
![]()
Networking, I/O, and Serialization
Most of this book focuses on optimizing computational aspects of application performance. We have seen numerous examples, such as tuning garbage collection, parallelizing loops and recursive algorithms, and even by coming up with better algorithms to reduce runtime costs.
For some applications, optimizing only the computational aspect results in limited performance gains, because the performance bottleneck lies in I/O work, such as network transfers or disk accesses. In our experience, a considerable portion of performance problems encountered in the field is not caused by an unoptimized algorithm or excessive CPU utilization, but is due to an inefficient utilization of the system’s I/O devices. Let us consider two scenarios in which optimizing I/O can result in performance gains:
- An application might incur a significant computational (CPU) overhead due to inefficient use of I/O, which comes at the expense of useful work. Worse, this overhead might be so high that it becomes the limiting factor to realizing the full potential capacity of the I/O device.
- The I/O device might be under-utilized or its capacity is wasted because of inefficient usage patterns, such as making many small I/O transfers or by failing to keep the channel fully utilized.
This chapter discusses strategies for improving I/O performance in general and network I/O performance in particular. In addition, we cover serialization performance and compare several serializers.
This section explores I/O concepts and provides performance guidelines pertaining to I/O of any kind. This advice is applicable to networking applications, heavy disk-accessing processes, and even software designed to access a custom high-bandwidth hardware device.
Synchronous and Asynchronous I/O
With synchronous I/O, the I/O transfer function (e.g. ReadFile, WriteFile, or DeviceIoControl Win32 API functions) blocks until the I/O operation completes. Although this model is convenient to use, it is not very efficient. During the time between issuing successive I/O requests, the device may be idle and, therefore, is potentially under-utilized. Another problem with synchronous I/O is that a thread is “wasted” for each concurrently pending I/O request. For example, in a server application servicing many clients concurrently, you may end up creating a thread per session. These threads, which are essentially mostly idle, are wasting memory and may create a situation called thread thrashing in which many threads wake up when I/O completes and compete with each other for CPU time, resulting in many context switches and poor scalability.
The Windows I/O subsystem (including device drivers) is internally asynchronous – execution of program flow can continue while an I/O operation is in progress. Almost all modern hardware is asynchronous in nature as well and does not need polling to transfer data or to determine if an I/O operation is complete. Most devices instead rely on Direct Memory Access (DMA) controllers to transfer data between the device and the computer RAM, without requiring the CPU’s attention during the transfer, and then raise an interrupt to signal completion the data transfer. It is only at the application level that Windows allows synchronous I/O that is actually asynchronous internally.
In Win32, asynchronous I/O is called overlapped I/O (see Figure 7-1 comparing synchronous and overlapped I/O). Once an application issues an overlapped I/O, Windows either completes the I/O operation immediately or returns a status code indicating the I/O operation is still pending. The thread can then issue more I/O operations, or it can do some computational work. The programmer has several options for receiving a notification about the I/O operation’s completion:
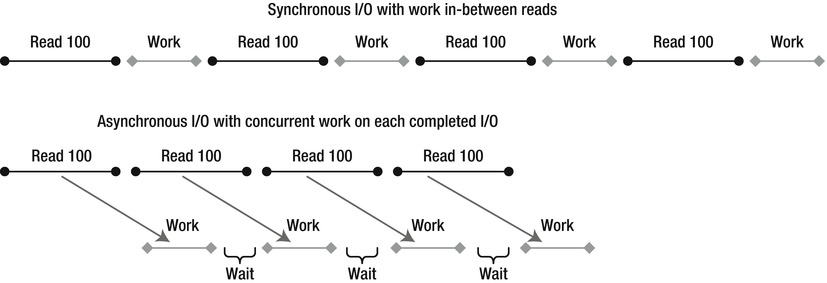
Figure 7-1 . Comparison between synchronous and overlapped I/O
- Signaling of a Win32 event: A wait operation on this event will complete when the I/O completes.
- Invocation of a user callback routine via the Asynchronous Procedure Call (APC) mechanism: The issuing thread must be in a state of alertable wait to allow APCs.
- Notification via I/O Completion Ports: This is usually the most efficient mechanism. We explore I/O completion ports in detail later in this chapter.
![]() Note Some I/O devices (e.g. a file opened in unbuffered mode) benefit (by increasing device utilization) if an application can keep a small amount of I/O requests pending. A recommended strategy is to pre-issue a certain number of I/O requests and, for each request that completes, re-issue another. This ensures the device driver can initiate the next I/O as quickly as possible, without waiting for the application to issue the next I/O in response. However, do not exaggerate with the amount of pending data, since it can consume limited kernel memory resources.
Note Some I/O devices (e.g. a file opened in unbuffered mode) benefit (by increasing device utilization) if an application can keep a small amount of I/O requests pending. A recommended strategy is to pre-issue a certain number of I/O requests and, for each request that completes, re-issue another. This ensures the device driver can initiate the next I/O as quickly as possible, without waiting for the application to issue the next I/O in response. However, do not exaggerate with the amount of pending data, since it can consume limited kernel memory resources.
I/O Completion Ports
Windows provides an efficient asynchronous I/O completion notification mechanism called the I/O Completion Port (IOCP). It is exposed through the .NET ThreadPool.BindHandle method. Several .NET types dealing with I/O utilize this functionality internally: FileStream, Socket, SerialPort, HttpListener, PipeStream, and some .NET Remoting channels.
An IOCP (see Figure 7-2) is associated with zero or more I/O handles (sockets, files, and specialized device driver objects) opened in overlapped mode and with user-created threads. Once an I/O operation of an associated I/O handle completes, Windows enqueues the completion notification to the appropriate IOCP and an associated thread handles the completion notification. By having a thread pool that services completions and by intelligently controlling thread wakeup, context switches are reduced and multi-processor concurrency is maximized. It is no surprise that high-performance servers, such as Microsoft SQL Server, use I/O completion ports.
