
Societal Issues
Abstract
Big Data, even Big Data used in science, is a social endeavor. The future directions of Big Data will be strongly influenced by social, political, and economic forces. Will a culture of data sharing prevail? Will data managers collect, organize, and archive their data in a manner that promotes data integration? Will data analysts use Big Data to improve our lives?
Or shall Big Data create a dystopian world? Will governments use the power of the Internet to rewrite history, control public perceptions, and shape the future? These questions will be discussed in this final chapter.
Keywords
Open access; Open source; Data sharing; Data protection; Benefits; Long-term efforts; Costs; Infrastructure; Overconfidence
Section 20.1. How Big Data Is Perceived by the Public
The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge.
Stephen Hawking
Big Data, even the Big Data that we use in scientific pursuits, is a social endeavor. The future directions of Big Data will be strongly influenced by social, political, and economic forces. Will scientists archive their experimental data in publicly accessible Big Data resources? Will scientists adopt useful standards for their operational policies and their data? The answers depend on a host of issues related to funding source (e.g., private or public), cost, and perceived risks. How scientists use Big Data may provide the strongest argument for or against the public's support for Big Data resources.
The purposes of Big Data can be imagined as one of the following dramatic settings:
In this hypothesis, Big Data exists for private investigators, police departments, and snoopy individuals who want to screen, scrutinize, and invade the privacy of individuals, for their own purposes. There is basis in reality to support this hypothesis. Investigators, including the FBI, use Big Data resources, such as: fingerprint databases, DNA databases, legal records, air travel records, arrest and conviction records, school records, home ownership records, geneology trees, credit card transactions, financial transactions, tax records, census records, Facebook pages, tweets, emails, and sundry electronic residua. The modern private eye has profited from Big Data, as have law enforcement officers. It is unsettling that savvy individuals have used Big Data to harass, stalk, and breach the privacy of other individuals. These activities have left some individuals dreading future sanctioned or unsanctioned uses of big Data. On the up side, there is a real possibility that Big Data will serve to prevent crime, bring criminals to justice, and enhance the security of law-abiding citizens. The value of Big Data, as a method to reduce crime, has not fully engaged the public consciousness.
Modern governments obtain data from surveillance cameras and sophisticated eavesdropping techniques, and from a wide variety of information collected in the course of official operations. Much of the data collected by governments is mandated by law (e.g., census data, income tax data, birth certificates), and cannot be avoided. When a government sponsors Big Data collections, there will always be some anxiety that the Big Data resource will be used to control the public, reducing our freedoms of movement, expression, and thought. On the plus side, such population-wide studies may eventually reduce the incidence of terrorist attacks, confine the spread of epidemics and emerging diseases, increase highway safety, and improve the public welfare.
I assume that if you are reading this book on Big Data, you most likely are a Star Trek devotee, and understand fully that the Borg are a race of collectivist aliens who travel through galaxies, absorbing knowledge from civilizations encountered along the way. The conquered worlds are absorbed into the Borg “collective” while their scientific and cultural achievements are added to a Big Data resource. According to the Borg hypothesis, Big Data is the download of a civilization. Big Data analysts predict and control the activities of populations: how crowds move through an airport; when and where traffic jams are likely to occur; when political uprisings will occur; how many people will buy tickets for the next 3-D movie production. Resistance is futile.
The late great comedian, George Carlin, famously chided us for wasting our time, money, and consciousness on one intractable problem: “Where do we put all our stuff?” Before the advent of Big Data, electronic information was ephemeral; created and then lost. With cloud computing, and with search engines that encompass the Web, and with depositories for our personal data, Big Data becomes an infinite storage attic. Your stuff is safe, forever, and it is available to you when you need it.
When the ancient Sumerians recorded buy-sell transactions, they used clay tablets. They used the same medium for recording novels, such as the Gilgamesh epic. These tablets have endured well over 4000 years. To this day, scholars of antiquity study and translate the Sumerian data sets. The safety, availability and permanence of electronic “cloud” data is a claim that will be tested, over time. When we are all dead and gone, will our data persist for even a fraction of the time that the Sumerian tablets have endured?
Big Data is a collection of everything, created for the purpose of searching for individual items and facts. According to the Scavenger hunt hypothesis, Big Data is everything you ever wanted to know about everything. A new class of professionals will emerge, trained to find any information their clients may need, by mining Big Data resources. It remains to be seen whether the most important things in life will ever be found in Big Data resources.
The National Science Foundation has issued a program solicitation entitled Core Techniques and Technologies for Advancing Big Data Science & Engineering [1]. This document encapsulates the Egghead hypothesis of Big Data.
“The Core Techniques and Technologies for Advancing Big Data Science and Engineering (BIGDATA) solicitation aims to advance the core scientific and technological means of managing, analyzing, visualizing, and extracting useful information from large, diverse, distributed, and heterogeneous data sets so as to: accelerate the progress of scientific discovery and innovation; lead to new fields of inquiry that would not otherwise be possible; encourage the development of new data analytic tools and algorithms; facilitate scalable, accessible, and sustainable data infrastructure; increase understanding of human and social processes and interactions; and promote economic growth, improved health, and quality of life. The new knowledge, tools, practices, and infrastructures produced will enable breakthrough discoveries and innovation in science, engineering, medicine, commerce, education, and national security-laying the foundations for US competitiveness for many decades to come [1].”
The underlying assumption here is that people want to use their computers to interact with other people (i.e., make friends and contacts, share thoughts, arrange social engagements, give and receive emotional support, and memorialize their lives). Some might dismiss social networks as a ruse whereby humans connect with their computers, while disconnecting themselves from committed human relationships that demand self-sacrifice and compassion. Still, a billion members cannot all be wrong, and the data collected by social networks must tell us something about what humans want, need, dislike, avoid, love, and, most importantly, buy. The Facebook hypothesis is the antithesis of the Egghead hypothesis in that participants purposefully add their most private thoughts and desires to the Big Data collection so that others will recognize them as unique individuals.
According to some detractors, Big Data represents what we have always done, but with more data. This last statement, which is somewhat of an anti-hypothesis, is actually prevalent among quite a few computer scientists. They would like to think that everything they learned in the final decades of the 20th century will carry them smoothly through their careers in the 21st century. Many such computer scientists hold positions of leadership and responsibility in the realm of information management. They may be correct; time will either vindicate or condemn them.
Discourse on Big Data is hindered by the divergence of opinions on the nature of the subject. A proponent of the Nihilist hypothesis will not be interested in introspection, identifiers, semantics, or any of the Big Data issues that do not apply to traditional data sets. Proponents of the George Carlin hypothesis will not dwell on the fine points of Big Data analysis if their goal is limited to archiving files in the Big Data cloud. If you read blogs and magazine articles on Big Data, from diverse sources (e.g., science magazines, popular culture magazines, news syndicates, financial bulletins), you will find that the authors are all talking about fundamentally different subjects called by the same name; Big Data. [Glossary Semantics]
To paraphrase James Joyce, there are many sides to an issue; unfortunately, I am only able to occupy one of them. I closely follow the National Science Foundation's lead (vida supra). The focus for this chapter is the Egghead hypothesis; using Big Data to advance science.
