
There is nothing like returning to a place that remains unchanged to find the ways in which you yourself have altered.
Maintaining a software application is probably harder, and definitely more bothersome, than writing it from the ground up. A large part of a developer’s career is spent performing maintenance tasks on existing code rather than planning and writing new software. Armed with this knowledge, I usually advise developers and architects I work with to always give top priority to one specific attribute of the numerous possible attributes of a software system—that attribute is maintainability.
The biggest challenge that many software architects face today is how to design and implement an application that can meet all of the requirements for version 1 plus other requirements that show up afterward. Maintainability has been one of the fundamental attributes of software design since the first draft of the ISO/IEC 9126 paper, back in 1991. (The paper provides a formal description of software quality and breaks it down into a set of characteristics and subcharacteristics, one of which is maintainability. A PDF version of the paper can be obtained at http://www.iso.org.)
The mother of all challenges for today’s software architects is focusing on current requested features while designing the system in a way that keeps it flexible enough to support future changes and additions. In this regard, maintainability is king and you should favor it over everything else. Maintainability represents the best compromise you can get; with a high level of maintainability in your code, you can achieve anything else—including scalability, performance, and security.
That sounds very nice, but how do you write software that is easy to maintain?
There are a few basic principles of software design that if properly, and extensively, applied will transform a piece of code into a manageable and flexible piece of code. Doing this probably won’t be enough to save your team from having to fix a few bugs once the application has been deployed to production, but at least it will keep regression at a reasonable level. More importantly, these principles make it less likely that you’ll have to fix a bug with a workaround rather than with a definitive update.
Let’s start by reviewing some of the most alarming symptoms that generally signal that code-related suffering is on the horizon.
The expression “big ball of mud” (or BBM) refers to a software system that shows no clear sign of thoughtful design and results in a jungle of spaghetti code, duplicated data and behavior, piecemeal growth, and frequent expedient repair. Coined by Brian Foote and Joseph Yooder, the term indicates a clear anti-pattern for developers and architects. You can read the original paper that formalized BBM at http://www.laputan.org/mud.
A BBM system usually results from the combined effect of a few causes: the limited skills of the team, frequent changing of requirements, and a high rate of turnover among team members. Often when you face a BBM the best thing you could ideally do is just rewrite the application based on a new set of reviewed requirements. But, honestly, I’m not sure I’ve ever seen this happen even once. Most of the time, a complete rewrite is simply not a feasible option.
If you have no way out other than facing the BBM, a reasonable but still painful approach consists of stopping any new development and starting to arrange a bunch of significant tests. What types of tests? Well, in a BBM scenario you can hardly expect to write plain isolated unit tests. You wouldn’t be immersed in a big ball of mud if you could write plain unit tests! More likely, you write some sort of integration tests that involve different layers (when not tiers) and that are not especially quick to run, but at least they provide you with an automated tool to measure any regression as you proceed with refactoring the existing code.
To try to keep your head above mud, you can only patiently refactor the code and introduce a better architecture, being very much aware that you’re operating in a fragile environment and any approach must be as delicate as possible. Obviously, this process won’t be completed quickly. It might even take years if the project is very large. On the other hand, the alternative is to just kill the project.
Let’s find out more about the factors that can lead to a big ball of mud.
Architecting a system requires some fundamental skills, maybe a bit of talent, and definitely hands-on experience. Knowledge of best and worst practices also helps a lot. In a word, education is key. However, the development team is not usually given enough power to cause huge damage on their own. Management and customers are usually responsible as well, maybe even more.
When management is too demanding, and when customers don’t really know what they want, the information being conveyed to developers won’t be clear and unambiguous. This leads to arbitrary choices, compromises, and workarounds at all levels that just make it impossible to come up with a defined architecture.
The term requirements churn refers to making numerous changes to the initially agreed-upon requirements. Incorporating a new requirement into an existing system, which was architected without that particular requirement, can be problematic. The cost of such a change depends on the size of the change, the dependencies in the code, and whether or not the change affects the structure of the system.
Adding a single change, even a significant one, is not enough to jeopardize the entire architecture. But when individual significant changes are frequent, over time you transform a system devised in a given way into something that probably requires a different architecture. If you keep adding new requirements individually without reconsidering the system as a whole, you create the ideal conditions for a big ball of mud.
When technical documentation is lacking or insufficient, the worst thing that can happen is that the rationale for making particular decisions is lost forever. As long as the application is deployed, works, and doesn’t require proactive or passive maintenance (although I still haven’t found such an application), you’re fine. But what if this is not the case?
If the rationale for design and architectural decisions is not entirely evident, how can you expect new members of the team to take over the maintenance or additional development for the system? At some point, in their efforts to understand the system, these new members must be informed of the rationale for various decisions. If they can’t figure out the real rationale, inevitably they will make further changes to the system based on their assumptions. Over time, this leads to a progressive deterioration of the system that is what we’ve been referring to as the big ball of mud.
The big ball of mud doesn’t get formed overnight. How can you detect that your system is deteriorating? There a few hard-to-miss symptoms you don’t want to ignore. They are very serious. Let’s find out what they are.
Can you bend a piece of wood? And what do you risk if you insist on trying to do that? A piece of wood is typically stiff and rigid and characterized by some resistance to deformation. When enough force is applied, the deformation becomes permanent.
Rigid software is characterized by some level of resistance to changes. Resistance is measured in terms of regression. You make a change in one module, but the effects of your change cascade down the list of dependent modules. As a result, it’s really hard to predict how large the impact of a change—any change, even the simplest—will actually be.
