
Chapter 1. Introduction
Programming Kubernetes can mean different things to different people. In this chapter, we’ll first establish the scope and focus of this book. Also, we will share the set of assumptions about the environment we’re operating in and what you’ll need to bring to the table, ideally, to benefit most from this book. We will define what exactly we mean by programming Kubernetes, what Kubernetes-native apps are, and, by having a look at a concrete example, what their characteristics are. We will discuss the basics of controllers and operators, and how the event-driven Kubernetes control plane functions in principle. Ready? Let’s get to it.
What Does Programming Kubernetes Mean?
We assume you have access to a running Kubernetes cluster such as Amazon EKS, Microsoft AKS, Google GKE, or one of the OpenShift offerings.
Tip
You will spend a fair amount of time developing locally on your laptop or desktop environment; that is, the Kubernetes cluster against which you’re developing is local, rather than in the cloud or in your datacenter. When developing locally, you have a number of options available. Depending on your operating system and other preferences you might choose one (or maybe even more) of the following solutions for running Kubernetes locally: kind, k3d, or Docker Desktop.1
We also assume that you are a Go programmer—that is, you have experience or at least basic familiarity with the Go programming language. Now is a good time, if any of those assumptions do not apply to you, to train up: for Go, we recommend The Go Programming Language by Alan A. A. Donovan and Brian W. Kernighan (Addison-Wesley) and Concurrency in Go by Katherine Cox-Buday (O’Reilly). For Kubernetes, check out one or more of the following books:
-
Kubernetes in Action by Marko Lukša (Manning)
-
Kubernetes: Up and Running, 2nd Edition by Kelsey Hightower et al. (O’Reilly)
-
Cloud Native DevOps with Kubernetes by John Arundel and Justin Domingus (O’Reilly)
-
Managing Kubernetes by Brendan Burns and Craig Tracey (O’Reilly)
-
Kubernetes Cookbook by Sébastien Goasguen and Michael Hausenblas (O’Reilly)
Note
Why do we focus on programming Kubernetes in Go? Well, an analogy might be useful here: Unix was written in the C programming language, and if you wanted to write applications or tooling for Unix you would default to C. Also, in order to extend and customize Unix—even if you were to use a language other than C—you would need to at least be able to read C.
Now, Kubernetes and many related cloud-native technologies, from container runtimes to monitoring such as Prometheus, are written in Go. We believe that the majority of native applications will be Go-based and hence we focus on it in this book. Should you prefer other languages, keep an eye on the kubernetes-client GitHub organization. It may, going forward, contain a client in your favorite programming language.
By “programming Kubernetes” in the context of this book, we mean the following: you are about to develop a Kubernetes-native application that directly interacts with the API server, querying the state of resources and/or updating their state. We do not mean running off-the-shelf apps, such as WordPress or Rocket Chat or your favorite enterprise CRM system, oftentimes called commercially available off-the-shelf (COTS) apps. Besides, in Chapter 7, we do not really focus too much on operational issues, but mainly look at the development and testing phase. So, in a nutshell, this book is about developing genuinely cloud-native applications. Figure 1-1 might help you soak that in better.

Figure 1-1. Different types of apps running on Kubernetes
As you can see, there are different styles at your disposal:
-
Take a COTS such as Rocket Chat and run it on Kubernetes. The app itself is not aware it runs on Kubernetes and usually doesn’t have to be. Kubernetes controls the app’s lifecycle—find node to run, pull image, launch container(s), carry out health checks, mount volumes, and so on—and that is that.
-
Take a bespoke app, something you wrote from scratch, with or without having had Kubernetes as the runtime environment in mind, and run it on Kubernetes. The same modus operandi as in the case of a COTS applies.
-
The case we focus on in this book is a cloud-native or Kubernetes-native application that is fully aware it is running on Kubernetes and leverages Kubernetes APIs and resources to some extent.
