
Chapter 3. Basics of client-go
We’ll now focus on the Kubernetes programming interface in Go. You’ll learn how to access the Kubernetes API of the well-known native types like pods, services, and deployment. In later chapters, these techniques will be extended to user-defined types. Here, though, we first concentrate on all API objects that are shipped with every Kubernetes cluster.
The Repositories
The Kubernetes project provides a number of third-party consumable Git repositories under the kubernetes organization on GitHub. You’ll need to import all of these with the domain alias k8s.io/… (not github.com/kubernetes/…) into your project. We’ll present the most important of these repositories in the following sections.
The Client Library
The Kubernetes programming interface in Go mainly consists of the k8s.io/client-go library (for brevity we will just call it client-go going forward). client-go is a typical web service client library that supports all API types that are officially part of Kubernetes. It can be used to execute the usual REST verbs:
-
Create
-
Get
-
List
-
Update
-
Delete
-
Patch
Each of these REST verbs are implemented using the “The HTTP Interface of the API Server”. Furthermore, the verb Watch is supported, which is special for Kubernetes-like APIs, and one of the main differentiators compared to other APIs.
client-go is available on GitHub (see Figure 3-1), and used in Go code with the k8s.io/client-go package name. It is shipped in parallel to Kubernetes itself; that is, for each Kubernetes 1.x.y release, there is a client-go release with a matching tag kubernetes-1.x.y.
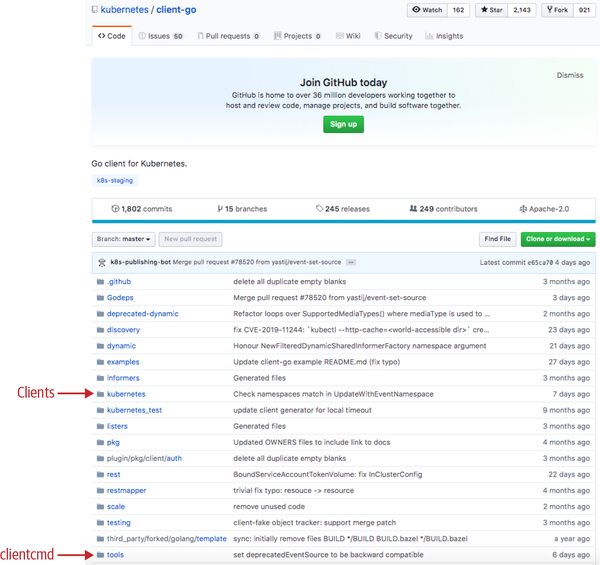
Figure 3-1. The client-go repository on GitHub
In addition, there is a semantic versioning scheme. For example, client-go 9.0.0 matches the Kubernetes 1.12 release, client-go 10.0.0 matches Kubernetes 1.13, and so on. There may be more fine-grained releases in the future. Besides the client code for Kubernetes API objects, client-go also contains a lot of generic library code. This is also used for user-defined API objects in Chapter 4. See Figure 3-1 for a list of packages.
While all packages have their use, most of your code that speaks to Kubernetes APIs will use tools/clientcmd/ to set up a client from a kubeconfig file and kubernetes/ for the actual Kubernetes API clients. We will see code doing this very soon. Before that, let’s finish a quick walk through with other relevant repositories and packages.
Kubernetes API Types
As we have seen, client-go holds the client interfaces. The Kubernetes API Go types for objects like pods, services, and deployments are located in their own repository. It is accessed as k8s.io/api in Go code.
Pods are part of the legacy API group (often also called the “core” group) version v1. Hence, the Pod Go type is found in k8s.io/api/core/v1, and similarly for all other API types in Kubernetes. See Figure 3-2 for a list of packages, most of which correspond to Kubernetes API groups and their versions.
The actual Go types are contained in a types.go file (e.g., k8s.io/api/core/v1/types.go). In addition, there are other files, most of them automatically generated by a code generator.
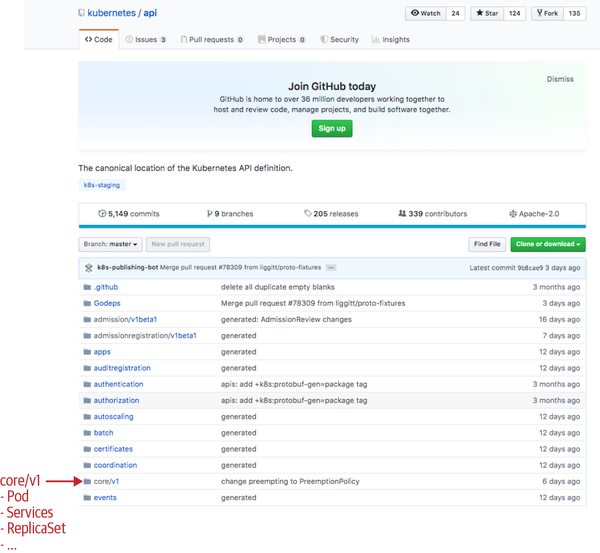
Figure 3-2. The API repository on GitHub
API Machinery
Last but not least, there is a third repository called API Machinery, which is used as k8s.io/apimachinery in Go. It includes all the generic building blocks to implement a Kubernetes-like API. API Machinery is not restricted to container management, so, for example, it could be used to build APIs for an online shop or any other business-specific domain.
Nevertheless, you’ll meet a lot of API Machinery packages in Kubernetes-native Go code. An important one is k8s.io/apimachinery/pkg/apis/meta/v1. It contains many of the generic API types such as ObjectMeta, TypeMeta, GetOptions, and ListOptions (see Figure 3-3).
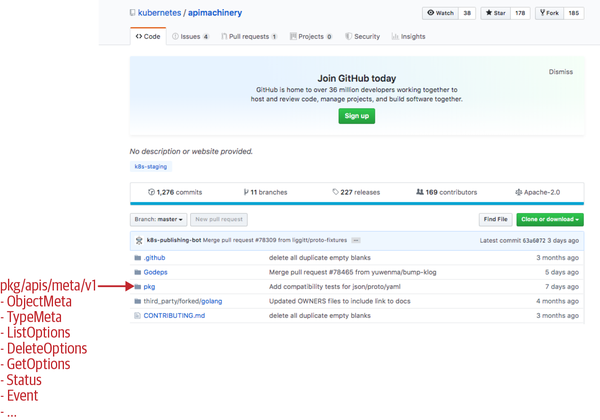
Figure 3-3. The API Machinery repository on GitHub
Creating and Using a Client
Now we know all the building blocks to create a Kubernetes client object, which means we can access resources in a Kubernetes cluster. Assuming you have access to a cluster in your local environment (i.e., kubectl is properly set up and credentials are configured), the following code illustrates how you can use client-go in a Go project:
import(metav1"k8s.io/apimachinery/pkg/apis/meta/v1""k8s.io/client-go/tools/clientcmd""k8s.io/client-go/kubernetes")kubeconfig=flag.String("kubeconfig","~/.kube/config","kubeconfig file")flag.Parse()config,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)clientset,err:=kubernetes.NewForConfig(config)pod,err:=clientset.CoreV1().Pods("book").Get("example",metav1.GetOptions{})
The code imports the meta/v1 package to get access to metav1.GetOptions. Furthermore, it imports clientcmd from client-go in order to read and parse the kubeconfig (i.e., the client configuration with server name, credentials, etc.). Then it imports the client-go kubernetes package with the client sets for Kubernetes resources.
