
Chapter 4. Producing and consuming Restlet representations
In part 1 of the book, we had several opportunities to discuss representations. In chapter 1 we briefly explained that representations in REST are used to transfer resource state. We pointed to appendix A for an overview of the org.restlet.representation package and to appendix D for details on RESTful representation design, covering the definition of representation classes and the importance of hypermedia as the preferred mechanism to interact with an application in REST. Finally we manipulated basic representations in chapters 2 and 3 using the StringRepresentation class and using the converter service to return String instances directly, without needing to wrap them in a complete representation.
In this chapter we explore in detail how to create and consume real-world representations. As XML is a primary language for RESTful representations, a large part of this chapter covers its deep support in Restlet. What you learn will also be applicable to other textual formats or media types. As an illustration we use a mail representation from appendix D and expose it in various formats using Restlet extensions.
4.1. Overview of representations
In the previous chapters we mainly explained how to work with resources and animate them with RESTful method calls. When needing to expose a representation on the server side or display one on the client side, we used the StringRepresentation class or the String class. Even though this is sufficient for basic cases, in real life you will find many reasons to go beyond that—for example, working with large representations and using automatic serialization and deserialization of regular Java objects to media types such as XML and JSON.
All those possibilities are based on the org.restlet.representation package introduced in chapter 1 and a set of Restlet extensions. In this section we explore this package, starting with root Variant and RepresentationInfo classes used to describe representation variants. We then continue with the abstract Representation class and the various subclasses provided to deal with byte and character content.
4.1.1. The Variant and RepresentationInfo base classes
This section provides a closer look at those two classes, starting with a class diagram in figure 4.1.
Figure 4.1. The Variant and RepresentationInfo classes are ancestors of all Restlet representations.

The purpose of the Variant class is to describe a representation with enough metadata for content negotiation to work. Content negotiation is a powerful feature of HTTP that we cover in section 4.5, but for now you can see Variant as the ancestor of all representations, containing the most important properties as detailed in table 4.1.
Table 4.1. Variant properties
Note that each of the properties in table 4.1 relies on classes located in the org.restlet.data package—that is, CharacterSet, Encoding, Language, and MediaType. For the identifier property we rely on the Reference class, which allows flexible manipulation of any kind of URI reference. These classes provide constants for common meta-data such as CharacterSet.UTF_8, Encoding.ZIP, or MediaType.APPLICATION_XML.
The RepresentationInfo class extends Variant to provide the two additional properties, shown in table 4.2. Its purpose is to support conditional method processing in an optimized way, without having to build full representations when a condition does not hold. First it adds the tag property based on the org.restlet.data.Tag class and a modificationDate property based on the usual java.util.Date class.
Table 4.2. RepresentationInfo properties
|
Name |
Description |
Equivalent HTTP header |
|---|---|---|
| modificationDate | Timestamp of this representation’s last modification | Last-Modified |
| tag | Validation tag uniquely identifying the content of the representation | ETag |
Because this sort of optimization is an advanced topic, we address it in chapter 7, section 7.4.5. For now, view it as a holder of additional representation properties you should try to set.
4.1.2. The Representation class and its common subclasses
Let’s continue our overview of Restlet representations with the abstract Representation class itself, the superclass of all concrete representations. Figure 4.2 gives an overview of this class, its parent RepresentationInfo class, and its main properties and methods.
Figure 4.2. The abstract Representation class is the superclass of all Restlet representations.
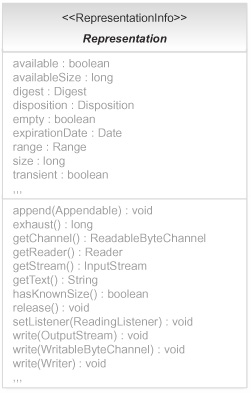
In REST, representations correspond to the current or intended state of a resource. They’re composed of content as a sequence of bytes and metadata as a collection of properties.
The content of a representation can be retrieved several times if there is a stable and accessible source, like a local file or a string. When the representation is obtained via a temporary source like a network socket, its content can be retrieved only once. The transient and available properties are available to help you figure out those aspects at runtime.
Properties in addition to those provided by Variant and RepresentationInfo are added by the Representation class, as summarized in table 4.3. They use the Digest, Disposition, and Range classes from the org.restlet.data package.
Table 4.3. Additional Representation properties
|
Name |
Description |
Equivalent HTTP header |
|---|---|---|
| available | Indicates whether some fresh content is available, without having to consume it. | N/A |
| availableSize | Size effectively available. This value is the same as the size property except for partial representation where this is the size of the selected range. | Content-Length and Content-Range |
| digest | Value and algorithm name of the digest or checksum associated to the representation. | Content-MD5 |
| disposition | Suggested download filename for this representation. | Content-Disposition |
| expirationDate | Future timestamp when this representation expires. | Expires |
| range | Range within the full content where the available partial content applies. | Content-Range |
| size | Size in bytes if known, UNKNOWN_SIZE (-1) otherwise. | Content-Length |
| transient | Indicates whether the representation’s content is transient, meaning that it can be obtained only once. | N/A |
In addition to all those properties, the Representation class provides many ways to consume its content, such as the getStream(), getReader(), getChannel(), and getText() methods that return, respectively, an instance of the java.io.InputStream, java.io.Reader, java.nio.ReadableByteChannel, and java.lang.String classes.
Another common way to consume the content of a representation is to ask it to write itself onto a target medium like a java.io.OutputStream, java.io.Writer, or java.nio.WritableByteChannel via one of the available write(...) methods. (Note that this approach requires the calling thread to block, which isn’t optimal for asynchronous handling.) Figure 4.3 summarizes how the content of any Restlet representation can be consumed.
Figure 4.3. The various ways to consume representations’ content

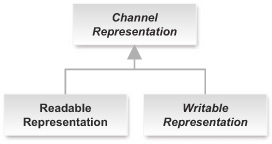
When you need to provide a concrete representation, you rarely start from scratch with this abstract Representation class but instead use one of its subclasses. The four class diagrams in figures 4.4, 4.5, 4.6, and 4.7 present the hierarchy of base representations provided in the core Restlet API. (Classes with italicized names are abstract.)
Figure 4.4. Subclasses of representation