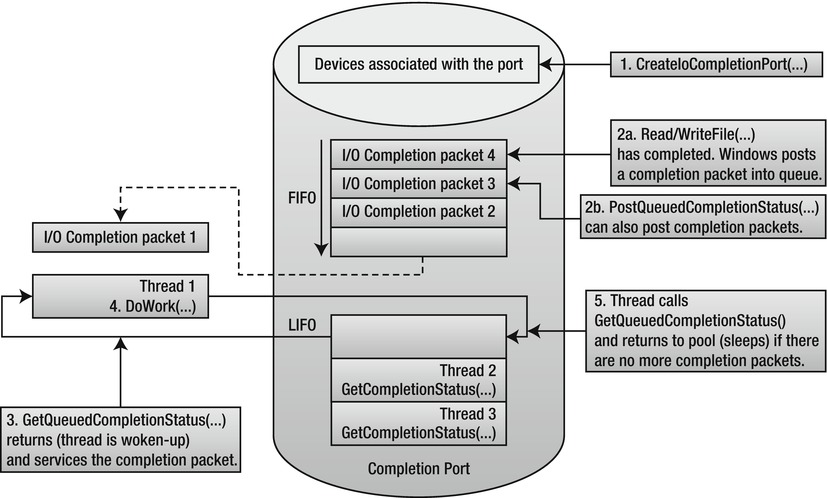
Figure 7-2 . Structure and operation of an I/O Completion Port
A completion port is created by calling the CreateIoCompletionPort Win32 API function, passing a maximum concurrency value, a completion key and optionally associating it with an I/O-capable handle. A completion key is a user-specified value that serves to distinguish between different I/O handles at completion. More I/O handles can be associated with the same or a different IOCP by again calling CreateIoCompletionPort and specifying the existing completion port handle.
User-created threads then call GetCompletionStatus to become bound to the specified IOCP and to wait for completion. A thread can only be bound to one IOCP at a time. GetQueuedCompletionStatus blocks until there is an I/O completion notification available (or a timeout period has elapsed), at which point it returns with the I/O operation details, such as the number of number of bytes transferred, the completion key, and the overlapped structure passed during I/O. If another I/O completes while all associated threads are busy (i.e., not blocked on GetQueuedCompletionStatus), the IOCP wakes another thread in LIFO order, up to the maximum concurrency value. If a thread calls GetQueuedCompletionStatus and the notification queue is not empty, the call returns immediately, without the thread blocking in the OS kernel.
![]() Note The IOCP is aware if one of the “busy” threads is actually doing a synchronous I/O or wait and will wake additional associated threads (if any), potentially exceeding the concurrency value. A completion notification can also be posted manually without involving I/O by calling PostQueuedCompletionStatus.
Note The IOCP is aware if one of the “busy” threads is actually doing a synchronous I/O or wait and will wake additional associated threads (if any), potentially exceeding the concurrency value. A completion notification can also be posted manually without involving I/O by calling PostQueuedCompletionStatus.
The following code listing shows an example of using ThreadPool.BindHandle on a Win32 file handle. Start by looking at the TestIOCP method. Here, we call CreateFile, which is a P/Invoke’d Win32 function used to open or create files or devices. We must specify the EFileAttributes.Overlapped flag in the call to use any kind of asynchronous I/O. CreateFile returns a Win32 file handle if it succeeds, which we then bind to .NET’s I/O completion port by calling ThreadPool.BindHandle. We create an auto-reset event, which is used to temporarily block the thread issuing I/O operations if there are too many such operations in progress (the limit is set by the MaxPendingIos constant).
We then begin a loop of asynchronous write operations. At each iteration, we allocate a buffer that contains the data to be written. We also allocate an Overlapped structure that contains the file offset (here, we always write to offset 0), an event handle signaled when I/O completes (not used in I/O Completion Ports) and an optional user-created IAsyncResult object that can be used to carry state to the completion function. We then call Overlapped structure’s Pack method, which takes the completion function and data buffer as parameters. It allocates an equivalent native overlapped structure from unmanaged memory and pins the data buffer. The native structure has to be manually freed to release the unmanaged memory it occupies and to unpin the managed buffer.
If there are not too many I/O operations in progress, we call WriteFile, while specifying the native overlapped structure. Otherwise, we wait until the event becomes signaled, which indicates the pending I/O operations count has dropped below the limit.
The I/O completion function WriteComplete is invoked by .NET I/O Completion thread pool threads when I/O completes. It receives a pointer to the native overlapped structure, which can be unpacked to convert it back to the managed Overlapped structure.
