
Chapter 5
Building a Multitable Relational Database
In This Chapter
![]() Deciding what to include in a database
Deciding what to include in a database
![]() Determining relationships among data items
Determining relationships among data items
![]() Linking related tables with keys
Linking related tables with keys
![]() Designing for data integrity
Designing for data integrity
![]() Normalizing the database
Normalizing the database
In this chapter, I take you through an example of how to design a multitable database. The first step to designing any database is to identify what to include and what not to include. The next steps involve deciding how the included items relate to each other and then setting up tables accordingly. I also discuss how to use keys, which enable you to access individual records and indexes quickly.
A database must do more than merely hold your data. It must also protect the data from becoming corrupted. In the latter part of this chapter, I discuss how to protect the integrity of your data. Normalization is one of the key methods you can use to protect the integrity of a database. I discuss the various normal forms and point out the kinds of problems that normalization solves.
Designing a Database
To design a database, follow these basic steps (I go into detail about each step in the sections that follow this list):
1. Decide what objects you want to include in your database.
2. Determine which of these objects should be tables and which should be columns within those tables.
3. Define tables based on how you need to organize the objects.
Optionally, you may want to designate a table column or a combination of columns as a key. Keys provide a fast way to locate a row of interest in a table.
The following sections discuss these steps in detail, as well as some other technical issues that arise during database design.
Step 1: Defining objects
The first step in designing a database is deciding which aspects of the system are important enough to include in the model. Treat each aspect as an object and create a list of all the objects you can think of. At this stage, don’t try to decide how these objects relate to each other. Just try to list them all.
 You may find it helpful to gather a diverse team of people who, in one way or another, are familiar with the system you’re modeling. These people can brainstorm and respond to each other’s ideas. Working together, you’ll probably develop a more complete and accurate set of important objects than you would on your own.
You may find it helpful to gather a diverse team of people who, in one way or another, are familiar with the system you’re modeling. These people can brainstorm and respond to each other’s ideas. Working together, you’ll probably develop a more complete and accurate set of important objects than you would on your own.
When you have a reasonably complete set of objects, move on to the next step: deciding how these objects relate to each other. Some of the objects are major entities (more about those in a minute) that are crucial to giving you the results you want. Other objects are subsidiary to those major entities. Ultimately you may decide that some objects don’t belong in the model at all.
Step 2: Identifying tables and columns
Major entities translate into database tables. Each major entity has a set of attributes — the table columns. Many business databases, for example, have a CUSTOMER table that keeps track of customers’ names, addresses, and other permanent information. Each attribute of a customer — such as name, street, city, state, zip code, phone number, and e-mail address — becomes a column (and a column heading) in the CUSTOMER table.
If you’re hoping to find a set of rules to help you identify which objects should be tables and which of the attributes in the system belong to which tables, think again: You may have some reasons for assigning a particular attribute to one table and other reasons for assigning the same attribute to another table. You must base your judgment on two goals:
![]() The information you want to get from the database
The information you want to get from the database
![]() How you want to use that information
How you want to use that information
 When deciding how to structure database tables, involve the future users of the database as well as the people who will make decisions based on database information. If you come up with what you think is a reasonable structure, but it isn’t consistent with the way that people will use the information, your system will be frustrating to use at best — and could even produce wrong information, which is even worse. Don’t let this happen! Put careful effort into deciding how to structure your tables.
When deciding how to structure database tables, involve the future users of the database as well as the people who will make decisions based on database information. If you come up with what you think is a reasonable structure, but it isn’t consistent with the way that people will use the information, your system will be frustrating to use at best — and could even produce wrong information, which is even worse. Don’t let this happen! Put careful effort into deciding how to structure your tables.
Take a look at an example to demonstrate the thought process that goes into creating a multitable database. Suppose you just established VetLab, a clinical microbiology laboratory that tests biological specimens sent in by veterinarians. You want to track several things, including the following:
![]() Clients
Clients
![]() Tests that you perform
Tests that you perform
![]() Employees
Employees
![]() Orders
Orders
![]() Results
Results
Each of these entities has associated attributes. Each client has a name, an address, and other contact information. Each test has a name and a standard charge. Each employee has contact information as well as a job classification and pay rate. For each order, you need to know who ordered it, when it was ordered, and what test was ordered. For each test result, you need to know the outcome of the test, whether the results were preliminary or final, and the test order number.
Step 3: Defining tables
Now you want to define a table for each entity and a column for each attribute. Table 5-1 shows how you may define the VetLab tables I introduce in the previous section.
Table 5-1 VetLab Tables
|
Table |
Columns |
|
CLIENT |
Client Name |
|
Address 1 |
|
|
Address 2 |
|
|
City |
|
|
State |
|
|
Postal Code |
|
|
Phone |
|
|
Fax |
|
|
Contact Person |
|
|
TESTS |
Test Name |
|
Standard Charge |
|
|
EMPLOYEE |
Employee Name |
|
Address 1 |
|
|
Address 2 |
|
|
City |
|
|
State |
|
|
Postal Code |
|
|
Home Phone |
|
|
Office Extension |
|
|
Hire Date |
|
|
Job Classification |
|
|
Hourly/Salary/Commission |
|
|
ORDERS |
Order Number |
|
Client Name |
|
|
Test Ordered |
|
|
Responsible Salesperson |
|
|
Order Date |
|
|
RESULTS |
Result Number |
|
Order Number |
|
|
Result |
|
|
Date Reported |
|
|
Preliminary/Final |
You can create the tables defined in Table 5-1 by using either a rapid application development (RAD) tool or by using SQL’s Data Definition Language (DDL), as shown in the following code:
CREATE TABLE CLIENT (
ClientName CHAR (30) NOT NULL,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30) ) ;
CREATE TABLE TESTS (
TestName CHAR (30) NOT NULL,
StandardCharge CHAR (30) ) ;
CREATE TABLE EMPLOYEE (
EmployeeName CHAR (30) NOT NULL,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
HomePhone CHAR (13),
OfficeExtension CHAR (4),
HireDate DATE,
JobClassification CHAR (10),
HourSalComm CHAR (1) ) ;
CREATE TABLE ORDERS (
OrderNumber INTEGER NOT NULL,
ClientName CHAR (30),
TestOrdered CHAR (30),
Salesperson CHAR (30),
OrderDate DATE ) ;
CREATE TABLE RESULTS (
ResultNumber INTEGER NOT NULL,
OrderNumber INTEGER,
Result CHAR(50),
DateReported DATE,
PrelimFinal CHAR (1) ) ;
These tables relate to each other by the attributes (columns) that they share, as the following list describes:
![]() The CLIENT table links to the ORDERS table by the
The CLIENT table links to the ORDERS table by the ClientName column.