If you pummel a glass or any other fragile material, you succeed only in breaking it down into several pieces. Likewise, when you enter a change in software and cause it to misbehave in some places, that software is definitely fragile.
Just as fragility and rigidity go hand in hand in real life, they also do so in software. When a change in a software module breaks (many) other modules because of (hidden) dependencies, you have a clear symptom of a bad design, and you need to remedy that situation as soon as possible.
Imagine you have a piece of software that works in one project; you would like to reuse it in another project. However, copying the class or linking the assembly in the new project just doesn’t work.
Why is this so?
If the same code doesn’t work when it’s moved to another project, it’s because of dependencies. However, the real problem isn’t just dependencies; it’s the number and depth of dependencies. The risk is that to reuse a piece of functionality in another project, you’ll have to import a much larger set of functions. In such cases, no reuse is ever attempted and code is rewritten from scratch. (Which, among other things, increases duplication.)
This also is not a good sign either for your design. This negative aspect of a design is often referred to as immobility.
When applying a change to a software module, it is not unusual that you find two or more ways to do it. Most of the time, one way of doing things is nifty, elegant, coherent with the design, but terribly laborious to implement because of certain constraints. The other way is, instead, much smoother and quicker to code, but it is sort of a hack.
What should you do?
Actually, you can solve the problem either way, depending on the given deadlines and your manager’s directives about it.
In summary, it’s not an ideal situation because a workaround might be much easier to apply than the right solution. And that’s not a great statement about your overall design either. It simply means that too many unneeded dependencies exist between classes and that your classes do not form a particularly cohesive mass of code. This negative aspect of a design is often referred to as viscosity.
So what should you do to avoid these symptoms showing up in your code and creating a big ball of mud?
In my opinion, maintainability is the fundamental attribute of modern software. The importance of maintainability spans the technology spectrum and applies to the Web as well as desktop applications.
A few universally valid design principles help significantly to produce code that is easier to maintain and evolve. It is curious to note that they are all principles devised and formulated a few decades ago. Apparently, for quite some time we’ve had the tools to build and manage complex software but real applications were just lacking the complexity to bring them to the forefront as design best practices. This is also my interpretation of the advent of the Rapid Application Development (RAD) paradigm a decade ago, which complemented (and in some cases superseded) object-oriented programming (OOP).
Today, the situation is different. With large companies now taking full advantage of Internet, cloud, and mobile computing, developers and architects are swamped with an incredible amount of complexity to deal with. That’s why RAD is no longer sufficient in many scenarios. On the other hand, not everybody is skilled enough to use OOP. It’s about time we all rediscover some fundamentals of software programming—regardless of the type of application we’re building.
Summarizing, I would boil software principles down to two principles: the High Cohesion and Low Coupling principle and the Separation of Concerns principle.
Cohesion and coupling go hand in hand even though they refer to orthogonal aspects of your code. Cohesion leads you toward simple components made of logically related functions—kind of atomic components. Coupling indicates the surface area between two interfacing components: the wider the area is, the deeper the dependency is between the components. The magic is all in finding the right balance between cohesion and coupling while trying to maximize both.
Cohesion indicates that a given software module—a class, if we assume the object-oriented paradigm—features a set of responsibilities that are strongly related. Put another way, cohesion measures the distance between the logic expressed by the various methods on a class.
If you look for a moment at the definition of cohesion in another field—chemistry—you can get a clearer picture of software cohesion. In chemistry, cohesion is a physical property of a substance that indicates the attraction existing between like-molecules within a body.
Cohesion measurement ranges from low to high, with the highest possible cohesion being preferable. Highly cohesive modules favor maintenance and reusability because they tend to have no dependencies. Low cohesion, on the other hand, makes it much harder to understand the purpose of a class, and it creates a natural habitat for rigidity and fragility in your software. Low-cohesive modules also propagate dependencies, thus contributing to the immobility and viscosity of the design.
Decreasing cohesion leads to creating classes where methods have very little in common and refer to distinct and unrelated activities. Translated into a practical guideline, the principle of cohesion recommends creating extremely specialized classes with few methods that refer to logically related operations. If the “logical” distance between methods needs to grow, well, you just create a new class.
Coupling measures the level of dependency existing between two software classes. An excellent description of coupling comes from the Cunningham wiki at http://c2.com/cgi/wiki?CouplingAndCohesion. Two classes, A and B, are coupled when it turns out that you have to make changes to B every time you make any change to A. In other words, B is not directly and logically involved in the change being made to module A. However, because of the underlying dependency B is forced to change; otherwise, the code won’t compile any longer.
Coupling measurement ranges from low to high, with the lowest possible coupling being preferable.
Low coupling doesn’t mean that your modules have to be completely isolated from one another. They are definitely allowed to communicate, but they should do that through a set of well-defined and stable interfaces. Each class should be able to work without intimate knowledge of the internal implementation of another class. You don’t want to fight coupling between components; you just want to keep it under control. A fully disconnected system is sort of nonsense today.
Conversely, high coupling hinders testing and reusing and makes understanding the system nontrivial. It is also one of the primary causes of a rigid and fragile design.
Low coupling and high cohesion are strongly correlated. A system designed to achieve low coupling and high cohesion generally meets the requirements of high readability, maintainability, easy testing, and good reuse.
