
Linux is an incredible piece of software. It's an operating system that's just as at home running on IBM's zSeries supercomputers as it is on a cell phone, manufacturing device, network switch, or even cow milking machine. What's more incredible is that this software is currently maintained by thousands of the best software engineers and it is available for free.
Linux didn't start as an embedded operating system. Linux was created by a Finnish university student (Linus Torvalds) who was smart enough to make his work available to all, take input from others and, most important, delegate to other talented engineers. As the project grew, it attracted other talented engineers who were able to contribute to Linux, increasing the burgeoning project's value and visibility and thus bootstrapping a virtuous cycle that continues to this day.
Linux was first written to run on the Intel IA-32 architecture and was first ported to a Motorola processor. The porting process was difficult enough that Linus Torvalds decided to rethink the architecture so that it could be easily ported, creating a clean interface between the processor-dependent parts of the software and those that are architecture independent. This design decision paved the way for Linux to be ported to other processors.
Linux is just a kernel, which by itself isn't that useful. An embedded Linux system, or any Linux system for that matter, uses software from many other projects in order to provide a complete operating system. The Linux kernel is written largely in C (with some assembler) and uses the GNU tool set, such as make; the GCC compiler; programs that provide an interface to the kernel; and a host of others that you'll encounter in this book. Much of this software already existed at Linux's genesis, and, fortunately, much of it was written with portability in mind. The fact that this software could be used on an embedded system or could be modified to make it suitable for embedded deployment contributed greatly to the acceptance of Linux for devices other than desktop machines.
Note
Linux exists in no small part because of the GNU (Gnu's Not Unix) project, which was (and still is) developing an open source implementation of Unix. The GNU project provided a high-quality compiler and command-line make environment along with basic utilities expected on a Unix-like system.
This book takes you through using Linux for your embedded project. Because Linux and its associated projects are open source, you learn how to build everything you need for an embedded project from scratch. The entire Linux environment has advanced to the point that this undertaking is no longer a quixotic exercise; it falls squarely within the reach of any engineer willing to put in a reasonable amount of time and effort. Building a complete Linux system is the best training for creating a small Linux system; as a result, doing so is more than a morale-building exercise.
Embedded Linux is just like the Linux distributions running on millions of desktops and servers worldwide, but it's adapted to a specific use case. On desktop and server machines, memory, processor cycles, power consumption, and storage space are limited resources—they just aren't as limiting as they are for embedded devices. A few extra MB or GB of storage can be nothing but rounding errors when you're configuring a desktop or server. In the embedded field, resources matter because they drive the unit cost of a device that may be produced in the millions; or the extra memory may require additional batteries, which add weight. A processor with a high clock speed produces heat; some environments have very tight heat budgets, so only so much cooling is available. As such, most of the efforts in embedded programming, if you're using Linux or some other operating system, focus on making the most with limited resources.
Compared to other embedded operating systems, such as VxWorks, Integrity, and Symbian, Linux isn't the most svelte option. Some embedded applications use frameworks such as ThreadX[1] for application support; the framework runs directly on the hardware, eschewing an operating system altogether. Other options involve skipping the framework and instead writing code that runs directly on the device's processor. The biggest difference between using a traditional embedded operating system and Linux is the separation between the kernel and the applications. Under Linux, applications run in a execution context completely separate from the kernel. There's no way for the application to access memory or resources other than what the kernel allocates. This level of process protection means that a defective program is isolated from kernel and other programs, resulting in a more secure and survivable system. All of this protection comes at a cost.
Despite its increased resource overhead compared to other options, the adoption of Linux continues to increase. That means engineers working on projects consider the increased overhead of Linux worth the additional cost. Granted, in recent years, the costs and power demands of system-onchip (SOC) processors has decreased to the point that they cost no more than a low-power 8-bit microcontroller from the past, so using a more sophisticated processor is an option when it might not have been before. Many design solutions use off-the-shelf SOC processors and don't run the leads from chip for the Ethernet, video, or other unused components.
Linux has flourished because it provides capabilities and features that can't be made available with other embedded solutions. Those capabilities are essential to implementing the ever more sophisticated designs used to differentiate devices in today's market. The open source nature of Linux means embedded engineers can take advantage of the continual development happening in the open source environment, which happens at a pace that no single software vendor can match.
The technical qualities of Linux drives its adoption. Linux is more than the Linux kernel project. That software is also at the forefront of technical development, meaning that Linux is the right choice for solving today's technical problems as well as being the choice for the foreseeable future.
For example, an embedded Linux system includes software such as the following:
SSL/SSH: The OpenSSH project is the most commonly used encryption and security mechanism today. The open nature of the project means that thousands of security experts are constantly evaluating it; when problems are found, updates occur in a matter of hours, provided the update is not included with the exploit itself.
Apache and other web servers: The Apache web server finds its way into embedded devices that need a full-featured web server. For devices with less demanding requirements, users can pick from smaller web servers like Boa, lighttp, and (a personal favorite) micro_httpd.
The C Library: The Linux environment has a wealth of options in this area, from the fully featured GNU C Library to the minimalist dietlibc. If you're new to embedded Linux development, having a choice in this area reinforces the open nature of open source.
Berkeley sockets (IP): Many projects move to Linux from another operating system because of the complete, high-performance network stack included in the operating system. A networked device is becoming the rule and not the exception.
The following sections explain why the Linux operating system is the best technological fit for embedded development.
The Linux operating system and accompanying open source projects adhere to industry standards; in most cases, the implementation available in open source is the canonical, or reference, implementation of a standard. A reference implementation embodies the interpretation of the specification and is the basis for conformance testing. In short, the reference implementation is the standard by which others are measured.
If you're new to the notion of a reference implementation, it may be a little confusing. Take for example the Portable Operating System Interface for Unix (POSIX) for handling threads and interprocess communication, commonly called pthreads. The POSIX group, part of the Institute of Electrical and Electronics Engineers (IEEE) is a committee that designs APIs for accomplishing the tasks of interacting with a thread but leaves the implementation of that standard to another group. In practice, when work begins on a standard, one or more of the participants on the committee volunteer to create the code to bring the standard to life, creating the reference implementation. The reference implementation includes a test suite; other implementations consider the passage of the test suite as evidence that the code works as per the specification.
Using standards-based software is not only about quality but also about independence. Basing a project on software that adheres to standards reduces the chances of lock-in due to vendor-specific features. A vendor may be well meaning, but the benefits of those extra features are frequently outweighed by the lack of interoperability and freedom that silently become part of the transaction and frequently don't receive the serious consideration they merit.