![]() The TESTS table links to the ORDERS table by the
The TESTS table links to the ORDERS table by the TestName (TestOrdered) column.
![]() The EMPLOYEE table links to the ORDERS table by the
The EMPLOYEE table links to the ORDERS table by the EmployeeName (Salesperson) column.
![]() The RESULTS table links to the ORDERS table by the
The RESULTS table links to the ORDERS table by the OrderNumber column.
If you want a table to serve as an integral part of a relational database, link that table to at least one other table in the database, using a common column. Figure 5-1 illustrates the relationships between the tables.

Figure 5-1: VetLab database tables and links.
The links in Figure 5-1 illustrate four different one-to-many relationships. The diamond in the middle of each relationship shows the maximum cardinality of each end of the relationship. The number 1 denotes the “one” side of the relationship, and N denotes the “many” side.
![]() One client can make many orders, but each order is made by one, and only one, client.
One client can make many orders, but each order is made by one, and only one, client.
![]() Each test can appear on many orders, but each order calls for one, and only one, test.
Each test can appear on many orders, but each order calls for one, and only one, test.
![]() Each order is taken by one, and only one, employee (or salesperson), but each salesperson can (and, you hope, does) take multiple orders.
Each order is taken by one, and only one, employee (or salesperson), but each salesperson can (and, you hope, does) take multiple orders.
![]() Each order can produce several preliminary test results and a final result, but each result is associated with one, and only one, order.
Each order can produce several preliminary test results and a final result, but each result is associated with one, and only one, order.
As you can see in the code, the attribute that links one table to another can have a different name in each table. Both attributes must, however, have matching data types. At this point, I have not included any referential integrity constraints, wanting to avoid hitting you with too many ideas at once. I cover referential integrity later in this chapter, after I have laid the foundation for understanding it.
Domains, character sets, collations, and translations
Although tables are the main components of a database, additional elements play a part, too. In Chapter 1, I define the domain of a column in a table as the set of all values that the column may assume. Establishing clear-cut domains for the columns in a table, through the use of constraints, is an important part of designing a database.
People who communicate in standard American English aren’t the only ones who use relational databases. Other languages — even some that use other character sets — work equally well. Even if your data is in English, some applications may still require a specialized character set. SQL enables you to specify the character set you want to use. In fact, you can use a different character set for each column in a table if you need to. This flexibility is generally unavailable in languages other than SQL.
A collation, or collating sequence, is a set of rules that determines how strings in a character set compare with one another. Every character set has a default collation. In the default collation of the ASCII character set, A comes before B, and B comes before C. A comparison, therefore, considers A as less than B and considers C as greater than B. SQL enables you to apply different collations to a character set. This degree of flexibility isn’t generally available in other languages, so you now have another reason to love SQL.
Sometimes you encode data in a database in one character set but want to deal with the data in another character set. Perhaps you have data in the German character set (for example) but your printer doesn’t support German characters that aren’t included in the ASCII character set. SQL allows translation of character strings from one character set to another. A translation may change one character into two, as when a German ü becomes an ASCII ue, or change lowercase characters to uppercase. You can even translate one alphabet into another (for example, Hebrew into ASCII).
Getting into your database fast with keys
A good rule for database design is to make sure that every row in a database table is distinguishable from every other row; each row should be unique. Sometimes you may want to extract data from your database for a specific purpose (such as a statistical analysis), and in doing so, end up creating tables in which the rows aren’t necessarily unique. For such a limited purpose, this sort of duplication doesn’t matter. Tables that you may use in more than one way, however, should not contain duplicate rows.
A key is an attribute (or combination of attributes) that uniquely identifies a row in a table. To access a row in a database, you must have some way of distinguishing that row from all the other rows. Because keys must be unique, they provide such an access mechanism.
 Furthermore, a key must never contain a null value. If you use null keys, you may not be able to distinguish between two rows that contain a null key field.
Furthermore, a key must never contain a null value. If you use null keys, you may not be able to distinguish between two rows that contain a null key field.
In the veterinary-lab example, you can designate appropriate columns as keys. In the CLIENT table, ClientName is a good key. This key can distinguish each individual client from all other clients. Therefore entering a value in this column becomes mandatory for every row in the table. TestName and EmployeeName make good keys for the TESTS and EMPLOYEE tables. OrderNumber and ResultNumber make good keys for the ORDERS and RESULTS tables. Make sure that you enter a unique value for every row.
You can have two kinds of keys: primary keys and foreign keys. The keys I discuss in the preceding paragraph are examples of primary keys; they guarantee uniqueness. I zero in on primary and foreign keys in the next two sections.
Primary keys
A primary key is a column or combination of columns in a table with values that uniquely identify the rows in the table. To incorporate the idea of keys into the VetLab database, you can specify the primary key of a table as you create the table. In the following example, a single column is sufficient (assuming that all of VetLab’s clients have unique names):
CREATE TABLE CLIENT (
ClientName CHAR (30) PRIMARY KEY,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30)
) ;
The constraint PRIMARY KEY replaces the constraint NOT NULL, given in the earlier definition of the CLIENT table. The PRIMARY KEY constraint implies the NOT NULL constraint, because a primary key can't have a null value.
Although most DBMSs allow you to create a table without a primary key, all tables in a database should have one. With that in mind, replace the NOT NULL constraint in all your tables. In my example, the TESTS, EMPLOYEE, ORDERS, and RESULTS tables should have the PRIMARY KEY constraint, as in the following example:
CREATE TABLE TESTS (
TestName CHAR (30) PRIMARY KEY,
StandardCharge CHAR (30) ) ;
Sometimes no single column in a table can guarantee uniqueness. In such cases, you can use a composite key — a combination of columns that guarantee uniqueness when used together. Imagine that some of VetLab's clients are chains that have offices in several cities. ClientName isn't sufficient to distinguish between two branch offices of the same client. To handle this situation, you can define a composite key as follows:
CREATE TABLE CLIENT (
ClientName CHAR (30) NOT NULL,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25) NOT NULL,
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30),
CONSTRAINT BranchPK PRIMARY KEY
(ClientName, City)
) ;
As an alternative to using a composite key to uniquely identify a record, you can let your DBMS assign one automatically, as Access does in suggesting that the first field in a new table be named ID and be of the Autonumber type. Such a key has no meaning in and of itself. Its only purpose is to be a unique identifier.
