
The number and range of books on software lifecycle methodologies is probably only eclipsed by the number of publications on weight loss. Despite the huge volume of literature and collective knowledge available on both topics, software projects still run late or fail completely to achieve their goals, and the western world still has an obesity problem.
Anyone wishing to lose weight is spoiled for a choice with an immense range of diets and dieting books from which to choose. However, the collective information in all of these works can be boiled down to a few simple facts that virtually everyone is aware of: If you eat less and exercise regularly, you will become fitter and trimmer.
I believe the same reductive analysis can be applied to software development processes and that out of all the material written on the subject, a core set of fundamental best practices exists that will help guide the majority of enterprise-level projects to a successful conclusion.
The objective of this chapter is therefore to define this distilled set of practices from the standpoint of a rapid development project. Within this chapter, we look at the rationale behind the choice of software development methodology and analyze those elements of a software engineering process that are conducive to rapid development.
We look at the classic waterfall model and see why, despite its widely recognized weaknesses, it still permeates the thinking of the majority of IT professionals. As an alternative to the waterfall model, we examine the benefits of adaptive development methods and compare two examples of this type: first, the well-established IBM Rational Unified Process (RUP), and second, the ultra-nimble process, Extreme Programming—the flagship of the agile movement.
A successful software development methodology defines how all of our tools, techniques, and practices combine into a winning formula. The techniques discussed throughout this book are meaningless in isolation unless a process is adopted to bind them into a cohesive development strategy. Indeed, the choice of methodology is a key part of defining an adaptive foundation for enterprise development.
The use of methodologies for software engineering arose out of the need to make the software development process a repeatable and quantifiable activity. Methodologies aim to place a degree of control over a software project, enabling it to be steered toward a successful conclusion through a proven series of steps and actions.
For RAD, we want a process that requires the minimum of administrative control and delivers the most productive method. The question is how much process is enough and how much is too much. Finding the correct answer has significant implications for rapid development.
The ideal methodology for rapid development is one that is optimal for the development underway. People tend to think of RAD methodologies as being lean and mean, carrying out only those tasks that relate directly to the success of the project.
This definition is valid but needs to be placed in context. A process that fits this criterion for a small project might be completely unsuitable for a large-scale development. Conversely, a method that has proven successful on a large project might prove completely unwieldy and inefficient when used by a smaller team.
A lean and mean approach is required, but we need to qualify the minimalist approach by being sensitive to the needs of the system under development.
In addition to being lightweight, the process adopted should exploit the strengths of the J2EE platform. J2EE solutions use distributed object-oriented technology; hence, the process followed should align with the needs of this type of solution. A process founded on procedural methods, for example, is unlikely to form a favorable complement to a J2EE project.
In order to conform with the central tenet of this book, that RAD projects require the ability to react quickly and effectively to change, the methodology selected also must offer an adaptive approach to software development. Indeed, all of the techniques in this book point toward an adaptive approach, and our choice of methodology should be no different.
Summarizing these points we get the following set of criteria for an ideal RAD methodology:
Lightweight.
The process must offer the minimum level of ceremony in the context of the size of system under development.
Complementary.
The process must work to exploit the strengths of the development tools and techniques adopted by the team. This relationship is symbiotic, as the tools and techniques should in turn support the chosen methodology.
Adaptive.
To be effective, the process must be able to contend with the emergent nature of business requirements, enabling the project team to change direction as and when the business dictates.
Let’s consider the different types of methodologies available for enterprise developments.
The number of different software development methodologies available is many and varied. However, after several decades of evolution, development methodologies generally fall into one of two categories: either predictive or adaptive [Fowler, 2000].
Predictive methods seek to draw upon the disciplines of established engineering principles to provide a measure of predictability to the software engineering process. They attempt to quantify the cost, duration, and resource requirements of a system up front, in the early stages of the project, by completing all work relating to requirements definition and design ahead of any actual implementation.
Predictive methods can prove very effective for systems whose requirements remain stable throughout the duration of the project. However, their rigid approach makes them resistant to change. Any refinement of the requirements downstream from the initial analysis phase can lead to costly rework. The process must backtrack in order to accommodate the change within the plan and identify the impact on the project schedule.
In contrast, adaptive methods accept that for most systems, the requirements will change during the course of the project. These methods look to put feedback mechanisms in place that enable changes to be incorporated back into the system with minimal effort and cost.
The classic waterfall lifecycle model personifies the predictive method, while adaptive methods rely on an incremental development approach for flexibility. The next sections cover the suitability of each of these lifecycle models for the rapid development of enterprise systems.
The waterfall model is the most well known of all the software lifecycles, and its basic steps have been ingrained into the heads of countless IT students. The waterfall model was one of the first attempts to bring order to the chaotic world of software development, and sought to bring predictability to software projects through the application of methods taken from the various engineering professions.
Despite its popularity, the model has some significant weaknesses that make it poorly suited to the rapid development of business software. This section reviews the waterfall approach to software development and discusses its strengths and weaknesses.
The waterfall model offers a linear approach to software development. Practitioners of the model diligently and methodically step through its distinct phases of analysis, design, coding, and testing.
Figure 3-1 shows the steps of the classic waterfall approach.
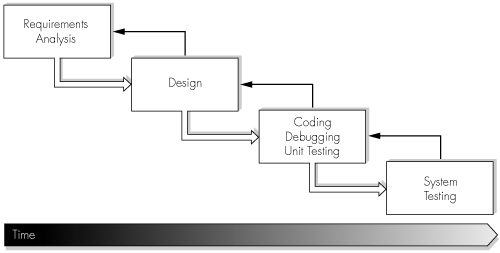
The approach is document-driven, with the initial phases focusing on the creation of highly detailed requirements and design documents before any coding work commences. The phases of the waterfall model do not overlap. As the name implies, they cascade one into another.
note
Contrary to many people’s understanding of the waterfall lifecycle, the model does provide for feedback between the phases, making it possible to backtrack and undertake rework from a previous phase. However, backtracking is difficult, and essentially the waterfall model sees the project progressing in a linear fashion, with each phase building on the work of the previous phase.
The model does offer some considerable benefits in lieu of an ad hoc approach to development. It enforces a disciplined method on the project team, ensuring that requirements are duly considered up front at the start of the project and that extensive planning is carried out before resources are committed to the development. To a degree, these are all good software engineering practices because they improve the team’s understanding of the customer’s needs.
Unfortunately, the waterfall lifecycle model also suffers from some inherent weaknesses:
No system is delivered until near the end of the schedule. This is high risk, since the system may have diverged from the customer’s initial expectations.
Mistakes in the design, or missed requirements, are extremely costly to rectify in the later stages of the process, since the entire project must be backtracked to an earlier phase.