The price you pay developing against the Kubernetes API pays off: on the one hand you gain portability, as your app will now run in any environment (from an on-premises deployment to any public cloud provider), and on the other hand you benefit from the clean, declarative mechanism Kubernetes provides.
Let’s move on to a concrete example now.
A Motivational Example
To demonstrate the power of a Kubernetes-native app, let’s assume you want to implement at—that is, schedule the execution of a command at a given time.
We call this cnat or cloud-native at, and it works as follows. Let’s say you want to execute the command echo "Kubernetes native rocks!" at 2 a.m. on July 3, 2019. Here’s what you would do with cnat:
$cat cnat-rocks-example.yaml apiVersion: cnat.programming-kubernetes.info/v1alpha1 kind: At metadata: name: cnrex spec: schedule:"2019-07-03T02:00:00Z"containers: - name: shell image: centos:7command: -"bin/bash"-"-c"-echo"Kubernetes native rocks!"$kubectl apply -f cnat-rocks-example.yaml cnat.programming-kubernetes.info/cnrex created
Behind the scenes, the following components are involved:
-
A custom resource called
cnat.programming-kubernetes.info/cnrex, representing the schedule. -
A controller to execute the scheduled command at the correct time.
In addition, a kubectl plug-in for the CLI UX would be useful, allowing simple handling via commands like kubectl at "02:00 Jul 3" echo "Kubernetes native rocks!" We won’t write this in this book, but you can refer to the Kubernetes documentation for instructions.
Throughout the book, we will use this example to discuss aspects of Kubernetes, its inner workings, and how to extend it.
For the more advanced examples in Chapters 8 and 9, we will simulate a pizza restaurant with pizza and topping objects in the cluster. See “Example: A Pizza Restaurant” for details.
Extension Patterns
Kubernetes is a powerful and inherently extensible system. In general, there are multiple ways to customize and/or extend Kubernetes:
using configuration files and flags for control plane components like the kubelet or the Kubernetes API server, and through a number of defined extension points:
-
So-called cloud providers, which were traditionally in-tree as part of the controller manager. As of 1.11, Kubernetes makes out-of-tree development possible by providing a custom
cloud-controller-managerprocess to integrate with a cloud. Cloud providers allow the use of cloud provider–specific tools like load balancers or Virtual Machines (VMs). -
Binary
kubeletplug-ins for network, devices (such as GPUs), storage, and container runtimes. -
Binary
kubectlplug-ins. -
Access extensions in the API server, such as the dynamic admission control with webhooks (see Chapter 9).
-
Custom resources (see Chapter 4) and custom controllers; see the following section.
-
Custom API servers (see Chapter 8).
-
Scheduler extensions, such as using a webhook to implement your own scheduling decisions.
-
Authentication with webhooks.
In the context of this book we focus on custom resources, controllers, webhooks, and custom API servers, along with the Kubernetes extension patterns. If you’re interested in other extension points, such as storage or network plug-ins, check out the official documentation.
Now that you have a basic understanding of the Kubernetes extension patterns and the scope of this book, let’s move on to the heart of the Kubernetes control plane and see how we can extend it.
Controllers and Operators
In this section you’ll learn about controllers and operators in Kubernetes and how they work.
Per the Kubernetes glossary, a controller implements a control loop, watching the shared state of the cluster through the API server and making changes in an attempt to move the current state toward the desired state.
Before we dive into the controller’s inner workings, let’s define our terminology:
-
Controllers can act on core resources such as deployments or services, which are typically part of the Kubernetes controller manager in the control plane, or can watch and manipulate user-defined custom resources.
-
Operators are controllers that encode some operational knowledge, such as application lifecycle management, along with the custom resources defined in Chapter 4.
Naturally, given that the latter concept is based on the former, we’ll look at controllers first and then discuss the more specialized case of an operator.
The Control Loop
In general, the control loop looks as follows:
-
Read the state of resources, preferably event-driven (using watches, as discussed in Chapter 3). See “Events” and “Edge- Versus Level-Driven Triggers” for details.