Foreign keys
A foreign key is a column or group of columns in a table that corresponds to or references a primary key in another table in the database. A foreign key doesn’t have to be unique, but it must uniquely identify the column(s) in the particular table that the key references.
If the ClientName column is the primary key in the CLIENT table (for example), every row in the CLIENT table must have a unique value in the ClientName column. ClientName is a foreign key in the ORDERS table. This foreign key corresponds to the primary key of the CLIENT table, but the key doesn't have to be unique in the ORDERS table. In fact, you hope the foreign key isn't unique; if each of your clients gave you only one order and then never ordered again, you'd go out of business rather quickly. You hope that many rows in the ORDERS table correspond with each row in the CLIENT table, indicating that nearly all your clients are repeat customers.
The following definition of the ORDERS table shows how you can add the concept of foreign keys to a CREATE statement:
CREATE TABLE ORDERS (
OrderNumber INTEGER PRIMARY KEY,
ClientName CHAR (30),
TestOrdered CHAR (30),
Salesperson CHAR (30),
OrderDate DATE,
CONSTRAINT NameFK FOREIGN KEY (ClientName)
REFERENCES CLIENT (ClientName),
CONSTRAINT TestFK FOREIGN KEY (TestOrdered)
REFERENCES TESTS (TestName),
CONSTRAINT SalesFK FOREIGN KEY (Salesperson)
REFERENCES EMPLOYEE (EmployeeName)
) ;
In this example, foreign keys in the ORDERS table link that table to the primary keys of the CLIENT, TESTS, and EMPLOYEE tables.
Working with Indexes
The SQL specification doesn’t address the topic of indexes, but that omission doesn’t mean that indexes are rare or even optional parts of a database system. Every SQL implementation supports indexes, but you’ll find no universal agreement on how to support them. In Chapter 4, I show you how to create an index by using Microsoft Access, a rapid application development (RAD) tool. Refer to the documentation for your particular database management system (DBMS) to see how the system implements indexes.
What’s an index, anyway?
Data generally appears in a table in the order in which you originally entered the information. That order may have nothing to do with the order in which you later want to process the data. Say, for example, that you want to process your CLIENT table in ClientName order. The computer must first sort the table in ClientName order. Sorting the data this way takes time. The larger the table, the longer the sort takes. What if you have a table with 100,000 rows? Or a table with a million rows? In some applications, such table sizes are not rare. The best sort algorithms would have to make some 20 million comparisons and millions of swaps to put the table in the desired order. Even if you're using a very fast computer, you may not want to wait that long.
Indexes can be a great timesaver. An index is a subsidiary or support table that goes along with a data table. For every row in the data table, you have a corresponding row in the index table. The order of the rows in the index table is different.
Table 5-2 is a small example of a data table for the veterinary lab.

Here the rows are not in alphabetical order by ClientName. In fact, they aren't in any useful order at all. The rows are simply in the order in which somebody entered the data.
An index for this CLIENT table may look like Table 5-3.
Table 5-3 Client Name Index for the CLIENT Table
|
ClientName |
Pointer to Data Table |
|
Amber Veterinary, Inc. |
2 |
|
Butternut Animal Clinic |
1 |
|
Doggie Doctor |
4 |
|
Dolphin Institute |
6 |
|
J. C. Campbell, Credit Vet |
7 |
|
The Equestrian Center |
5 |
|
Vets R Us |
3 |
|
Wenger’s Worm Farm |
8 |
The index contains the field that forms the basis of the index (in this case, ClientName) and a pointer into the data table. The pointer in each index row gives the row number of the corresponding row in the data table.
Why you should want an index
If you want to process a table in ClientName order, and you have an index arranged in ClientName order, you can perform your operation almost as fast as you could if the data table itself were already in ClientName order. You can work through the index, moving immediately to each index row's corresponding data record by using the pointer in the index.
If you use an index, the table processing time is proportional to N, where N is the number of records in the table. Without an index, the processing time for the same operation is proportional to N lg N, where lg N is the logarithm of N to the base 2. For small tables, the difference is insignificant, but for large tables, the difference is great. On large tables, some operations aren’t practical to perform without the help of indexes.
Suppose you have a table containing 1,000,000 records (N = 1,000,000), and processing each record takes one millisecond (one-thousandth of a second). If you have an index, processing the entire table takes only 1,000 seconds — less than 17 minutes. Without an index, you need to go through the table approximately 1,000,000 × 20 times to achieve the same result. This process would take 20,000 seconds — more than five and a half hours. I think you can agree that the difference between 17 minutes and five and a half hours is substantial. That’s just one example of the difference indexing makes on processing records.
Maintaining an index
After you create an index, you must maintain it. Fortunately, you don’t have to think too much about maintenance — your DBMS maintains your indexes for you automatically, by updating them every time you update the corresponding data tables. This process takes some extra time, but it’s worth it. When you create an index and your DBMS maintains it, the index is always available to speed up your data processing, no matter how many times you need to call on it.
The best time to create an index is at the same time you create its corresponding data table. If you create the index early and the DBMS starts maintaining it at the same time, you don’t need to undergo the pain of building the index later; the entire operation takes place in a single, long session. Try to anticipate all the ways that you may want to access your data, and then create an index for each possibility.
Some DBMS products give you the capability to turn off index maintenance. You may want to do so in some real-time applications where updating indexes takes a great deal of time and you have precious little to spare. You may even elect to update the indexes as a separate operation during off-peak hours. As usual, “do what works for you” is the rule.
Don’t fall into the trap of creating an index for retrieval orders that you’re unlikely ever to use. Index maintenance is an extra operation that the computer must perform every time it modifies the index field or adds or deletes a data table row — and this operation affects performance. For optimal performance, create only those indexes that you expect to use as retrieval keys — and only for tables containing a large number of rows. Otherwise indexes can degrade performance.