Testing is left until the last phase of the project. Defects detected at this late stage of the development are the most expensive to fix with the waterfall model.
Leaving testing to the end of the project also means the quality of the application being developed cannot be gauged until testing has been completed. This leaves it very late to address any quality concerns in either the design or implementation.
The model is document-intensive and devotes considerable resources to the production of specifications for each phase.
Many of you have examples of projects conducted according to the disciplines of the waterfall model. One such project I worked on early in my career made the inefficiencies of the model abundantly clear, especially when the pressure to deliver intensified.
The project team was developing a shrink-wrapped hydrographic surveying system in C++ (this was in the days before Java). The team was small, but every member was well skilled in the use of the technology and knowledgeable in the practices of object-oriented development.
The team was under considerable pressure to deliver the product. The competition had stolen a lead with the latest release of its software, and the company was in catch-up mode. The project stakeholders were in a state of constant high stress. Every passing day that we didn’t deliver, the competition stole more and more of the market share. On the project, stress levels were high and tempers were short.
We were a dedicated group of developers who were well aware of the concerns of the stakeholders. We wanted to deliver quickly, but we also took pride in our work and wanted to produce a quality product.
To achieve both aims, we decided, called for a formal disciplined approach. The biggest consumer of time on the project was rework. If we could reduce the amount of rework, we could reduce our time to market.
Working on the premise that documents are cheap, while skillfully crafted object-oriented code is expensive, we put the following process in place based on our knowledge of the software engineering best practices of the day.
Discuss the requirements with one of the product specialists at the team’s disposal.
Have the developer sit down and carefully document how the new functionality should operate.
Present the functional specification to the product specialists for approval.
The specialists sign off the document if they are happy with the content; if not, step 1 is revisited and the document revised.
Once the specification has been accepted by the product specialists, the developer designs, implements, and delivers the new functionality.
Finally, the product specialists take on the role of testers and verify the functionality of the delivered product feature.
The approach seemed both sound and diligent. Having the product specialists accept the requirements specification meant the development team could focus on implementing the exact functionality requested. Unfortunately, things didn’t progress as smoothly as anticipated.
One of my main tasks was the design and implementation of the system’s real-time navigational displays. The purpose of one particular display was to provide the helmsman with a visual cue as to whether the vessel was maintaining the correct course. After creating a functional specification for the navigational display, work began on the implementation.
Weeks later, the display was complete and a new version of the software was released to the product specialists for formal testing. At this point the problems started.
The product specialists were not happy. Yes, they agreed the helmsman’s display met the original requirements, and no, they could not find any defects. However, it was not what they wanted.
Seeing the display in action, they realized requirements had been missed that meant the display would prove unusable for navigation out on the water. They also didn’t like the flat, two-dimensional look of the display and suggested something more three-dimensional. Why hadn’t they said so at the time?
This feedback was very frustrating. I had worked extra hours to get the job done on time and to make sure the display’s behavior was exactly as the product specialists had requested. From my perspective, I had achieved my goal yet had failed to deliver functionality that met their needs.
To avoid repeating the problem a second time, I took a different approach. First, I ignored the requirements document, instead taking a day to restructure the code so it roughly incorporated some of the changes. This next version was far from production quality but demonstrated some of the main new ideas. I went back to the product group with the new version, explaining that the software was not stable and was only a rough prototype. They liked the revamped display but suggested some further changes.
Over the course of the next week, I went through the cyclic process of revising and demonstrating the display. Quite soon, the display evolved to the point where the requirements were agreed and effort then went into bringing the software up to a production level.
Once the final version was ready, the product group documented the display’s functionality as part of the user guide, leaving me free to get on with the next system feature.
From the experience, I learned a few things:
In this case, writing software was quicker than writing a requirements specification.
People like to see things working. Few of us can appreciate the nuances of the final system from reading a description in a document.
The approach of involving the end users throughout the process, and getting their input, made for a better product. The final version of the display looked much better than my first effort.
If the display had been demonstrated when it was only even half complete, the problems would have been picked up much earlier, thereby saving a lot of extra work.
Despite all of this, a heroic team effort won through and the project was a success. The architecture we produced for the system proved a stable platform and served as the basis for other profitable products. In the end, we came through, but the questions arose: Is there a better way, and could we have got to market any sooner?
The answer is yes, and we could see the key to successful future projects lay in the application of an approach that allowed us to factor in feedback from the product specialists at every step of the development process. For that, we needed to ditch our waterfall variant in favor of something along adaptive lines. To do that required turning to an iterative approach to development.
Adaptive methods offer the ability to cope with changing requirements by adopting an iterative development approach. Iterative development is common to most forms of adaptive methods and provides some considerable advantages over conventional linear development approaches, as typified by the waterfall model. With an iterative approach, the entire project lifecycle is broken up into smaller pieces known as iterations, where each iteration is a complete “mini-waterfall” in its own right.
The approach is largely founded on the spiral model defined by Barry Boehm [Boehm, 1988]. The spiral model forms the basis of modern adaptive methods and is an incremental, risk-averse approach to software development. Boehm’s approach was conceived in reaction to the observation that existing linear methods were discouraging more effective approaches to software engineering, such as prototyping and software reuse.
Instead of trying to digest the requirements of a system in one sitting, iterative development avoids heartburn by taking smaller, digestible bites out of the full system. These bites are known as iterations. A typical iteration takes a subset of the requirements through the standard phases of the waterfall model from requirements analysis through to functioning system.
Each iteration is conducted over a short, palatable timeframe, thereby providing near-term milestones for the team to achieve. At the conclusion of the iteration, a demonstrable system is available for inspection by the customer, although ideally the customer should provide input throughout the entire timeframe of the iteration.
Feedback received from the completed iteration is used for planning the objectives and scope of the next iteration. This ongoing planning effort, driven by the feedback from iterations, enables the project to adjust course as new requirements emerge and existing ones are consolidated.
Figure 3-2 shows the basic structure of an iterative development process.
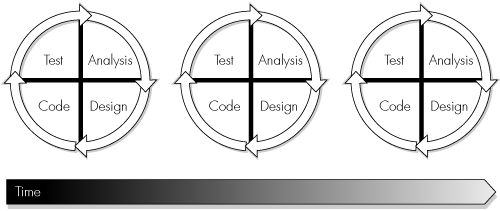
Boehm described his approach as being spiral, as the model sees an iteration cycle through the phases of requirements analysis, design, implementation, and testing—although Boehm’s model contained several more phases, including the important activity of risk analysis. Subsequent cycles follow the same path, but the system spirals gradually outward as the software grows in terms of functionality, complexity, and investment.