Figure 4.5. Character-based representation classes
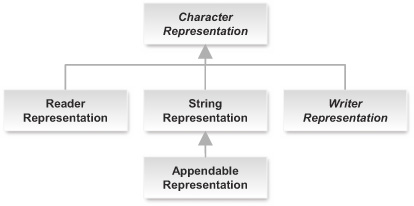
Figure 4.6. BIO stream-based representation classes
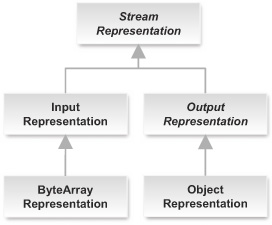
Figure 4.7. NIO channel-based representation classes
You’ve already seen StringRepresentation in earlier chapters, but notice in figure 4.5 that a convenient subclass called Appendable-Representation lets you build a string in several steps without having to supply the full text at construction time.
Keep in mind that additional representations are provided by Restlet extensions. We cover some of these extensions later in the book, but we encourage you to check the Javadocs and additional online documentation for comprehensive coverage.
As explained later in this chapter, the converter service reduces the need to manipulate those representation classes directly, but it’s nonetheless important to be familiar with them and to be able to manipulate them occasionally. The following listing shows a little sample of how an AppendableRepresentation wraps textual content that grows dynamically and that can be manipulated in various ways.
Listing 4.1. Manipulating the AppendableRepresentation

If you run this test case, it should succeed as no exception is thrown and the assertion is valid. The console should also print four lines with the abcd1234 content. We will have other opportunities to discuss these representation classes, such as in section 7.4 when explaining how to improve the performance of your Restlet applications.
Although the classes discussed define the foundation of all Restlet representations, you will often prefer to use more specific classes, such as SaxRepresentation, Jaxb-Representation, JsonRepresentation, and JacksonRepresentation, to handle complex structures like XML or JSON documents. The goal is to use higher levels of abstraction instead of working with representations at the byte or character level. The next section extensively covers different ways of dealing with XML representations.
4.2. Producing and consuming XML representations
As XML is the most popular format used by REST resources to expose their state as representations, it’s essential to cover how the Restlet Framework supports them. XML is as important for programmatic REST clients as HTML is for human REST clients. It’s a generic markup language with numerous concrete applications such as Atom for web feeds, DocBook for technical publications, RDF for semantic description of resources, and SVG for vector graphics, among others.
As you’ll see in this section, the Restlet Framework provides numerous powerful and extensible ways to produce XML representations, consume and validate them, transform them, extract specific content, and bind them to regular Java beans.
The first ways to produce and consume representations as XML documents are based on the standard DOM and SAX APIs, which offer very fine-grained levels of manipulation—for example, allowing evaluation of XPath expressions, handling of XML namespaces, and validation against XML schemas. We introduce three convenient Restlet extensions (org.restlet.ext.jaxb, org.restlet.ext.jibx, and org.restlet.ext.xstream) supporting the automatic binding between XML representations and regular Java objects. JAXB is a standard API built into Java SE since version 6, and JiBX and XStream are powerful open source libraries.
To illustrate those features, we represent the Homer mail resource number 123 introduced in section 2.4.7 as an XML document. This resource corresponds to a specific email resource that would have been received by the Homer user of our RESTful mail system. Having an XML representation of this email allows its retrieval in other applications—for example, in indexing and search purposes. Figure 4.8 illustrates this use case, with the resource identified by the /accounts/chunkylover53/mails/123 absolute URI.
Figure 4.8. Example resource exposing an XML document as representation

For reference, the following listing shows the XML mail document that we want to expose and consume as a representation of the Homer mail resource.
Listing 4.2. The target XML mail representation
<mail>
<status>received</status>
<subject>Message to self</subject>
<content>Doh!</content>
<accountRef>
http://www.rmep.org/accounts/chunkylover53/
</accountRef>
...
</mail>
Before using DOM and SAX support available in Restlet via the DomRepresentation and SaxRepresentation, you should know about their parent XmlRepresentation class.
4.2.1. The org.restlet.ext.xml.XmlRepresentation class
The XmlRepresentation abstract class has been provided since version 2.0 of the framework in the org.restlet.ext.xml extension. As illustrated in figure 4.9, it first contains a set of mostly Boolean properties that allows the configuration of SAX and DOM parsers in a way similar to the properties defined in the standard JAXP API provided in Java SE in the javax.xml.parser package.
Figure 4.9. Partial details of the base XmlRepresentation class

The default values of those properties are typically sufficient to get started, so we don’t present them in detail in this book, but you can refer to Restlet Java-docs if you want to know more about each of them. Additional properties are also available and will be introduced in other subsections.
In the methods compartment, we find two constructors and four methods that can be used to manipulate an XmlRepresentation instance as a JAXP source object for integration purposes. The last static method is a convenience method that can aggregate all the text content of a given DOM node. More methods are available; they’re introduced in the subsections covering XML namespace handling, XPath expression evaluation, and XML schema validation. Speaking of DOM, the next section shows how to concretely build and parse XML representation as DOM documents.
4.2.2. Using the DOM API
The Document Object Model (DOM) API was defined by the W3C and provides a standard way to manipulate an XML document in Java as a hierarchy of node objects. As the document is fully stored in memory, this API allows node navigation, insertion and removal. The main drawback is the memory consumed, especially for large documents.
In Java SE, the org.w3c.dom package and subpackages provide the DOM API itself, mostly as a set of Java interfaces, whereas the javax.xml.parser package provides the classes to parse XML documents as DOM documents. In Restlet, we support DOM-driven manipulation of XML documents with DomRepresentation, also part of the org.restlet.ext.xml extension.
As illustrated in figure 4.10, the Dom-Representation class contains two properties, document and indenting. The document property is the DOM document object that has been parsed or that has been created empty (by default) and that can be written as XML content using the standard representation methods such as getStream() or write(OutputStream). The indenting Boolean property indicates if XML content should be pretty printed with nice indentation or written in a more compact way.
Figure 4.10. Properties and methods of the DomRepresentation class

Regarding constructors, the first two assume that you want to start with an empty DOM document that you will later edit via the document property, and the third provides an existing Document instance as a starting point. The last constructor can parse XML representations, independent of the Representation subclass used, into a DOM document object. Note that in this case the parsing is done lazily, only when the getDocument() method is invoked. Providing several representation constructors for different purposes is a common and important Restlet API design pattern.
The methods compartment contains three methods that can be useful for advanced scenarios. For example, createTransformer() can be overridden to customize the way the DOM document is serialized as XML.
For the mail server example, imagine that you want to use DOM to produce the XML representations of emails exchanged with your clients. As illustrated in the following listing, we first create a simple test application where you can attach the MailServerResource class on the proper URI template.
Listing 4.3. Simple test application serving mail resources
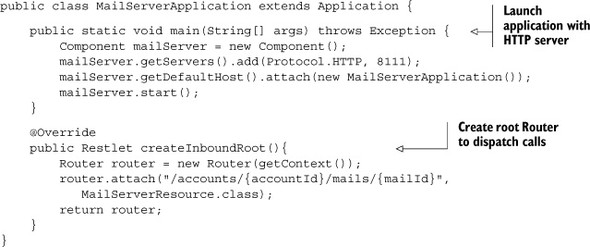
Nothing much is new in listing 4.3, so check out listing 4.4 for the MailServer-Resource class, which uses a DomRepresentation. This class supports the GET and PUT methods to illustrate the generation of a DOM representation as well as its parsing.
Listing 4.4. Mail server resource using the DOM API


