
Chapter 2. Kubernetes API Basics
In this chapter we walk you through the Kubernetes API basics. This includes a deep dive into the API server’s inner workings, the API itself, and how you can interact with the API from the command line. We will introduce you to Kubernetes API concepts such as resources and kinds, as well as grouping and versioning.
The API Server
Kubernetes is made up of a bunch of nodes (machines in the cluster) with different roles, as shown in Figure 2-1: the control plane on the master node(s) consists of the API server, controller manager, and scheduler. The API server is the central management entity and the only component that talks directly with the distributed storage component etcd.
The API server has the following core responsibilities:
-
To serve the Kubernetes API. This API is used cluster-internally by the master components, the worker nodes, and your Kubernetes-native apps, as well as externally by clients such as
kubectl. -
To proxy cluster components, such as the Kubernetes dashboard, or to stream logs, service ports, or serve
kubectl execsessions.
Serving the API means:
-
Reading state: getting single objects, listing them, and streaming changes
-
Manipulating state: creating, updating, and deleting objects
State is persisted via etcd.
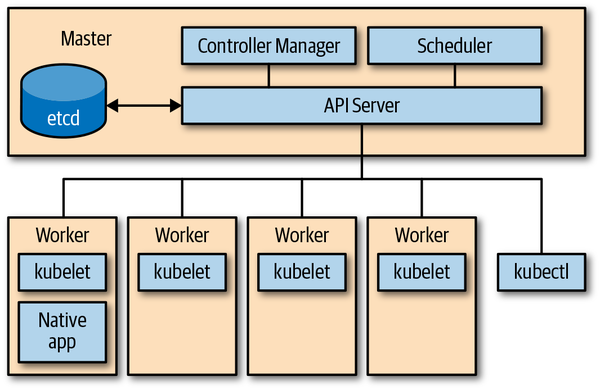
Figure 2-1. Kubernetes architecture overview
The heart of Kubernetes is its API server. But how does the API server work? We’ll first treat the API server as a black box and take a closer look at its HTTP interface, then we’ll move on to the inner workings of the API server.
The HTTP Interface of the API Server
From a client’s perspective, the API server exposes a RESTful HTTP API with JSON or protocol buffer (protobuf for short) payload, which is used mainly for cluster-internal communication, for performance reasons.
The API server HTTP interface handles HTTP requests to query and manipulate Kubernetes resources using the following HTTP verbs (or HTTP methods):
-
The HTTP
GETverb is used for retrieving the data with a specific resource (such as a certain pod) or a collection or list of resources (for example, all pods in a namespace). -
The HTTP
POSTverb is used for creating a resource, such as a service or a deployment. -
The HTTP
PUTverb is used for updating an existing resource—for example, changing the container image of a pod. -
The HTTP
PATCHverb is used for partial updates of existing resources. Read “Use a JSON merge patch to update a Deployment” in the Kubernetes documentation to learn more about the available strategies and implications here. -
The HTTP
DELETEverb is used for destroying a resource in a nonrecoverable manner.
If you look at, say, the Kubernetes 1.14 API reference, you can see the different HTTP verbs in action. For example, to list pods in the current namespace with the CLI command equivalent of kubectl -n THENAMESPACE get pods, you would issue GET /api/v1/namespaces/THENAMESPACE/pods (see Figure 2-2).

Figure 2-2. API server HTTP interface in action: listing pods in a given namespace
For an introduction on how the API server HTTP interface is invoked from a Go program, see “The Client Library”.
API Terminology
Before we get into the API business, let’s first define the terms used in the context of the Kubernetes API server:
- Kind
-
The type of an entity. Each object has a field
Kind(lowercasekindin JSON, capitalizedKindin Golang), which tells a client such askubectlthat it represents, for example, a pod. There are three categories of kinds:-
Objects represent a persistent entity in the system—for example,
PodorEndpoints. Objects have names, and many of them live in namespaces. -
Lists are collections of one or more kinds of entities. Lists have a limited set of common metadata. Examples include
PodLists orNodeLists. When you do akubectl get pods, that’s exactly what you get. -
Special-purpose kinds are used for specific actions on objects and for nonpersistent entities such as
/bindingor/scale. For discovery, Kubernetes usesAPIGroupandAPIResource; for error results, it usesStatus.
-
In Kubernetes programs, a kind directly corresponds with a Golang type. Thus, as Golang types, kinds are singular and begin with a capital letter.