The default location for the kubeconfig file is in .kube/config in the user’s home directory. This is also where kubectl gets the credentials for the Kubernetes clusters.
That kubeconfig is then read and parsed using clientcmd.BuildConfigFromFlags. We omitted the mandatory error handling throughout this code, but the err variable would normally contain, for example, the syntax error if a kubeconfig is not well formed. As syntax errors are common in Go code, such an error ought to be checked for properly, like so:
config,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)iferr!=nil{fmt.Printf("The kubeconfig cannot be loaded: %v ",erros.Exit(1)}
From clientcmd.BuildConfigFromFlags we get a rest.Config, which you can find in the k8s.io/client-go/rest package). This is passed to kubernetes.NewForConfig in order to create the actual Kubernetes client set. It’s called a client set because it contains multiple clients for all native Kubernetes resources.
When running a binary inside of a pod in a cluster, the kubelet will automatically mount a service account into the container at /var/run/secrets/kubernetes.io/serviceaccount. It replaces the kubeconfig file just mentioned and can easily be turned into a rest.Config via the rest.InClusterConfig() method. You’ll often find the following combination of rest.InClusterConfig() and clientcmd.BuildConfigFromFlags(), including support for the KUBECONFIG environment variable:
config,err:=rest.InClusterConfig()iferr!=nil{// fallback to kubeconfigkubeconfig:=filepath.Join("~",".kube","config")ifenvvar:=os.Getenv("KUBECONFIG");len(envvar)>0{kubeconfig=envvar}config,err=clientcmd.BuildConfigFromFlags("",kubeconfig)iferr!=nil{fmt.Printf("The kubeconfig cannot be loaded: %v ",erros.Exit(1)}}
In the following example code we select the core group in v1 with clientset.CoreV1() and then access the pod "example" in the "book" namespace:
pod,err:=clientset.CoreV1().Pods("book").Get("example",metav1.GetOptions{})
Note that only the last function call, Get, actually accesses the server. Both CoreV1 and Pods select the client and set the namespace only for the following Get call (this is often called the builder pattern, in this case to build a request).
The Get call sends an HTTP GET request to /api/v1/namespaces/book/pods/example on the server, which is set in the kubeconfig. If the Kubernetes API server answers with HTTP code 200, the body of the response will carry the encoded pod objects, either as JSON—which is the default wire format of client-go—or as protocol buffers.
Note
You can enable protobuf for native Kubernetes resource clients by modifying the REST config before creating a client from it:
cfg,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)cfg.AcceptContentTypes="application/vnd.kubernetes.protobuf,application/json"cfg.ContentType="application/vnd.kubernetes.protobuf"clientset,err:=kubernetes.NewForConfig(cfg)
Note that the custom resources presented in Chapter 4 do not support protocol buffers.
Versioning and Compatibility
Kubernetes APIs are versioned. We have seen in the previous section that pods are in v1 of the core group. The core group actually exists in only one version today. There are other groups, though—for example, the apps group, which exists in v1, v1beta2, and v1beta1 (as of this writing). If you look into the k8s.io/api/apps package, you will find all the API objects of these versions. In the k8s.io/client-go/kubernetes/typed/apps package, you’ll see the client implementations for all of these versions.
All of this is only the client side. It does not say anything about the Kubernetes cluster and its API server. Using a client with a version of an API group that the API server does not support will fail. Clients are hardcoded to a version, and the application developer has to select the right API group version in order to speak to the cluster at hand. See “API Versions and Compatibility Guarantees” for more on API group compatibility guarantees.
A second aspect of compatibility is the meta API features of the API server that client-go is speaking to. For example, there are option structs for CRUD verbs, like CreateOptions, GetOptions, UpdateOptions, and DeleteOptions. Another important one is ObjectMeta (discussed in detail in “ObjectMeta”), which is part of every kind. All of these are frequently extended with new features; we usually call them API machinery features. In the Go documentation of their fields, comments specify when features are considered alpha or beta. The same API compatibility guarantees apply as for any other API fields.
In the example that follows, the DeleteOptions struct is defined in the package k8s.io/apimachinery/pkg/apis/meta/v1/types.go:
// DeleteOptions may be provided when deleting an API object.typeDeleteOptionsstruct{TypeMeta`json:",inline"`GracePeriodSeconds*int64`json:"gracePeriodSeconds,omitempty"`Preconditions*Preconditions`json:"preconditions,omitempty"`OrphanDependents*bool`json:"orphanDependents,omitempty"`PropagationPolicy*DeletionPropagation`json:"propagationPolicy,omitempty"`// When present, indicates that modifications should not be// persisted. An invalid or unrecognized dryRun directive will// result in an error response and no further processing of the// request. Valid values are:// - All: all dry run stages will be processed// +optionalDryRun[]string`json:"dryRun,omitempty" protobuf:"bytes,5,rep,name=dryRun"`}
The last field, DryRun, was added in Kubernetes 1.12 as alpha and in 1.13 as beta (enabled by default). It is not understood by the API server in earlier versions. Depending on the feature, passing such an option might simply be ignored or even rejected. So it is important to have a client-go version that is not too far off from the cluster version.
Tip
The reference for which fields are available in which quality level is the sources in k8s.io/api, which are accessible, for example, for Kubernetes 1.13 in the release-1.13 branch. Alpha fields are marked as such in their description.
There is generated API documentation for easier consumption. It is the same information, though, as in k8s.io/api.
Last but not least, many alpha and beta features have corresponding feature gates (check here for the primary source). Features are tracked in issues.
The formally guaranteed support matrix between cluster and client-go versions is published in the client-go README (see Table 3-1).
| Kubernetes 1.9 | Kubernetes 1.10 | Kubernetes 1.11 | Kubernetes 1.12 | Kubernetes 1.13 | Kubernetes 1.14 | Kubernetes 1.15 | |
|---|---|---|---|---|---|---|---|
client-go 6.0 |
✓ |
+– |
+– |
+– |
+– |
+– |
+– |
client-go 7.0 |
+– |
✓ |
+– |
+– |
+– |
+– |
+– |
client-go 8.0 |
+– |
+– |
✓ |
+– |
+– |
+– |
+– |
client-go 9.0 |
+– |
+– |
+– |
✓ |
+– |
+– |
+– |
client-go 10.0 |
+– |
+– |
+– |
+– |
✓ |
+– |
+– |
client-go 11.0 |
+– |
+– |
+– |
+– |
+– |
✓ |
+– |
client-go 12.0 |
+– |
+– |
+– |
+– |
+– |
+– |
✓ |
client-go HEAD |
+– |
+– |
+– |
+– |
+– |
+– |
+– |
-
✓: both
client-goand the Kubernetes version have the same features and the same API group versions. -
+:client-gohas features or API group versions that may be absent from the Kubernetes cluster. This may be because of added functionality inclient-goor because Kubernetes removed old, deprecated functionality. However, everything they have in common (i.e., most APIs) will work. -
–:client-gois knowingly incompatible with the Kubernetes cluster.