Section 20.2. Reducing Costs and Increasing Productivity With Big Data
Every randomized clinical trial is an observational study on day two.
Ralph Horwitz
We tend to think of Big Data exclusively as an enormous source of data; for analysis and for fact-finding. Perhaps we should think of Big Data as a time-saver; something that helps us do our jobs more efficiently, and at reduced cost. It is easy to see how instant access to industry catalogs, inventory data, transaction logs, and communication records can improve the efficiency of businesses. It is less easy to see how Big Data can speed up scientific research, an endeavor customarily based on labor-intensive, and tedious experiments conducted by scientists and technicians in research laboratories. For many fields of science, the traditional approach to experimentation has reached its fiscal and temporal limits; the world lacks the money and the time to do research the old-fashioned way. Everyone is hoping for something to spark the next wave of scientific progress, and that spark may be Big Data.
Here is the problem facing scientists today. Scientific experiments have increased in scale, cost, and time, but the incremental progress resulting from each experiment is no greater today than it was fifty years ago. In the field of medicine, 50-year progress between 1910 and 1960 greatly outpaced progress between 1960 and 2010. Has society reached a state of diminishing returns on its investment in science?
By 1960, industrial science reached the level that we see today. In 1960, we had home television (1947), transistors (1948), commercial jets (1949), nuclear bombs (fission, fusion in 1952), solar cells (1954), fission reactors (1954), satellites orbiting the earth (Sputnik I, 1957), integrated circuits (1958), photocopying (1958), probes on the moon (Lunik II, 1959), practical business computers (1959), and lasers (1960). Nearly all the engineering and scientific advances that shape our world today were discovered prior to 1960.
These engineering and scientific advancements pale in comparison to the advances in medicine that occurred between 1920 and 1960. In 1921, we had insulin. Over the next four decades, we developed antibiotics effective against an enormous range of infectious diseases, including tuberculosis. Civil engineers prevented a wide range of common diseases using a clean water supply and improved waste management. Safe methods to preserve food, such as canning, refrigeration, and freezing saved countless lives. In 1941, Papanicolaou introduced the Pap smear technique to screen for precancerous cervical lesions, resulting in a 70% drop in the death rate from uterine cervical cancer, one of the leading causes of cancer deaths in women. By 1947, we had overwhelming epidemiologic evidence that cigarettes caused lung cancer. No subsequent advances in cancer research have yielded reductions in cancer death rates that are comparable to the benefits achieved with Pap smear screening and cigarette avoidance. The first polio vaccine and the invention of oral contraceptives came in 1954. By the mid 1950s, sterile surgical technique was widely practiced, bringing a precipitous drop in post-surgical and post-partum deaths. The great achievements in molecular biology, from Linus Pauling, James D. Watson, and Francis Crick, came in the 1950s.
If the rate of scientific accomplishment were dependent upon the number of scientists on the job, you would expect that progress would be accelerating, not decelerating. According to the National Science Foundation, 18,052 science and engineering doctoral degrees were awarded in the United States, in 1970. By 1997, that number had risen to 26,847, nearly a 50% increase in the annual production of the highest level scientists [2]. The growing work force of scientists failed to advance science at rates achieved in an earlier era; but not for lack of funding. In 1953, according to the National Science Foundation, the total United States expenditures on research and development was $5.16 billion, expressed in current dollar values. In 1998, that number has risen to $227 billion, greater than a 40-fold increase in research spending [2]. Most would agree that, over this same period, we have not seen a 40-fold increase in the rate of scientific progress.
Big Data provides a way to accelerate scientific progress by providing a large, permanent, and growing collection of data obtained from many different sources; thus sparing researchers the time and expense of collecting all of the data that they use, for very limited purposes, for a short span of time.
In the field of experimental medicine, Big Data provides researchers with an opportunity to bypass the expensive and time-consuming clinical trial process. With access to millions of medical records and billions of medical tests, researchers can find subpopulations of patients with a key set of clinical features that would qualify them for inclusion in narrowly focused, small trials [3]. The biological effects of drugs, and the long-term clinical outcomes, can sometimes be assessed retrospectively on medical records held in Big Data resources. The effects of drugs, at different doses, or in combination with other drugs, can be evaluated by analyzing large numbers of treated patients. Evaluations of drugs for optimal doses, and optical treatment schedule, in combination with other drugs, is something that simply cannot be answered by clinical trials (there are too many variables to control).
Perhaps the most important scientific application of Big Data will be as a validation tool for small data experiments. All experiments, including the most expensive prospective clinical trials, are human endeavors and are subject to all of the weaknesses and flaws that characterize the human behavior [4–6]. Like any human endeavor, experiments must be validated, and the validation of an experiment, if repeated in several labs, will cost more than the original study. Using Big Data, it may be feasible to confirm experimental findings based on a small, prospective studies, if the small-scale data is consistent with observations made on very large populations [7]. In some cases, confirmatory Big Data observations, though not conclusive in themselves, may enhance our ability to select the most promising experimental studies for further analysis. Moreover, in the case of drug trials, observations of potential side effects, non-responsive subpopulations, and serendipitous beneficial drug activities may be uncovered in a Big Data resource.
In the past, statisticians have criticized the use of retrospective data in drug evaluations. There are just too many biases and too many opportunities to reach valueless or misleading conclusions. Today, there is a growing feeling that we just do not have the luxury of abandoning Big Data. Using these large resources may be worth a try, if we are provided access to the best available data, and if our results are interpreted by competent analysts, and sensibly validated. Today, statisticians are finding opportunities afforded by retrospective studies for establishing causality, once considered the exclusive domain of prospective experiments [8–10]. One of the most promising areas of Big Data studies, over the next decade or longer, will be in the area of retrospective experimental design. The incentives are high. Funding agencies, and corporations should ask themselves, before financing any new and expensive research initiative, whether the study can be performed using existing data held in Big Data resources [11].
Section 20.3. Public Mistrust
Never attribute to malice that which is adequately explained by stupidity
Commonly attributed to Robert J. Hanlon, but echoed by countless others over the ages
Much of the reluctance to share data is based on mistrust. Corporations, medical centers, and other entities that collect data on individuals will argue, quite reasonably, that they have a fiduciary responsibility to the individuals whose data is held in their repositories. Sharing such data with the public would violate the privacy of their clients. Individuals agree. Few of us would choose to have our medical records, financial transactions, and the details of our personal lives examined by the public.
Recent campaigns have been launched against the “database state.” One such example is NO2ID, a British campaign against ID cards and a National Identify Register. Other anti-database campaigns include TheBigOptOut.org which campaigns against involuntary participation in the United Kingdom medical record database and LeaveThemKidsAlone, protesting fingerprinting in schools.
When the identifying information that links a personal record to a named individual is removed, then the residual data becomes disembodied values and descriptors. Properly deidentified data poses little or no threat to humans, but it has great value for scientific research. The public receives the benefits of deidentified medical data every day. This data is used to monitor the incidence and the distribution of cancer, detect emerging infectious diseases, plan public health initiatives, rationally appropriate public assistance funds, manage public resources, and monitor industrial hazards. Deidentified data collected from individuals provides objective data that describes us to ourselves. Without this data, society is less safe, less healthy, less smart, and less civilized.
