
Deep learning models are becoming very popular. They have very deep roots in the way biological neurons are connected and the way they transmit information from one node to another node in a network model.
Deep learning has a very specific usage, particularly when the single function–based machine learning techniques fail to approximate real-life challenges. For example, when the data dimension is very large (in the thousands), then standard machine learning algorithms fail to predict or classify the outcome variable. This is also not very efficient computationally. It consumes a lot of resources and model convergence never happens. Most prominent examples are object detection, image classification, and image segmentation.
Convolutional neural network . Mostly suitable for highly sparse datasets, image classification, image recognition, object detection, and so forth.
Recurrent neural network . Applicable to processing sequential information, if there is any internal sequential structure in the way data is generated. This includes music, natural language, audio, and video, where the information is consumed in a sequence.
- Deep neural network . Typically applicable when a single layer of a machine learning algorithm cannot classify or predict correctly. There are three variants.
Deep network, where the number of neurons present in each hidden layer is usually more than the previous layer
Wide network, where the number of hidden layers are more than a usual neural network model
Both deep and wide network, where the number of neurons and the number of layers in the network are very high
This chapter discusses how to fine-tune deep learning models using hyperparameters. There is a difference between the parameters and hyperparameters. Usually in the deep learning models, we are not interested in estimating the parameters because they are the weights and keep changing based on the initial values, learning rate, and number of iterations. What is important is deciding on the hyperparameters to fine-tune the models, as discussed in Chapter 3, so that optimum results can be derived.
Recipe 6-1. Building Sequential Neural Networks
Problem
Is there any way to build sequential neural network models, as we do in Keras in PyTorch, instead of declaring the neural network models?
Solution
If we declare the entire neural network model, line by line, with the number of neurons, number of hidden layers and iterations, choice of loss functions, optimization functions, and the selection of weight distribution, and so forth, it will be extremely cumbersome to scale the model. And, it is not foolproof—errors could crop up in the model. To avoid the issues in declaring the entire model line by line, we can use a high-level function that assumes certain default parameters in the back end and returns the result to the user with minimum hyperparameters. Yes, it is possible to not have to declare the neural network model.
How It Works
Let’s look at how to create such models. In the Torch library, the neural network module contains a functional API (application programming interface) that contains various activation functions, as discussed in earlier chapters.

In the following lines of script, we create a simple neural network model with linear function as the activation function for input to the hidden layer, and the hidden layer to the output layer.
The following function requires declaring class Net , declaring the features, hidden neurons, and activation functions, which can be easily replaced by the sequential module.

Instead of using this script, we can change the class function and replace it with the sequential function. The Keras functions replace the TensorFlow functions, which means that many lines of TensorFlow code can be replaced by a few lines of Keras script. The same thing is possible in PyTorch without requiring any external modules. As an example, in the following, net2 explains the sequential model and net1 explains the preceding script. From a readability perspective, net2 is much better than net1.
