
Since Chapter 4, Designing for Rapidity, we have progressed from design concerns to modeling tools to code generation techniques. This chapter looks at Model-Driven Architecture (MDA), a model-centric software development approach that combines the practices of modeling and code generation into a single paradigm. MDA pushes both technologies to the extreme, using models as the basis for generating a substantial amount of the code for the entire application.
Vendors of MDA tools are promoting the paradigm as the next generation in software development, promising unprecedented levels of developer productivity and software quality.
This chapter examines the merits of these claims and assesses the benefits MDA offers the rapid developer. The chapter covers the concepts underpinning the paradigm and demonstrates the use of AndroMDA, an open source MDA product.
Throughout the history of the software industry, many new development tools and methodologies have emerged onto the IT landscape proclaiming to revolutionize software development. Sadly, many of these hoped-for revolutions in IT have failed to bring about improvements in the status quo, further supporting the argument of Frederick Brook that there is no silver bullet [Brooks, 1995].
MDA is the new kid on the block, and its advocates are not shy about proclaiming the virtues of the MDA paradigm. Only time will tell if MDA can succeed where so many other development approaches have failed.
The software engineering industry’s thought leaders are divided on the likely future for MDA, with some quarters dismissing the paradigm as unworkable. Nevertheless, the reasons for adopting MDA are compelling, and those advocating the uptake of MDA are pointing to an ever-increasing number of success stories as proof the paradigm is effective.
MDA encourages a business-centric approach to development and uses modeling as a means of allowing the architect to focus on business-critical system functionality without the distraction of technical implementation constraints. From these early models, MDA-compliant tools generate executable code, thereby reducing dramatically the effort involved in producing a functioning system.
This use of models and code generation means some of the touted benefits of MDA will sound familiar from our discussions in previous chapters:
Reduced development timeframes.
The focus of MDA is on models, not code. Models are produced at the business level and translated into code using sophisticated code generation tools. This ability to jump from business model to implementation cuts out much of the coding effort and enables a running system to be available early in the project lifecycle.
Consistent quality of software.
MDA puts the automated process of transforming models into a working implementation under the control of the architect. The architect can produce best-practice transformation rules for converting models to code. This transformation process can then be applied to every applicable development project, resulting in software that is of a consistent quality and standard.
Platform portability.
The models that initiate the MDA process are platform-neutral. By using code generators tailored to a specific platform type, MDA promises platform independence that enables systems to target any technology or framework for which a suitable code generator exists.
These are some of the promises; but what exactly is MDA, and how does it differ from the traditional use of models within the software development process? Moreover, how can MDA help us write quality J2EE solutions in a reduced timeframe?
Note
Models and the Unified Modeling Language are covered in Chapter 5.
To answer these questions, the next section walks through some of the main concepts underpinning MDA.
MDA is a model-based approach to software development defined by the Object Management Group (OMG), the same body responsible for administering the UML and CORBA. The aim of the paradigm is to enable a system to be fully specified using software models, independent of any supporting technology platform. This architectural separation of concerns between system and platform is an overarching principle for realizing the three primary goals of MDA:
Portability
Interoperability
Reusability
To this list, we could also add the development concerns of agility and rapidity.
The MDA approach defines a process whereby a working application can be generated from a business domain model, known as a platform-independent model (PIM). This leap from conceptual model to working application is achieved by the refinement of a series of models, with each model being generated at ever-decreasing levels of abstraction. The final model in the process is tightly coupled to the target platform, and from this, a substantial percentage of the code for a working application can be generated.
Let’s consider some of the core concepts that make up the MDA paradigm.
MDA uses the term platform to embody all the technical aspects of a system relating to its implementation. The MDA standard provides the following definition for the term:
platform definition
Technological and engineering details that are irrelevant to the fundamental functionality of a software component.
This definition covers such technical aspects as the choice of middleware, such as J2EE, or .NET, as well as such pressing technical design decisions as which design patterns to apply and what model-view-controller framework to adopt for the Web application.
As we shall see, MDA places great emphasis on platform neutrality and separates invariant business functionality from the design requirements of the target platform.
The MDA paradigm uses models for all of the benefits associated with modeling. Models are an extremely good means of communication, both with the customer and among members of the development team. They also provide a means to validate the design against any requirement changes throughout the project lifecycle using UML interaction diagrams.
Models can assist in the development of quality software, even if not supported by sophisticated modeling tools. Models drawn on the whiteboard or scribbled down on notepaper all contribute toward clearly articulating aspects of the system to the members of the project team.
MDA maximizes the benefits of modeling by making the model central to the development process and incorporates the strengths of automated application generation.
code generation with modeling tools versus MDA
The forward-engineering approach of modeling tools is fundamentally different than that of MDA.
Modeling tools generate code at the class and method levels; MDA tools generate nearly complete applications.
With MDA, models are transformed at ever-decreasing levels of abstraction until a functioning application is arrived at. The relationship between models that provide a view of the same system at different levels of abstraction is often called a refinement. This concept is pivotal to MDA, which sees models refined throughout the development process.