Those of us who value our privacy and our personal freedom have a legitimate interest in restraining Big Data. Yet, we must admit that nothing comes free in this world. Individuals who receive the benefits of Big Data, should expect to pay something back. In return for contributing private records to Big Data resources, the public should expect resources to apply the strictest privacy protocols to their data. Leaks should be monitored, and resources that leak private data should be disciplined and rehabilitated. Non-compliant resources should be closed.
There are about a billion people who have Facebook accounts wherein they describe the intimate details of their lives. This private information is hanging in the cloud, to be aggregated, analyzed and put to all manner of trivial, commercial purposes. Yet, many of these same Facebook users would not permit their deidentified medical records to be used to save lives. It would be ideal if there were no privacy or confidentiality risks associated with Big Data. Unfortunately, zero-risk is not obtainable. However, it is technically possible to reduce the imagined risks of Big Data to something far below the known risks that we take with every electronic monetary transaction, every transfer of information, every move we make in public places, every click on our keyboards, and every tap on our smartphones. Brave new world!
Section 20.4. Saving Us From Ourselves
Man needs more to be reminded than instructed.
Samuel Johnson
Ever since computers were invented, there has been a push toward developing decision-making algorithms. The idea has been that computers can calculate better and faster than humans and can process more data than humans. Given the proper data and algorithms, computers can make better decisions than humans. In some areas, this is true. Computers can beat us at chess, they can calculate missile trajectories, and they can crack encryption codes. They can do many things better and faster than humans. In general the things that computers do best are the things that humans cannot do at all.
If you look over the past half century of computer history, computers have not made much headway in the general area of decision-making. Humans continue to muddle through their days, making their own decisions. We do not appoint computers to sit in juries, doctors seldom ask a computer for their diagnostic opinions, computers do not decide which grant applications receive funding, and computers do not design our clothing. Despite billions of dollars spent on research on artificial intelligence, the field of computer-aided decision-making has fallen short of early expectations [12–15]. It seems we humans still prefer to make our own mistakes, unassisted. [Glossary Artificial intelligence, Machine learning]
Although computers play a minor role in helping us make correct decisions, they can play a crucial role in helping us avoid incorrect decisions. In the medical realm, medical errors account for about 100,000 deaths and about a million injuries each year, in the United States [16]. Can we use Big Data to avoid such errors? The same question applies to driving errors, manufacturing errors, construction errors, and any realm where human errors have awful consequences.
It really does not make much sense, at this early moment in the evolution of computational machines, to use computers to perform tasks that we humans can do very well. It makes much more sense to use computers to prevent the kinds of errors that humans commit because we lack the qualities found in computers.
Here are a few examples wherein Big Data resources may reduce human errors:
As discussed at length in Section 3.4, “Really Bad Identifier Methods,” identification is a complex process that should involve highly trained staff, particularly during the registration process. Biometrics may help establish uniqueness (i.e., determining that an individual is not registered under another identifier) and authenticity (i.e., determining that an individual is who he claims to be). Computer evaluation of biometric data (e.g., fingerprints, iris imaging, retinal scan, signature, etc.) may serve as an added check against identification errors.
Data entry error rates are exceedingly common and range from about 2% of entries up to about 30% of entries, depending on various factors including the data type (e.g., numeric or textual) and length of the entry [17,18].
As society becomes more and more complex, humans become less and less capable of avoiding errors. Errors that have been entered into a data resource can be very difficult to detect and correct. A warning from a computer may help humans avoid making some highly regrettable entry errors. Probably the simplest, but most successful, example of a computational method to find entry errors is the check-digit. The check-digit (which can actually be several digits in length) is a number that is computed from a sequence (e.g., charge card number) and appended to the end of the sequence. If the sequence is entered incorrectly, the computed check digit will be different from the check-digit that had been embedded as a part of the original (correct) sequence. The check-digit has proven to be a very effective method for reducing data entry errors for identifiers and other important short sequences; and a wide variety of check-digit algorithms are available. [Glossary Checksum]
Spell-checkers are another example of software that finds data errors at the moment of entry. In fact, there are many opportunities for data scientists to develop methods that check for inconsistencies in human-entered data. If we think of an inconsistency as anything that differs from what we would expect to see, based on past experience, than Big Data resources may be the proper repository of “consistent” values with which inconsistencies can be detected.
Computer systems can suspend prescriptions for which doses exceed expected values, or for which known drug interactions contraindicate use, or for which abuse is suspected (e.g., multiple orders of narcotics from multiple physicians for a single patient). With access to every patient's complete electronic medical record, computers can warn us of idiosyncratic reactions that may occur, and the limits of safe dosages, for any particular patient. With access to biometric identifying information, computers can warn us when a treatment is about to be provided to the wrong patient. As an example, in operating rooms, computers can check that the screened blood components are compatible with the screened blood of the patient; and that the decision to perform the transfusion meets standard guidelines established by the hospital.
Computers can determine when all sensors report normally (e.g., no frozen o-rings), when all viewed subsystems appear normal (e.g., no torn heat shield tiles hanging from the hull), and when all systems are go (e.g., no abnormalities in the function of individual systems), and when the aggregate system is behaving normally (e.g., no conflicts between subsystems). Rockets are complex, and the job of monitoring every system for errors is a Big Data task.
It is thrilling to know that computers may soon be driving our cars, but most motor vehicle collisions could be prevented if we would simply eliminate from our roads those human drivers who are impaired, distracted, reckless, or otherwise indisposed to obeying the legal rules of driving. With everything we know about electronic surveillance, geopositioning technology, traffic monitoring, vehicle identification, and drug testing, you might think that we would have a method to rid the roads of poor drivers and thereby reduce motor vehicle fatalities. More than 32,000 people die each year from traffic accidents in the United States, and many more individuals are permanently disabled. Big Data technology could collect, analyze, and instantly react to data collected from highways; and it is easy to see how this information could greatly reduce the rate of motor vehicle deaths. What are we waiting for?
Section 20.5. Who Is Big Data?
The horizons of physics, philosophy, and art have of late been too widely separated, and, as a consequence, the language, the methods, and the aims of any one of these studies present a certain amount of difficulty for the student of any other of them.
Hermann L. F. Helmholtz, 1885 [19]
To get the most value from Big Data resources, will we need armies of computer scientists trained with the most advanced techniques in supercomputing? According to an industry report prepared by McKinsey Global Institute, the United States faces a current shortage of 140,000–190,000 professionals adept in the analytic methods required for Big Data [20]. The same group estimates that the United States needs an additional 1.5 million data-savvy managers [20].
Analysis is important; it would be good to have an adequate workforce of professionals trained in a variety of computationally-intensive techniques that can be applied to Big Data resources. Nevertheless, there is little value in applying advanced computational methods to poorly designed resources that lack introspection and data identification. A high-powered computer operated by a highly trained analyst cannot compensate for opaque or corrupted data. Conversely, when the Big Data resource is well designed, the task of data analysis becomes relatively straightforward.