The takeaway from Table 3-1 is that the client-go library is supported with its corresponding cluster version. In case of version skew, developers have to carefully consider which features and which API groups they use and whether these are supported in the cluster version the application speaks to.
In Table 3-1, the client-go versions are listed. We briefly mentioned in “The Client Library” that client-go uses semantic versioning (semver) formally, though by increasing the major version of client-go each time the minor version of Kubernetes (the 13 in 1.13.2) is increased. With client-go 1.0 being released for Kubernetes 1.4, we are now at client-go 12.0 (at the time of this writing) for Kubernetes 1.15.
This semver applies only to client-go itself, not to API Machinery or the API repository. Instead, the latter are tagged using Kubernetes versions, as seen in Figure 3-4. See “Vendoring” to see what this means for vendoring k8s.io/client-go, k8s.io/apimachinery, and k8s.io/api in your project.
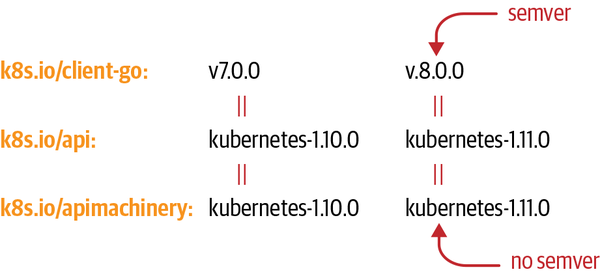
Figure 3-4. client-go versioning
API Versions and Compatibility Guarantees
As seen in the previous section, the selection of the right API group versions may be crucial if you target different cluster versions with your code. Kubernetes versions all API groups. A common Kubernetes-style versioning scheme is used, which consists of alpha, beta, and GA (general availability) versions.
The pattern is:
-
v1alpha1,v1alpha2,v2alpha1, and so on are called alpha versions and considered unstable. This means:-
They might go away or change at any time, in any incompatible way.
-
Data might be dropped, get lost, or become inaccessible from Kubernetes version to version.
-
They are often disabled by default, if the administrator does not opt in manually.
-
-
v1beta1,v1beta2,v2beta1, and so on, are called beta versions. They are on the way to stability, which means:-
They will still exist for at least one Kubernetes release in parallel to the corresponding stable API version.
-
They will usually not change in incompatible ways, but there is no strict guarantee of that.
-
Objects stored in a beta version will not be dropped or become inaccessible.
-
Beta versions are often enabled in clusters by default. But this might depend on the Kubernetes distribution or cloud provider used.
-
-
v1,v2, and so on are stable, generally available APIs; that is:-
They will stay.
-
They will be compatible.
-
Tip
Kubernetes has a formal deprecation policy behind these rules of thumb. You can find many more details about which APIs constructs are considered compatible at the Kubernetes community GitHub.
In connection to API group versions, there are two important points to keep in mind:
-
API group versions apply to API resources as a whole, like the format of pods or services. In addition to API group versions, API resources might have single fields that are versioned orthogonally; for example, fields in stable APIs might be marked as alpha quality in their Go inline code documentation. The same rules as those just listed for API groups will apply to those fields. For example:
-
An alpha field in a stable API could become incompatible, lose data, or go away at any time. For example, the
ObjectMeta.Initializersfield, which was never promoted beyond alpha, will go away in the near future (it is deprecated in 1.14):// DEPRECATED - initializers are an alpha field and will be removed// in v1.15.Initializers*Initializers`json:"initializers,omitempty" -
It usually will be disabled by default and must be enabled with an API server feature gate, like so:
typeJobSpecstruct{...// This field is alpha-level and is only honored by servers that// enable the TTLAfterFinished feature.TTLSecondsAfterFinished*int32`json:"ttlSecondsAfterFinished,omitempty"} -
The behavior of the API server will differ from field to field. Some alpha fields will be rejected and some will be ignored if the corresponding feature gate is not enabled. This is documented in the field description (see
TTLSecondsAfterFinishedin the previous example).
-
-
Furthermore, API group versions play a role in accessing the API. Between different versions of the same resource, there is an on-the-fly conversion done by the API server. That is, you can access objects created in one version (e.g.,
v1beta1) in any of the other supported versions (e.g.,v1) without any further work in your application. This is very convenient for building backward- and forward-compatible applications.-
Each object stored in
etcdis stored in a specific version. By default, this is called the storage version of that resource. While the storage version can change from Kubernetes version to version, the object stored inetcdwill not automatically be updated as of this writing. Hence, the cluster administrator has to make sure migration happens in time when Kubernetes clusters are updated, before old version support is dropped. There is no generic migration mechanism for that, and migration differs from Kubernetes distribution to distribution. -
For the application developer, though, this operational work should not matter at all. On-the-fly conversion will make sure the application has a unified picture of the objects in the cluster. The application will not even notice which storage version is in use. Storage versioning will be transparent to the written Go code.
-
Kubernetes Objects in Go
In “Creating and Using a Client”, we saw how to create a client for the core group in order to access pods in a Kubernetes cluster. In the following, we want to look in more detail at what a pod—or any other Kubernetes resource, for that matter—is in the world of Go.
Kubernetes resources—or more precisely the objects—that are instances of a kind1 and are served as a resource by the API server are represented as structs. Depending on the kind in question, their fields of course differ. But on the other hand, they share a common structure.
From the type system point of view, Kubernetes objects fulfill a Go interface called runtime.Object from the package k8s.io/apimachinery/pkg/runtime, which actually is very simple:
// Object interface must be supported by all API types registered with Scheme.// Since objects in a scheme are expected to be serialized to the wire, the// interface an Object must provide to the Scheme allows serializers to set// the kind, version, and group the object is represented as. An Object may// choose to return a no-op ObjectKindAccessor in cases where it is not// expected to be serialized.typeObjectinterface{GetObjectKind()schema.ObjectKindDeepCopyObject()Object}
Here, schema.ObjectKind (from the k8s.io/apimachinery/pkg/runtime/schema package) is another simple interface:
// All objects that are serialized from a Scheme encode their type information.// This interface is used by serialization to set type information from the// Scheme onto the serialized version of an object. For objects that cannot// be serialized or have unique requirements, this interface may be a no-op.typeObjectKindinterface{// SetGroupVersionKind sets or clears the intended serialized kind of an// object. Passing kind nil should clear the current setting.SetGroupVersionKind(kindGroupVersionKind)// GroupVersionKind returns the stored group, version, and kind of an// object, or nil if the object does not expose or provide these fields.GroupVersionKind()GroupVersionKind}
In other words, a Kubernetes object in Go is a data structure that can:
A deep copy is a clone of the data structure such that it does not share any memory with the original object. It is used wherever code has to mutate an object without modifying the original. See “Global Tags” about code generation for details on how deep copy is implemented in Kubernetes.
Put simply, an object stores its type and allows cloning.
