
![]()
Unsafe Codeand Interoperability
Few real-world applications are composed strictly of managed code. Instead, they frequently make use of in-house or 3rd party libraries implemented in native code. The .NET Framework offers several mechanisms to interoperate with native code that is implemented in a number of widespread technologies:
- P/Invoke: enables interoperability with DLLs exporting C-style functions.
- COM Interop: enables consumption of COM objects by managed code as well as exposing .NET classes as COM objects to be consumed by native code.
- C++/CLI language: enables interoperability with C and C++ via a hybrid programming language.
In fact, the Base Class Library (BCL), which is the set of DLLs shipped with the .NET Framework (mscorlib.dll being the main one) that contain .NET Framework’s built-in types, uses all of the aforementioned mechanisms. It can therefore be argued that any non-trivial managed application is actually a hybrid application under the covers, in the sense that it calls native libraries.
While these mechanisms are very useful, it is important to understand the performance implications associated with each interop mechanism, and how to minimise their impact.
Unsafe Code
Managed code offers type safety, memory safety, and security guarantees, which eliminate some of the most difficult to diagnose bugs and security vulnerabilities prevalent in native code, such as heap corruptions and buffer overflows. This is made possible by prohibiting direct memory access with pointers, instead working with strongly-typed references, checking array access boundaries and ensuring only legal casting of objects.
However, in some cases these constraints may complicate otherwise simple tasks and reduce performance by forcing you to use a safe alternative. For example, one might read data from a file into a byte[] but would like to interpret this data as an array of double values. In C/C++, you would simply cast the char pointer to a double pointer. In contrast, in a safe .NET code, one could wrap the buffer with a MemoryStream object and use a BinaryReader object on top of the former to read each memory location as double values; another option is to use the BitConverter class. These solutions would work, but they’re slower than doing this in unmanaged code. Fortunately, C# and the CLR support unsafe memory access with pointers and pointer casting. Other unsafe features are stack memory allocation and embedded arrays within structures. The downside of unsafe code is compromised safety, which can lead to memory corruptions and security vulnerabilities, so you should be very careful when writing unsafe code.
To use unsafe code, you must first enable compiling unsafe code in C# project settings (see Figure 8-1), which results in passing the /unsafe command-line parameter to the C# compiler. Next, you should mark the region where unsafe code or unsafe variables are permitted, which can be a whole class or struct, a whole method or just a region within a method.
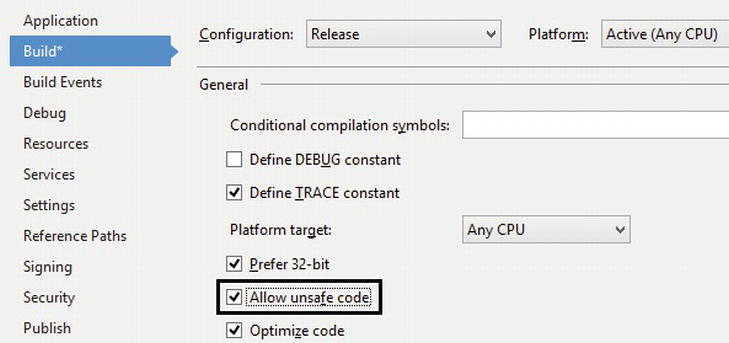
Figure 8-1 . Enabling unsafe code in C# project settings (Visual Studio 2012)
Because managed objects located on the GC heap can be relocated during garbage collections occurring at unpredictable times, you must pin them in order to obtain their address and prevent them from being moved around in memory.
Pinning can be done either by using the fixed scope (see example in Listing 8-1) in C# or by allocating a pinning GC handle (see Listing 8-2). P/Invoke stubs, which we will cover later, also pin objects in a way equivalent to the fixed statement. Use fixed if the pinning requirement can be confined to the scope of a function, as it is more efficient than the GC handle approach. Otherwise, use GCHandle.Alloc to allocate a pinning handle to pin an object indefinitely (until you explicitly free the GC handle by calling GCHandle.Free). Stack objects (value types) do not require pinning, because they’re not subject to garbage collection. A pointer can be obtained directly for stack-located objects by using the ampersand (&) reference operator.
Listing 8-1. Using fixed scope and pointer casting to reinterpret data in a buffer
using (var fs = new FileStream(@"C:Devsamples.dat", FileMode.Open)) {
var buffer = new byte[4096];
int bytesRead = fs.Read(buffer, 0, buffer.Length);
unsafe {
double sum = 0.0;
fixed (byte* pBuff = buffer) {
double* pDblBuff = (double*)pBuff;
for (int i = 0; i < bytesRead / sizeof(double); i++)
sum + = pDblBuff[i];
}
}
}
![]() Caution The pointer obtained from the fixed statement must not be used outside the fixed scope because the pinned object becomes unpinned when the scope ends. You can use the fixed keyword on arrays of value types, on strings and on a specific value type field of a managed class. Be sure to specify structure memory layout.
Caution The pointer obtained from the fixed statement must not be used outside the fixed scope because the pinned object becomes unpinned when the scope ends. You can use the fixed keyword on arrays of value types, on strings and on a specific value type field of a managed class. Be sure to specify structure memory layout.
GC handles are a way to refer to a managed object residing on the GC heap via an immutable pointer-sized handle value (even if the object’s address changes), which can even be stored by native code. GC handles come in four varieties, specified by the GCHandleType enumeration: Weak, WeakTrackRessurection, Normal and Pinned. The Normal and Pinned types prevent an object from being garbage collected even if there is no other reference to it. The Pinned type additionally pins the object and enables its memory address to be obtained. Weak and WeakTrackResurrection do not prevent the object from being collected, but enable obtaining a normal (strong) reference if the object hasn’t been garbage collected yet. It is used by the WeakReference type.
Listing 8-2. Using a pinning GCHandle for pinning and pointer casting to reinterpret data in a buffer
using (var fs = new FileStream(@"C:Devsamples.dat", FileMode.Open)) {
var buffer = new byte[4096];
int bytesRead = fs.Read(buffer, 0, buffer.Length);
GCHandle gch = GCHandle.Alloc(buffer, GCHandleType.Pinned);
unsafe {
double sum = 0.0;
double* pDblBuff = (double *)(void *)gch.AddrOfPinnedObject();
for (int i = 0; i < bytesRead / sizeof(double); i++)
sum + = pDblBuff[i];
gch.Free();
}
}
![]() Caution Pinning may cause managed heap fragmentation if a garbage collection is triggered (even by another concurrently running thread). Fragmentation wastes memory and reduces the efficiency of the garbage collector’s algorithm. To minimize fragmentation, do not pin objects longer than necessary.
Caution Pinning may cause managed heap fragmentation if a garbage collection is triggered (even by another concurrently running thread). Fragmentation wastes memory and reduces the efficiency of the garbage collector’s algorithm. To minimize fragmentation, do not pin objects longer than necessary.
In many cases, native code continues to hold unmanaged resources across function calls, and will require an explicit call to free the resources. If that’s the case, implement the IDisposable interface in the wrapping managed class, in addition to a finalizer. This will enable clients to deterministically dispose unmanaged resources, while the finalizer should be a last-resort safety net in case you forgot to dispose explicitly.