Two types of model form the backbone of the MDA paradigm: the PIM mentioned earlier and the specialized platform-specific models (PSM).
To this list could also be added the code model, or implementation. The OMG defines an implementation as a specification capable of providing all the information necessary to put it into operation. The source code produced for a particular implementation is considered a model by MDA, as it is executable by a machine.
Figure 8-1 depicts the lifecycle of the MDA models.
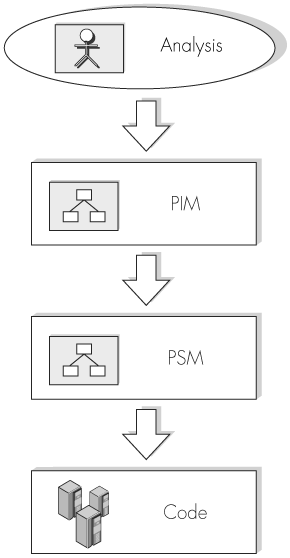
Let’s look at these two model types and the purpose each serves in the MDA lifecycle.
The PIM results from an intensive analysis phase and focuses on the core business functionality required by the customer. As the name suggests, the PIM gives a view of the system that is not constrained to any particular platform. Instead, the PIM embodies pure business behavior.
Not surprisingly, given the involvement of the OMG, the MDA approach recommends the use of UML notation for constructing the PIM, with class diagrams commonly used to describe the business domain. The UML is ideally suited to this type of model due to its rich and expressive syntax. Moreover, because the PIM is constructed in collaboration with the customer, UML diagrams are an effective mechanism for communicating system intent and behavior.
What the PIM does not show is the use of platform-specific technologies required to realize a working application. The next MDA model type provides this view.
The PSM is a refinement of a PIM for a particular platform, where the platform represents an actual operating system, framework, middleware, database product, or any of a number of system-implementation technologies. The PSM is therefore closely aligned with application code and is at a level where code can be directly generated from the structure the model defines.
The PSM is equivalent to the type of model produced with a modeling tool such as Together ControlCenter. It is at a low level of abstraction that sits just above the final implementation. Using a suitable transformation process, the PSM is further refined into executable application code.
The process of transformation between model types is known as mapping and is another core MDA concept.
The crux of the MDA paradigm is the method by which models are transformed on the journey from PIM to working application. Mapping is therefore one of the most fundamental MDA concepts, and the success of the paradigm hinges on how effectively this task can be automated.
Essentially, a mapping is a set of rules and techniques that enable one model type to be converted into another form, for example, mapping from a PIM to a PSM.
note
Mappings can be defined between any of the MDA models. For example, it is valid to map directly from the PIM to the code model.
The task of generating code from a PSM is well-known technology and is already demonstrated by established modeling tools such as Together ControlCenter and IBM’s Rational Rose. The greatest challenge for MDA-compliant tool vendors lies in the transformation of PIM to PSM.
In conventional development without MDA, the architect instructs the project team on how a PIM is to be rendered as an executable design. The architect may decide to implement the system’s Web application component using the Apache Struts framework instead of Java Server-Faces. Likewise, the architect may make the call to construct the persistence layer using Hibernate rather than entity beans.
Note
Hibernate and entity beans are discussed in Chapter 7.
The architect’s decisions are not simply a list of frameworks and technologies. The architect may elect to access the persistence layer via the use of the Data Access Object pattern, with Values Objects returned to the client application through a Session Façade.
These architectural directions, and many more, must all be applied by the design team in order to take a PIM to the point where it can be built as a working solution. For the MDA tool to go from PIM to PSM, it too must follow the same directions. This is a highly complex task with which even the best architects and designers still struggle.
The MDA approach states the transformation process can be manual, but the true benefits of MDA are only realized if this process can be automated by the use of software tools. In this regard, an MDA tool could be regarded as a form of expert system, because the process is one of applying the knowledge and skill of the experienced architect to the mapping problem.
Note
An overview of expert systems is provided in Chapter 10.
MDA tool vendors find themselves in the position of not only developing products capable of accurately performing this mapping, but also having to convince skeptical developers that such an approach is feasible. They must sell the concepts as well as the benefits of MDA against those of existing model-centric processes.
Modeling tools such as Together ControlCenter and Gentleware’s Poseidon enable the software engineer to use UML models to develop software applications. A question that commonly arises is how development processes centered on the use of tools such as these differ from an MDA development approach.
The similarities between the two approaches are not immediately apparent. Both look to leverage the power of modeling techniques to drive the development process, and the toolsets of each approach take time to learn. Moreover, neither claims to be an ease-of-use layer on top of J2EE. For each approach, strong technical knowledge and design skills are still a prerequisite as they are with traditional approaches.
Nevertheless, differences between MDA and other model-driven development methods do exist. The next sections highlight these differences by looking at the strengths and weaknesses of MDA for software development.
The defining difference between the two approaches comes down to the level of abstraction employed. MDA leverages the power of high-level PIMs to drive the development process. This higher level of working gives MDA fundamental advantages over conventional, technology-specific modeling processes.