Standards are increasingly important in a world where many embedded devices are connected, many times to arbitrary systems rather than just to each other. The Ethernet is one such connection method, but others abound, like Zigbee, CANbus, and SCSI, to name a few.
The Linux kernel, at its most basic level, offers these services as a way of providing a common API for accessing system resources:
Manage tasks, isolating them from the kernel and each other
Provide a uniform interface for the system's hardware resources
Serve as an arbiter to resources when contention exists
These are very important features that result in a more stable environment versus an environment where access to the hardware and resources isn't closely managed. For example, in the absence of an operating system, every program running has equal access to all available RAM. This means an overrun bug in one program can write into memory used by another program, which will then fail for what appear to be mysterious, unexplainable reasons until all the code on the system is examined. The notion of resource contention is more complex than just making sure two processes don't attempt to write data to the serial port simultaneously—the scarcest resource is time, and the operating system can decide what tasks run when in order to maximize the amount of work performed. The following sections look at each item in more detail.
Linux is a multitasking operating system. In Linux, the word process describes a task that the kernel tracks for execution. The notion of multitasking means the kernel must keep some data about what is running, the current state of the task, and the resources it's using, such as open files and memory.
For each process, Linux creates an entry in a process table and assigns the process a separate memory space, file descriptors, register values, stack space, and other process specific information. After it's created, a process can't access the memory space of another process unless both have negotiated a shared memory pool; but even access to that memory pool doesn't give access to an arbitrary address in another process.
Processes in Linux can contain multiple execution threads. A thread shares the process space and resources of the process that started it, but it has its own instruction pointer. Threads, unlike processes, can access each other's memory space. For some applications, this sharing of resources is both desired and convenient; however, managing several threads' contention for resources is a study unto itself. The important thing is that with Linux, you have the design freedom to use these process-control constructs.
Processes are isolated not only from each other but from the kernel as well. A process also can't access arbitrary memory from the kernel. Access to kernel functionality happens under controlled circumstances, such as syscalls or file handles. A syscall, short for system call, is a generic concept in operating system design that allows a program to perform a call into the kernel to execute code. In the case of Linux, the function used to execute a system call is conveniently named syscall().
When you're working with a syscall, as explained later in this chapter, the operation works much like a regular function call for an API. Using a file handles, you can open what appears to be a file to read and write data. The implementation of a file still reduces to a series of syscalls; but the file semantics make them easier to work with under certain circumstances.
The complete separation of processes and the kernel means you no longer have to debug problems related to processes stepping on each other's memory or race conditions related to trying to access shared resources, such as a serial port or network device. In addition, the operating system's internal data structures are off limits to user programs, so there's no chance of an errant program halting execution of the entire system. This degree of survivability alone is why some engineers choose Linux over other lighter-weight solutions.
Linux uses a virtual memory-management system. The concept of virtual memory has been around since the early 1960s and is simple: the process sees its memory as a vector of bytes; and when the program reads or writes to memory, the processor, in conjunction with the operating system, translates the address into a physical address.
The bit of the processor that performs this translation is the memory management unit (MMU). When a process requests memory, the CPU looks up the address in a table populated by the kernel to translate the requested address into a physical address. If the CPU can't translate the address, it raises an interrupt and passes control to the operating system to resolve the address.
The level of indirection supplied by the memory management means that if a process requests memory outside its bounds, the operating system gets a notification that it can handle or pass along to the offending process. In an environment without proper memory management, a process can read and write any physical address; this means memory-access errors may go unnoticed until some other part of the program fails because its memory has been corrupted by another process.
Programs running in Linux do so in a virtual memory space. That is, when a program runs, it has a certain address space that is a subset of the total system's memory. That subset appears to start at 0. In reality, the operating system allocates a portion of memory and configures the processor so that the running program thinks address 0 is the start of memory, but the address is actually some arbitrary point in RAM. For embedded systems that use paging, this fiction continues: the kernel swaps some of the available RAM out to disk when not in use, a feature commonly called virtual memory. Many embedded systems don't use virtual memory because no disk exists on the system; but for those that do, this feature sets Linux apart from other embedded operating systems.
This sounds ambiguous because there are so many different forms of resources. Consider the most common resource: the system's memory. In all Linux systems, from an application perspective, memory from the heap is allocated using the malloc() function. For example, this bit of code allocates 100 bytes, storing the address to the first byte in from_the_heap:
char* from_the_heap; from_the_heap = (char*) malloc(100);
No matter what sort of underlying processor is running the code or how the processor accesses the memory, this code works (or fails in a predictable manner) on all Linux systems. If paged virtual memory is enabled (that is, some memory is stored on a physical device, like a hard drive) the operating system ensures that the requested addresses are in physical RAM when the process requests them.
Memory management requires interplay between the operating system and the processor to work properly. Linux has been designed so that you can access memory in the same way on all supported processors.
The same is true for accessing files: all you need to do is open a file descriptor and begin reading or writing. The kernel handles fetching or writing the bytes, and that operation is the same no matter what physical device is handling the bits:
FILE* file_handle;
file_handle = fopen("/proc/cpuinfo", "r");Because Linux is based on the Unix operating system philosophy that "everything is a file," the most common interface to system resource is through a file handle. The interface to that file handle is identical no matter how the underlying hardware implements this functionality. Even TCP connections can be represented with file semantics.
The uniformity of access to resources lets you simulate a target environment on your development system, a process that once required special (and sometimes costly) software. For example, if the target device uses the USB subsystem, it has the same interface on the target as it does on the development machine. If you're working on a device that shuffles data across the USB bus, that code can be developed, debugged, and tested on the development host, a process that's much easier and faster than debugging code on a remote target.
In addition to file semantics, the kernel also uses the idea of syscalls to expose functionality. Syscalls are a simple concept: when you're working on the kernel and want to expose some functionality, you create an entry in a vector that points to an entry point of for the routine. The data from the application's memory space is copied into the kernel's memory space. All system calls for all processes are funneled through the same interface.
When the kernel is finished with the syscall, it transfers the results back into the caller, returning the result into the application's memory space. Using this interface, there's no way for a program in user space to have access to data structures in the kernel. The kernel can also keep strict control over its data, eliminating any chance of data corruption caused by an errant caller.
``At last count, Linux supported more than 200 network adapters, 5 vendors of flash memory, and 10 USB mass storage devices. Because SOC vendors use Linux as their testing system for the chip, support for the chip itself implies support for the components on the device.