You may need to compile something such as a monthly or quarterly report that requires the data in an odd order that you don’t ordinarily need. Create an index just before running that periodic report, run the report, and then drop the index so the DBMS isn’t burdened with maintaining the index during the long period between reports.
Maintaining Data Integrity
A database is valuable only if you're reasonably sure that the data it contains is correct. In medical, aircraft, and spacecraft databases, for example, incorrect data can lead to loss of life. Incorrect data in other applications may have less severe consequences but can still prove damaging. Database designers must do their best to make sure that incorrect data never enters the databases they produce. This isn't always possible, but it is possible to at least make sure the data that is entered is valid. Maintaining data integrity means making sure any data that is entered into a database system satisfies the constraints that have been established for it. For example, if a database field is of the Date type, the DBMS should reject any entry into that field that is not a valid date.
Some problems can’t be stopped at the database level. The application programmer must intercept these problems before they can damage the database. Everyone responsible for dealing with the database in any way must remain conscious of the threats to data integrity and take appropriate action to nullify those threats.
Databases can experience several distinctly different kinds of integrity — and a number of problems that can affect integrity. In the following sections, I discuss three types of integrity: entity, domain, and referential. I also look at some of the problems that can threaten database integrity.
Entity integrity
Every table in a database corresponds to an entity in the real world. That entity may be physical or conceptual, but in some sense, the entity’s existence is independent of the database. A table has entity integrity if the table is entirely consistent with the entity that it models. To have entity integrity, a table must have a primary key that uniquely identifies each row in the table. Without a primary key, you can’t be sure that the row retrieved is the one you want.
To maintain entity integrity, be sure to specify that the column (or group of columns) making up the primary key is NOT NULL. In addition, you must constrain the primary key to be UNIQUE. Some SQL implementations enable you to add such constraints to the table definition. With other implementations, however, you must apply the constraint later, after you specify how to add, change, or delete data from the table.
The best way to ensure that your primary key is both NOT NULL and UNIQUE is to give the key the PRIMARY KEY constraint when you create the table, as shown in the following example:
CREATE TABLE CLIENT (
ClientName CHAR (30) PRIMARY KEY,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30)
) ;
An alternative is to use NOT NULL in combination with UNIQUE, as shown in the following example:
CREATE TABLE CLIENT (
ClientName CHAR (30) NOT NULL,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30),
UNIQUE (ClientName) ) ;
Domain integrity
You usually can't guarantee that a particular data item in a database is correct, but you can determine whether a data item is valid. Many data items have a limited number of possible values. If you make an entry that is not one of the possible values, that entry must be an error. The United States, for example, has 50 states plus the District of Columbia, Puerto Rico, and a few possessions. Each of these areas has a two-character code that the U.S. Postal Service recognizes. If your database has a State column, you can enforce domain integrity by requiring that any entry into that column be one of the recognized two-character codes. If an operator enters a code that's not on the list of valid codes, that entry breaches domain integrity. If you test for domain integrity, you can refuse to accept any operation that causes such a breach.
Domain integrity concerns arise if you add new data to a table by using either the INSERT statement or the UPDATE statement. You can specify a domain for a column by using a CREATE DOMAIN statement before you use that column in a CREATE TABLE statement, as shown in the following example, which creates a table for major league baseball teams:
CREATE DOMAIN LeagueDom CHAR (8)
CHECK (VALUE IN ('American', 'National'));
CREATE TABLE TEAM (
TeamName CHAR (20) NOT NULL,
League LeagueDom NOT NULL
) ;
The domain of the League column includes only two valid values: American and National. Your DBMS doesn't enable you to commit an entry or update to the TEAM table unless the League column of the row you're adding has a value of either 'American' or 'National'.
Referential integrity
Even if every table in your system has entity integrity and domain integrity, you may still have a problem because of inconsistencies in the way one table relates to another. In most well-designed multitable databases, every table contains at least one column that refers to a column in another table in the database. These references are important for maintaining the overall integrity of the database. The same references, however, make update anomalies possible. Update anomalies are problems that can occur after you update the data in a row of a database table. The next several sections look at a typical example and suggest how to deal with it.
Trouble between parent and child tables
The relationships among tables are generally not bidirectional. One table is usually dependent on the other. Say, for example, that you have a database with a CLIENT table and an ORDERS table. You may conceivably enter a client into the CLIENT table before she makes any orders. You can’t, however, enter an order into the ORDERS table unless you already have an entry in the CLIENT table for the client who’s making that order. The ORDERS table is dependent on the CLIENT table. This kind of arrangement is often called a parent-child relationship, where CLIENT is the parent table and ORDERS is the child table. The child is dependent on the parent.
Generally, the primary key of the parent table is a column (or group of columns) that appears in the child table. Within the child table, that same column (or group) is a foreign key. Keep in mind, however, that a foreign key need not be unique.
Update anomalies arise in several ways between parent and child tables. A client moves away, for example, and you want to delete her information from your database. If she has already made some orders (which you recorded in the ORDERS table), deleting her from the CLIENT table could present a problem. You’d have records in the ORDERS (child) table for which you have no corresponding records in the CLIENT (parent) table. Similar problems can arise if you add a record to a child table without making a corresponding addition to the parent table.
The corresponding foreign keys in all child tables must reflect any changes to the primary key of a row in a parent table; otherwise an update anomaly results.