The construction of a platform-independent domain model is not exclusive to the MDA paradigm. Domain models are commonly constructed at the outset of any model-centric approach.
Traditional modeling methods rely on the business model to establish an understanding of the problem domain with the customer. The architect uses the requirements captured in this early model to build a PSM, which can be readily converted into code by most modeling tools.
The construction of the PSM is a skilled and time-consuming task. Before the modeling tool can generate a functioning system, the design team must have defined a detailed PSM.
The modeling tool generates a system from the PSM, but it does not assist in the transformation of business requirements into a functioning system. Consequently, the architect finds his or her attention diverted away from the critical business needs of the customer, and instead becomes focused on the technical challenges of implementing a solution for a specific platform.
The need for the architect to design a PSM is a distraction that can result in the initial business model being neglected. Using conventional modeling tools, the PSM becomes the main focal point of the development effort.
MDA forces the architect to concentrate on the domain model, or PIM, first and regards the PSM as a stepping-stone on the way to a working application. The use of the PIM to drive the development process keeps the focus on the customer requirements and not on the implementation platform.
An MDA-compliant tool can convert a business model into a functioning application at the click of a button, with mapping rules filling in the gaps for the missing infrastructure required by the target platform. Admittedly, the generated system will be very raw and most likely lacking in critical business functionality. However, the generated application provides a solid foundation on which to build further functionality.
This ability to jump from business model to demonstrable application is perfectly suited to development processes founded upon short, incremental, iterative cycles. In this way, a working prototype can be constructed from a minimal model in an incredibly short timeframe. This type of development process has proven benefits, not just for rapidity but also for building systems that accurately meet the needs of the customer.
Traditional modeling tools provide a one-to-one mapping with the application code. Change a property on a class in a UML class diagram, and a single Java class is affected. Some model changes have no effect on the generated code. Switching an association between composition and aggregation, for example, is unlikely to result in any change to Java source.
With an MDA-compliant tool, a change in the PIM results in widespread change in the generated application. An update to a business entity in a PIM ripples through all layers of the architecture. The DDL generated for creating database tables changes; objects in the persistence layer change; business components change; and any corresponding Web application components change.
This ability to make sweeping and consistent application changes with a small modification to a conceptual model is a powerful feature of MDA tools, enabling customer requirement changes to be effected extremely rapidly.
A high percentage of defects found in application code are a result of code errors as opposed to incorrectly specified requirements. By using best-practice software generation methods in the mapping from PIM to PSM, the overall risk of code errors being introduced is significantly reduced.
Java is a crossplatform development language, which raises the question, Why would a paradigm whose focus is on platform independence be of relevance to anyone building J2EE solutions? The answer lies in the interpretation of the term platform.
J2EE is a constantly evolving platform. A search of the Java Community Process site at http://jcp.org is testament to the rapid rate of change Java technologies continually undergo.
A high-profile example is the EJB 3.0 specification, as defined by JSR-220, which has switched the focus of Enterprise JavaBeans from heavyweight components to lightweight POJOs, requiring minimal boilerplate code for deployment into the EJB container. Keeping pace with this change, and thereby keeping a system current, is an ongoing battle.
MDA, with its use of models to describe systems using platform-neutral semantics, can help extend the life of a system by ensuring the long-lived business functionality endures beyond the shorter-lived platform technology.
The MDA paradigm can make us more adaptive in relation to these fast-paced technology changes. For software engineers, MDA reduces the cost of change, making it possible to adopt emerging Java-based technologies without requiring prohibitively expensive application upgrades.
This is a good thing for any system, as it helps ward off the unwanted label legacy application.
Powerful as the MDA paradigm appears to be, it is not without an Achilles’ heel. Some of the weaknesses in the paradigm are as follows.
One area where MDA tools fall behind their conventional modeling counterparts is in working with existing applications and data structures. Modeling tools can reverse-engineer applications into model form. However, as code is a representation of the system implemented on a specific platform, the models these tools build are all platform-specific. They do not reverse-engineer to the level of the PIM.
Mapping from PSM to PIM is complex and hard to automate. Most MDA tools focus their efforts on mapping from PIM to PSM. Consequently, anyone looking to reverse-engineer to a PIM in order to use an MDA approach has a hard task. The MDA standard specifies a mapping from PSM to PIM; currently, however, few tools can satisfactorily demonstrate this particular mapping.
Even if a PIM is produced for an existing system, problems still face the MDA practitioner. The power of an MDA tool to effect sweeping changes in the application code by a small change to the PIM is likely to prove too intrusive on the underlying application. It is akin to using a chainsaw where a scalpel is required.
Due to the technical challenges involved in mapping back to a PIM, traditional modeling methods are likely to prove more effective when extending or working with existing applications and data structures. Although an MDA approach should not be ruled out, a modeling tool is likely to prove the more effective software tool in this scenario, because it enables the architect to make small, strategic changes to what might be a fragile architecture.