Wide device support is an artifact of the fact that Linux runs on millions of desktops and servers, representing a customer base that device manufacturers can't ignore. Plus, the open nature of Linux allows device vendors to create drivers without getting a development license from an operating system vendor.
What really differentiates peripheral support on Linux is that the drivers are (primarily) written in C and use the kernel's API to implement their functionality. This means that once a driver has been written for the x86 Linux kernel, it frequently requires zero or a small amount of work for a different processor.
Security means access to data and resources on the machine as well as maintaining confidentiality for data handled by the computer. The openness of Linux is the key to its security. The source code is available for anyone and everyone to review; therefore, security loopholes are there for all to see, understand, and fix.
Security has a few different dimensions, all of which may be necessary for an embedded, or any other, system. One is ensuring that users and programs have the minimal level of rights to resources in order to be able to execute; another is keeping information hidden until a user with the correct credentials requests to see or change it. The advantage of Linux is that all of these tools are freely available to you, so you can select the right ones to meet your project requirements.
A few years ago, a governmental agency with an interest in security—the National Security Agency (NSA)—and with several other private companies with similar interests took it upon themselves to examine the Linux kernel and introduce concepts such as data protection, program isolation, and security policies, following a Mandatory Access Control (MAC) model. This project is called SELinux (where SE stands for Security Enhanced), and the changes and concepts of the project were made part of the 2.6.0 release of the Linux kernel.
The MAC concepts in SELinux specify controls whereby programs must be assigned the rights to perform certain activities, like opening a socket or file, as part of their security policy. The assignment must come from an administrator; a regular user of the system can't make changes. SELinux systems operate under the principle of least privilege, meaning that a process has only the rights granted and no more. The least-privilege concept makes errant or compromised programs less dangerous in a properly configured environment, because the administrator has already granted a program the minimal set of rights in order to function. As you may guess, creating security policies can be a project itself. I'll spend some time talking about how to go about doing this on an embedded system.
Pluggable Authentication Modules (PAM) are a way to create a uniform interface to the process of authenticating users. Traditionally, user authentication on a Linux system occurs by looking up the user name in the /etc/passwd file and checking the password encrypted therein (or using the shadow password file). The PAM framework also provides session management: performing certain actions after a user is authenticated and before they log out of the system.
The open design of the PAM system is important for embedded projects that are attached to a network in a corporate environment. For example, if the device serves as a shared drive, some of your target market may use LDAP to decide who has access to the device, whereas others may put use accounts in an NT domain. PAM works equally well with both of these technologies, and you can switch between the two with simple configuration changes.
IPsec is a system for authenticating and transmitting data between two trusted hosts over an IP network. IPsec at level 3, the Network Layer of the OSI stack, isn't a single piece of software but rather a collection of tools working together to provide secure communication. By operating at this layer, IPsec can provide secure communication between hosts with no participation by the protocols running further up the stack.
A classic use for IPSec is encrypting virtual private network traffic. It can also be used in cases where you want to use a simple protocol for sending data, like HTTP or even plain text, but you want this data to be kept secure.
One of the nice things about embedded Linux is that you can perform all the configuration work to use IPsec on a pair of desktop machines and transport those configuration files to the embedded target. This is possible because when you create an embedded Linux system, you can use the same software that is running on the target on the desktop used for development, making it an ideal platform for emulating your target hardware.
In addition to the outstanding technical aspects of Linux that make it advantageous to use for an embedded device, there are also compelling commercial reasons to choose Linux over other commercial offerings. Some of these reasons, such as lower costs, will appeal to the bean-counters in your organization; but the key difference is that you'll have greater control over a critical aspect of your development project.
The universe of software around Linux is vast and varied. If you're new to Linux, you'll soon find that Linux is a more than its namesake kernel: it's a collection of software that works together. The nice thing about Linux is that what's available on your desktop can be used on an embedded system. Even better, the ability to run and test software on a regular desktop gives you the chance to see if the software offers the right feature set for the application.
The nature of open source gives you plenty of choices for nearly every piece of your configuration, and that can cause consternation if you're trying to pick the right package. Oddly, the large amount of choice is posited by commercial vendors as a reason to use their closed source or highly structured Linux distribution. Don't fall for this line of reasoning! You're reading this book so you can take advantage of what open source has to offer.
Open source software is always available as source code. Most of the time, the authors have written both the package itself and the build instructions so that the project isn't architecture dependent and can be built for the target system. Software that is part of the root file system is nearly always completely portable, because it's written in a high-level language like C. Because of the nice job done in the Linux kernel to isolate architecture-dependent code, even a vast amount of kernel code is portable.
Note
Cross compiling and a root file system are two key concepts for embedded developers. During cross compilation, the compiler produces code that doesn't run on the processor or operating system of the machine that performed the compilation. Compiling Java into bytecode that runs on a Java Virtual Machine (JVM) is an example. If you've written a Netware Loadable Module, you've also done cross-compilation. The root file system is the population of files and folders under the / folder of a computer. Developers creating enterprise systems rarely give this part of the system a second thought; but embedded developers put care and effort not only into selecting the right sort of root file system, but also into populating it efficiently in order to conserve space and reduce hardware costs and power requirements. I'll cover both of these topics in detail.
The key to using what's available in open source is two-fold: having a cross-compiler and having the build scripts work when you're cross-compiling. The vast majority of packages use the automake/autoconf project for creating build scripts. Automake and autoconf by default produce scripts suitable for cross-compilation. Later in this book, I explain how to use them properly. I talk about the cross-compiler that later in this chapter and tell you how to build your own from source.
Although constraints like memory and storage space may make some choices impractical, if you really need certain functionality, the source is there for you to reduce the size of the package. Throughout the book, you'll find references to software projects typically used by embedded engineers.
Royalties, in the software sense, are the per-unit software costs paid for every unit shipped, which compensate an owner of intellectual property for a license granted for limited use of that property. Royalties increase the Bill of Materials (BOM) cost of every unit shipped that contains the licensed intellectual property. A licensee must make regular reports and prompt payment and must avail itself for audit so that the holder of the licensed property can ensure the monies paid accurately reflect what was shipped.
In this model, forms must be filled out, checked, and signed. Paper must be shuffled, and competitive wages and benefits need to be paid to those doing the shuffling. With a contract to sign, expect a bill from your attorney as well. The entire cost of the royalty is greater than what appears on the BOM.
Royalties impose another cost: lack of flexibility. Want to experiment with a newer processor? Want to create a new revision of the product or add features? All these activities likely require permission from the vendor and, when you ship a new product, a new royalty payment to not only make but properly administer.