Functional to achieving high cohesion and low coupling is the separation of concerns (SoC) principle, introduced by Edsger W. Dijkstra in his paper “On the role of scientific thought” which dates back to 1974. If you’re interested, you can download the full paper from http://www.cs.utexas.edu/users/EWD/ewd04xx/EWD447.PDF.
SoC is all about breaking the system into distinct and possibly non-overlapping features. Each feature you want in the system represents a concern and an aspect of the system. Terms like feature, concern, and aspect are generally considered synonyms. Concerns are mapped to software modules and, to the extent that it is possible, there’s no duplication of functionalities.
SoC suggests that you focus your attention on one particular concern at a time. It doesn’t mean, of course, that you ignore all other concerns of the system. More simply, after you’ve assigned a concern to a software module, you focus on building that module. From the perspective of that module, any other concerns are irrelevant.
Note
If you go through the original text written by Dijkstra back in 1974, you note that he uses the expression “separation of concerns” to indicate the general principle, but he switches to the word “aspect” to indicate individual concerns that relate to a software system. For quite a few years, the word “aspect” didn’t mean anything special to software engineers. Things changed in the late 1990s when aspect-oriented programming (AOP) came into the industry. Ignored for many years, AOP is being rediscovered today mostly thanks to some ad hoc frameworks such as Spring .NET and other Inversion of Control (IoC) frameworks.
SoC is concretely achieved through modular code and making large use of information hiding.
Modular programming encourages the use of separate modules for each significant feature. Modules are given their own public interface to communicate with other modules and can contain internal chunks of information for private use.
Only members in the public interface are visible to other modules. Internal data is either not exposed or it is encapsulated and exposed in a filtered manner. The implementation of the interface contains the behavior of the module, whose details are not known or accessible to other modules.
Information hiding (IH) is a general design principle that refers to hiding behind a stable interface some implementation details of a software module that are subject to change. In this way, connected modules continue to see the same fixed interface and are unaffected by changes.
A typical application of the information hiding principle is the implementation of properties in Microsoft C# or Visual Basic .NET classes. The property name represents the stable interface through which callers refer to an internal value. The class can obtain the value in various ways (for example, from a private field, from a control property, from a cache, and from the view state in ASP.NET) and can even change this implementation detail without breaking external code.
// Software module where information hiding is applied
public class Customer
{
// Implementation detail being hidden
private string _name;
// Public and stable interface
public string CustomerName
{
// Implementation detail being hidden
get {return _name;}
}
}Information hiding is often referred to as encapsulation. I like to distinguish between the principle and its practical applications. In the realm of object-oriented programming, encapsulation is definitely an application of IH.
In general, though, the principle of SoC manifests itself in different ways in different programming paradigms, and so it is also for modularity and information hiding.
Note
Separation of concerns is the theoretical pillar of multitiered (or just multilayered) systems. When you try to apply SoC to classes, you run across just one fundamental concept that you can then find formulated in a number of different ways. You essentially achieve separation of concerns by isolating dependencies and abstracting them to interfaces. This is called low coupling, interface-based programming or, perhaps in a more formal way, the Dependency Inversion principle that I’ll cover in just a moment. Different names—each appropriate in its own context—but just one key idea.
Recently, a particular acronym is gaining a lot of popularity—SOLID. The acronym results from the initials of five design principles formulated by Robert Martin. The S stands for Single Responsibility; the O is for the Open/Closed principle; the L is for Liskov’s principle; the I is for Interface Segregation; and finally, the D is for Dependency Inversion.
Taken individually, these principles are nothing new. Any experienced developer and architect should be at least vaguely familiar with the idea behind each principle, either because it is part of the developer’s personal education or because of the experience the developer has gained the field.
SOLID principles are just a further specialization and refinement of universal and object-oriented design principles. Their definition is relatively simple; yet the adoption of these principles can be fairly complex.
Note
As you’ll see in a moment, not all principles should be taken literally. Some of them are just driving vectors that attempt to show you the right direction, but without being dogmatic. You can download the original papers describing the SOLID principles and their canonical examples from http://www.objectmentor.com.
The Single Responsibility Principle (SRP) is a formal way of rephrasing the idea behind cohesion. The principle states that there should never be more than one reason for a class to change. Applied to the design of the class, it means each class you add to your solution should focus on just one primary task.
The responsibilities of a class that does just one thing are much smaller than the responsibilities of a class that does multiple things. A responsibility is defined as a “reason to change”; more specifically, it’s a reason for you—the developer—to put your hands on the class’s source code and edit it.
The purposes of SRP are to simplify maintenance and improve readability. Keeping the code simple at the root—by taking out additional features—is an effective way to smooth maintenance chores. At the end of the day, SRP is a form of defensive programming.
Like any other SOLID principle, SRP has its own canonical example aimed at illustrating the point of the principle. Here’s a piece of code that contains the gist of SRP:
public class Modem
{
public void Dial(String number);
public void Hangup();
public void Send(Char c);
public Char Receive();
}How many sets of responsibilities do you see in the Modem class? Dial and Hangup represent the connection management functionality, whereas the Send and Receive pair of methods represent communication functionalities. Should these two sets of responsibilities be separated? As usual, it depends.
An effective implementation of SRP passes through the identification of specific responsibilities in the programming interface of the class. One task is identifying responsibilities; it is quite a different task to actually split the class into two other classes, each taking care of a specific responsibility. In general, you should always consider splitting responsibilities in distinct classes when the two sets of functions have little in common. If this happens, the two resulting classes will likely change for different reasons and will likely be called from different parts of the application. In addition, different parts of the application will change for different reasons.