If you’re familiar with the DOM API, listing 4.4 should look simple and natural. If not, we recommend reading the Java & XML book [2] which also covers other ways to manipulate XML in Java, which we explore in the rest of this chapter.
The following listing shows a simple mail client that will first GET the XML mail and then PUT it back in the same state.
Listing 4.5. Mail client retrieving a mail, then storing it again on the same resource
public class MailClient {
public static void main(String[] args) throws Exception {
ClientResource mailClient = new ClientResource(
"http://localhost:8111/accounts/chunkylover53/mails/123");
Representation mailRepresentation = mailClient.get();
mailClient.put(mailRepresentation);
}
}
To try it out, we first launch the MailServerApplication class, thanks to its main method, and then the MailClient. The output you should see in the console, ensuring that DOM document creation, serialization, deserialization, and parsing are working as expected, looks like this:
Status: received Subject: Message to self Content: Doh! Account URI: http://localhost:8111/accounts/chunkylover53/
Let’s now imagine that the mail XML representation is getting very large and that your server has to handle many of them at the same time. You can’t hold all the DOM documents in memory, so you need to look at alternative approaches. The SAX API introduced in the next subsection is an excellent solution to this problem.
4.2.3. Using the SAX API
The Simple API for XML (SAX), defined by David Megginson, provides a standard way to manipulate an XML document in Java as a stream of events. Because the document isn’t fully stored in memory, this API allows processing of infinitely large XML documents. The main drawback is that it’s harder to process and modify XML because it must happen on the fly, whereas the DOM API is easier to process with but can use a lot of memory.
In Java SE, the org.xml.sax package and subpackages provide the SAX API itself, as a set of Java interfaces and classes, whereas the javax.xml.parser package provides the classes to parse XML documents as SAX event streams. In Restlet we support SAX-driven parsing and writing of XML documents with SaxRepresentation, also part of the org.restlet.ext.xml extension.
As illustrated in figure 4.11, the Sax-Representation class contains a single source property that is the source of SAX events, typically a Restlet XML representation. Note that this property only describes the source—in the same way that java.io.File is only a file descriptor. In order to get the XML content, you need to explicitly call the parse(Content-Handler) method. On the other side, if you want to write a SAX representation, you need to produce SAX events on the fly by overriding the write(XmlWriter) method. Regarding constructors, the first two assume that you want to produce SAX events, and the other constructors will set up the saxSource property to parse XML content.
Figure 4.11. Properties and methods of the SaxRepresentation class

The following listing illustrates those features with the same example that we used for the DomRepresentation, but this time using a SaxRepresentation.
Listing 4.6. Mail server resource using the SAX API


If you execute the MailClient again with this different code, you will obtain the exact same output on the console. Note how we used an anonymous subclass of SAX’s DefaultHandler to get called back by the SAX parser each time a parsing event occurs, such as the start of an element. In this case the parsing logic is rather straightforward, but it can quickly get complex if your XML structure is deep or if the same element name is used in several parts of the document, as you will have to maintain some sort of state machine. The great advantage again is the ability to parse very large XML representations using limited system resources.
Now let’s look at a convenient way to extract specific content from an XML representation using XPath.
4.2.4. Evaluating XPath expressions
When we introduced the XmlRepresentation class, we didn’t list all the available methods. The additional methods in figure 4.12 evaluate XML Path Language (XPath) expressions. XPath is a W3C recommendation that can be used to address specific parts of an XML document. It can be used standalone (explained soon), inside XSLT documents (see subsection 4.2.7), or in other places such as XQuery or XPointer (not covered in this book—refer to other books or online documentation for more information). In Java SE, the javax.xml.xpath package contains a standard API for XPath engines.
Figure 4.12. XPath-related methods of the XmlRepresentation class

The XmlRepresentation class and its two concrete DomRepresentation and SaxRepresentation subclasses can call those methods to evaluate an XPath expression passed as a string parameter and return a single Boolean, a DOM Node, a Double number, or character String.
When the expression is expected to return several items, you can use getNodes(String) which returns an instance of org.restlet.ext.xml.NodeList. Note that this Restlet’s NodeList class implements both the List<Node> and DOM’s Node-List interface by wrapping an instance of DOM’s NodeList. The advantage is that you can use this structure in a loop thanks to its iterator, whereas DOM’s interface has to be manually iterated.
The following listing shows the result of implementing the PUT method of the MailServerResource to use XPath expression to get the elements’ content.
Listing 4.7. Mail server resource using the XPath API

As before, if you run the MailClient you will obtain the same output in the console. Compared to the DOM and SAX equivalents listed earlier, this PUT method implementation is very simple. And we barely used XPath’s capabilities; there is an extensive XPath functions library.
The advanced topic of XML name-spaces and how the XmlRepresentation subclasses can handle them continues our exploration of XML support in Restlet.
4.2.5. Handling XML namespaces
XML namespaces allow the mixing of XML elements and attributes from several vocabularies in the same XML document. Namespaces are identified by URI references, and prefixes are used as shortcuts.
In Java SE, XML namespaces are supported by two packages: javax.xml with its XMLConstants class containing common namespace URI references and prefixes, as well as the javax.xml.namespace package and its NamespaceContext interface, which is implemented by our XmlRepresentation class. Figure 4.13 lists the three methods of NamespaceContext plus the namespaceAware Boolean property used to activate its support in the DomRepresentation and SaxRepresentation subclasses, and the namespaces property, containing a modifiable map of namespace prefix and URI references.
Figure 4.13. XML namespace-related properties and methods of the XmlRepresentation class

Now it’s time to add XML namespace support to the example MailServerResource. In the following listing we update the example based on DomRepresentation to create an XML element inside a dedicated RMEP namespace with a URI of www.rmep.org/namespaces/1.0.
Listing 4.8. Mail server resource-handling XML namespaces


