
19. Object-Relational Support
The SQL:2003 standard introduced a variety of object-relational features. Although not all relational DBMSs support this part of the standard, you will find at least some OR features in most of today's major DBMSs.
Note: There are some people who cling to the pure relational data model like a lifeline. However, in practice there is nothing that requires you to avoid SQL's OR features. If those features can help model your database environment, then those designing your database shouldn't be afraid to use them. Just be aware of the referential integrity issues that can arise when you store more than one piece of data in a single column in a single row.
SQL provides four column data types for OR storage as well as support for user-defined data types (UDTs). The SQL programming constructs discussed in Chapter 14—along with extensions for accessing OO structures—are used to write methods for UDTs when they are needed.
Note: Some of the OR features covered in this chapter require programming. As when we discussed triggers, stored procedures, and embedded SQL, in those instances this chapter assumes that you have programming experience.
An Additional Sample Database
For some of the examples in this chapter we will be working with a classic home computer application: recipes. You can find the ERD in Figure 19-1. (It has been designed to illustrate OR concepts and therefore is probably missing elements that would be part of a commercial application.)
 |
| Figure 19-1 An object-relational ERD |
The recipe class is an abstract class that stores data common to all types of recipes. The six subclasses represents categories of recipes, each of which has at least one unique attribute.
The ingredient, instruction, and ingredient_amount classes are more traditional entities. A recipe has many instructions. Each instruction uses zero, one, or more ingredients. The ingredient_amount class therefore stores relationship data: the amount of a given ingredient used in a given instruction.
SQL Data Types for Object-Relational
SQL's OR features include three column data types for storing multiple values: ROW, ARRAY, and MULTISET. You can use these data types without using any of the other OR features (in particular, typed tables to store objects). Because they do not act as objects, these columns cannot have methods.
Row Type
A column declared as a row type holds an entire row of data (multiple pieces of data). This gives you the equivalent of a table within a table. The contents of the row—called fields—can be declared as built-in data types or UDTs.
As an example, we'll create a table for customers of the rare book store that stores the customer's address in a single column using the ROW data type:
CREATE TABLE customer
(first_name CHAR (20),
last_name CHAR (20),
address ROW (street CHAR (50),
city CHAR (30),
state CHAR (2),
zip CHAR (10),
phone CHAR (12)));
Notice that the ROW column is given a name, just as a single-valued column. The data type is followed by the contents of the row in parentheses. The row's fields are declared in the same way as any other SQL column (name followed by data type).
We use “dot” notation to access the individual fields in a column of type ROW. For example, to reference the street field in the address column without qualifying the table name you would use
address.street
When the SQL statement requires a table name (for example, for use in a join or for display by a query in which the field appears in multiple tables), you preference the field reference with the table name, as in
customer.address.street
Inserting values into a row column is only a bit different from the traditional INSERT statement. Consider the following example:
INSERT INTO customer VALUES
(‘John’,’Doe’,
ROW (‘123 Main
Street,’Anytown’,’ST’,’11224’),
‘555-111-2233’);
The data for the address column are preceded by the keyword ROW. The values follow in parentheses.
Array Type
An array is an ordered collection of elements. Like arrays used in programming, they are declared to have a maximum number of elements of the same type. That type can be a simple data type or a UDT. For example, we might want to store order numbers as part of a customer's data in a customer table:
CREATE TABLE customer
(first CHAR (20),
last CHAR (20),
orders INT ARRAY[100],
numb_orders INT,
phone CHAR (12));
The array column is given a name and a data type, which are followed by the keyword ARRAY and the maximum number of elements the array should hold (the array's cardinality), in brackets. The array's data type can be one of SQL's built-in data types or a UDT.
Access to values in an array is by the array's index (its position in the array order). Although you specify the maximum number of elements in an array counting from 1, array indexes begin at 0. An array of 100 elements therefore has indexes from 0 to 99. The sample customer table above includes a column (numb_orders) that stores the total number of elements in the array. The last used index will be numb_orders - 1.
You can input multiple values into an array at one time when you first insert a row:
INSERT INTO customer VALUES
(‘John’,’Doe’,
ARRAY (25,109,227,502,610), 5,
’555-111-2233’);
The keyword ARRAY precedes the values in parentheses.