When presenting an embedded operating system that has royalties, the salescritter[2] will explain that the payments represent a small concession compared to what the software they're selling brings to the table. What they leave out is the loss of liberty with respect to how your company structures its development operations and the additional administrative and legal costs that never make it into the calculations showing your "savings." Caveat emptor.
This is an often-missed reason to use Linux: you have the sources to the project and have complete control over every bit of software included in the device. No software is perfect, but with Linux you aren't at the mercy of a company that may not be interested in helping you when a defect becomes apparent. When you have trouble understanding how the software works, the source code can serve as the definitive reference.
Unfortunately, this amount of control is frequently used to scare people away from Linux. "You may have the source code, but you'll never figure anything out ... it's so complex," the fear mongers say. The Linux code base is well written and documented. If you're capable of writing a commercial embedded Linux application, you no doubt have the ability to understand the Linux project—or any other open source project, for that matter.
This section contains a quick and dirty explanation of the embedded Linux development process. Embedded Linux is a topic with many interdependencies; this section lays out the big points and purposely lacks detail so you can see the big picture without getting distracted by the fine details. The heft of this book should indicate that more details are forthcoming.
Nearly every project involves selecting the processor to be used. A processor is just a chip and not much more until it's soldered on a board with some peripherals and connectors. Processor vendors frequently create development boards containing their chip and a collection of peripherals and connectors. Some companies have optimized this process to the point that a board with connectors and peripherals is connected to a small daughter board containing the processor itself, allowing the base board to be shared across several different processor daughter boards.
Development boards are large, bulky, and designed to be easily handled. Every connector is supported by the processor because the vendor wants to create only one board to ship, inventory, and support. The development kit for a cell phone occupies as much space as a large laptop computer.
In a majority of products, the development board isn't used in the final product. An electrical engineer lays out a new board that fits in the product's case and contains only the leads for the peripherals used in the final application, and he probably sneaks in a place to connect a serial or JTAG port for debugging.
Linux is nearly always included with a development board and has support for the peripherals supported by the chip or the development board. Chances are, the board was tested with Linux to ensure that the processor and connectors work as expected. Early in the history of embedded Linux, there were porting efforts to get Linux running on a board; today, this would be an anomaly.
If the board is an Intel IA-32 (frequently called x86) architecture, you can boot it (under most circumstances) with any desktop distribution of Linux. In order to differentiate their IA-32 boards, vendors frequently include a Linux distribution suitable for an embedded project.
Just as the development board has every known connector, the Linux included with the board is suited for development and not for final deployment. Part of using Linux is customizing the kernel and the distribution so they're correct for the application.
Because most board vendors supply a Linux distribution with a board, getting Linux booted is about configuring the software services Linux needs to boot and ensuring the cabling is proper and attached. At this point, you probably need a null modem serial cable, a null modem Ethernet cable (or a few cables and an Ethernet concentrator or switch), and maybe a USB cable. Unlike a desktop system with a monitor, the user interface for an embedded target may be just a few lights or a one-line LCD display. In order for these boards to be useful in development, you connect to the board and start a session in a terminal emulator to get access to a command prompt similar to a console window on a desktop Linux system.
Some (enlightened) vendors put Linux on a Flash partition so the board runs Linux at power up. In other cases, the board requires you to attach it to a Linux host that has a terminal emulator, file-transfer software, and a way to make a portion of your Linux system's hard drive remotely accessible.
In the rare cases where the board doesn't include Linux (or the board in question hails from before you welcomed the embedded Linux overlords), the process requires you to locate a kernel and create a minimal root file system.
Much of the activity around embedded development occurs on a desktop. Although embedded processors have become vastly more powerful, they still pale in comparison to the dual core multi-gigabyte machine found on your desk. You run the editor, tools, and compiler on a desktop system and produce binaries for execution on the target. When the binary is ready, you place it on the target board and run it. This activity is called cross-compilation because the output produced by the compiler isn't suitable for execution on your machine.
You use the same set of software tools and configuration to boot the board and to put the newly compiled programs on the board. When the development environment is complete, work on the application proper can begin.
The Linux distribution used to boot the board isn't the one shipped in the final product. The requirements for the device and application largely dictate what happens in this area. Your application may need a web server or drivers for a USB device. If the project doesn't have a serial port, network connection, or screen, those drivers are removed. On the other hand, if marketing says a touch-screen UI is a must-have, then a suitable UI library must be located. In order for the distribution to fit in the amount of memory specified, other changes are also necessary.
Even though this is the last step, most engineers dig in here first after getting Linux to boot. When you're working with limited resources, this can seem like a reasonable approach; but it suffers from the fact that you don't have complete information about requirements and the person doing the experimentation isn't aware of what can be done to meet the requirements.
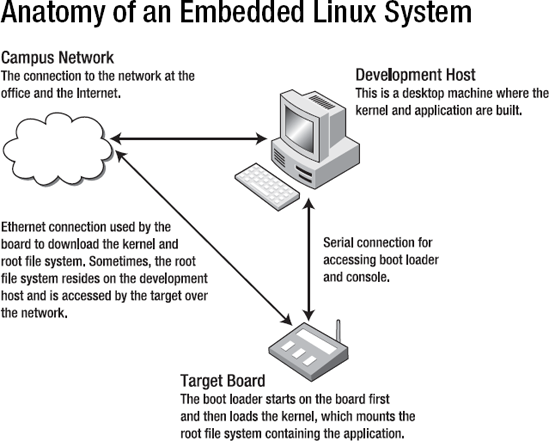
At runtime, an embedded Linux system contains the following software components:
Boot loader: What gets the operating system loaded and running on the board.
Kernel: The software that manages the hardware and the processes.
Root file system: Everything under the
/directory, containing the programs run by the kernel. Every Linux system has a root file system. Embedded systems have a great amount of flexibility in this respect: the root file system can reside in flash, can be bundled with the kernel, or can reside on another computer on the network.Application: The program that runs on the board. The application can be a single file or a collection of hundreds of executables.
All these components are interrelated and thus depend on each other to create a running system. Working on an embedded Linux system requires interaction with all of these, even if your focus is only on the application.
If you're new to Linux but have used other commercial embedded solutions, the notion of a distinct kernel and root file system can be disorienting. With a traditional embedded solution, the application code is linked into a binary image with the rest of the embedded OS. After initialization, the operating system calls a function that is the entry point into your code and starts running.
Next, I define these components so you understand what they do and how they work together.