In the GET handling method, we used the createElementNS(String, String) method from the DOM API to create XML elements qualified with the RMEP namespace. If you try to obtain the XML representation in a browser entering the URI reference http://localhost:8111/accounts/chunkylover53/mails/123, you will obtain the following document. Note that a default namespace (without prefix) is declared with the xmlns attribute on the root mail element:
<?xml version="1.0" encoding="UTF-8"?>
<mail xmlns="http://www.rmep.org/namespaces/1.0">
<status>received</status>
<subject>Message to self</subject>
<content>Doh!</content>
<accountRef>http://localhost:8111/accounts/chunkylover53/</accountRef>
</mail>
Coming back to listing 4.8, let’s present the method-handling PUT requests. We still use the XPath approach but this time have to declare namespaces—otherwise the code from subsection 4.2.4 would no longer work. To illustrate the flexibility provided in XPath expressions, we declare two prefixes for the same RMEP namespace URI: “” for the default namespace and “rmep.” Then we can qualify the XML elements to select, such as :mail or rmep:mail. We encourage you to run the MailClient again to verify that the console output is still the same!
Even if this mechanism adds some complexity, it allows you to mix several XML languages in the same document, which is necessary with languages such as Atom XML for web feeds. Let’s continue our exploration of XML features provided by Restlet with XML schemas—powerful mechanisms to validate the correctness of the structure and content of XML documents.
4.2.6. Validating against XML schemas
Imagine that you need to validate the XML documents submitted by users of your applications and warn them precisely about the cause of the refusal. How would you do it?
XML schema languages such as W3C XML Schema (XSD) and Relax NG (RNG) can help. Let’s see how to use them in Restlet with the XmlRepresentation by first looking at the remaining properties and methods listed in figure 4.14.
Figure 4.14. XML schema validation-related properties and methods of the XmlRepresentation class

Restlet largely relies on the features of the javax.xml.validation package to offer an integrated, simpler way to validate XML representations. For example, the schema property is an instance of the Schema class from this package, but there’s also a setSchema(Representation) method that allows you to provide the schema using any type of Restlet representation—but with the media type correctly set (application/x-xsd+xml for W3C XML Schemas, application/relax-ng-compact-syntax, and application/x-relax-ng+xml for Relax NG).
Note that DTDs are an older way to validate XML documents, built directly inside the XML language. DTD has been largely deprecated, so we recommend you use XML Schema or modern alternatives such as Relax NG or Schematron instead. In case you need DTD validation at parsing time, you can turn the validatingDtd Boolean property to true.
Let’s now illustrate how this could be used with our example mail resource. The W3C XML Schema in the following listing corresponds to our current mail XML format.
Listing 4.9. W3C XML Schema for the mail XML representations
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
xmlns:rmep="http://www.rmep.org/namespaces/1.0"
targetNamespace="http://www.rmep.org/namespaces/1.0"
elementFormDefault="qualified">
<element name="mail">
<complexType>
<sequence>
<element name="status" type="string" />
<element name="subject" type="string" />
<element name="content" type="string" />
<element name="accountRef" type="string" />
</sequence>
</complexType>
</element>
</schema>
This schema defines a root mail element as a sequence of four elements: status, subject, content, and accountRef, themselves of the datatype XSD string. With the proper definition of the target namespace, this schema matches the XML representation produced in the previous subsection.
The next listing shows how to ensure that the XML representations PUT to your mail resource validate against this schema. There are two steps: first set the schema property and then set the errorHandler to catch parsing errors and warnings.
Listing 4.10. Mail server resource handling XML namespaces


Now you can run the MailClient against this new resource to verify that the XML representation received by the PUT method is indeed valid. Then change the name of an element in the GET method—for example, mail to email—to observe that a failure to validate produces a log entry on both the server and client sides, with an explicit description of the error.
Note that it’s not usually a good idea to systematically require inbound XML documents to conform to a given schema. Web browsers are flexible about the format of the HTML documents they can parse, so you should consider giving this level of flexibility to your users, using XPath for parsing, for example. But when you send output XML documents, you should try to respect any provided schema as closely as possible. This general internet rule was nicely summarized by Jon Postel: “Be conservative in what you do; be liberal in what you accept from others.” (“DoD standard Transmission Protocol.” http://tools.ietf.org/html/rfc761.)
Restlet’s XML support isn’t limited to static XML documents. With XML transformations, you can produce representations in other text formats.
4.2.7. Applying XSLT transformations
XSL Transformations (XSLT) is a standard XML transformation language that is natively supported by Java SE, thanks to the javax.xml.transform package and sub-packages. It’s ideal for producing other markup-oriented XML languages such as HTML or XHTML or XML vocabularies.
Here we want to illustrate the use of the TransformRepresentation class, part of the org.restlet.ext.xml package described in figure 4.15. Note that unlike Dom-Representation and SaxRepresentation classes, TransformRepresentation is a oneway converter. The two important properties are sourceRepresentation, which defines the wrapped XML representation to be transformed, and transformSheet, which contains the XSLT document to apply to the source to obtain the resulting TransformRepresentation. Other properties support more advanced configuration options. All the methods mentioned provide ways to customize the default behavior.
Figure 4.15. Properties and methods of the TransformRepresentation class

To illustrate this feature we transform the example XML mail into a format used by Restlet’s extension for JavaMail.
Introducing JavaMail extension
To add support for the SMTP and POP 3 protocols to your Restlet application, you can use the JavaMail API directly in your resource classes. But the org.restlet.ext.javamail extension provides an easier-to-use and more flexible alternative that’s also more RESTful. The idea is to use a pseudoprotocol based on the SMTP and POP URI schemes, as in
smtp://host[:port] pop://host[:port]
Authentication is handled using the ChallengeResponse class (introduced in chapter 5) and the SMTP_PLAIN, POP_BASIC, and POP_DIGEST authentication schemes. The client connector provided is capable of sending and receiving emails using either the Java-Mail Message class or Restlet’s specific XML format, as follows:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<email>
<head>
<subject>Account activation</subject>
<from>[email protected]</from>
<to>[email protected]</to>
<cc>[email protected]</cc>
</head>
<body>
<![CDATA[Your account was successfully created!]]>
</body>
</email>
When sending an email out, you need to POST an email representation to the relaying SMTP server defined by the target smtp:// URI. When reading an email from your inbox, you GET it from the POP3 server defined by the target pop:// URI. Generally you first need to retrieve the representation of the list of available emails as Restlet’s specific XML document.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<emails>
<email href="/1234"/>
<email href="/5678"/>
<email href="/9012"/>
<email href="/3456"/>
</emails>
Now that you have a better understanding of the JavaMail extension and the XML representations required, you can use XSLT to achieve your original goal.
Applying the XSLT Transformation
The next listing contains the XSLT transform sheet that we’ll apply to the example XML mail representation to obtain the desired JavaMail XML format. We could use this capability to provide a bridge between our RESTful mail system and traditional SMTP and POP servers.
Listing 4.11. XSLT transform sheet

The transform sheet contains a skeleton for the target XML document we want to produce, including xsl:value-of elements using XPath expressions in select attributes to dynamically insert content from the source XML representation.
Look at the modified MailServerResource in the following listing.
Listing 4.12. Mail server resource applying an XSLT transformation