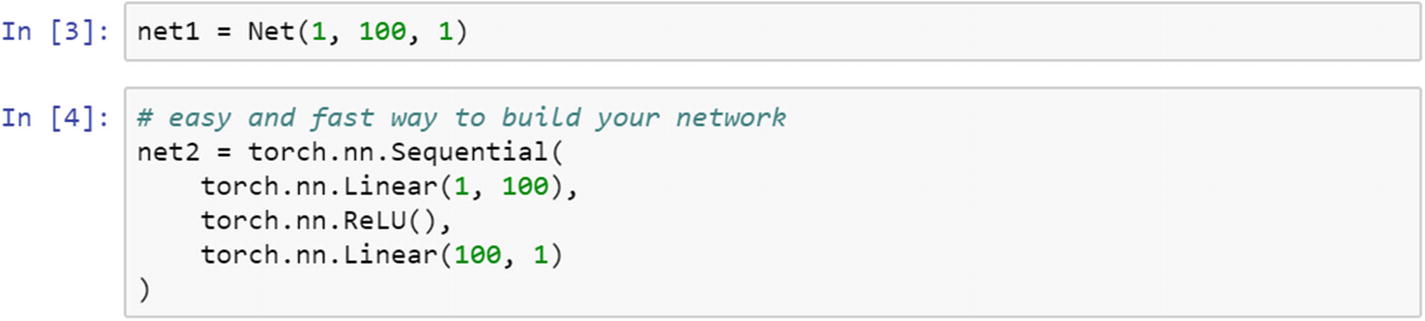
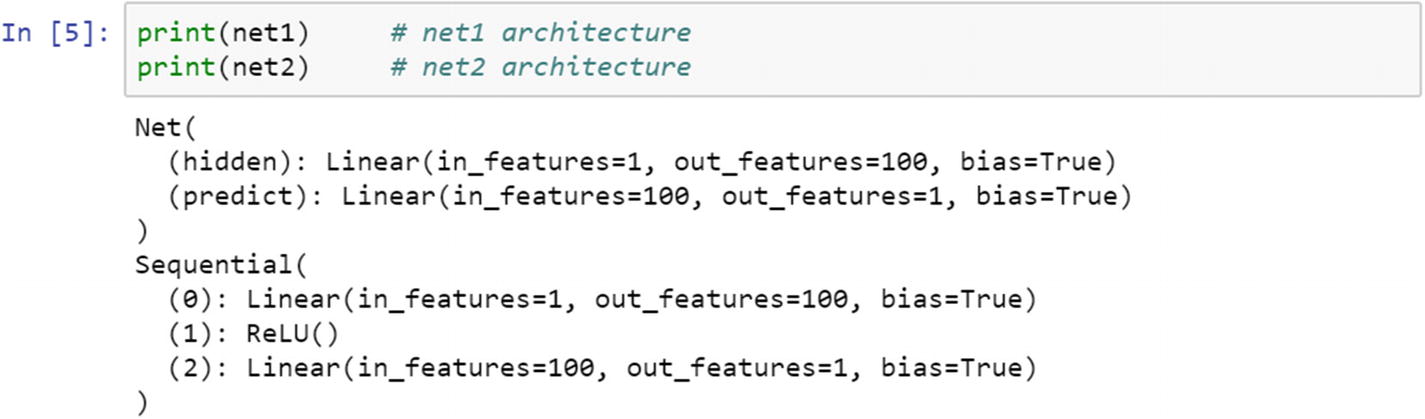
If we simply print both the net1 and net2 model architectures, it does the same thing.
Recipe 6-2. Deciding the Batch Size
Problem
How do we perform batch data training for a deep learning model using PyTorch?
Solution
Training a deep learning model requires a large amount of labeled data. Typically, it is the process of finding a set of weights and biases in such a way that the loss function becomes minimal with respect to matching the target label. If the training process approximates well to the function, the prediction or classification becomes robust.
How It Works
There are two methods for training a deep learning network: batch training and online training. The choice of training algorithm dictates the method of learning. If the algorithm is backpropagation, then online learning is better. For a deep and wide network model with various layers of backpropagation and forward propagation, then batch training is better.