Another scenario that suggests the need to split a class into two (or more) is when the two sets of functions you identified in the original interface are large enough to require sufficiently complex logic of their own. In this case, you simply lower the level of granularity of your design a bit. However, the size is not always, and not necessarily, a good parameter to use to make a decision about SRP. A function can be complex and large enough to justify a breakup; however, if it’s not likely to change over time, it might not require a distinct class. Scenarios like this, however, represent a tough call, with no uniform guidance to help you determine what to do.
Finally, you should pay a lot of attention not to split the original class into small pieces. The risk of taking SRP to the limit is falling into the Overdesign anti-pattern that occurs when a system is excessively layered and each layer ends up being a thin wrapper around an if statement. As mentioned, SRP is a driving vector rather than a dogma. You should always keep it in your mind but never apply it blindly and blissfully.
We owe the Open/Closed Principle (OCP) to Bertrand Meyer. The principle addresses the need of creating software entities (whether classes, modules, or functions) that can happily survive changes.
The purpose of the principle is to provide guidance on how to write components that can be extended without actually touching the source code. Sounds like quite an ambitious plan, doesn’t it? Let’s get at the formulation:
A class should be open for extension but closed for modification.
Honestly, I find the formulation a bit idealistic and bordering on magic. However, the principle is in itself quite concrete. It essentially says that the source code of the class must remain intact, but the compiled code must be able to work with types it doesn’t know directly. This can be achieved in just one way: abstracting aspects of the class that can lead to changes over time. To abstract these aspects, you can either use interfaces and code injection or generics.
Low coupling between interfacing modules is beneficial because it instructs the caller to work with an abstraction of its counterpart rather than with a concrete implementation. In their masterpiece Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1994), the Gang of Four (Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides) formulate a basic principle of object-oriented design as “Program to an interface, not to an implementation.”
The gist of OCP is all here. Code that is based on an abstraction can work with a concrete object it gets passed as long as this object is compatible with known abstraction. Behind the term “abstraction,” you can find at least two concrete syntax elements: a base class or an interface. Here’s the canonical example of a class—the Renderer class—that fully complies with OCP:
public abstract class Shape
{
public abstract void Render();
}
public class Renderer
{
public void Draw(IList<Shape> shapes)
{
foreach(Shape s in shapes)
s.Render();
}
}The abstraction is represented by the base class Shape. The Renderer class is closed for modification but still open for extension because it can deal with any class that exposes the Shape abstraction—for example, any class that derives from Shape.
Analogously, you can have a Renderer<T> class that receives its working type as a generic argument.
OCP should not be taken literally. Like SRP, it works much better if used as a driving vector. Frankly, no significant class can be 100 percent closed for modification. By “significant class” here, I mean most real-world classes or, better, all classes except those you write just for demo purposes!
If closure of a given class can’t realistically be complete, it should then be strategic. It is a precise architect’s responsibility to identify the most likely changes in the class body and close the class design against them. In other words, designing a class that can support all possible future extensions is a utopian pursuit. However, identifying just one specific abstraction or two and making the class work against them is, most of the time, an excellent compromise. Aiming for fully pluggable classes is over designing; even a partial application of OCP is beneficial and rewarding.
If you ignore OCP, at some point you might catch yourself downcasting to a specific subclass to compile the code and avoid run-time exceptions. If this happens, it’s a clear sign that something is wrong in the design.
Of the five SOLID principles, Liskov’s principle is probably the only one that should be taken literally, because it serves you a detailed list of dos and don’ts and it isn’t limit to being a generic guidance on design. The formulation of the principle couldn’t be simpler. To some extent, it also seems a bit obvious:
Subclasses should always be substitutable for their base classes.
When a new class is derived from an existing one, it should always be possible to use the derived class in any place where the parent class is accepted. Wait a moment! Isn’t this something you get out of the box with any object-oriented language? Well, not exactly!
What you really get from OOP is just the mere promise that derived classes can be used wherever their base class is accepted. However, OOP still lets you write hierarchies of classes where this basic requirement isn’t met; hence, the principle.
Suppose you have a Rectangle class and a method that works with that. The method just receives a parameter of type Rectangle and, of course, it takes advantage of the logical contract this class exposes. For example, the Rectangle class exposes a Width and Height pair of properties that can be independently set.
Suppose that after doing this, you then need to introduce a Square object. How would you do that? Logically speaking, you see the Square entity as a special case of the Rectangle entity. Therefore, the natural step is deriving Square from Rectangle and overriding Width and Height so that their values are always in sync.
If you do this, you potentially break the original code written against the contract of the Rectangle class. The violation of the principle here doesn’t necessarily result in a run-time exception or a compile error. Your code might still work just fine, despite the Liskov violation. However, your code is inherently fragile because there’s the possibility of introducing bugs during maintenance. The violation has to be considered in the mathematical sense—you can find a counterexample that shows you can’t use a Square where a Rectangle is expected. Here’s a code snippet that illustrates this point:
public class Rectangle
{
public virtual Int32 Width { get; set; }
public virtual Int32 Height { get; set; }
}
public class Square : Rectangle
{
public override Int32 Width
{
get {return base.Width; }
set {base.Width = value; base.Height = value; }
}
public override Int32 Height
{
get {return base.Height; }
set {base.Height = value; base.Width = value; }
}
}Here’s some client code that consumes the Rectangle class:
public void Process(Rectangle rect)
{
rect.Width = 100;
rect.Height = 2* rect.Width;
Debug.Assert(rect.Height == 2*rect.Width);
}This code works fine if a real Rectangle is passed, but it violates the assertion if a Square is passed. The easiest way to fix it—the workaround that increases viscosity—is simply the following:
public void Process(Rectangle rect)
{
if (rect is Rectangle)
{
rect.Width = 100;
rect.Height = 2* rect.Width;
Debug.Assert(rect.Height == 2*rect.Width);
}
else
{
...
