
Another method of modeling that tells us which features have an impact on our model is the feature importance that comes out of a random forest classifier. This more accurately reflects the true impact of a given feature.
Let's run our data through this type of model and examine the results:
from sklearn.ensemble import RandomForestClassifier clf_rf = RandomForestClassifier(n_estimators=1000) clf_rf.fit(X_train, y_train) f_importances = clf_rf.feature_importances_ f_names = X_train.columns f_std = np.std([tree.feature_importances_ for tree in clf_rf.estimators_], axis=0) zz = zip(f_importances, f_names, f_std) zzs = sorted(zz, key=lambda x: x[0], reverse=True) n_features = 10 imps = [x[0] for x in zzs[:n_features]] labels = [x[1] for x in zzs[:n_features]] errs = [x[2] for x in zzs[:n_features]] fig, ax = plt.subplots(figsize=(16, 8)) ax.bar(range(n_features), imps, color="r", yerr=errs) plt.xticks(range(n_features), labels) plt.setp( ax.xaxis.get_majorticklabels(), rotation=-70, ha="left" );
The preceding code generates the following output:
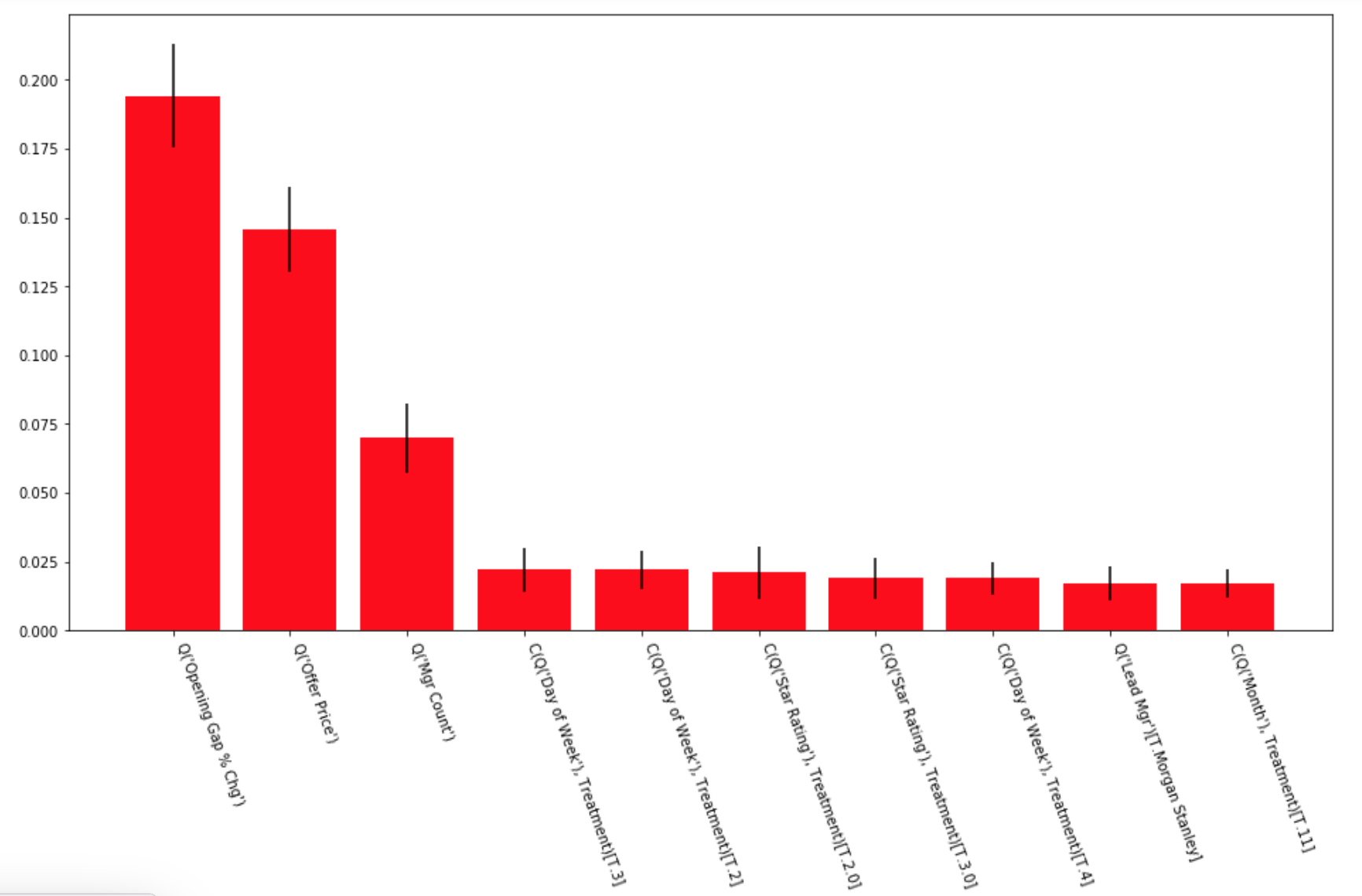
In the preceding code, we ran a random forest classifier, extracted and sorted the importance of the features, and then graphed those values with their error bars.
From this data, we see that what has the most impact on the model is the opening gap, the offer price, and the number of managers involved in the deal. These would all seem to make sense as having predictive values, since they indicate that there is strong demand for the deal.