
In the first place, we generate wordclouds for most frequent keywords for posts and consumer comments on the whole dataset.
In the following screenshot, you can see the most frequent keywords in brand posts:

In the following screenshot, you can see the most frequent keywords used in comments:

We can easily notice that the keywords are polluted by lots of comments related to political and religious issues. As we don't want to focus our analysis on these topics, we'll create a filtering method to remove all the irrelevant words.
We define a list of keywords associated with comments considered as noise in a global variable, CLEANING_LST. Our list can be also saved in a file and loaded to the variable:
CLEANING_LST = ['gulf','d','ban','persic' ...]
Cleaning irrelevant words is an iterative process and you can add any other word considered as a noise with respect to the subject that you are supposed to analyze. We did a few iterations ourselves to reduce the corpus to our topics of interest.
To be more specific, noise is a relative context around the topic you're focusing on. If you're interested in analyzing things that are related to the brand business, words about politics could be considered as noise. On the other hand, if you're analyzing politics, then it's not noise.
We add a following line to the viz_wordcloud function in order to filter out all phrases containing irrelevant words:
lst_phrases = [phrase for phrase in lst_phrases if not any(spam in phrase.lower() for spam in CLEANING_LST)]
We also noticed that our wordcloud contains one letter tokens that are useless for our analysis. We add the following line to the viz_wordcloud function to remove them:
lst_phrases = [phrase.replace(" ","_") for phrase in lst_phrases if len(phrase) > 1 ]
Finally, we obtain a cleaned wordcloud, as shown in the following screenshot; we obtain the most frequent keywords in comments after cleaning:
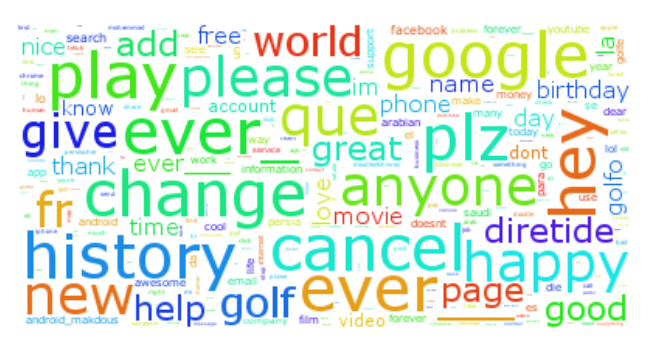
Another way to be more precise is to look at top 10 keywords and their frequencies in the following table format and then extract the posts:
|
User comments |
Frequency |
Brand posts |
Frequency |
|
|
123986 |
|
516 |
|
cancel |
62846 |
new |
155 |
|
play |
62729 |
search |
130 |
|
ever |
30538 |
day |
96 |
|
be |
16089 |
today |
95 |
|
plz |
15447 |
world |
94 |
|
change |
13431 |
doodle |
92 |
|
history |
12665 |
check |
91 |
|
hey |
11562 |
see |
91 |
|
anyone |
11027 |
get |
87 |
In the above table, we see the most frequent keywords for both the brand and the users. Among the users, words such as cancel, play, plz, change among others are the most frequent. In the case of the brand new, search, world, doodle are among the top 10 keywords the most frequent.
Now to get more context on the keywords we extract some of the actual verbatims for the brand and users. Extracting for all the keywords is beyond the scope of this chapter.