
Before next chapter's deep dive into a real ASP.NET MVC e-commerce development experience, it's important to make sure you're familiar with the architecture, design patterns, tools, and techniques that we'll be using. By the end of this chapter, you'll know about the following:
MVC architecture
Domain models and service classes
Creating loosely coupled systems using a dependency injection (DI) container
The basics of automated testing
C# 3 language features that all ASP.NET MVC developers need to understand
You might never have encountered these topics before, or you might already be quite comfortable with some combination of them. Feel free to skip ahead if you hit familiar ground. For most readers, this chapter will contain a lot of new material, and even though it's only a brief outline, it will put you in a strong position to use the MVC Framework effectively.
You should understand by now that ASP.NET MVC applications are built with MVC architecture. But what exactly does that mean, and what is the point of it anyway? In high-level terms, it means that your application will be split into (at least) three distinct pieces:
Models, which represent the things that users are browsing or editing. Sometimes you'll work with simple view models, which merely hold data that's being transferred between controllers and views, and at other times you'll create more sophisticated domain models that encapsulate the information, operations, and rules that are meaningful in the subject matter (business domain) of your application. For example, in a banking application, domain models might represent bank accounts and credit limits, their operations might include funds transfers, and their rules might require that accounts stay within credit limits. Domain models describe the state of your application's universe at the present moment, but are totally disconnected from any notion of a UI.
A set of views, which describe how to render model objects as a visible UI, but otherwise contain no logic.
A set of controllers, which handle incoming requests, perform operations on the domain model, and choose a view to render back to the user.
There are many variations on the MVC pattern—I'll explain the main ones in a moment. Each has its own terminology and slight difference of emphasis, but they all have the same primary goal: separation of concerns. By keeping a clear division between concerns, your application will be easier to maintain and extend over its lifetime, no matter how large it becomes. The following discussion will not labor over the precise academic or historical definitions of each possible twist on MVC; instead, you will learn why MVC is important and how it works effectively in ASP.NET MVC.
In some ways, the easiest way to understand MVC is to understand what it is not, so let's start by considering the alternatives.
To build a Smart UI application, a developer first constructs a UI, usually by dragging a series of UI widgets onto a canvas,[12] and then fills in event handler code for each possible button click or other UI event. All application logic resides in these event handlers: logic to accept and validate user input, to perform data access and storage, and to provide feedback by updating the UI. The whole application consists of these event handlers. Essentially, this is what tends to come out by default when you put a novice in front of Visual Studio.
In this design, there's no separation of concerns whatsoever. Everything is fused together, arranged only in terms of the different UI events that may occur. When logic or business rules need to be applied in more than one handler, the code is usually copied and pasted, or certain randomly chosen segments are factored out into static utility classes. For so many obvious reasons, this kind of design pattern is often called an anti-pattern.
Let's not sneer at Smart UI for too long. We've all developed applications like this, and in fact, the design has genuine advantages that make it the best possible choice in certain cases:
It delivers visible results extremely quickly. In just days or even hours, you might have something reasonably functional to show to a client or boss.
If a project is so small (and will always remain so small) that complexity will never be a problem, then the costs of a more sophisticated architecture outweigh their benefits.
It has the most obvious possible association between GUI elements and code subroutines. This leads to a very simple mental model for developers—hardly any cognitive friction—which might be the only viable option for development teams with less skill or experience. In that case, attempting a more sophisticated architecture may just waste time and lead to a worse result than Smart UI.
Copy/paste code has a natural (though perverse) kind of decoupling built in. During maintenance, you can change an individual behavior or fix an individual bug, without fear that your changes will affect any other parts of the application.
You have probably experienced the disadvantages of this design (anti) pattern firsthand. Such applications become exponentially harder to maintain as each new feature is added: there's no particular structure, so you can't possibly remember what each piece of code does; changes may need to be repeated in several places to avoid inconsistencies; and there's obviously no way to set up unit tests. Within one or two person-years, these applications tend to collapse under their own weight.
It's perfectly OK to make a deliberate choice to build a Smart UI application when you feel it's the best trade-off of pros and cons for a your project (in which case, use classic Web Forms, not ASP.NET MVC, because Web Forms has an easier event model), as long as your business recognizes the limited life span of the resulting software.
Given the limitations of Smart UI architecture, there's a widely accepted improvement that yields huge benefits for an application's stability and maintainability.
By identifying the real-world entities, operations, and rules that exist in the industry or subject matter you're targeting (the domain), and by creating a representation of that domain in software (usually an object-oriented representation backed by some kind of persistent storage system, such as a relational database or a document database), you're creating a domain model. What are the benefits of doing this?
First, it's a natural place to put business rules and other domain logic, so that no matter what particular UI code performs an operation on the domain (e.g., "open a new bank account"), the same business processes occur.
Second, it gives you an obvious way to store and retrieve the state of your application's universe at the current point in time, without duplicating that persistence code everywhere.
Third, you can design and structure the domain model's classes and inheritance graph according to the same terminology and language used by experts in your domain, permitting a ubiquitous language shared by your programmers and business experts, improving communication and increasing the chance that you deliver what the customer actually wants (e.g., programmers working on an accounting package may never actually understand what an accrual is unless their code uses the same terminology).
In a .NET application, it makes sense to keep a domain model in a separate assembly (i.e., a C# class library project—or several of them) so that you're constantly reminded of the distinction between domain model and application UI. You would have a reference from the UI project to the domain model project, but no reference in the opposite direction, because the domain model shouldn't know or care about the implementation of any UI that relies on it. For example, if you send a badly formed record to the domain model, it should return a data structure of validation errors, but would not attempt to display those errors on the screen in any way (that's the UI's job).
If the only separation in your application is between UI and domain model,[13] it's called model-view architecture (see Figure 3-1).

It's far better organized and more maintainable than Smart UI architecture, but still has two striking weaknesses:
The model component contains a mass of repetitious data access code that's specific to the vendor of the particular database being used. That will be mixed in among code for the business processes and rules of the true domain model, obscuring both.
Since both model and UI are tightly coupled to their respective database and GUI platforms, it's very hard to do unit testing on either, or to reuse any of their code with different database or GUI technologies.
Responding in part to these criticisms, three-tier architecture[14] cuts persistence code out of the domain model and places that in a separate, third component, called the data access layer (DAL) (see Figure 3-2).

Often—though not necessarily—the DAL is built according to the repository pattern, in which an object-oriented representation of a data store acts as a façade on top of a database. For example, you might have a class called OrdersRepository, having methods such as GetAllOrders() or DeleteOrder(int orderID). These will use the underlying database to fetch instances of model objects that match stated criteria (or delete them, update them, etc.). If you add in the abstract factory pattern, meaning that the model isn't coupled to any concrete implementation of a data repository, but instead accesses repositories only through .NET interfaces or abstract base classes, then the model becomes totally decoupled from the database technology. That means you can easily set up unit tests for its logic, using fake or mock repositories to simulate different conditions. You'll see this technique at work in the next chapter.
Three-tier is among the most widely adopted architectures for business software today, because it can provide a good separation of concerns without being too complicated, and because it places no constraints on how the UI is implemented, so it's perfectly compatible with a forms-and-controls-style GUI platform such as Windows Forms or ASP.NET Web Forms.
Three-tier architecture is perfectly good for describing the overall design of a software product, but it doesn't address what happens inside the UI layer. That's not very helpful when, as in many projects, the UI component tends to balloon to a vast size, amassing logic like a great rolling snowball. It shouldn't happen, but it does, because it's quicker and easier to attach behaviors directly to an event handler (a la Smart UI) than it is to refactor the domain model. When the UI layer is directly coupled to your GUI platform (Windows Forms, Web Forms), it's almost impossible to set up any automated tests on it, so all that sneaky new code escapes any kind of rigor. Three-tier's failure to enforce discipline in the UI layer means, in the worst case, that you can end up with a Smart UI application with a feeble parody of a domain model stuck on its side.
Recognizing that even after you've factored out a domain model, UI code can still be big and complicated, MVC architecture splits that UI component in two (see Figure 3-3).

In this architecture, requests are routed to a controller class, which processes user input and works with the domain model to handle the request. While the domain model holds domain logic (i.e., business objects and rules), controllers hold application logic, such as navigation through a multistep process or technical details like authentication. When it's time to produce a visible UI for the user, the controller prepares the data to be displayed (the presentation model, or ViewData in ASP.NET MVC, which for example might be a list of Product objects matching the requested category), selects a view, and leaves it to complete the job. Since controller classes aren't coupled to the UI technology (HTML), they are just pure application logic. You can write unit tests for them if you want to.
Views are simple templates for converting the view model into a finished piece of HTML. They are allowed to contain basic, presentation-only logic, such as the ability to iterate over a list of objects to produce an HTML table row for each object, or the ability to hide or show a section of the page according to a flag on some object in the view model, but nothing more complicated than that. By keeping them simple, you'll truly have the benefit of separating application logic concerns from presentation logic concerns.
Don't worry if this seems obscure at the moment; soon you'll see lots of examples. If you're struggling to understand how a view could be distinct from a controller, as I did when I first tried to learn MVC architecture (does a TextBox go into a view or into a controller?), it may be because you've only used technologies that make the division very hard or impossible, such as Windows Forms or classic ASP.NET Web Forms. The answer to the TextBox conundrum is that you'll no longer think in terms of UI widgets, but in terms of requests and responses, which is more appropriate for a web application.
In ASP.NET MVC, controllers are .NET classes, usually derived from the built-in Controller base class. Each public method on a Controller-derived class is called an action method, which is automatically associated with a URL on your configurable URL schema, and after performing some operations, is able to render its choice of view. The mechanisms for both input (receiving data from an HTTP request) and output (rendering a view, redirecting to a different action, etc.) are designed for unit testability, so during implementation and unit testing, you're not coupled to any live web server.
The framework supports a choice of view engines, but by default, views are streamlined ASP.NET Web Forms pages, usually implemented purely as ASPX templates (with no code-behind class files) and always free of ViewState/postback complications. ASPX templates give a familiar, Visual Studio-assisted way to define HTML markup with inline C# code for injecting and responding to ViewData as supplied by the controller.
ASP.NET MVC leaves your model implementation entirely up to you. It provides no particular infrastructure for a domain model, because that's perfectly well handled by a plain vanilla C# class library, .NET's extensive facilities, and your choice of database and data access code or ORM tool. Default, new-born ASP.NET MVC projects do contain a folder called /Models, but this is typically used only for simple view model classes, with the more sophisticated domain model code kept in a separate Visual Studio class library project. You'll learn more about how to implement a domain model in this chapter, and see examples of view models in the next chapter.
The term model-view-controller has been in use since the late 1970s and the Smalltalk project at Xerox PARC. It was originally conceived as a way to organize some of the first GUI applications, although some aspects of its meaning today, especially in the context of web applications, are a little different than in the original Smalltalk world of "screens" and "tools." For example, the original Smalltalk design expected a view to update itself whenever the underlying data model changed, following the observer synchronization pattern, but that's not necessarily possible when the view is already rendered as a page of HTML in somebody's browser.
These days, the essence of the MVC design pattern turns out to work wonderfully for web applications, because
Interaction with an MVC application follows a natural cycle of user actions and view updates, with the view assumed to be stateless, which maps well to a cycle of HTTP requests and responses.
MVC applications enforce a natural separation of concerns. Domain model and controller logic is decoupled from the mess of HTML, which makes the whole code base easier to read and understand. This separation also permits easy unit testing.
ASP.NET MVC is hardly the first web platform to adopt MVC architecture. Ruby on Rails is the most famous MVC poster child, but Apache Struts, Spring MVC, and many others have already proven its benefits.