These next sections highlight the benefits of iterative development.
A change in requirements can be a schedule-destroying event on a waterfall project if the change occurs downstream of the requirements phase. Iterative development projects are considerably more flexible and can be adjusted midcourse to align the project in the wake of any changes through the essential activity of iteration planning.
Customers are notorious for not knowing what they want until they have seen it in action. This isn’t a criticism but an observation of basic human nature, and is something of which we are all guilty.
Having each iteration conclude in a functioning system, demonstrating a subset of the total requirements, enables the end user to build up an accurate picture of how the system will look and behave. Based on this understanding, the end user is empowered to refine the requirements until the system exhibits the required functionality.
By continually going through each of the phases of development in each iteration, risks to the project are quickly identified. For example, integration issues can be highlighted in the first iteration when the system is still small. In comparison, the waterfall model will not uncover these same integration problems until late in the project, when the system is of such a bulk that integration problems are not easily remedied.
The analysis and design activity isn’t carried out just once on an iterative project; it is revisited throughout the lifetime of the development. This enables the design and architecture of the system to evolve as the system grows. Problems can be detected early, and corrections can be more easily effected. Thus, a robust architecture is the result of a process of constant refinement.
Iterative projects break the complexity of a system into manageable chunks. This has the advantage that initial iterations of the system are limited in scope and therefore easily understood by everyone on the team. Developers can build up an early understanding of the design and can appreciate where the system is heading in terms of a final architecture. As the system increases in functionality and consequently grows in complexity, developers can increment their understanding of the system accordingly.
This understanding of the design enables developers to make decisions as to where parts of the system can be reused or where further development is required. Conversely, waterfall projects, which have all design done up front, can leave developers ignorant of large parts of the system architecture. This runs the risk that developers will duplicate existing designs, since they may be unaware of the existence of a suitable component.
People learn from their mistakes. They also learn from their experiences. With a waterfall project, having made mistakes in the design phase and gained valuable experience from the design effort, software engineers have to wait until the next project before they can apply those skills again. On an iterative project, engineers can apply the knowledge they have gained from a previous iteration into the next. Thus, the existing project gains from the skills the team is building. Moreover, the team is able to hone its skills as the project progresses.
The waterfall model leaves testing until the last phase of the project. This approach does nothing to mitigate the risk of poor-quality software being generated throughout the project. Often, with waterfall projects, good progress is made up until the point where the testing phase starts. At this time, the project team is deluged with defects, and the project schedule is immediately put in jeopardy. Iterative development has testing commencing early, enabling remedial action to be taken if the quality of the software is below expectations.
Long-term plans, like long-term weather forecasts, are often nothing more than a best guess. Waterfall projects suffer badly from the effects of long-term estimation practices. Estimates are built on assumptions that may prove incorrect as the project progresses. Iterative development projects avoid detailed estimation efforts until planning an individual iteration. These estimates are far more realistic because the team is estimating over a much shorter timeframe, and team members have the knowledge accumulated from previous iterations on which to found their estimates. Thus, estimates on iterative developments tend to be accurate, and they increase in accuracy as the team’s understanding of the software improves.
Iterations allow the continuous evolution of the development process, not just the software, as the project progresses. Shortcomings in the approach soon become apparent in early iterations, and the process can be adjusted accordingly between iterations.
Here, the team also includes the customer. People thrive on feedback from their efforts. By ensuring a running system is available at the conclusion of each iteration, the team builds up a sense of ownership for the software it creates. Furthermore, positive feedback from the customer helps keeps the team motivated for the course of the project. Likewise, the customer gains security from seeing a working system early in the project lifecycle. Customers also feel in control as they see their ideas and changes being quickly incorporated into their system.
The benefits of iterative development make the approach a central practice for all adaptive methods. In the next sections, we look at two types of adaptive methods. Each follows an incremental, iterative approach to software development: the IBM Rational Unified Process and the agile methodology Extreme Programming (XP).
The RUP is a commercial method and is sold as an online resource on CD-ROM, although numerous books and articles are available on the subject.
It was developed as a complementary methodology to the Unified Modeling Language (UML) and is a use-case-driven, architecture-centric, iterative development process for producing object-oriented software. The process is the result of the combination of many software engineering best practices as well as the acquisition by Rational of several software engineering methods. Its lineage goes back to the Objectory process, created in 1987 by methodology guru Ivar Jacobson.
Note
Chapter 5, Modeling Software, examines the Unified Modeling Language.
RUP is actually a process framework rather than a methodology. It defines an extensive selection of disciplines, artifacts, activities, and roles each of which represents industry best practice for the development of object-oriented software. The best practices that underpin the RUP framework are as follows:
Develop software iteratively.
Manage requirements.
Use component-based architectures.
Visually model software.
Continuously verify software quality.
Control changes to software.
Due to the comprehensive nature of the framework, the process is often assumed to be high-ceremony and heavyweight. While RUP does emphasize the importance of certain key artifacts and activities that are central to the process, this assumption is largely incorrect. Instead, RUP encourages the developer to tailor the process to the needs of his or her specific project by selecting from the long list of elements RUP provides for just about every conceivable project type. By tailoring the process, RUP can take on the agility of a lightweight methodology if the needs of the project dictate. However, the reliance of the process on artifacts such as use cases and design models means it is unable to slim down to the feather-light weights of methods such as XP, which we cover later.
A second common misconception with the process is that it is based upon predictive methods rather than adaptive methods. Again, this assumption is incorrect: RUP promotes the best practice of developing software iteratively. Many adopters of the RUP have been guilty of overlaying the waterfall lifecycle model on top of the process framework, thereby turning it into a predictive method. This is counter to the best practices of the process and certainly goes against the intent of its creators.
To understand how RUP is applied on projects, over the next sections we look at two of the key drivers for the process: use cases and timeboxed iterative development. We also examine the core elements of the framework.
We know that a successful system meets the needs of its end users. To achieve this goal, IT staff must work closely with the business domain experts to elicit the requirements that will ultimately drive the development effort. The interaction between business representatives and members from the project team is a critical success factor for ensuring all relevant requirements are both understood and captured correctly. Achieving this objective is a challenge, since both parties approach the engagement with very different mindsets and viewpoints. The end users focus on business concerns, while the IT staff likely thinks in terms of system design and architecture.
The question becomes, “How do we capture requirements in a form that is understandable to both the business domain experts and the IT-focused software engineers?” One of the most successful methods to date of achieving this is to develop a set of use cases.
Use cases describe what the system should do from the end user’s perspective. They are text-based documents, as opposed to diagrams, that step through the flow of a set of closely related business scenarios. Each use case represents a functional slice of the system and describes how actors interact with the system in order to execute the use case.