Cascading deletions — use with care
You can eliminate most referential integrity problems by carefully controlling the update process. In some cases, you have to cascade deletions from a parent table to its children. To cascade a deletion when you delete a row from a parent table, you also delete all the rows in its child tables whose foreign keys match the primary key of the deleted row in the parent table. Take a look at the following example:
CREATE TABLE CLIENT (
ClientName CHAR (30) PRIMARY KEY,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25) NOT NULL,
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30)
) ;
CREATE TABLE TESTS (
TestName CHAR (30) PRIMARY KEY,
StandardCharge CHAR (30)
) ;
CREATE TABLE EMPLOYEE (
EmployeeName CHAR (30) PRIMARY KEY,
ADDRESS1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
HomePhone CHAR (13),
OfficeExtension CHAR (4),
HireDate DATE,
JobClassification CHAR (10),
HourSalComm CHAR (1)
) ;
CREATE TABLE ORDERS (
OrderNumber INTEGER PRIMARY KEY,
ClientName CHAR (30),
TestOrdered CHAR (30),
Salesperson CHAR (30),
OrderDate DATE,
CONSTRAINT NameFK FOREIGN KEY (ClientName)
REFERENCES CLIENT (ClientName)
ON DELETE CASCADE,
CONSTRAINT TestFK FOREIGN KEY (TestOrdered)
REFERENCES TESTS (TestName)
ON DELETE CASCADE,
CONSTRAINT SalesFK FOREIGN KEY (Salesperson)
REFERENCES EMPLOYEE (EmployeeName)
ON DELETE CASCADE
) ;
The constraint NameFK names ClientName as a foreign key that references the ClientName column in the CLIENT table. If you delete a row in the CLIENT table, you also automatically delete all rows in the ORDERS table that have the same value in the ClientName column as those in the ClientName column of the CLIENT table. The deletion cascades down from the CLIENT table to the ORDERS table. The same is true for the foreign keys in the ORDERS table that refer to the primary keys of the TESTS and EMPLOYEE tables.
Alternative ways to control update anomalies
You may not want to cascade a deletion. Instead, you may want to change the child table's foreign key to a NULL value. Consider the following variant of the previous example:
CREATE TABLE ORDERS (
OrderNumber INTEGER PRIMARY KEY,
ClientName CHAR (30),
TestOrdered CHAR (30),
SalesPerson CHAR (30),
OrderDate DATE,
CONSTRAINT NameFK FOREIGN KEY (ClientName)
REFERENCES CLIENT (ClientName),
CONSTRAINT TestFK FOREIGN KEY (TestOrdered)
REFERENCES TESTS (TestName),
CONSTRAINT SalesFK FOREIGN KEY (Salesperson)
REFERENCES EMPLOYEE (EmployeeName)
ON DELETE SET NULL
) ;
The constraint SalesFK names the Salesperson column as a foreign key that references the EmployeeName column of the EMPLOYEE table. If a salesperson leaves the company, you delete her row in the EMPLOYEE table. New salespeople are eventually assigned to her accounts, but for now, deleting her name from the EMPLOYEE table causes all of her orders in the ORDER table to receive a null value in the Salesperson column.
You can also keep inconsistent data out of a database by using one of these methods:
![]() Refuse to permit an addition to a child table until a corresponding row exists in its parent table. If you refuse to permit rows in a child table without a corresponding row in a parent table, you prevent the occurrence of “orphan” rows in the child table. This refusal helps maintain consistency across tables.
Refuse to permit an addition to a child table until a corresponding row exists in its parent table. If you refuse to permit rows in a child table without a corresponding row in a parent table, you prevent the occurrence of “orphan” rows in the child table. This refusal helps maintain consistency across tables.
![]() Refuse to permit changes to a table’s primary key. If you refuse to permit changes to a table’s primary key, you don’t need to worry about updating foreign keys in other tables that depend on that primary key.
Refuse to permit changes to a table’s primary key. If you refuse to permit changes to a table’s primary key, you don’t need to worry about updating foreign keys in other tables that depend on that primary key.
Just when you thought it was safe . . .
The one thing you can count on in databases (as in life) is change. Wouldn’t you know? You create a database, complete with tables, constraints, and rows and rows of data. Then word comes down from management that the structure needs to be changed. How do you add a new column to a table that already exists? How do you delete one that you don’t need any more? SQL to the rescue!
Adding a column to an existing table
Suppose your company institutes a policy of having a party for every employee on his or her birthday. To give the party coordinator the advance warning she needs when she plans these parties, you have to add a Birthday column to the EMPLOYEE table. As they say in the Bahamas, "No problem!" Just use the ALTER TABLE statement. Here's how:
ALTER TABLE EMPLOYEE
ADD COLUMN Birthday DATE ;
Now all you have to do is add the birthday information to each row in the table, and you can party on. (By the way, where did you say you work?)
Deleting a column from an existing table
Now suppose that an economic downturn hits your company and it can no longer afford to fund lavish birthday parties. Even in a bad economy, DJ fees have gone through the roof. No more parties means no more need to retain birthday data. With the ALTER TABLE statement, you can handle this situation too.
ALTER TABLE EMPLOYEE
DROP COLUMN Birthday ;
Ah, well, it was fun while it lasted.
Potential problem areas
Data integrity is subject to assault from a variety of quarters. Some of these problems arise only in multitable databases; others can happen even in databases that contain only a single table. You want to recognize and minimize all these potential threats.
Bad input data
The source documents or data files that you use to populate your database may contain bad data. This data may be a corrupted version of the correct data, or it may not be the data you want. A range check tells you whether the data has domain integrity. This type of check catches some — but not all — problems. (For example, incorrect field values that are within the acceptable range — but still incorrect — aren’t identified as problems.)
Operator error
Your source data may be correct, but the data entry operator may incorrectly transcribe the data. This type of error can lead to the same kinds of problems as bad input data. Some of the solutions are the same, too. Range checks help, but they’re not foolproof. Another solution is to have a second operator independently validate all the data. This approach is costly because independent validation takes twice the number of people and twice the time. But in some cases where data integrity is critical, the extra effort and expense may prove worthwhile.
Mechanical failure
If you experience a mechanical failure, such as a disk crash, the data in the table may be destroyed. Good backups are your main defense against this problem.
Malice
Consider the possibility that someone may want to corrupt your data. Your first line of defense against intentional corruption is to deny database access to anyone who may have a malicious intent and to restrict authorized users so they can access only the data they need. Your second defense is to maintain data backups in a safe place. Periodically re-evaluate the security features of your installation. Being just a little paranoid doesn’t hurt.
Data redundancy
Data redundancy — the same data items cropping up in multiple places — is a big problem with the hierarchical database model, but the problem can plague relational databases, too. Not only does such redundancy waste storage space and slow down processing, but it can also lead to serious data corruption. If you store the same data item in two different tables in a database, the item in one of those tables may change while the corresponding item in the other table remains the same. This situation generates a discrepancy, and you may have no way of determining which version is correct. That’s a good reason to keep data redundancy to a minimum.