Managed objects taking more than 85,000 bytes (commonly, byte buffers and strings) are placed on the Large Object Heap (LOH), which is garbage collected together with Gen2 of the GC heap, which is quite expensive. The LOH also often becomes fragmented because it is never compacted; rather free spaces are re-used if possible. Both these issues increase memory usage and CPU usage by the garbage collector. Therefore, it is more efficient to use managed memory pooling or to allocate these buffers from unmanaged memory (e.g. by calling Marshal.AllocHGlobal). If you later need to access unmanaged buffers from managed code, use a “streaming” approach, where you copy small chunks of the unmanaged buffer to managed memory and work with one chunk at a time. You can use System.UnmanagedMemoryStream and System.UnmanagedMemoryAccessor to make the job easier.
Memory Pooling
If you are heavily using buffers to communicate with native code, you can either allocate them from GC heap or from an unmanaged heap. The former approach becomes inefficient for high allocation rates and if the buffers aren’t very small. Managed buffers will need to be pinned, which promotes fragmentation. The latter approach is also problematic, because most managed code expects buffers to be managed byte arrays (byte[]) rather than pointers. You cannot convert a pointer to a managed array without copying, but this is bad for performance.
![]() Tip You can look up the % Time in GC performance counter under the .NET CLR Memory performance counter category to get an estimate of the CPU time “wasted” by the GC, but this doesn’t tell you what code is responsible. Use a profiler (see Chapter 2) before investing optimization effort, and see Chapter 4 for more tips on garbage collection performance.
Tip You can look up the % Time in GC performance counter under the .NET CLR Memory performance counter category to get an estimate of the CPU time “wasted” by the GC, but this doesn’t tell you what code is responsible. Use a profiler (see Chapter 2) before investing optimization effort, and see Chapter 4 for more tips on garbage collection performance.
We propose a solution (see Figure 8-2) which provides a copy-free access from both managed and unmanaged code and does not stress the GC. The idea is to allocate large managed memory buffers (segments) which reside on the Large Object Heap. There is no penalty associated with pinning these segments because they’re already non-relocatable.
A simple allocator, where the allocation pointer (an index actually) of a segment moves only forward with each allocation will then allocate buffers of varying sizes (up to the segment size) and will return a wrapper object around those buffers. Once the pointer approaches the end and an allocation fails, a new segment is obtained from the segment pool and allocation is attempted again.
Segments have a reference count that is incremented for every allocation and decremented when the wrapper object is disposed of. Once its reference count reaches zero, it can be reset, by setting the pointer to zero and optionally zero filling memory, and then returned to the segment pool.
The wrapper object stores the segment’s byte[], the offset where data begins, its length, and an unmanaged pointer. In effect, the wrapper is a window into the segment’s large buffer. It will also reference the segment in order to decrement the segment in-use count once the wrapper is disposed. The wrapper could provide convenience methods such a safe indexer access which accounts for the offset and verifies that access is within bounds.
Since .NET developers have a habit of assuming that buffer data always begins at index 0 and lasts the entire length of the array, you will need to modify code not to assume that, but to rely on additional offset and length parameters that will be passed along with the buffer. Most .NET BCL methods that work with buffers have overloads which take offset and length explicitly.
The major downside to this approach is the loss of automatic memory management. In order for segments to be recycled, you will have to explicitly dispose of the wrapper object. Implementing a finalizer isn’t a good solution, because this will more than negate the performance benefits.
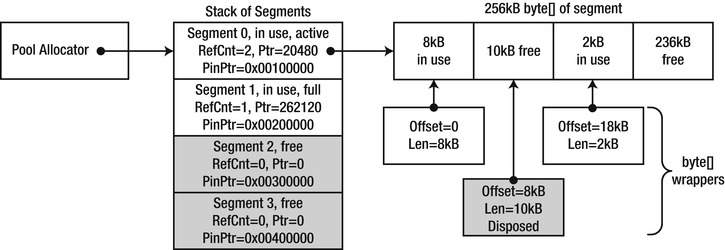
Figure 8-2 . Proposed memory pooling scheme
P/Invoke
Platform Invoke, better known as P/Invoke, enables calling C-style functions that are exported by DLLs from managed code. To use P/Invoke, the managed caller declares a static extern method, with a signature (parameter types and return value type) equivalent to those of the C function. The method is then marked with the DllImport attribute, while specifying at a minimum, the DLL which exports the function.
// Native declaration from WinBase.h:
HMODULE WINAPI LoadLibraryW(LPCWSTR lpLibFileName);
// C# declaration:
class MyInteropFunctions {
[DllImport("kernel32.dll", SetLastError = true)]
public static extern IntPtr LoadLibrary(string fileName);
}
In the preceding code, we define LoadLibrary as a function taking a string and returning an IntPtr, which is a pointer type that cannot be dereferenced directly, thus using it does not render the code unsafe. The DllImport attribute specifies that the function is exported by kernel32.dll (which is the main Win32 API DLL) and that the Win32 last error code should be saved so Thread Local Storage so that it will not be overwritten by calls to Win32 functions not done explicitly (e.g. internally by the CLR) . The DllImport attribute can also be used to specify the C function’s calling convention, string encoding, exported name resolution options, etc.
If the native function’s signature contains complex types such as C structs, then equivalent structures or classes must be defined by the managed code, using equivalent types for each field. Relative structure field order, field types and alignment must match to what the C code expects. In some cases, you will need to apply the MarshalAs attribute on fields, on function parameters or the return value to modify default marshaling behavior. For example, the managed System.Boolean (bool) type can have multiple representations in native code: the Win32 BOOL type is four bytes long and a true value is any non-zero value, while in C++ the bool value is one byte long and the true value equals 1.
In the following code listing, the StructLayout attribute that is applied to the WIN32_FIND_DATA struct, specifies that a sequential in-memory field layout is desired; without it, the CLR is free to re-arrange fields for better efficiency. The MarshalAs attributes applied to the cFileName and cAlternativeFileName fields specify that the strings should be marshaled as fixed-size strings embedded within the structure, as opposed to being just pointers to a string external to the structure.
// Native declaration from WinBase.h:
typedef struct _WIN32_FIND_DATAW {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD dwReserved0;
DWORD dwReserved1;
WCHAR cFileName[MAX_PATH];
WCHAR cAlternateFileName[14];
} WIN32_FIND_DATAW;
HANDLE WINAPI FindFirstFileW(__in LPCWSTR lpFileName,
__out LPWIN32_FIND_DATAW lpFindFileData);
// C# declaration:
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]
struct WIN32_FIND_DATA {
public uint dwFileAttributes;
public FILETIME ftCreationTime;
public FILETIME ftLastAccessTime;
public FILETIME ftLastWriteTime;
public uint nFileSizeHigh;
public uint nFileSizeLow;
public uint dwReserved0;
public uint dwReserved1;
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 260)]
public string cFileName;
[MarshalAs(UnmanagedType.ByValTStr, SizeConst = 14)]
public string cAlternateFileName;
}
[DllImport("kernel32.dll", CharSet = CharSet.Auto)]
static extern IntPtr FindFirstFile(string lpFileName, out WIN32_FIND_DATA lpFindFileData);
When you call the FindFirstFile method in the preceding code listing, the CLR loads the DLL that is exporting the function (kernel32.dll), locates the desired function (FindFirstFile), and translates parameter types from their managed to native representations (and vice versa). In this example, the input lpFileName string parameter is translated to a native string, whereas writes to the WIN32_FIND_DATAW native structure pointed to by the lpFindFileData parameter are translated to writes to the managed WIN32_FIND_DATA structure. In the following sections, we will describe in detail each of these stages.