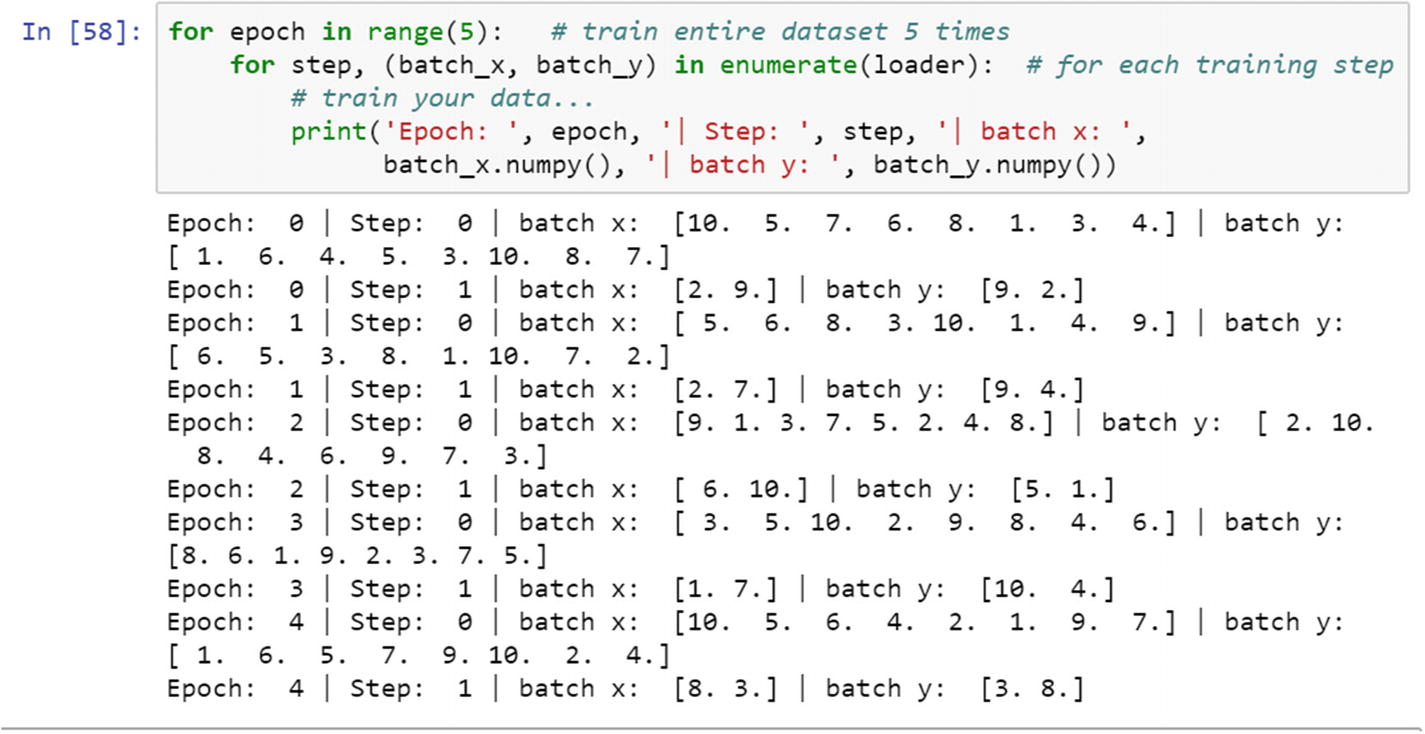
In the training process, the batch size is 5; we can change the batch size to 8 and see the results. In online training process, the weights and biases are updated for every training example based on the variations between predicted result and actual result. However, in the batch training process, the differences between actual and predicted values which is error gets accumulated and computed as a single number over the batch size, and reported at the final layer.


After training the dataset for five iterations, we can print the batch and step. If we compare the online training and batch training, batch training has many more advantages than online training. When the requirement is to train a huge dataset, there are memory constraints. When we cannot process a huge dataset in a CPU environment, batch training comes to the rescue. In a CPU environment, we can process large amounts of data with a smaller batch size.

We take the batch size as 8 and retrain the model.

Recipe 6-3. Deciding the Learning Rate
Problem
How do we identify the best solution based on learning rate and the number of epochs?
Solution
We take a sample tensor and apply various alternative models and print model parameters. The learning rate and epoch number are associated with model accuracy. To reach the global minimum state of the loss function, it is important to keep the learning rate to a minimum and the epoch number to a maximum so that the iteration can take the loss function to the minimum state.
How It Works
First, the necessary library needs to be imported. To find the minimum loss function, gradient descent is typically used as the optimization algorithm, which is an iterative process. The objective is to find the rate of decline of the loss function with respect to the trainable parameters.
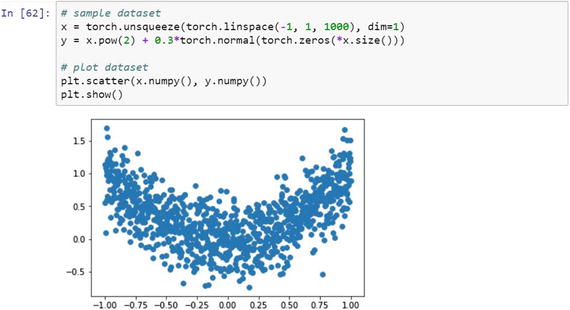
The sample dataset taken for the experiment includes the following.