Boot loaders can be laden with features, but their primary responsibility is to get the processor initialized and ready to run the operating system. Later in the book, I go through the boot-up process from beginning to end; but for practical purposes, this is the software that's first run on the system.
In most modern embedded Linux systems, the kernel is stored in a partition in flash memory. The boot loader copies that flash partition into a certain location in RAM, sets the instruction pointer to that memory location, and tells the processor to start executing at the instruction pointer's current location. After that, the program that's running unceremoniously writes over the boot loader. The important thing to note is that the boot loader is agnostic with respect to what is being loaded and run. It can be a Linux kernel or another operating system or a program written to run without an operating system. The boot loader doesn't care; it performs the same basic actions in all these use scenarios.
As boot loaders have matured, they've become more like operating systems with network, video, and increasing support for flash storage devices. Later in this book, I look at the popular boot loaders you may encounter when working with Linux.
One more important note: boot loaders are now ubiquitous. Rarely as an embedded Linux developer do you need to port a boot loader for your board. You may want to recompile the boot loader (I'll cover that, too) to remove functionality to conserve space and increase boot time, but the low-level engineering is done by the board vendor. Users of Intel-based systems that use the Phoenix BIOS boot loader have no opportunity to change this code, because it's baked into the board design.
As discussed earlier, the Linux kernel was created by a Finnish computer science student as a hobby project and was first released in August 1991. The operating system originally ran only on x86 hosts and was modeled on a teaching aid operating system, MINIX. The Linux kernel was first ported to the Motorola 68KB processor, a painful process resulting in Linus Torvalds designing the kernel for portability. By doing the right thing, he laid the groundwork for Linux being ported to nearly every major processor over the following decade.
Due to the maturity and wide device support of Linux, engineers spend less time doing kernel development work such as creating device drivers (for example, to drive an LCD) and more time and effort creating applications the user values (like displaying the current weather conditions). Some effort may go into customizing the kernel by removing unneeded components or making other tweaks to increase booting time, but generally you don't need to do the low-level programming necessary to get the Linux kernel running in the first place.
Although it's an essential and vital component, the kernel has a symbiotic[3] relationship with the software it runs. The point isn't to give the Linux kernel short shrift or minimize its importance! The point is to make clear how the kernel fits into the overall functioning of a Linux system. Without something to run, the kernel stops executing and panics. That's where the root file system and your application come into play.
A file system is a way of representing a hierarchical collection of directories, where each directory can contain either more directories or files. For computer science types, this hierarchy is a tree structure in which the files are always leaf nodes and directories are internal nodes when they contain something and leaf nodes otherwise. The point of making this trip down data-structure memory lane is that the top node in a tree structure is the root node and that, in Linux, the file system mounted at the top node is aptly called the root file system.
On your desktop Linux system, you can see what's mounted as the root file system by doing the following:
gene@imac-2:˜$ mount | head −1 /dev/hda3 on / type ext3 (rw,errors=remount-ro)
Just typing mount shows all the file systems mounted. Most Linux systems have several file systems mounted, but all the file systems are mounted relative to the root file system.
When the Linux kernel boots, it must be able to mount a root file system. During the boot process, the root file system can be replaced with another, but only one root file system can be mounted at a time. Failure to mount a root file system means that the system can't find something to run, because a file system is a container for your program and the kernel panics and halts.
Depending on the board's hardware and application requirements, you're free to select any number of root file system types. A completed device contains a single file system mounted at root but likely uses several different file systems mounted at other directories within the root file system. Only one file system can be mounted at the root (/ directory), but Linux allows for an arbitrary number of file systems to be mounted at other locations in the root file system. For example, a system that uses flash memory for storage mounts a RAM-based file system for temporary storage because it's faster, and flash memory has a much smaller duty cycle than RAM. In the chapters that follow, this book covers how to select a root file system type and how to build one from the ground up.
After the boot loader loads the kernel and the kernel mounts the root file system, it's time for something to start running that you and your boss view as useful. When Linux starts, it looks for a program to execute by default, or you can supply it with the name of something to run. This program runs as the first process and must continue to run. When this process stops, the kernel, and thus the entire system, stops running.
On your desktop Linux system, this program is likely init. You can find out by doing the following:
gene@imac-2:˜$ ps aux | head −2 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.2 1692 516 ? S Dec07 0:01 init [2]
Later in the book, I cover what init does and how it's used in an embedded system, if at all.
It's important to note that your application can be anything that can be executed by Linux: a shell script, a C program, a Perl script, or even an assembly written in C# (the Mono project is a robust, open source C# platform)—you name it. As long as it can be executed by Linux, it's fair game to be the application. This is obvious to those who have already worked with Linux; and it's liberating almost to the point of disbelief for embedded engineers new to Linux. In addition, you can implement a solution using a few different languages if necessary.
All the shared libraries and other supporting files for the application must be present in the root file system deployed on the board. The mechanics for gathering what's necessary for your application are covered in a later chapter.
So far, I've discussed the software components that are on the board. A cross-compiler is part of the development environment and, in the most basic terms, produces code that runs on a different processor or operating system than where the compiler ran. For example, a compiler that runs on a Linux x86 host that produces code to execute on an ARM9 target is a cross-compiler. Another example is a compiler running on Windows that produces code that runs on a x86 Linux host. In both cases, the compiler doesn't produce binaries that can be executed on the machine where the compiler ran.
In Linux, the cross-compiler is frequently referred to as a tool chain because it's a confederation of tools that work together to produce an executable: the compiler, assembler, and linker. The debugger is a separate software component. The book later describes how to obtain or create a tool chain for your target processor based on the GNU Compiler Collection (GCC) project.
Linux is GNU licensed software, and subsequently users who receive a Linux kernel must have the ability to get the source code for the binaries they receive. Having the source code is just one part of what's necessary to rebuild the software for the board. Without the cross-compiler, you can't transform that source into something that can run on the remote target.
The de facto compiler for Linux is GCC, but this need not always be the case. Several chip vendors market compilers that produce highly optimized code for their processors. The Linux operating system, although written in C and assembler, requires GCC for compilation. However, you can compile programs to be run on the system with a different compiler.
For a certain segment of embedded boards, a cross-compiler isn't necessary. Many PowerPC boards are as powerful as your desktop system; and some embedded systems are, for all intents and purposes, PCs in a different case. In these cases, development can happen right on the board. The compiler runs on the board, which produces code that runs in the same environment; the development cycle is much like that of a regular software project.