An actor is defined as something external to the system, usually a person, who interacts with the system. The use case itself is a series of actions a system performs for the actor.
Here is an example of the structure of a typical use case:
Use-case name: A short but descriptive title based on the goal of the use case
Goal: A longer description of the goal
Category: Several categories are possible but are likely to be one of primary, secondary, or summary
Preconditions: Conditions that must exist before starting
Postconditions: Conditions present upon the successful conclusion of the use case
Actors: A list of all the participating actors
Trigger: The event that starts the execution of the use case
Flow of events: A series of numbered steps that walks through each of the flows. You can optionally include activity diagrams for each flow:
Main flow
Alternative flows
Exception flows
Extensions: Points at which branching to other use cases occurs within the flow of events
Special requirements: Any additional processing requirements not covered by the different flows
Performance goals: Measurable performance criteria the system must meet when executing the main flow
Outstanding issues: Any unresolved issues that are preventing the completion of the use case
Templates for use cases vary, with publications on the subject each presenting slight variations on a common theme. The structure of the use case shown represents the elements commonly found in use-case templates. You may wish to tailor this template to suit the needs of your own project.
The most important part of a use-case document is the flow of events section:. This describes the interplay between actors and system for a given scenario in a concise, natural language form.
note
A scenario is a flow of events within the use case. Very often, a use case comprises additional alternative flows to the main flow. These secondary flows typically cover exception conditions or slight deviations from the main scenario.
Let’s look at an example of a use case that details the flow of events for a customer who enters the office of a travel company to reserve seats on a suitable flight. Table 3-1 shows an example of the complete use case.
Table 3-1. Use Case Example
Name | Customer flight reservation. |
Goal | To allow a customer to reserve seats on an airline flight. |
Category | Primary. |
Preconditions | The Customer is in the Travel Agency office meeting with the Travel Agent. The Flight Reservation system is online, and flights are available that meet the Customer’s travel needs. |
Postconditions | The Customer has reserved a seat(s) that meets her travel requirements and is ready either to pay for the flight or to place a deposit for the reservation. |
Actors | Customer Travel Agent |
Trigger | The Customer requests to make a flight booking. |
1. The use case starts when the Customer requests to make a flight reservation. 2. The Travel Agent asks the customer for the date of travel, the destinations, and the number of people traveling. 3. The Travel Agent enters the Customer’s details into the Flight Reservation system. 4. The Flight Reservation system lists the available flights that match the Customer’s travel requirements and displays the airfare for each option. 5. The Customer selects a flight from the list and requests to make a booking. 6. The Travel Agent asks the customer for name, address, and contact telephone number. 7. The Travel Agent enters the Customer’s details into the Flight Reservation system and reserves seats on the flight. 8. The Flight Reservation system prints out the details of the booking. 9. The Travel Agent asks the Customer how she wishes to pay, at which point the use case ends. | |
Extensions | 5a. No flights match the Customer’s criteria. 8a. The system cannot print the flight details. 9a. Handle Customer payment (Use Case: Customer Pays Invoice). |
Special requirements | No special requirements. |
Performance goals | The Flight Reservation system must display the list of available flights within 10 seconds. |
Outstanding issues | Need to identify the exact details and format of the booking information printed out by the Flight Reservation system. |
The plain language of use cases, which is both business- and technology-neutral, makes them ideal for communicating system behavior to both end users and developers. Use cases are important in RUP because they provide a common thread through many activities, particularly in the area of linking requirements to design. They also serve to focus the design, implementation, and testing efforts around a central set of requirements, which form the core of the system.
Use cases are organized by producing a use-case model. A use-case model is a UML diagram that graphically illustrates how the different use cases and actors interact. Models are useful for gaining an understanding of the relationships that exist between each use case and actor. However, the true value of use cases is in the text of the use case itself, not the diagram in the model.
Ivar Jacobson initially proposed the concept of use cases. As Jacobson’s Objectory is one of the foundation methodologies on which the RUP framework is built, it is not surprising that use cases are one of the driving forces of the process.
Although they are an important part of the process, use cases are not confined to object-oriented development and have enjoyed widespread acceptance in all manner of projects. They are an excellent technique for capturing and understanding customer requirements and are worth considering for inclusion in any methodology.
We next examine how the RUP framework centers on the use of iterations throughout the project lifecycle.
The process prescribes an iterative approach to development with timeboxed iterations. Here, all iterations occur over a fixed duration but have a variable scope.
A RUP iteration focuses on a subset of the system’s use cases. Within a typical iteration, the selected use cases are elaborated and a design is evolved followed by implementation and testing. The objective of each iteration is a functioning system. Should it appear that this objective will not be achieved, then the scope is reduced in preference to extending the timeboxed duration of the iteration or bringing more people on to the project.
The exact content of an iteration is dependent upon the particular phase of RUP within which the planned iteration is being conducted. Let’s examine the different phases of a RUP project cycle.
Conventional waterfall-based processes are broken down into phases according to specific software engineering activities, with phase names denoting the associated activity. We therefore commonly have requirements, analysis and design, implementation, and testing. Only a single type of activity is undertaken in each of these phases. For example, during the requirements phase, only work relating to the gathering, analysis, and documenting of requirements is performed. Absolutely no design, coding, or testing work is undertaken as part of this early phase.
RUP projects are also divided into the four discrete phases. These are inception, elaboration, construction, and transition. Unlike in the waterfall model, these phases are not aligned by activity but instead demark the achievement of a major project milestone. Phases within the process include a number of iterations, with each iteration serving to advance the project toward the phase milestone. As an iteration is a complete mini-waterfall project, we can expect to see the general activities of requirements, analysis and design, implementation, and testing being undertaken in each phase.
A common failing in implementing the RUP is to mistakenly associate these four phases with the four phases of the classic waterfall lifecycle. This is a fact Philippe Kruchten, one of the creators of RUP, went to great pains to point out with his fellow authors in the article, “How to Fail with the Rational Unified Process: Seven Steps to Pain and Suffering” [Larman, 2002].
Please note:
Inception does not equal requirements
Elaboration does not equal design
Construction does not equal coding
Transition does not equal testing
Here are the four phases of a RUP project and a brief description of the work undertaken in each phase:
Inception.
During inception, a preliminary iteration focuses on establishing a business case for the system. A small but critical set of primary use cases are identified, and based on these, the scope of the project is estimated, architectural options explored, and key risks assessed. Findings from this phase assist in determining if the project is viable and if it should continue on to the elaboration phase.
Elaboration.
Having made the decision to continue with the project, the elaboration phase shifts the focus of the project to iteratively constructing the architecture for the system. This exercise is conducted in parallel with a detailed investigation of the core requirements.