You've seen the core design of an MVC application, especially as it's commonly used in ASP.NET MVC; but others interpret MVC differently, adding, removing, or changing components according to the scope and subject of their project.
MVC architecture places no constraints on how the domain model component is implemented or how its state is persisted. You can choose to perform data access through abstract repositories if you wish (and in fact this is what you'll see in the next chapter's example), but it's still MVC even if you don't.
From looking at the earlier diagram (Figure 3-3), you might realize that there aren't any strict rules to force developers to correctly split logic between controllers and the domain model. It is certainly possible to put domain logic into a controller, even though you shouldn't, just because it seems like it will work anyway. It's easy to avoid this if you imagine that you have multiple UI technologies (e.g., an ASP.NET MVC application plus a native iPhone application) operating on the same underlying business domain layer (and maybe one day you will!). With this in mind, it's clear that you don't want to put domain logic into any of the UI layers.
Most ASP.NET MVC demonstrations and sample code, to save time, abandon the distinction between controllers and the domain model altogether, in what you might call controller-view architecture. This is inadvisable for a real application because it loses the benefits of a domain model, as listed earlier. You'll learn more about domain modeling in the next part of this chapter.
Model-view-presenter (MVP) is a recent variation on MVC that's designed to fit more easily with stateful GUI platforms such as Windows Forms or ASP.NET Web Forms. You don't need to know about MVP when you're using ASP.NET MVC, so you can skip this section unless you'd like to know how it differs.
In this twist, the presenter has the same responsibilities as MVC's controller, plus it also takes a more hands-on relationship to the stateful view, directly editing the values displayed in its UI widgets according to user input (instead of letting the view render itself from a template). There are two main flavors:
The difference between the two flavors is quite subjective and simply relates to how intelligent the view is allowed to be. Either way, the presenter is decoupled from the GUI technology, so its logic can be followed easily and is suitable for unit testing.
Some folks contend that ASP.NET Web Forms' code-behind model is like an MVP design (supervising controller), in which the ASPX markup is the view and the code-behind class is the presenter. However, in reality, ASPX pages and their code-behind classes are so tightly fused that you can't slide a hair between them. Consider, for example, a grid's ItemDataBound event (that's a view concern, but here it's handled in the code-behind class): it doesn't do justice to MVP. There are ways to implement a genuine MVP design with Web Forms by accessing the control hierarchy only through an interface, but it's complicated and you're forever fighting against the platform. Many have tried, and many have given up.
ASP.NET MVC follows the MVC pattern rather than MVP because MVC remains more popular and is arguably simpler for a web application.
Model-view-view model (MVVM) is the most recent major variation on MVC. It originated in 2005 at Microsoft in the teams working on Avalon, the technology now central to Windows Presentation Foundation (WPF) and Silverlight. You don't need to know about MVVM when you're using ASP.NET MVC, so you can skip this section unless you'd like to know how it differs.
In MVVM, models and views play the same roles as the equivalents in MVC. The difference is MVVM's concept of a view model. This is an abstract representation of a user interface—typically a C# class exposing properties for both the data to be displayed in the UI and operations that can be invoked from the UI. Unlike controllers in MVC or presenters in MVP, an MVVM view model has no awareness that a view (or any specific UI technology) even exists. Instead, an MVVM view uses WCF/Silverlight's binding feature to bidirectionally associate view control properties (e.g., entries in drop-down lists, or the effects of button clicks) with the properties exposed by the view model. The whole MVVM pattern is designed around WCF/Silverlight bindings, so it doesn't always make sense to apply it on other technology platforms.
Note
Confusingly, ASP.NET MVC developers also use the term "view model"to mean something quite different. For us, view models are just simple model objects that exist only to hold some data items so that a controller can pass that data to a view. We distinguish these from domain models, which may have sophisticated business logic and are usually persisted in a database.
Don't be confused by thinking that ASP.NET MVC's view models and MVVM's view models are the same concept—they're not. Nor is ASP.NET MVC's notion of model binding in any way related to WCF/Silverlight's binding feature. ASP.NET MVC deals with sequences of interactions over HTTP, whereas WCF/Silverlight deals with stateful GUIs running directly on the user's PC. As such, the two technologies use very different mechanisms and encourage different design patterns.
As an ASP.NET MVC developer, you can forget about MVVM. I won't need to mention it again in this book, and whenever I use the terms view model or binding, I mean them in the ASP.NET MVC sense.
You've already seen how it makes sense to take the real-world objects, processes, and rules from your software's subject matter and encapsulate them in a component called a domain model. This component is the heart of your software; it's your software's universe. Everything else, including controllers and views, is just a technical detail designed to support or permit interaction with the domain model. Eric Evans, a leader in domain-driven design (DDD), puts it well:
The part of the software that specifically solves problems from the domain model usually constitutes only a small portion of the entire software system, although its importance is disproportionate to its size. To apply our best thinking, we need to be able to look at the elements of the model and see them as a system. We must not be forced to pick them out of a much larger mix of objects, like trying to identify constellations in the night sky. We need to decouple the domain objects from other functions of the system, so we can avoid confusing domain concepts with concepts related only to software technology or losing sight of the domain altogether in the mass of the system.
ASP.NET MVC doesn't force you to use a specific technology for domain modeling. Instead, it relies on what it inherits from the .NET Framework and ecosystem. However, it does provide infrastructure and conventions to help you connect your model classes with your controllers, with your views, and with the MVC Framework itself:
Model binding is a conventions-based mechanism that can populate model objects automatically using incoming data, usually from an HTML form post.
Model metadata lets you describe the meaning of your model classes to the framework. For example, you can provide human-readable descriptions of their properties or give hints about how they should be displayed. The MVC Framework can then automatically render a display or editor UI for your model classes into your views.
Validation happens during model binding and applies rules that can be defined as metadata.
You'll find much more detail about these mechanisms in Chapter 12. But first, let's put ASP.NET MVC aside and think about domain modeling as a concept in its own right. For the next portion of this chapter, you'll see a quick example of implementing a domain model with .NET and SQL Server, using a few of the core techniques from DDD.
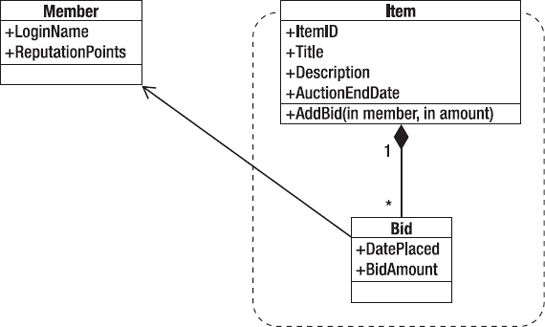
No doubt you've already experienced the process of brainstorming a domain model in your previous projects. Typically, it involves one or more developers, one or more business experts, a whiteboard, and a lot of cookies. After a while, you'll pull together a first-draft model of the business processes you're going to automate. For example, if you were going to implement an online auctions site, you might get started with something like that shown in Figure 3-4.

This diagram indicates that the model contains a set of members who each hold a set of bids, and each bid is for an item. An item can have multiple bids from different members.
A key benefit of implementing your domain model as a distinct component is the ability to design it according to the language and terminology of your choice. Strive to find and stick to a terminology for its entities, operations, and relationships that makes sense not just to developers, but also to your business (domain) experts. Perhaps you might have chosen the terms users and roles, but in fact your domain experts say agents and clearances. Even when you're modeling concepts that domain experts don't already have words for, come to an agreement about a shared language, otherwise you can't really be sure that you're faithfully modeling the processes and relationships that the domain expert has in mind. But why is this "ubiquitous language" so valuable?
Developers naturally speak in the language of the code (the names of its classes, database tables, etc.). Keep code terms consistent with terms used by business experts and terms used in the application's UI, and you'll permit easier communication. Otherwise, current and future developers are more likely to misinterpret new feature requests or bug reports, or will confuse users by saying,"The user has no access role for that node" (which sounds like the software is broken), instead of,"The agent doesn't have clearance on that file."
It helps you to avoid overgeneralizing your software. We programmers have a tendency to want to model not just one particular business reality, but every possible reality (e.g., in the auctions example, by replacing "members" and "items" with a general notion of "resources" linked not by "bids" but by "relationships"). By failing to constrain a domain model along the same lines that a particular business in a particular industry operates, you are rejecting any real insight into its workings, and will struggle in the future to implement features that will seem to you like awkward special cases in your elegant metaworld. Constraints are not limitations; they are insight.
Be ready to refactor your domain model as often as is necessary. DDD experts say that any change to the ubiquitous language is a change to the software. If you let the software model drift out of sync with your current understanding of the business domain, awkwardly translating concepts in the UI layer despite the underlying impedance mismatch, your model component will become a real drain on developer effort. Aside from being a bug magnet, this could mean that some apparently simple feature requests turn out to be incredibly hard to implement, and you won't be able to explain it to your clients.
Take another look at the auctions example diagram (Figure 3-4). As it stands, it doesn't offer much guidance when it comes to implementation with C# and SQL Server. If you load a member into memory, should you also load all their bids, and all the items associated with those bids, and all the other bids for those items, and all the members who have placed all those other bids? When you delete something, how far does that deletion cascade through the object graph? If you want to impose validation rules that involve relationships across objects, where do you put those rules? If instead of using a relational database, you chose to use a document database, which groups of objects would constitute a single document? And this is just a trivial example-how much more complicated will it get in real life?
The DDD way to break down this complexity is to arrange domain entities into groups called aggregates. Figure 3-5 shows how you might do it in the auctions example.
Each aggregate has a root entity that defines the identity of the whole aggregate, and acts as the "boss" of the aggregate for the purposes of validation and persistence. The aggregate is a single unit when it comes to data changes, so choose aggregates that relate logically to real business processes—that is, the sets of objects that tend to change as a group (thereby embedding further insight into your domain model).
Objects outside a particular aggregate may only hold persistent references to the root entity, not to any other object inside that aggregate (in fact, ID values for nonroot entities don't have to be unique outside the scope of their aggregate, and in a document database, they wouldn't even have IDs). This rule reinforces aggregates as atomic units, and ensures that changes inside an aggregate don't cause data corruption elsewhere.
In this example, members and items are both aggregate roots, because they have to be independently accessible, whereas bids are only interesting within the context of an item. Bids are allowed to hold a reference to members, but members can't directly reference bids because that would violate the items aggregate boundary. Keeping relationships unidirectional, as much as possible, leads to considerable simplification of your domain model and may well reflect additional insight into the domain. This might be an unfamiliar thought if you've previously thought of a SQL database schema as being your domain model (given that all relationships in a SQL database are bidirectional), but C# can model a wider range of concepts.
A C# representation of our domain model so far looks like this:
public class Member
{
public string LoginName { get; set; } // The unique key
public int ReputationPoints { get; set; }
}
public class Item
{
public int ItemID { get; private set; } // The unique keypublic string Title { get; set; }
public string Description { get; set; }
public DateTime AuctionEndDate { get; set; }
public IList<Bid> Bids { get; private set; }
}
public class Bid
{
public Member Member { get; private set; }
public DateTime DatePlaced { get; private set; }
public decimal BidAmount { get; private set; }
}Notice that Bid is immutable (to match how we think of bids in the real world), and the other classes' properties are appropriately protected. These classes respect aggregate boundaries in that no references violate the boundary rule.