PInvoke.net and P/Invoke Interop Assistant
Creating P/Invoke signatures can be hard and tedious. There are many rules to obey and many nuances to know. Producing an incorrect signature can result in hard to diagnose bugs. Fortunately, there are two resources which make this easier: the PInvoke.net website and the P/Invoke Interop Assistant tool.
PInvoke.net is a very helpful Wiki-style website, where you can find and contribute P/Invoke signatures for various Microsoft APIs. PInvoke.net was created by Adam Nathan, a senior software development engineer at Microsoft who previously worked on the .NET CLR Quality Assurance team and has written an extensive book about COM interoperability. You can also download a free Visual Studio add-on to access P/Invoke signatures without leaving Visual Studio.
P/Invoke Interop Assistant is a free tool from Microsoft downloadable from CodePlex, along with source code. It contains a database (an XML file) describing Win32 functions, structures, and constants which are used to generate a P/Invoke signature. It can also generate a P/Invoke signature given a C function declaration, and can generate native callback function declaration and native COM interface signature given a managed assembly.
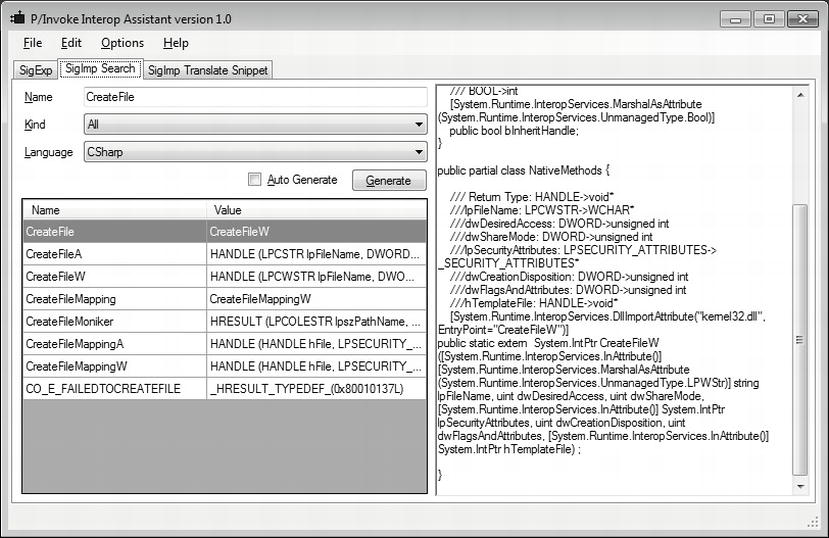
Figure 8-3 . Screenshot of P/Invoke Interop Asssitant showing the P/Invoke signature for CreateFile
Figure 8-3 shows Microsoft’s P/Invole Interop Assistant tool showing the search results for “CreateFile” on the left side and the P/Invoke signature along with associated structures is shown on the right. The P/Invoke Interop Assistant tool (along with other useful CLR interop-related tools) can be obtained from http://clrinterop.codeplex.com/ .
When you first call a P/Invoke’d function, the native DLL and its dependencies are loaded into the process via the Win32 LoadLibrary function (if they’ve not already been loaded). Next, the desired exported function is searched for, possibly searching for mangled variants first. Search behavior depends on the values of the CharSet and ExactSpelling fields of DllImport.
- If ExactSpelling is true, P/Invoke searches only for a function with the exact name, taking into account only the calling convention mangling. If this fails, P/Invoke will not continue searching for other name variations and will throw an EntryPointNotFoundException.
- If ExactSpelling is false, then behavior is determined by the CharSet property:
- If set to CharSet.Ansi (default), P/Invoke searches the exact (unmangled) name first, and then the mangled name (with “A” appended).
- If set to CharSet.Unicode, P/Invoke searches the mangled name first (with “W” appended), and then the unmanaged name.
The default value for ExactSpelling is false for C# and True for VB.NET. The CharSet.Auto value behaves like CharSet.Unicode on any modern operating system (later than Windows ME).
![]() Tip Use the Unicode versions of Win32 functions. Windows NT and beyond are natively Unicode (UTF16). If you call the ANSI versions of Win32 functions, strings are converted to Unicode which results in a performance penalty, and the Unicode version of the function is called. The .NET string representation is also natively UTF16, so marshaling string parameters is faster if they are already UTF16. Design your code and especially the interface to be Unicode-compatible, which has globalization benefits as well. Set ExactSpelling to true, which will speed up initial load time by eliminating an unnecessary function search.
Tip Use the Unicode versions of Win32 functions. Windows NT and beyond are natively Unicode (UTF16). If you call the ANSI versions of Win32 functions, strings are converted to Unicode which results in a performance penalty, and the Unicode version of the function is called. The .NET string representation is also natively UTF16, so marshaling string parameters is faster if they are already UTF16. Design your code and especially the interface to be Unicode-compatible, which has globalization benefits as well. Set ExactSpelling to true, which will speed up initial load time by eliminating an unnecessary function search.
When you first call a P/Invoke’d function, right after loading the native DLL, a P/Invoke marshaler stub will be generated on demand, and will be re-used for subsequent calls. The marshaler performs the following steps once called:
- Checks for callers’ unmanaged code execution permissions.
- Converts managed arguments to their appropriate native in-memory representation, possibly allocating memory.
- Sets thread’s GC mode to pre-emptive, so GC can occur without waiting the thread to reach a safe point.
- Calls the native function.
- Restores thread GC mode to co-operative.
- Optionally saves Win32 error code in Thread Local Storage for later retrieval by Marshal.GetLastWin32Error.
- Optionally converts HRESULT to an exception and throws it.
- Converts native exception if thrown to a managed exception.
- Converts the return value and output parameters back to their managed in-memory representations.
- Cleans up any temporarily allocated memory.
P/Invoke can also be used to call managed code from native code. A reverse marshaler stub can be generated for a delegate (via Marshal.GetFunctionPointerForDelegate) if it is passed as a parameter in a P/Invoke call to a native function. The native function will receive a function pointer in place of the delegate, which it can call to invoke the managed method. The function pointer points to a dynamically generated stub which in addition to parameter marshaling, also knows the target object’s address (this pointer).