Embedded development can be done with a simple collection of tools. This section covers the most frequently used tools so you can understand what they do and how they fit into an embedded system. This book covers each of these in great detail, to provide terra firma on which to stand if you're new to the world of embedded development. One of the most confusing aspects of embedded Linux is that there are many interrelated tools, it's difficult to talk about any one in isolation.
This is just a subset of the tools used during any development project, but it represents the bare minimum subset. Most projects of any consequence use a variety of tools in addition to the ones mentioned.
The GCC compiler, like the kernel, is designed for portability. Like all open source programs, GCC is available in source form, and you can compile the code to create your own compiler. Part of the compilation process of GCC involves configuring the project; during that step, you can configure GCC to produce code for a different target processor and thus become a cross-compiler.
However, the compiler is only one part of the tool chain necessary to produce running code. You must also get a linker, a C standard library, and a debugger. These are separate, albeit related, projects in Linux. This separation is vexing for engineers used to tools from a certain company in Redmond, Washington, where the tools are monolithic in nature. But not to worry; when you're working on an embedded project, this separation is an advantage, because the additional choice lets you select the right tool for your application.
The GCC compiler installed on your host machine is preconfigured to use the GNU C Standard Library, frequently called glibc. Most embedded projects use an alternate, smaller library called uClibc for embedded development; it's discussed later in this chapter.
The GNU Debugger (GDB) project deserves a special mention. It's the most commonly used debugger on Linux systems. Although it's frequently included in the tool chain, GDB is a separate, independent project.
For embedded development, GDB is compiled so that it can debug code running on a different processor than the debugger, much like GCC can cross-compile code. This sort of debugging adds another complication: the machine running the debugger is rarely the machine running the code to be debugged. Debugging code in this fashion is called remote debugging and is accomplished by running the program to be debugged with a stub program that communicates with another host where the debugger is running.
The stub program in this case is gdbserver, and it can communicate by serial or TCP connection with a host running GDB. Using gdbserver also has practical considerations because at only 100KB, give or take, it's small enough in terms of size and resources required when running on even the most resource constrained targets.
BusyBox is a multicall (more later on what this means) binary that provides many of the programs normally found on a Linux host. The implementations of the programs are designed so that they're small both in size but also with respect to how much memory they consume while running. In order to be as small as possible, the programs supply a subset of the functionality offered by the programs running on desktop system. BusyBox is highly configurable, with lots of knobs to turn to reduce the amount of space it requires; for example, you can leave out all the command-line help to reduce the size of the program.
As for the multicall binary concept, BusyBox is compiled as a single program. The root file system is populated with symlinks to the BusyBox executable; the name of the symlink controls what bit of functionality BusyBox runs. For example, you can do the following on an embedded system:
$ls -l /bin/ls /bin/ls -> /bin/busybox
When you executes /bin/ls, the value of argv[0] is "/bin/ls". BusyBox runs this argument through a switch statement, which then calls the function ls_main(), passing in all the parameters on the command line. BusyBox calls the programs it provides applets.
Note
If you're new to Linux (or Unix-like operating systems), a symlink (symbolic link) is a new concept. A symlink is a pointer to another file in the file system, called the target. The symlink functions just like its target file; opening and reading from a symlink produces the same results as opening and reading from the target file. Deleting a symlink, however, results in the link being deleted, not the target file.
BusyBox is a key component of most embedded systems. It's frequently used in conjunction with the uClibc project to create very small systems. I dedicate a chapter to the nuances of BusyBox and uClibc so you can understand when and how to take advantage of these great projects.
As you'll find out reading this book, nearly everything in an embedded Linux system is fair game for some sort of substitution—even things you take for granted. One such item that most engineers use frequently but never give much consideration to is the implementation of the standard C library. The C language contains about 30 keywords (depending on the implementation of C), and the balance of the language's functionality is supplied by the standard library.[4] This bit of design genius means that C can be easily implemented on a new platform by creating a minimal compiler and using that to compile the standard library to produce something sufficient for application development.
The separation between the core language and the library also means there can be several implementations. That fact inhibited the adoption of C for a while, because each compiler maker shipped a C standard library that differed from their competitors', meaning a complex project needed tweaking (or major rework) in order to be used with a different compiler.
In the case of Linux, several small library implementations exist, with uClibc being the most common. uClibc is smaller because it was written with size in mind and doesn't have the platform support of glibc; it's also missing some other features. Most of what's been removed has no effect on an embedded system. Later in the book, I cover the finer points of uClibc as well as some of the other small libc implementations.
Open source software is designed to be distributed in source code form so that it can be compiled for the target platform. When target platforms were diverse, this made perfect sense, because there was no way for a binary to work on a wide range of targets. For example, one key part of the target system was the C library. Most open source software is written in C; when compiled, the binary attempts to use the C library on the target system. If the C library used for compilation wasn't compatible with the library on the target system, the software wouldn't run.
To make sure the software could be compiled on a wide range of systems, open source software developers found themselves doing the same sort of work, such as detecting the existence of a function or the length of a buffer in order to compile properly. For a project to be widely adopted, not only did it need to work, but users also needed to be able to compile it easily.
The Automake and Autoconf projects solve the problem of discovering the state of the target environment and creating make files that can build the project. Projects using Automake and Autoconf can be compiled on a wide range of targets with much less effort on the part of the software developer, meaning more time can be dedicated to improving the state of the software itself rather than working through build-related problems.
As Linux became more mainstream, distributions were developed. A distribution is a kernel and a group of programs for a root file system, and one of the things on the root file system is the C library. The increasing use of distributions means a user can compile open source software with the expectation that it will run on a computer with a certain target distribution.
Distributions added another layer with the concept of packages. A package is a layer of indirection on top of an open source project; it has the information about how to compile the software it contains, thereby producing a binary package. In addition to the binaries, the package contains dependency information such as the version of the C library that's required and, sometimes, the ability to run arbitrary scripts to properly install the package. Distributions typically built a group of packages as a set; you install a subset of those packages on your system. If you install additional packages, then as long as they come from the same set used to create the distribution, the dependencies are satisfied or can be satisfied by using other packages in the set.
Several packaging systems are available. RPM (neé Red Hat Package Manager, now RPM Package Manager) and deb (the packaging system used by the Debian project first and then Ubuntu) are two of the more popular packages for desktop systems. Some embedded distributions use these packing systems to create a distribution for embedded targets. In some cases, it makes sense to use a packaging system; in this book, I cover what's available for embedded developers and when using a packing system makes sense.
You hear a lot about patches when working with Linux. You may even make one or two yourself. A patch is nothing other than a file containing a unified diff, which is enough information that it can be used to non-interactively edit a file. This information is frequently referred to as a change set. The file to which the changes are applied is called the target file. Change sets can specify that lines can be changed, removed from, or added to the target. Although patches are typically created for text files, a patch can be created for a binary program as well.