At this time, we have a great many analytic techniques at our disposal, and we have open source software programs that implement these techniques. Every university offers computer science courses and statistics courses that teach these techniques. We will soon reach a time when there will be an oversupply of analysts, and an under-supply of well-prepared data. When this time arrives, there will be a switch in emphasis from data analysis to data preparation. The greatest number of Big Data professionals will be those people who prepare data for analysis.
Will Big Data create new categories of data professionals, for which there are currently no training programs? In the near future, millions of people will devote large portions of their careers toward the design, construction, operation, and curation of Big Data resources. Who are the people best equipped for these tasks?
Big Data does not self-assemble into a useful form. It must be designed before any data is collected. The job of designing a Big Data resource cannot be held by any single person, but a data manager (i.e., the person who supervises the project team) is often saddled with the primary responsibility of proffering a design or model of the resource. Issues such as what data will be included, where the data comes from, how to verify the data, how to annotate and classify the data, how to store and retrieve data, how to access the system, and a thousand other important concerns must be anticipated by the designers. If the design is bad, the Big Data resource will likely fail.
As discussed in Section 2.4, indexes help us find the data we need, quickly. The Google search engine is, at its heart, an index, built by the PageRank algorithm. Without indexers and the algorithms that organize data in a way that facilitates the kinds of searches that users are likely to conduct, Big Data would have very little appeal. The science of indexing is vastly underrated in universities, and talented indexers are hard to find. Indexers should be actively recruited into most Big Data projects.
It is impossible to sensibly collect and organize Big Data without having a deep understanding of the data domain. An effective data domain expert has an understanding of the kinds of problems that the data can help solve, and can communicate her knowledge to the other members of the Big Data project, without resorting to opaque jargon. The domain expert must stay current in her field and should regularly share information with other domain experts in her field and in fields that might be relatable to the project.
The most common mistake made by beginners to the metadata field is to create their own metadata tags to describe their data. Metadata experts understand that individualized metadata solutions produce Big Data than cannot be usefully merged with other data sets. Experts need to know the metadata resources that are available on the web, and they must choose metadata descriptors that are defined in permanent, accessible, and popular schemas. Such knowledge is an acquired skill that should be valued by Big Data managers.
As noted in Sections 5.6–5.8, it is almost impossible to create a good classification. Creating, maintaining, and improving a classification is a highly demanding skill, and classification errors can lead to disastrous results for a Big Data resource and its many users. Hence, highly skill taxonomists and ontologists are essential to any Big Data project.
Software programmers are nice to have around, but they have a tendency to get carried away with large applications and complex graphic user interfaces. Numerous examples shown throughout this book would suggest that most of the useful algorithms in Big Data are actually quite simple. Programmers who have a good working knowledge of many different algorithms, and who can integrate short implementations of these algorithms, as needed, within the framework of a Big Data Resource, are highly useful.
In many cases, Big Data projects can operate quite well using free and open source database applications. The primary purpose of programmers, in this case, often falls to making incremental additions and adjustments to the bare-bones system. As a general rule, the fewer the additions, the better the results. Programmers who employ good practices (e.g., commenting code, documenting changes, avoiding catastrophic interactions between the different modules of an application) can be more effective than genious-grade programmers who make numerous inscrutable system modifications before moving to a higher-paying job with your competitor.
Who is responsible for all this immutability that haunts every Big Data resource? Most of the burden falls upon the data curator. The word “curator” derives from the Latin, “curatus,” the same root for “curative” and conveys that curators fix things. In a Big Data resource the curator must oversee the accrual of sufficiently annotated legacy and prospective data into the resource; must choose appropriate nomenclatures for annotating the data; must annotate the data; and must supplement records with updated annotations as appropriate, when new versions of nomenclatures, specifications, and standards are applied. The curator is saddled with the almost impossible task of keeping current the annotative scaffold of the Big Data resource, without actually changing any of the existing content of records. In the absence of curation, all resources will eventually fail.
It all seems so tedious! Is it really necessary? Sadly, yes. Over time, data tends to degenerate: records are lost or duplicated, links become defunct, unique identifiers lose their uniqueness, the number of missing values increases, nomenclature terms become obsolete, mappings between terms coded to different standards become decreasingly reliable. As personnel transfer, quit, retire, or die, the institutional memory for the Big Data resource weakens. As the number of contributors to a Big Data resource increases, controlling the quality of the incoming data becomes increasingly difficult. Data, like nature, regresses from order to disorder; unless energy is applied to reverse the process. There is no escape; every reliable Big Data resource is obsessed with self-surveillance and curation.
In most instances the data manager is also the data project manager in charge of a team of workers. Her biggest contribution will involve creating a collegial, productive, and supportive working environment for their team members. The database manager must understand why components of Big Data resources, that are not found in smaller data projects (e.g., metadata, namespaces, ontologies, identifier systems, timestamps) are vital, and why the professionals absorbed in these exclusively Big Data chores are integral to the success of the projects. Team training is crucial in Big Data efforts, and the data manager must help each member of her team understand the roles played by the other members. The data manager must also understand the importance of old data and data permanence and data immutability.
Big Data seldom exists in a silo. Throughout this book, and only as a convenience, data is described as something that is conveyed in a document. In reality, data is something that streams between clouds. Network specialists, not discussed in any detail in this book, are individuals who know how to access and link data, wherever it may reside.
Security issues were briefly discussed in Section 18.3, “Data Security and Cryptographic Protocols.” Obviously, this important subject cannot be treated in any great depth in this book. Suffice it to say, Big Data requires the services of security experts whose knowledge is not confined to the type of encryption protocols described earlier. Data security is more often a personnel problem than a cryptographic puzzle. Breaches are likely to arise due to human carelessness (i.e., failure to comply with security protocols) or from misuse of confidential information (i.e., carrying around gigabytes of private information on a personal laptop, or storing classified documents at home). Security experts, skilled in the technical and social aspects of their work, fulfill an important role.
What do we really know about the measurements contained in Big Data resources? How can we know what these measurements mean, and whether they are correct? Data managers approach these questions with three closely related activities: data verification, data reproducibility, and validation. As previously mentioned, verification is the process that ensures that data conforms to a set of specifications. As such, it is a pre-analytic process (i.e., done on the data, before it is analyzed). Data reproducibility involves getting the same measurement over and over when you perform the test properly. Validation involves showing that correct conclusions were obtained from a competent analysis of the data. The primary purpose of data validators is to show that the scientific conclusions drawn from a Big Data resource are trustworthy and can be used as the foundation for other studies. The secondary purpose of data validators is to determine when the conclusions drawn from the data are not trustworthy, and to make recommendations that might rectify the situation.
Most data analysts carry a set of methods that they have used successfully, on small data problems. No doubt, they will apply the same methods to Big Data, with varying results. The data analysts will be the ones who learn, from trial and error, which methods are computationally impractical on large sets of data, which methods provide results that have no practical value, which methods are unrepeatable, and which methods cannot be validated. The data analysts will also be the ones who try new methods and report on their utility. Because so many of the analytic methods on Big Data are over-hyped, it will be very important to hire data analysts who are objective, honest, and resistant to bouts of hubris.