In theory, MDA is the ultimate solution for rapid development. Produce an accurate, high-level model of the system requirements, press a button, and generate the system. In practice, though, the million-dollar question is, does it work?
The approach sounds both simple and obvious, but then, you could also state that the obvious method to reduce the traveling time between New York and London is to use technology that supports instantaneous teleportation. While the idea may sound good on paper, and it is possible to produce a long list of benefits for using teleportation technology over a commercial airline, making the concept a reality is another matter entirely.
Mapping from PIM to PSM is a difficult task. Ordinarily, this is a challenging task for a skilled design team; successfully automating the process has to be harder still.
It is in this critical area that opponents of MDA claim the paradigm falls down. MDA opponents argue the current state of the technology is not yet at a stage where a quality application can be produced without intervention from a skilled software engineer.
Despite this claim, tools are available that claim to be MDA-compliant. Moreover, the OMG proudly lists a growing number of MDA success stories on its Web site at http://www.omg.org/mda/products_success.htm.
The best way to establish the truth is to judge for ourselves by looking at a current MDA tool and analyzing how it addresses the problems inherent in mapping between models.
The list of commercially available MDA-compliant tools is a short but growing list. Two of the market leaders are OptimalJ from Compuware Corporation and ArcStyler from Interactive Objects Software. Both products are sophisticated, enterprise-level MDA offerings pursuing the MDA vision for the next generation of software development tools.
A trial version of OptimalJ Professional Edition is available from the Compuware Web site at http://www.compuware.com. A community edition of ArcStyler can be downloaded from http://www.io-software.com.
Although both tools support platforms other than J2EE, it is interesting that both have a Java bias. This is a common trend: Java is supported by more code generators than any other language. It would be nice to believe this fact is a result of the willingness of the Java community to embrace cutting-edge software engineering methods, though skeptics might argue it is a sign of serious shortcomings in both Java and J2EE.
In keeping with the stated preference for using software that is freely available to demonstrate the concepts discussed within this book, we use the services of an open source MDA tool.
It is perhaps an indication of the growing acceptance of the viability of MDA that an open source MDA product has emerged. AndroMDA, pronounced Andromeda, is the product of considerable hard work by its founder, Matthias Bohlen, and his dedicated team of contributors.
Matthias’s first release of the tool went under the name of UML2EJB and focused on generating EJB from UML models. The success of the tool prompted a widening of scope, and the development team moved away from pure EJB generation toward an MDA-compliant tool. The result of their efforts was a revamped UML2EJB, subsequently renamed AndroMDA to reflect its MDA approach.
AndroMDA is freely available for download from the product’s Web site: http://www.andromda.org. Full instructions for installing and running AndroMDA come with the software.
The AndroMDA distribution also includes a complete example that can be deployed into the JBoss application server. Rather than walk through a similar example, we look under the hood of AndroMDA to see how the product transforms models into code. This information will help familiarize you with the product and provide an insight into how AndoMDA can be customized to perform your own PIM-to-PSM mappings.
Compared to the slick commercial MDA products, AndroMDA offers a nuts-and-bolts approach to practicing MDA. It provides no form of visual development environment, instead initiating the entire MDA process using an Ant build file.
It may seem strange that a tool proclaiming to support MDA should have no means of visually building a PIM. This is in stark contrast to products like OptimalJ that offer a complete integrated MDA development environment with support for building the initial model through to editing, deploying, and debugging the generated application. In this regard, OptimalJ rates as a complete MDA implementation.
Due to the wide scope of the MDA domain, the MDA standard states MDA can be practiced using a federated collection of tools, each supporting a specific aspect of the process. For example, a tool may focus on support for mapping from PIM to PSM, while another generates code from the PSM. MDA makes this approach possible by ensuring models are shareable between tools.
AndroMDA relies on a suitable modeling tool to first generate the PIM from which it can start the code generation process. AndroMDA generates a working application with the template engine Velocity and the attribute-oriented programming product XDoclet.
Note
Chapter 6 covers both Velocity and XDoclet.
Figure 8-2 provides an overview of MDA with AndroMDA.
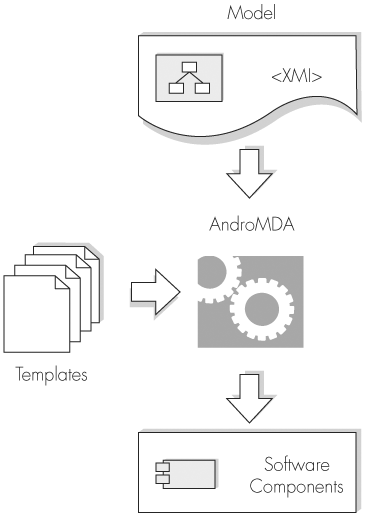
Moving from PIM to working application with AndroMDA involves a number of steps:
A PIM is generated using a modeling tool capable of exporting the model in XML Metadata Interchange (XMI) format.
AndroMDA imports the PIM and builds an in-memory representation of the model.