The sample dataset and the first five records would look like the following.

Using the PyTorch utility function, let’s load the tensor dataset, introduce the batch size, and test out.
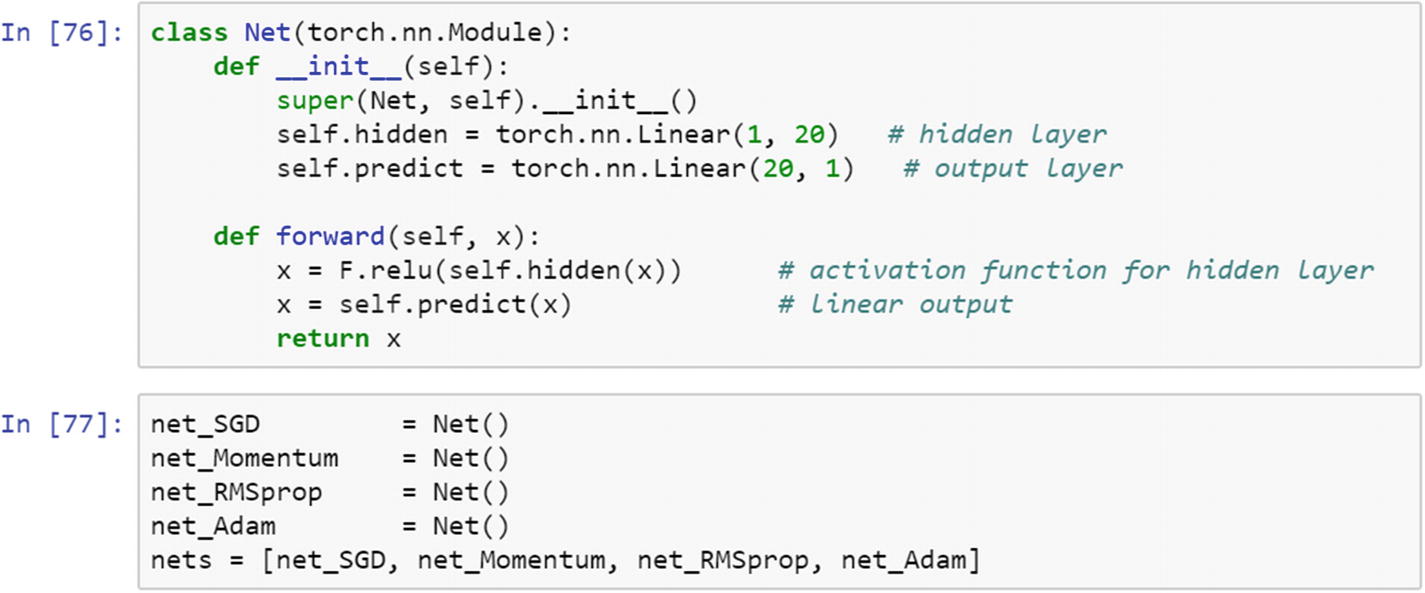
Declare the neural network module.
Now, let’s look at the network architecture.

While performing the optimization, we can include many options; select the best among the best.