As you can see, the code is straightforward; the hardest part is writing the XSLT transform sheet. If you call GET on the resource in your browser, you will obtain the following output:
<?xml version="1.0" encoding="UTF-8"?> <email> <head> <subject>Message to self</subject> <from>[email protected]</from> <to>[email protected]</to> </head> <body>Doh!</body> </email>
Now you can run the MailClient again and observe the expected values for the subject and body XML elements on the console log.
The Transformer class in org.restlet.ext.xml can provide a Restlet filter to systematically apply the same XSLT transformation to incoming request entities or to outgoing response entities.
This overview of the Restlet XML extension is now over, but the Restlet Framework provides additional ways to handle XML, thanks to the integration with XML binding libraries such as JAXB, JiBX, and XStream. These are the topics of the next three subsections.
4.2.8. Using the JAXB extension
Java Architecture for XML Binding (JAXB) is a standard Java API that’s built into Java SE version 6.0 but is also usable with Java SE 5.0 as an additional library. Compared to DOM and SAX, it works at a higher level, providing marshaling (serialization) and unmarshaling (deserialization) between Java classes and XML documents.
You can use JAXB in three ways. The first and most common is to start from a W3C XML Schema and generate the corresponding Java classes using the provided xjc tool. The second way uses the provided schemagen tool to derive an XML Schema from Java classes. And you can manually annotate your own Java classes to generate the correct XML documents. All three approaches can be customized and work fine, but starting from an XML Schema is definitely a convenient and productive way.
Let’s generate the JAXB artifacts from the Mail.xsd file that we introduced in subsection 4.2.6; the following listing shows the command line to accomplish this.
Listing 4.13. Compiling the XML Schema into JAXB annotated Java classes
xjc -npa -p org.restlet.example.book.restlet.ch04.sec2.sub8
org
estletexampleook
estletch04sec2sub8Mail.xsd
The xjc tool produces two Java classes in the example package: Mail, containing your four simple properties, and Object-Factory, acting as both a factory and a JAXB registry.
The Restlet extension for JAXB is available in the org.restlet.ext.jaxb package. The main class, JaxbRepresentation<T>, is illustrated in figure 4.16. It either parses an XML representation into a given Java class or generates an XML representation given a Java object. All properties are optional; in this example we set the formattedOutput property to get nice indentation and line breaks for easier debugging in a web browser.
Figure 4.16. Properties and methods of the JaxbRepresentation class

It’s time to rework the mail example using JAXB and compare with previous approaches. The following listing contains the new MailServerResource.
Listing 4.14. Compiling the XML Schema into JAXB annotated Java classes

The resulting code is very simple, and the parsing logic produced is optimized and naturally provides schema validation. Although you gained productivity, you lost some flexibility, such as the ability to interact with the XML parsing logic. For example, it’s harder to make evolutions to schema without requiring changes to existing clients of your application. This is the usual drawback of these kinds of abstractions, but they’re so powerful that it is hard to resist using them!
In addition to JAXB, the Restlet Framework supports several alternatives, which we introduce in the next section.
4.2.9. Alternative XML binding extensions
Although JAXB is a standard binding solution for Java, it comes with the drawbacks discussed, leaving some place for alternative solutions. In the Restlet Framework, we decided to support three alternatives: EMF, JiBX, and XStream. It would be easy to support others if necessary.
The first extension is for Eclipse Modeling Framework (EMF), an open source library-facilitating, model-driven development with code generation and tooling within Eclipse IDE. You can use EMF to define representation structures and generate the matching representation beans in Java for use with Restlet-annotated interfaces. The generated classes extend base EMF classes by default, which doesn’t fit very well with other XML serialization mechanisms supported by the Restlet Framework.
But EMF comes with its own serialization capabilities. By default, EMF lets you serialize any EMF object as XML Metadata Interchange (XMI), a generic XML language originating from UML to exchange diagrams. Plus, if your EMF model was created by importing an XML Schema, EMF is capable of producing and consuming regular XML representations, conforming to the original schema.
Logically the org.restlet.ext.emf extension uses this capability with an Emf-Representation class and a related converter helper. EmfRepresentation can produce simple HTML representations, even distinguishing property values corresponding to hyperlinks by adding special EMF eAnnotations to your model. Those annotations need to be defined in the www.restlet.org/schemas/2011/emf/html namespace and then contain an entry with the linked name and a true value.
The second extension is for JiBX, an open source library providing XML binding. JiBX uses byte code enhancement instead of Java reflection and a special pull parser to obtain the best parsing and generation performance. It also offers a rich XML language to define the mapping between the XML structure and the Java structure. To define the binding, it provides tools to start from either code or an XML schema. For more information read the Javadocs of the org.restlet.ext.jibx package and the JiBX project’s documentation itself.
The third extension is for XStream, another open source library providing XML binding. This library has a focus on ease of use—for example, removing the need for mapping information in many cases. It is also a nonintrusive solution that can work with Java classes over which you have no control, which can prove very convenient. For more information read the Javadocs of the org.restlet.ext.xstream package and the XStream project’s documentation itself.
It’s time to wrap up our coverage of XML representations, which took you from the low-level SAX and DOM APIs to higher-level JAXB and XStream binding libraries. Although XML is an excellent format for most REST representations, it isn’t the most compact and can affect performance of intensive AJAX applications. That’s why an alternative JSON format has emerged, with a lighter syntax and fewer features. In the next section you’ll discover that the Restlet Framework provides an equivalent support for JSON, with the exception of validation, transformation, and XPath-like selection, which aren’t available yet for JSON.
4.3. Producing and consuming JSON representations
JavaScript Object Notation (JSON) is a lightweight data format that’s typically used for exchanges between AJAX clients and web services. You can use JSON in other situations, but keep in mind that it’s simpler than XML. For example, there’s no standard like XPath to select content from JSON content, nor is there one like W3C XML Schema to validate a JSON document.
The Restlet Framework has extensive support for JSON, thanks to three dedicated extensions. In this section we continue to illustrate Restlet features using our example Homer mail resource—except this time exposing and consuming a JSON representation, as illustrated in figure 4.17.
Figure 4.17. Example resource exposing a JSON document as representation

For reference, the JSON mail document that we want to expose and consume as a representation of the Homer mail resource is in the following listing.
Listing 4.15. The target JSON mail representation
{
"content":"Doh!",
"status":"received",
"subject":"Message to self",
"accountRef":"http://localhost:8111/accounts/chunkylover53/"
}
The first way to build and consume representations as JSON documents is an equivalent of the DOM API for JSON. We then introduce two convenient Restlet extensions (org.restlet.ext.xstream and org.restlet.ext.jackson) supporting the automatic binding between JSON representations and regular Java objects.
4.3.1. Using the JSON.org extension
The www.json.org website is the official home of the JSON language and provides a Java library to manipulate JSON documents that lives in org.json.* packages. It’s similar to the DOM API for XML documents in the sense that it stores all the JSON data in memory when parsing, but this is rarely an issue because JSON documents are not generally intended to be very large due to AJAX constraints in browsers.
Let’s rewrite the MailServerResource to exchange JSON representations. Listing 4.16 contains the new code, using the org.json.JSONObject class to store a map of properties. You can then use the JsonRepresentation from the org.restlet.ext.json package to wrap this JSON object and provide the proper metadata. By default the application/json media type is used.
Listing 4.16. Mail server resource using the JSON.org API