Configurations settings in the Ant build file used to invoke AndroMDA define pluggable MDA cartridges that provide a mapping between the PIM and the working application.
The MDA cartridges associate special identifiers in the object model, known as marks, with templates that generate code from the model.
Depending on the MDA cartridges installed, where necessary, AndroMDA may generate customizable implementation classes that can be modified by the developer to add functionality to the generated application.
To conclude the process, all generated code is compiled and deployed into the target environment.
note
Notice in Figure 8-2 that AndroMDA foregoes the mapping to a PSM and instead goes directly to the implementation model. This direct transformation from PIM to code is a valid MDA approach and complies with the MDA standard.
Commercial MDA tools such as OptimalJ support the generation of a PSM. Generating a PSM allows the architect to further refine the PSM and so gives greater control over the application generated. AndroMDA users must rely on the pluggable MDA cartridges to produce suitable output. However, refinement of the model is possible under AndroMDA by modifying the templates used by the relevant MDA cartridges.
The steps outlined introduce several new MDA concepts, such as marks and cartridges, which warrant further explanation.
AndroMDA uses the XMI specification for importing models built with a modeling tool. XMI is another OMG standard that, along with standards such as UML and MOF, has been bundled under the MDA umbrella.
Unfortunately, while XMI is a standard for model interchange, like ice cream, it comes in many different flavors. In practice, these different flavors, or dialects, virtually negate the benefits of the XMI standard, because different dialects raise compatibility issues between modeling tools. This situation is at odds with the MDA concept of sharing models between tools.
Due to this confusion over the XMI format, you may find you cannot use your favorite modeling tool for generating a model that can be imported into AndroMDA. To avoid this problem, you can use a modeling tool the AndroMDA team states is compliant with an XMI dialect AndroMDA expects. One such product that has close ties with AndroMDA is Poseidon from Gentleware, a commercial spinoff from the open source modeling tool ArgoUML. A community edition of this product is available from the Gentleware Web site at http://www.gentleware.com. The community edition offers a good feature set and supports the exporting of models as XMI.
An AndroMDA plug-in has been developed for Poseidon that integrates the two products and enables AndroMDA to access a Poseidon model in its native format. Full details of this plug-in are available from the Gentleware and AndroMDA sites.
If Poseidon is not to your liking, MagicDraw from No Magic is also recommended. A community edition of MagicDraw is obtainable from http://www.magicdraw.com.
Despite the richness of information conveyable by a UML model, tools that perform the mapping between PIM and PSM often require some direction as to how a mapping should be performed. The MDA standard provides several guidelines for the mapping process, one of which is the use of marks.
Marks identify those elements within a PIM that must be transformed with a predetermined set of transformation rules. The marks themselves can be from a variety of UML-compliant sources, including:
Type information for model elements such as classes or associations
Specific roles within the model
Stereotypes
The use of stereotypes is one of the more common approaches to marking the PIM, and this is the method used by AndroMDA.
Stereotypes, a concept from the UML, are a means of extending the UML. They enable model elements to be embellished with additional values, constraints, and if required, a new graphical representation. Essentially, they serve as metaclasses within the UML. Declaring a model element to be of a particular stereotype causes the element to take on the full list of characteristics associated with the stereotype.
The UML notation has the name of the stereotype enclosed within guillemets, or chevrons. Perhaps the stereotype with which most people are familiar is the <<interface>> stereotype. Although Java supports the use of interfaces through a reserved keyword, other languages do not, and the UML relies on a specialized form of the class type to represent elements with this behavior. The <<interface>> stereotype expresses the constraint that all methods of the class are abstract. The stereotype further allows UML tools to render classes of this type using a circle for the notation instead of the classic rectangle.
The <<interface>> stereotype is already well used by the code generation facilities of most modeling tools. Such tools know how to generate Java interfaces from elements expressing this stereotype instead of generating Java classes.
We can declare stereotypes for our models as we wish and have the MDA tool map them accordingly. Figure 8-3, drawn using MagicDraw, depicts a simple class diagram showing stereotypes known to AndroMDA. Table 8-1 summarizes the stereotypes used in the example model. These stereotypes are used during code generation to direct output.