-
Change the state of objects in the cluster or the cluster-external world. For example, launch a pod, create a network endpoint, or query a cloud API. See “Changing Cluster Objects or the External World” for details.
-
Update status of the resource in step 1 via the API server in
etcd. See “Optimistic Concurrency” for details. -
Repeat cycle; return to step 1.
No matter how complex or simple your controller is, these three steps—read resource state ˃ change the world ˃ update resource status—remain the same. Let’s dig a bit deeper into how these steps are actually implemented in a Kubernetes controller. The control loop is depicted in Figure 1-2, which shows the typical moving parts, with the main loop of the controller in the middle. This main loop is continuously running inside of the controller process. This process is usually running inside a pod in the cluster.
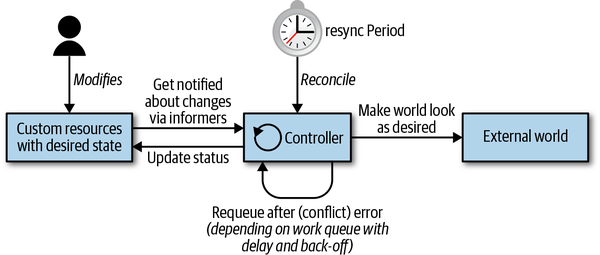
Figure 1-2. Kubernetes control loop
From an architectural point of view, a controller typically uses the following data structures (as discussed in detail in Chapter 3):
- Informers
-
Informers watch the desired state of resources in a scalable and sustainable fashion. They also implement a resync mechanism (see “Informers and Caching” for details) that enforces periodic reconciliation, and is often used to make sure that the cluster state and the assumed state cached in memory do not drift (e.g., due bugs or network issues).
- Work queues
-
Essentially, a work queue is a component that can be used by the event handler to handle queuing of state changes and help to implement retries. In
client-gothis functionality is available via the workqueue package (see “Work Queue”). Resources can be requeued in case of errors when updating the world or writing the status (steps 2 and 3 in the loop), or just because we have to reconsider the resource after some time for other reasons.
For a more formal discussion of Kubernetes as a declarative engine and state transitions, read “The Mechanics of Kubernetes” by Andrew Chen and Dominik Tornow.
Let’s now take a closer look at the control loop, starting with Kubernetes event-driven architecture.
Events
The Kubernetes control plane heavily employs events and the principle of loosely coupled components. Other distributed systems use remote procedure calls (RPCs) to trigger behavior. Kubernetes does not. Kubernetes controllers watch changes to Kubernetes objects in the API server: adds, updates, and removes. When such an event happens, the controller executes its business logic.
For example, in order to launch a pod via a deployment, a number of controllers and other control plane components work together:
-
The deployment controller (inside of
kube-controller-manager) notices (through a deployment informer) that the user creates a deployment. It creates a replica set in its business logic. -
The replica set controller (again inside of
kube-controller-manager) notices (through a replica set informer) the new replica set and subsequently runs its business logic, which creates a pod object. -
The scheduler (inside the
kube-schedulerbinary)—which is also a controller—notices the pod (through a pod informer) with an emptyspec.nodeNamefield. Its business logic puts the pod in its scheduling queue. -
Meanwhile the
kubelet—another controller—notices the new pod (through its pod informer). But the new pod’sspec.nodeNamefield is empty and therefore does not match thekubelet’s node name. It ignores the pod and goes back to sleep (until the next event). -
The scheduler takes the pod out of the work queue and schedules it to a node that has enough free resources by updating the
spec.nodeNamefield in the pod and writing it to the API server. -
The
kubeletwakes up again due to the pod update event. It again compares thespec.nodeNamewith its own node name. The names match, and so thekubeletstarts the containers of the pod and reports back that the containers have been started by writing this information into the pod status, back to the API server. -
The replica set controller notices the changed pod but has nothing to do.