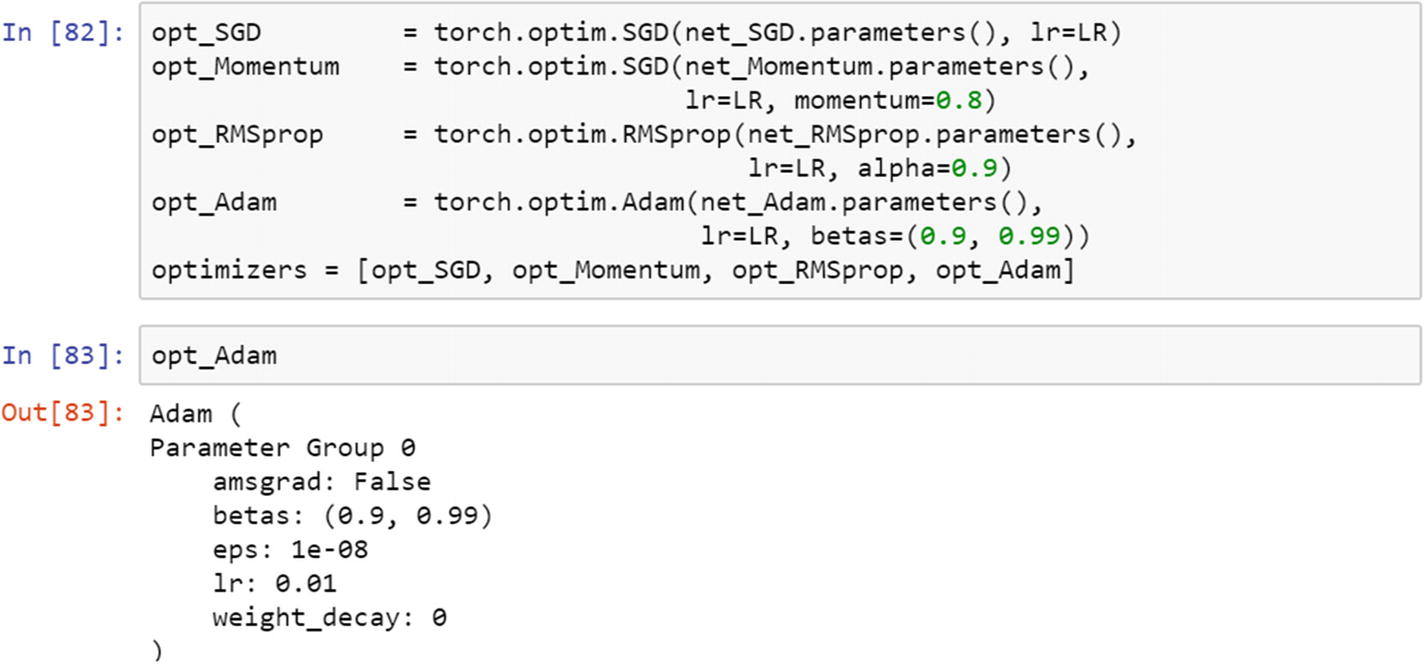
Recipe 6-4. Performing Parallel Training
Problem
How do we perform parallel data training that includes a lot of models using PyTorch?
Solution
The optimizers are really functions that augment the tensor. The process of finding a best model requires parallel training of many models. The choice of learning rate, batch size, and optimization algorithms make models unique and different from other models. The process of selecting the best model requires hyperparameter optimization.
How It Works
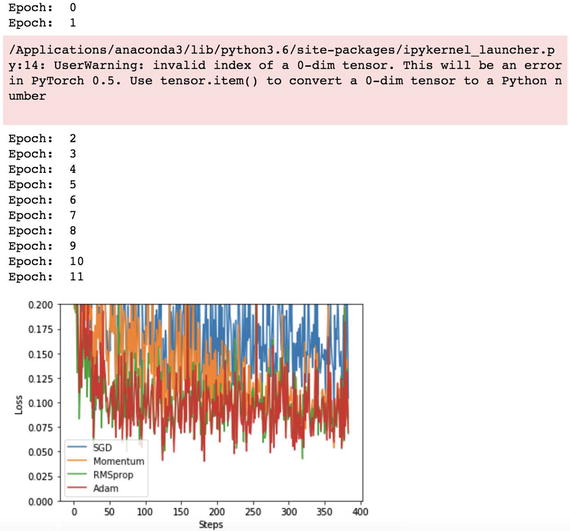
First, the right library needs to be imported. The three hyperparameters (learning rate, batch size, and optimization algorithm) make it possible to train multiple models in parallel, and the best model is decided by the accuracy of the test dataset. The following script uses the stochastic gradient descent algorithm, momentum, RMS prop, and Adam as the optimization method.