- API group
-
A collection of
Kinds that are logically related. For example, all batch objects likeJoborScheduledJobare in the batch API group. - Version
-
Each API group can exist in multiple versions, and most of them do. For example, a group first appears as
v1alpha1and is then promoted tov1beta1and finally graduates tov1. An object created in one version (e.g.,v1beta1) can be retrieved in each of the supported versions. The API server does lossless conversion to return objects in the requested version. From the cluster user’s point of view, versions are just different representations of the same objects.
Tip
There is no such thing as “one object is in v1 in the cluster, and another object is in v1beta1 in the cluster.” Instead, every object can be returned as a v1 representation or in the v1beta1 representation, as the cluster user desires.
- Resource
-
A usually lowercase, plural word (e.g.,
pods) identifying a set of HTTP endpoints (paths) exposing the CRUD (create, read, update, delete) semantics of a certain object type in the system. Common paths are:-
The root, such as …/pods, which lists all instances of that type
-
A path for individual named resources, such as …/pods/nginx
Typically, each of these endpoints returns and receives one kind (a
PodListin the first case, and aPodin the second). But in other situations (e.g., in case of errors), aStatuskind object is returned.In addition to the main resource with full CRUD semantics, a resource can have further endpoints to perform specific actions (e.g., …/pod/nginx/port-forward, …/pod/nginx/exec, or …/pod/nginx/logs). We call these subresources (see “Subresources”). These usually implement custom protocols instead of REST—for example, some kind of streaming connection via WebSockets or imperative APIs.
-
Tip
Resources and kinds are often mixed up. Note the clear distinction:
-
Resources correspond to HTTP paths.
-
Kinds are the types of objects returned by and received by these endpoints, as well as persisted into
etcd.
Resources are always part of an API group and a version, collectively referred to as GroupVersionResource (or GVR). A GVR uniquely defines an HTTP path. A concrete path, for example, in the default namespace would be /apis/batch/v1/namespaces/default/jobs. Figure 2-3 shows an example GVR for a namespaced resource, a Job.

Figure 2-3. Kubernetes API—GroupVersionResource (GVR)
In contrast to the jobs GVR example, cluster-wide resources such as nodes or namespaces themselves do not have the $NAMESPACE part in the path. For example, a nodes GVR example might look as follows: /api/v1/nodes. Note that namespaces show up in other resources’ HTTP paths but are also a resource themselves, accessible at /api/v1/namespaces.
Similarly to GVRs, each kind lives in an API group, is versioned, and is identified via a GroupVersionKind (GVK).
GVKs and GVRs are related. GVKs are served under HTTP paths identified by GVRs. The process of mapping a GVK to a GVR is called REST mapping. We will see RESTMappers that implement REST mapping in Golang in “REST Mapping”.
From a global point of view, the API resource space logically forms a tree with top-level nodes including /api, /apis, and some nonhierarchical endpoints such as /healthz or /metrics. An example rendering of this API space is shown in Figure 2-4. Note that the exact shape and paths depend on the Kubernetes version, with an increasing tendency to stabilize over the years.

Figure 2-4. An example Kubernetes API space
Kubernetes API Versioning
For extensibility reasons, Kubernetes supports multiple API versions at different API paths, such as /api/v1 or /apis/extensions/v1beta1. Different API versions imply different levels of stability and support:
-
Alpha level (e.g.,
v1alpha1) is usually disabled by default; support for a feature may be dropped at any time without notice and should be used only in short-lived testing clusters. -
Beta level (e.g.,
v2beta3) is enabled by default, meaning that the code is well tested; however, the semantics of objects may change in incompatible ways in a subsequent beta or stable release. -
Stable (generally available, or GA) level (e.g.,
v1) will appear in released software for many subsequent versions.
Let’s look at how the HTTP API space is constructed: at the top level we distinguish between the core group—that is, everything below /api/v1—and the named groups in paths of the form /apis/$NAME/$VERSION.
Note
The core group is located under /api/v1 and not, as one would expect, under /apis/core/v1, for historic reasons. The core group existed before the concept of an API group was introduced.
There is a third type of HTTP paths—ones that are not resource aligned—that the API server exposes: cluster-wide entities such as /metrics, /logs, or /healthz. In addition, the API server supports watches; that is, rather than polling resources at set intervals, you can add a ?watch=true to certain requests and the API server changes into a watch modus.
Declarative State Management
Most API objects make a distinction between the specification of the desired state of the resource and the status of the object at the current time. A specification, or spec for short, is a complete description of the desired state of a resource and is typically persisted in stable storage, usually etcd.