-
Eventually the pod terminates. The
kubeletwill notice this, get the pod object from the API server and set the “terminated” condition in the pod’s status, and write it back to the API server. -
The replica set controller notices the terminated pod and decides that this pod must be replaced. It deletes the terminated pod on the API server and creates a new one.
-
And so on.
As you can see, a number of independent control loops communicate purely through object changes on the API server and events these changes trigger through informers.
These events are sent from the API server to the informers inside the controllers via watches (see “Watches”)—that is, streaming connections of watch events. All of this is mostly invisible to the user. Not even the API server audit mechanism makes these events visible; only the object updates are visible. Controllers often use log output, though, when they react on events.
If you want to learn more about events, read Michael Gasch’s blog post “Events, the DNA of Kubernetes”, where he provides more background and examples.
Edge- Versus Level-Driven Triggers
Let’s step back a bit and look more abstractly at how we can structure business logic implemented in controllers, and why Kubernetes has chosen to use events (i.e., state changes) to drive its logic.
There are two principled options to detect state change (the event itself):
- Edge-driven triggers
-
At the point in time the state change occurs, a handler is triggered—for example, from no pod to pod running.
- Level-driven triggers
-
The state is checked at regular intervals and if certain conditions are met (for example, pod running), then a handler is triggered.
The latter is a form of polling. It does not scale well with the number of objects, and the latency of controllers noticing changes depends on the interval of polling and how fast the API server can answer. With many asynchronous controllers involved, as described in “Events”, the result is a system that takes a long time to implement the users’ desire.
The former option is much more efficient with many objects. The latency mostly depends on the number of worker threads in the controller’s processing events. Hence, Kubernetes is based on events (i.e., edge-driven triggers).
In the Kubernetes control plane, a number of components change objects on the API server, with each change leading to an event (i.e., an edge). We call these components event sources or event producers. On the other hand, in the context of controllers, we’re interested in consuming events—that is, when and how to react to an event (via an informer).
In a distributed system there are many actors running in parallel, and events come in asynchronously in any order. When we have a buggy controller logic, some slightly wrong state machine, or an external service failure, it is easy to lose events in the sense that we don’t process them completely. Hence, we have to take a deeper look at how to cope with errors.
In Figure 1-3 you can see different strategies at work:
-
An example of an edge-driven-only logic, where potentially the second state change is missed.
-
An example of an edge-triggered logic, which always gets the latest state (i.e., level) when processing an event. In other words, the logic is edge-triggered but level-driven.
-
An example of an edge-triggered, level-driven logic with additional resync.

Figure 1-3. Trigger options (edge-driven versus level-driven)
Strategy 1 does not cope well with missed events, whether because broken networking makes it lose events, or because the controller itself has bugs or some external cloud API was down. Imagine that the replica set controller would replace pods only when they terminate. Missing events would mean that the replica set would always run with fewer pods because it never reconciles the whole state.
Strategy 2 recovers from those issues when another event is received because it implements its logic based on the latest state in the cluster. In the case of the replica set controller, it will always compare the specified replica count with the running pods in the cluster. When it loses events, it will replace all missing pods the next time a pod update is received.
Strategy 3 adds continuous resync (e.g., every five minutes). If no pod events come in, it will at least reconcile every five minutes, even if the application runs very stably and does not lead to many pod events.
Given the challenges of pure edge-driven triggers, the Kubernetes controllers typically implement the third strategy.
If you want to learn more about the origins of the triggers and the motivations for level triggering with reconciliation in Kubernetes, read James Bowes’s article, “Level Triggering and Reconciliation in Kubernetes”.
This concludes the discussion of the different, abstract ways to detect external changes and to react on them. The next step in the control loop of Figure 1-2 is to change the cluster objects or to change the external world following the spec. We’ll look at it now.
Changing Cluster Objects or the External World
In this phase, the controller changes the state of the objects it is supervising. For example, the ReplicaSet controller in the controller manager is supervising pods. On each event (edge-triggered), it will observe the current state of its pods and compare that with the desired state (level-driven).