You can also insert or modify a specific array element directly:
INSERT INTO customer (first, last, orders[0], numb_orders,phone)
VALUES (‘John’,’Doe’,25,1,’555-111-2233’);
When you query a table and ask for display of an array column by name, without an index, SQL displays the entire contents of the array, as in:
SELECT orders
FROM customer
WHERE first = ‘John’ AND last = ‘Doe’;
Use an array index when you want to retrieve a single array element. The query
SELECT orders [numb_orders - 1]
FROM customer
WHERE first = ‘John’ AND last = ‘Doe’;
displays the last order stored in the array.
Processing each element in an array requires programming (a trigger, stored procedure, or embedded SQL). Declare a variable to hold the array index, initialize it to 0, and increment it by 1 each time an appropriate loop iterates—the same way you would process all elements in an array using any high-level programming language.
Note: Although many current DBMSs support arrays in columns, not all automatically perform array bounds checking. In otherwords, they do not necessarily validate that an array index is within the maximum number specified when the table was created. Check your software's documentation to determine whether array bounds constraints must be handled by an application program or can be left up to the DBMS.
Manipulating Arrays
Restrictions of content and access notwithstanding, there are two operations that you can perform on arrays:
◊ Comparisons: Two arrays can be compared (for example, in a WHERE clause) if the two arrays are created from data types that can be compared. When making the comparison, SQL compares the elements in order. Two arrays A and B therefore are equivalent if A[0] = B[0], A[1] = B[1], and so on; all comparisons between all the pairs of values in the array must be true. By the same token, A > B if A[0] > B[0], throughout the arrays.
◊ Concatenation: Two arrays with compatible data types (data types that can be converted into a single data type) can be concatenated with the concatenation operator (‖). The result is another array, as in Figure 19-2. Notice that the data from array A have been converted to real numbers because SQL will always convert to the format that has the highest precision.
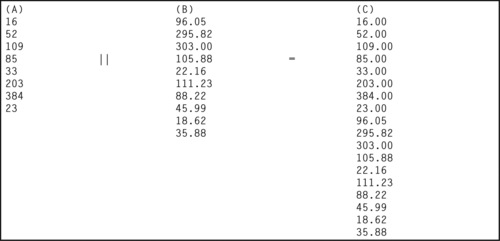 |
| Figure 19-2 Concatenating arrays |
Multiset Type
A multiset is an unordered collection of elements of the same type. The following table contains a multiset to hold multiple phone numbers:
CREATE TABLE customer
(first CHAR (20),
last CHAR (20),
orders INT ARRAY[100],
phones CHAR (20) MULTISET);
You specify the contents of a multiset when you insert a row into a table much like you do for an array. The only difference is the use of the keyword MULTISET to indicate that the values in parentheses are intended as a single group:
INSERT INTO customer (first, last, orders[0],numb_orders,phones)
VALUES (‘John’,’Doe’,25,1, MULTISET (’555-111-2233’,’555-222-1122’));
Because a multiset is unordered, you cannot access individual elements by position as you do with array elements. You can, however, display the entire contents of the multiset by using its name in a query:
SELECT phones
FROM customer
WHERE first = ‘John’ AND last = ‘Doe’;
Updating a multiset is an all or nothing proposition. In other words, you can't pull one value out or put in a single value. An UPDATE statement such as
replaces the entire contents of the phones column.
Manipulating Multisets
As with arrays, there are a few operations that can be performed on multisets with compatible data types:
◊ Multisets can be compared, just as arrays. Multisets A and B will be true if they contain exactly the same elements.
◊ Union: The MULTISET UNION operator returns a multiset that contains all elements in the participating multisets. For example,
UPDATE some_table
SET big_multiset = small_multiset1
MULTISET UNION small_multiset2
puts the two small multisets into the big multiset.
◊ Intersect: The MULTISET INTERSECT operator returns all elements that two multisets have in common. For example,
SELECT table1.multiset MULTISET INTERSECT table2.multiset
FROM table1 JOIN table2;
works on each row in the joined tables, returning the elements that the multisets in each row have in common.