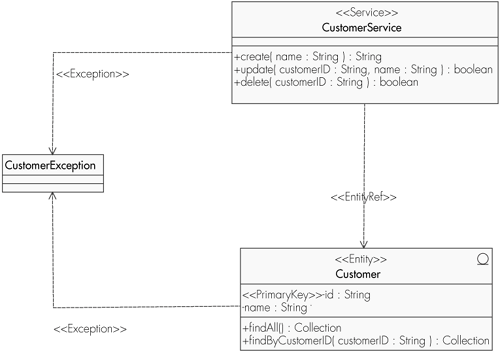
Table 8-1. AndroMDA Stereotypes
Stereotype | Description |
|---|---|
<<Entity>> | Denotes an object in the business domain. |
<<Service>> | Identifies a class that acts on domain objects. |
<<PrimaryKey>> | Unique identifier for persistent domain object. |
<<FinderMethod>> | Method to query for domain object from persistent store. |
<<EntityRef>> | Identifies relationship between classes that MDA cartridge must be aware of. |
<<ServiceRef>> | |
<<Exception>> | Denotes an exception that must be thrown by all business methods of a dependent class. |
<<WebAction>> | Maps to the controller part of a Web application using the model-view-controller paradigm. |
<<WebAppConfig>> | Web application configuration object. |
<<WebForm>> | Maps to the model part of a Web application using the model-view-controller paradigm. |
<<WebPage>> | Maps to the view part of a Web application using the model-view-controller paradigm. |
The PIM shown in Figure 8-3 has a stereotype for each class. Adding the stereotype <<Service>> to CustomerService marks the class as being a provider of some form of business service. In a PIM, we are unconcerned with how the customer service is represented in the final system. Likely, implementation options include a Web Service, an enterprise bean, or even an RMI object.
A stereotype of <<Entity>>, as shown on the Customer class, indicates some form of domain model object, which requires persistence. Again, how this persistence is implemented is the concern of the transformation process. The modeler defers the decision as to whether technologies such as entity beans, JDO, or an O/R mapping product like Hibernate will be used. Although this model is supposed to be platform-neutral, admittedly the operation findByCustomerID() has distinct EJB architecture overtones.
Not only the classes but also the associations and operations in the diagram have been marked. The dependency association between CustomerService and Customer carries a stereotype of <<EntityRef>>. Likewise, the attribute id has been stereotyped with <<PrimaryKey>>. All of this metainformation is used by AndroMDA to determine the architecture of the application generated.
Next, we examine how AndroMDA transforms model elements into code based on their stereotype.
AndroMDA code generation is driven by stereotypes. Stereotyped elements in a PIM are mapped to code using pluggable code generation cartridges, with cartridges existing to specify the transformation rules for each AndroMDA stereotype.
We saw a similar approach used with Middlegen, albeit without the use of stereotypes. Middlegen allows different persistence mechanisms to be supported with plug-ins. Our example used the Hibernate plug-in to generate Hibernate configuration files based on metadata retrieved from the database. Other Middlegen plug-ins exist for entity beans and JDO. Middlegen delegates the task of generating code to its plug-ins. Middlegen itself takes responsibility for interrogating the database for the necessary metadata, supplying this information to all plug-ins configured from the Ant build file.
Note
Middlegen is covered in Chapter 7.
AndroMDA plays a similar role to Middlegen, except AndroMDA obtains its metadata from a UML model instead of the database. An AndroMDA cartridge is similar to a Middlegen plug-in insofar as they both generate code from metadata.
Four cartridges come complete with the AndroMDA distribution:
andromda-ejb.
This cartridge generates a persistence layer using entity beans with session beans acting as a Session Façade over the persistence layer.
Like Middlegen, AndroMDA provides a cartridge for building a persistence layer using the Hibernate O/R mapping tool. With the Hibernate cartridge, Java classes are generated with embedded Hibernate XDoclet tags. Session beans are also laid down over the Hibernate based persistence layer.
andromda-java.
This is the simplest of the four cartridges and generates Value/Transfer Objects.
andromda-struts.
No system is complete without a Web front end. The
andromda-strutscartridge generates all the files necessary for a Web application based on the Apache Struts framework.
The AndroMDA core searches the classpath to locate any installed cartridges. Model elements that have a known AndroMDA stereotype are passed to each cartridge discovered on the classpath.
Cartridges are configured under the <andromda> Ant task. This task points AndroMDA at a PIM and specifies those cartridges used for generating the application. Listing 8-1 shows a section taken from an Ant build file of a build configuration using the andromda-struts cartridge.
Example 8-1. AndroMDA Build File
<andromda basedir="." modelURL="${model}.xmi" lastModifiedCheck="true" typeMappings="${andromda}/src/xml/TypeMapping.xml"> <userProperty name="foreignKeySuffix" value="_FK" /> <outlet cartridge="java" outlet="value-objects" dir="${gen.dir}" /> <outlet cartridge="hibernate" outlet="entities" dir="${gen.dir}" /> <outlet cartridge="hibernate" outlet="entity-impls" dir="${impl.dir}" /> <outlet cartridge="hibernate" outlet="session-beans" dir="${gen.dir}" /> <outlet cartridge="hibernate" outlet="session-impls" dir="${impl.dir}" /> </andromda>
The nested element <outlet> configures the location of all source generated by each cartridge’s outlet. An outlet is essentially a template defined within the MDA cartridge. We look at the function of outlets in the next section. Each cartridge is referred to by its name, as specified using the cartridge attribute, with the outlet attribute identifying the outlet within the cartridge.
The ability to direct generated source to different locations is important, as some generated classes are intended to be modified by the developer. This fits in with the code generation guideline of separating actively generated code from code maintained by hand.
In the next section, we deconstruct the anatomy of an AndroMDA cartridge to determine how it generates code from a UML model.