A patch is just a data file. To update the target files, another program must be used, and that program is patch. Created by the Perl guy Larry Wall, patch does the work of reading the patch file, locating the file to be edited, and applying the changes. Patch is clever in that it can apply changes even if the file to be patched is a little different than the one used to create the patch.
You can create patches using the diff program, like so:
diff -Naur old-something new-something > patch-file
However, many source code control systems generate a patch based on the current contents of your directory versus what's stored in the source code control repository. No matter how you create your patch, applying it works the same:
patch < patch-file
If the patch program can't make the changes requested, it produces error messages and creates reject files so you can see where things went wrong.
Make is a core underpinning of open source software. It works by scanning a list of rules and building a dependency graph. Each rule contains a target, which is usually a file and a list of dependencies. A dependency can be either another target or the name of a file. Make then scans the file system to determine what files aren't present and figures out what targets to run in what order to create the missing files.
Make has been around since 1977 and has been rewritten several times. The version used on Linux systems is GNU Make.
Make uses a combination of a terse syntax in conjunction with many preset defaults, such that the way a make file works is nearly magic. Consider this:
mybinary: file1.c file2.c
This is sufficient to give make the proper instructions to compile the file mybinary.c into the executable mybinary. The defaults tell make how to compile and link a C file from the files in the make rule.
Using make for embedded development isn't much different from using make for desktop development. One big difference is that when you're doing embedded development, you need to tell make to invoke a cross-compiler or compile under emulation. In the previous example, it's as simple as this:
LD=arm-linux-ld CC=arm-linux-gcc mybinary: file1.c file2.c
Although this is the simplest approach, it can probably be done more elegantly so that changing the compiler requires fewer changes to the make file. I dedicate time to creating make files so you can use a different compiler with minimal impact.
Using make along with your favorite editor is all you need to do embedded development. IDE tools like KDevelop and Eclipse scan the project to create a make file that is then executed to perform a build. You may decide to use an IDE, but having a firm understanding of what's happening under the covers is important when you're working with other open source projects or creating automated builds.
All software developers depend on little helpers, whether visible or invisible. Open Source developers tend to call upon a large number of resources to get help, very few of which require a contract or a well-stocked bank account. I introduce a selection of them here to make your life a little easier, but please be aware of the fact that new resources are being created all the time. This is just meant to get you started.
As far as I know, Google doesn't have a university—yet. But searching via Google seems to be the best first approach. When you search, make sure you take advantage both the web search (www.google.com) and the newsgroup search (groups.google.com). Google has an archive of newsgroup messages since before the advent of Linux. Many talented engineers share what they know through personal pages, project pages, and blog postings; and Google, as you know, is the perfect way to find this sort of information on the Web.
Some crafty web sites grab the contents of mailing lists and/or newsgroups and wrap them in a web page as a way of attracting visitors to their ad-laden slices of hell; they don't have any better content than you find on a newsgroup, so feel free to look elsewhere.
Mailing lists constitute the primary means of communication and serve as the mechanism of record for open source projects. A mailing list is nothing more than a system whereby communications are posted via e-mail and the postings are then forwarded to the list's subscribers. The software managing the mailing list keeps an archive of the messages, usually grouped by month and then organized by topic. Reading the archives is a great way to understand how people use the software you're interested in and what sorts of problems are common.
You should also feel free to subscribe to the mailing lists of projects in which you have greater interest. To do this, you need to supply your e-mail address. Don't worry about being spammed—these sites are run by people like you and aren't interested in enhancing anything other than your technical knowledge. As a subscriber to the list, you can choose to receive messages as they're posted or once a day, in digest mode. Digest mode is fine for occasional readers; but if you find yourself more involved in the project, once-a-day updates introduce too much latency.
For the newbie, the mailing list archives offer a wealth of knowledge. The open source community is large enough that somebody has worked through a problem like yours before. Google searches the mailing lists, but reading them directly gives you more context and understanding than reading a few messages in isolation. If you ask a question on the mailing list, you may get a reply that this has already been resolved or answered and a pointer to a URL of a message in the archives.
Throughout the book are recommendations for mailing lists devoted to various topics.
When groups of people regularly get together, rules form to make interaction pleasant for all those involved; this is the notion of etiquette. Etiquette involves thinking about others before yourself and making life easier for them. Now, stop slouching and start using the proper fork for your salad.
If you're new to using mailing lists or newsgroups, here are some basic rules:
No spam: If it's not related to the mailing list, don't post it. If you're asking about C++ syntax corner cases on a C mailing list, somebody will likely tell you nicely that your question is off topic. Posting about your latest medical procedure or trying to sell something is verboten.
Keep it short and to the point, and use simple English. This makes your message easy to download and easy to read for non–English speakers who may be participating. Don't include large attachments with your message (where large is more than a few kilobytes).
Post in plain text. Many people reading the mailing list don't have a mail client that renders the message with fancy formatting.
Don't post in ALL CAPS. It's the computer equivalent of shouting.
When replying, don't include all the text from the prior poster. Clip out what you need to reference, and include that in the message.
Don't post "questions" that are thinly veiled invitations for somebody else to do your work. Likewise, don't set deadlines or make demands of your fellow readers.
Open source somehow has attracted some of the smartest people and also some of the nicest. Fear not when posting a message; be reasonable and respectful, and your treatment will be the same.
Because having Linux running on a board is an important part of a vendor's release strategy, many vendors also offer support in varying degrees for the Linux distributed with the board. For some vendors, the only way to get Linux is to download it from their site.
The advantage of using one of these sites is that you have access to the Linux kernel and root file system that have been tested with the board and at the same time have access to a group of engineers who are working with the same hardware and software platform, because most vendor sites include a mailing list or web-based forum for support. Depending on the enlightenment of the hardware vendor and the dedication of its Linux-using customer base, the site may also contain technical articles or technical support offered directly by the company.
The trend among hardware vendors is to ensure that the changes to the Linux kernel that are required for it to run on a board make it into the mainline Linux kernel project. Due to the coordination efforts involved in the main kernel release process, processor and board vendors are always a little unsynchronized with the main kernel release, but not to the extent they were a few years back.
Creating embedded Linux distributions is a much more pedestrian activity than it was a few years back, when creating a Linux distribution from scratch was a mysterious process. Several projects grew out of the need to create an embedded distribution; they built an infrastructure to help users configure and build an embedded Linux distribution. Frequently, the distributions created by these sites target a family of processors for a particular type of distribution, like a mobile phone.