If you GET the mail resource in your browser, you should obtain the same document as in listing 4.15, except the order of the properties might vary. This is normal because JSON objects are unordered structures. The JsonRepresentation class illustrated in figure 4.18 is rather simple and works like the other extensions in this chapter by wrapping either a JSON value or a JSON representation, providing various methods to parse or consume this value.
Figure 4.18. Properties and methods of the JsonRepresentation

As with XML representations, it’s often more convenient to use a JSON binding library to marshal and unmarshal JSON representations. The Restlet Framework has two extensions to achieve this: XStream and Jackson. The XStream extension—a powerful XML binding solution introduced in the previous section—provides an interesting bridge to JSON representations by using the Jettison JSON library. But the JSON representations that it produces tend to be verbose, so we generally recommend using the more specialized Jackson extension for JSON instead.
4.3.2. Using the Jackson extension
Jackson is an open source library that was quickly embraced by various frameworks due to its features and outstanding performance. It’s a comprehensive solution providing both a DOM-like API and a JSON binding mechanism.
In this section we illustrate the org.restlet.ext.jackson extension and its main JacksonRepresentation class, described in figure 4.19. It has three properties: the object property contains the wrapped Java object that was parsed or can be formatted; the objectClass indicates the target class of the object to parse; and objectMapper offers a way to customize the mapping. There are three constructors, two for serialization and one for deserialization, and a createObjectMapper() method that can be overridden to customize Jackson’s behavior.
Figure 4.19. Properties and methods of the JacksonRepresentation

Even though the class looks simple, it can produce very nice results, as illustrated in listing 4.17. We manually wrote a Mail class, containing our four String properties with getters and setters, and then in the GET handling method let Jackson produce the correct JSON representation. Handling of the PUT methods and parsing of the JSON representation received into a Mail instance is equally simple and very similar to the way the JAXB extension is working.
Listing 4.17. Mail server resource using the Jackson extension

Not surprisingly the MailClient class, with logic unchanged since the beginning of the chapter, works equally well. When you consider how close this example is to the JAXB one, it’s tempting to ask whether it would be possible to unify both approaches to produce XML or JSON at the same time. In fact this is indeed possible, and we cover that in section 4.5 when introducing the converter service—but there are a few steps to climb before that.
Template representations are useful in producing HTML representations in a way comparable to JSP technology.
4.4. Applying template representations
So far in this chapter, you’ve exchanged data-oriented representations using the XML and JSON languages, but we’ve barely explained how to produce HTML representations to be displayed in a web browser. You need a solution to realize the promise (made in chapter 1) of web applications unifying web services and websites.
Because Restlet applications can be deployed standalone, outside Servlet containers, we can’t rely on the standard Java Server Pages (JSP) technology. But that’s not an issue because we have powerful alternatives: dynamic representations powered by the FreeMarker and Apache Velocity template engines. We call them template representations because they’re built around the skeleton of the target document, filled with instructions to insert dynamic values provided by a data model.
Figure 4.20 shows a new variant of our Homer mail resource, a dynamically built HTML document. Keep in mind that template representations can be successfully used to produce any kind of textual representations, such as XML representations or even Java code. HTML is a particularly appropriate target language.
Figure 4.20. Example resource exposing an HTML document as representation

For reference, the following listing shows the HTML mail document that we want the Homer mail resource to expose.
Listing 4.18. The target HTML mail representation
<html>
<head>
<title>Example mail</title>
</head>
<body>
<table>
<tbody>
<tr>
<td>Status</td>
<td>received</td>
</tr>
<tr>
<td>Subject</td>
<td>Message to self</td>
</tr>
<tr>
<td>Content</td>
<td>Doh!</td>
</tr>
<tr>
<td>Account</td>
<td><a href="http://www.rmep.org/accounts/chunkylover53/">Link</
a></td>
</tr>
</tbody>
</table>
</body>
</html>
In the next subsection we put those ideas into practice by using FreeMarker to dynamically generate the preceding HTML representation.
4.4.1. Using the FreeMarker extension
FreeMarker is a powerful open source template engine with a comprehensive syntax allowing simple value insertion, loop control, conditions, custom macros, and directives. We recommend it as an alternative to JSP to produce HTML or other textual representations.
The template corresponding to the example HTML mail in the next listing takes the same structure as the target HTML representation and uses ${variableName} to insert the content provided with an object data model. This data model can be hierarchical or even be an XML document. (The complete syntax of FreeMarker is explained at www.freemarker.org.)
Listing 4.19. The FreeMarker template HTML representation
<html>
<head>
<title>Example mail</title>
</head>
<body>
<table>
<tbody>
<tr>
<td>Status</td>
<td>${mail.status}</td>
</tr>
<tr>
<td>Subject</td>
<td>${mail.subject}</td>
</tr>
<tr>
<td>Content</td>
<td>${mail.content}</td>
</tr>
<tr>
<td>Account</td>
<td><a href="${mail.accountRef}">Link</a></td>
</tr>
</tbody>
</table>
</body>
</html>
With the template file ready, we can now use the FreeMarker extension for Restlet, located in org.restlet.ext.freemarker, to produce the target representation. This extension contains the TemplateRepresentation class, which works by wrapping a template object and a data model.
Various constructors are also available, providing different ways to create or obtain the template. Either you provide it as a Restlet representation, as in listing 4.20, or you indicate only a template name.
In the latter case FreeMarker will load the template from a local directory that you indicate with a Configuration instance, which can be reused for several Template-Representation instances. This approach is more scalable because FreeMarker can use its caching strategies to accelerate the resolution of your templates.
For the data model you can provide Java beans or collections such as maps and lists. There’s also a setDataModel(Request, Response) method able to wrap a Restlet call to allow access to request and response values using shortcut variable names (see the org.restlet.util.Resolver interface for details on these shortcuts).
Listing 4.20. Mail server resource using the FreeMarker extension

