keyword works similar to rows between unbounded preceding and unbounded following.
As my pattern matching is ordered by rn, it starts at rn = 1 (Harold) and classifies him strt (since any row can match strt) and then repeatedly checks if the next row has a lvl greater than the lvl of the strt row, which is true for all of the remaining 13 rows, as everybody else has a lvl greater than 1. That means that the first match does not stop until it reaches the end of the rows.
Match number 1 has now been found, containing 1 strt row and 13 higher rows as shown in the cls column. In the strt row, no higher rows have been found yet, so when I qualify a column with higher (and I am not using the final keyword), the result is null, as you can see in column hiname. This also means that when I do the total (final) count of higher in column subs, the strt row is not counted, and the result is the desired 13 subordinates.
You can also see in the output how the running total goes in column roll and that strt.name in column stname keeps the value of the last (in this case only) strt row.
After Axel as strt, this match finds four higher rows, because row rn = 7 (Ursula) has lvl = 2, which is not higher than Axel (it is the same), and therefore the match stops with Maria. The counting of subordinates works just like before – even though there are five rows in the match, there are only four that are classified higher and are counted. These rows were also included in the count of Harold King’s subordinates in match number 1, but because of skipping back up to rn = 2 to find the next match, these rows are included once more.
Match number 3 ends up with one strt row and just 2 higher rows, since Maria (who follows Simon in the rn order) does not have a lvl higher than Jim. So Laura and Simon are counted as Jim’s subordinates – just as they also were counted under Axel and under Harold.
Pivoting to show which rows are in which match
The only measure I am using is match_number() in line 27, and then in lines 19–22, I select just mn, rn, and the name. This allows me to do a pivot for mn in line 38 specifying the 14 match numbers in line 39, thereby getting rn, name, and 14 columns named 1–14 (these column names must be enclosed in double quotes, as they do not start with a letter).
In this pivoted output, it is easy to use the Xs to check that all rows are included in match number 1, the rows from Axel to Maria are included in match number 2, and so on.
Fiddling with the output
Having examined the detailed output, I’ll return to the one row per match version to fiddle a bit more and show you a couple of things.
Adding multiple measures when doing one row per match
So my first point was the use of multiple measures for whatever output I want in the various columns. Can I fiddle with the rows in the output as well? Say, for example, I want to output only those employees that actually have subordinates (or in other words are not leaf nodes in the tree).
Sure, I could put the entire query in an inline view and then use a where clause to filter on subs > 0 and that way not get any leaf nodes in the output. It would work fine, but my second point to show you is a better alternative that filters away the non-leaf nodes earlier in the processing.
In Listing 22-3 line 29, I’m using a pattern of strt higher* which is a pattern that by design will be matched by any row that will be classified strt – it is just a question of how many higher rows will follow after that strt row. So Listing 22-3 will by the nature of the pattern output all rows of the table.
Filtering matches with the pattern definition
Doing it this way allows the database to discard the unwanted rows immediately as it works its way through the pattern matching process – rather than the inline view that lets the database build a result set of all rows and then afterward removes the unwanted ones again.
Lessons learned
Preparing the source query by creating an ordering column that allows match_recognize to work in the hierarchical order
Setting a pattern that for each row finds the group of rows that are in the subtree below
Using after match skip to next row to use the pattern search on every row, even if it was included in previous matches
Changing the pattern to ignore those rows not having a subtree below
These methods you can use on any hierarchical data. They can also be useful on other data with an ordering that is nontrivial, where you can set up a more complex query to prepare the data and preserve the ordering, before you process the data with match_recognize.