using System;
using System.Threading;
using Microsoft.Win32.SafeHandles;
using System.Runtime.InteropServices;
[DllImport("kernel32.dll", SetLastError = true, CharSet = CharSet.Auto)]
internal static extern SafeFileHandle CreateFile(
string lpFileName,
EFileAccess dwDesiredAccess,
EFileShare dwShareMode,
IntPtr lpSecurityAttributes,
ECreationDisposition dwCreationDisposition,
EFileAttributes dwFlagsAndAttributes,
IntPtr hTemplateFile);
[DllImport("kernel32.dll", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
static unsafe extern bool WriteFile(SafeFileHandle hFile, byte[] lpBuffer,
uint nNumberOfBytesToWrite, out uint lpNumberOfBytesWritten,
System.Threading.NativeOverlapped *lpOverlapped);
[Flags]
enum EFileShare : uint {
None = 0x00000000,
Read = 0x00000001,
Write = 0x00000002,
Delete = 0x00000004
}
enum ECreationDisposition : uint {
New = 1,
CreateAlways = 2,
OpenExisting = 3,
OpenAlways = 4,
TruncateExisting = 5
}
[Flags]
enum EFileAttributes : uint {
//Some flags not present for brevity
Normal = 0x00000080,
Overlapped = 0x40000000,
NoBuffering = 0x20000000,
}
[Flags]
enum EFileAccess : uint {
//Some flags not present for brevity
GenericRead = 0x80000000,
GenericWrite = 0x40000000,
}
static long _numBytesWritten;
static AutoResetEvent _waterMarkFullEvent; // throttles writer thread
static int _pendingIosCount;
const int MaxPendingIos = 10;
//Completion routine called by .NET ThreadPool I/O completion threads
static unsafe void WriteComplete(uint errorCode, uint numBytes, NativeOverlapped* pOVERLAP) {
_numBytesWritten + = numBytes;
Overlapped ovl = Overlapped.Unpack(pOVERLAP);
Overlapped.Free(pOVERLAP);
//Notify writer thread that pending I/O count fell below watermark
if (Interlocked.Decrement(ref _pendingIosCount) < MaxPendingIos)
_waterMarkFullEvent.Set();
}
static unsafe void TestIOCP() {
//Open file in overlapped mode
var handle = CreateFile(@"F:largefile.bin",
EFileAccess.GenericRead | EFileAccess.GenericWrite,
EFileShare.Read | EFileShare.Write,
IntPtr.Zero, ECreationDisposition.CreateAlways,
EFileAttributes.Normal | EFileAttributes.Overlapped, IntPtr.Zero);
_waterMarkFullEvent = new AutoResetEvent(false);
ThreadPool.BindHandle(handle);
for (int k = 0; k < 1000000; k++) {
byte[] fbuffer = new byte[4096];
//Args: file offset low & high, event handle, IAsyncResult object
Overlapped ovl = new Overlapped(0, 0, IntPtr.Zero, null);
//The CLR takes care to pin the buffer
NativeOverlapped* pNativeOVL = ovl.Pack(WriteComplete, fbuffer);
uint numBytesWritten;
//Check if too many I/O requests are pending
if (Interlocked.Increment(ref _pendingIosCount) < MaxPendingIos) {
if (WriteFile(handle, fbuffer, (uint)fbuffer.Length, out numBytesWritten,
pNativeOVL)) {
//I/O completed synchronously
_numBytesWritten + = numBytesWritten;
Interlocked.Decrement(ref _pendingIosCount);
} else {
if (Marshal.GetLastWin32Error() ! = ERROR_IO_PENDING) {
return; //Handle error
}
}
} else {
Interlocked.Decrement(ref _pendingIosCount);
while (_pendingIosCount > = MaxPendingIos) {
_waterMarkFullEvent.WaitOne();
}
}
}
}
To summarize, when working with high-throughput I/O devices, use overlapped I/O with completion ports, either by directly creating and using your own completion port in the unmanaged library or by associating a Win32 handle with .NET’s completion port through ThreadPool.BindHandle.
NET Thread Pool
The .NET Thread Pool is used for many purposes, each served by a different kind of thread. Chapter 6 showed the thread pool APIs that we used to tap into the thread pool’s ability to parallelize a CPU-bound computation. However, there are numerous kinds of work for which the thread pool is suited:
- Worker threads handle asynchronous invocation of user delegates (e.g. BeginInvoke or ThreadPool.QueueUserWorkItem).
- I/O completion threads handle completions for the global IOCP.
- Wait threads handle registered wait. A registered wait saves threads by combining several waits into one wait (using WaitForMultipleObjects), up to the Windows limit (MAXIMUM_WAIT_OBJECTS = 64). Registered wait is used for overlapped I/O that is not using I/O completion ports.
- Timer thread combines waiting on multiple timers.
- Gate thread monitors CPU usage of thread pool threads, as well as grows or shrinks the thread counts (within preset limits) for best performance.
![]() Note You can issue an I/O operation that may appear asynchronous, although it really is not. For example, calling ThreadPool.QueueUserWorkItem on a delegate and then doing a synchronous I/O operation does not make it truly asynchronous and is no better than doing so on a regular thread.
Note You can issue an I/O operation that may appear asynchronous, although it really is not. For example, calling ThreadPool.QueueUserWorkItem on a delegate and then doing a synchronous I/O operation does not make it truly asynchronous and is no better than doing so on a regular thread.
Commonly, a data buffer received from a hardware device is copied over and over until the application finishes processing it. Copying can become a significant source of CPU overhead and, thus, should be avoided for high throughput I/O code paths. We now survey some scenarios in which you copy data and how to avoid it.
Unmanaged Memory
In .NET, an unmanaged memory buffer is more cumbersome to work with than a managed byte[], so programmers often take the easy way out and just copy the buffer to managed memory.
If your API or library lets you specify your own memory buffer or has a user-defined allocator callback, allocate a managed buffer and pin it so that it can be accessed through both a pointer and as a managed reference. If the buffer is so large (>85,000 bytes) it is allocated in the Large Object Heap, try to re-use the buffer. If re-using is non-trivial because of indeterminate object lifetime, use memory pooling, as described in Chapter 8.
In other cases, the API or library insists on allocating its own (unmanaged) memory buffer. You can access it directly with a pointer (requires unsafe code) or by using wrapper classes, such as UnmanagedMemoryStream or UnmanagedMemoryAccessor. However, if you need to pass the buffer to some code that only works with byte[] or string objects, copying may be unavoidable.
Even if you cannot avoid copying memory, if some or most of your data is filtered early on (e.g. network packets), it is possible to avoid unnecessary memory copying by first checking if the data is useful without copying it.
As Chapter 8 explains, programmers sometime assume that a byte[] contains only the desired data and that it spans from the beginning until the end, forcing the caller to splice the buffer (allocate a new byte[] and copy only the desired portion). This scenario often comes up in parsing a protocol stack. In contrast, equivalent unmanaged code would take a pointer, will have no knowledge whether it points to the beginning of the allocation or not, and will have to take a length parameter to tell it where the data ends.