}
}The real problem you have here, instead, is an incorrect definition of inheritance rules. Square can’t be derived from Rectangle because it is not expected to be able to do at least all the things that the base class does.
Liskov’s principle can be difficult to grasp for many developers. An easier way to explain it is the following: each derived class should expect no more than the parent and provide no less than the parent.
This means, for example, that you break the principle if a virtual member ends up using a private member of the class. Likewise, you break the principle if a derived class adds more preconditions to a virtual method.
Liskov’s principle isn’t meant to portray inheritance—a pillar of OOP—in a bad light. Quite the reverse, it calls your attention to a safe use of virtual members. If you derive and just add new features, you’re absolutely safe. If you don’t have virtual members, you’re absolutely safe. If you have virtuals and actually override them in derived class, you should pay additional attention.
Note
In .NET 4, you have the Code Contracts API to express preconditions, postconditions, and invariants around your classes. A precondition is simply an IF in a method that executes at the very beginning of the code. If you use this API to express preconditions for the methods of a class, and happen to add preconditions to an overridden method of a class, you get a warning (not an error) from the C# compiler.
There’s an aspect of coding that I find particularly annoying—being forced to write code that I don’t really need. You might say that you should not write any code that you don’t need. There are situations, however, in which this is necessary. When? For sure, when the code ignores the Interface Segregation principle.
The principle is so simple that it seems like merely common sense. It says that client components should not be forced to depend upon interfaces that they do not use. More precisely, components should not be forced to implement members of interfaces (or base classes) that they don’t plan to use.
There’s nothing bad in a client that provides a void implementation of a particular interface method or that just throws if invoked. Sometimes this happens simply because the client deliberately intends to provide a partial implementation; sometimes, however, it happens because the interface is poorly designed. Fat interfaces are a bad thing. The Single Responsibility principle should hold true for interfaces also.
The classic scenario to examine to start thinking about interface segregation is the definition of a door. If you’re asked to simply define a door, you would probably come up with an interface with just a couple of Lock and Unlock methods and perhaps a Boolean property IsDoorOpen. However, if you know that you also need to deal with timed doors that sound an alarm if left open for too long, you might arrange something like this:
public interface IDoor
{
void Lock();
void Unlock();
Boolean IsDoorOpen { get; }
Int32 OpenTimeout { get; set; }
event EventHandler DoorOpenForTooLong;
}The apparent plus of this design is that it gives you just one interface that can serve up both scenarios: timed and regular doors. This is an apparent benefit because it forces you to have two extra members on any class that implements the interface: the event DoorOpenForTooLong and the timeout property. Why on earth should you have these members where they aren’t needed?
Note also that code that is not strictly needed can’t be ignored after it is compiled. In other words, any code that gets compiled does count, regardless of whether or not it was necessary when you designed your classes. Because it’s there, it can influence the application, it must be tested, it must be debugged, and it must be maintained. Quite paradoxically, because it’s there it can even represent a constraint and limit further necessary improvements!
The natural solution is to use slimmer interfaces. The IDoor interface should be split into two smaller and much more specific interfaces—say IDoor and ITimedDoor:
public interface IDoor
{
void Lock();
void Unlock();
Boolean IsDoorOpen { get; }
}
public interface ITimedDoor
{
Int32 OpenTimeout { get; set; }
event EventHandler DoorOpenForTooLong;
}Now if you need to create RegularDoor and TimedDoor classes, you proceed as shown here:
public class RegularDoor : IDoor
{
...
}
public class TimedDoor : IDoor, ITimedDoor
{
...
}Unlike classes, interfaces can be easily summed up; so there’s really no reason to have fat interfaces any more.
I consider Dependency Inversion to be the most important of the five SOLID principles. You don’t need it in every class and method that you write, but if you miss it where you need it, well, you’re in serious trouble. Take a look at Figure 13-1.
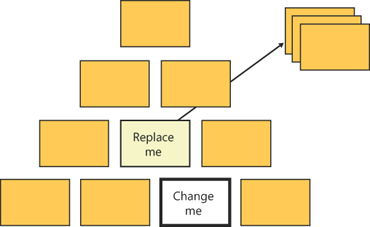
I’m not sure the idea behind this figure is completely original, and I don’t even know if there’s anybody I should thank for that. For sure, I remember having seen it somewhere, likely at some software conference somewhere in the world. Then I simply revised the idea and made it mine.
So you have built the architecture of your system by simply composing parts. What if, at some point during development, you need to replace or significantly modify one of the building blocks? As the graphics attempts to show, it might be hard to change some of the building blocks that form the skeleton of the system. Dependency inversion is simply aimed at making this difficult task simpler and less expensive.
The principle says that every high-level module should always depend on abstractions of lower level modules. This is just a reformulation of the concept of interface-based programming.