Iterations within the elaboration phase focus on refining these core requirements and constructing the architecture to the point where it can be demonstrated. Both requirements and the system architecture may undergo significant change during this phase because of feedback between the two tasks.
The output from this phase is a stable architecture on which the bulk of the functionality of the system can be built during the construction phase.
Construction.
With a stable architecture in place and most of the primary requirements defined, the construction phase looks to build the remaining functionality of the system on this stable platform. The objective of the iterations for this phase is a system that is ready for deployment into a beta testing environment.
Iterations in the fourth and final phase focus on producing a fully tested system, with all outstanding issues resolved, that is ready for final deployment.
Running throughout each of these phases are the different disciplines of a RUP project.
A discipline represents an area of work. Disciplines are undertaken in each iteration, although the degree to which each discipline is practiced depends on the current project phase. There are nine different disciplines:
Business modeling.
Seeks to describe an organization’s core business processes in order to assist in identifying the important requirements for the system targeted for development.
Requirements management.
Involves the gathering, structuring, and documenting of all requirements.
Analysis and design.
Involves the conception and demonstration of an architecture for the system that is capable of supporting the requirements of the system.
Implementation.
Writing, testing, building, and debugging the source code for the system.
Test.
Performing quality-assurance tests, such as functional, performance, and system testing.
Deployment.
Undertaking all the necessary tasks to ensure the system is deliverable into the environment of the end users.
Project management.
Planning and monitoring of the project.
Configuration and change management.
Associated with all tasks that relate to change control, versioning, and release management.
Environment.
Tailoring the process to a specific project and selecting and supporting the project infrastructure and associated development tools.
The amount of effort required in each discipline varies as the project traverses through the four different phases over time. Iterations in inception and elaboration phases will be heavy on the business modeling and requirements management disciplines. Later in the project, during the transition phase, effort in these disciplines will have trailed off but may still play a minor part in later iterations.
The RUP framework provides all the elements necessary for building a comprehensive project around the different disciplines. For each discipline, RUP defines a set of roles, activities, artifacts, and workflows that represent the core elements of the lifecycle model. Each of these elements is an answer to the questions of who, how, what, and when.
An artifact is a work product used to capture and convey project-related information. Artifacts can be documents, models, model elements, source code, or executables. Complete artifact sets are defined that align to each discipline; for example, artifacts from the analysis and design discipline include a software architecture document (SAD) and a design model.
Producing an artifact requires undertaking an activity. The RUP views an activity as a unit of work carried out by a member of the team with a specific role. Examples of activities for the analysis and design discipline include those of architectural analysis and database design. Artifacts resulting from these two activities include a software architecture document and a data model respectively.
RUP allocates responsibilities to members of the team by handing out roles. Roles are associated with a set of performed activities and owned artifacts. From the activities and artifacts mentioned so far, the software architect is responsible for undertaking the architectural analysis activity and producing the software architecture document artifact, while the database designer produces a database model as an artifact resulting from the database design activity.
Team members are not assigned a single role but instead take on a range of roles as and when the project dictates. On smaller projects, a member of the team may hold several roles if he is undertaking a range of activities, whereas large projects may require a single person to be dedicated to a particular role.
To work with the different artifacts, activities, and roles, we need more information than merely a list of each element. It is necessary to understand how each different element interacts as part of the process. This is the purpose of workflows.
A workflow is represented in RUP as a modified activity diagram illustrating how a particular set of activities is organized. Workflows equate to the disciplines we have already covered. In fact, a discipline is a type of high-level workflow, as disciplines represent a logical grouping of a set of artifacts, activities, and roles. A discipline is therefore one type of workflow. A second type of workflow is the workflow detail, which breaks disciplines down into finer levels of granularity.
Within RUP, we therefore have phases, iterations, disciplines, roles, activities, and artifacts. The question is how you go about combining all of these elements into a coherent project plan.
Planning is a key part of RUP, which encourages the production of two types of plan: a coarse-grained phase plan and a series of detailed iteration plans.
The phase plan is a single plan that spans the duration of the entire project from inception to transition. This high-level plan defines the anticipated dates for the major project milestones, the required project resources, and scheduled dates for each of the planned iterations.
The phase plan is created early in the project during the inception phase. Detailed planning is reserved for the iteration plan, which, like traditional management plans, allocates tasks to individuals and specifies minor milestone dates and project review points. Milestone dates within the iteration plan are made with an expectation of accuracy, as the estimates are made for near-term deadlines as opposed to the long-term forecasts of the phase plan. Toward the end of the iteration, the plan is concluded and work on the plan for the next iteration commences. Thus, in RUP it is common to have two iteration plans: one plan for tracking progress to schedule in the current iteration and a second plan that is under construction for the upcoming iteration.
Two of the most frequently asked questions regarding planning for iterative processes relate to how iterations should be structured throughout the project and what should be the length of an individual iteration.
For structuring the iterations within the project, Philippe Kruchten gives some guidance in an article on planning iterative projects [Kruchten, 2002]. For very simple projects, Kruchten suggests a single iteration for each of the four phases:
Inception: A single iteration to produce a user-interface prototype or mock up
Elaboration: One iteration to build a stable architectural prototype
Construction: One iteration to advance the software to the beta release stage
Transition: A last iteration to complete the final system
Where a large project with many unknowns in terms of both problem domain and technology is under development, Kruchten advises the following structure between the phases:
Inception: Two iterations to enable suitable prototyping activities
Elaboration: Three iterations to explore different solutions and technical options
Construction: Three iterations, or as many are required, to build in all the called-for functionality
Transition: Two iterations to incorporate operational feedback
The length of a timebox for a single iteration is governed by the size of the project team. Extremely large projects with hundreds of people involved require careful coordination in order to maintain momentum for the project. This coordination effort soaks up time and tends to lead to longer iterations. Smaller teams can work to iterations with shorter durations.
Ideally, iterations should be short and focused, running to weeks rather than months. Iterations of two to five weeks work well if the team size allows it. Where longer iterations are unavoidable, then consider setting minor milestones within the timeframe of the iteration. This helps keep the team focused on delivery and prevents risks from creeping back into the project. These minor milestones also help in tracking longer iteration plans.
Enterprise J2EE developments and RUP fit well together. The way in which enterprise projects are conducted can vary greatly based on both the customer and the development team involved. Thanks to the extensive range of elements RUP provides, the process can tailor to suit most situations.
The size and scope of enterprise developments varies immensely, ranging from teams with only a handful of developers to projects comprised of hundreds of people spread across geographically distant locations. The RUP framework supports both extremes and can meet the needs of small, adaptive style projects while also providing the high-ceremony artifacts necessary for developments conducted on a much grander scale.