Arguably the most essential new professional is the “generalist problem solver,” a term that describes people who have a genuine interest in many different fields, a naturally inquisitive personality, and who have a talent for seeing relationships where others do not. The data held in Big Data resources becomes much more valuable when information from different knowledge domains lead to unexpected associations that enlighten both fields (e.g., veterinary medicine and human medicine, bird migration and global weather patterns, ecologic catastrophes and epidemics of emerging diseases, political upheaval and economic cycles, social media activity and wages in African nations). For these kinds of efforts, someone needs to create a new set of cross-disciplinary questions that could not have been asked prior to the creation of Big Data resources.
Historically, academic training narrows the interests of students and professionals. Students begin their academic careers in college, where they are encouraged to select a major field of study as early as their freshman year. In graduate school, they labor in a sub-discipline, within a rigidly circumscribed department. As postdoctoral trainees, they narrow their interests even further. By the time they become tenured professors, their expertise is so limited that they cannot see how other fields relate to their own studies. The world will always need people who devote their professional careers to a single sub-discipline, to the exclusion of everything else, but the future will need fewer and fewer of these specialists [21]. My experience has been that cross-disciplinary approaches to scientific problems are very difficult to publish in scientific journals that are, with few exceptions, devoted to one exclusive area of research. When a journal editor receives a manuscript that employs methods from another discipline, the editor usually rejects the paper, indicating that it belongs in some other journal. Even when the editor recognizes that the study applies to a problem within the scope of the journal, the editor would have a very difficult time finding reviewers who can evaluate a set of methods from another field. To get the greatest value from Big Data resources, it is important to understand when a problem in one field has an equivalence to a problem from another field. The baseball analyst may have the same problem as the day trader; the astrophysicist may have the same problem as the chemist. We need to have general problem solvers who understand how data from one resource can be integrated with the data from other resources, and how problems from one field can be generalized to other fields, and can be answered with an approach that combines data and methods from several different disciplines. It is important that universities begin to train students as problem solvers, without forcing them into restrictive academic departments.
In the 1980s, as the cost of computers plummeted, and desktop units were suddenly affordable to individuals, it was largely assumed that all computer owners would become computer programmers. At the time, there was nothing much worth doing with a computer other than programming and word processing. By the mid-1990s, the Internet grabbed the attention of virtually every computer owner. Interest in programming languages waned, as our interest in social media and recreational uses of the computer grew. It is ironic that we find ourselves inundated with an avalanche of Big Data, just at the time that society, content with online services provided by commercial enterprises, have traded their computers for smartphones. Scientists and other data users will find that they cannot do truly creative work using proprietary software applications. They will always encounter situations wherein software applications fail to meet their exact needs. In these cases it is impractical to seek the services of a full-time programmer.
Today, programming is quite easy. Within a few hours, motivated students can pick up the rudiments of popular scripting languages such as Python, Perl, Ruby and R. With few exceptions, the scripts needed for Big Data analysis are simple and most can be written in under 10 lines of code [22–25]. It is not necessary for Big Data users to reach the level of programming proficiency held by professional programmers. For most scientists, programming is one of those subjects for which a small amount of training preparation will usually suffice. I would strongly urge scientists to return to their computational roots and to develop the requisite skills for analyzing Big Data.
There will be a need for professionals to develop strategies for reducing the computational requirements of Big Data and for simplifying the way that Big Data is examined. For example, the individuals who developed the CODIS DNA identification system (discussed in Section 17.4, “Case Study: Scientific Inferencing from a Database of Genetic Sequences”) relieved forensic analysts from the prodigious task of comparing and storing, for each sampled individual, the 3 billion base pairs that span the length of the human genome. Instead, a selection of 13 short sequences can suffice to identify individual humans. Likewise, classification experts drive down the complexity of their analyses by focusing on data objects that belong to related classes with shared and inherited properties. Similarly, data modelers attempt to describe complex systems with mathematical expressions, with which the behavior of the system can be predicted when a set of parameters are obtained. Experts who can extract, reduce, and simplify Big Data will be in high demand and will be employed in academic centers, federal agencies and corporations.
Often, all that is needed to make an important observation is a visualized summary of data. Luckily, there are many data visualization tools that are readily available to today's scientists. Examples of simple data plots using matplotlib (a Python module) or Gnuplot (an open source application that can be called from the command line) have been shown. Of course, Excel afficionados have, at their disposal, a dazzling number of ways with which they can display their spreadsheet data. Regardless of your chosen tools, anyone working with data should become adept at transforming raw data into pictures.
Big Data freelancers are self-employed professionals who have the skills to unlock the secrets that lie within Big Data resources. When they work under contract for large institutions and corporations, they may be called consultants, or freelance analysts. When they sell their data discoveries on the open market, they may be called entrepreneurial analysts. They will be the masters of data introspection, capable of quickly determining whether the data in a resource can yield the answers sought by their clients. Some of these Big Data freelancers will have expertise limited to one or several Big Data resources; expertise that may have been acquired as a regular employee of an institution or corporation, in the years preceding his or her launch into self-employment. Freelancers will have dozens, perhaps hundreds, of small utilities for data visualization and data analysis. When they need assistance with a problem, the freelancer might enlist the help of fellow freelancers. Subcontracted alliances can be arranged quickly, through Internet-based services. The need for bricks-and-mortar facilities, or for institutional support, or for employers and supervisors, will diminish. The freelancer will need to understand the needs of his clients and will be prepared to help the client redefine their specific goals, within the practical constraints imposed by the available data. When the data within a resource is insufficient, the freelancer would be the best person to scout alternate resources. Basically, freelance analysts will live by their wits, exploiting the Big Data resources for the benefit of themselves and their clients.
As public data becomes increasingly available, there will be an opportunity for everyone to participate in the bounty. See Section 20.7, “Case Study: The Citizen Scientists”.
Section 20.6. Hubris and Hyperbole
Intellectuals can tell themselves anything, sell themselves any bill of goods, which is why they were so often patsies for the ruling classes in nineteenth-century France and England, or twentieth-century Russia and America.
Lillian Hellman
A Forbes magazine article, published in 2015, running under the title, “Big Data: 20 Mind-Boggling Facts Everyone Must Read,” listed some very impressive “facts,” including that claim that more data has been created in the past two years than in all of prior history [26]. Included in the article was the claim that by the year 2020, the accumulated data collected worldwide will be about 44 zettabytes (44 trillion gigabytes). The author wrote, as one of his favorite facts, “At the moment less than 0.5% of all data is ever analyzed and used, just imagine the potential here” [26].
Of course, it is impossible to either verify or to discredit such claims, but experience would suggest that only a small percentage of the data that is collected today is worth the serious attention of data analysts. It is quite rare to find data that has been annotated with even the most minimal information required to conduct credible scientific research. These minimal annotations, as discussed previously, would be the name of the data creator, the owner of the data, the legal restraints on the usage of the data, the date that the data was created, the protocols by which the data was measured and collected, identifiers for data objects, class information on data objects, and metadata describing data within data objects. If you have read the prior chapters, you know the drill.