Note
Why do we say “usually etcd“? Well, there are Kubernetes distros and offerings, such as k3s or Microsoft’s AKS, that have replaced or are working on replacing etcd with something else. Thanks to the modular architecture of the Kubernetes control plane, this works just fine.
Let’s talk a little more about spec (desired state) versus status (observed state) in the context of the API server.
The spec describes your desired state for the resource, something you need to provide via a command-line tool such as kubectl or programmatically via your Go code. The status describes the observed or actual state of the resource and is managed by the control plane, either by core components such as the controller manager or by your own custom controller (see “Controllers and Operators”). For example, in a deployment you might specify that you want 20 replicas of the application to be running at all times. The deployment controller, part of the controller manager in the control plane, reads the deployment spec you provided and creates a replica set, which then takes care of managing the replicas: it creates the respective number of pods, which eventually (via the kubelet) results in containers being launched on worker nodes. If any replica fails, the deployment controller would make this known to you in the status. This is what we call declarative state management—that is, declaring the desired state and letting Kubernetes take care of the rest.
We will see declarative state management in action in the next section, as we start to explore the API from the command line.
Using the API from the Command Line
In this section we’ll be using kubectl and curl to demonstrate the use of the Kubernetes API. If you’re not familiar with these CLI tools, now is a good time to install them and try them out.
For starters, let’s have a look at the desired and observed state of a resource. We will be using a control plane component that is likely available in every cluster, the CoreDNS plug-in (old Kubernetes versions were using kube-dns instead) in the kube-system namespace (this output is heavily edited to highlight the important parts):
$kubectl -n kube-system get deploy/coredns -o=yaml apiVersion: apps/v1 kind: Deployment metadata: name: coredns namespace: kube-system ... spec: template: spec: containers: - name: coredns image: 602401143452.dkr.ecr.us-east-2.amazonaws.com/eks/coredns:v1.2.2 ... status: replicas: 2 conditions: -type: Available status:"True"lastUpdateTime:"2019-04-01T16:42:10Z"...
As you can see from this kubectl command, in the spec section of the deployment you’d define characteristics such as which container image to use and how many replicas you want to run in parallel, and in the status section you’d learn how many replicas at the current point in time are actually running.
To carry out CLI-related operations, we will, for the remainder of this chapter, be using batch operations as the running example. Let’s start by executing the following command in a terminal:
$kubectl proxy --port=8080 Starting to serve on 127.0.0.1:8080
This command proxies the Kubernetes API to our local machine and also takes care of the authentication and authorization bits. It allows us to directly issue requests via HTTP and receive JSON payloads in return. Let’s do that by launching a second terminal session where we query v1:
$curl http://127.0.0.1:8080/apis/batch/v1{"kind":"APIResourceList","apiVersion":"v1","groupVersion":"batch/v1","resources":[{"name":"jobs","singularName":"","namespaced":true,"kind":"Job","verbs":["create","delete","deletecollection","get","list","patch","update","watch"],"categories":["all"]},{"name":"jobs/status","singularName":"","namespaced":true,"kind":"Job","verbs":["get","patch","update"]}]}
Tip
You don’t have to use curl along with the kubectl proxy command to get direct HTTP API access to the Kubernetes API. You can instead use the kubectl get --raw command: for example, replace curl http://127.0.0.1:8080/apis/batch/v1 with kubectl get --raw /apis/batch/v1.
Compare this with the v1beta1 version, noting that you can get a list of supported versions for the batch API group when looking at http://127.0.0.1:8080/apis/batch v1beta1:
$curl http://127.0.0.1:8080/apis/batch/v1beta1{"kind":"APIResourceList","apiVersion":"v1","groupVersion":"batch/v1beta1","resources":[{"name":"cronjobs","singularName":"","namespaced":true,"kind":"CronJob","verbs":["create","delete","deletecollection","get","list","patch","update","watch"],"shortNames":["cj"],"categories":["all"]},{"name":"cronjobs/status","singularName":"","namespaced":true,"kind":"CronJob","verbs":["get","patch","update"]}]}
As you can see, the v1beta1 version also contains the cronjobs resource with the kind CronJob. At the time of this writing, cron jobs have not been promoted to v1.
If you want to get an idea of what API resources are supported in your cluster, including their kinds, whether or not they are namespaced, and their short names (primarily for kubectl on the command line), you can use the following command:
$kubectl api-resources NAME SHORTNAMES APIGROUP NAMESPACED KIND bindingstrueBinding componentstatuses csfalseComponentStatus configmaps cmtrueConfigMap endpoints eptrueEndpoints events evtrueEvent limitranges limitstrueLimitRange namespaces nsfalseNamespace nodes nofalseNode persistentvolumeclaims pvctruePersistentVolumeClaim persistentvolumes pvfalsePersistentVolume pods potruePod podtemplatestruePodTemplate replicationcontrollers rctrueReplicationController resourcequotas quotatrueResourceQuota secretstrueSecret serviceaccounts satrueServiceAccount services svctrueService controllerrevisions appstrueControllerRevision daemonsets ds appstrueDaemonSet deployments deploy appstrueDeployment ...