Although a certain amount of redundancy is necessary for the primary key of one table to serve as a foreign key in another, you should try to avoid the repetition of any data items beyond that.
After you eliminate most redundancy from a database design, you may find that performance is now unacceptable. Operators often purposefully use a little redundancy to speed up processing. In the VetLab database, for example, the ORDERS table contains only the client’s name to identify the source of each order. If you prepare an order, you must join the ORDERS table with the CLIENT table to get the client’s address. If this joining of tables makes the program that prints orders run too slowly, you may decide to store the client’s address redundantly in the ORDERS table as well as in the CLIENT table. Then, at least, you can print the orders faster — but at the expense of slowing down and complicating any updating of the client’s address.
A common practice is to initially design a database with little redundancy and with high degrees of normalization, and then, after finding that important applications run slowly, to selectively add redundancy and denormalize. The key word here is selectively. The redundancy that you add back in must have a specific purpose, and because you’re acutely aware of both the redundancy and the hazard it represents, you take appropriate measures to ensure that the redundancy doesn’t cause more problems than it solves. (For more information, jump ahead a bit to the “Normalizing the Database” section.)
Exceeding the capacity of your DBMS
A database system might work properly for years and then start experiencing intermittent errors that become progressively more serious. This may be a sign that you’re approaching one of the system’s capacity limits. There are, after all, limits to the number of rows that a table may have. There are also limits on columns, constraints, and various other database features. Check the current size and content of your database against the specifications listed in the documentation of your DBMS. If you’re near the limit in any area, consider upgrading to a system with a higher capacity. Or you may want to archive older data that is no longer active and then delete it from your database.
Constraints
Earlier in this chapter, I talk about constraints as mechanisms for ensuring that the data you enter into a table column falls within the domain of that column. A constraint is an application rule that the DBMS enforces. After you define a database, you can include constraints (such as NOT NULL) in a table definition. The DBMS makes sure that you can never commit any transaction that violates a constraint.
You have three kinds of constraints:
![]() A column constraint imposes a condition on a column in a table.
A column constraint imposes a condition on a column in a table.
![]() A table constraint puts a specified constraint on an entire table.
A table constraint puts a specified constraint on an entire table.
![]() An assertion is a constraint that can affect more than one table.
An assertion is a constraint that can affect more than one table.
Column constraints
An example of a column constraint is shown in the following Data Definition Language (DDL) statement:
CREATE TABLE CLIENT (
ClientName CHAR (30) NOT NULL,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30)
) ;
The statement applies the constraint NOT NULL to the ClientName column, specifying that ClientName may not assume a null value. UNIQUE is another constraint that you can apply to a column. This constraint specifies that every value in the column must be unique. The CHECK constraint is particularly useful because it can take any valid expression as an argument. Consider the following example:
CREATE TABLE TESTS (
TestName CHAR (30) NOT NULL,
StandardCharge NUMERIC (6,2)
CHECK (StandardCharge >= 0.0
AND StandardCharge <= 200.0)
) ;
VetLab's standard charge for a test must always be greater than or equal to zero. And none of the standard tests costs more than $200. The CHECK clause refuses to accept any entries that fall outside the range 0 <= StandardCharge <= 200. Another way of stating the same constraint is as follows:
CHECK (StandardCharge BETWEEN 0.0 AND 200.0)
Table constraints
The PRIMARY KEY constraint specifies that the column to which it applies is a primary key. This constraint applies to the entire table and is equivalent to a combination of the NOT NULL and UNIQUE column constraints. You can specify this constraint in a CREATE statement, as shown in the following example:
CREATE TABLE CLIENT (
ClientName CHAR (30) PRIMARY KEY,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30)
) ;
Named constraints, such as the NameFK constraint in the example in the earlier "Cascading deletions — use with care" section, can have some additional functionality. Suppose for example, that you want to do a bulk load of several thousand prospective clients into your PROSPECT table. You have a file that contains mostly prospects in the United States, but with a few Canadian prospects sprinkled throughout the file. Normally, you want to restrict your PROSPECT table to include only U.S. prospects, but you don't want this bulk load to be interrupted every time it hits one of the Canadian records. (Canadian postal codes include letters as well as numbers, but U.S. zip codes contain only numbers.) You can choose to not enforce a constraint on PostalCode until the bulk load is complete, and then you can restore constraint enforcement later.
Initially, your PROSPECT table was created with the following CREATE TABLE statement:
CREATE TABLE PROSPECT (
ClientName CHAR (30) PRIMARY KEY,
Address1 CHAR (30),
Address2 CHAR (30),
City CHAR (25),
State CHAR (2),
PostalCode CHAR (10),
Phone CHAR (13),
Fax CHAR (13),
ContactPerson CHAR (30),
CONSTRAINT Zip CHECK (PostalCode BETWEEN 0 AND 99999)
) ;
Before the bulk load, you can turn off the enforcement of the Zip constraint:
ALTER TABLE PROSPECT
CONSTRAINT Zip NOT ENFORCED;
After the bulk load is complete, you can restore enforcement of the constraint:
ALTER TABLE PROSPECT
CONSTRAINT Zip ENFORCED;
At this point you can eliminate any rows that do not satisfy the constraint with:
DELETE FROM PROSPECT
WHERE PostalCode NOT BETWEEN 0 AND 99999 ;
Assertions
An assertion specifies a restriction for more than one table. The following example uses a search condition drawn from two tables to create an assertion:
CREATE TABLE ORDERS (
OrderNumber INTEGER NOT NULL,
ClientName CHAR (30),
TestOrdered CHAR (30),
Salesperson CHAR (30),
OrderDate DATE
) ;
CREATE TABLE RESULTS (
ResultNumber INTEGER NOT NULL,
OrderNumber INTEGER,
Result CHAR (50),
DateOrdered DATE,
PrelimFinal CHAR (1)
) ;
CREATE ASSERTION
CHECK (NOT EXISTS (SELECT * FROM ORDERS, RESULTS
WHERE ORDERS.OrderNumber = RESULTS.OrderNumber
AND ORDERS.OrderDate > RESULTS.DateReported)) ;
This assertion ensures that test results aren’t reported before the test is ordered.