Make no mistake, despite the obstacles and the risks, the potential value of Big Data is inestimable. A hint at future gains from Big Data comes from the National Science Foundation's (NSF) 2012 solicitation for grants in core techniques for Big Data. The NSF envisions a Big Data future with the following pay-offs [1]:
- – “Responses to disaster recovery empower rescue workers and individuals to make timely and effective decisions and provide resources where they are most needed;
- – Complete health/disease/genome/environmental knowledge bases enable biomedical discovery and patient-centered therapy; The full complement of health and medical information is available at the point of care for clinical decision-making;
- – Accurate high-resolution models support forecasting and management of increasingly stressed watersheds and ecosystems;
- – Access to data and software in an easy-to-use format are available to everyone around the globe;
- – Consumers can purchase wearable products using materials with novel and unique properties that prevent injuries;
- – The transition to use of sustainable chemistry and manufacturing materials has been accelerated to the point that the US leads in advanced manufacturing;
- – Consumers have the information they need to make optimal energy consumption decisions in their homes and cars;
- – Civil engineers can continuously monitor and identify at-risk man-made structures like bridges, moderate the impact of failures, and avoid disaster;
- – Students and researchers have intuitive real-time tools to view, understand, and learn from publicly available large scientific data sets on everything from genome sequences to astronomical star surveys, from public health databases to particle accelerator simulations and their teachers and professors use student performance analytics to improve that learning; and
- – Accurate predictions of natural disasters, such as earthquakes, hurricanes, and tornadoes, enable life-saving and cost-saving preventative actions.”
Lovely. It would seem that there is nothing that cannot be accomplished with Big Data!
I know lots of scientists; the best of them lack self-confidence. They understand that their data may be flawed, their assumptions may be wrong, their methods might be inappropriate, their conclusions may be unrepeatable, and their most celebrated findings may one day be discredited. The worst scientists are just the opposite; confident of everything they do, say, or think [27].
The sad fact is that, among scientific disciplines, Big Data is probably the least reliable, providing major opportunities for blunders. Prior chapters covered limitations in measurement, data representation, and methodology. Some of the biases encountered in every Big Data analysis were covered in Chapter 14, “Special Considerations in Big Data Analysis.” Apart from these limitations lies the ever-present dilemma that assertions based on Big Data analyses can sometimes be validated, but they can never be proven true. Confusing validation with proof is a frequently encountered manifestation of overconfidence. If you want to attain proof, you must confine your interests to pure mathematics. Mathematics is the branch of science devoted to truth. With math, you can prove that an assertion is true, you can prove that an assertion is false, you can prove that an assertion cannot be proven to be true or false. Mathematicians have the monopoly on proving things. None of the other sciences have the slightest idea what they're doing when it comes to proof.
In the non-mathematical sciences, such as chemistry, biology, medicine, and astronomy, assertions are sometimes demonstrably valid (true when tested), but assertions never attain the level of a mathematical truth (proven that it will always be true, and never false, forever). Nonetheless, we can do a little better than showing that an assertion is simply valid. We can sometimes explain why an assertion ought to be true for every test, now and forever. To do so, an assertion should have an underlying causal theory that is based on interactions of physical phenomena that are accepted as true. For example, F = ma ought to be true, because we understand something about the concepts of mass and acceleration, and we can see why the product of mass and acceleration produce a force. Furthermore, everything about the assertion is testable in a wide variety of settings.
Big Data analysts develop models that are merely descriptive (e.g., predicting the behavior of variables in different settings), without providing explanations in terms of well-understood causal mechanisms. Trends, clusters, classes, and recommenders may appear to be valid over a limited range of observations; but may fail miserably in tests conducted over time, with a broader range of data. Big Data analysts must always be prepared to abandon beliefs that are not actually proven [21].
Finance has eagerly entered the Big Data realm, predicting economic swings, stock values, buyer preferences, the impact of new technologies, and a variety of market reactions, all based on Big Data analysis. For many financiers, accurate short-term predictions have been followed, in the long-run, with absolutely ruinous outcomes. In such cases, the mistake was overconfidence; the false belief that their analyses will always be correct [28].
In my own field of concentration, cancer research, there has been a major shift of effort away from small experimental studies toward large clinical trials and so-called high-throughput molecular methods that produce vast arrays of data. This new generation of cancer research costs a great deal in terms of manpower, funding, and the time to complete a study. The funding agencies and the researchers are confident that a Big Data approach will work where other approaches have failed. Such efforts may one day lead to the eradication of cancer; who is to say? In the interim, we have already seen a great deal of time and money wasted on huge, data-intensive efforts that have produced predictions that are not reproducible, with no more value than a random throw of dice [4,29–32].
Despite the limitations of Big Data, the creators of Big Data cannot restrain their enthusiasm. The following is an announcement from the National Human Genome Research Institute concerning their own achievements [33]:
“In April 2003, NHGRI celebrated the historic culmination of one of the most important scientific projects in history: the sequencing of the human genome. In addition, April 2003 marked the 50th anniversary of another momentous achievement in biology: James Watson and Francis Crick's Nobel Prize winning description of the DNA double helix” and “To mark these achievements in the history of science and medicine, the NHGRI, the NIH and the DOE held a month-long series of scientific, educational, cultural and celebratory events across the United States.”
In the years following this 2003 announcement, it has become obvious that the genome is much more complex than previously thought, that common human diseases are genetically complex, that the genome operates through mechanisms that cannot be understood by examining DNA sequences, and that much of the medical progress expected from the Human Genome Project will not be forthcoming anytime soon [29,34,35]. In a 2011 article, Eric Lander, one of the luminaries of the Human Genome Project, was quoted as saying, “anybody who thought in the year 2000 that we'd see cures in 2010 was smoking something” [35]. Monica Gisler and co-workers have hypothesized that large-scale projects create their own “social bubble,” inflating the project beyond any rational measure [36]. It is important that Big Data proselytizers, myself included, rein in their enthusiasm.
Section 20.7. Case Study: The Citizen Scientists
There is no reason why someone would want a computer in their home.
Ken Olson, President and founder of Digital Equipment Corporation, in 1977.
In a sense, we have reached a post-information age. At this point, we have collected an awful lot of information, and we all have access too much more information than we can possibly analyze within our lifetimes. In fact, all the professional scientists and data analysts who are living today could not possibly exhaust the information available to anyone with Internet access. If we want to get the most out of the data that currently resides within our grasps, we will need to call upon everyone's talents, including amateurs. Lest we forget, every professional scientist enters the ranks of the amateur scientists on the day that he or she retires. Today, the baby boomer generation is amassing an army of well-trained scientists who are retiring into a world that provides them with unfettered access to limitless data. Hence, we can presume that the number of amateur scientists will soon exceed the number of professional scientists.