Aggregates bring superstructure into a complex domain model, adding a whole extra level of manageability. They make it easier to define and enforce data integrity rules (an aggregate root can validate the state of the entire aggregate). They give you a natural unit for persistence, so you can easily decide how much of an object graph to bring into memory (perhaps using lazy-loading for references to other aggregate roots). They're the natural unit for cascade deletion, too. And since data changes are atomic within an aggregate, they're an obvious unit for transactions.
On the other hand, they impose restrictions that can sometimes seem artificial—because often they are artificial—and compromise is painful. Aggregates arise naturally in document databases, but they aren't a native concept in SQL Server, nor in most ORM tools, so to implement them well, your team will need discipline and effective communication.
Sooner or later you'll have to think about getting your domain objects into and out of some kind of persistent storage—usually a relational, object, or document database. Of course, this concern is purely a matter of today's software technology, and isn't part of the business domain you're modeling. Persistence is an independent concern (real architects say orthogonal concern—it sounds much cleverer), so you don't want to mix persistence code with domain model code, either by embedding database access code directly into domain entity methods, or by putting loading or querying code into static methods on those same classes.
The usual way to keep this separation clean is to define repositories. These are nothing more than object-oriented representations of your underlying database store (or file-based store, or data accessed over a web service, or whatever), acting as a façade over the real implementation. When you're working with aggregates, it's normal to define a separate repository for each aggregate, because aggregates are the natural unit for persistence logic. For example, continuing the auctions example, you might start with the following two repositories (note that there's no need for a BidsRepository, because bid instances need only be found by following references from item instances):
public class MembersRepository
{
public void AddMember(Member member) { /* Implement me */ }
public Member FetchByLoginName(string loginName) { /* Implement me */ }public void SubmitChanges() { /* Implement me */ }
}
public class ItemsRepository
{
public void AddItem(Item item) { /* Implement me */ }
public Item FetchByID(int itemID) { /* Implement me */ }
public IList<Item> ListItems(int pageSize,int pageIndex) { /* Implement me */ }
public void SubmitChanges() { /* Implement me */ }
}Notice that repositories are concerned only with loading and saving data, and contain as little domain logic as is possible. At this point, you can fill in the code for each repository method using whatever data access strategy you prefer. You might call stored procedures, but in this example, you'll see how to use an ORM tool (LINQ to SQL) to make your job easier.
We're relying on these repositories being able to figure out what changes they need to save when we call SubmitChanges() (by spotting what you've done to its previously returned entities—LINQ to SQL, NHibernate, and Entity Framework all handle this easily), but we could instead pass specific updated entity instances to, say, a SaveMember(member) method if that seems easier for your preferred data access technique.
Finally, you can get a whole slew of extra benefits from your repositories by defining them abstractly (e.g., as a .NET interface) and accessing them through the abstract factory pattern, or with a DI container. That makes it easy to unit test code that depends on persistence: you can supply a fake or mock repository implementation that simulates any domain model state you like. Also, you can easily swap out the repository implementation for a different one if you later choose to use a different database or ORM tool. You'll see DI at work with repositories later in this chapter.
Microsoft introduced LINQ to SQL in 2007 as part of .NET 3.5. It's designed to give you a strongly typed .NET view of your database schema and data, dramatically reducing the amount of code you need to write in common data access scenarios, and freeing you from the burden of creating and maintaining stored procedures for every type of query you need to perform. It is an ORM tool, not as mature and sophisticated as alternatives such as NHibernate, but sometimes easier to use, considering its full support for LINQ and itsinclusion by default in all editions of Visual Studio 2008 and 2010.
Note
In case you're wondering why I'm building this and other examples on LINQ to SQL instead of Microsoft's newer and more sophisticated ORM product, Entity Framework, it's for two main reasons. First, Entity Framework is only just catching up with LINQ to SQL's support for working with plain C# domain model classes (also known as plain-old CLR objects [POCOs]), and at the time of writing, POCO support is only available as a separately downloadable community technology preview (CTP). Second, Entity Framework 4 requires .NET 4, whereas this book's audience includes readers in a Visual Studio 2008/.NET 3.5 environment.
I'm aware that some developers have expressed concerns that Microsoft might deprecate LINQ to SQL in favor of Entity Framework. However, Microsoft included and enhanced LINQ to SQL in .NET 4, so these fears cannot be entirely justified. LINQ to SQL is a great straightforward tool, so I will use it in various examples in this book, and am happy to use it in real projects. Of course, ASP.NET MVC itself has no dependency on LINQ to SQL. By keeping data access code separate from domain and application logic, you can easily swap it out and use a different ORM tool (such as Entity Framework or the popular NHibernate) instead.
Most demonstrations of LINQ to SQL use it as if it were a quick prototyping tool. You can start with an existing database schema and use a Visual Studio editor to drag tables and stored procedures onto a canvas, and the tool will generate corresponding entity classes and methods automatically. You can then use LINQ queries inside your C# code to retrieve instances of those entities from a data context (it converts LINQ queries into SQL at runtime), modify them in C#, and then call SubmitChanges() to write those changes back to the database.
While this is excellent in a Smart UI application, there are limitations in multilayer architectures, and if you start from a database schema rather than an object-oriented domain model, you've already abandoned a clean domain model design.
There are various different ways to use LINQ to SQL. Here are the two main ones:
You can take a database-first approach by first creating a SQL Server database schema. Then, as I just described, use LINQ to SQL's visual designer to have it generate corresponding C# classes and a mapping configuration.
You can take a code-first approach by first creating a clean, object-oriented domain model with interfaces for its repositories. Then create a SQL Server database schema to match. Finally, either provide an XML mapping configuration or use mapping attributes to tell LINQ to SQL how to convert between the two. (Alternatively, just give LINQ to SQL the mapping configuration and ask it to create the initial SQL Server database for you.)
As you can guess, the second option requires more work to get started, but it wins in the long term. You can keep persistence concerns separate from the domain classes, and you get total control over how they are structured and how their properties are encapsulated. Plus, you can freely update either the object-oriented or relational representation and update your mapping configuration to match.
The code-first approach isn't too difficult when you get going. Next, you'll see how to build the auctions example domain model and repositories in this way.
With LINQ to SQL, you can set up mappings between C# classes and an implied database schema either by decorating the classes with special attributes or by writing an XML configuration file. The XML option has the advantage that persistence artifacts are totally removed from your domain classes,[15] but the disadvantage that it's not so obvious at first glance. For simplicity, I'll compromise here and use attributes.
Here are the Auctions domain model classes now fully marked up for LINQ to SQL:[16]
using System;
using System.Collections.Generic;
using System.Linq;
using System.Data.Linq.Mapping;
using System.Data.Linq;
[Table(Name="Members")] public class Member
{
[Column(IsPrimaryKey=true, IsDbGenerated=true, AutoSync=AutoSync.OnInsert)]
internal int MemberID { get; set; }
[Column] public string LoginName { get; set; }
[Column] public int ReputationPoints { get; set; }
}
[Table(Name = "Items")] public class Item
{
[Column(IsPrimaryKey=true, IsDbGenerated=true, AutoSync=AutoSync.OnInsert)]
public int ItemID { get; internal set; }
[Column] public string Title { get; set; }
[Column] public string Description { get; set; }
[Column] public DateTime AuctionEndDate { get; set; }
[Association(OtherKey = "ItemID")]
private EntitySet<Bid> _bids = new EntitySet<Bid>();
public IList<Bid> Bids { get { return _bids.ToList().AsReadOnly(); } }
}
[Table(Name = "Bids")] public class Bid
{
[Column(IsPrimaryKey=true, IsDbGenerated=true, AutoSync=AutoSync.OnInsert)]
internal int BidID { get; set; }[Column] internal int ItemID { get; set; }
[Column] public DateTime DatePlaced { get; internal set; }
[Column] public decimal BidAmount { get; internal set; }
[Column] internal int MemberID { get; set; }
internal EntityRef<Member> _member;
[Association(ThisKey = "MemberID", Storage = "_member")]
public Member Member {
get { return _member.Entity; }
internal set { _member.Entity = value; MemberID = value.MemberID; }
}
}This code brings up several points:
This does, to some extent, compromise the purity of the object-oriented domain model. In a perfect world, LINQ to SQL artifacts wouldn't appear in domain model code, because LINQ to SQL isn't a feature of your business domain. I don't really mind the attributes (e.g.,
[Column]) because they're more like metadata than code.Slightly more inconvenient, though, areEntityRef<T>andEntitySet<T>—these support LINQ to SQL's special way of describing references between entities that support lazy-loading (i.e., fetching the referenced entities from the database only on demand).In LINQ to SQL, every domain object has to be an entity with a primary key. That means you need an ID value on everything—even on
Bid, which shouldn't really need one. Similarly, any foreign key in the database has to map to a[Column]in the object model, so it's necessary to addItemIDandMemberIDtoBid. Fortunately, you can mark such ID values asinternalso the compromise isn't exposed outside of the model layer.Instead of using
Member.LoginNameas a primary key, I've added a new, artificial primary key (MemberID). That will be handy if it's ever necessary to change login names. Again, it can beinternalbecause it's not important to the rest of the application.The
Item.Bidscollection returns a list in read-only mode. This is vital for proper encapsulation, ensuring that any changes to theBidscollection happens via domain model code that can enforce appropriate business rules.Even though these classes don't define any domain logic (they're just data containers), they are still the right place to put domain logic (e.g., the
AddBid()method onItem). We just haven't got to that bit yet.
If you want the system to create a corresponding database schema automatically, you can arrange it with a few lines of code:
DataContext dc = new DataContext(connectionString); // Get a live DataContext dc.GetTable<Member>(); // Tells dc it's responsible for persisting the class Member dc.GetTable<Item>(); // Tells dc it's responsible for persisting the class Item dc.GetTable<Bid>(); // Tells dc it's responsible for persisting the class Bid dc.CreateDatabase(); // Causes dc to issue CREATE TABLE commands for each class
Remember, though, that you'll have to perform any future schema updates manually, because CreateDatabase() can't update an existing database. Alternatively, you can just create the schema manually in the first place. Either way, once you've created a corresponding database schema, you can create, update, and delete entities using LINQ syntax and methods on System.Data.Linq.DataContext. Here's an example of constructing and saving a new entity:
DataContext dc = new DataContext(connectionString);
dc.GetTable<Member>().InsertOnSubmit(new Member
{
LoginName = "Steve",
ReputationPoints = 0
});
dc.SubmitChanges();Here's an example of retrieving a list of entities in a particular order:
DataContext dc = new DataContext(connectionString);
var members = from m in dc.GetTable<Member>()
orderby m.ReputationPoints descending
select m;
foreach (Member m in members)
Console.WriteLine("Name: {0}, Points: {1}", m.LoginName, m.ReputationPoints);You'll learn more about the internal workings of LINQ queries and the new C# language features that support them later in this chapter. For now, instead of scattering data access code all over the place, let's implement some repositories.
Now that the LINQ to SQL mappings are set up, it's dead easy to provide a full implementation of the repositories outlined earlier:
using System.Data.Linq;
using System.Linq;
public class MembersRepository
{
private Table<Member> membersTable;
public MembersRepository(string connectionString) {
membersTable = new DataContext(connectionString).GetTable<Member>();
}
public void AddMember(Member member) {
membersTable.InsertOnSubmit(member);
}
public void SubmitChanges() {
membersTable.Context.SubmitChanges();
}
public Member FetchByLoginName(string loginName) {
// If this syntax is unfamiliar to you, check out the explanation
// of lambda methods near the end of this chapter
return membersTable.FirstOrDefault(m => m.LoginName == loginName);
}
}public class ItemsRepository
{
private Table<Item> itemsTable;
public ItemsRepository(string connectionString) {
DataContext dc = new DataContext(connectionString);
itemsTable = dc.GetTable<Item>();
}
public IList<Item> ListItems(int pageSize, int pageIndex) {
return itemsTable.Skip(pageSize * pageIndex)
.Take(pageSize).ToList();
}
public void SubmitChanges() {
itemsTable.Context.SubmitChanges();
}
public void AddItem(Item item) {
itemsTable.InsertOnSubmit(item);
}
public Item FetchByID(int itemID) {
return itemsTable.FirstOrDefault(i => i.ItemID == itemID);
}
}Notice that these repositories take a connection string as a constructor parameter, and then create their own DataContext from it. This context-per-repository pattern means that repository instances won't interfere with one another, accidentally saving each other's changes or rolling them back. Taking a connection string as a constructor parameter works really well with a DI container, because you can set up constructor parameters in a configuration file, as you'll see later in the chapter.