Although RUP supports a lightweight adaptive approach, this is not the nature of the majority of enterprise-level developments. Traditionally, such projects are highly contractual, requiring upfront fixed-price quotes for agreed-upon levels of functionality. This type of engagement is the forte of RUP. Placing great importance on early prototype and investigation work helps to drive out the risks involved in this type of project.
Another factor in adopting RUP is the current trend for offshore development. Regardless of whether you favor this contentious practice, it has become a part of the IT industry. The extensive range of artifacts RUP defines makes it possible to conduct large projects with distributed development teams spread across the world. Here, elements of the process provide a common technical vocabulary between teams of different cultures and backgrounds, allowing them to work effectively and collaboratively on a system.
Furthermore, practitioners of best practice processes such as RUP are also able to convey a high degree of professionalism. When organizations are selecting software vendors, an important criterion is often their adopted development methodology. Companies with development teams who demonstrate a knowledge and investment in an established lifecycle model are more likely to win business than those companies who see little value in such methods.
RUP is not without its downsides. A major issue is the amount of time and effort that must be invested in knowledge and education of the process framework. The extensive nature of the framework means this investment is often considerable, as becoming expert in the use of the process requires both training and practical experience. Ensuring all team members receive sufficient upfront training before embarking on any project is an important part of developing an adaptive foundation within a company in order to facilitate rapid development methods.
If taking RUP on board is viewed as being too expensive, an alternative is to adopt the practices of a lightweight agile methodology. We look at the benefits of these methods next.
While the RUP framework allows for the adoption of either a lightweight or a heavyweight approach, RUP tends toward a high-ceremony, heavyweight process due to the emphasis it places on project artifacts.
In recent years, the software development community has invested significant effort in establishing overtly lightweight processes that rely on a minimum level of ceremony to deliver quality software solutions for systems with emergent or rapidly evolving requirements. Efforts in this area by the leading methodologists have given rise to a number of new development processes, collectively known as agile methods.
Processes of this type are based on incremental development with timeboxed iterations. They differ from process frameworks such as RUP in that they emphasize the importance of performing a particular activity rather than producing a specific artifact. Such processes lay claim to being people-centric as opposed to document-centric.
The software engineer has a number of these methods from which to choose, including SCRUM, Crystal, and feature-driven development (FDD). However, by far the most well known of the agile methodologies is XP, and it is this process that we cover next.
XP is a lightweight, agile process whose creation is attributed to Kent Beck, Ward Cunningham, and Ron Jefferies. XP was first put into practice back in 1996 by Kent Beck, who applied the process on the now famous C3 project at DaimlerChrysler. The process personifies the current crop of agile methods and targets small to medium projects with vague or rapidly changing requirements.
XP has created a huge buzz within the software development community, and much discussion still rages about the true benefits of its ultra-lightweight approach to development. Unlike most methodologies that stress the importance of upfront design and meticulous documentation, XP throws away the old rulebook and instead concentrates on the act of coding rather than documenting.
This standpoint has made the process immensely popular with hardcore developers, who have welcomed XP with open arms. To most software engineers, it was as if someone had announced that cigarettes, chocolate, and alcohol were all good for your health.
Unfortunately, the minimalist approach of XP has been interpreted by some engineers as being an excuse to discard many of the disciplines of software development and jump straight into the activity of coding. As we shall discover, this is not the intent of XP, and instead the method promotes a deliberate and highly disciplined approach to software development. Arguably, XP requires more discipline than RUP, which gives the engineer the option to omit many parts of the process. Instead, XP demands that you embrace all of its practices.
The RUP framework comes with an abundance of disciplines, activities, artifacts, and roles, any of which you may choose to incorporate in your project. XP is more concise and is essentially comprised of 12 basic practices, each of which you must follow in order to exploit the full benefits of the process.
These practices, or rules, of XP align with the key activities of planning, designing, coding, and testing. Each practice is undertaken in accordance with the XP values of simplicity, communication, feedback, and courage, which permeate the entire process.
Let’s begin with the 12 practices that make up XP:
Planning game.
Plan regularly and involve all members of the team in the planning activity, including the customer. Plans are devised based on business priorities supplied by the customer and technical estimates from the development team.
Small releases.
In line with the value of simplicity, first put a simple system quickly into production, and then release new versions over a number of short iterations.
Metaphor.
Have a simple shared story of how the system operates to guide all development effort.
Simple design.
Keep the design simple and avoid designing for unspecified requirements. Refactor out complexity as soon as it is discovered.
Testing.
Write unit tests continually and ensure they execute flawlessly. Automated unit tests are written ahead of the implementation of a class. Suspend development until a failed test has been rectified. Customers write tests to validate new features.
Refactoring.
Developers continually restructure the code base without changing its behavior to maintain simplicity, remove duplication, improve communication, and add flexibility.
Pair programming.
All production code is written by two developers working at a single machine.
Collective ownership.
Any developer can change any system code at any time.
Integrate all code as soon as any task is complete. Look to integrate all code several times a day.
Forty-hour week.
Stick to a 40-hour week. Never work overtime two weeks in a row.
Onsite customer.
Have an empowered representative from the customer working with the development team and available any time to answer questions or discuss requirements.
Coding standards.
All developers write code in accordance with a common set of coding standards, thereby emphasizing communication throughout the code base.
The 12 practices complement one another to the extent that to omit a single practice could cause the whole process to unravel. For example, simple design requires refactoring to remove unnecessary complexity; refactoring relies on the testing practice to guard against unintended changes in system behavior. XP therefore requires discipline from the team in ensuring all practices are employed on the project.
The practices of XP lay down the rules for how developers work on an XP project. To understand how an XP project is conducted, we need to look at the activities of XP.
Planning is a critical activity on any project, more so if the project is following an adaptive method. These methods require decisions on the direction of the project to be made at every step, and in close consultation with the customer, if the project is to be carefully steered toward a successful conclusion.
Planning on an XP project is a continuous activity driven by the feedback from both customers and developers. Like RUP, planning in XP occurs on two levels. The first level is the broad project plan, or release plan using XP terminology. This defines the overall structure for the project and gauges the number of iterations necessary to complete the system.
The second level of planning is the detailed iteration plan. This covers just a single iteration. Iterations in XP run for approximately two weeks, and the content of an iteration is decided upon based on the customer’s prioritized requirements and estimates from the developers for each requirement. A release is made at the conclusion of an iteration, as dictated by the practice of small releases.
Throughout the iteration, teams should look to integrate their work on a regular basis, as specified by the continuous integration practice. This avoids the danger of costly integration problems caused by last-minute integration efforts.