In .NET Framework 1.x, marshaler stubs consisted of either generated assembly code (for simple signatures) or of generated ML (Marshaling Language) code (for complex signatures). ML is an internal byte code and is executed by an internal interpreter. With the introduction of AMD64 and Itanium support in .NET Framework 2.0, Microsoft realized that implementing a parallel ML infrastructure for every CPU architecture would be a great burden. Instead, stubs for 64-bit versions of .NET Framework 2.0 were implemented exclusively in generated IL code. While the IL stubs were significantly faster than the interpreted ML stubs, they were still slower than the x86 generated assembly stubs, so Microsoft opted to retain the x86 implementation. In .NET Framework 4.0, the IL stub generation infrastructure was significantly optimized, which made IL stubs faster compared even to the x86 assembly stubs. This allowed Microsoft to remove the x86-specific stub implementation entirely and to unify stub generation across all architectures.
![]() Tip A function call that crosses the managed-to-native boundary is at least an order of magnitude slower than a direct call within the same environment. If you’re in control of both the native and managed code, construct the interface in a way that minimizes native-to-managed round trips (chatty interfaces). Try to combine several “work items” into one call (chunked interfaces). Similarly, combine invocations of several trivial functions (e.g.trivial Get/Set functions) into a façade which does equivalent work in one call.
Tip A function call that crosses the managed-to-native boundary is at least an order of magnitude slower than a direct call within the same environment. If you’re in control of both the native and managed code, construct the interface in a way that minimizes native-to-managed round trips (chatty interfaces). Try to combine several “work items” into one call (chunked interfaces). Similarly, combine invocations of several trivial functions (e.g.trivial Get/Set functions) into a façade which does equivalent work in one call.
Microsoft provides a freely downloadable tool called IL Stub Diagnostics from CodePlex along with source code. It subscribes to the CLR ETW IL stub generation/cache hit events and displays the generated IL stub code in the UI.
Below we show an annotated example IL marshaling stub, consisting of five sections of code: initialization, marshaling of input parameters, invocation, marshaling back of return value and/or output parameters and cleanup. The marshaler stub is for the following signature:
// Managed signature:
[DllImport("Server.dll")]static extern int Marshal_String_In(string s);
// Native Signature:
unmanaged int __stdcall Marshal_String_In(char *s)
In the initialization section, the stub declares local (stack) variables, obtains a stub context and demands unmanaged code execution permissions.
// IL Stub:
// Code size 153 (0x0099)
.maxstack 3
// Local variables are:
// IsSuccessful, pNativeStrPtr, SizeInBytes, pStackAllocPtr, result, result, result
.locals (int32,native int,int32,native int,int32,int32,int32)
call native int [mscorlib] System.StubHelpers.StubHelpers::GetStubContext()
// Demand unmanaged code execution permissioncall void [mscorlib] System.StubHelpers.StubHelpers::DemandPermission(native int)
In the marshaling section, the stub marshals input parameters native function. In this example, we marshal a single string input parameter. The marshaler may call helper types under the System.StubHelpersnamespace or the System.Runtime.InteropServices.Marshal class to assist in converting of specific types and of type categories from managed to native representation and back. In this example, we call CSTRMarshaler::ConvertToNative to marshal the string.
There’s a slight optimization here: if the managed string is short enough, it is marshaled to memory allocated on the stack (which is faster). Otherwise, memory has to be allocated from the heap.
ldc.i4 0x0 // IsSuccessful = 0 [push 0 to stack]
stloc.0 // [store to IsSuccessful]
IL_0010:
nop // argument {
ldc.i4 0x0 // pNativeStrPtr = null [push 0 to stack]
conv.i // [convert to an int32 to "native int" (pointer)]
stloc.3 // [store result to pNativeStrPtr]
ldarg.0 // if (managedString == null)
brfalse IL_0042 // goto IL_0042
ldarg.0 // [push managedString instance to stack]
// call the get Length property (returns num of chars)
call instance int32 [mscorlib] System.String::get_Length()
ldc.i4 0x2 // Add 2 to length, one for null char in managedString and
// one for an extra null we put in [push constant 2 to stack]
add // [actual add, result pushed to stack]
// load static field, value depends on lang. for non-Unicode
// apps system setting
ldsfld System.Runtime.InteropServices.Marshal::SystemMaxDBCSCharSize
mul // Multiply length by SystemMaxDBCSCharSize to get amount of
// bytes
stloc.2 // Store to SizeInBytes
ldc.i4 0x105 // Compare SizeInBytes to 0x105, to avoid allocating too much
// stack memory [push constant 0x105]
// CSTRMarshaler::ConvertToNative will handle the case of
// pStackAllocPtr == null and will do a CoTaskMemAlloc of the
// greater size
ldloc.2 // [Push SizeInBytes]
clt // [If SizeInBytes > 0x105, push 1 else push 0]
brtrue IL_0042 // [If 1 goto IL_0042]
ldloc.2 // Push SizeInBytes (argument of localloc)
localloc // Do stack allocation, result pointer is on top of stack
stloc.3 // Save to pStackAllocPtr
IL_0042:
ldc.i4 0x1 // Push constant 1 (flags parameter)
ldarg.0 // Push managedString argument
ldloc.3 // Push pStackAllocPtr (this can be null)
// Call helper to convert to Unicode to ANSI
call native int [mscorlib]System.StubHelpers.CSTRMarshaler::ConvertToNative(int32,string, native int)
stloc.1 // Store result in pNativeStrPtr,
// can be equal to pStackAllocPtr
ldc.i4 0x1 // IsSuccessful = 1 [push 1 to stack]
stloc.0 // [store to IsSuccessful]
nop
nop
nop
In the next section, the stub obtains the native function pointer from the stub context and invokes it. The call instruction actually does more work than we can see here, such as changing the GC mode and catching the native function’s return in order to suspend execution of managed code while the GC is in progress and is in a phase that requires suspension of managed code execution.
ldloc.1 // Push pStackAllocPtr to stack,
// for the user function, not for GetStubContext
call native int [mscorlib] System.StubHelpers.StubHelpers::GetStubContext()
ldc.i4 0x14 // Add 0x14 to context ptr
add // [actual add, result is on stack]
ldind.i // [deref ptr, result is on stack]
ldind.i // [deref function ptr, result is on stack]
calli unmanaged stdcall int32(native int) // Call user function
The following section is actually structured as two sections that handle the “unmarshaling” (conversion of native types to managed types) of the return value and output parameters, respectively. In this example, the native function returns an int which does not require marshaling and is just copied as-is to a local variable. Since there are no output parameters, the latter section is empty.
// UnmarshalReturn {
nop // return {
stloc.s 0x5 // Store user function result (int) into x, y and z
ldloc.s 0x5
stloc.s 0x4
ldloc.s 0x4
nop // } return
stloc.s 0x6
// } UnmarshalReturn
// Unmarshal {
nop // argument {
nop // } argument
leave IL_007e // Exit try protected block
IL_007e:
ldloc.s 0x6 // Push z
ret // Return z
// } Unmarshal
Finally, the cleanup section releases memory that was allocated temporarily for the sake of marshaling. It performs cleanup in a finally block so that cleanup happens even if an exception is thrown by the native function. It may also perform some cleanup only in case of an exception. In COM interop, it may translate an HRESULT return value indicating an error into an exception.