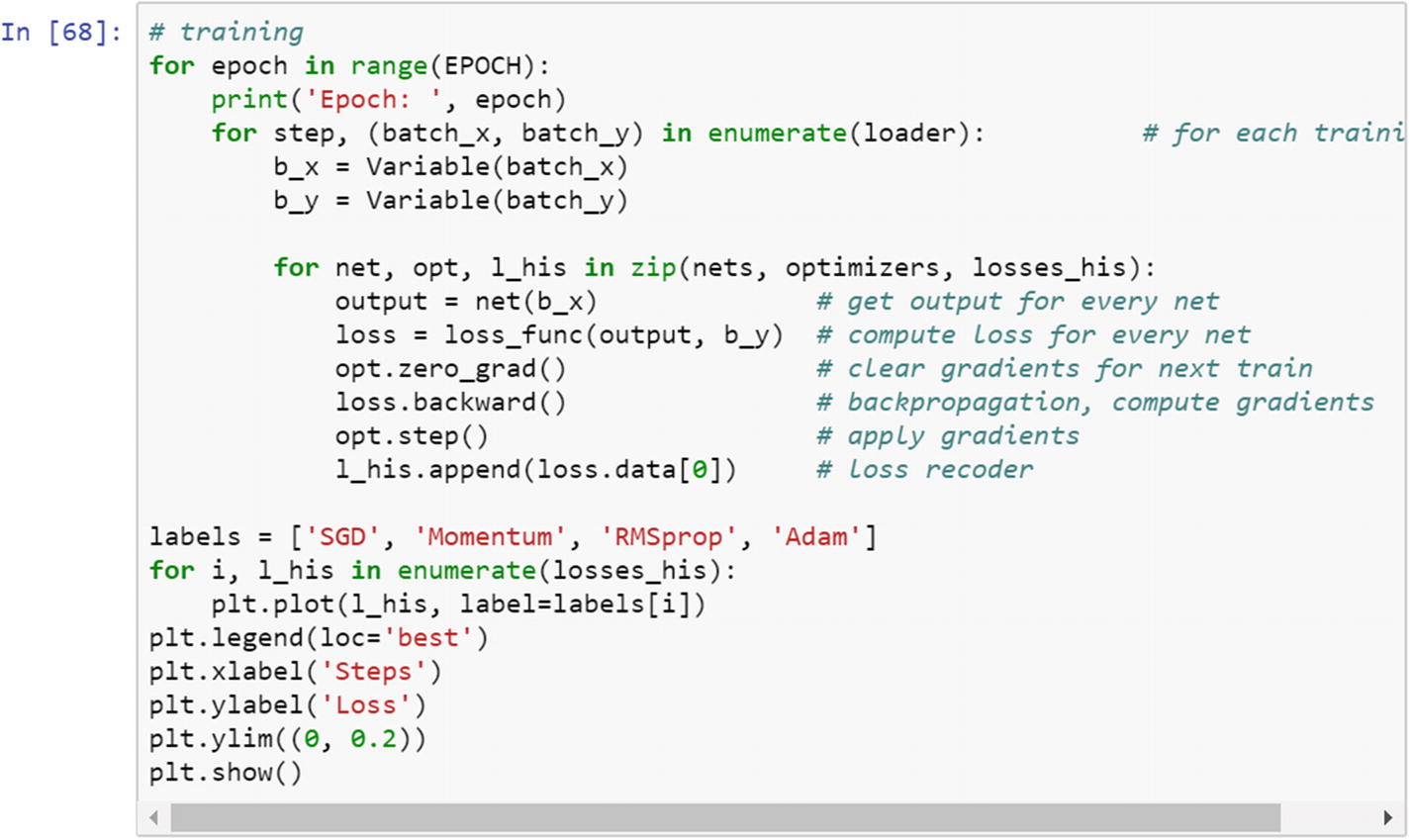
Let’s look at the chart and epochs.
Conclusion
In this chapter, we looked at various ways to make the deep learning model learn from the training dataset. The training process can be made effective by using hyperparameters. The selection of the right hyperparameter is the key. The deep learning models (convolutional neural network, recurrent neural network, and deep neural network) are different in terms of architecture, but the training process and the hyperparameters remain the same. The choice of hyperparameters and selection process is much easier in PyTorch than any other framework.