Since the act of changing the resource state is domain- or task-specific, we can provide little guidance. Instead, we’ll keep looking at the ReplicaSet controller we introduced earlier. ReplicaSets are used in deployments, and the bottom line of the respective controller is: maintain a user-defined number of identical pod replicas. That is, if there are fewer pods than the user specified—for example, because a pod died or the replica value has been increased—the controller will launch new pods. If, however, there are too many pods, it will select some for termination. The entire business logic of the controller is available via the replica_set.go package, and the following excerpt of the Go code deals with the state change (edited for clarity):
// manageReplicas checks and updates replicas for the given ReplicaSet.// It does NOT modify <filteredPods>.// It will requeue the replica set in case of an error while creating/deleting pods.func(rsc*ReplicaSetController)manageReplicas(filteredPods[]*v1.Pod,rs*apps.ReplicaSet,)error{diff:=len(filteredPods)-int(*(rs.Spec.Replicas))rsKey,err:=controller.KeyFunc(rs)iferr!=nil{utilruntime.HandleError(fmt.Errorf("Couldn't get key for %v %#v: %v",rsc.Kind,rs,err),)returnnil}ifdiff<0{diff*=-1ifdiff>rsc.burstReplicas{diff=rsc.burstReplicas}rsc.expectations.ExpectCreations(rsKey,diff)klog.V(2).Infof("Too few replicas for %v %s/%s, need %d, creating %d",rsc.Kind,rs.Namespace,rs.Name,*(rs.Spec.Replicas),diff,)successfulCreations,err:=slowStartBatch(diff,controller.SlowStartInitialBatchSize,func()error{ref:=metav1.NewControllerRef(rs,rsc.GroupVersionKind)err:=rsc.podControl.CreatePodsWithControllerRef(rs.Namespace,&rs.Spec.Template,rs,ref,)iferr!=nil&&errors.IsTimeout(err){returnnil}returnerr},)ifskippedPods:=diff-successfulCreations;skippedPods>0{klog.V(2).Infof("Slow-start failure. Skipping creation of %d pods,"+" decrementing expectations for %v %v/%v",skippedPods,rsc.Kind,rs.Namespace,rs.Name,)fori:=0;i<skippedPods;i++{rsc.expectations.CreationObserved(rsKey)}}returnerr}elseifdiff>0{ifdiff>rsc.burstReplicas{diff=rsc.burstReplicas}klog.V(2).Infof("Too many replicas for %v %s/%s, need %d, deleting %d",rsc.Kind,rs.Namespace,rs.Name,*(rs.Spec.Replicas),diff,)podsToDelete:=getPodsToDelete(filteredPods,diff)rsc.expectations.ExpectDeletions(rsKey,getPodKeys(podsToDelete))errCh:=make(chanerror,diff)varwgsync.WaitGroupwg.Add(diff)for_,pod:=rangepodsToDelete{gofunc(targetPod*v1.Pod){deferwg.Done()iferr:=rsc.podControl.DeletePod(rs.Namespace,targetPod.Name,rs,);err!=nil{podKey:=controller.PodKey(targetPod)klog.V(2).Infof("Failed to delete %v, decrementing "+"expectations for %v %s/%s",podKey,rsc.Kind,rs.Namespace,rs.Name,)rsc.expectations.DeletionObserved(rsKey,podKey)errCh<-err}}(pod)}wg.Wait()select{caseerr:=<-errCh:iferr!=nil{returnerr}default:}}returnnil}
You can see that the controller computes the difference between specification and current state in the line diff := len(filteredPods) - int(*(rs.Spec.Replicas)) and then implements two cases depending on that:
-
diff<0: Too few replicas; more pods must be created. -
diff>0: Too many replicas; pods must be deleted.
It also implements a strategy to choose pods where it is least harmful to delete them in getPodsToDelete.