// ExceptionCleanup {
IL_0081:
// } ExceptionCleanup
// Cleanup {
ldloc.0 // If (IsSuccessful && !pStackAllocPtr)
ldc.i4 0x0 // Call ClearNative(pNativeStrPtr)
ble IL_0098
ldloc.3
brtrue IL_0098
ldloc.1
call void [mscorlib] System.StubHelpers.CSTRMarshaler::ClearNative(native int)
IL_0098:
endfinally
IL_0099:
// } Cleanup
.try IL_0010 to IL_007e finally handler IL_0081 to IL_0099
In conclusion, the IL marshaler stub is non-trivial even for this trivial function signature. Complex signatures result in even lengthier and slower IL marshaler stubs.
Most native types share a common in-memory representation with managed code. These types, called blittable types, do not require conversion, and are passed as-is across managed-to-native boundaries, which is significantly faster than marshaling non-blittable types. In fact, the marshaler stub can optimize this case even further by pinning a managed object and passing a direct pointer to the managed object to native code, avoiding one or two memory copy operations (one for each required marshaling direction).
A blittable type is one of the following types:
- System.Byte (byte)
- System.SByte (sbyte)
- System.Int16 (short)
- System.UInt16 (ushort)
- System.Int32 (int)
- System.UInt32 (uint)
- Syste.Int64 (long)
- System.UInt64 (ulong)
- System.IntPtr
- System.UIntPtr
- System.Single (float)
- System.Double (double)
In addition, a single-dimensional array of blittable types (where all elements are of the same type) is also blittable, so is a structure or class consisting solely of blittable fields.
A System.Boolean (bool) is not blittable because it can have 1, 2 or 4 byte representation in native code, a System.Char (char) is not blittable because it can represent either an ANSI or Unicode character and a System.String (string) is not blittable because its native representation can be either ANSI or Unicode, and it can be either a C-style string or a COM BSTR and the managed string needs to be immutable (which is risky if the native code modifies the string, breaking immutability). A type containing an object reference field is not blittable, even if it’s a reference to a blittable type or an array thereof. Marshaling non-blittable types involves allocation of memory to hold a transformed version of the parameter, populating it appropriately and finally releasing of previously allocated memory.
You can get better performance by marshaling string input parameters manually (see the following code for an example). The native callee must take a C-style UTF-16 string and it should never write to the memory occupied by the string, so this optimization is not always possible. Manual marshaling involves pinning the input string and modifying the P/Invoke signature to take an IntPtr instead of a string and passing a pointer to the pinned string object.
class Win32Interop {
[DllImport("NativeDLL.DLL", CallingConvention = CallingConvention.Cdecl)]
public static extern void NativeFunc(IntPtr pStr); // takes IntPtr instead of string
}
//Managed caller calls the P/Invoke function inside a fixed scope which does string pinning:
unsafe
{
string str = "MyString";
fixed (char *pStr = str) {
//You can reuse pStr for multiple calls.
Win32Interop.NativeFunc((IntPtr)pStr);
}
}
Converting a native C-style UTF-16 string to a managed string can also be optimized by using System.String’sconstructor taking a char* as parameter. The System.String constructor will make a copy of the buffer, so the native pointer can be freed after the managed string has been created. Note that no validation is done to ensure that the string only contains valid Unicode characters.
Marshaling Direction, Value and Reference Types
As mentioned earlier, function parameters can be marshaled by the marshaler stub in either or both directions. Which direction a parameter gets marshaled is determined by a number of factors:
- Whether the parameter is a value or reference type.
- Whether the parameter is being passed by value or by reference.
- Whether the type is blittable or not.
- Whether marshaling direction-modifying attributes (System.RuntimeInteropService.InAttribute and System.RuntimeInteropService.OutAttribute) are applied to the parameter.
For the purposes of this discussion, we define the “in” direction to be the managed to native marshaling direction; conversely the “out” direction is the native to managed direction. Below is a list of default marshaling direction rules:
- Parameters passed by value, regardless whether they’re value or reference types, are marshaled in the “in” direction only.
- You do not need to apply the In attribute manually.
- StringBuilder is an exception to this rule and is always marshaled “in/out”.
- Parameters passed by reference (via the ref C# keyword or the ByRef VB .NET keyword), regardless whether they’re value or reference types, are marshaled “in/out”.
Specifying the OutAttribute alone will inhibit the “in” marshaling, so the native callee may not see initializations done by the caller. The C# out keyword behaves like ref keyword but adds an OutAttribute.
![]() Tip If parameters are not blittable in a P/Invoke call, and you require marshaling in only the “out” direction, you can avoid unnecessary marshaling by using the out C# keyword instead of the ref keyword.
Tip If parameters are not blittable in a P/Invoke call, and you require marshaling in only the “out” direction, you can avoid unnecessary marshaling by using the out C# keyword instead of the ref keyword.
Due to the blittable parameter pinning optimization mentioned above, blittable reference types will get an effective “in/out” marshaling, even if the above rules tell otherwise. You should not rely on this behavior if you need “out” or “in/out” marshaling behavior, but instead you should specify direction attributes explicitly, as this optimization will stop working if you later add a non-blittable field or if this is a COM call that crosses an apartment boundary.
The difference between marshaling value types versus reference types manifests in how they are passed on the stack.
- Value types passed by value are pushed as copies on the stack, so they are effectively always marshaled “in”, regardless of modifying attributes.
- Value types passed by reference and reference types passed by value are passed by pointer.
- Reference types passed by reference are passed as pointer to a pointer.
![]() Note Passing large value type parameters (more than a dozen or so bytes long) by value is more expensive than passing them by reference. The same goes for large return values, where out parameters are a possible alternative.
Note Passing large value type parameters (more than a dozen or so bytes long) by value is more expensive than passing them by reference. The same goes for large return values, where out parameters are a possible alternative.
The .NET Code Access Security mechanism enables running partially trusted code in a sandbox, with restricted access to runtime capabilities (e.g. P/Invoke) and BCL functionality (e.g. file and registry access). When calling native code, CAS requires that all assemblies whose methods appear in the call stack to have the UnmanagedCode permission. The marshaler stub will demand this permission for each call, which involves walking the call stack to ensure that all code has this permission.
![]() Tip If you run only fully trusted code or you have other means to ensure security, you can gain a substantial performance increase by placing the SuppressUnmanagedCodeSecurityAttribute on the P/Invoke method declaration, a class (in which case it applies to contained methods), an interface or a delegate.
Tip If you run only fully trusted code or you have other means to ensure security, you can gain a substantial performance increase by placing the SuppressUnmanagedCodeSecurityAttribute on the P/Invoke method declaration, a class (in which case it applies to contained methods), an interface or a delegate.
COM Interoperability
COM was designed for the very purpose of writing components in any COM-capable language/platform and consumption thereof in any (other) COM-capable language/platform. .NET is no exception, and it allows you to easily consume COM objects and expose .NET types as COM objects.
With COM interop, the basic idea is the same as in P/Invoke: you declare a managed representation of the COM object and the CLR created a wrapper object that handles the marshaling. There are two kinds of wrappers: Runtime Callable Wrapper (RCW) which enables managed code to use COM objects (see Figure 8-4), and COM Callable Wrapper (CCW) that enables COM code to call managed types (see Figure 8-5). Third party COM components are often shipped with a Primary Interop Assembly, which contains vendor-approved interop definitions and is strongly named (signed) and installed in the GAC . Other times, you can use the tlbimp.exe tool, which is part of the Windows SDK to auto-generate an interop assembly based on the information contained in the type library.