Now you can interact with your data store purely through the repository, like so:
ItemsRepository itemsRep = new ItemsRepository(connectionString);
itemsRep.AddItem(new Item {
Title = "Private Jet",
AuctionEndDate = new DateTime(2012, 1, 1),
Description = "Your chance to own a private jet."
});
itemsRep.SubmitChanges();One common metaphor in software architecture is layers (see Figure 3-6).

In this architecture, each layer depends only on lower layers, meaning that each layer is only aware of the existence of, and is only able to access, code in the same or lower layers. Typically, the top layer is a UI, the middle layers handle domain concerns, and the bottom layers are for data persistence and other shared services. The key benefit is that, when developing code in each layer, you can forget about the implementation of other layers and just think about the API that you're exposing above. This helps you to manage complexity in a large system.
This "layer cake" metaphor is useful, but there are other ways to think about software design, too. Consider the alternative depicted in Figure 3-7, which relates software pieces to components on a circuit board.
A component-oriented design is a little more flexible than a layered design. With this mindset, we don't emphasize the location of each component in a fixed pile, but instead we emphasize that each component is self contained and communicates with selected others only through a well-defined interface.
Components never make any assumptions about the inner workings of any other component: they consider each other component to be a black box that correctly fulfils one or more public contracts (e.g., .NET interfaces), just as the chips on a circuit board don't care for each other's internal mechanisms, but merely interoperate through standard connectors and buses. To prevent careless tight coupling, each software component shouldn't even know of the existence of any other concrete component, but should know only the interface, which expresses functionality but nothing about internal workings. This goes beyond encapsulation; this is loose coupling.
For an obvious example, when you need to send e-mail, you can create an "e-mail sender" component with an abstract interface. You can then attach it to the domain model, or to some other service component (without having to worry about where exactly it fits in the stack), and then easily set up domain model tests using mock implementations of the e-mail sender interface; or in the future swap out the e-mail sender implementation for another if you change your SMTP infrastructure.
Going a step further, repositories are just another type of service component, so you don't really need a special "data access" layer to contain them. It doesn't matter how a repository component fulfils requests to load, save, or query data—it just has to satisfy some interface that describes the available operations. As far as its consumers are concerned, any other implementation of the same contract is just as good, whether it stores data in a database, in flat files, across a web service, or anything else. Working against an abstract interface again reinforces the component's separation—not just technically, but also in the minds of the developers implementing its features.
A component-oriented design isn't mutually exclusive with a layered design (you can have a general sense of layering in your component graph if it helps), and not everything has to expose an abstract interface—for example, your UI probably doesn't need to, because nothing will depend upon it. Similarly, in a small ASP.NET MVC application, you might choose not to completely decouple your controllers from your domain model—it depends on whether there's enough logic in the domain model to warrant maintaining all the interfaces. However, you'll almost certainly benefit by encapsulating data access code and services inside abstract components.
Be flexible; do what works best in each case. The real value is in understanding the mindset: unlike in a pure layered design where each layer tends to be tightly coupled to the one and only concrete implementation of each lower layer, componentization promotes encapsulation and design-by-contract on a piece-by-piece basis, which leads to greater simplicity and testability.
Component-oriented design goes hand in hand with DI.[17] DI is a software design pattern that helps you decouple your application components from one another. If you've never used DI before, then you might at first wonder why it's worth bothering with; it may seem like an unnecessary hassle. But trust me—it's worth it! Once you've got it set up, it will make your work simpler, not harder, and you'll get great satisfaction from being able to interchange application components with ease. Let's first talk through some examples.
Imagine you have a class, PasswordResetHelper, that needs to send e-mail and write to a log file. Without DI, you could allow it to construct concrete instances of MyEmailSender and MyLogWriter, and use them directly to complete its task. But then you've got hard-coded dependencies from PasswordResetHelper to the other two components, leaking and weaving their specific concerns and API designs throughout PasswordResetHelper. You can't then design and unit test PasswordResetHelper in isolation; and of course, switching to a different e-mail-sending or log-writing technology will involve considerable changes to PasswordResetHelper. The three classes are fused together. That's the starting point for the dreaded spaghetti code disease.
Avoid this by applying the DI pattern. Create some interfaces that describe arbitrary e-mail-sending and log-writing components (e.g., called IEmailSender and ILogWriter), and then make PasswordResetHelper dependent only on those interfaces:
public class PasswordResetHelper
{
private IEmailSender _emailSender;
private ILogWriter _logWriter;
// Constructor
public PasswordResetHelper(IEmailSender emailSender, ILogWriter logWriter)
{
// This is the DI bit. The constructor demands instances
// of IEmailSender and ILogWriter, which we save and will use later
this._emailSender = emailSender;
this._logWriter = logWriter;
}
// Rest of code uses _emailSender and _logWriter
}Now, PasswordResetHelper needs no knowledge of any specific concrete e-mail sender or log writer. It knows and cares only about the interfaces, which could equally well describe any e-mail-sending or log-writing technology, without getting bogged down in the concerns of any specific one. You can easily switch to a different concrete implementation (e.g., for a different technology), or support multiple ones concurrently, without changing PasswordResetHelper. At runtime, its dependencies are injected into it from outside. And in unit tests, as you'll see later, you can supply mock implementations that allow for simple tests, or ones that simulate particular external circumstances (e.g., error conditions). You have achieved loose coupling.
Note
This PasswordResetHelper demands its dependencies as constructor parameters. That's called constructor injection. Alternatively, you could allow external code to supply dependencies through publicly writable properties—that's called setter injection.
Let's go back to the auctions example and apply DI. The specific goal is to create a controller class, AdminController, that uses the LINQ to SQL-powered MembersRepository, but without coupling AdminController to MembersRepository (with all its LINQ to SQL and database connection string concerns).
We'll start by assuming that you've refactored MembersRepository to implement a public interface:
public interface IMembersRepository
{
void AddMember(Member member);
Member FetchByLoginName(string loginName);
void SubmitChanges();
}(Of course, you still have the concrete MembersRepository class, which now implements this interface.) You can now write an ASP.NET MVC controller class that depends on IMembersRepository:
public class AdminController : Controller
{
IMembersRepository membersRepository;
// Constructor
public AdminController(IMembersRepository membersRepository)
{
this.membersRepository = membersRepository;
}
public ActionResult ChangeLoginName(string oldLogin, string newLogin)
{
Member member = membersRepository.FetchByLoginName(oldLogin);
member.LoginName = newLogin;
membersRepository.SubmitChanges();
// ... now render some view
}
}This AdminController requires you to supply an implementation of IMembersRepository as a constructor parameter. Now AdminController can just work with the IMembersRepository interface, and doesn't need to know of any concrete implementation.
This simplifies AdminController in several ways—for one thing, it no longer needs to know or care about database connection strings (remember, the concrete class MembersRepository demands connectionString as a constructor parameter). The bigger benefit is that DI ensures that you're coding to contract (i.e., explicit interfaces), and it greatly enhances unit testability (we'll create a unit test for ChangeLoginName() in a moment).
But wait a minute—something further up the call stack now has to create an instance of MembersRepository—so that now needs to supply a connectionString. Does DI really help, or does it just move the problem from one place to another? What if you have loads of components and dependencies, and even chains of dependencies with child dependencies—how will you manage all this, and won't the end result just be even more complicated? Say hello to the DI container.
A DI container (also called an IoC container) is a standard software component that supports and simplifies DI. It lets you register a set of components (i.e., abstract types and your currently chosen concrete implementations), and then handles the business of instantiating them. You can configure and register components either with C# code or an XML file (or both).
At runtime, you can call a method similar to container.Resolve(Type type), where type could be a particular interface or abstract type, or a particular concrete type, and the container will return an object satisfying that type definition, according to whatever concrete type is configured. It sounds trivial, but a good DI container adds three clever features:
Dependency chain resolution: If you request a component that itself has dependencies (e.g., constructor parameters), the container will satisfy those dependencies recursively, so you can have component A, which depends on B, which depends on C, and so on. In other words, you can forget about the wiring on your component circuit board—just think about the components, because wiring happens automatically.
Object lifetime management: If you request component A more than once, should you get the same actual instance of A each time, or a fresh new instance each time? The container will usually let you configure the "lifestyle" of a component, allowing you to select from predefined options including singleton (the same instance each time), transient (a new instance each time), instance-per-thread, instance-per-HTTP-request, instance-from-a-pool, and so on.
Configuration of constructor parameter values: For example, if the constructor for
MembersRepositorydemands a string calledconnectionString(as ours did earlier), you can set a value for it in your DI container configuration. It's a crude but simple configuration system that removes any need for your code to pass around connection strings, SMTP server addresses, and so on.
So, in the preceding example, you'd configure MembersRepository as the active concrete implementation for IMembersRepository. Then, when some code calls container.Resolve(typeof(AdminController)), the container will figure out that to satisfy AdminController's constructor parameters it first needs an object implementing IMembersRepository. It will get one according to whatever concrete implementation you've configured (in this case, MembersRepository), supplying the connectionString you've configured. It will then use that to instantiate and return an AdminController.
There are at least five different widely used open source DI containers for .NET that offer all the features just described, and all work well with ASP.NET MVC. The one we're going to use in the next chapter, Ninject (http://ninject.org/), is especially easy to get started with, highly extensible, and uses conventions to eliminate a lot of routine configuration. It only requires you to reference a single assembly, Ninject.dll.
Ninject uses the term kernel for the thing that can map abstract types (interfaces) to specific concrete types. When someone calls myKernel.Get<ISomeAbstractType>(), it will return an instance of whatever corresponding concrete type is currently configured, resolving any chain of dependencies, and respecting your component's configured lifestyle.
This is especially useful in ASP.NET MVC for building a "controller factory" that can resolve dependencies automatically. Continuing the previous example, this means that AdminController's dependency on IMembersRepository will be resolved automatically, according to whatever concrete implementation you've currently got configured for IMembersRepository.
Note
What's a controller factory? In ASP.NET MVC, it's an object that the framework calls to instantiate whatever controller is needed to service an incoming request. ASP.NET MVC has a built-in one, called DefaultControllerFactory, but you can replace it with a different one of your own. You just need to create a class that implements IControllerFactory or inherits from DefaultControllerFactory.
In the next chapter, you'll use Ninject to build a custom controller factory called NinjectControllerFactory. That will take care of resolving all controllers' dependencies automatically, whenever they are needed to service a request.
ASP.NET MVC provides an easy means for hooking up a custom controller factory—you just need to edit the Application_Start handler in your Global.asax.cs file, like so:
protected void Application_Start()
{
RegisterRoutes(RouteTable.Routes);
ControllerBuilder.Current.SetControllerFactory(new NinjectControllerFactory());
}For now, you need only understand that this is possible. The full implementation of NinjectControllerFactory can wait until the next chapter.