Cartridges enable a stereotype to be married to a template. AndroMDA uses the Apache Velocity as its template engine, making the task of building a cartridge simple for anyone familiar with the Velocity Template Language (VTL).
Note
For a summary of VTL commands, see Chapter 6.
The MDA standard states a mapping may include templates, which it describes as parameterized models for specifying a particular transformation. Templates offer a very powerful mapping mechanism and enable entire design patterns to be generated from a single mark in the PIM.
The secret to how a cartridge associates a stereotype with a Velocity template lies in the cartridge’s deployment descriptor. Each AndroMDA cartridge must provide a deployment descriptor named andromda-cartridge.xml that resides under the META-INF directory in the jar file.
Listing 8-2 shows the deployment descriptor for the andromda-hibernate cartridge.
Example 8-2. AndroMDA Hibernate Cartridge Deployment Descriptor
<cartridge name="hibernate">
<property name="persistence" value="hibernate" />
<stereotype name="Entity" />
<stereotype name="Service" />
<outlet name="entities" />
<outlet name="entity-impls" />
<outlet name="session-beans" />
<outlet name="session-impls" />
<template
stereotype="Entity"
sheet="templates/HibernateEntity.vsl"
outputPattern="{0}/{1}.java"
outlet="entities"
overWrite="true"
/>
<template
stereotype="Entity"
sheet="templates/HibernateEntityImpl.vsl"
outputPattern="{0}/{1}Impl.java"
outlet="entity-impls"
overWrite="false"
/>
<template
stereotype="Entity"
sheet="templates/HibernateEntityFactory.vsl"
outputPattern="{0}/{1}Factory.java"
outlet="entities"
overWrite="true"
/>
<template
stereotype="Service"
sheet="templates/HibernateSessionBean.vsl"
outputPattern="{0}/{1}Bean.java"
outlet="session-beans"
overWrite="true"
/>
<template
stereotype="Service"
sheet="templates/HibernateSessionBeanImpl.vsl"
outputPattern="{0}/{1}BeanImpl.java"
outlet="session-impls"
overWrite="false"
/>
</cartridge>
The first clue to how the AndroMDA core triggers a cartridge is with the <stereotype> elements:
<stereotype name="Entity" /> <stereotype name="Service" />
These two lines associate the cartridge with model elements bearing the stereotypes of <<Entity>> and <<Service>>. The cartridge generates code for model elements based on either of these two stereotypes using a template. AndroMDA allows multiple template types to be associated with a single stereotype, thus several templates can be used in generating the code for a single model element.
The <template> element maps stereotypes to templates:
<template
stereotype="Entity"
sheet="templates/HibernateEntity.vsl"
outputPattern="{0}/{1}.java"
outlet="entities"
overWrite="true"
/>
The stereotype attribute declares the stereotype being mapped, while the sheet attribute points AndroMDA at the Velocity template for code generation. Templates are bundled as part of the cartridge jar file, and along with the deployment descriptor, are all that is required for a valid cartridge.
The outlet attribute links the template to the <outlet> custom Ant task specified under the <andromda> task in the Ant build file. This setting informs the Velocity engine of the location of all output generated with the template.
The overWrite attribute enables AndroMDA to differentiate between code that is actively generated and code that is modified by the developer. For classes where the developer adds business functionality, setting the overWrite attribute to false ensures modified code will not be overwritten each time AndroMDA is run.
The final part of a cartridge is the Velocity templates referenced in the deployment descriptor. These templates perform the mapping from the UML model to code. The AndroMDA core makes available information on model elements to the template. This information can then be rendered as required with the VTL.
Table 8-2 lists the objects supplied by AndroMDA for use in the Velocity templates.
Table 8-2. AndroMDA VTL Scripting Objects
Object | Description |
|---|---|
| Holds the model imported via the XMI file in the form of a UML 1.4 model. |
| Represents the UML model element from which code will be generated. |
| Helper object for transforming model objects into a printable form, thereby making them easier to use from VTL. |
| Helper object for performing string formatting operations. |
| The current date as a |
To appreciate how these objects can be used from within a template, an extract of a template from the andromda-java cartridge is shown in Listing 8-3.
Example 8-3. Cartridge Template Extract from ValueObject.vsl
public class ${class.name} implements java.io.Serializable
{
#foreach ( $att in $class.attributes )
#set ($atttypename = $transform.findFullyQualifiedName($att.type))
private $atttypename ${att.name};
#end
...
#foreach ( $att in $class.attributes )
#set ($atttypename =
$transform.findFullyQualifiedName($att.type))
#if ( ($atttypename == "boolean") ||
($atttypename == "java.lang.Boolean") )
/**
#generateDocumentation ($att " ")
*
*/
public $atttypename
is${str.upperCaseFirstLetter(${att.name})}()
{
return this.${att.name};
}
#else
/**
#generateDocumentation ($att " ")
*
*/
public $atttypename
get${str.upperCaseFirstLetter(${att.name})}()
{
return this.${att.name};
}
#end
public void
set${str.upperCaseFirstLetter(
${att.name})}(${atttypename} newValue)
{
this.${att.name} = newValue;
}
#end
}
The template example in Listing 8-3 illustrates the use of AndroMDA scripting objects to define the attributes in a Java class, complete with getter and setter methods. The template illustrates how easily information can be pulled from the model and transformed with a Velocity template.