Historically, some of the greatest advancements in science have come from amateurs. For example, Antonie van Leeuwenhoek (1632–1723), one of the earliest developers of the compound microscope, who is sometimes credited as the father of microbiology, was a janitor. Augustin-Jean Fresnel (1788–1827) was a civil engineer who found time to make significant and fundamental contributions to the theory of wave optics. Johann Jakob Balmer (1825–1898) earned his living as a teacher in a school for girls while formulating the mathematical equation describing the spectral emission lines of hydrogen. His work, published in 1885, led others, over the next four decades, to develop the new field of quantum mechanics. Of course, Albert Einstein was a paid patent clerk and an amateur physicist who found time, in 1905, to publish three papers that forever changed the landscape of science.
In the past few decades a wealth of scientific resources has been made available to anyone with Internet access. Many of the today's most successful amateurs are autodidacts with access to Big Data [37–42]. Here are a few examples:
In the field of medicine, some of the most impressive data mining feats have come from individuals affected by rare diseases who have used publicly available resources to research their own conditions.
Jill Viles is a middle-aged woman who, when she was a college undergraduate, correctly determined that she was suffering from Emery-Dreifuss muscular dystrophy. The diagnosis of this very rare form of muscular dystrophy was missed by her physicians. After her self-diagnosis was confirmed, she noticed that her father, who had never been told he had any muscular condition, had a distribution of his muscle mass that was suggestive of Emery-Dreifuss. Jill's suspicions initiated a clinical consultation indicating that her father indeed had a mild form of the same disorder and that his heart had been affected. Her father received a needed pacemaker, and Jill's shrewd observations were credited with saving her father's life. Jill pursued her interest in her own condition and soon became one of the early beneficiaries of genome sequencing. A mutation of the lamin gene was apparently responsible for her particular variant of Emery-Dreifuss muscular dystrophy. Jill later realized that in addition to Emery-Dreifuss muscular dystrophy, she also exhibited some of the same highly distinctive features of partial lipodystrophy, a disease characterized by a decrease in the fat around muscles. When the fat around muscles is decreased, the definition of the muscles (i.e., the surface outline of musculature) is enhanced. She reasoned, correctly, that the lamin gene, in her case, was responsible for both conditions (i.e., Emery-Dreifuss muscular dystrophy and partial lipodystrophy).
Jill's story does not end here. While looking at photographs of Priscilla Lopes-Schlief, an Olympic athlete known for her hypertrophied muscles, Jill noticed something very peculiar. The athlete had a pattern of fat-deficient muscle definition on her shoulders, arms, hips, and butt, that was identical to Jill's; the difference being that Priscilla's muscles were large, and Jill's muscles were small. Jill contacted the Olympian, and the discussions that followed eventually led to Priscilla's diagnosis of lipodystrophy due to a mutation on the lamin gene, at a locus different from Jill's. Lipodystrophy can produce a dangerous elevation in triglycerides, and Priscilla's new diagnosis prompted a blood screen for elevated lipids. Priscilla had high levels of triglyceride, requiring prompt treatment. Once again, Jill had made a diagnosis that was missed by physicians, linked the diagnosis to a particular gene and uncovered a treatable and overlooked secondary condition (i.e., hypertriglyceridemia). And it was all done by an amateur with Internet access [43]!
Jill Viles' story is not unique. Kim Goodsell, a patient with two rare diseases, Charcot-Marie-Tooth disease and arrhythmogenic right ventricular cardiomyopathy, searched the available gene datasets until she found a single gene that might account for both of her conditions. After much study, she determined that a point mutation in the LMNA gene was the most likely cause of her condition. Kim paid $3000 for gene sequencing of her own DNA, and a rare point mutation on LMNA was confirmed to be responsible for her dual afflictions [44]. In Kim's case, as in Jill's case, a persistent and motivated amateur can be credited with a significant advance in the genetics of human disease.
The International Space/Earth Explorer 3 (ISEE-3) spacecraft was launched in 1978 and proceeded on a successful mission to monitor the interaction between the solar wind and the earth's magnetic field. In 1985, ISEE-3 visited the comet Giacobini-Zinner, and was thereupon given a new name, ICE (the International Cometary Explorer). In 1999 NASA, short of funds, decommissioned ICE. In 2008, NASA tried to contact ICE and found that all but one of its 13 observational experiments were still in operation, and that the spacecraft had not yet exhausted its propellant.
In April 2014, a citizens group of interested scientists and engineers announced their intention to reboot ICE [38]. In May, 2014, NASA entered into a Non-Reimbursable Space Act Agreement with the citizen group, which would provide the reboot team with NASA advisors, but no funding. Later in May, the team successfully commanded the probe to broadcast its telemetry (i.e., its recorded data). In September, the team lost contact with ICE. ICE will return to a near-earth position, in 17 years (Fig. 20.1). There is reason to hope that scientists will eventually recover ICE telemetry, and, with it, find new opportunities for data analysis [45].
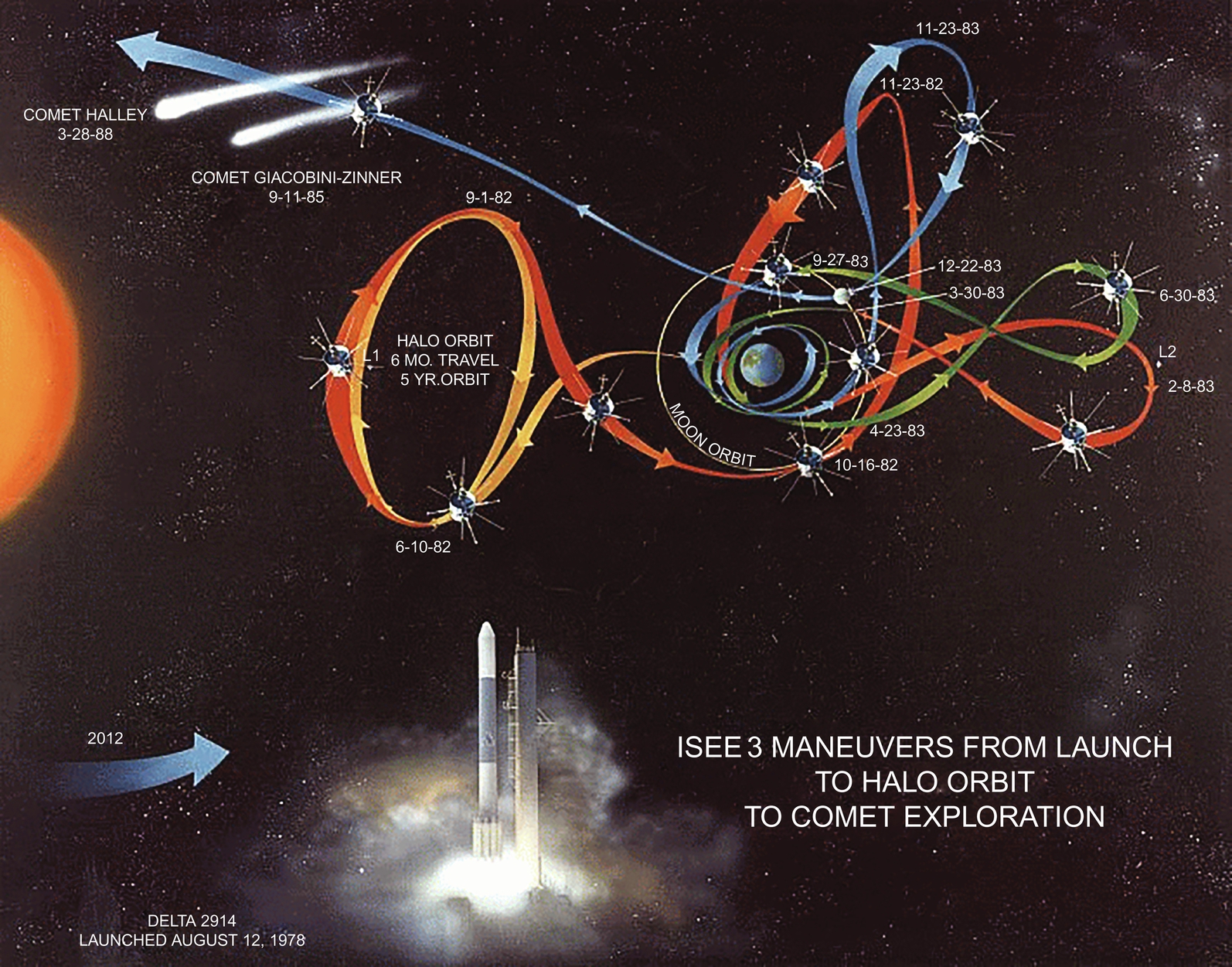
In the past, the term “amateurish” was used to describe products that are unprofessional and substandard. In the realm of Big Data, where everyone has access to the same data, amateurs and professionals can now compete on a level playing field. To their credit, amateurs are unsullied by the kind of academic turf battles, departmental jealousies, and high-stakes grantsmanship ploys that produce fraudulent, misleading, or irreproducible results [46]. Because amateurs tend to work with free and publicly available data sets, their research tends to be low-cost or no-cost. Hence, on a cost-benefit analysis, amateur scientist may actually have more value, in terms of return on investment, than professional scientists. Moreover, there are soon to be many more amateur scientists than there are professionals, making it likely that these citizen scientists, who toil for love, not money, will achieve the bulk of the breakthroughs that come from Big Data science. Of course, none of these breakthroughs, from citizen scientists, would be possible without free and open access to Big Data resources.