In recent years, automated testing has turned from a minority interest into a mainstream, can't-live-without-it, core development technique. The ASP.NET MVC Framework is designed, from every possible angle, to make it as easy as possible to set up automated tests and use development methodologies such as test-driven development (TDD) (or behavior-driven development [BDD], which is very similar—you'll hear about it later). When you create a brand new ASP.NET MVC 2 Web Application project, Visual Studio even prompts you to help set up a unit testing project, offering project templates for several testing frameworks, depending on which ones you have installed.[18]
Broadly speaking, web developers today focus on two main types of automated testing:
Unit testing: This is a way to specify and verify the behavior of individual classes or other small code units in isolation.
Integration testing: This is a way to specify and verify the behavior of multiple components working together—typically your entire web application running on a real web server.
For most web applications, both types of automated tests are valuable. TDD practitioners tend to focus on unit tests, which run faster, are easier to set up, and are brilliantly precise when you're working on algorithms, business logic, or other back-end infrastructure. Integration tests are worth considering too, because they can model how a user will interact with your UI, can cover your entire technology stack including web server and database configurations, and tend to be better at detecting new bugs that have arisen in old features (also called regressions).
In the .NET world, you can choose from a range of open source and commercial unit test frameworks, the most widely known of which is NUnit. Typically, you create a separate class library project in your solution to hold test fixtures (unless Visual Studio has already created one for you). A test fixture is a C# class that defines a set of test methods—one test method per behavior that you want to verify.
Note
In the next chapter, I'll explain the full details of how to get NUnit and start using it—you don't need to do that yourself right now. The goal for this chapter is just to give you an understanding of the concepts so that you'll be comfortable when they're applied over the next few chapters.
Here's an example test fixture, written using NUnit, that tests the behavior of AdminController's ChangeLoginName() method from the previous example:
[TestFixture]
public class AdminControllerTests
{
[Test]
public void Can_Change_Login_Name()
{
// Arrange (set up a scenario)
Member bob = new Member { LoginName = "Bob" };
FakeMembersRepository repos = new FakeMembersRepository();
repos.Members.Add(bob);
AdminController controller = new AdminController(repos);
// Act (attempt the operation)
controller.ChangeLoginName("Bob", "Anastasia");
// Assert (verify the result)
Assert.AreEqual("Anastasia", bob.LoginName);
Assert.IsTrue(repos.DidSubmitChanges);
}
private class FakeMembersRepository : IMembersRepository
{
public List<Member> Members = new List<Member>();
public bool DidSubmitChanges = false;
public void AddMember(Member member) {
throw new NotImplementedException();
}public Member FetchByLoginName(string loginName){
return Members.First(m => m.LoginName == loginName);
}
public void SubmitChanges(){
DidSubmitChanges = true;
}
}
}Tip
The Can_Change_Login_Name() test method code follows a pattern known as arrange/act/assert (A/A/A). Arrange refers to setting up a test condition, act refers to invoking the operation under test, and assert refers to checking the result. Being so consistent about test code layout makes it easier to skim-read, and you'll appreciate that when you have hundreds of tests. Most of the unit test methods in this book follow the A/A/A pattern.
This test fixture uses a test-specific fake implementation of IMembersRepository to simulate a particular condition (i.e., there's one member in the repository: Bob). Next, it calls the method being tested (ChangeLoginName()), and finally verifies the result using a series of Assert() calls. You can run your tests using one of many freely available test runner GUIs,[19] such as NUnit GUI (see Figure 3-8).
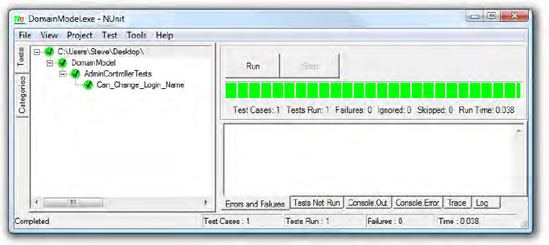
NUnit GUI finds all the [TestFixture] classes in an assembly, and all their [Test] methods, letting you run them either individually or all in sequence. If all the Assert() calls pass and no unexpected exceptions are thrown, you'll get a green light. Otherwise, you'll get a red light and a list of which assertions failed.
It might seem like a lot of code to verify a simple behavior, but it wouldn't be much more code even if you were testing a very complex behavior. As you'll see in later examples in this book, you can write far more concise tests, entirely eliminating fake test classes such as FakeMembersRepository, by using a mocking tool.
The preceding test is a unit test because it tests just one isolated component: AdminController. It doesn't rely on any real implementation of IMembersRepository, so it doesn't need to access any database.
Things would be different if AdminController weren't so well decoupled from its dependencies. If instead it directly referenced a concrete MembersRepository, which in turn contained database access code, then it would be impossible to unit test AdminController in isolation—you'd be forced to test the repository, the data access code, and even the SQL database itself all at once. That would make it an integration test, not a unit test.
Enabling unit testing is not the only reason to use DI. Personally, I would use DI for my ASP.NET MVC controllers anyway, because it enforces their logical separation from other components. Over time, this keeps controllers simple and means their dependencies can be changed or replaced easily.
You're off to a good start with unit testing. But how can your unit tests help you design your code unless you write the tests before the code itself? And how do you know whether your tests actually prove something? What if you accidentally missed a vital Assert(), or didn't set up your simulated conditions quite right, so that the test gives a false positive?
TDD prescribes a development workflow called red-green-refactor, an approach to writing code that implicitly tests your tests. The basic workflow is as follows:
Decide that you need to add a new behavior to your code. Write a unit test for the behavior, even though you haven't implemented it yet.
See the test fail (red).
Implement the behavior.
See the test pass (green).
If you think the code could be improved by being restructured—for example, by reorganizing or renaming methods or variables but without changing the behavior, do that now (refactor). Afterward, the tests should still pass.
Repeat.
The fact that the test result switches from red to green, even though you don't change the test, proves that it responds to the behavior you've added in the code.
Let's see an example. Earlier in this chapter, during the auctions example, there was planned to be a method on Item called AddBid(), but we haven't implemented it yet. Let's say the behavior we want is,"You can add bids to an item, but any new bid must be higher than all previous bids for that item." First, add a method stub to the Item class:
public void AddBid(Member fromMember, decimal bidAmount)
{
throw new NotImplementedException();
}Note
You don't have to write method stubs before you write test code. You could just write a unit test that tries to call AddBid() even though no such method exists yet. Obviously, there'd be a compiler error. You could think of that as the first failed test.Or, if you prefer to skip that ceremony, you can just add method stubs as you're going along.
It may be obvious that this code doesn't have the desired behavior, but that doesn't stop you from writing a unit test:
[TestFixture]
public class AuctionItemTests
{
[Test]
public void Can_Add_Bid()
{
// Set up a scenario
Member member = new Member();
Item item = new Item();
// Attempt the operation
item.AddBid(member, 150);
// Verify the result
Assert.AreEqual(1, item.Bids.Count());
Assert.AreEqual(150, item.Bids[0].BidAmount);
Assert.AreSame(member, item.Bids[0].Member);
}
}Run this test, and of course you'll get a red light (NotImplementedException). It's time to create a first-draft implementation for Item.AddBid():
public void AddBid(Member fromMember, decimal bidAmount)
{
_bids.Add(new Bid{
Member = fromMember,
BidAmount = bidAmount,
DatePlaced = DateTime.Now,
ItemID = this.ItemID
});
}Now if you run the test again, you'll get a green light. So this proves you can add bids, but says nothing about new bids being higher than existing ones. Start the red-green cycle again by adding two more tests:
[Test]
public void Can_Add_Higher_Bid()
{
// Set up a scenario
Member member1 = new Member();
Member member2 = new Member();
Item item = new Item();
// Attempt the operation
item.AddBid(member1, 150);
item.AddBid(member2, 200);
// Verify the result
Assert.AreEqual(2, item.Bids.Count());
Assert.AreEqual(200, item.Bids[1].BidAmount);
Assert.AreSame(member2, item.Bids[1].Member);
}
[Test]
public void Cannot_Add_Lower_Bid()
{
// Set up a scenario
Item item = new Item();
item.AddBid(new Member(), 150);
// Attempt the operation
try
{
item.AddBid(new Member(), 100);
Assert.Fail("Should throw exception when invalid bid attempted");
}
catch (InvalidOperationException) { /* Expected */ }
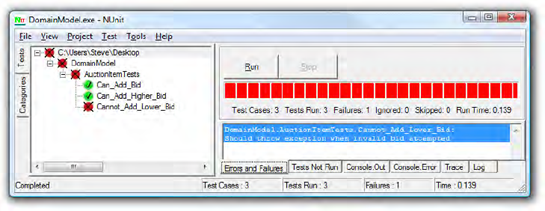
}Run all three tests together, and you'll see that Can_Add_Bid and Can_Add_Higher_Bid both pass, whereas Cannot_Add_Lower_Bid fails, showing that the test correctly detects a failure to prevent adding lower bids (see Figure 3-9).
Of course, there isn't yet any code to prevent you from adding lower bids. Update Item.AddBid():
public void AddBid(Member fromMember, decimal bidAmount)
{
if ((Bids.Count() > 0) && (bidAmount <= Bids.Max(b => b.BidAmount)))
throw new InvalidOperationException("Bid too low");
else
{
_bids.Add(new Bid
{
Member = fromMember,
BidAmount = bidAmount,
DatePlaced = DateTime.Now,
ItemID = this.ItemID
});
}
}Run the tests again and all three will pass! And that, in a nutshell, is TDD. We drove the development process by specifying a sequence of required behaviors (first, you can add bids, and second, you can't add lower bids). We represented each specification as a unit test, and the code to satisfy them followed.
Writingunit tests certainly means you have to do more typing, but it ensures that the code's behavior is now "locked down" forever—nobody's going to break this code without noticing it, and you can refactor to your heart's content, and then get rapid reassurance that the whole code base still works properly.
Personally, I love being able to do long stretches of work on my domain model, service classes, or other back-end infrastructure code—unit testing behavior as I go, without ever having to fire up a web browser. It's faster, and I can test edge cases that would be very difficult to simulate manually through the application's UI. Adding in the red-green iterative workflow might seem to increase the workload further, but does it really? If you're going to write unit tests anyway, you might as well write them first.
But what about user interfaces, and specifically in ASP.NET MVC, controllers?
If you don't have integration tests, or if your controllers contain complex logic, you'll get a lot of benefit from designing them through unit tests and having the safety net of being able to rerun the unit test suite at any time.
If you do have integration tests, and if you're disciplined enough to factor any significant complexity out of your controllers and into separately unit-tested domain or service classes, then there isn't a strong case for unit testing the controllers themselves; the maintenance cost can easily outweigh the small benefit gained.
Integration tests can be a better fit for user interfaces, because often it's more natural to specify UI behaviors as sequences of interactions—maybe involving JavaScript and multiple HTTP requests—rather than just isolated, atomic C# method calls. However, integration tests are much more difficult to set up than unit tests, and have other drawbacks such as running more slowly. Every project has its own unique requirements and constraints; you must choose your own methodology.
Since ASP.NET MVC has specific support for unit testing (it doesn't need to give specific support for integration testing, because most approaches to integration simply involve automating the application's UI), I'll demonstrate it throughout this book. For example, Controller classes aren't coupled to the HTTP runtime—they access Request, Response, and other context objects only through abstract interfaces, so you can replace them with fake or mock versions during tests. Controller factories give you an easy way to instantiate controllers through a DI container, which means you can hook them up to any graph of loosely coupled components, including mocks or test doubles.