These sites have great starting points for application development, if you're working on a project similar to that of the distribution. If you're doing something different, you need to learn the underlying build system for the project in order to build a distribution for your project. The build systems are great pieces of software that commendably do a difficult job and can be helpful for your project. You must evaluate the project and see if it can be helpful for your efforts.
Following are several embedded Linux distributions. This is by no means an exhaustive list:
Openmoko and OpenEmbedded (
http://openmoko.organdhttp://openembedded.org): The Openmoko distribution runs on Neo FreeRunner phones. It's targeted for an ARM9 processor and includes software for a touch device, a small Linux desktop environment, and, of course, the software necessary to run a cell phone. Openmoko grew-up around the BitBake build system, which has a bit of a learning curve. OpenEmbedded is the generic embedded distribution used in the creation of Openmoko.OpenWRT (
http://openwrt.org): This distribution appeared to support Linksys routers that were running Linux and had branched out to support additional boards. It's geared toward networking devices. The build for this project is built up make and downloads and installs all the software and patches necessary to build a distribution. If you're comfortable with make, using this project should be fairly easy.Android (
http://source.android.com): This is the open source project for the platform that runs the Google phone, which runs an ARM9 processor. It contains components for a UI and, most interesting, a smallish Java runtime environment. The documentation for the project explains how to use the IDE Eclipse environment to create and debug applications.Linux from Scratch (
http://linuxfromscratch.org): This distribution is primarily targeted at Intel IA-32 processors. It's very configurable and gives you considerable control over the Linux that's being built. A variant of this project, CLFS, is designed to cross-build the distribution. The build system uses an XML file containing the build instructions.
The following is a list of sites focused on hardware vendors. Some of these sites are run by enthusiasts, and others are sponsored by the companies that make the hardware:
Linux4SAM (
http://linux4sam.org): This site contains information supporting the Atmel SAM9xxx processors. It provides a Linux distribution for each of Atmel's ARM boards and also has ancillary tools such as the flash programmer (SAM-BA) used to program the boot loader on the board.Penguin PPC (
http://penguinppc.org): A wealth of information resides on this site regarding Linux running on PowerPC boards. The site has a link to a group of pages that address using PowerPC chips in embedded systems.ARM, Ltd (
www.arm.com/products/os/linux_download.html): This is part of the official ARM, Ltd site and contains Linux distributions for most of the development boards offered by the company. The distributions contained on this page are good enough to quickly boot an ARM board. No mailing list or community support is offered on the site. If you have an ARM board and want to get Linux running quickly, this is the page to visit.Linux/MIPS (
www.linux-mips.org): This site contains distributions, hardware information, porting guides, and patches for getting Linux running on a variety of MIPS-based systems. A group of pages explain the level of Linux support for all the MIPS architectures and even spell out things like how the 4Kc design is different than 4Kp. This site also has information about MIPs hardware manufacturers and includes a well-frequented mailing list.
Finally, these are general-purpose embedded Linux sites. They don't have much depth about any one processor or type of project. What they lack in depth, however, is made up for in breadth:
Linux Devices (
www.linuxdevices.com): This news site has more "Look! Linux runs on this hardware" articles than it has about Linux itself. Recently, the site has been focusing more on Linux software, with articles about deploying Linux on a variety of boards. Unlike many news sites, Linux Devices doesn't have community features; it's one of the few read-only news sites.Free Electrons (
www.free-electrons.com): This started as a site with great training content and has built on that with a blog, technical videos, and other training information. It's a great resource for those new to embedded Linux. Many courses of the practical labs contain high-quality, step-by-step exercises to reinforce the concepts laid out in the training materials.LWN (
http://lwn.net/): This is a general Linux news site that also covers embedded Linux. The site operates by subscription, with newer articles for subscribers only. LWN does a great job of summarizing the features of each new Linux distribution, explaining critical new features and bug fixes in detail. Although the site covers Linux in general, it provides a decent amount of news coverage about embedded topics and is worth a regular visit.IBM developerWorks (
www.ibm.com/developerworks/linux/library/lembl.html): You may not expect IBM to have so much high-quality information about embedded Linux. The mix of content is incredible, from articles demystifying open source licensing to in-depth articles explaining how Linux's virtual memory subsystem works. The site contains very few how-to step-by-step articles, instead favoring articles that explain Linux's technology in depth.
Internet Relay Chat (IRC) is a communication protocol that lets you communicate quickly by sending short messages either through a public channel or privately. IRC messages hosted by a server and channels can be thought of as existing on that server. Some projects or companies maintain their own IRC services. Client software required to use IRC is part of a standard Linux distribution. Windows users can download one of several IRC clients for that platform.
This communication medium has some rules to make it useful and easy for those who participate. Like using a mailing list, you should be courteous and respectful to the people participating:
Keep it short: The purpose of IRC is to exchange short messages, maybe a line or so. The act of being verbose is called flooding and is frowned on.
Don't send status messages: Some IRC clients let you change your user name or send out messages after a span of inactivity. In a channel frequented by many people, this is nothing but noise and makes it hard for others participating to see the real discussion of the channel.
Don't use Caps Lock: As in e-mail, it's the same as shouting.
Don't ask somebody to solve your problem: Also as on a mailing list, you can ask questions to get help, but the people in the channel have no obligation to help you or solve your problem. Just like any other online community, lots of people are willing to help you if you're willing to help yourself.
Chapter 2 digs in and explains how to configure a host for embedded Linux development. The nature of embedded development requires some specialized software tools to communicate with the target board. The book also covers how to configure a Windows workstation so that it can be used for development. Of course, the tools necessary for development are free and open source (even on Windows); it's just a matter of getting them.
[1] I can't comment about the usefulness or features of ThreadX, but I can attest that the stuffed monkeys given away at every trade show for the last ten years are adorable. This company also sponsored a booth one year that had actors in Star Trek get-ups explaining what ThreadX did; I wasn't paying attention, but I got another stuffed monkey after the presentation.
[2] You're paying for them, too.
[3] The biologically minded may think about the type of symbiotic relationship. I classify it as obligate mutualism, because neither can survive without the other. If you can discuss this topic with your significant other, they're a keeper.
[4] When it was popular to quiz engineers during an interview, a common tactic was to let the interviewee identify the keywords in a sampling of C code. Many candidates thought printf and putc were keywords. I'm glad those days are over, because I think this sort of quiz didn't do much to sort out good programmers from poor ones.