◊ Difference: The MULTISET EXCEPT operation returns the difference between two multisets (all elements they don't have in common). The query
SELECT table1.multiset MULTISET EXCEPT
table2.multiset
FROM table1 JOIN table2;
functions exactly like the previous example but returns elements from each row that the multisets don't share.
The union, intersect, and difference operators have two options. If you include ALL after the operator, SQL includes duplicate elements in the result. To exclude duplicates, use DISTINCT.
User-Defined Data Types and Typed Tables
The more classic SQL object-oriented features are built from UDTs and typed tables. The UDT defines a class and the typed table defines a place to store objects from that class. Even if you choose not to use OR elements in a database, you may want to use a UDT as a domain.
UDTs as Domains
A user-defined data type is a structured, named group of attributes of existing data types (either built-in types or other UDTs). In its simplest form, the UDT has the following general syntax:
CREATE TYPE type_name AS (column_definitions);
We could create a very simple type to hold a date, for example:
CREATE TYPE date_type AS
(month int,
day int,
year int);
We could then specify date_type as the data type for a column in a table:
CREATE TABLE people
(first CHAR (20),
last CHAR (20),
birthdate date_type);
UDTs as Classes
More commonly, we use a UDT to define a class. For example, we could create a type for the Ingredient class with
CREATE TYPE ingredient_type AS OBJECT
(ingredient_name CHAR (256),
unit char (20),
on_hand int);
Notice the AS OBJECT clause that has been inserted after the UDT's name. This indicates that rather than being used as the domain for a value in a table, this class will be used as the structure of a typed table.
Note: UDTs can have methods, just like a class created in an object-oriented programming language. We'll look at them at the end of this chapter.
Creating Typed Tables Using UDTs
Once you have created a class as a UDT, you then use that UDT to create a typed table:
CREATE TABLE table_name OF UDT_name
REF IS reference_column_name (method_to_generate_row_ID)
SQL creates a table with one column for each column in the UDT on which the table is based along with a column for the self-referencing object ID. There are three options for creating the object ID of a row:
◊ The user generates the object ID (REF USING existing_data_type)
◊ The DBMS generates the object ID (REF IS identifier_name SYSTEM GENERATED)
◊ The object ID comes from the values in a list of attributes (REF FROM attribute_list)
You may want to use a primary key as a source for an object ID. Although this makes sense logically, it also provides the slowest retrieval performance.
By default, the object ID value is generated by the SQL command processor whenever a row is inserted into the typed table, using the method that was specified when the table was created. However, an insert operation can override the default object ID, placing a user-specified value into the ID column. Once created, the object ID cannot be modified.
To create the ingredient table, we could use
CREATE TABLE ingredient OF ingredient_type
(REF IS ingredient_ID SYSTEM GENERATED);
Note: Only base tables or views can be typed tables. Temporary tables cannot be created from UDTs.
Inheritance
One of the most important OO features added to the SQL:2003 standard was support for inheritance. To create a subtype (a subclass or derived class, if you will), you create a UDT that is derived from another and then create a typed table of that subtype.
As a start, let's create the Recipe type that will be used as the superclass for types of recipes:
CREATE TYPE recipe_type AS OBJECT
(recipe_name CHAR (256),
instruction_list instruction ARRAY[20],
numb_servings INT)
NOT INSTANTIABLE,
NOT FINAL;
The two last lines in the preceding example convey important information about this class. Recipe is an abstract class: Objects will never be created from it directly. We add NOT INSTANTIABLE to indicate this property.
By default, a UDT has a finality of FINAL. It cannot be used as the parent of a subtype. (In other words, nothing can inherit from it.) Because we want to use this class as a superclass, we must indicate that it is NOT FINAL.
To create the subtypes, we indicate the parent type preceded by the keyword UNDER. The subtype declaration also includes any attributes (and methods) that are not in the parent type that need to be added to the subtype. For example, we could create the Desert type with:
CREATE TYPE desert_type
UNDER recipe_type (calories INT);
Because this type will be used to create objects and because no other types will be derived from it, we can accept the defaults of INSTIABLE and FINAL.