To avoid unnecessary memory copying, take an offset and length parameters wherever you take a byte[] parameter. The length parameter is used instead of the array’s Length property, and the offset value is added to the index.
Scatter–gather is a Windows I/O capability that enables I/O transfers to or from a set of non-contiguous memory locations as if they were contiguous. Win32 exposes this capability through ReadFileScatter and WriteFileGather functions. The Windows Sockets library also supports scatter–gather through its own functions: WSASend, WSARecv, as well as others.
Scatter–gather is useful in the following scenarios:
- You have a fixed header prepended to the payload of each packet. This saves you from copying the header each time to make a contiguous buffer.
- You want to save on system call overhead by performing I/O to multiple buffers in one system call.
Although ReadFileScatter and WriteFileGather are limiting because each buffer must be exactly of system page size and the functions require that the handle be opened as overlapped and unbuffered (which imposes even more constraints), socket-based scatter–gather is more practical, because it does not have these limitations. The .NET Framework exposes socket scatter–gather through overloads of Socket’s Send and Receive methods, but the generic scatter/gather functions are not exposed.
An example of scatter–gather usage is by HttpWebRequest. It combines an HTTP header with the payload without constructing a contiguous buffer to hold both.
Normally, file I/O goes through the filesystem cache, which has some performance benefits: caching of recently accessed data, read-ahead (speculative pre-fetching data from disk), write-behind (asynchronously writing data to disk), and combining of small writes. By hinting Windows about your expected file access pattern, you can gain a bit more performance. If your application does overlapped I/O and can intelligently handle buffers facing some complexities, then bypassing caching entirely can be more efficient.
When creating or opening a file, you specify flags and attributes to the CreateFile Win32 API function, some of which influence caching behavior:
- FILE_FLAG_SEQUENTIAL_SCAN hints to the Cache Manager that the file is accessed sequentially, possibly skipping some parts, but is seldom accessed randomly. The cache will read further ahead.
- FILE_FLAG_RANDOM_ACCESS hints that the file is accessed in random order, so the Cache Manager reads less ahead, since it is unlikely that this data will actually be requested by the application.
- FILE_ATTRIBUTE_TEMPORARY hints that the file is temporary, so flushing writes to disk (to prevent data loss) can be delayed.
NET exposes these options (except the last one) through a FileStream constructor overload that accepts a FileOptions enumeration parameter.
![]() Caution Random access is bad for performance, especially on disk media since the read/write head has to physically move. Historically, disk throughput has improved with increasing aereal storage density, but latency has not. Modern disks can intelligently (taking disk rotation into account) re-order random-access I/O so that the total time the head spends travelling is minimized. This is called Native Command Queuing (NCQ). For this to work effectively, the disk controller must be aware of several I/O requests ahead. In other words, if possible, you should have several asynchronous I/O requests pending.
Caution Random access is bad for performance, especially on disk media since the read/write head has to physically move. Historically, disk throughput has improved with increasing aereal storage density, but latency has not. Modern disks can intelligently (taking disk rotation into account) re-order random-access I/O so that the total time the head spends travelling is minimized. This is called Native Command Queuing (NCQ). For this to work effectively, the disk controller must be aware of several I/O requests ahead. In other words, if possible, you should have several asynchronous I/O requests pending.
Unbuffered I/O bypasses the Windows cache entirely. This has both benefits and drawbacks. Like with cache hinting, unbuffered I/O is enabled through the “flags and attributes” parameter during file creation, but .NET does not expose this functionality:
- FILE_FLAG_NO_BUFFERING prevents the data read or written from being cached but has no effect on hardware caching by the disk controller. This avoids a memory copy (from user buffer to cache) and prevents cache pollution (filling the cache with useless data at the expense of more important data). However, reads and writes must obey alignment requirements. The following parameters must be aligned to or have a size that is an integer multiple of the disk sector size: I/O transfer size, file offset, and memory buffer address. Typically, the sector size is 512 bytes long. Recent high-capacity disk drives have 4,096 byte sectors (known as “Advanced Format”), but they can run in a compatibility mode that emulates 512 byte sectors (at the expense of performance).
- FILE_FLAG_WRITE_THROUGH instructs the Cache Manager to flush cached writes (if FILE_FLAG_NO_BUFFERING is not specified) and instructs the disk controller to commit writes to physical media immediately, rather than storing them in the hardware cache.
Read-ahead improves performance by keeping the disk utilized, even if the application makes synchronous reads, and has delays between reads. This depends on Windows correctly predicting what part of the file the application will request next. By disabling buffering, you also disable read-ahead and should keep the disk busy by having multiple overlapped I/O operations pending.
Write-behind also improves performance for applications making synchronous writes by giving the illusion that disk-writes finish very quickly. The application can better utilize the CPU, because it blocks for less time. When you disable buffering, writes complete in the actual amount of time it takes to write them to disk. Therefore, doing asynchronous I/O becomes even more important when using unbuffered I/O.
Networking
Network access is a fundamental capability in most modern applications. Server applications that process client requests strive to maximize scalability and their throughput capacity to serve clients faster and to serve more clients per server, whereas clients aim to minimize network access latencies or to mitigate its effects. This section provides advice and tips for maximizing networking performance.
The way an applicative network protocol (OSI Layer 7) is constructed can have a profound influence on performance. This section explores some optimization techniques to better utilize the available network capacity and to minimize overhead.
In a non-pipelined protocol, a client sends a request to server and then waits for the response to arrive before it can send the next request. With such a protocol, network capacity is under-utilized, because, during the network round-trip time (i.e. time it takes network packets to reach the server and back), the network is idle. Conversely, in a pipelined connection, the client can continue to send more requests, even before the server has processed the previous requests. Better yet, the server can decide to respond to requests out of order, responding to trivial requests first, while deferring processing of more computationally-demanding requests.