Changing the resource state does not, however, necessarily mean that the resources themselves have to be part of the Kubernetes cluster. In other words, a controller can change the state of resources that are located outside of Kubernetes, such as a cloud storage service. For example, the AWS Service Operator allows you to manage AWS resources. Among other things, it allows you to manage S3 buckets—that is, the S3 controller is supervising a resource (the S3 bucket) that exists outside of Kubernetes, and the state changes reflect concrete phases in its lifecycle: an S3 bucket is created and at some point deleted.
This should convince you that with a custom controller you can manage not only core resources, like pods, and custom resources, like our cnat example, but even compute or store resources that exist outside of Kubernetes. This makes controllers very flexible and powerful integration mechanisms, providing a unified way to use resources across platforms and environments.
Optimistic Concurrency
In “The Control Loop”, we discussed in step 3 that a controller—after updating cluster objects and/or the external world according to the spec—writes the results into the status of the resource that triggered the controller run in step 1.
This and actually any other write (also in step 2) can go wrong. In a distributed system, this controller is probably only one of many that update resources. Concurrent writes can fail because of write conflicts.
To better understand what’s happening, let’s step back a bit and have a look at Figure 1-4.2
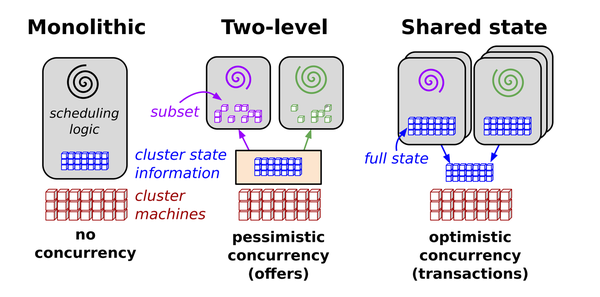
Figure 1-4. Scheduling architectures in distributed systems
The source defines Omega’s parallel scheduler architecture as follows:
Our solution is a new parallel scheduler architecture built around shared state, using lock-free optimistic concurrency control, to achieve both implementation extensibility and performance scalability. This architecture is being used in Omega, Google’s next-generation cluster management system.
While Kubernetes inherited a lot of traits and lessons learned from Borg, this specific, transactional control plane feature comes from Omega: in order to carry out concurrent operations without locks, the Kubernetes API server uses optimistic concurrency.
This means, in a nutshell, that if and when the API server detects concurrent write attempts, it rejects the latter of the two write operations. It is then up to the client (controller, scheduler, kubectl, etc.) to handle a conflict and potentially retry the write operation.
The following demonstrates the idea of optimistic concurrency in Kubernetes:
var err errorforretries :=0;retries < 10;retries++{foo,err=client.Get("foo", metav1.GetOptions{})iferr !=nil{break}<update-the-world-and-foo> _,err=client.Update(foo)iferr !=nil&&errors.IsConflict(err){continue}elseiferr !=nil{break}}
The code shows a retry loop that gets the latest object foo in each iteration, then tries to update the world and foo’s status to match foo’s spec. The changes done before the Update call are optimistic.
The returned object foo from the client.Get call contains a resource version (part of the embedded ObjectMeta struct—see “ObjectMeta” for details), which will tell etcd on the write operation behind the client.Update call that another actor in the cluster wrote the foo object in the meantime. If that’s the case, our retry loop will get a resource version conflict error. This means that the optimistic concurrency logic failed. In other words, the client.Update call is also optimistic.
Note
The resource version is actually the etcd key/value version. The resource version of each object is a string in Kubernetes that contains an integer. This integer comes directly from etcd. etcd maintains a counter that increases each time the value of a key (which holds the object’s serialization) is modified.
Throughout the API machinery code the resource version is (more or less consequently) handled like an arbitrary string, but with some ordering on it. The fact that integers are stored is just an implementation detail of the current etcd storage backend.
Let’s look at a concrete example. Imagine your client is not the only actor in the cluster that modifies a pod. There is another actor, namely the kubelet, that constantly modifies some fields because a container is constantly crashing. Now your controller reads the pod object’s latest state like so:
kind:Podmetadata:name:fooresourceVersion:57spec:...status:...