For web applications, the most common approach to integration testing is UI automation, which means automating a web browser—simulating an end user clicking links and submitting forms—to exercise the application's entire technology stack. The two best-known open source browser automation options for .NET developers are
Selenium RC (
http://seleniumhq.org/), which consists of a Java "server" application that can send automation commands to Internet Explorer, Firefox, Safari, or Opera, plus clients for .NET, Python, Ruby, and multiple others so that you can write test scripts in the language of your choice. Selenium is powerful and mature; its only drawback is that you have to run its Java server.WatiN (
http://watin.sourceforge.net/), a .NET library that can send automation commands to Internet Explorer or Firefox. Its API isn't quite as powerful as Selenium's, but it comfortably handles most common scenarios and is easy to set up—you need only reference a single DLL.
Here's an example integration test, written using NUnit and WatiN, for the default application that Visual Studio gives you when you create a brand new ASP.NET MVC 2 web application. It checks that once a user is logged in, their login name appears in the page header area.
[TestFixture]
public class UserAccountTests
{
private const string rootUrl = "http://localhost:8080";
[Test]
public void DisplaysUserNameInPageHeader()
{var userName = "steve";
var password = "mysecret";
// Register a new account
using (var browser = CreateBrowser()) {
browser.GoTo(rootUrl + "/Account/Register");
browser.TextField("UserName").Value = userName;
browser.TextField("Email").Value = "[email protected]";
browser.TextField("Password").Value = password;
browser.TextField("ConfirmPassword").Value = password;
browser.Forms[0].Submit();
}
// Log in and check the page caption
using (var browser = CreateBrowser()) {
browser.GoTo(rootUrl + "/Account/LogOn");
browser.TextField("UserName").Value = userName;
browser.TextField("Password").Value = password;
browser.Forms[0].Submit();
browser.GoTo(rootUrl);
string actualHeaderText = browser.Element("logindisplay").Text;
StringAssert.Contains("Welcome " + userName + "!", actualHeaderText);
}
}
// Just using IE here, but WatiN can automate Firefox too
private Browser CreateBrowser() { return new IE(); }
}This integration test has a number of benefits over a unit test for the same behavior:
It can naturally describe a flow of interactions through the user interface, not just an isolated C# method call. It clearly shows that an end user really could do this, and documents or acts as the design for how they could do it.
It can describe and verify JavaScript or browser behaviors just as easily as server-side behaviors in your ASP.NET MVC application.
You can run an integration test suite against a remotely deployed instance of your application to gain confidence that the web server, the database, the application, the routing system, the firewall, and so on are configured properly and won't prevent an end user from successfully using the deployed site.
At the same time, there are drawbacks:
It's slow—perhaps two or more orders of magnitude slower than a unit test against a local .NET assembly. This is because it involves HTTP requests, rendering HTML pages, database queries, and so on. You can run a big integration test suite overnight, but not before each source control commit.
It's likely to require more maintenance. Clearly, if you change your models or views, then the DOM elements' IDs may change, so the preceding integration test may start failing. Less obviously, if over time you change the meaning of being logged in or the requirements for user registration, integration tests that rely on old assumptions will start to fail.
Because it uses a real database rather than a mock one, you have to think about managing the test data and possibly resetting it after each test run (though in this example, you could avoid that by using a different randomly generated username on each run). Your mechanism will depend on the database technology in use: for SQL Server Developer or Enterprise editions you can use snapshot/revert; for other SQL Server editions you can use backup/restore; other database platforms have their own mechanisms.
The speed and test data issues are fundamental, but to address the maintenance issue, let's consider a different approach to structuring integration tests.
Over the last few years, TDD practitioners have been refining the methodology in an effort to increase its usefulness and avoid some of the difficulties that newcomers often face. The main movement, now known as Behavior Driven Development, has been toward specifying an application's behavior in business domain terms rather than code implementation terms.
For example, instead of having a unit test called RegistrationTest or even Registration_NullEmail_ThrowsException, BDD practitioners would have a "specification" called "Users cannot register without an e-mail address." It's supposed to help you elevate your thinking above the code implementation. Why? Because if you can't think beyond the implementation, then your tests will merely be another way of describing the same implementation, and it might be that neither of them is really what the business wants.
BDD can be done at the code unit level, as TDD is traditionally done, but it's also often done at the UI level using integration test tools. Within the Ruby community, a popular tool called Cucumber introduced a streamlined way of structuring BDD-style integration tests. Cucumber lets you use a flexible, human-readable language called Gherkin (Ruby folks seem to love product names like these ...). Here's how you could rewrite the previous integration test in Gherkin:
Scenario: See my account name in the page header
Given I have registered as a user called "Steve"
And I am logged in as "Steve"
When I go to the homepage
Then the page header should display "Welcome Steve!"That doesn't look much like a programming language! But it is (well, a domain-specific language for integration testing), as well as a form of documentation. But it's not magic: in order to execute this specification, you need to provide step definitions that tell the runner how to execute each line of the previous listing. Gherkin only has a few keywords—Given (for preconditions), When (for the user's actions), Then (for expected outcomes), and a few others—all the other text is matched against regular expressions in your step definitions. This way of describing sequences of interactions is known as given-when-then (GWT).[20]
Cucumber lets you write step definitions in Ruby. If you prefer C#, there are a few open source .NET Gherkin runners you can choose from. At the moment, my favorite of these is SpecFlow (http://specflow.org/), which can call step definitions written in any .NET language and transparently converts the Gherkin feature files into NUnit test fixtures so you can use any NUnit runner (or compatible continuous integration system) to run them.
The following C# step definitions illustrate how you can use SpecFlow with WatiN to automate a browser and extract parameters from lines in a Gherkin feature specification:
[Binding]
public class Homepage
{
[When(@"I go to the homepage")]
public void WhenIGoToTheHomepage() {
WebBrowser.Current.GoTo(WebBrowser.RootUrl);
}
[Then(@"the page header should display ""(.*)""")]
public void ThenThePageHeaderShouldDisplay(string text) {
string actualHeaderText = WebBrowser.Current.Element("logindisplay").Text;
StringAssert.Contains(text, actualHeaderText);
}
}Note
If you want to run this code as a complete working example (including the implementation of WebBrowser.Current), download the source code from this book's page on the Apress web site, at http://tinyurl.com/y7mhxww. You'll need to install SpecFlow from http://specflow.org/ before you can edit the Gherkin .feature files.
That's pretty easy. The runner matches the Gherkin lines against your regular expressions (shown in bold), passing any capture groups to your method as parameters.
To handle the remaining lines, the following code shows how you can store temporary state during a specification run (it uses a dictionary object to track randomly generated passwords):
[Binding]
public class UserRegistration
{
private Dictionary<string, string> passwords = new Dictionary<string, string>();
[Given(@"I have registered as a user called ""(.*)""")]
public void GivenIHaveRegisteredAsAUserCalled(string userName) {
passwords[userName] = Guid.NewGuid().ToString();
WebBrowser.Current.GoTo(WebBrowser.RootUrl + "/Account/Register");
WebBrowser.Current.TextField("UserName").Value = userName;
WebBrowser.Current.TextField("Email").Value = "[email protected]";
WebBrowser.Current.TextField("Password").Value = passwords[userName];
WebBrowser.Current.TextField("ConfirmPassword").Value = passwords[userName];
WebBrowser.Current.Forms[0].Submit();
}
[Given(@"I am logged in as ""(.*)""")]
public void GivenIAmLoggedInAs(string userName) {WebBrowser.Current.GoTo(WebBrowser.RootUrl + "/Account/LogOff");
WebBrowser.Current.GoTo(WebBrowser.RootUrl + "/Account/LogOn");
WebBrowser.Current.TextField("UserName").Value = userName;
WebBrowser.Current.TextField("Password").Value = passwords[userName];
WebBrowser.Current.Forms[0].Submit();
}
}This has a range of advantages over writing plain WatiN tests:
Gherkin files are human-readable and written in the language of your business domain, so you can ask customers or business experts for feedback about whether your behavior specifications really match and cover their requirements.
Gherkin lets you be as fuzzy or as precise as you like. This leads to a human-friendly development process sometimes called outside-in. You can first collect early customer requirements in vague high-level terms, and then over time perform further analysis to refine these into clearer or more consistent steps. Finally, you can write the precise step definitions alongside the implementation code.
Assuming you write the GWT steps in business domain terms (not in detailed UI interaction terms, which change more frequently), the steps will be highly reusable between scenarios. Once you've covered the main domain concepts, a lot of new scenarios can be constructed purely from existing step definitions. This greatly eases the maintenance burden: if you change the meaning of logging in or the requirements for user registration, you only need to change one step definition.
This form of integration testing does work well, especially if you're handling complex user interaction workflows and need confidence that changes to these workflows or application configuration don't stop existing features from working. But I won't lie to you: it's significantly harder to set up than unit tests, and because it involves so many moving parts, it still requires diligent maintenance.
The main reason I've included the last few pages about integration testing and the GWT model is to emphasize that design and testability aren't only matters of unit testing (and I haven't even mentioned performance testing, security testing, usability testing, etc.). Too many ASP.NET MVC developers have put a disproportionate emphasis on unit testing without weighing its business value against other techniques.
However, there are a number of reasons why this book's development methodology still focuses on unit testing and doesn't demonstrate integration testing in detail:
ASP.NET MVC itself provides specific support for unit testing. To be faithful to the subject matter, that's what I need to show you.
Many readers will be totally new to automated testing and will benefit most by learning about unit test-driven development—a fundamental methodology you can apply not only to ASP.NET MVC but also very well to business domain logic and other non-UI code.
Integration testing involves complexities beyond this book's subject matter (e.g., managing test data in a database).
So, the next few chapters will demonstrate building a realistic e-commerce application with ASP.NET MVC through unit test-driven development—a very valuable technique, though not the only option.
ASP.NET MVC 2 is built on .NET 3.5. To use it effectively, you need to be familiar with all the language features that Microsoft added to C# 3 with .NET 3.5 and Visual Studio 2008, including anonymous types, lambda methods, extension methods, and LINQ. Of course, we now also have .NET 4 and Visual Studio 2010, but the new C# 4 language features such as dynamic invocation and named/optional parameters aren't prerequisites for using ASP.NET MVC 2: for backward compatibility, it doesn't depend on them at all.
If you're already familiar with C# 3, you can safely skip ahead to the next chapter. Otherwise, if you're moving from C# 2, you'll need this knowledge before you can really understand what's going on in an ASP.NET MVC application. I'll assume you already understand C# 2, including generics, iterators (i.e., the yield return statement), and anonymous delegates.
Almost all the new language features in C# 3 have one thing in common: they exist to support language-integrated query (LINQ). The idea of LINQ is to make data querying a native feature of the language, so that when you're selecting, sorting, filtering, or transforming of sets of data—whether it's a set of .NET objects in memory, a set of XML nodes in a file on disk, or a set of rows in a SQL database—you can do so using one standard, IntelliSense-assisted syntax in your C# code (and using far less code).
As a very simple example, in C# 2, if you wanted to find the top three integers in an array, you'd write a function like this:
int[] GetTopThreeValues(int[] values)
{
Array.Sort(values);
int[] topThree = new int[3];
for (int i = 0; i < 3; i++)
topThree[i] = values[values.Length − i − 1];
return topThree;
}whereas using LINQ, you'd simply write this:
var topThree = (from i in values orderby i descending select i).Take(3);
Note that the C# 2 code has the unfortunate side effect of destroying the original sort order of the array—it's slightly trickier if you want to avoid that. The LINQ code does not have this problem.