The idea behind Dependency Inversion doesn’t need a complex scenario to be effectively illustrated. Just imagine a method that reads bytes from a stream and writes them out to some buffer:
void Copy()
{
Byte byte;
while(byte = ReadFromStream())
WriteToBuffer(byte);
}The pseudocode just shown depends on two lower level modules: the reader and writer. According to the principle, we should then abstract the dependencies to interfaces—say, IReader and IWriter. The method can be rewritten as follows:
void Copy()
{
Byte byte;
IReader reader;
IWriter writer;
while(byte = reader.Read())
writer.Write(byte);
}Who really does provide instances of the reader and writer modules? That’s the principle, or the general law; to actually solve the issue, you need some further specification. In other words, you need a pattern.
The first pattern used to apply the Dependency Inversion principle is Service Locator pattern, which can be summarized as follows:
void Copy()
{
Byte byte;
var reader = ServiceLocator.GetService<IReader>();
var writer = ServiceLocator.GetService<IWriter>();
while(byte = reader.Read())
writer.Write(byte);
}You use a centralized component that locates and returns an instance to use whenever the specified abstraction is requested. The service locator operates while embedded in the code that it serves. You can say that it looks for services, but it is not a service itself. Most of the time, you use this pattern when you have some legacy code that you need to make easier to extend that is hard to redesign in a different way—for example, in a way that uses dependency injection.
A better alternative is to use Dependency Injection (or inversion of control). The resulting code looks like this:
void Copy(IReader reader, IWriter writer)
{
Byte byte;
while(byte = reader.Read())
writer.Write(byte);
}The list of dependencies is now explicit from the signature of the method and doesn’t require you to go down the line to pinpoint calls to a service locator component. In addition, the burden of creating instances for each spot dependency is moved elsewhere.
Dependency inversion is about layers, and layers don’t reduce the total amount of code (quite the reverse, I’d say). Layers, however, contribute to readability and, subsequently, to maintainability and testability.
In light of this, the motivation for special frameworks such as Inversion of Control (IoC) frameworks is right in front of your eyes.
You don’t want to write the factory yourself for all instances that populate the graph of dependencies for pieces of your application. The task is repetitive and error prone. Although it might be a boring task for developers, it’s just plain business as usual for certain tools. IoC frameworks are just a way for you to be more productive when it comes to implementing the Dependency Inversion principle.
These days, we tend to oversimplify things by using the name of the most popular pattern—Dependency Injection—to refer to the universal principle. Even more often, we just use the name of a family of tools (IoC) to refer to the principle. What really matters is that you give the principle its due consideration. The details of how you actually implement it are up to you and your team.
You don’t need an IoC tool to implement good dependency injection; you can get it through overloaded constructors (also known as the poor man’s dependency injection) or even by writing your own homemade IoC framework. In the simplest case, it’s a thin layer of code around some .NET reflection primitives. You can ignore the Dependency Inversion principle, but you do so at your own peril.
The list of tools for dependency injection is quite long in the .NET space nowadays. Most of these tools provide the same set of core functionalities and are, to a large extent, equivalent. Choosing one is often a matter of preference, skill level, and perhaps your comfort with the exposed API. There are some who prefer simplicity and speed and opt for Autofac or Ninject. Others would opt for rich functionality and go for Spring.NET or Castle Windsor. Another group would pick up the entire Microsoft stack and then use Unity. Table 13-1 lists the most popular options today, with the URL from where you can get further information.
All IoC frameworks are built around a container object that, bound to some configuration information, resolves dependencies. The caller code instantiates the container and passes the desired interface as an argument. In response, the IoC framework returns a concrete object that implements that interface. Let’s top off the chapter by taking a quick tour of two frameworks in the Microsoft stack that, although they have different characteristics and goals, can both be employed to implement the Dependency Inversion principle.
Introduced with the Microsoft .NET Framework 4, the Managed Extensibility Framework (MEF) attempts to give a consistent answer to the loud demand for tools for building plugin-based applications.
A plugin-based application is an application that can rely on a number of optional components that are discovered and composed together at run time. Microsoft Visual Studio is an excellent example of this application; a simpler but still valid example is Windows Explorer, whose menus can be extended by registering shell extensions. A plugin-based application provides a number of extensibility points and builds its core user interface and logic using abstractions for those extensibility points. Some run-time code then attempts to resolve all pending dependencies in a quick and direct way.
MEF does some work that any IoC does. Like an IoC framework, MEF is able to spot dependencies and resolve them, returning a usable graph of objects to the caller application. In raw terms of functionality, MEF is not as powerful as most IoC tools. MEF has limited support for managing the object’s lifetime and doesn’t currently support any form of aspect orientation. MEF also requires that classes it deals with be decorated with ad hoc attributes.
You can’t just take a plain old CLR class and use it with MEF. On the other hand, MEF swallows exceptions when some particular things go wrong during the composition process.
In summary, MEF is an IoC framework optimized for the specific task of discovering and loading optional and compatible components on the fly.
MEF is already in the .NET Framework 4; any IoC tools of choice is a separate set of assemblies and adds dependencies to the project. MEF is available only for .NET 4, whereas most IoC frameworks are available for most .NET platforms. This said, however, I’d like to remark that MEF doesn’t bring new significant capabilities to the table that you couldn’t code yourself or achieve through an IoC. MEF, however, makes writing plugin-based applications really fast and simpler than ever before.
If MEF serves all your IoC needs, choose MEF and code your way within the .NET Framework 4. If you’re happy with the IoC you’re using today, perhaps there’s no need for you to change it. In this regard, MEF won’t give you an ounce more than your favorite IoC.
The real issue is when you want to use MEF because of plugins but still need to mix it with an IoC because MEF doesn’t offer the advanced services of rich IoC—for example, call interception. In this case, either you drop MEF in favor of IoC or configure MEF to accept instances created by the IoC of choice.