TypeMeta
While runtime.Object is only an interface, we want to know how it is actually implemented. Kubernetes objects from k8s.io/api implement the type getter and setter of schema.ObjectKind by embedding the metav1.TypeMeta struct from the package k8s.io/apimachinery/meta/v1:
// TypeMeta describes an individual object in an API response or request// with strings representing the type of the object and its API schema version.// Structures that are versioned or persisted should inline TypeMeta.//// +k8s:deepcopy-gen=falsetypeTypeMetastruct{// Kind is a string value representing the REST resource this object// represents. Servers may infer this from the endpoint the client submits// requests to.// Cannot be updated.// In CamelCase.// +optionalKindstring`json:"kind,omitempty" protobuf:"bytes,1,opt,name=kind"`// APIVersion defines the versioned schema of this representation of an// object. Servers should convert recognized schemas to the latest internal// value, and may reject unrecognized values.// +optionalAPIVersionstring`json:"apiVersion,omitempty"`}
With this, a pod declaration in Go looks like this:
// Pod is a collection of containers that can run on a host. This resource is// created by clients and scheduled onto hosts.typePodstruct{metav1.TypeMeta`json:",inline"`// Standard object's metadata.// +optionalmetav1.ObjectMeta`json:"metadata,omitempty"`// Specification of the desired behavior of the pod.// +optionalSpecPodSpec`json:"spec,omitempty"`// Most recently observed status of the pod.// This data may not be up to date.// Populated by the system.// Read-only.// +optionalStatusPodStatus`json:"status,omitempty"`}
As you can see, TypeMeta is embedded. Moreover, the pod type has JSON tags that also declare TypeMeta as being inlined.
Note
This ",inline" tag is actually superfluous with the Golang JSON en/decoders: embedded structs are automatically inlined.
This is different in the YAML en/decoder go-yaml/yaml, which was used in very early Kubernetes code in parallel to JSON. We inherited the inline tag from that time, but today it is merely documentation without any effect.
The YAML serializers foudn in k8s.io/apimachinery/pkg/runtime/serializer/yaml use the sigs.k8s.io/yaml marshal and unmarshal functions. And these in turn encode and decode YAML via interface{}, and use the JSON encoder into and decoder from Golang API structs.
This matches the YAML representation of a pod, which all Kubernetes users know:2
apiVersion:v1kind:Podmetadata:namespace:defaultname:examplespec:containers:-name:helloimage:debian:latestcommand:-/bin/shargs:--c-echo "hello world"; sleep 10000
The version is stored in TypeMeta.APIVersion, the kind in TypeMeta.Kind.
When running the example in “Creating and Using a Client” to get a pod from the cluster, notice that the pod object returned by the client does not actually have the kind and the version set. The convention in client-go–based applications is that these fields are empty in memory, and they are filled with the actual values on the wire only when they’re marshaled to JSON or protobuf. This is done automatically by the client, however, or, more precisely, by a versioning serializer.
In other words, client-go–based applications check the Golang type of objects to determine the object at hand. This might differ in other frameworks, like the Operator SDK (see “The Operator SDK”).
ObjectMeta
In addition to TypeMeta, most top-level objects have a field of type metav1.ObjectMeta, again from the k8s.io/apimachinery/pkg/meta/v1 package:
typeObjectMetastruct{Namestring`json:"name,omitempty"`Namespacestring`json:"namespace,omitempty"`UIDtypes.UID`json:"uid,omitempty"`ResourceVersionstring`json:"resourceVersion,omitempty"`CreationTimestampTime`json:"creationTimestamp,omitempty"`DeletionTimestamp*Time`json:"deletionTimestamp,omitempty"`Labelsmap[string]string`json:"labels,omitempty"`Annotationsmap[string]string`json:"annotations,omitempty"`...}
In JSON or YAML these fields are under metadata. For example, for the previous pod, metav1.ObjectMeta stores:
metadata:namespace:defaultname:example
In general, it contains all metalevel information like name, namespace, resource version (not to be confused with the API group version), several timestamps, and the well-known labels and annotations is part of ObjectMeta. See “Anatomy of a type” for a deeper discussion of ObjectMeta fields.
The resource version was discussed earlier in “Optimistic Concurrency”. It is hardly ever read or written from client-go code. But it is one of the fields in Kubernetes that makes the whole system work. resourceVersion is part of ObjectMeta because each object with embedded ObjectMeta corresponds to a key in etcd where the resourceVersion value originated.
spec and status
Finally, nearly every top-level object has a spec and a status section. This convention comes from the declarative nature of the Kubernetes API: spec is the user desire, and status is the outcome of that desire, usually filled by a controller in the system. See “Controllers and Operators” for a detailed discussion of controllers in Kubernetes.
There are only a few exceptions to the spec and status convention in the system—for example, endpoints in the core group, or RBAC objects like ClusterRole.
Client Sets
In the introductory example in “Creating and Using a Client”, we saw that kubernetes.NewForConfig(config) gives us a client set. A client set gives access to clients for multiple API groups and resources. In the case of kubernetes.NewForConfig(config) from k8s.io/client-go/kubernetes, we get access to all API groups and resources defined in k8s.io/api. This is, with a few exceptions—such as APIServices (for aggregated API servers) and CustomResourceDefinition (see Chapter 4)—the whole set of resources served by the Kubernetes API server.
In Chapter 5, we will explain how these client sets are actually generated from the API types (k8s.io/api, in this case). Third-party projects with custom APIs use more than just the Kubernetes client sets. What all of the client sets have in common is a REST config (e.g., returned by clientcmd.BuildConfigFromFlags("", *kubeconfig), like in the example).
The client set main interface in k8s.io/client-go/kubernetes/typed for Kubernetes-native resources looks like this:
typeInterfaceinterface{Discovery()discovery.DiscoveryInterfaceAppsV1()appsv1.AppsV1InterfaceAppsV1beta1()appsv1beta1.AppsV1beta1InterfaceAppsV1beta2()appsv1beta2.AppsV1beta2InterfaceAuthenticationV1()authenticationv1.AuthenticationV1InterfaceAuthenticationV1beta1()authenticationv1beta1.AuthenticationV1beta1InterfaceAuthorizationV1()authorizationv1.AuthorizationV1InterfaceAuthorizationV1beta1()authorizationv1beta1.AuthorizationV1beta1Interface...}
There used to be unversioned methods in this interface—for example, just Apps() appsv1.AppsV1Interface—but they were deprecated as of Kubernetes 1.14–based client-go 11.0. As mentioned before, it is seen as a good practice to be very explicit about the version of an API group that an application uses.
Every client set also gives access to the discovery client (it will be used by the RESTMappers; see “REST Mapping” and “Using the API from the Command Line”).