In listing 4.20 we only implemented the GET method because it’s rarely useful to consume HTML representations. We cover the processing of HTML form posts in section 7.1.1. Our MailClient was also slightly modified to write the HTML representation on the console. Launch the application again and go to the http://localhost:8111/accounts/chunkylover53/mails/123 URI and see the HTML page produced.
In addition to this FreeMarker extension, a similar extension is provided for the Apache Velocity template engine.
4.4.2. Using the Velocity extension
Velocity is another popular open source template engine provided by the Apache Foundation, similar to FreeMarker but with a slightly different syntax and set of features. Listing 4.21 shows the template corresponding to our example HTML mail. It takes the same structure as the target HTML representation and uses the $variable-Name to insert the content provided with an object data model. This data model can be hierarchical or even an XML document. (For more information, the complete syntax of Velocity is explained at http://velocity.apache.org.)
Listing 4.21. The Velocity template HTML representation
<html>
<head>
<title>Example mail</title>
</head>
<body>
<table>
<tbody>
<tr>
<td>Status</td>
<td>$mail.status</td>
</tr>
<tr>
<td>Subject</td>
<td>$mail.subject</td>
</tr>
<tr>
<td>Content</td>
<td>$mail.content</td>
</tr>
<tr>
<td>Account</td>
<td><a href="$mail.accountRef">Link</a></td>
</tr>
</tbody>
</table>
</body>
</html>
With the template file ready, you can now use the Velocity extension for Restlet, located at org.restlet.ext.velocity, to produce the target representation. This extension contains the TemplateRepresentation, which works exactly like the Free-Marker extension, as shown in the following listing.
Listing 4.22. Mail server resource using the Velocity extension

At this point, you’ve learned various techniques to exchange XML, JSON, and HTML representations for the example Homer mail resource, but each time you had to develop a separate Restlet application, with a new MailServerResource class. This isn’t exactly the idea of unified web applications proposed in chapter 1. The key feature missing to realize our goal is the topic of the next section: HTTP content negotiation.
4.5. Content negotiation
The modern web supports many kinds of clients, each with different capacities and expectations: classic desktop web browsers, mobile web browsers, native mobile applications, programmatic (not human-driven) clients like search bots, and so on. Wouldn’t it be nice to avoid building a different version of your application for each client? The good news is that HTTP has a content negotiation feature (frequently shortened to conneg) that can help you unify your developments. Let’s now look at how HTTP conneg works before learning how to apply it within the Restlet Framework.
4.5.1. Introducing HTTP content negotiation
HTTP allows any resource to have multiple representations, called variants, and specify how a client and a server can determine which variant is the most appropriate for a given interaction. You might prefer to use HTML when exchanging representations with a web browser and XML or JSON with a programmatic client wanting structured data that’s easy to manipulate.
Let’s illustrate those concepts with our RESTful mail example. In figure 4.21 we reuse the type of diagrams introduced in figure 1.4 when explaining the relationships between resources, identifiers (URIs), and representations. We also apply it to our Homer mail resource described in appendix D and used throughout this chapter.
Figure 4.21. Account resource identified by a URI and represented by three variants
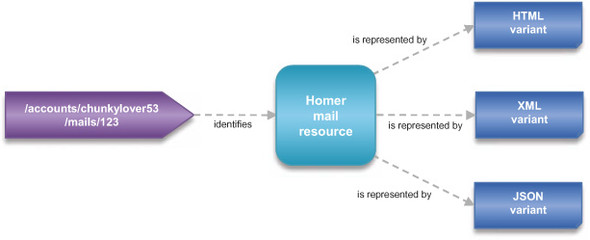
What the figure says is that the Homer mail resource is identified by a single URI, /accounts/chunkylover53/mails/123, and exposes three variants, each corresponding to a different type of content:
- HTML variant for retrieval by web browsers
- XML variant for consumption by programmatic clients
- JSON variant typically for retrieval by AJAX applications
HTTP uses a system where possible types of content are described by media types. A media type has a name and defines how conforming content should be interpreted. A number of standard media types have been defined (see table 4.4 for examples), and you can define your own if needed. The Restlet API naturally supports media types with the org.restlet.data.MediaType class, which declares many constants as well. Note that you can always create your own instances if no constant matches your needs.
Table 4.4. A few examples of common standard media types
|
Name |
Description |
|---|---|
| text/plain | Some plain text |
| text/html | An HTML document |
| application/xml | An XML document |
| application/json | A JSON document |
| image/jpeg | An image in JPEG format |
| image/png | An image in PNG format |
| application/pdf | A PDF document |
When issuing an HTTP request, a client can include an Accept header that lists the acceptable media types for the representation that the server could send back in the response. It’s even possible to specify the degree of preference for each acceptable media type, using the q parameter to associate weights to media types.
The server can then use this information to generate the best representation possible for that particular client. The following header specifies that the client expects either an XML or a JSON representation, with a preference for JSON:
Accept: application/json; q=1.0, application/xml; q=0.5
In addition to the Accept header, HTTP defines other useful headers related to other dimensions of content negotiation:
- The Accept-Language header specifies preferred languages for the response (for example, English or French).
- The Accept-Encoding header specifies preferences for content encoding (for example, to indicate support for receiving gzip-compressed responses).
- The Accept-Charset header specifies supported character sets such as UTF-8.
- The User-Agent header can also be used to drive content generation. It identifies the client (for example, discriminating between Internet Explorer and Firefox) and lets you adapt your content to its specificities or limitations.
Content negotiation is a powerful feature of HTTP, and you should consider using it for your applications. In the next subsections we put it into practice with the Restlet Framework, first showing how resource variants can be declared and then configuring the client to retrieve the desired variants.
4.5.2. Declaring resource variants
Since version 2.0 of the Restlet Framework, there are two ways for a server resource to declare the variants that it exposes. The first is programmatic, using the modifiable variants property, and the second is based on Restlet annotations (discussed in subsection 4.5.4).
If you declare some variants, your ServerResource subclass needs to override the get(Variant) method instead of the get() one, or the put(Representation, Variant) instead of put(Representation). Note that content negotiation can be used for all methods, not just GET ones, but they only apply to the response entity.
Let’s illustrate this feature with the same example, but this time trying to expose and consume the mail as XML or JSON representations depending on client preferences. For XML, you use XStream instead of JAXB because it can work with the same Mail class already used with Jackson for JSON representations in subsection 4.3.2. Note in listing 4.23 how you override the doInit() method to declare the supported variants.
Then you test the variant parameter of the get(Variant) method to know which variant is preferred by the client. The selection of the best variant matching the client preferences is done transparently by the Restlet Framework!
Listing 4.23. Mail server resource supporting XML and JSON representations