COM interop re-uses the P/Invoke parameter marshaling infrastructure, with some changes in defaults (e.g. a string is marshaled to BSTR by default), so the advice provided in the P/Invoke section of this chapter applies here as well.
COM has its own performance issues resulting from COM-specific particularities such as the apartment threading model and a mismatch between the the reference counted nature of COM and the .NET garbage collected approach.
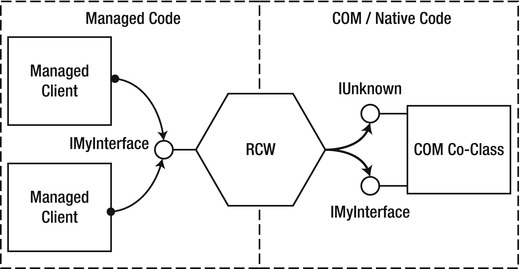
Figure 8-4 . Managed client calling unmanaged COM object
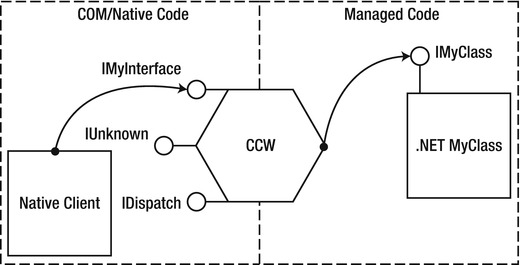
Figure 8-5 . Unmanaged client calling a managed COM object
When you hold a reference to a COM object in .NET, you are actually holding a reference to an RCW. The RCW always holds a single reference to the underlying COM object and there is only one RCW instance per COM object. The RCW maintains its own reference count, separate from the COM reference count. This reference count’s value is usually one but can be greater if a number of interface pointers have been marshaled or if the same interface has been marshaled by multiple threads.
Normally, when the last managed reference to the RCW is gone and there is a subsequent garbage collection at the generation where the RCW resides; the RCW’s finalizer runs and it decrements the COM objects’s reference count (which was one) by calling the Release method on the IUnknown interface pointer for the COM underlying object. The COM object subsequently destroys itself and releases its memory.
Since the .NET GC runs at non-deterministic times and is not aware of the unmanaged memory burden caused by it holding the RCWs and subsequently COM objects alive, it will not hasten garbage collections and memory usage may become be very high.
If necessary, you can call the Marshal.ReleaseComObject method to explicitly release the object. Each call will decrement RCW’s reference count and when it reaches zero, the underlying COM object’s reference count will be decremented (just like in the case of the RCW’s finalizer running), thus releasing it. You must ensure that you do not continue to use the RCW after calling Marshal.ReleaseComObject. If the RCW reference count is greater than zero, you will need to call Marshal.ReleaseComObject in a loop until the return value equals zero. It is a best practice to call Marshal.ReleaseComObject inside a finally block, to ensure that the release occurs even in the case of an exception being thrown somewhere between the instantiation and the release of the COM object.
Apartment Marshaling
COM implements its own thread synchronization mechanisms for managing cross-thread calls, even for objects not designed for multi-threading. These mechanisms can degrade performance if one is not aware of them. While this issue is not specific for interoperability with .NET, it is nonetheless worth discussing as it is a common pitfall, likely because developers that are accustomed to typical .NET thread synchronizations conventions might be unaware of what COM is doing behind the scenes.
COM assigns objects and threads apartments which are boundaries across which COM will marshal calls. COM has several apartment types:
- Single–threaded apartment (STA), each hosts a single thread, but can host any number of objects. There can be any number of STA apartments in a process.
- Multi–threaded apartment (MTA), hosts any number of threads and any number of objects,but there is only one MTA apartment in a process. This is the default for .NET threads.
- Neutral-threaded apartment (NTA), hosts objects but not threads. There is only one NTA apartment in a process.
A thread is assigned to an apartment when a call is made to CoInitialize or CoInitializeEx to initialize COM for that thread. Calling CoInitialize will assign the thread to a new STA apartment, while CoInitializeEx allows you to specify either an STA or an MTA assignment. In .NET, you do not call those functions directly, but instead mark a thread’s entry point (or Main) with the STAThread or MTAThread attribute. Alternatively, you can call Thread.SetApartmentState method or the Thread.ApartmentState property before a thread is started. If not otherwise specified, .NET initializes threads (including the main thread) as MTA.
COM objects are assigned to apartments based on the ThreadingModel registry value, which can be:
- Single – object resides in the default STA.
- Apartment (STA) – object must reside in any STA, and only that STA’s thread is allowed to call the object directly. Different instances can reside in different STA.
- Free (MTA) – object resides in the MTA. Any number of MTA threads can call it directly and concurrently. Object must ensure thread-safety.
- Both – object resides in the creator’s apartment (STA or MTA). In essense, it becomes either STA-like or MTA-like object once created.
- Neutral – object resides in the neutral apartment and never requires marshaling. This is the most efficient mode.
Refer to Figure 8-6 for a visual representation of apartments, threads and objects.
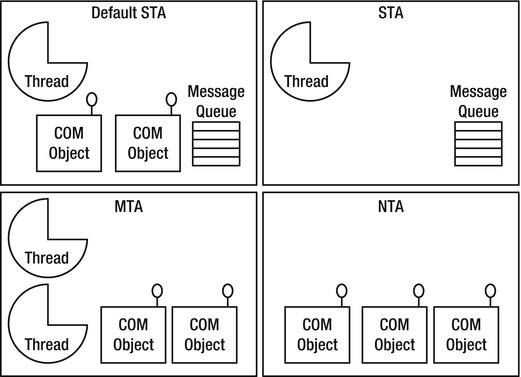
Figure 8-6 . Process division into COM apartments
If you create an object with a threading model incompatible with that of the creator thread’s apartment, you will receive an interface pointer which actually points to a proxy. If the COM object’s interface needs to be passed to a different thread belonging to a different apartment, the interface pointer should not be passed directly, but instead needs to be marshaled. COM will return a proxy object as appropriate.
Marshaling involves translating the function’s call (including parameters) to a message which will be posted to the recipient STA apartment’s message queue. For STA objects, this is implemented as a hidden window whose window procedure receives the messages and dispatches calls to the COM object via a stub. In this way, STA COM objects are always invoked by the same thread, which is obviously thread-safe.
When the caller’s apartment is incompatible with the COM object’s apartment, a thread switch and cross-thread parameter marshaling occurs.
![]() Tip Avoid the cross-thread performance penalty by matching the COM object’s apartment with the creating thread’s apartment. Create and use apartment threaded (STA) COM objects on STA threads, and free-threaded COM objects on MTA threads. COM objects marked as supporting both modes can be used from either thread without penalty.