Normalizing the Database
Some ways of organizing data are better than others. Some are more logical. Some are simpler. Some are better at preventing inconsistencies when you start using the database. Yep, modifying a database opens another whole nest of troubles and (fortunately) their solutions, known respectively as . . .
Modification anomalies and normal forms
A host of problems — called modification anomalies — can plague a database if you don’t structure the database correctly. To prevent these problems, you can normalize the database structure. Normalization generally entails splitting one database table into two simpler tables.
Modification anomalies are so named because they are generated by the addition of, change to, or deletion of data from a database table.
To illustrate how modification anomalies can occur, consider the table shown in Figure 5-2.
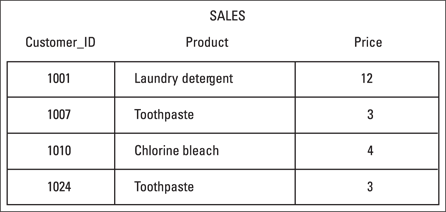
Figure 5-2: This SALES table leads to modification anomalies.
Suppose, for example, that your company sells household cleaning and personal-care products, and you charge all customers the same price for each product. The SALES table keeps track of everything for you. Now assume that customer 1001 moves out of the area and no longer is a customer. You don’t care what he’s bought in the past, because he’s not going to buy anything from your company again. You want to delete his row from the table. If you do so, however, you don’t just lose the fact that customer 1001 has bought laundry detergent; you also lose the fact that laundry detergent costs $12. This situation is called a deletion anomaly. In deleting one fact (that customer 1001 bought laundry detergent), you inadvertently delete another fact (that laundry detergent costs $12).
You can use the same table to illustrate an insertion anomaly. For example, suppose you want to add stick deodorant to your product line at a price of $2. You can’t add this data to the SALES table until a customer buys stick deodorant.
The problem with the SALES table in the figure is that this table deals with more than one thing: It covers not just which products customers buy, but also what the products cost. To eliminate the anomalies, you have to split the SALES table into two tables, each dealing with only one theme or idea, as shown in Figure 5-3.
Figure 5-3 shows the SALES table divided into two tables:
![]() CUST_PURCH, which deals with the single idea of customer purchases.
CUST_PURCH, which deals with the single idea of customer purchases.
![]() PROD_PRICE, which deals with the single idea of product pricing.
PROD_PRICE, which deals with the single idea of product pricing.
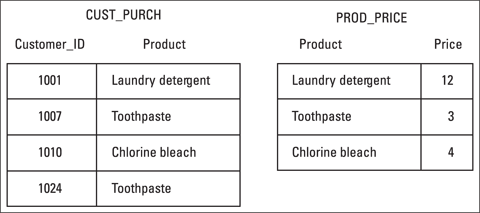
Figure 5-3: Splitting the SALES table into two tables.
You can now delete the row for customer 1001 from CUST_PURCH without losing the fact that laundry detergent costs $12. (The cost of laundry detergent is now stored in PROD_PRICE.) You can also add stick deodorant to PROD_PRICE whether or not anyone has bought the product. Purchase information is stored elsewhere, in the CUST_PURCH table.
The process of breaking up a table into multiple tables, each of which has a single theme, is called normalization. A normalization operation that solves one problem may not affect other problems. You may have to perform several successive normalization operations to reduce each resulting table to a single theme. Each database table should deal with one — and only one — main theme. Sometimes (as you probably guessed) determining that a table really deals with two or more themes can be difficult.
 You can classify tables according to the types of modification anomalies to which they’re subject. In a 1970 paper, E. F. Codd, the first to describe the relational model, identified three sources of modification anomalies and defined first, second, and third normal forms (1NF, 2NF, 3NF) as remedies to those types of anomalies. In the ensuing years, Codd and others discovered additional types of anomalies and specified new normal forms to deal with them. The Boyce-Codd normal form (BCNF), the fourth normal form (4NF), and the fifth normal form (5NF) each afforded a higher degree of protection against modification anomalies. Not until 1981, however, did a paper, written by Ronald Fagin, describe domain-key normal form or DK/NF (which gets a whole section to itself later in this chapter). Using this last normal form enables you to guarantee that a table is free of modification anomalies.
You can classify tables according to the types of modification anomalies to which they’re subject. In a 1970 paper, E. F. Codd, the first to describe the relational model, identified three sources of modification anomalies and defined first, second, and third normal forms (1NF, 2NF, 3NF) as remedies to those types of anomalies. In the ensuing years, Codd and others discovered additional types of anomalies and specified new normal forms to deal with them. The Boyce-Codd normal form (BCNF), the fourth normal form (4NF), and the fifth normal form (5NF) each afforded a higher degree of protection against modification anomalies. Not until 1981, however, did a paper, written by Ronald Fagin, describe domain-key normal form or DK/NF (which gets a whole section to itself later in this chapter). Using this last normal form enables you to guarantee that a table is free of modification anomalies.
The normal forms are nested in the sense that a table that’s in 2NF is automatically also in 1NF. Similarly, a table in 3NF is automatically in 2NF, and so on. For most practical applications, putting a database in 3NF is sufficient to ensure a high degree of integrity. To be absolutely sure of its integrity, you must put the database into DK/NF; for more about why, flip ahead to the “Domain-key normal form (DK/NF)” section.
After you normalize a database as much as possible, you may want to make selected denormalizations to improve performance. If you do, be aware of the types of anomalies that may now become possible.
First normal form
To be in first normal form (1NF), a table must have the following qualities:
![]() The table is two-dimensional with rows and columns.
The table is two-dimensional with rows and columns.
![]() Each row contains data that pertains to some thing or portion of a thing.
Each row contains data that pertains to some thing or portion of a thing.
![]() Each column contains data for a single attribute of the thing it’s describing.
Each column contains data for a single attribute of the thing it’s describing.
![]() Each cell (intersection of a row and a column) of the table must have only a single value.
Each cell (intersection of a row and a column) of the table must have only a single value.
![]() Entries in any column must all be of the same kind. If, for example, the entry in one row of a column contains an employee name, all the other rows must contain employee names in that column, too.
Entries in any column must all be of the same kind. If, for example, the entry in one row of a column contains an employee name, all the other rows must contain employee names in that column, too.
![]() Each column must have a unique name.
Each column must have a unique name.
![]() No two rows may be identical (that is, each row must be unique).