Note: As you have just seen, inheritance can operate on UDTs. It can also be used with typed tables, where a typed table is created UNDER another.
Reference (REF) Type
Once you have a typed table, you can store references to the objects (in other words, the rows) in that table in a column of type REF that is part of another type. For example, there is one REF column in the recipe database: the attribute in the ingredient_amount table (related_ingredient) that points to which ingredient is related to each occurrence of ingredient_amount.
To set up the table that will store that reference, use the data type REF for the appropriate column. For example,
CREATE TABLE ingredient_amount
(related_ingredient REF ingredient_type SCOPE IS ingredient, amount decimal (5,2));
creates a table with a column that stores a reference to an ingredient. The SCOPE clause specifies the table or view that is the source of the reference.
To insert a row into a table with a REF column, you must include a SELECT in the INSERT statement that locates the row whose reference is to be stored. As you would expect, the object being referenced must exist in its own table before a reference to it can be generated. We must therefore first insert an ingredient into the ingredient table:
INSERT INTO ingredient VALUES
(‘Unbleached flour,’ ‘cups’,25);
Then we can insert a referencing row into ingredient_amount:
INSERT INTO ingredient_amount
(SELECT REF (i) FROM ingredient i WHERE i.ingredient_name = ‘Unbleached flour’)
VALUES (2.5);
Dereferencing for Data Access
An application program that is using the recipe database as its data store will need to use the reference stored in the ingredient_amount table to locate the name of the ingredient. The DEREF function follows a reference back to the table being referenced and returns data from the appropriate row. A query to retrieve the name and amount of an ingredient used in a recipe instruction could therefore be written:
SELECT
DEREF(related_ingredient).ingredient_name, amount
FROM ingredient_amount
WHERE DEREF(related_instruction).recipe_name = ‘French toast’;
Note that the DEREF function accesses an entire row in the referenced table. If you don't specify otherwise, you will retrieve the values from every column in the referenced row. To retrieve just the value of a single column, we use “dot” notation. The first portion—
DEREF(related_ingredient)
—actually performs the dereference. The portion to the right of the dot specifies the column in the referenced row.
Some DBMSs provide a dereference operator (->) that can be used in place of the DEREF function. The preceding query might be written:
SELECT
related_ingredient->ingredient_name, amount
FROM ingredient_amount;
Methods
The UDTs that we have seen to this point have attributes, but not methods. It is certainly possible, however, to declare methods as part of a UDT and then to use SQL programming to define the body of the methods. Like classes used by OO programming languages such C++, SQL the body a method is defined separately from the declaration of the UDT.
You declare a method after declaring the structure of a UDT. For example, we could add a method to display the instructions of a recipe with
CREATE TYPE recipe_type AS OBJECT
(recipe_name CHAR (256),
instruction_list instruction ARRAY[20],
numb_servings INT)
NOT INSTANTIABLE,
NOT FINAL
METHOD show_instructions ();
This particular method does not return a value and the declaration therefore does not include the optional RETURNS clause. However, a method to compute the cost of a recipe (if we were to include ingredient costs in the database) could be declared as
Methods can accept input parameters within the parentheses following the method name. A method declared as
METHOD scale_recipe (IN numb_servings INT):
accepts an integer value as an input value. The parameter list can also contain output parameters (OUT) and parameters used for both input and output (INOUT).
Defining Methods
As mentioned earlier, although methods are declared when UDTs tables are declared, the bodies of methods are written separately. To define a method, use the CREATE METHOD statement:
CREATE METHOD method_name FOR UDT_name
BEGIN
// body of method
END
A SQL-only method is written using the language constructs discussed in Chapter 14.
Random programming note: Like the C++ and Java “this,” SQL methods use SELF to refer to the object to which the method belongs.
Executing Methods
Executing a method uses the “dot” notation used in C++:
typed_table_name.method_name (parameter_list);
Such an expression can be, for example, included in an INSERT statement to insert the method's return value into a column. It can also be included in another SQL method, trigger, or stored procedure. Its return value can then be captured across an assignment operator. Output parameters return their values to the calling routine, where they can be used as needed.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.