Behind each GroupVersion method (e.g., AppsV1beta1), we find the resources of the API group—for example:
typeAppsV1beta1Interfaceinterface{RESTClient()rest.InterfaceControllerRevisionsGetterDeploymentsGetterStatefulSetsGetter}
with RESTClient being a generic REST client, and one interface per resource, as in:
// DeploymentsGetter has a method to return a DeploymentInterface.// A group's client should implement this interface.typeDeploymentsGetterinterface{Deployments(namespacestring)DeploymentInterface}// DeploymentInterface has methods to work with Deployment resources.typeDeploymentInterfaceinterface{Create(*v1beta1.Deployment)(*v1beta1.Deployment,error)Update(*v1beta1.Deployment)(*v1beta1.Deployment,error)UpdateStatus(*v1beta1.Deployment)(*v1beta1.Deployment,error)Delete(namestring,options*v1.DeleteOptions)errorDeleteCollection(options*v1.DeleteOptions,listOptionsv1.ListOptions)errorGet(namestring,optionsv1.GetOptions)(*v1beta1.Deployment,error)List(optsv1.ListOptions)(*v1beta1.DeploymentList,error)Watch(optsv1.ListOptions)(watch.Interface,error)Patch(namestring,pttypes.PatchType,data[]byte,subresources...string)(result*v1beta1.Deployment,errerror)DeploymentExpansion}
Depending on the scope of the resource—that is, whether it is cluster or namespace scoped—the accessor (here DeploymentGetter) may or may not have a namespace argument.
The DeploymentInterface gives access to all the supported verbs of the resource. Most of them are self-explanatory, but those requiring additional commentary are described next.
Status Subresources: UpdateStatus
Deployments have a so-called status subresource. This means that UpdateStatus uses an additional HTTP endpoint suffixed with /status. While updates on the /apis/apps/v1beta1/namespaces/ns/deployments/name endpoint can change only the spec of the deployment, the endpoint /apis/apps/v1beta1/namespaces/ns/deployments/name/status can change only the status of the object. This is useful in order to set different permissions for spec updates (done by a human) and status updates (done by a controller).
By default the client-gen (see “client-gen Tags”) generates the UpdateStatus() method. The existence of the method does not guarantee that the resource actually supports the subresource. This will be important when we’re working with CRDs in “Subresources”.
Listings and Deletions
DeleteCollection allows us to delete multiple objects of a namespace at once. The ListOptions parameter allows us to define which objects should be deleted using a field or label selector:
typeListOptionsstruct{...// A selector to restrict the list of returned objects by their labels.// Defaults to everything.// +optionalLabelSelectorstring`json:"labelSelector,omitempty"`// A selector to restrict the list of returned objects by their fields.// Defaults to everything.// +optionalFieldSelectorstring`json:"fieldSelector,omitempty"`...}
Watches
Watch gives an event interface for all changes (adds, removes, and updates) to objects. The returned watch.Interface from k8s.io/apimachinery/pkg/watch looks like this:
// Interface can be implemented by anything that knows how to watch and// report changes.typeInterfaceinterface{// Stops watching. Will close the channel returned by ResultChan(). Releases// any resources used by the watch.Stop()// Returns a chan which will receive all the events. If an error occurs// or Stop() is called, this channel will be closed, in which case the// watch should be completely cleaned up.ResultChan()<-chanEvent}
The result channel of the watch interface returns three kinds of events:
// EventType defines the possible types of events.typeEventTypestringconst(AddedEventType="ADDED"ModifiedEventType="MODIFIED"DeletedEventType="DELETED"ErrorEventType="ERROR")// Event represents a single event to a watched resource.// +k8s:deepcopy-gen=truetypeEventstruct{TypeEventType// Object is:// * If Type is Added or Modified: the new state of the object.// * If Type is Deleted: the state of the object immediately before// deletion.// * If Type is Error: *api.Status is recommended; other types may// make sense depending on context.Objectruntime.Object}
While it is tempting to use this interface directly, in practice it is actually discouraged in favor of informers (see “Informers and Caching”). Informers are a combination of this event interface and an in-memory cache with indexed lookup. This is by far the most common use case for watches. Under the hood informers first call List on the client to get the set of all objects (as a baseline for the cache) and then Watch to update the cache. They handle error conditions correctly—that is, recover from network issues or other cluster problems.
Client Expansion
DeploymentExpansion is actually an empty interface. It is used to add custom client behavior, but it’s hardly used in Kubernetes nowadays. Instead, the client generator allows us to add custom methods in a declarative way (see “client-gen Tags”).
Note again that all of those methods in DeploymentInterface neither expect valid information in the TypeMeta fields Kind and APIVersion, nor set those fields on Get() and List() (see also “TypeMeta”). These fields are filled with real values only on the wire.
Client Options
It is worth looking at the different options we can set when creating a client set. In the note before “Versioning and Compatibility”, we saw that we can switch to the protobuf wire format for native Kubernetes types. Protobuf is more efficient than JSON (both spacewise and for the CPU load of the client and server) and therefore preferable.
For debugging purposes and readability of metrics, it is often helpful to differentiate between different clients accessing the API server. To do so, we can set the user agent field in the REST config. The default value is binary/version (os/arch) kubernetes/commit; for example, kubectl will use a user agent like kubectl/v1.14.0 (darwin/amd64) kubernetes/d654b49. If that pattern does not suffice for the setup, it can be customized like so:
cfg,err:=clientcmd.BuildConfigFromFlags("",*kubeconfig)cfg.AcceptContentTypes="application/vnd.kubernetes.protobuf,application/json"cfg.UserAgent=fmt.Sprintf("book-example/v1.0 (%s/%s) kubernetes/v1.0",runtime.GOOS,runtime.GOARCH)clientset,err:=kubernetes.NewForConfig(cfg)
Other values often overridden in the REST config are those for client-side rate limiting and timeouts:
// Config holds the common attributes that can be passed to a Kubernetes// client on initialization.typeConfigstruct{...// QPS indicates the maximum QPS to the master from this client.// If it's zero, the created RESTClient will use DefaultQPS: 5QPSfloat32// Maximum burst for throttle.// If it's zero, the created RESTClient will use DefaultBurst: 10.Burstint// The maximum length of time to wait before giving up on a server request.// A value of zero means no timeout.Timeouttime.Duration...}
The QPS value defaults to 5 requests per second, with a burst of 10.
The timeout has no default value, at least not in the client REST config. By default the Kubernetes API server will timeout every request that is not a long-running request after 60 seconds. A long-running request can be a watch request or unbounded requests to subresources like /exec, /portforward, or /proxy.
Informers and Caching
The client interface in “Client Sets” includes the Watch verb, which offers an event interface that reacts to changes (adds, removes, updates) of objects. Informers give a higher-level programming interface for the most common use case for watches: in-memory caching and fast, indexed lookup of objects by name or other properties in-memory.
A controller that accesses the API server every time it needs an object creates a high load on the system. In-memory caching using informers is the solution to this problem. Moreover, informers can react to changes of objects nearly in real-time instead of requiring polling requests.
Figure 3-5 shows the conceptional pattern of informers; specifically, they:
-
Get input from the API server as events.
-
Offer a client-like interface called
Listerto get and list objects from the in-memory cache. -
Register event handlers for adds, removes, and updates.