XP iterations are timeboxed, so discussion is required with the customer to determine which requirements must be included within the allocated timeframe. The need to collaborate closely with the customer in all aspects of the project, including its planning, gives rise to the XP practice of having an onsite customer.
Where RUP iterations are driven by use cases, XP iterations are planned around user stories. The function of an XP user story is similar to that of a use case but is considerably simpler and shorter, usually running to just a few sentences. The iteration evolves the story, but the “written” story remains in its original terse form. Like use cases, user stories also drive other project tasks, with acceptance tests being written for the stories provided.
Note
Acceptance testing is described in Chapter 15, Efficient Quality Assurance, along with tools for supporting the testing activity.
Figure 3-3 illustrates how user stories drive iterations within XP.
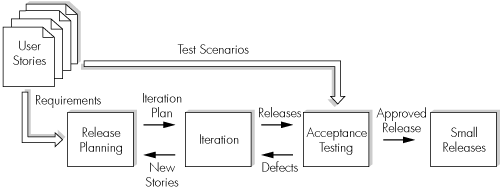
In addition to release and iteration planning, XP teams look to hold short, standup meetings at the start of each day to lay out the tasks for the day, arrange pair-programming teams, and discuss any issues that may have arisen since the last meeting.
Design is one of the most contentious areas of XP, as according to the main practices, followers of XP do not appear to do any design work. In contrast, RUP capitalizes on its links with the UML and uses modeling as the main design activity.
XP has no place for models, stating only that design should be kept simple, as per the simple design practice. This is enforced by the refactoring practice, which looks to remove complexity at every opportunity. Furthermore, all members of the team should have a common understanding, or metaphor, as to what the system is and how it works.
As for formal design processes, the original C3 project used Class, Responsibilities, and Collaboration (CRC) cards for running design sessions, and this technique has proven popular with some XP teams.
If the subject of design on XP projects is contentious, then the practice of pair programming, whereby two developers share a single machine, is positively explosive.
The arguments against pair programming are twofold. First, management becomes nervous about the productivity implications of having two developers constrained by the bottleneck of just one machine. Second, developers become almost territorial over a task they have taken responsibility for, and they have a tendency to feel threatened at the thought of having anyone closely scrutinizing their work. Frequently, developers cite the need for quiet time in order to fully focus on a problem, claiming the need to be “in the zone” in order to overcome technical development challenges.
Resistance to pair programming can be quite extreme, with developers vehemently denouncing the need for the practice. It is well worth reading the article “The Case Against XP”, by Matt Stephens, on the subject of pair programming and XP in general. This amusing article provides an opposing viewpoint to the practices of XP and can be found on the Software Reality site at http://www.softwarereality.com/lifecycle/xp.
If you have tried pair programming, you likely found it mentally exhausting. Having a second developer working with you on a piece of code seems to keep you constantly alert. Common distractions, such as getting up and making coffee or surfing the Web, get pushed to one side with a second pair of eyes on the screen. The excessive mental effort pair programming imposes is probably one of the reasons why XP recommends sticking to a 40-hour week.
The pair-programming practice came into being as an extreme reaction to code reviews. While they may sound like a good practice, code reviews, as they are commonly practiced, are a flawed quality-control process.
Code reviews are often left to the last minute on a project, by which time it is often too late to fix any of the problems identified by the review. Moreover, conducting a thorough review takes time, as the reviewer must form a clear understanding of the developer’s intent and approach. Seldom is enough time set aside to conduct a proper review. Likewise, reviewers often have their own tasks to complete and so frequently fail to invest the necessary effort in the review process.
The XP solution to the problems surrounding code reviews is to have them occurring all the time. Pair programming achieves this, since the developer pair is continually checking the code against both the requirements and the project’s coding standards. Mixing up pairs regularly ensures that no developer flaunts the project standards unnoticed. Furthermore, the practice also links in with collective ownership, as knowledge of the code is spread around the entire team.
Pair programming is making in-roads into mainstream development as more and more companies discover that two heads really are better than one. Some novel approaches are being formed that enable people to more easily work together in pairs. One group at HP undertook a distributed XP project and gave all developers hands-free headsets and desktop sharing software in order that team members could pair program remotely.
Pair programming does have its limitations and is not suitable for all programming tasks. A classic example is research or investigative work. Here, people really do need some quiet time to explore and read. However, if programmers are writing production code, then under XP rules, they should be doing so in pairs.
XP has single-handedly breathed new life into the concept of test-driven development, whereby tests are written ahead of any implementation.
Under XP, all classes in the project should have supporting unit tests. This practice enables refactoring of the code base without the danger of system behavior being impacted.
Unit tests also support the practice of collective ownership of the code. If a programming pair is changing code developed by other members of the team, the supporting unit tests will ensure they can do so without inadvertently destabilizing existing system behavior. The test suite should identify this situation if it occurs.
Upon identifying a defect, the programmer must write a unit test for the problem. This approach guards against the defect creeping back into the system.
Note
The test-first development approach is examined further in Chapter 14, Test-Driven Development.
Agile methods have gone to great lengths to reaffirm the importance of the individual worker. Early methodologies looked to downplay the role of the individual, seeking to make software development a production-like process, with IT staff undertaking factory-type roles.
Job descriptions in XP are sparse compared to the comprehensive list included under RUP. Nevertheless, this serves to underline the importance of the individual on the project and the significant contribution he or she makes.
True to the nature of the profession, software engineers on an XP project must be multi-skilled. They are expected to take part in the planning, designing, coding, and testing of the system. Thus, XP breaks away from the standard convention of defining specific roles for architects, designers, managers, coders, testers, and the like. XP places greater emphasis on generalists rather than on specialists, so if you’re working on an XP project, expect to get your hands dirty.
Unfortunately, J2EE developments often have a need for specialist skills due to the diverse range of Java-based technologies involved. It is not atypical to find developers who are expert in JSP but have never written an Enterprise JavaBean. Even fewer developers will have been near a J2EE Connector Architecture (JCA) adapter. This can be an issue, especially with the collective ownership practice. Attempting to get the entire development team through the learning curve associated with the intricacies of JCA technology in many cases just isn’t practical. Pair programming is one way of spreading the knowledge, but on complex J2EE systems, it is hard to avoid the need for specialization in a particular J2EE technology. XP does advocate the consultant role, which can help in this area.
The following list provides a brief description of the roles for an XP project, as defined by Kent Beck:
Programmer
The programmer is a fully fledged software engineer and represents the heart of the process. The programmer is involved in almost every aspect of the development, contributing to the planning, designing, programming, and testing of the system.