Tip Avoid the cross-thread performance penalty by matching the COM object’s apartment with the creating thread’s apartment. Create and use apartment threaded (STA) COM objects on STA threads, and free-threaded COM objects on MTA threads. COM objects marked as supporting both modes can be used from either thread without penalty.
CALLING STA OBJECTS FROM ASP.NET
ASP.NET executes pages on MTA threads by default. If you call STA objects, they undergo marshaling. If you predominantly call STA objects, this will degrade performance. You can remedy this by marking pages with the ASPCOMPAT attribute, as follows:
Note that page constructors still executes in an MTA thread, so defer creating STA objects to Page_Load and Page_Init events.
TLB Import and Code Access Security
Code Access Security does the same security checking as in P/Invoke. You can use the /unsafe switch with the tlbimp.exe utility which will emit the SuppressUnmanagedCodeSecurity attribute on generated types. Use this only in full-trust environments as this may introduce security issues.
Prior to .NET Framework 4.0, you had to distribute interop assemblies or Primary Interop Assemblies (PIA) alongside with your application or add-in. These assemblies tend to be large (even more so compared to the code that uses them), and they are not typically installed by the vendor of the COM component; instead they are installed as redistributable packages, because they are not required for the operation of the COM component itself. Another reason for not installing the PIAs is that they have to be installed in the GAC, which imposes a .NET Framework dependency on the installer of an otherwise completely native application.
Starting with .NET Framework 4.0, the C# and VB.NET compilers can examine which COM interfaces and which methods within them are required, and can copy and embed only the required interface definitions into the caller assembly, eliminating the need to distribute PIA DLLs and reducing code size. Microsoft calls this feature NoPIA. It works both for Primary Interop Assemblies and for interop assemblies in general.
PIA assemblies had an important feature called type equivalence. Since they have a strong name and are put into the GAC, different managed components can exchange the RCWs, and from .NET’s perspective, they would have equivalent type. In contrast, interop assemblies generated by tlbimp.exe would not have this feature, since each component would have its own distinct interop assembly. With NoPIA, since there is a strongly named assembly is not used, Microsoft came up with a solution which treats RCWs from different assemblies as the same type, as long as the interfaces have the same GUID.
To enable NoPIA, select Properties on the interop assembly under References, and set “Embed Interop Types” to True (see Figure 8-7).
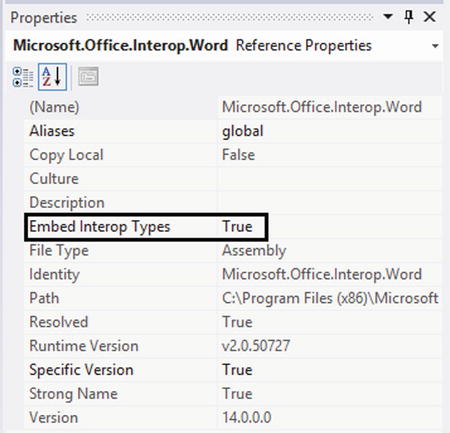
Figure 8-7 . Enabling NoPIA in interop assembly reference properties
Most COM interface methods report success or failure via an HRESULT return value. Negative HRESULT values (with most significant bit set) indicate failure, while zero (S_OK) or positive values report success. Additionally, a COM object may provide richer error information by calling the SetErrorInfo function, passing an IErrorInfo object which is created by calling CreateErrorInfo. When calling a COM method via COM interop, the marshaler stub converts the HRESULT into a managed exception according to the HRESULT value and the data contained inside the IErrorInfo object. Since throwing exceptions is relatively expensive, COM functions that fail frequently will negatively impact performance. You can suppress automatic exception translation by marking methods with the PreserveSigAttribute. You will have to change the managed signature to return an int, and the retval parameter will become an “out” parameter.
C++/CLI is a set of C++ language extensions, which enables creating hybrid managed and native DLLs. In C++/CLI, you can have both managed and unmanaged classes or functions even within the same .cpp file. You can use both managed types as well as native C and C++ types, just as you would in ordinary C++, i.e. by including a header and linking against the library. These powerfulcapabilities can be used to construct managed wrapper types callable from any .NET language as well as native wrapper classes and functions (exposed as .dll, .lib and .h files) which are callable by native C/C++ code.
Marshaling in C++/CLI is done manually, and the developer is in bettercontrol and more aware of marshaling performance penalties. C++/CLI can be successfully used in scenarios with which P/Invoke cannot cope, such as marshaling of variable-length structures. Another advantage to C++/CLI is that you can simulate a chunky interface approach even if you do not control the callee’s code, by calling native methods repeatedly without crossing the managed-to-native boundary each time.
In the code listing below, we implement a native NativeEmployee class and a managed Employee class, wrapping the former. Only the latter is accessible from managed code.
If you look at the listing, you’ll see that Employee’s constructor showcases two techniques of managed to native string conversion: one that allocates GlobalAlloc memory that needs to be released explicitly and one that temporarily pins the managed string in memory and returns a direct pointer. The latter method is faster, but it only works if the native code expects a UTF-16 null-terminated string, and you can guarantee that no writes occur to the memory pointed to by the pointer. Furthermore, pinning managed objects for a long time can lead to memory fragmentation (see Chapter 4), so if said requirements are not satisfied, you will have to resort to copying.
Employee’s GetName method showcases three techniques of native to managed string conversion: one that uses the System.Runtime.InteropServices.Marshal class, one that uses the marshal_as template function (that we will discuss later) which is defined in the msclr/marshal.h header file and finally one that uses System.String’s constructor, which is the fastest.
Employee’s DoWork method takes a managed array or managed strings, and converts that into an array of wchar_t pointers, each pointing to a string; in essence it’s an array of C-style strings. Managed to native string conversions are done via the marshal_context’s marshal_as method. In contrast to marshal_as global function, marshal_context is used for conversions which require cleanup. Usually these are managed to unmanaged conversions that allocate unmanaged memory during the call to marshal_as that needs to be released once it’s not longer required. The marshal_context object contains a linked list of cleanup operations that are executed when it is destroyed.
#include <msclr/marshal.h>
#include <string>
#include <wchar.h>
#include <time.h>
using namespace System;
using namespace System::Runtime::InteropServices;
class NativeEmployee {
public:
NativeEmployee(const wchar_t *employeeName, int age)
: _employeeName(employeeName), _employeeAge(age) { }
void DoWork(const wchar_t **tasks, int numTasks) {
for (int i = 0; i < numTasks; i++) {
wprintf(L"Employee %s is working on task %s ",
_employeeName.c_str(), tasks[i]);
}
}
int GetAge() const {
return _employeeAge;
}
const wchar_t *GetName() const {
return _employeeName.c_str();
}
private:
std::wstring _employeeName;
int _employeeAge;
};
#pragma managed
namespace EmployeeLib {
public ref class Employee {
public:
Employee(String ^employeeName, int age) {
//OPTION 1:
//IntPtr pEmployeeName = Marshal::StringToHGlobalUni(employeeName);
//m_pEmployee = new NativeEmployee(
// reinterpret_cast<wchar_t *>(pEmployeeName.ToPointer()), age);
//Marshal::FreeHGlobal(pEmployeeName);
//OPTION 2 (direct pointer to pinned managed string, faster):
pin_ptr<const wchar_t> ppEmployeeName = PtrToStringChars(employeeName);
_employee = new NativeEmployee(ppEmployeeName, age);
}
∼Employee() {
delete _employee;
_employee = nullptr;
}
int GetAge() {
return _employee->GetAge();
}
String ^GetName() {
//OPTION 1:
//return Marshal::PtrToStringUni(
// (IntPtr)(void *) _employee->GetName());
//OPTION 2:
return msclr::interop::marshal_as<String ^>(_employee->GetName());
//OPTION 3 (faster):
return gcnew String(_employee->GetName());
}
void DoWork(array<String^>^ tasks) {
//marshal_context is a managed class allocated (on the GC heap)
//using stack-like semantics. Its IDisposable::Dispose()/d’tor will
//run when exiting scope of this function.