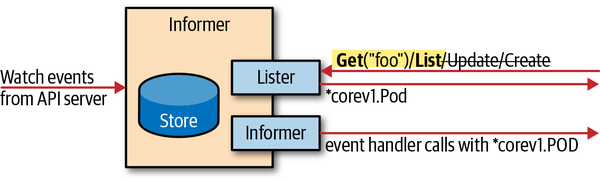
Figure 3-5. Informers
Informers also have advanced error behavior: when the long-running watch connection breaks down, they recover from it by trying another watch request, picking up the event stream without losing any events. If the outage is long, and the API server lost events because etcd purged them from its database before the new watch request was successful, the informer will relist all objects.
Next to relists, there is a configurable resync period for reconciliation between the in-memory cache and the business logic: the registered event handlers will be called for all objects each time this period has passed. Common values are in minutes (e.g., 10 or 30 minutes).
Warning
The resync is purely in-memory and does not trigger a call to the server. This used to be different but was eventually changed because the error behavior of the watch mechanism had been improved enough to make relists unnecessary.
All this advanced and battle-proven error behavior is a good reason for using informers instead of rolling out custom logic using the client Watch() method directly. Informers are used everywhere in Kubernetes itself and are one of the main architectural concepts in the Kubernetes API design.
While informers are preferred over polling, they create load on the API server. One binary should instantiate only one informer per GroupVersionResource. To make sharing of informers easy, we can instantiate an informer by using the shared informer factory.
The shared informer factory allows informers to be shared for the same resource in an application. In other words, different control loops can use the same watch connection to the API server under the hood. For example, the kube-controller-manager, one of the main Kubernetes cluster components (see “The API Server”), has a larger, two-digit number of controllers. But for each resource (e.g., pods), there is only one informer in the process.
Tip
Always use a shared informer factory to instantiate informers. Don’t try to instantiate informers manually. The overhead is minimal, and a nontrivial controller binary that does not use shared informers probably is opening multiple watch connections for the same resource somewhere.
Starting with a REST config (see “Creating and Using a Client”), it is easy to create a shared informer factory using a client set. The informers are generated by a code generator and shipped as part of client-go for the standard Kubernetes resources in k8s.io/client-go/informers:
import(..."k8s.io/client-go/informers")...clientset,err:=kubernetes.NewForConfig(config)informerFactory:=informers.NewSharedInformerFactory(clientset,time.Second*30)podInformer:=informerFactory.Core().V1().Pods()podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc:func(newinterface{}){...},UpdateFunc:func(old,newinterface{}){...},DeleteFunc:func(objinterface{}){...},})informerFactory.Start(wait.NeverStop)informerFactory.WaitForCacheSync(wait.NeverStop)pod,err:=podInformer.Lister().Pods("programming-kubernetes").Get("client-go")
The example shows how to get a shared informer for pods.
You can see that informers allow for the addition of event handlers for the three cases add, update, and delete. These are usually used to trigger the business logic of a controller—that is, to process a certain object again (see “Controllers and Operators”). Often those handlers just add the modified object into a work queue.
Also note that many event handlers can be added. The whole shared informer factory concept exists only because this is so common in controller binaries with many control loops, each installing event handlers to add objects to their own work queue.
After registering handlers, the shared informer factory has to be started. There are Go routines under the hood that do the actual calls to the API server. The Start method (with a stop channel to control the lifecycle) starts these Go routines, and the WaitForCacheSync() method makes the code wait for the first List calls to the clients to finish. If the controller logic requires that the cache is filled, this WaitForCacheSync call is essential.
In general, the event interface of the watches behind the scenes leads to a certain lag. In a setup with proper capacity planning, this lag is not huge. Of course, it is good practice to measure this lag using metrics. But the lag exists regardless, so the application logic has be built in such a way that the lag does not harm the behavior of the code.
Warning
The lag of informers can lead to races between changes the controller makes with client-go directly on the API server, and the state of the world as known by the informers.
If the controller changes an object, the informer in the same process has to wait until the corresponding event arrives and the in-memory store is then updated. This process is not instantaneous, and another controller work loop run might be started through another trigger before the previous change has become visible.
The resync interval of 30 seconds in this example leads to a complete set of events being sent to the registered UpdateFunc such that the controller logic is able to reconcile its state with that of the API server. By comparing the ObjectMeta.resourceVersion field, it is possible to distinguish a real update from a resync.
Tip
Choosing a good resync interval depends on the context. For example, 30 seconds is pretty short. In many situations several minutes, or even 30 minutes, is a good choice. In the worst case, 30 minutes means that it takes 30 minutes until a bug in the code (e.g., a lost signal due to bad error handling) is repaired via reconciliation.
Also note that the final line in the example calling Get("client-go") is purely in-memory; there is no access to the API server. Objects in the in-memory store cannot be modified directly. Instead, the client set must be used for any write access to the resources. The informer will then get events from the API server and update its in-memory store.
The informer constructor NewSharedInformerFactory in the example caches all objects of a resource in all namespaces in the store. If this is too much for the application, there is an alternative constructor with more flexibility:
// NewFilteredSharedInformerFactory constructs a new instance of// sharedInformerFactory. Listers obtained via this sharedInformerFactory will be// subject to the same filters as specified here.funcNewFilteredSharedInformerFactory(clientversioned.Interface,defaultResynctime.Duration,namespacestring,tweakListOptionsinternalinterfaces.TweakListOptionsFunc)SharedInformerFactortypeTweakListOptionsFuncfunc(*v1.ListOptions)
It allows us to specify a namespace and to pass a TweakListOptionsFunc, which may mutate the ListOptions struct used to list and watch objects using the List and Watch calls of the client. It can be used to set label or field selectors, for example.
Informers are one of the building blocks of controllers. In Chapter 6 we will see what a typical client-go-based controller looks like. After the clients and informers, the third main building block is the work queue. Let’s look at it now.
Work Queue
A work queue is a data structure. You can add elements and take elements out of the queue, in an order predefined by the queue. Formally, this kind of queue is called a priority queue. client-go provides a powerful implementation for the purpose of building controllers in k8s.io/client-go/util/workqueue.
More precisely, the package contains a number of variants for different purposes. The base interface implemented by all variants looks like this:
typeInterfaceinterface{Add(iteminterface{})Len()intGet()(iteminterface{},shutdownbool)Done(iteminterface{})ShutDown()ShuttingDown()bool}
Here Add(item) adds an item, Len() gives the length, and Get() returns an item with the highest priority (and it blocks until one is available). Every item returned by Get() needs a Done(item) call when the controller has finished processing it. Meanwhile, a repeated Add(item) will only mark the item as dirty such that it is readded when Done(item) has been called.