Section 20.8. Case Study: 1984, by George Orwell
He who controls the past controls the future.
George Orwell
When you have access to Big Data, you feel liberated; when Big Data has access to you, you feel enslaved. Everyone is familiar with the iconic image, from Orwell's 1984, of a totalitarian government that spies on its citizens from telescreens [47]. The ominous phrase, “Big Brother is watching you,” evokes an important thesis of Orwell's masterpiece; that an evil government can use an expansive surveillance system to crush its critics.
Lest anyone forget, Orwell's book had a second thesis, that was, in my opinion, more insidious and more disturbing than the threat of governmental surveillance. Orwell was concerned that governments could change the past and the present by inserting, deleting, and otherwise distorting the information available to citizens. In Orwell's 1984, previously published reports of military defeats, genocidal atrocities, ineffective policies, mass starvation, and any ideas that might foment unrest among the proletariat, were deleted and replaced with propaganda pieces. Such truth-altering activities were conducted undetected, routinely distorting everyone's perception of reality to suit a totalitarian agenda. Aside from understanding the dangers in a surveillance-centric society, Orwell was alerting us to the dangers inherent with mutable Big Data.
Today, our perception of reality can be altered by deleting or modifying electronic data distributed via the Internet. In 2009, Amazon was eagerly selling electronic editions of a popular book, much to the displeasure of the book's publisher. Amazon, to mollify the publisher, did something that seemed impossible. Amazon retracted the electronic books from the devices of readers who had already made their purchase. Where there was once a book on a personal eBook reader, there was now nothing. Amazon rectified their action by crediting customer accounts for the price of the book. So far as Amazon and the publisher were concerned, the equilibrium of the world was restored [48].
The public reaction to Amazon's vanishing act was a combination of bewilderment (“What just happened?”), shock (“How was it possible for Amazon to do this?”), outrage (“That book was mine!”), fear (“What else can they do to my eBook reader?”), and suspicion (“Can I ever buy another eBook?”). Amazon quickly apologized for any misunderstanding and promised never to do it again.
To add an element of irony to the episode, the book that was bought, then deleted, to suit the needs of a powerful entity, was George Orwell's 1984.
One of the purposes of this book is to describe the potential negative consequences of Big Data when data is not collected ethically, prepared thoughtfully, analyzed openly, or subjected to constant public review and correction. These lessons are important because the future reality of our Big Data universe will be determined by some of the people who are reading this book today.
Glossary
Artificial intelligence Artificial intelligence is the field of computer science that seeks to create machines and computer programs that seem to have human intelligence. The field of artificial intelligence sometimes includes the related fields of machine learning and computational intelligence. Over the past few decades, the term “artificial intelligence” has taken a battering from professionals inside and outside the field, for good reasons. First and foremost is that computers do not think in the way that humans think. Though powerful computers can now beat chess masters at their own game, the algorithms for doing so do not simulate human thought processes. Furthermore, most of the predicted benefits from artificial intelligence have not come to pass, despite decades of generous funding. The areas of neural networks, expert systems, and language translation have not met expectations. Detractors have suggested that artificial intelligence is not a well-defined sub discipline within computer science as it has encroached into areas unrelated to machine intelligence, and has appropriated techniques from other fields, including statistics and numerical analysis. Some of the goals of artificial intelligence have been achieved (e.g., speech-to-text translation), and the analytic methods employed in Big Data analysis should be counted among the enduring successes of the field.
Checksum An outdated term that is sometimes used synonymously with one-way hash or message digest. Checksums are performed on a string, block or file yielding a short alphanumeric string intended to be specific for the input data. Ideally, If a single bit were to change, anywhere within the input file, then the checksum for the input file would change drastically. Checksums, as the name implies, involve summing values (typically weighted character values), to produce a sequence that can be calculated on a file before and after transmission. Most of the errors that were commonly introduced by poor transmission could be detected with checksums. Today, the old checksum algorithms have been largely replaced with one-way hash algorithms. A checksum that produces a single digit as output is referred to as a check digit.
Machine learning Refers to computer systems and software applications that learn or improve as new data is acquired. Examples would include language translation software that improves in accuracy as additional language data is added to the system, and predictive software that improves as more examples are obtained. Machine learning can be applied to search engines, optical character recognition software, speech recognition software, vision software, neural networks. Machine learning systems are likely to use training data sets and test data sets.
Semantics The study of meaning. In the context of Big Data, semantics is the technique of creating meaningful assertions about data objects. A meaningful assertion, as used here, is a triple consisting of an identified data object, a data value, and a descriptor for the data value. In practical terms, semantics involves making assertions about data objects (i.e., making triples), combining assertions about data objects (i.e., merging triples), and assigning data objects to classes; hence relating triples to other triples. As a word of warning, few informaticians would define semantics in these terms, but I would suggest that most definitions for semantics would be functionally equivalent to the definition offered here.