Pipelining is increasingly important, because, while Internet bandwidth continues to increase worldwide, latency improves at a much slower rate because it is capped to physical limits imposed by the speed of light.
An example of pipelining in a real-world protocol is HTTP 1.1, but it is often disabled by default on most servers and web browsers because of compatibility issues. Google SPDY, an experimental HTTP-like protocol supported by Chrome and Firefox web browsers, as well as some HTTP servers, and the upcoming HTTP 2.0 protocol mandate pipelining support.
Streaming is not just for video and audio, but can be used for messaging. With streaming, the application begins sending data over the network even before it is complete. Streaming reduces latency and improves network channel utilization.
For example, if a server application fetches data from a database in response to a request, it can either read it in one chunk into a DataSet (which can consume large amounts of memory) or it can use a DataReader to retrieve records one at a time. In the former approach, the server has to wait until the entire dataset has arrived before it can begin sending a response to the client, whereas in the latter approach, the server can begin sending a response to the client as soon as the first DB record arrives.
Sending small chunks of data at a time over the network is wasteful. Ethernet, IP, and TCP/UDP headers are no smaller, because the payload is smaller, so although bandwidth utilization can still be high, you end up wasting it on headers, not actual data. Additionally, Windows itself has per-call overhead that is independent or weakly dependent on data chunk size. A protocol can mitigate this by allowing several requests to be combined. For example, the Domain Name Service (DNS) protocol allows a client to resolve multiple domain names in one request.
Chatty Protocols
Sometimes, the client cannot pipeline requests, even if the protocol allows this, because the next requests depend on the content of the previous replies.
Consider an example of a chatty protocol session. When you browse to a web page, the browser connects to the web server via TCP, sends an HTTP GET request for the URL you are trying to visit, and receives an HTML page as a response. The browser then parses the HTML to figure out which JavaScript, CSS, and image resources it has to retrieve and downloads them individually. The JavaScript script is then executed, and it can fetch further content. In summary, the client does not immediately know all the content it has to retrieve to render the page. Instead, it has to iteratively fetch content until it discovers and downloads all content.
To mitigate this problem, the server might hint to the client which URLs it will need to retrieve to render the page and might even send content without the client requesting it.
Message Encoding and Redundancy
Network bandwidth is often a constrained resource, and having a wasteful messaging format does not help performance. Here are a few tips to optimize messaging format:
- Do not transmit the same thing over and over, and keep headers small.
- Use smart encoding or representation for data. For example, strings can be encoded in UTF-8, instead of UTF-16. A binary protocol can be many times more compact than a human-readable protocol. If possible, avoid encapsulations, such as Base64 encoding.
- Use compression for highly compressible data, such as text. Avoid it for uncompressible data, such as already-compressed video, images, and audio.
The sockets API is the standard way for applications to work with network protocols, such as TCP and UDP. Originally, the sockets API was introduced in the BSD UNIX operating system and since became standard in virtually all operating systems, sometimes with proprietary extensions, such as Microsoft’s WinSock. There are a number of ways for doing socket I/O in Windows: blocking, non-blocking with polling, and asynchronous. Using the right I/O model and socket parameters enables higher throughput, lower latency, and better scalability. This section outlines performance optimization pertaining to Windows Sockets.
.NET supports asynchronous I/O through the Socket class. However, there are two families of asynchronous APIs: BeginXXX and XXXAsync, where XXX stands for Accept, Connect, Receive, Send, and other operations. The former use the .NET Thread Pool’s registered wait capability to await overlapped I/O completion, whereas the latter use .NET Thread Pool’s I/O Completion Port mechanism, which is more performant and scalable. The latter APIs were introduced in .NET Framework 2.0 SP1.
Socket Buffers
Socket objects expose two settable buffer sizes: ReceiveBufferSize and SendBufferSize, which specify buffer sizes allocated by the TCP/IP stack (in OS memory space). Both are set to 8,192 bytes by default. The receive buffer is used to hold received data not yet read by the application. The send buffer is used to hold data that has been sent by the application but that has not yet been acknowledged by the receiver. Should the need to retransmit arise, data from the send buffer is retransmitted.
When the application reads from the socket, it unfills the receive buffer by the amount read. When the receive buffer becomes empty, the call either blocks or becomes pending, depending if synchronous or asynchronous I/O is used.
When the application writes to the socket, it can write data without blocking until the send buffer is full and cannot accommodate the data or until the receiver’s receive buffer becomes full. The receiver advertises how full its receive buffer size is with each acknowledgement.
For high-bandwidth, high latency connections, such as satellite links, the default buffer sizes may be too small. The sending end quickly fills up its send buffer and has to wait for acknowledgement, which is slow to arrive because of high latency. While waiting, the pipe is not kept full and the endpoints only utilize a fraction of the available bandwidth.
In a perfectly reliable network, the ideal buffer size is the product of the bandwidth and latency. For example, in a 100Mbps connection with a 5 ms round-trip time, an ideal buffer window size would be (100,000,000 / 8) × 0.005 = 62,500 bytes. Packet loss reduces this value.
Nagle’s Algorithm
As mentioned before, small packets are wasteful, because packet headers may be large compared to the payload. Nagle’s algorithm improves performance of TCP sockets by coalescing multiple writes by the application into up to a whole packet’s worth of data. However, this service does not come for free as it introduces delay before data is sent. A latency sensitive application should disable Nagle’s algorithm by setting the Socket.NoDelay property to true. A well-written application would send large buffers at a time and would not benefit from Nagle’s algorithm.