An MEF application is based on components known as composable parts. Each part can contain some members decorated as imports. An import is a class member with the Import attribute, and it indicates a member that will be resolved and instantiated by the MEF runtime. In a MEF application, you also find classes decorated as exports. An export is a class decorated with the Export attribute. An instance of an export class can be used to perform an import as long as the import and export match.
What does determine a valid match?
An import/export match is based on a contract. A contract here has little to do with service or interface contracts. An MEF contract is a collection of meta information that both imports and exports contain. In most cases, it is a simple string. In other cases, it contains type information or both unique strings and type information.
The list of exports is determined by catalogs. A catalog is a provider that returns the list of available exports to be matched to the imports of the object being resolved. Finally, the composition process is the process in which all imports (that is, dependencies) are resolved.
Here’s a brief code example to illustrate:
public class PasswordCreator
{
private CompositionContainer _container;
public ProgramBody() {
InitializeMef();
}
private void InitializeMef()
{
var catalog = new DirectoryCatalog("Plugins");
_container = new CompositionContainer(catalog);
// Fill the imports of this object
try {
_container.ComposeParts(this);
}
catch (CompositionException compositionException);
}
[Import]
public IPasswordFactory PasswordFactory { get; set; }
public String CreatePassword()
{
if (PasswordFactory == null)
{
return "Dependency not resolved.";
}
return PasswordFactory.Create(12);
}
}The class PasswordCreator generates a random password using the services of an object that implements the IPasswordFactory interface. No such a component, though, is instantiated by the class itself. The task, in fact, is delegated to MEF.
MEF will use a directory catalog to explore all assemblies in the specified relative folder, looking for exports that match the contract of the IPasswordFactory import. So where’s the contract name?
When you use the plain attribute, the contract name defaults to the name of the member. In this case, it is typeof(IPasswordFactory). What about exports?
Consider the following example:
[Export(typeof(IPasswordFactory))]
public class DefaultPasswordFactory : IPasswordFactory
{
public String Create(Int32 passwordLength)
{
// Create the password
}
protected virtual String GeneratePasswordCore(Int32 passwordLength)
{
// ...
}
}Deployed to an assembly located in the specified plugin folder, the class DefaultPasswordFactory exports the typeof(IPasswordFactory) factory. If the class features the simple Export attribute, the contract then corresponds to the class name, thus missing the previous import.
Note that if an export, in turn, misses one key import, the export is ignored to ensure the stability of the solution. If multiple exports qualify to resolve the same import, you get a composition exception.
Unity is an open-source project from the Patterns & Practices group at Microsoft, which is attempting to provide an IoC framework for developers to build object instances in a smart and highly configurable way. Unity works as a standalone framework, but it’s also packaged along with Enterprise Library. To add Unity to a project, you add a reference to the Microsoft.Practices.Unity assembly. You optionally add a reference to Microsoft.Practices.Unity.Configuration if you configure the library using the application’s configuration file.
Let’s see how to accomplish some key IoC operations with Unity, such as registering types both programmatically and declaratively.
Just like any other IoC library, Unity is centered around a container object. In Unity, the container type is UnityContainer, and you use it to register types and instances, as shown here:
var container = new UnityContainer();
container
.RegisterType<IServiceLayer,
DefaultServiceLayer>()
.RegisterType<ICustomerRepository,
CustomerRepository>();
var serviceLayer = container.Resolve<IServiceLayer>();You use the RegisterType method to establish a mapping between an abstract type and a concrete type. If the same abstract type should be mapped to different types in different contexts of the same application, you can use the following overload:
container
.RegisterType<ILogger, DefaultLogger>()
.RegisterType<ILogger, FileLogger>("Tracing");The additional string parameter disambiguates the request and gives Unity enough information about which concrete type to pick up. You use RegisterInstance instead of RegisterType to supply the container a prebuilt instance of a type. In this case, Unity will use the provided instance instead of creating one on its own. Does it really make sense for an application to pass to a factory the instance it will get back later? The purpose is to preserve the benefits of an IoC also in situations in which you can’t annotate a class to be automatically resolved by Unity.
To see an example of this, let’s first introduce the syntax required to annotate constructors and properties for injection. When requested to create an instance of a given type, Unity gets information about the constructors of the type. If multiple constructors are found, Unity picks up the one with the longest signature. If multiple options are available, an exception is thrown. It might be the case, however, that you want a particular constructor to be used. This requires that an attribute be attached to the selected constructor:
[InjectionConstructor]
public MyClass()
{
...
}If you have no access to the source code, you might want to consider RegisterInstance. Similarly, if injection happens through the setter of a property, you need to decorate the property accordingly, as shown here:
private ILogger _logger; [Dependency] public ILogger Logger { get { return _logger; } set { _logger = value; } }
RegisterType and RegisterInstance are the methods you work with if you opt for configuring the Unity framework programmatically. However, offline configuration is also supported via an ad hoc section in the application’s configuration file. In any case, programmatic and declarative configuration is totally equivalent.
In Unity, you invoke the method Resolve on the container class to trigger the process that returns an instance of the type at the root of the dependency chain:
container.Resolve(registeredType);
The resolver can be passed any additional information it might need to figure out the correct type to return:
var logger = container.Resolve<ILogger>("Tracing");If you have multiple registrations for the same type, only the last one remains in the container’s list and will be taken into account. The resolver can walk down the chain of dependencies and resolve everything that needs to be resolved. However, you get an exception if the chain is broken at some point and the resolver can’t locate the proper mapping. When this happens in MEF, instead, the dependency is simply not resolved and is skipped over. On the other hand, multiple candidates to resolve a dependency are managed by Unity (the last wins) but cause a composition exception in MEF.