Now assume the controller needs several seconds with its updates to the world. Seven seconds later, it tries to update the pod it read—for example, it sets an annotation. Meanwhile, the kubelet has noticed yet another container restart and updated the pod’s status to reflect that; that is, resourceVersion has increased to 58.
The object your controller sends in the update request has resourceVersion: 57. The API server tries to set the etcd key for the pod with that value. etcd notices that the resource versions do not match and reports back that 57 conflicts with 58. The update fails.
The bottom line of this example is that for your controller, you are responsible for implementing a retry strategy and for adapting if an optimistic operation failed. You never know who else might be manipulating state, whether other custom controllers or core controllers such as the deployment controller.
The essence of this is: conflict errors are totally normal in controllers. Always expect them and handle them gracefully.
It’s important to point out that optimistic concurrency is a perfect fit for level-based logic, because by using level-based logic you can just rerun the control loop (see “Edge- Versus Level-Driven Triggers”). Another run of that loop will automatically undo optimistic changes from the previous failed optimistic attempt, and it will try to update the world to the latest state.
Let’s move on to a specific case of custom controllers (along with custom resources): the operator.
Operators
Operators as a concept in Kubernetes were introduced by CoreOS in 2016. In his seminal blog post, “Introducing Operators: Putting Operational Knowledge into Software”, CoreOS CTO Brandon Philips defined operators as follows:
A Site Reliability Engineer (SRE) is a person [who] operates an application by writing software. They are an engineer, a developer, who knows how to develop software specifically for a particular application domain. The resulting piece of software has an application’s operational domain knowledge programmed into it.
[…]
We call this new class of software Operators. An Operator is an application-specific controller that extends the Kubernetes API to create, configure, and manage instances of complex stateful applications on behalf of a Kubernetes user. It builds upon the basic Kubernetes resource and controller concepts but includes domain or application-specific knowledge to automate common tasks.
In the context of this book, we will use operators as Philips describes them and, more formally, require that the following three conditions hold (see also Figure 1-5):
-
There’s some domain-specific operational knowledge you’d like to automate.
-
The best practices for this operational knowledge are known and can be made explicit—for example, in the case of a Cassandra operator, when and how to re-balance nodes, or in the case of an operator for a service mesh, how to create a route.
-
The artifacts shipped in the context of the operator are:
-
A set of custom resource definitions (CRDs) capturing the domain-specific schema and custom resources following the CRDs that, on the instance level, represent the domain of interest.
-
A custom controller, supervising the custom resources, potentially along with core resources. For example, the custom controller might spin up a pod.
-

Figure 1-5. The concept of an operator
Operators have come a long way from the conceptual work and prototyping in 2016 to the launch of OperatorHub.io by Red Hat (which acquired CoreOS in 2018 and continued to build out the idea) in early 2019. See Figure 1-6 for a screenshot of the hub in mid-2019 sporting some 17 operators, ready to be used.

Figure 1-6. OperatorHub.io screenshot
Summary
In this first chapter we defined the scope of our book and what we expect from you. We explained what we mean by programming Kubernetes and defined Kubernetes-native apps in the context of this book. As preparation for later examples, we also provided a high-level introduction to controllers and operators.
So, now that you know what to expect from the book and how you can benefit from it, let’s jump into the deep end. In the next chapter, we’ll take a closer look at the Kubernetes API, the API server’s inner workings, and how you can interact with the API using command-line tools such as curl.
1 For more on this topic, see Megan O’Keefe’s “A Kubernetes Developer Workflow for MacOS”, Medium, January 24, 2019; and Alex Ellis’s blog post, “Be KinD to yourself”, December 14, 2018.
2 Source: “Omega: Flexible, Scalable Schedulers for Large Compute Clusters”, by Malte Schwarzkopf et al., Google AI, 2013.