At first, it's hard to imagine how this strange, SQL-like syntax actually works, especially when you consider that much more complex LINQ queries might join, group, and filter heterogeneous data sources. Let's consider each one of the underlying mechanisms in turn, not just to help you understand LINQ, but also because those mechanisms turn out to be useful programming tools in their own right, and you need to understand their syntax to use ASP.NET MVC effectively.
Have you ever wanted to add an extra method to a class you don't own? Extension methods give you the syntactic convenience of "adding" methods to arbitrary classes, even sealed ones, without letting you access their private members or otherwise compromising on encapsulation.
For example, a string doesn't by default have a method to convert itself to title case (i.e., capitalizing the first letter of each word), so you might traditionally define a static method to do it:
public static string ToTitleCase(string str)
{
if (str == null)
return null;
else
return CultureInfo.CurrentUICulture.TextInfo.ToTitleCase(str);
}Now, by placing this static method into a public static class, and by using the this keyword in its parameter list, as in the following code:
public static class MyExtensions{public static string ToTitleCase(this string str){ if (str == null) return null; else return CultureInfo.CurrentUICulture.TextInfo.ToTitleCase(str); } }
you have created an extension method (i.e., a static method that takes a this parameter). The C# compiler lets you call it as if it were a method on the .NET type corresponding to the this parameter—for example:
string place = "south west australia"; Console.WriteLine(place.ToTitleCase()); // Prints "South West Australia"
Of course, this is fully recognized by Visual Studio's IntelliSense. Note that it doesn't really add an extra method to the string class. It's just a syntactic convenience: the C# compiler actually converts your code into something looking almost exactly like the first nonextension static method in the preceding code, so there's no way you can violate any member protection or encapsulation rules this way.
There's nothing to stop you from defining an extension method on an interface, which creates the previously impossible illusion of having code automatically shared by all implementers of an interface. The following example uses the C# 2 yield return keyword to get all the even values out of an IEnumerable<int>:
public static class MyExtensions
{
public static IEnumerable<int> WhereEven(this IEnumerable<int> values)
{
foreach (int i in values)
if (i % 2 == 0)
yield return i;
}
}You'll now find that WhereEven() is available on List<int>, Collection<int>, int[], and anything else that implements IEnumerable<int>.
If you wanted to generalize the preceding WhereEven() function into an arbitrary Where<T>() function, performing an arbitrary filter on an arbitrary data type, you could use a delegate, like so:
public static class MyExtensions
{
public delegate bool Criteria<T>(T value);
public static IEnumerable<T> Where<T>(this IEnumerable<T> values,
Criteria<T> criteria)
{
foreach (T item in values)
if (criteria(item))
yield return item;
}
}Now you could, for example, use Where<T> to get all the strings in an array that start with a particular letter, by passing a C# 2 anonymous delegate for its criteria parameter:
string[] names = new string[] { "Bill", "Jane", "Bob", "Frank" };
IEnumerable<string> Bs = names.Where<string>(
delegate(string s) { return s.StartsWith("B"); }
);I think you'll agree that this is starting to look quite ugly. That's why C# 3 introduces lambda methods (well, it borrows them from functional programming languages), which have simplified syntax for writing anonymous delegates. The preceding code may be reduced to
string[] names = new string[] { "Bill", "Jane", "Bob", "Frank" };
IEnumerable<string> Bs = names.Where<string>(s => s.StartsWith("B"));That's much tidier, and even starts to read a bit like an English sentence. In general, lambda methods let you express a delegate with any number of parameters using the following syntax:
(a, b, c) => SomeFunctionOf(a, b, c)
If you're describing a delegate that takes only one parameter, you can drop the first set of brackets:
x => SomeFunctionOf(x)
You can even put more than one line of code into a lambda method, finishing with a return statement:
x => {
var result = SomeFunctionOf(x);
return result;
}Once again, this is just a compiler feature, so you're able to use lambda methods when calling into a .NET 2.0 assembly that expects a delegate.
Actually, the previous example can be made one step simpler:
string[] names = new string[] { "Bill", "Jane", "Bob", "Frank" };
IEnumerable<string> Bs = names.Where(s => s.StartsWith("B"));Spot the difference. This time, we haven't specified the generic parameter for Where<T>()—we just wrote Where(). That's another one of the C# 3 compiler's party tricks: it can infer the type of a function's generic argument from the parameters of a delegate (or lambda method) passed to it. (The C# 2 compiler had some generic type inference abilities, but it couldn't do this.)
Now we have a totally general purpose Where() operator with a tidy syntax, which takes you a long way toward understanding how LINQworks.
This may seem like a strange tangent in this discussion, but bear with me. Most of us C# programmers are, by now, quite bored of writing properties like this:
private string _name;
public string Name
{
get { return _name; }
set { _name = value; }
}
private int _age;
public int Age
{
get { return _age; }
set { _age = value; }
}
// ... and so onSo much code, so little reward. It makes you tempted just to expose a public field on your class, considering that the end result is the same, but that would prevent you from ever adding getter or setter logic in the future without breaking compatibility with assemblies you've already shipped (and screwing up data binding). Fortunately, our hero the C# 3 compiler is back with a new syntax:
public string Name { get; set; }
public int Age { get; set; }These are known as automatic properties. During compilation, the C# 3 compiler automatically adds a private backing field for each automatic property (with a weird name you'll never access directly), and wires up the obvious getters and setters. So now you have the benefits without the pain. Note that you can't omit the get; or set; clauses to create a read-only or write-only field; you add an access modifier instead—for example:
public string Name { get; private set; }
public int Age { internal get; set; }Should you need to add custom getter or setter logic in the future, you can convert these to regular properties without breaking compatibility with anything. There's a missing feature, though—there's no way to assign a default value to an automatic property as you can with a field (e.g., private object myObject = new object();), so you have to initialize them during your constructor, if at all.
Here's another common programming task that's quite boring: constructing objects and then assigning values to their properties. For example
Person person = new Person(); person.Name = "Steve"; person.Age = 93; RegisterPerson(person);
It's one simple task, but it takes four lines of code to implement it. Just when you were on the brink of getting RSI, the C# 3 compiler swoops in with a new syntax:
RegisterPerson(new Person { Name = "Steve", Age = 93 });So much better! By using the curly brace notation after a new expression, you can assign values to the new object's publicly settable properties, which is great when you're just creating a quick new instance to pass into a method. The code within the curly braces is called an object initializer, and you can put it after a normal set ofconstructor parameters if you need. Or, if you're calling a parameterless constructor, you can simply omit the normal constructor parentheses.
Along similar lines, the C# 3 compiler will generate some code for you if you're initializing a new collection—for example:
List<string> countries = new List<string>();
countries.Add("England");
countries.Add("Ireland");
countries.Add("Scotland");
countries.Add("Wales");can now be reduced to this:
List<string> countries = new List<string> {
"England", "Ireland", "Scotland", "Wales"
};The compiler lets you use this syntax when constructing any type that exposes a method called Add(). There's a corresponding syntax for initializing dictionaries, too:
Dictionary<int, string> zipCodes = new Dictionary<int,string> {
{ 90210, "Beverly Hills" },
{ 73301, "Austin, TX" }
};C# 3also introduces the var keyword, in which a local variable is defined without specifying an explicit type; the compiler infers the type from the value being assigned to it—for example:
var now = new DateTime(2001, 1, 1); // The variable takes the type DateTime
int dayOfYear = now.DayOfYear; // This is legal
string test = now.Substring(1, 3); // Compiler error! No such function on DateTimeThis is called type inference or implicit typing. Note that, although many developers misunderstand this point at first, the var keyword does not create dynamically typed variables (e.g., in the sense that all variables are dynamically typed in JavaScript, or in the sense of C#4's dynamic invocation). After compilation, the variable is just as explicitly typed as ever—the only difference is that the compiler works out what type it should be instead of being told. Implicitly typed variables can only be used in a local method scope: you can't use var for a class member or as a return type.
An interesting thing happens at this point. By combining object initializers with type inference, you can construct simple data storage objects without ever having to define a corresponding class anywhere—for example:
var salesData = new { Day = new DateTime(2009, 01, 03), DollarValue = 353000 };
Console.WriteLine("In {0}, we sold {1:c}", salesData.Day, salesData.DollarValue);Here, salesData is an anonymously typed object. Again, that doesn't mean it's dynamically typed; it's of some real .NET type that you just don't happen to know (or care about) the name of. The C# 3 compiler will generate an invisible class definition on your behalf during compilation. Note that Visual Studio's IntelliSense is fully aware of what's going on here, and will pop up the appropriate property list when you type salesData., even though the type it's prompting you about doesn't even exist yet. Clever stuff indeed.
The compiler generates a different class definition for each combination of property names and types that you use to build anonymously typed objects. So, if two anonymously typed objects have the same property names and types, then at runtime they'll actually be of the same .NET type. This means you can put corresponding anonymously typed objects into an anonymously typed array—for example:
var dailySales = new[] {
new { Day = new DateTime(2009, 01, 03), DollarValue = 353000 },
new { Day = new DateTime(2009, 01, 04), DollarValue = 379250 },
new { Day = new DateTime(2009, 01, 05), DollarValue = 388200 }
};For this to be allowed, all the anonymously typed objects in the array must have the same combination of property names and types. Notice that dailySales is still introduced with the var keyword, never var[], List<var>, or anything like that. Because var means "whatever fits," it's always sufficient on its own, and retains full type safety both at compile time and runtime.
If you haven't seen any of these features before, the last few pages may have seemed quite bizarre, and it might not be obvious how any of this contributes to LINQ. But actually, the scene is now set and all can be revealed.
You've already seen how you might implement a Where() operator using extension methods, lambda methods, and generic type inference. The next big step is to show how implicitly typed variables and anonymous types support a projection operator (i.e., the equivalent to the SELECT part of a SQL query). The idea with projection is that, for each element in the source set, we want to map it to a transformed element to go into the destination set. In C# 2 terms, you'd use a generic delegate to map each element, like this:
public delegate TDest Transformation<TSrc, TDest>(TSrc item);
But in C# 3, you can use the built-in delegate type Func<TSrc, TDest>, which is exactly equivalent. So, here's a general purpose projection operator:
public static class MyExtensions
{
public static IEnumerable<TDest> Select<T, TDest>(this IEnumerable<T> values,
Func<T, TDest> transformation)
{
foreach (T item in values)
yield return transformation(item);
}
}Now, given that both Select<T, TDest>() and Where<T>() are available on any IEnumerable<T>, you can perform an arbitrary filtering and mapping of data onto an anonymously typed collection:
// Prepare sample data
string[] nameData = new string[] { "Steve", "Jimmy", "Celine", "Arno" };
// Transform onto an enumerable of anonymouslytyped objects
var people = nameData.Where(str => str != "Jimmy") // Filter out Jimmy
.Select(str => new { // Project on to anonymous type
Name = str,
LettersInName = str.Length,
HasLongName = (str.Length > 5)
});
// Retrieve data from the enumerable
foreach (var person in people)
Console.WriteLine("{0} has {1} letters in their name. {2}",
person.Name,
person.LettersInName,
person.HasLongName ? "That's long!" : ""
);This will print the following to the console:
Steve has 5 letters in their name. Celine has 6 letters in their name. That's long! Arno has 4 letters in their name.
Note that we're assigning the results of the query to an implicitly typed (var) variable. That's because the real type is an enumerable of anonymously typed objects, so there's no way of writing its type explicitly (but the compiler can do so during compilation).
Hopefully it's clear by now that, with Select() and Where(), this could be the basis for a general purpose object query language. No doubt you could also implement OrderBy(), Join(), GroupBy(), and so on. But of course you don't have to, because that's exactly what LINQ to Objects already is—a general purpose query language for in-memory collections of .NET objects, built almost exactly along the lines described here.