Registered I/O
Registered I/O (RIO) is a new extension of WinSock available in Windows Server 2012 that provides a very efficient buffer registration and notification mechanism. RIO eliminates the most significant inefficiencies in Windows I/O:
- User buffer probing (checking for page access permissions), locking and unlocking (ensuring the buffers are resident in RAM).
- Handle lookups (translating a Win32 HANDLE to a kernel object pointer).
- System calls made (e.g. to dequeue I/O completion notifications).
These are “taxes” paid to isolate the application from the operating system and from other applications, to the end of ensuring security and reliability. Without RIO, you pay these taxes per call, which, at high I/O rates, becomes significant. Conversely, with RIO, you incur the costs of the “taxes” only once, during initialization.
RIO requires registration of buffers, which locks them in physical memory until they are de-registered (when the application or subsystem uninitializes). Since the buffers remain allocated and resident in memory, Windows can skip probing, locking, and unlocking per call.
RIO request and completion queues reside in the process’ memory space and are accessible to it, meaning a system call is no longer required to poll the queue or dequeue completion notifications.
RIO supports three notification mechanisms:
- Polling: This has the lowest latency but means a logical processor is dedicated to polling the network buffers.
- I/O Completion Ports.
- Signaling a Windows event.
At the time of writing, RIO was not exposed by the .NET Framework, but it is accessible through the standard .NET interoperability mechanisms (discussed in Chapter 8).
Data Serialization and Deserialization
Serialization is the act of representing an object in a format that can be written to disk or sent via a network. De-serialization is the act of reconstructing an object from the serialized representation. For example, a hash table can be serialized to an array of key-value records.
The .NET Framework comes with several generic serializers that can serialize and de-serialize user-defined types. This section weighs the advantages and disadvantages of each, benchmark serializers in terms serialization throughput and serialized message size.
First, we review the available serializers:
- System.Xml.Serialization.XmlSerializer
- Serializes to XML, either text or binary.
- Works on child objects, but does not support circular references.
- Works only on public fields and properties, except those that are explicitly excluded.
- Uses Reflection only once to code-generate a serialization assembly, for efficient operation. You can use the sgen.exe tool to pre-create the serialization assembly.
- Allows customization of XML schema.
- Requires knowing all types that participate in serialization a priori: It infers this information automatically, except when inherited types are used.
- System.Runtime.Serialization.Formatters.Binary.BinaryFormatter
- Serializes to a proprietary binary format, consumable only by .NET BinaryFormatter.
- Is used by .NET Remoting, but can also be used stand-alone for general serialization.
- Works in both public and non-public fields.
- Handles circular references.
- Does not require a priori knowledge of types to be serialized.
- Requires types to be marked as serializable by applying the [Serializable] attribute.
- System.Runtime.Serialization.Formatters.Soap.SoapFormatter
- Is similar in capabilities to BinaryFormatter, but serializes to a SOAP XML format, which is more interoperable but less compact.
- Does not support generics and generic collections, and therefore deprecated in recent versions of the .NET Framework.
- System.Runtime.Serialization.DataContractSerializer
- Serializes to XML, either text or binary.
- Is used by WCF but can also be used stand-alone for general serialization.
- Serializes types and fields as an opt-in through the use of [DataContract] and [DataMember] attributes: If a class is marked by the [Serializable] attribute, all fields get serialized.
- Requires knowing all types that participate in serialization a priori: It infers this information automatically, except when inherited types are used.
- System.Runtime.Serialization.NetDataContractSerializer
- Is similar to DataContractSerializer, except it embeds .NET-specific type information in the serialized data.
- Does not require foreknowledge of types that participate in serialization.
- Requires sharing assemblies containing serialized types.
- System.Runtime.Serialization.DataContractJsonSerializer
- Is similar to DataContractSerializer, but serializes to JSON format instead of XML format.
Figure 7-3 presents benchmark results for the previously listed serializers. Some serializers are tested twice for both text XML output and binary XML output. The benchmark involves the serialization and de-serialization of a high-complexity object graph, consisting of 3,600 instances of five types with a tree-like referencing pattern. Each type consists of string and double fields and arrays thereof. No circular references were present, because not all serializers support them; however, those serializers that support circular references ran significantly slower in their presence. The benchmark results presented here were run on .NET Framework 4.5 RC, which has slightly improved results over .NET Framework 3.5 for tests using binary XML, but otherwise there is no significant difference.
The benchmark results show that DataContractSerializer and XmlSerializer, when working with binary XML format, are fastest overall.
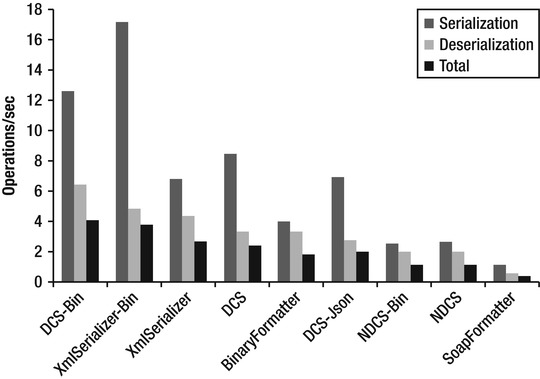
Figure 7-3 . Serializer throughput benchmark results, in operations/sec
Next, we compare the serialized data size of the serializers (see Figure 7-4). There are several serializers that are very close to one another in this metric. This is likely because the object tree has most of its data in the form of strings, which is represented the same way across all serializers.
The most compact serialized representation is produced by the DataContractJsonSerializer, closely followed by XmlSerializer and DataContractSerializer when used with a binary XML writer. Perhaps surprisingly, BinaryFormatter was outperformed by most other serializers.