msclr::interop::marshal_context ctx;
const wchar_t **pTasks = new const wchar_t*[tasks->Length];
for (int i = 0; i < tasks->Length; i++) {
String ^t = tasks[i];
pTasks[i] = ctx.marshal_as<const wchar_t *>(t);
}
m_pEmployee->DoWork(pTasks, tasks->Length);
//context d’tor will release native memory allocated by marshal_as
delete[] pTasks;
}
private:
NativeEmployee *_employee;
};
}
In summary, C++/CLI offers fine control over marshaling and does not require duplicating function declarations, which is error prone, especially when you often change the native function signatures.
In this section, we will elaborate on the marshal_as helper library provided as part of Visual C++ 2008 and later.
marshal_as is a template library for simplified and convenient marshaling of managed to native types and vice versa. It can marshal many native string types, such as char *, wchar_t *, std::string, std::wstring, CStringT<char>, CStringT<wchar_t>, BSTR, bstr_t and CComBSTR to managed types and vice versa. It handles Unicode/ANSI conversions and handles memory allocations/release automatically.
The library is declared and implemented inline in marshal.h (for base types), in marshal_windows.h (for Windows types), in marshal_cppstd.h (for STL data types) and in marshal_atl.h (for ATL data types).
marshal_as can be extended to handle conversion of user-defined types. This helps avoid code duplication when marshaling the same type in many places and allows having a uniform syntax for marshaling of different types.
The following code is an example of extending marshal_as to handle conversion of a managed array of strings to an equivalent native array of strings.
namespace msclr {
namespace interop {
template<>
ref class context_node<const wchar_t**, array<String^>^> : public context_node_base {
private:
const wchar_t** _tasks;
marshal_context _context;
public:
context_node(const wchar_t**& toObject, array<String^>^ fromObject) {
//Conversion logic starts here
_tasks = NULL;
const wchar_t **pTasks = new const wchar_t*[fromObject->Length];
for (int i = 0; i < fromObject->Length; i++) {
String ^t = fromObject[i];
pTasks[i] = _context.marshal_as<const wchar_t *>(t);
}
toObject = _tasks = pTasks;
}
∼context_node() {
this->!context_node();
}
protected:
!context_node() {
//When the context is deleted, it will free the memory
//allocated for the strings (belongs to marshal_context),
//so the array is the only memory that needs to be freed.
if (_tasks != nullptr) {
delete[] _tasks;
_tasks = nullptr;
}
}
};
}
}
//You can now rewrite Employee::DoWork like this:
void DoWork(array<String^>^ tasks) {
//All unmanaged memory is freed automatically once marshal_context
//gets out of scope.
msclr::interop::marshal_context ctx;
_employee->DoWork(ctx.marshal_as<const wchar_t **>(tasks), tasks->Length);
}
An unmanaged class will by default be compiled to IL code in C++/CLI rather than to machine code. This can degrade performance relative to optimized native code, because Visual C++ compiler can optimize code better than the JIT can.
You can use #pragma unmanaged and #pragma managed before a section of code to override complication behavior. Additionally, in a VC++ project you can also enable C++/CLI support for individual compilation units (.cpp files).
Windows Runtime (WinRT) is the new platform designed for Windows 8 Metro-style applications. WinRT is implemented in native code (i.e. .NET Framework is not used by WinRT), but you can target WinRT from C++/CX, .NET languages or JavaScript. WinRT replaces a large portion of Win32 and .NET BCL, which become inaccessible. WinRT places an emphasis on asynchrony, making it mandatory for any operation potentially taking more than 50ms to complete. This is done to ensure smooth UI performance which is especially important for touch-based user interfaces like Metro.
WinRT is built on top of an advanced version of COM. Below are some differences between WinRT and COM:
- Objects are created using RoCreateInstance.
- All objects implement the IInspectable interface which in turn derives from the familiar IUnknown interface.
- Supports .NET-style properties, delegates and events (instead of sinks).
- Supports parameterized interfaces (“generics”).
- Uses the .NET metadata format (.winmd files) instead of TLB and IDL.
- All types derive from Platform::Object.
Despite borrowing many ideas from .NET, WinRT is implemented entirely in native code, so the CLR is not required when calling WinRT from a non-.NET language.
Microsoft implemented language projections that map WinRT concepts to language-specific concepts, whether the language in C++/CX, C# or JavaScript. For example, C++/CX is a new language extension of C++ which manages reference counting automatically, translates WinRT object activation (RoActivateInstance) to a C++ constructor, converts HRESULTs to exceptions, converts “retval” arguments to return values, etc.
When the caller and callee are both managed, the CLR is smart enough to make the call directly and there is not inerop involved. For calls that cross a native to managed boundary, regular COM interop is involved. When both the caller and callee are implemented in C++, and the callee’s header files are available to the caller, no COM interop is involved and the call is very fast, otherwise, a COM QueryInterface needs to be done.
Best Practices for Interop
The following is a summary list of best practices for high-performance interop:
- Design interfaces to avoid native-managed transitions, by chunking (combining) work.
- Reduce round trips with a façade.
- Implement IDisposable if unmanaged resources are held across calls.
- Consider using memory pooling or unmanaged memory.
- Consider using unsafe code for re-interpreting data (e.g. in network protocols).
- Explicitly name the function you call and use ExactSpelling=true.
- Use blittable parameter types whenever possible.
- Avoid Unicode to ANSI conversions where possible.
- Manually marshall strings to/from IntPtr.
- Use C++/CLI for better control and performance for C/C++ and COM interop.
- Specify [In] and [Out] attributes to avoid unnecessary marshaling.
- Avoid long lifetime for pinned objects.
- Consider calling ReleaseComObject.
- Consider using SuppressUnmanagedCodeSecurityAttribute for performance-critical full- trust scenarios.
- Consider using TLBIMP /unsafe for performance-critical full-trust scenarios.
- Reduce or avoid COM cross-apartment calls.
- If appropriate, use ASPCOMPAT attribute in ASP.NET to reduce or avoid COM cross-apartment calls.
Summary
In this chapter, you have learned about unsafe code, about how the various interop mechanisms are implemented, how each implementation detail can have a profound impact on performance, and how to mitigate it. You’ve been introduced to best practices and techniques for improving interop performance and making coding easier and less error prone (e.g. help with P/Invoke signature generation and the marshal_as library).