I'd like to make one final point before we move on. Since all the code used to build these query operators uses C# 2.0 iterator blocks (i.e., using the yield return keyword), the enumerables don't actually get evaluated until you start enumerating over them. That is, when we instantiated var people in the previous example, it defined the nature and parameters of the query (somewhat reminiscent of a closure[21]), but didn't actually touch the data source (nameData) until the subsequent foreach loop pulled out the results one by one. Even then, the iterator code only executes one iteration at a time, not transforming each record until you specifically request it.
This is more than just a theoretical point. It makes a great difference when you're composing and combining queries—especially later when you query an external SQL database—to know that the expensive bit doesn't actually happen until the last possible moment.
So finally we're here. You've now seen essentially how LINQ to Objects works, and using the various C# 3 features, you could pretty much reinvent it yourself if you had to. You could certainly add extra general purpose query operators if they turned out to be useful.
When Microsoft's LINQ team got this far, they organized some usability testing, had a beer, and considered their work finished. But predictably, early adopters were still not satisfied. The feedback was that the syntax was still too complicated, and why didn't it just look like SQL? All the dots and brackets were giving people a headache. So, the LINQ crew got back to business and designed a more expressive syntax for the same queries. The previous example could now be reexpressed as
var people = from str in nameData
where str != "Jimmy"
select new{
Name = str,
LettersInName = str.Length,
HasLongName = (str.Length > 5)
};This new syntax is called a query expression. It's an alternative to writing chains of LINQ extension methods, as long as your query follows a prescribed structure. It's very reminiscent of SQL, I'm sure you'll agree, except that select comes at the end rather than the beginning (which makes more sense when you think about it).
It doesn't make much difference in this example, but query expressions are arguably easier to read than chains of extension methods if you have a longer query with many clauses and subclauses. It's entirely up to you which syntax you choose to use—it makes no difference at runtime, considering that the C# 3 compiler simply converts query expressions into a chain of extension method calls early in the compilation process anyway. Personally, I find some queries easier to express as a chain of function calls, and others look nicer as query expressions, so I swap back and forth between the two.
Note
In query expression syntax, the keywords (from, where, orderby, select, etc.) are hard-coded into the language. You can't add your own keywords. There are lots of LINQ extension methods that are only reachable by calling them directly, because there's no corresponding query expression keyword. You can of course use extension method calls inside a query expression (e.g., from p in people.Distinct() orderby p.Name select p).
The final new C# 3 compiler feature isn't something you'll want to involve in all your code, but it creates powerful new possibilities for API designers. It's the basis for LINQ to Everything, as well as some of the ingeniously expressive APIs in ASP.NET MVC.
Lambda expressions look just like lambda methods—the syntax is identical—but during compilation they aren't converted into anonymous delegates. Instead, they're embedded in the assembly as data—not code—called an abstract syntax tree (AST). Here's an example:
// This is a regular lambda method and is compiled to .NET code Func<int, int, int> add1 = (x, y) => x + y;// This is a lambda expression, and is compiled to *data* (an AST)Expression<Func<int, int, int>> add2 = (x, y) => x + y;// You can compile the expression *at runtime* and then run it Console.WriteLine("1 + 2 = " + add2.Compile()(1, 2)); // Or, at runtime, you can inspect it as a hierarchy of expressions Console.WriteLine("Root node type: " + add2.Body.NodeType.ToString()); BinaryExpression rootNode = add2.Body as BinaryExpression; Console.WriteLine("LHS: " + rootNode.Left.NodeType); Console.WriteLine("RHS: " + rootNode.Right.NodeType);
This will output the following:
1 + 2 = 3 Root node type: Add LHS: Parameter RHS: Parameter
So, merely by adding Expression<> around the delegate type, add2 becomes a data structure that you can do two different things with at runtime:
Compile into an executable delegate simply by calling
add2.Compile()Inspect as a hierarchy of expressions (here, it's a single
Addnode taking two parameters)
What's more, you can manipulate the expression tree data at runtime, and then still compile it to executable code.
But why on earth would you want to do any of this? It's not just an opportunity to write bizarre, self-modifying code that confuses the heck out of your coworkers (although that is an option). The main purpose is to let you pass code as a parameter into an API method—not to have that code executed, but to communicate some other intention. For example, ASP.NET MVC's Html.TextBoxFor() method takes a parameter of type Expression<Func<modelType, propertyType>>. You call it like this:
Html.TextBoxFor(x =>x.PhoneNumber)
This uses a whole bunch of C# 3 features. First, it's an extension method. Second, the compiler infers the two generic parameters (modelType and propertyType) from the type of the Html object you're using and the lambda expression you pass to the method. Third, the lambda expression gets compiled into a hierarchy consisting of a single MemberAccess node, specifying the model property you've referenced. ASP.NET MVC doesn't just evaluate the expression to get the property value; it also uses the AST to figure out the property name and any metadata associated with that property so that it can render a suitably annotated text box.
Now that you have lambda expressions, you can do some seriously clever things. There's an important standard interface in .NET 3.5 called IQueryable<T>. It represents deferred-execution queries that can be compiled at runtime not just to executable .NET code, but—theoretically—to anything. Most famously, LINQ to SQL (which works on .NET 3.5) and Entity Framework (the latest version of which requires .NET 4) provide IQueryable<T> objectsthat they can convert to SQL queries.
For example, assume that in your code you have something like this:
var members = (from m in myDataContext.GetTable<Member>()
where m.LoginName == "Joey"
select m).ToList();LINQ to SQL coverts this into a parameterized (yes, SQL injection-proof) database query, as follows:
SELECT [t0].[MemberID], [t0].[LoginName], [t0].[ReputationPoints]
FROM [dbo].[Members] AS [t0]
WHERE [t0].[LoginName] = @p0
{Params: @p0 = 'Joey'}So, how does it work? To get started, let's break that single line of C# code into three parts:
// [1] Get an IQueryable to represent a database tableIQueryable<Member> membersTable = myDataContext.GetTable<Member>();// [2] Convert the first IQueryable into a different one by // prepending its lambda expression with a Where() nodeIQueryable<Member> query1 = membersTable.Where(m => m.LoginName == "Joey");// ... or use this syntax, which is equivalent after compilation IQueryable<Member> query2 = from m in membersTable where m.LoginName == "Joey" select m;
// [3] Now execute the query
IList<Member> results = query1.ToList();After step 1, you have an object of type System.Data.Linq.Table<Member>, implementing IQueryable<Member>. The Table<Member> class handles various SQL-related concerns such as connections, transactions, and the like, but more importantly, it holds a lambda expression object, which at this stage is just a ConstantExpression pointing to itself (membersTable).
During step 2, you're calling not Enumerable.Where() (i.e., the .Where() extension method that operates on an IEnumerable), but Queryable.Where() (i.e., the .Where() extension method that operates on an IQueryable). That's because membersTable implements IQueryable, which takes priority over IEnumerable. Even though the syntax is identical, it's a totally different extension method, and it behaves totally differently. What Queryable.Where() does is take the existing lambda expression (currently just a ConstantExpression) and create a new lambda expression: a hierarchy that describes both the previous lambda expression and the predicate expression you've supplied (i.e., m => m.LoginName == "Joey") (see Figure 3-10).
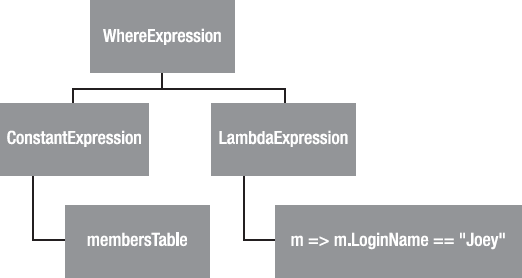
If you specified a more complex query, or if you built up a query in several stages by adding extra clauses, the same thing would happen. No databases are involved—each Queryable.* extension method just adds extra nodes to the internal lambda expression, combining it with any lambda expressions you supply as parameters.
Finally, in step 3, when you convert the IQueryable object to a List or otherwise enumerate its contents, behind the scenes it walks over its internal lambda expression, recursively converting it into SQL syntax. This is far from simple: it has special-case code for every C# language operator you might have used in your lambda expressions, and even recognizes specific common function calls (e.g., string.StartsWith()) so it can "compile" the lambda expression hierarchy into as much pure SQL as possible. If your lambda expression involves things it can't represent as SQL (e.g., calls to custom C# functions), it has to figure out a way of querying the database without them, and then filtering or transforming the result set by calling your C# functions later. Despite all this complexity, it does an outstanding job of producing tidy SQL queries.
Note
LINQ to SQLand Entity Framework both also add extra ORM facilities that aren't built on the IQueryable<T> query expression infrastructure, such as the ability to track the changes you make to any objects they have returned, and then commit those changes back to the database.
IQueryable<T> isn't just about LINQ to SQL and Entity Framework. You can use the same query operators, and the same ability to build up lambda expression trees, to query other data sources. It might not be easy, but if you can interpret lambda expression trees in some other custom way, you can create your own "query provider." Other ORM projects support IQueryable<T> (e.g., LINQ to NHibernate), and there are emerging query providers for MySQL, LDAP data stores, RDF files, SharePoint, and so on. As an interesting aside, consider the elegance of LINQ to Amazon:
var mvcBooks = from book in new Amazon.BookSearch()
where book.Title.Contains("ASP.NET MVC")
&& (book.Price < 49.95)
&& (book.Condition == BookCondition.New)
select book;In this chapter, you got up to speed with the core concepts underpinning ASP.NET MVC, and the tools and techniques needed for successful web development with .NET and C# 3 or later. In the next chapter, you'll use this knowledge to build a real ASP.NET MVC e-commerce application, combining MVC architecture, loosely coupled components, unit testing, and a clean domain model built with an object-relational mapping (ORM) tool.
[12] Or in ASP.NET Web Forms, by writing a series of tags endowed with the special runat="server" attribute.
[13] I'm using language that I prefer, but you may substitute the terms business logic or engine for domain model if you're more familiar with those. I prefer domain model because it reminds me of some of the clear concepts in domain-driven design (mentioned later).
[14] Some argue that it should be called three-layer architecture, because the word tiers usually refers to physically separate software services (i.e., running on different servers or at least in different OS processes). That distinction doesn't matter for this discussion, however.
[15] Many DDD practitioners strive to decouple their domain entities from all notions of persistence (e.g., database storage). This goal is known as persistence ignorance—it's another example of separation of concerns. But you shouldn't get too fixated on the idea of persistence ignorance, because in reality that goal often clashes with performance goals. Often, domain model objects have to be structured in a way that lets you query and load them efficiently according to the limitations of your persistence technology.
[16] For this to compile, your project needs a reference to System.Data.Linq.dll.
[17] The other common name for it is inversion of control (IoC). I don't like that name because it sounds like a magic spell from Harry Potter, and falsely gives the impression that it's more complicated, obscure, or advanced than it really is.
[18] It doesn't bring up this prompt if you use the ASP.NET MVC 2 Empty Web Application project template.
[19] If you have a build server (e.g. if you're using continuous integration), you can run such automated tests using a command-line tool as part of the build process.
[20] GWT is not the only way to do BDD. The GWT model (and the original Cucumber runner) did come from the Ruby BDD community, but that community has also pioneered other tools and techniques such as RSpec and the alternative context/specification model.
[21] In functional programming languages, a closure lets you defer the execution of a block of code without losing track of any local variables in its context. Depending on your precise definition of that term, you may or may not consider C# anonymous methods to be true closures.