In the put(Representation, Variant) method, we test the value of the representation’s media type, not the variant’s media type. The variant only defines the preferred response type. You could, for example, submit a representation in XML and receive HTML as a result. In the next subsection we continue the example on the client side by configuring the client preferences to retrieve a specific variant.
4.5.3. Configuring client preferences
You can define your preferences in different ways as a client when issuing requests so that a server can make the best guess regarding the variant you want to obtain via content negotiation.
As shown in subsection 4.5.1, the standard HTTP way is to set the Accept* headers. The Restlet API facilitates this, thanks to a set of ClientInfo.accepted* properties that are instances of List<Preference<T extends Metadata>>. Subclasses of Metadata are defined for all the dimensions of content negotiation: CharacterSet, Encoding, Language, and MediaType metadata classes, all from the org.restlet.data package.
The advantage of using those properties is that you can set fined-grained preferences, with various levels of qualities for each media type you accept. But in many cases you only want to retrieve a single specific media type. In this case it’s easy to use helper methods directly on the ClientResource class, as illustrated in the next listing.
Listing 4.24. Mail client selecting XML, then JSON variants
public static void main(String[] args) throws Exception {
ClientResource mailClient = new ClientResource(
"http://localhost:8111/accounts/chunkylover53/mails/123");
Representation mailRepresentation = mailClient
.get(MediaType.APPLICATION_XML);
mailClient.put(mailRepresentation);
mailRepresentation = mailClient.get(MediaType.APPLICATION_JSON);
mailClient.put(mailRepresentation);
}
In this example you issue two GET calls, the first requesting the XML variant and the second the JSON variant. If you run your server application and then this mail client, the server displays the following output on its console:
XML representation received Status: received Subject: Message to self Content: Doh! Account URI: http://localhost:8111/accounts/chunkylover53/ JSON representation received Status: received Subject: Message to self Content: Doh! Account URI: http://localhost:8111/accounts/chunkylover53/
In addition, since version 2.1 the ClientResource class provides the convenient shortcut accept(Metadata...) method that lets you add new preferences with a 1.0 quality. Another way to express your preferences is to rely on the TunnelService (briefly presented in section 2.3.4). For example you can enter the following URI in your browser to retrieve the JSON representation:
http://localhost:8111/accounts/chunkylover53/mails/123?media=json
The json value passed in the query parameter at the end of the URI must correspond to one of the declared prefixes in the MetadataService, which defines default extension names for common media types. To end this chapter we combine the power of conneg with the converter service that we also encountered in chapter 2, resulting in even simpler code.
4.5.4. Combining annotated interfaces and the converter service
In chapter 2 we used the converter service and annotated Java interfaces to simplify the implementation of example account resources exchanging simple strings as representations.
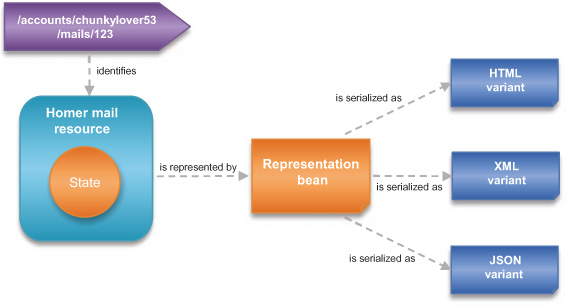
What we’d like now is to use the same mechanism with more complex structures, like our Mail bean class. In figure 4.22 we enhance our previous one to introduce the representation bean (the Mail class in our case) and its relationship with the resource’s state and the variants that can be serialized from it.
Figure 4.22. Account resource represented by bean serialized in three variants
We start by defining the annotated MailResource interface in the following listing that will be implemented on the server side and used as a proxy on the client side.
Listing 4.25. Annotated MailResource interface
public interface MailResource {
@Get
public Mail retrieve();
@Put
public void store(Mail mail);
}
As mentioned in chapter 1, the @Get and @Put annotations come from the org.restlet.resource package and define the binding between Java and HTTP methods. Let’s implement the server side (see the next listing). Again, the code is extremely straightforward. We abstracted away many Restlet concepts, but note that we’re still extending the ServerResource class, giving us access to the whole call context, such as the resource reference used in the accountRef property.
Listing 4.26. Mail server resource implementing the MailResource interface
public class MailServerResource extends ServerResource
implements MailResource {
public Mail retrieve(){
Mail mail = new Mail();
mail.setStatus("received");
mail.setSubject("Message to self");
mail.setContent("Doh!");
mail.setAccountRef(new Reference(getReference(), "..").
getTargetRef().toString());
return mail;
}
public void store(Mail mail) {
System.out.println("Status: " + mail.getStatus());
System.out.println("Subject: " + mail.getSubject());
System.out.println("Content: " + mail.getContent());
System.out.println("Account URI: " + mail.getAccountRef());
System.out.println();
}
}
The nice thing about this code is that all the serialization and deserialization is done transparently by the Restlet Framework. In order to work as expected, it’s essential to properly configure your classpath to have the org.restlet.ext.jackson extension first, covering JSON serialization, then the org.restlet.ext.xstream extension, covering XML serialization. This is because the XStream also has the ability to convert to JSON, and not only to XML, but is less powerful than Jackson for this purpose.
At this point you can already launch the mail server application and try to get the mail resource from your browser. Adjusting the media query parameter should let you obtain either JSON or XML representation produced by Jackson or XStream. What’s remarkable is that we obtained transparent serialization of the Mail beans as well as the ability to negotiate their format using standard HTTP conneg. You could potentially support additional formats by adding new extensions with the proper converter to your classpath! The following listing shows how the MailClient looks.
Listing 4.27. Mail server resource implementing the MailResource interface

If you need access to the ClientResource instance backing the dynamic proxy created, you can make your interface extend the org.restlet.resource.ClientProxy to have access to an getClientResource() method automatically implemented.
You can now run the client to confirm that the server works the same as for alternative approaches presented earlier in the chapter. We dramatically reduced the number of lines of code while keeping the full power of the Restlet API in hand if needed.
4.6. Summary
In this chapter you explored in depth how representations are supported by the Restlet Framework, from the low level Variant, RepresentationInfo, and Representation classes to the higher level JacksonRepresentation or XstreamRepresentation classes, providing an automatic binding between HTTP entities and Java classes.
You learned how to manipulate XML representations with powerful features such as XPath selections, XML schema validation, or XSLT transformation. You also saw two ways to deal with JSON representations and used template representations with engines such as FreeMarker to produce HTML representations dynamically.
Then you learned about the power of HTTP content negotiation and two main ways to support it in Restlet, through explicit declaration or transparently with the converter service and annotated Java interfaces. In the last case you obtained a remarkable reduction in terms of number of lines of source code.
Abstracting away the parsing and formatting logic makes you dependent on binding libraries such as JAXB, XStream, and Jackson for properly handling the evolution of your representation beans. For simple evolutions like the addition or removal of properties, you should be pretty safe, but you need to be aware of the impact of deeper structural changes.
In the end the various abstraction mechanisms provided are very attractive due to the huge productivity gains, but they couple your client and server code (while still retaining the ability to use any HTTP client using standard content negotiation). For most applications this is an acceptable trade-off, although others will need to keep a finer control on those aspects by using the more explicit approach that we’ve seen before.
With the Restlet Framework you’re free to choose the approach that best fits your requirements, even keeping the ability to mix both approaches if needed. In the next chapter we discuss a totally different, but nonetheless very important, subject: how to secure your Restlet applications.