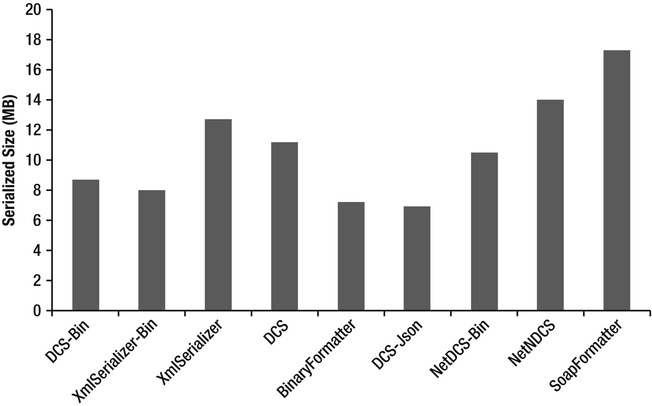
Figure 7-4 . Comparison of serialized data size
A DataSet is an in-memory cache for data retrieved from a database through a DataAdapter. It contains a collection of DataTable objects, which contain the database schema and data rows, each containing a collection of serialized objects. DataSet objects are complex, consume a large amount of memory, and are computationally intensive to serialize. Nevertheless, many applications pass them between tiers of the application. Tips to somewhat reduce the serialization overhead include:
- Call DataSet.ApplyChanges method before serializing the DataSet. The DataSet stores both the original values and the changed values. If you do not need to serialize the old values, call ApplyChanges to discard them.
- Serialize only the DataTables you need. If the DataSet contains other tables you do not need, consider copying only the required tables to a new DataSet object and serializing it instead.
- Use column name aliasing (As keyword) to give shorter names and reduce serialized length. For example, consider this SQL statement:SELECT EmployeeID As I, Name As N, Age As A
Windows Communication Foundation
Windows Communication Foundation (WCF), released in .NET 3.0, is quickly becoming the de-facto standard for most networking needs in .NET applications. It offers an unparalleled choice of network protocols and customizations and is continuously being extended with new .NET releases. This section covers WCF performance optimizations.
WCF, especially before .NET Framework 4.0, has conservative throttling values by default. These are designed to protect against Denial of Service (DoS) attacks, but, unfortunately in the real world, they are often set too low to be useful.
Throttling settings can be modified by editing the system.serviceModel section in either app.config (for desktop applications) or web.config for ASP.NET applications:
<system.serviceModel>
<behaviors>
<serviceBehaviors>
<behavior>
<serviceThrottling>
<serviceThrottling maxConcurrentCalls = "16"
maxConcurrentSessions = "10" maxConcurrentInstances = "26" />
Another way to change these parameters is by setting properties on a ServiceThrottling object during service creation time:
Uri baseAddress = new Uri("http://localhost:8001/Simple");
ServiceHost serviceHost = new ServiceHost(typeof(CalculatorService), baseAddress);
serviceHost.AddServiceEndpoint(
typeof(ICalculator),
new WSHttpBinding(),
"CalculatorServiceObject");
serviceHost.Open();
IChannelListener icl = serviceHost.ChannelDispatchers[0].Listener;
ChannelDispatcher dispatcher = new ChannelDispatcher(icl);
ServiceThrottle throttle = dispatcher.ServiceThrottle;
throttle.MaxConcurrentSessions = 10;
throttle.MaxConcurrentCalls = 16;
throttle.MaxConcurrentInstances = 26;
Let us understand what these parameters mean.
- maxConcurrentSessions limits the number of messages that currently process across a ServiceHost. Calls in excess of the limit are queued. Default value is 10 for .NET 3.5 and 100 times the number of processors in .NET 4.
- maxConcurrentCalls limits the number of InstanceContext objects that execute at one time across a ServiceHost. Requests to create additional instances are queued and complete when a slot below the limit becomes available.
- Default value is 16 for .NET 3.5 and 16 times the number of processors in .NET 4.
- maxConcurrentInstances limits the number of sessions a ServiceHost object can accept. The service accepts connections in excess of the limit, but only the channels below the limit are active (messages are read from the channel).
- Default value is 26 for .NET 3.5 and 116 times the number of processors in .NET 4.
Another important limit is the number of concurrent connections an application is allowed per host, which is two by default. If your ASP.NET application calls an external WCF service, this limit may be a significant bottleneck. This is a configuration example that sets these limits:
<system.net>
<connectionManagement>
<add address = "*" maxconnection = "100" />
</connectionManagement>
</system.net>
When writing a WCF service, you need to determine its activation and concurrency model. This is controlled by ServiceBehavior attribute’s InstanceContextMode and ConcurrencyMode properties, respectively. The meaning of InstanceContextMode values is as follows:
- PerCall – A service object instance is created for each call.
- PerSession (default) – A service object instance is created for each session. If the channel does not support sessions, this behaves like PerCall.
- Single – A single service instance is re-used for all calls.
The meaning of ConcurrencyMode values is as follows:
- Single (default) – The service object is single-threaded and does not support re-entrancy. If InstanceContextMode is set to Single and it already services a request, then additional requests have to wait for their turn.
- Reentrant – The service object is single-threaded but is re-entrant. If the service calls another service, it may be re-entered. It is your responsibility to ensure object state is left in a consistent state prior to the invocation of another service.
- Multiple – No synchronization guarantees are made, and the service must handle synchronization on its own to ensure consistency of state.
Do not use Single or Reentrant ConcurrencyMode in conjunction with Single InstanceContextMode. If you use Multiple ConcurrencyMode, use fine-grained locking so that better concurrency is achieved.
WCF invokes your service objects from .NET thread pool I/O completion threads, previously described within this chapter. If during servicing you perform synchronous I/O or do waits, you may need to increase the number of thread pool threads allowed by editing the system.web configuration section for an ASP.NET application (see below) or by calling ThreadPool.SetMinThreads and ThreadPool.SetMaxThreads in a desktop application.