Customer
The business skills of the customer complement the technical skills of the programmer. A customer on an XP project is a decision maker, and by writing user stories and ongoing involvement in the project, steers the direction of the development. An XP customer is also a tester and takes on the responsibility for writing the functional tests that ultimately become the acceptance tests for the finished system.
Tester
As both the programmer and customer roles take on the responsibility for writing tests in XP, the role of the tester switches to focusing on the customer. The tester takes charge of ensuring all tests are incorporated into an automated build process and communicates the results of test runs to the team.
Tracker
A key to successful planning is the ability to compare actual task completion times to estimates. Iterative development benefits from this ability, as the estimation process can be refined between iterations. The tracker role is responsible for collating the actual times and providing these figures as feedback to the developers. The tracker also gauges the progress of the team against the overall goals of the project and uses this information for planning purposes.
Coach
The coach is the XP process expert and advises the team on all matters relating to the implementation of an XP project. This role diminishes as the project progresses, as collectively, the whole team begins to pick up responsibility for the process.
Consultant
The role of the consultant is to inject technical knowledge into the team as and when it is required. Consultants tend to be transient members of the group who pass on their valuable technical skills by mentoring the team in a particular problem area.
Big Boss
The final role is for the individual who is ultimately responsible for the project. The role involves helping to guide and assist the team through problems, acquiring additional resources as required, and making some of the hard decisions around delivery in consultation with the team.
Now that we’ve covered the main points of an XP development, let’s consider how well suited the process is for the development of a J2EE solution.
XP will be not be a perfect fit for all projects, since certain conditions must be present in order to get maximum benefit from the method. First, a business domain expert is required from the customer to work closely with the development team. This individual must be empowered to make key decisions about the direction and behavior of the system being developed.
The customer is not the only one who must commit to an XP development. Management must also back the approach and be prepared to embark on a project that may have uncertain requirements and no clear deliverables from the outset. This presents the manager with all manner of contractual challenges around price and delivery commitments.
For XP to work, the software engineers assigned to the project must be prepared to adopt its practices faithfully. XP is a disciplined process and requires teams to adhere to all of its practices in order for the process to operate effectively. Developers who don’t want to work in pairs and resent other developers changing their code would be better off placed on other projects—preferably with another company.
Even if all of these conditions are in place, XP is still not a good match for all project types. To quote from Kent Beck’s Extreme Programming Explained [Beck, 1999]:
Note
There are times and places and people and customers that would explode an XP project like a cheap balloon.
So, how well does XP gel with a J2EE-based project? Well, XP is technology-neutral. The original C3 project was an object-oriented project developed in Smalltalk, and XP has been used effectively with other programming platforms since then, so the use of the J2EE platform should not be a barrier to adopting XP.
When J2EE projects do find themselves hitting the limitations of XP has more to do with the nature of enterprise development than with the J2EE platform itself. Enterprise developments tend toward large teams, with a current trend toward having split-site development using offshore resources.
XP works best with small teams averaging around 10 people, and with the team members in close proximity. Big team sizes are definitely an issue for XP, as the lightweight process lacks the necessary ceremony to coordinate large numbers of developers. Nevertheless, XP as a process is still evolving, and work is currently ongoing to determine how XP can scale for larger projects.
Another major barrier to the use of XP on enterprise projects is the contractual nature of these developments. A fixed-price quote with clearly defined scope is the norm for an enterprise system. Working to these contractual constraints requires a level of predictability that does not sit well with the low-ceremony approach of XP.
Instead, XP in its current form favors inhouse, collaborative projects. Projects of this type fit the profile for an XP project extremely well. Onsite domain experts are often easily arranged, and as the customer and development team all work for the same company, the contractual requirements are not so stringent. It is possible to operate an XP project with an external customer, but a good relationship must be in place for the process to prove workable.
To conclude, XP and J2EE can work well together, but pick your projects with care. Don’t opt for an excessively lightweight process when the conditions call for something more substantial.
The characteristics of a software lifecycle methodology that uniquely qualify a process as being suitable for rapid development include the following:
Lightweight, by requiring the minimum level of procedure for the size and scope of the system under development
Complementary, to the techniques and tools you adopt as part of your adaptive foundation for rapid software development
Adaptive, so system changes can be easily accommodated by the process
Adaptive methods are preferable to conventional predictive approaches, as they offer the necessary techniques to accommodate changing requirements. The key to adaptive methods is their iterative approach to development, the benefits of which are:
Low risk, as early iterations are used to target identified areas of high risk early in the process
Well suited to projects with emergent requirements, as iterations refine the requirements over time
High quality, with testing being a continuous activity undertaken from the outset of the project
Improved customer satisfaction, as the customer plays an active role in guiding the evolution of the system
Two examples of popular methodologies offering iterative approaches are the IBM Rational Unified Process and the agile methodology, Extreme Programming.
Of these two, RUP provides an extensive process framework from which a tailored process can be designed for a particular project type. Due to its comprehensive list of activities and artifacts, RUP scales well and so is applicable for both small and extremely large projects. The ability of RUP to contend with large development projects, potentially with distributed development teams, makes it an ideal candidate for enterprise-level J2EE systems.
In comparison, XP offers a highly disciplined, ultra-lightweight process that has been proven to work well for small teams developing projects with the vaguest of requirements. It is easy to learn and is proving popular with the software engineers who have so far embraced its values and practices.
Now that we have covered some of the key concepts around the choice of a development process for rapid development, we can move on to the business of designing, building, and testing our J2EE solutions.
Philippe Kruchten, one the founding fathers of RUP, has openly criticized publications that misrepresent the practices of his process, particularly those that present it as a waterfall model. I’m confident I’ve done his creation justice, but if you want to hear about the process framework from the horse’s mouth, as well as learn more about RUP, then you should read his excellent book, The Rational Unified Process: An Introduction [Kruchten, 2003].
Numerous resources exist for XP, with volumes of material being published on the process. A good starting point is Kent Beck’s original text on the subject, Extreme Programming Explained [Beck, 1999]. A detailed online reference is also available for XP at http://www.extremeprogramming.org.
From my exposure to XP, I was always of the opinion that XP would be unsuitable for split-site development, especially for projects with the bulk of the development work taking place offshore. I may need to revise my opinion, as Martin Fowler has written a thought-provoking article on his experiences using XP with an offshore development shop in Bangalore. The article is available from http://martinfowler.com/articles/agileOffshore.html.
For more information on use cases, Alistair Cockburn has written a number of articles on the subject, which can found at his Web site at http://alistair.cockburn.us. His site also contains an example of a use-case template on which the example in this chapter is based. See http://alistair.cockburn.us/usecases/uctempla.htm.
The site also includes information on Alistair’s agile methodology framework, Crystal.