The following queue types are derived from this generic interface:
-
DelayingInterfacecan add an item at a later time. This makes it easier to requeue items after failures without ending up in a hot-loop:typeDelayingInterfaceinterface{Interface// AddAfter adds an item to the workqueue after the// indicated duration has passed.AddAfter(iteminterface{},durationtime.Duration)} -
RateLimitingInterfacerate-limits items being added to the queue. It extends theDelayingInterface:typeRateLimitingInterfaceinterface{DelayingInterface// AddRateLimited adds an item to the workqueue after the rate// limiter says it's OK.AddRateLimited(iteminterface{})// Forget indicates that an item is finished being retried.// It doesn't matter whether it's for perm failing or success;// we'll stop the rate limiter from tracking it. This only clears// the `rateLimiter`; you still have to call `Done` on the queue.Forget(iteminterface{})// NumRequeues returns back how many times the item was requeued.NumRequeues(iteminterface{})int}Most interesting here is the
Forget(item)method: it resets the back-off of the given item. Usually, it will be called when an item has been processed successfully.The rate limiting algorithm can be passed to the constructor
NewRateLimitingQueue. There are several rate limiters defined in the same package, such as theBucketRateLimiter, theItemExponentialFailureRateLimiter, theItemFastSlowRateLimiter, and theMaxOfRateLimiter. For more details, you can refer to the package documentation. Most controllers will just use theDefaultControllerRateLimiter() *RateLimiterfunctions, which gives:-
An exponential back-off starting at 5 ms and going up to 1,000 seconds, doubling the delay on each error
-
A maximal rate of 10 items per second and 100 items burst
-
Depending on the context, you might want to customize the values. A 1,000 seconds maximal back-off per item is a lot for certain controller applications.
API Machinery in Depth
The API Machinery repository implements the basics of the Kubernetes type system. But what is this type system exactly? What is a type to begin with?
The term type actually does not exist in the terminology of API Machinery. Instead, it refers to kinds.
Kinds
Kinds are divided into API groups and are versioned, as we already have seen in “API Terminology”. Therefore, a core term in the API Machinery repository is GroupVersionKind, or GVK for short.
In Go, each GVK corresponds to one Go type. In contrast, a Go type can belong to multiple GVKs.
Kinds do not formally map one-to-one to HTTP paths. Many kinds have HTTP REST endpoints that are used to access objects of the given kind. But there are also kinds without any HTTP endpoint (e.g., admission.k8s.io/v1beta1.AdmissionReview, which is used to call out to a webhook). There are also kinds that are returned from many endpoints—for example, meta.k8s.io/v1.Status, which is returned by all endpoints to report a nonobject status like an error.
By convention, kinds are formatted in CamelCase like words and are usually singular. Depending on the context, their concrete format differs. For CustomResourceDefinition kinds, it must be a DNS path label (RFC 1035).
Resources
In parallel to kinds, as we saw in “API Terminology”, there is the concept of a resource. Resources are again grouped and versioned, leading to the term GroupVersionResource, or GVR for short.
Each GVR corresponds to one HTTP (base) path. GVRs are used to identify REST endpoints of the Kubernetes API. For example, the GVR apps/v1.deployments maps to /apis/apps/v1/namespaces/namespace/deployments.
Client libraries use this mapping to construct the HTTP path to access a GVR.
By convention, resources are lowercase and plural, usually corresponding to the plural words of the parallel kind. They must conform to the DNS path label format (RFC 1025). As resources map directly to HTTP paths, this is not surprising.
REST Mapping
The mapping of a GVK to a GVR is called REST mapping.
A RESTMapper is the Golang interface that enables us to request the GVR for a GVK:
RESTMapping(gkschema.GroupKind,versions...string)(*RESTMapping,error)
where the type RESTMapping on the right looks like this:
typeRESTMappingstruct{// Resource is the GroupVersionResource (location) for this endpoint.Resourceschema.GroupVersionResource.// GroupVersionKind is the GroupVersionKind (data format) to submit// to this endpoint.GroupVersionKindschema.GroupVersionKind// Scope contains the information needed to deal with REST Resources// that are in a resource hierarchy.ScopeRESTScope}
In addition, a RESTMapper provides a number of convenience functions:
// KindFor takes a partial resource and returns the single match.// Returns an error if there are multiple matches.KindFor(resourceschema.GroupVersionResource)(schema.GroupVersionKind,error)// KindsFor takes a partial resource and returns the list of potential// kinds in priority order.KindsFor(resourceschema.GroupVersionResource)([]schema.GroupVersionKind,error)// ResourceFor takes a partial resource and returns the single match.// Returns an error if there are multiple matches.ResourceFor(inputschema.GroupVersionResource)(schema.GroupVersionResource,error)// ResourcesFor takes a partial resource and returns the list of potential// resource in priority order.ResourcesFor(inputschema.GroupVersionResource)([]schema.GroupVersionResource,error)// RESTMappings returns all resource mappings for the provided group kind// if no version search is provided. Otherwise identifies a preferred resource// mapping for the provided version(s).RESTMappings(gkschema.GroupKind,versions...string)([]*RESTMapping,error)
Here, a partial GVR means that not all fields are set. For example, imagine you type kubectl get pods. In that case, the group and the version are missing. A RESTMapper with enough information might still manage to map it to the v1 Pods kind.
For the preceding deployment example, a RESTMapper that knows about deployments (more about what this means in a bit) will map apps/v1.Deployment to apps/v1.deployments as a namespaced resource.
There are multiple different implementations of the RESTMapper interface. The most important one for client applications is the discovery-based DeferredDiscoveryRESTMapper in the package k8s.io/client-go/restmapper: it uses discovery information from the Kubernetes API server to dynamically build up the REST mapping. It will also work with non-core resources like custom resources.
Scheme
The final core concept we want to present here in the context of the Kubernetes type system is the scheme in the package k8s.io/apimachinery/pkg/runtime.
A scheme connects the world of Golang with the implementation-independent world of GVKs. The main feature of a scheme is the mapping of Golang types to possible GVKs:
func(s*Scheme)ObjectKinds(objObject)([]schema.GroupVersionKind,bool,error)
As we saw in “Kubernetes Objects in Go”, an object can return its group and kind via the GetObjectKind() schema.ObjectKind method. However, these values are empty most of the time and are therefore pretty useless for identification.
Instead, the scheme takes the Golang type of the given object via reflection and maps it to the registered GVK(s) of that Golang type. For that to work, of course, the Golang types have to be registered into the scheme like this:
scheme.AddKnownTypes(schema.GroupVersionKind{"","v1","Pod"},&Pod{})
The scheme is used not only to register the Golang types and their GVK, but also to store a list of conversion functions and defaulters (see Figure 3-6). We’ll discuss conversions and defaulters in more detail in Chapter 8. It is the data source to implement encoders and decoders as well.
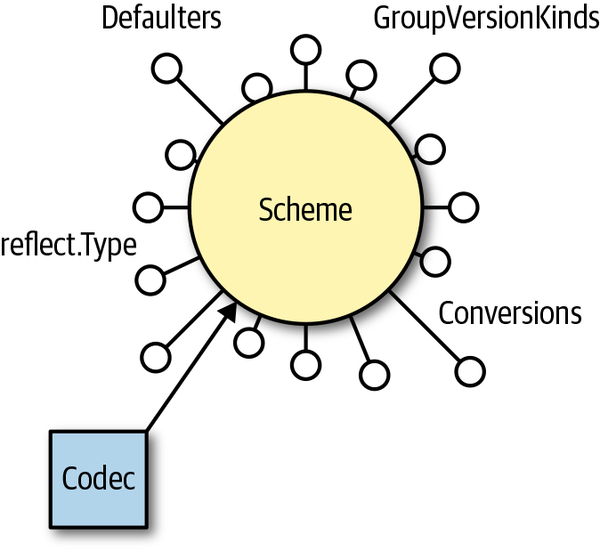
Figure 3-6. The scheme, connecting Golang data types with the GVK, conversions, and defaulters
For Kubernetes core types there is a predefined scheme in the client-go client set in the package k8s.io/client-go/kubernetes/scheme, with all the types preregistered. Actually, every client set generated by the client-gen code generator (see Chapter 5) has the subpackage scheme with all types in all groups and versions in the client set.