The following is a related command that can be very useful to determine the different resource versions supported in your cluster:
$ kubectl api-versions
admissionregistration.k8s.io/v1beta1
apiextensions.k8s.io/v1beta1
apiregistration.k8s.io/v1
apiregistration.k8s.io/v1beta1
appmesh.k8s.aws/v1alpha1
appmesh.k8s.aws/v1beta1
apps/v1
apps/v1beta1
apps/v1beta2
authentication.k8s.io/v1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1
authorization.k8s.io/v1beta1
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
batch/v1
batch/v1beta1
certificates.k8s.io/v1beta1
coordination.k8s.io/v1beta1
crd.k8s.amazonaws.com/v1alpha1
events.k8s.io/v1beta1
extensions/v1beta1
networking.k8s.io/v1
policy/v1beta1
rbac.authorization.k8s.io/v1
rbac.authorization.k8s.io/v1beta1
scheduling.k8s.io/v1beta1
storage.k8s.io/v1
storage.k8s.io/v1beta1
v1How the API Server Processes Requests
Now that you have an understanding of the external-facing HTTP interface, let’s focus on the inner workings of the API server. Figure 2-5 shows a high-level overview of the request processing in the API server.
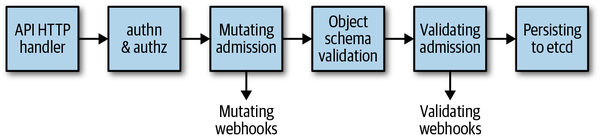
Figure 2-5. Kubernetes API server request processing overview
So, what actually happens now when an HTTP request hits the Kubernetes API? On a high level, the following interactions take place:
-
The HTTP request is processed by a chain of filters registered in
DefaultBuildHandlerChain(). This chain is defined in k8s.io/apiserver/pkg/server/config.go and discussed in detail shortly. It applies a series of filter operations on said request. Either the filter passes and attaches respective information to the context—to be precise,ctx.RequestInfo, withctxbeing the context in Go (e.g., the authenticated user)—or, if a request does not pass a filter, it returns an appropriate HTTP response code stating the reason (e.g., a401response if the user authentication failed). -
Next, depending on the HTTP path, the multiplexer in k8s.io/apiserver/pkg/server/handler.go routes the HTTP request to the respective handler.
-
A handler is registered for each API group—see k8s.io/apiserver/pkg/endpoints/groupversion.go and k8s.io/apiserver/pkg/endpoints/installer.go for details. It takes the HTTP request as well as the context (for example, user and access rights) and retrieves as well as delivers the requested object from
etcdstorage.
Let’s now take a closer look at the chain of filters that DefaultBuildHandlerChain() in server/config.go sets up, and what happens in each of them:
funcDefaultBuildHandlerChain(apiHandlerhttp.Handler,c*Config)http.Handler{h:=WithAuthorization(apiHandler,c.Authorization.Authorizer,c.Serializer)h=WithMaxInFlightLimit(h,c.MaxRequestsInFlight,c.MaxMutatingRequestsInFlight,c.LongRunningFunc)h=WithImpersonation(h,c.Authorization.Authorizer,c.Serializer)h=WithAudit(h,c.AuditBackend,c.AuditPolicyChecker,LongRunningFunc)...h=WithAuthentication(h,c.Authentication.Authenticator,failed,...)h=WithCORS(h,c.CorsAllowedOriginList,nil,nil,nil,"true")h=WithTimeoutForNonLongRunningRequests(h,LongRunningFunc,RequestTimeout)h=WithWaitGroup(h,c.LongRunningFunc,c.HandlerChainWaitGroup)h=WithRequestInfo(h,c.RequestInfoResolver)h=WithPanicRecovery(h)returnh}
All packages are in k8s.io/apiserver/pkg. To review more specifically:
WithPanicRecovery()-
Takes care of recovery and log panics. Defined in server/filters/wrap.go.
WithRequestInfo()-
Attaches a
RequestInfoto the context. Defined in endpoints/filters/requestinfo.go. WithWaitGroup()-
Adds all non-long-running requests to a wait group; used for graceful shutdown. Defined in server/filters/waitgroup.go.