No two rows may be identical (that is, each row must be unique).
![]() The order of the columns and the order of the rows are not significant.
The order of the columns and the order of the rows are not significant.
A table (relation) in first normal form is immune to some kinds of modification anomalies but is still subject to others. The SALES table shown in Figure 5-2 is in first normal form, and as discussed previously, the table is subject to deletion and insertion anomalies. First normal form may prove useful in some applications but unreliable in others.
Second normal form
To appreciate second normal form, you must understand the idea of functional dependency. A functional dependency is a relationship between or among attributes. One attribute is functionally dependent on another if the value of the second attribute determines the value of the first attribute. If you know the value of the second attribute, you can determine the value of the first attribute.
Suppose, for example, that a table has attributes (columns) StandardCharge, NumberOfTests, and TotalCharge that relate through the following equation:
TotalCharge = StandardCharge * NumberOfTests
TotalCharge is functionally dependent on both StandardCharge and NumberOfTests. If you know the values of StandardCharge and NumberOfTests, you can determine the value of TotalCharge.
Every table in first normal form must have a unique primary key. That key may consist of one or more than one column. A key consisting of more than one column is called a composite key. To be in second normal form (2NF), all non-key attributes (columns) must depend on the entire key. Thus, every relation that is in 1NF with a single attribute key is automatically in second normal form. If a relation has a composite key, all non-key attributes must depend on all components of the key. If you have a table where some non-key attributes don’t depend on all components of the key, break the table up into two or more tables so that — in each of the new tables — all non-key attributes depend on all components of the primary key.
Sound confusing? Look at an example to clarify matters. Consider a table like the SALES table back in Figure 5-2. Instead of recording only a single purchase for each customer, you add a row every time a customer buys an item for the first time. An additional difference is that charter customers (those with Customer_ID values of 1001 to 1007) get a discount off the normal price. Figure 5-4 shows some of this table's rows.

Figure 5-4: In the SALES_TRACK table, the Customer_ID and Product columns constitute a composite key.
In Figure 5-4, Customer_ID does not uniquely identify a row. In two rows, Customer_ID is 1001. In two other rows, Customer_ID is 1010. The combination of the Customer_ID column and the Product column uniquely identifies a row. These two columns together are a composite key.
If not for the fact that some customers qualify for a discount and others don't, the table wouldn't be in second normal form, because Price (a non-key attribute) would depend only on part of the key (Product). Because some customers do qualify for a discount, Price depends on both CustomerID and Product, and the table is in second normal form.
Third normal form
Tables in second normal form are especially vulnerable to some types of modification anomalies — in particular, those that come from transitive dependencies.
A transitive dependency occurs when one attribute depends on a second attribute, which depends on a third attribute. Deletions in a table with such a dependency can cause unwanted information loss. A relation in third normal form is a relation in second normal form with no transitive dependencies.
Look again at the SALES table in Figure 5-2, which you know is in first normal form. As long as you constrain entries to permit only one row for each Customer_ID, you have a single-attribute primary key, and the table is in second normal form. However, the table is still subject to anomalies. What if customer 1010 is unhappy with the chlorine bleach, for example, and returns the item for a refund? You want to remove the third row from the table, which records the fact that customer 1010 bought chlorine bleach. You have a problem: If you remove that row, you also lose the fact that chlorine bleach has a price of $4. This situation is an example of a transitive dependency. Price depends on Product, which, in turn, depends on the primary key Customer_ID.
Breaking the SALES table into two tables solves the transitive dependency problem. The two tables shown in Figure 5-3, CUST_PURCH and PROD_PRICE, make up a database that’s in third normal form.
Domain-key normal form (DK/NF)
After a database is in third normal form, you’ve eliminated most, but not all, chances of modification anomalies. Normal forms beyond the third are defined to squash those few remaining bugs. Boyce-Codd normal form (BCNF), fourth normal form (4NF), and fifth normal form (5NF) are examples of such forms. Each form eliminates a possible modification anomaly but doesn’t guarantee prevention of all possible modification anomalies. Domain-key normal form, however, provides such a guarantee.
A relation is in domain-key normal form (DK/NF) if every constraint on the relation is a logical consequence of the definition of keys and domains. A constraint in this definition is any rule that’s precise enough that you can evaluate whether or not it’s true. A key is a unique identifier of a row in a table. A domain is the set of permitted values of an attribute.
Look again at the database in Figure 5-2, which is in 1NF, to see what you must do to put that database in DK/NF.
|
Table: |
SALES ( |
|
Key: |
|
|
Constraints: |
1. |
To enforce Constraint 3 (that Customer_ID must be an integer greater than 1000), you can simply define the domain for Customer_ID to incorporate this constraint. That makes the constraint a logical consequence of the domain of the CustomerID column. Product depends on Customer_ID, and Customer_ID is a key, so you have no problem with Constraint 1, which is a logical consequence of the definition of the key. Constraint 2 is a problem. Price depends on (is a logical consequence of) Product, and Product isn't a key. The solution is to divide the SALES table into two tables. One table uses Customer_ID as a key, and the other uses Product as a key. This setup is what you have in Figure 5-3. The database in Figure 5-3, besides being in 3NF, is also in DK/NF.
Design your databases so they’re in DK/NF if possible. If you can do that, then enforcing key and domain restrictions causes all constraints to be met, and modification anomalies aren’t possible. If a database’s structure is designed in a way that prevents you from putting it into DK/NF, then you have to build the constraints into the application program that uses the database. The database itself doesn’t guarantee that the constraints will be met.
Abnormal form
As in life, so in databases: Sometimes being abnormal pays off. You can get carried away with normalization and go too far. You can break up a database into so many tables that the entire thing becomes unwieldy and inefficient. Performance can plummet. Often the optimal structure for your database is somewhat denormalized. In fact, practical databases (the really big ones, anyway) are almost never normalized all the way to DK/NF. You want to normalize the databases you design as much as possible, however, to eliminate the possibility of data corruption that results from modification anomalies.
After you normalize the database as far as you can, make some retrievals as a dry run. If performance isn’t satisfactory, examine your design to see whether selective denormalization would improve performance without sacrificing integrity. By carefully adding redundancy in strategic locations and denormalizing just enough, you can arrive at a database that’s both efficient and safe from anomalies.