By building your own cartridges or manipulating the cartridges AndroMDA supplies, all manner of transformations are possible from the model. Existing templates can be modified to meet your own coding standards, or you may add a template to the cartridge to generate unit tests for certain model elements.
AndroMDA makes it easy to create cartridges that can be tailored to the needs of your project. This extensibility makes AndroMDA a powerful model-driven code generation framework.
The powerful and versatile code generation features of AndroMDA make it ideal for rapid development. As do most MDA-compliant tools, it has excellent potential for prototyping, since a nearly complete framework for the application can be generated very quickly. Furthermore, requirements changes can be readily reflected in the application by updating the model and regenerating.
As is the case with most MDA tools, the downsides of the paradigm also apply to AndroMDA; specifically, difficulties can arise when working with legacy systems.
Two questions are often asked concerning AndroMDA: Can the tool perform roundtrip engineering from source to model, and how does AndroMDA guard against overwriting handwritten code?
You cannot reverse-engineer from code back to the model. Although this feature is expected of any high-end modeling tools, the MDA-compliant tools take a different approach to model-driven development than do modeling tools like Together ControlCenter.
Reverse engineering is a problem for MDA-compliant tools due to the difficulties inherent in transforming from a PSM to a PIM. To avoid the need to undertake this difficult mapping, MDA tools instead look to protect code modified by the developer, allowing the PIM to be changed and new code generated without overwriting any business logic added by the developer.
This brings us to the next question: If we are updating the PIM and regenerating each time, how are the business rules implemented in the code preserved between build cycles?
No matter how sophisticated the UML model, all MDA-generated applications of any real complexity will require further modification by a developer. Such modifications are required in order to add the all-important business rules to the application. It is therefore vital the MDA tool treats all handwritten code as sacrosanct and preserves the state of modified code between generation cycles.
The methods of safeguarding handwritten code vary between MDA tools. High-end tools such as OptimalJ have the concept of guard blocks, areas of code that the developer must not modify. By using the OptimalJ development environment, the OptimalJ code editor ensures this rule is followed. Any code modified outside of these guarded areas is preserved.
Tools like AndroMDA, which do not control the editing of Java source, must resort to other means. AndroMDA generates special implementation classes that are updated with application-specific behavior by the developer. When an AndroMDA build is next initiated, AndroMDA detects the presence of these classes and ensures they are not overwritten.
The implementation classes typically extend generated classes. A change to the UML model, which results in a change to the superclass of an implementation class, should be flagged as an error by the compiler. Although this approach leaves the developer with work to do in the event of a domain model change, no handwritten code is lost.
The information in this section applies to version 2.0 of AndroMDA. At the time of writing, Matthias and his team are hard at work on version 3.0. This new version looks to increase the sophistication of the transformation process and introduces several new features:
A
bpm4strutscartridge capable of generating Web-based workflows from UML activity diagramsModel validation at the time of code generation
Pluggable template engines, giving options other than Velocity
A new EJB cartridge able to support Java inheritance of abstract enterprise beans
Developers are invited to look in on the progress of the new version at http://team.andromda.org.
This site for version 3.0 looks very professional. If the quality of the site is backed up by the quality of the software, then the next version of AndroMDA will be worth waiting for.
Keep your eye on the AndroMDA Web site for all breaking news.
MDA is touted as a potential revolution of the software development process, claiming improved developer productivity, reduced development timeframes, and higher quality software. All of these points make MDA worthy of consideration for anyone undertaking a rapid development project.
MDA technology is still improving, and the dream of fully executable UML models is still unrealized. Despite this, the current crop of MDA tools are well suited to the development of new applications and the generation of prototypes, making MDA products ideal for incremental development processes.
Where MDA tools are less effective is when working with existing systems or legacy data. In this scenario, conventional modeling tools are likely to prove a more productive option.
Regardless of whether you consider MDA a viable technology for software development, the use of AndroMDA to leverage the power of model-based software generation makes it a valuable tool to add to the enterprise software engineer’s repertoire, even if it is used purely for prototype generation.
The next chapter moves on to domain-specific languages and looks at how languages other than Java can be applied to the development of enterprise systems.
All of the OMG standards documents on MDA and its associated standards can be freely downloaded from the OMG Web site at http://www.omg.org. Current information on MDA is available from the same site at http://www.omg.org/mda.
The OMG also has a guide available to the MDA paradigm, at http://www.omg.org/docs/omg/03-06-01.pdf.
The AndroMDA team operates a mailing list for all discussions relating to the practice of MDA with AndroMDA. For help and advice on using AndroMDA, see http://sourceforge.net/mail/?group_id=73047 or try the newer “Tiki” at http://team.andromda.org/tiki/tiki-index.php.