WithTimeoutForNonLongRunningRequests()-
Times out non-long-running requests (like most
GET,PUT,POST, andDELETErequests), in contrast to long-running requests such as watches and proxy requests. Defined in server/filters/timeout.go. WithCORS()-
Provides a CORS implementation. CORS, short for cross-origin resource sharing, is a mechanism that allows JavaScript embedded in an HTML page to make XMLHttpRequests to a domain different from the one that the JavaScript originated in. Defined in server/filters/cors.go.
WithAuthentication()-
Attempts to authenticate the given request as a human or machine user and stores the user info in the provided context. On success, the
AuthorizationHTTP header is removed from the request. If the authentication fails, it returns an HTTP401status code. Defined in endpoints/filters/authentication.go. WithAudit()-
Decorates the handler with audit logging information for all incoming requests. The audit log entries contain information such as the source IP of the request, user invoking the operation, and namespace of the request. Defined in admission/audit.go.
WithImpersonation()-
Handles user impersonation by checking requests that attempt to change the user (similar to
sudo). Defined in endpoints/filters/impersonation.go. WithMaxInFlightLimit()-
Limits the number of in-flight requests. Defined in server/filters/maxinflight.go.
WithAuthorization()-
Checks permissions by invoking authorization modules and passes all authorized requests on to a multiplexer, which dispatches the request to the right handler. If the user doesn’t have sufficient rights, it returns an HTTP
403status code. Kubernetes nowadays uses role-based access control (RBAC). Defined in endpoints/filters/authorization.go.
After this generic handler chain is passed (the first box in Figure 2-5), the actual request processing starts (i.e., the semantics of the request handler is executed):
-
Requests for /, /version, /apis, /healthz, and other nonRESTful APIs are directly handled.
-
Requests for RESTful resources go into the request pipeline consisting of:
- admission
-
Incoming objects go through an admission chain. That chain has some 20 different admission plug-ins.1 Each plug-in can be part of the mutating phase (see the third box in Figure 2-5), part of the validating phase (see the fourth box in the figure), or both.
In the mutating phase, the incoming request payload can be changed; for example, the image pull policy is set to
Always,IfNotPresent, orNeverdepending on the admission configuration.The second admission phase is purely for validation; for example, security settings in pods are verified, or the existence of a namespace is verified before creating objects in that namespace.
- validation
-
Incoming objects are checked against a large validation logic, which exists for each object type in the system. For example, string formats are checked to verify that only valid DNS-compatible characters are used in service names, or that all container names in a pod are unique.
etcd-backed CRUD logic-
Here the different verbs we saw in “The HTTP Interface of the API Server” are implemented; for example, the update logic reads the object from
etcd, checks that no other user has modified the object in the sense of “Optimistic Concurrency”, and, if not, writes the request object toetcd.
We will look into all these steps in greater detail in the following chapters; for example:
- Custom resources
-
Validation in “Validating Custom Resources”, admission in “Admission Webhooks”, and general CRUD semantics in Chapter 4
- Golang native resource
-
Validation in “Validation”, admission in “Admission”, and the implementation of CRUD semantics in “Registry and Strategy”
Summary
In this chapter we first discussed the Kubernetes API server as a black box and had a look at its HTTP interface. Then you learned how to interact with that black box on the command line, and finally we opened up the black box and explored its inner workings. By now you should know how the API server works internally, and how to interact with it using the CLI tool kubectl for resource exploration and manipulation.
It’s now time to leave the manual interaction on the command line behind us and get started with programmatic API server access using Go: meet client-go, the core of the Kubernetes “standard library.”
1 In a Kubernetes 1.14 cluster, these are (in this order): AlwaysAdmit, NamespaceAutoProvision, NamespaceLifecycle, NamespaceExists, SecurityContextDeny, LimitPodHardAntiAffinityTopology, PodPreset, LimitRanger, ServiceAccount, NodeRestriction, TaintNodesByCondition, AlwaysPullImages, ImagePolicyWebhook, PodSecurityPolicy, PodNodeSelector, Priority, DefaultTolerationSeconds, PodTolerationRestriction, DenyEscalatingExec, DenyExecOnPrivileged, EventRateLimit, ExtendedResourceToleration, PersistentVolumeLabel, DefaultStorageClass, StorageObjectInUseProtection, OwnerReferencesPermissionEnforcement, PersistentVolumeClaimResize, MutatingAdmissionWebhook, ValidatingAdmissionWebhook, ResourceQuota, and AlwaysDeny.