With the scheme we conclude our deep dive into API Machinery concepts. If you only remember one thing about these concepts, let it be Figure 3-7.

Figure 3-7. From Golang types to GVKs to GVRs to an HTTP path—API Machinery in a nutshell
Vendoring
We have seen in this chapter that k8s.io/client-go, k8s.io/api, and k8s.io/apimachinery are central to Kubernetes programming in Golang. Golang uses vendoring to include these libraries in a third-party application source code repository.
Vendoring is a moving target in the Golang community. At the time of this writing, several vendoring tools are common, such as godeps, dep, and glide. At the same time, Go 1.12 is getting support for Go modules, which will probably become the standard vendoring method in the Go community in the future, but is not ready in the Kubernetes ecosystem at this time.
Most projects nowadays use either dep or glide. Kubernetes itself in github.com/kubernetes/kubernetes made the jump to Go modules for the 1.15 development cycle. The following comments are relevant for all of these vendoring tools.
The source of truth for supported dependency versions in each of the k8s.io/* repositories is the shipped Godeps/Godeps.json file. It is important to stress that any other dependency selection can break the functionality of the library.
See “The Client Library” for more on the published tags of k8s.io/client-go, k8s.io/api, and k8s.io/apimachinery and which tags are compatible with each other.
glide
Projects using glide can use its ability to read the Godeps/Godeps.json file on any dependency change. This has proven to work pretty reliably: the developer has only to declare the right k8s.io/client-go version, and glide will select the right version of k8s.io/apimachinery, k8s.io/api, and other dependencies.
For some projects on GitHub, the glide.yaml file might look like this:
package:github.com/book/exampleimport:-package:k8s.io/client-goversion:v10.0.0...
With that, glide install -v will download k8s.io/client-go and its dependencies into the local vendor/ package. Here, -v means to drop vendor/ packages from vendored libraries. This is required for our purposes.
If you update to a new version of client-go by editing glide.yaml, glide update -v will download the new dependencies, again in the right versions.
dep
dep is often considered more powerful and advanced than glide. For a long time it was seen as the successor to glide in the ecosystem and seemed destined to be the Go vendoring tool. At the time of this writing, its future is not clear, and Go modules seem to be the path forward.
In the context of client-go, it is very important to be aware of a couple of restrictions of dep:
-
depdoes read Godeps/Godeps.json on the first run ofdep init. -
depdoes not read Godeps/Godeps.json on laterdep ensure -updatecalls.
This means that the resolution for dependencies of client-go is most probably wrong when the client-go version is updated in Godep.toml. This is unfortunate, because it requires the developer to explicitly and usually manually declare all dependencies.
A working and consistent Godep.toml file looks like this:
[[constraint]]name = "k8s.io/api"version = "kubernetes-1.13.0"[[constraint]]name = "k8s.io/apimachinery"version = "kubernetes-1.13.0"[[constraint]]name = "k8s.io/client-go"version = "10.0.0"[prune]go-tests = trueunused-packages = true# the following overrides are necessary to enforce# the given version, even though our# code does not import the packages directly.[[override]]name = "k8s.io/api"version = "kubernetes-1.13.0"[[override]]name = "k8s.io/apimachinery"version = "kubernetes-1.13.0"[[override]]name = "k8s.io/client-go"version = "10.0.0"
Warning
Not only does Gopkg.toml declare explicit versions for both k8s.io/apimachinery and k8s.io/api, it also has overrides for them. This is necessary for when the project is started without explicit imports of packages from those two repositories. In that case, without these overrides dep would ignore the constraints in the beginning, and the developer would get wrong dependencies from the beginning.
Even the Gopkg.toml file shown here is technically not correct because it is incomplete, as it does not declare dependencies on all other libraries required by client-go. In the past, an upstream library broke compilation of client-go. So be prepared for this to happen if you use dep for dependency management.
Go Modules
Go modules are the future of dependency management in Golang. They were introduced in Go 1.11 with preliminary support and were further stabilized in 1.12. A number of commands, like go run and go get, work with Go modules by setting the GO111MODULE=on environment variable. In Go 1.13 this will be the default setting.
Go modules are driven by a go.mod file in the root of a project. Here is an excerpt of the go.mod file for our github.com/programming-kubernetes/pizza-apiserver project in Chapter 8:
module github.com/programming-kubernetes/pizza-apiserver
require (
...
k8s.io/api v0.0.0-20190222213804-5cb15d344471 // indirect
k8s.io/apimachinery v0.0.0-20190221213512-86fb29eff628
k8s.io/apiserver v0.0.0-20190319190228-a4358799e4fe
k8s.io/client-go v2.0.0-alpha.0.0.20190307161346-7621a5ebb88b+incompatible
k8s.io/klog v0.2.1-0.20190311220638-291f19f84ceb
k8s.io/kube-openapi v0.0.0-20190320154901-c59034cc13d5 // indirect
k8s.io/utils v0.0.0-20190308190857-21c4ce38f2a7 // indirect
sigs.k8s.io/yaml v1.1.0 // indirect
)
client-go v11.0.0—matching Kubernetes 1.14—and older versions do not have explicit support for Go modules. Still, it is possible to use Go modules with the Kubernetes libraries, as you see in the preceding example.
As long as client-go and the other Kubernetes repositories do not ship a go.mod file, though (at least until Kubernetes 1.15), the right versions must be selected manually. That is, you’ll need a complete list of all dependencies matching the revisions of dependencies of the Godeps/Godeps.json in client-go.
Also note the not-very-readable revisions in the previous example. They are pseudo-versions derived from existing tags, or using v0.0.0 as the prefix if there are no tags. Even worse, you can reference tagged versions in that file, but the Go module commands will replace those on the next run with the pseudo-versions.
With client-go v12.0.0—matching Kubernetes 1.15—we ship a go.mod file and deprecate support for all other vendoring tools (see the corresponding proposal document). The shipped go.mod file includes all dependencies, and your project go.mod file no longer has to list all transitive dependencies manually. In later releases, it’s also possible that the tagging scheme will be changed to fix the ugly pseudo-revisions and replace them with proper semver tags. But at the time of this writing, this is still not fully implemented or decided.
Summary
In this chapter our focus was on the Kubernetes programming interface in Go. We discussed accessing the Kubernetes API of well-known core types—that is, the API objects that are shipped with every Kubernetes cluster.
With this we’ve covered the basics of the Kubernetes API and its representation in Go. Now we’re ready to move on to the topic of custom resources, one of the pillars of operators.
1 See “API Terminology”.
2 kubectl explain pod lets you query the API server for the schema of an object, including field documentation.