The Unity framework comes with a custom configuration section that can be merged with the web.config file of a Web application. Here’s the script you need to register types:
<unity>
<container name="MyApp">
<register ="ILogger" mapTo="DefaultLogger">
<lifetime type="singleton"/>
<constructor>
<param name="sourceName" type="string" value="default"/>
</constructor>
</registerType>
</container>
</unity>Under the <register> section, you list the abstract types mapped to some concrete implementation. The following code shows how to map ILogger to DefaultLogger:
<register type="ILogger" mapTo="DefaultLogger">
If the type is a generic, you use the following notation:
<container>
<register type="IDictionary[string,int]" </register>
</container>Taking the declarative approach, you can also select the constructor to be used and set up the lifetime of the instance.
To configure the Unity container with the information in the web.config file, you need the following code:
var container = new UnityContainer();
// Retrieve the <unity> section
var section = ConfigurationManager.GetSection("unity") as UnityConfigurationSection;
if (section != null)
{
// Retrieve the specified container by name
var containerElement = section.Containers["MyApp"];
// Load information into the specified instance of the container
if (containerElement != null)
containerElement.Configure(container);
}As it turns out, Unity allows you to have multiple containers with different settings to load as appropriate. You can skip over all the preceding details by calling an extension method added in Unity 2.0:
var container = new UnityContainer(); container.LoadConfiguration();
It requires that you add a reference to the Microsoft.Practices.Unity.Configuration assembly.
Just like any other IoC framework, Unity allows you to assign a fixed lifetime to any managed instance of mapped types. By default, Unity doesn’t apply any special policy to control the lifetime of the object returned for a registered type. It simply creates a new instance of the type each time you call the Resolve or ResolveAll method. However, the reference to the object is not stored, so a new one is required to serve a successive call.
The default behavior can be modified by using any of the predefined lifetime managers you find in Unity. Table 13-2 lists them.
Table 13-2. Lifetime Managers
Class | Description |
|---|---|
ContainerControlledLifetimeManager | Implements a singleton behavior for objects. The object is disposed of when you dispose of the container. |
ExternallyControlledLifetimeManager | Implements a singleton behavior, but the container doesn’t hold a reference to the object that will be disposed of when out of scope. |
HierarchicalLifetimeManager | New in Unity 2.0, implements a singleton behavior for objects. However, child containers don’t share instances with parents. |
PerResolveLifetimeManager | New in Unity 2.0, implements a behavior similar to the transient lifetime manager except that instances are reused across build-ups of the object graph. |
PerThreadLifetimeManager | Implements a singleton behavior for objects, but it’s limited to the current thread. |
TransientLifetimeManager | Returns a new instance of the requested type for each call. This is the default behavior. |
You can also create custom managers by inheriting the LifetimeManager base class.
Here’s how you set a lifetime manager in code:
container
.RegisterType<ILogger, DefaultLogger>(
"Tracing",
new ContainerControlledLifetimeManager());Here’s what you need, instead, to set a lifetime manager declaratively:
<register type="ILogger" mapTo="DefaultLogger">
<lifetime type="singleton" />
</register>Note, however, that the word singleton you assign to the type attribute is not a keyword or a phrase with a special meaning. More simply, it is intended to be an alias for a type that must be declared explicitly:
<!-- Lifetime manager aliases -->
<alias alias="singleton"
type="Microsoft.Practices.Unity.ContainerControlledLifetimeManager,
Microsoft.Practices.Unity" />
<alias alias="perThread"
type="Microsoft.Practices.Unity.PerThreadLifetimeManager,
Microsoft.Practices.Unity" />
<alias alias="external"
type="Microsoft.Practices.Unity.ExternallyControlledLifetimeManager,
Microsoft.Practices.Unity" />
...
<!-- User-defined aliases -->
<alias alias="IMyInterface"
type="MyApplication.MyTypes.MyInterface, MyApplication.MyTypes" />
...After you have the aliases all set, you can use alias names in the section where you register types.
Just as an architect designing a house wouldn’t ignore building codes that apply to the context, a software architect working in an object-oriented context shouldn’t ignore principles of software design such as the SOLID principles discussed in this chapter when designing a piece of software. Proper application of these principles leads straight to writing software that is far easier to maintain and fix. It keeps the code readable and understandable and makes it easier to test, both during development and for refactoring and extensibility purposes.
Most developers (and even more managers) commonly think that using software principles is first and foremost a waste of time and that no distinction is actually possible between “well-designed code that works” and “software that just works.” Guess what? I totally agree with this statement. If you don’t need design, any effort is overdesign. And overdesign is an anti-pattern.
So you save a lot of time by skipping over principles. However, if your “software that just works” has to be fixed or extended one day, be aware that you will find yourself in a serious mess. The costs at that point will be much higher. It all depends on the expected lifespan of the application. Ideally, you learn principles and make them a native part of your skill set so that you use them all the time in a natural way. Otherwise, the costs of applying principles will always be too high to seem effective. Ad hoc tools can help a lot in making the development of good code more sustainable. IoC frameworks are just one of these tools.
In the next chapter, I’ll continue with the theme of application design by tackling layers (and communication related to them) in ASP.NET applications.