<system.web>
<processModel
...
enable = "true"
autoConfig = "false"
maxWorkerThreads ="80"
maxIoThreads = "80"
minWorkerThreads = "40"
minIoThreads = "40"
/>
WCF does not ship with built-in support for caching. Even if you are hosting your WCF service in IIS, it still cannot use its cache by default. To enable caching, mark your WCF service with the AspNetCompatibilityRequirements attribute.
[AspNetCompatibilityRequirements(RequirementsMode = AspNetCompatibilityRequirementsMode.Allowed)]
In addition, enable ASP.NET compatibility by editing web.config and adding the following element under the system.serviceModel section:
<serviceHostingEnvironment aspNetCompatibilityEnabled = "true" />
Starting with .NET Framework 4.0, you can use the new System.Runtime.Caching types to implement caching. It is not dependent on the System.Web assembly, so it is not limited to ASP.NET.
Asynchronous WCF Clients and Servers
WCF lets you issue asynchronous operation on both the client and server side. Each side can independently decide whether it operates synchronously or asynchronously.
On the client side, there are two ways to invoke a service asynchronously: event-based and .NET async pattern based. The event-based model is not compatible with channels created with ChannelFactory. To use the event-based model, generate a service proxy by using the svcutil.exe tool with both the /async and /tcv:Version35 switches:
svcutil /n:http://Microsoft.ServiceModel.Samples,Microsoft.ServiceModel.Sampleshttp://localhost:8000/servicemodelsamples/service/mex /async /tcv:Version35
The generated proxy can then be used as follows:
// Asynchronous callbacks for displaying results.
static void AddCallback(object sender, AddCompletedEventArgs e) {
Console.WriteLine("Add Result: {0}", e.Result);
}
static void Main(String[] args) {
CalculatorClient client = new CalculatorClient();
client.AddCompleted + = new EventHandler < AddCompletedEventArgs > (AddCallback);
client.AddAsync(100.0, 200.0);
}
In the IAsyncResult-based model, you use svcutil to create a proxy specifying the /async switch but without also specifying the /tcv:Version35 switch. You then call the BeginXXX methods on the proxy and provide a completion callback as follows:
static void AddCallback(IAsyncResult ar) {
double result = ((CalculatorClient)ar.AsyncState).EndAdd(ar);
Console.WriteLine("Add Result: {0}", result);
}
static void Main(String[] args) {
ChannelFactory < ICalculatorChannel > factory = new ChannelFactory < ICalculatorChannel > ();
ICalculatorChannel channelClient = factory.CreateChannel();
IAsyncResult arAdd = channelClient.BeginAdd(100.0, 200.0, AddCallback, channelClient);
}
On the server, asynchrony is implemented by creating BeginXX and EndXX versions of your contract operations. You should not have another operation named the same but without the Begin/End prefix, because WCF will invoke it instead. Follow these naming conventions, because WCF requires it.
The BeginXX method should take input parameters and return IAsyncResult with little processing; I/O should be done asynchronously. The BeginXX method (and it alone) should have the OperationContract attribute applied with the AsyncPattern parameter set to true.
The EndXX method should take an IAsyncResult, have the desired return value, and have the desired output parameters. The IAsyncResult object (returned from BeginXX) should contain all the necessary information to return the result.
Additionally, WCF 4.5 supports the new Task-based async/await pattern in both server and client code. For example:
//Task-based asynchronous service
public class StockQuoteService : IStockQuoteService {
async public Task<double> GetStockPrice(string stockSymbol) {
double price = await FetchStockPriceFromDB();
return price;
}
}
//Task-based asynchronous client
public class TestServiceClient : ClientBase < IStockQuoteService>, IStockQuoteService {
public Task<double> GetStockPriceAsync(string stockSymbol) {
return Channel.GetStockPriceAsync();
}
}
When designing your WCF service, it is important to select the right binding. Each binding has its own features and performance characteristics. Choose the simplest binding, and use the smallest number of binding features that will serve your needs. Features, such as reliability, security, and authentication, add a great deal of overhead, so use them only when necessary.
For communication between processes on the same machine, the Named Pipe binding offers the best performance. For cross-machine two-way communication, the Net TCP binding offers the best performance. However, it is not interoperable and can only work with WCF clients. It is also not load-balancer-friendly, as the session becomes affine to a particular server address.
You can use a custom binary HTTP binding to get most of the performance benefits of TCP binding, while remaining compatible with load balancers. Below is an example of configuring such a binding:
<bindings>
< customBinding>
<binding name = "NetHttpBinding">
<reliableSession />
<compositeDuplex />
<oneWay />
<binaryMessageEncoding />
<httpTransport />
</binding>
</customBinding>
<basicHttpBinding>
<binding name = "BasicMtom" messageEncoding = "Mtom" />
</basicHttpBinding>
<wsHttpBinding>
<binding name = "NoSecurityBinding">
<security mode = "None" />
</binding>
</wsHttpBinding>
</bindings>
<services>
<service name = "MyServices.CalculatorService">
<endpoint address = " " binding = "customBinding" bindingConfiguration = "NetHttpBinding"
contract = "MyServices.ICalculator" />
</service>
</services>
Finally, choose the basic HTTP binding over the WS-compatible one. The latter has a significantly more verbose messaging format.
Summary
As you have seen throughout this chapter, by improving your application’s I/O performance, you can make a vast difference and refrain from any computation-related optimizations. This chapter:
- Examined the difference between synchronous and asynchronous I/O.
- Explored various I/O completion notification mechanisms.
- Gave general tips about I/O, such as minimizing memory buffer copying.
- Discussed file-I/O-specific optimizations.
- Examined socket-specific optimizations.
- Showed how to optimize network protocol to fully exploit available network capacity.
- Compared and benchmarked various serializers built into the .NET Framework.
- Covered WCF optimizations.