
Chapter 6
Manipulating Database Data
In This Chapter
![]() Dealing with data
Dealing with data
![]() Retrieving the data you want from a table
Retrieving the data you want from a table
![]() Displaying only selected information from one or more tables
Displaying only selected information from one or more tables
![]() Updating the information in tables and views
Updating the information in tables and views
![]() Adding a new row to a table
Adding a new row to a table
![]() Changing some or all of the data in a table row
Changing some or all of the data in a table row
![]() Deleting a table row
Deleting a table row
Chapters 3 and 4 reveal that creating a sound database structure is critical to maintaining data integrity. The stuff you’re really interested in, however, is the data itself — not its structure. At any given time, you probably want to do one of four things with data: add it to tables, retrieve and display it, change it, or delete it from tables.
In principle, database manipulation is quite simple. Understanding how to add data to a table isn't difficult — you can add your data either one row at a time or in a batch. Changing, deleting, or retrieving one or more table rows is also easy in practice. The main challenge to database manipulation is selecting the rows that you want to change, delete, or retrieve. The data you want may reside in a database that contains a large volume of data you don't want. Fortunately, if you can specify what you want by using an SQL SELECT statement, the computer does all the searching for you. I guess that means manipulating a database with SQL is a piece of cake. Adding, changing, deleting, and retrieving are all easy! (Hmmm. Perhaps "easy" might be a slight exaggeration.) At least you get to start off easy with simple data retrieval.
Retrieving Data
The data-manipulation task that users perform most frequently is retrieving selected information from a database. You may want to retrieve the contents of one row out of thousands in a table. You may want to retrieve all rows that satisfy a condition or a combination of conditions. You may even want to retrieve all rows in the table. One particular SQL statement, the SELECT statement, performs all these tasks for you.
The simplest use of the SELECT statement is to retrieve all the data in all the rows of a specified table. To do so, use the following syntax:
SELECT * FROM CUSTOMER ;
 The asterisk (
The asterisk (*) is a wildcard character that means everything. In this context, the asterisk is a shorthand substitute for a listing of all the column names of the CUSTOMER table. As a result of this statement, all the data in all the rows and columns of the CUSTOMER table appear onscreen.
SELECT statements can be much more complicated than the statement in this example. In fact, some SELECT statements can be so complicated that they're virtually indecipherable. This potential complexity is a result of the fact that you can tack multiple modifying clauses onto the basic statement. Chapter 10 covers modifying clauses in detail; in this chapter, I briefly discuss the WHERE clause, which is the most commonly used method of restricting the rows that a SELECT statement returns.
A SELECT statement with a WHERE clause has the following general form:
SELECT column_list FROM table_name
WHERE condition ;
The column list specifies which columns you want to display. The statement displays only the columns that you list. The FROM clause specifies from which table you want to display columns. The WHERE clause excludes rows that don't satisfy a specified condition. The condition may be simple (for example, WHERE CUSTOMER_STATE = 'NH'), or it may be compound (for example, WHERE CUSTOMER_STATE='NH' AND STATUS='Active').
The following example shows a compound condition inside a SELECT statement:
SELECT FirstName, LastName, Phone FROM CUSTOMER
WHERE State = 'NH'
AND Status = 'Active' ;
This statement returns the names and phone numbers of all active customers living in New Hampshire. The AND keyword means that for a row to qualify for retrieval, that row must meet both conditions: State = 'NH' and Status = 'Active'.
Creating Views
The structure of a database that’s designed according to sound principles — including appropriate normalization (see Chapter 5) — maximizes the integrity of the data. This structure, however, is often not the best way to look at the data. Several applications may use the same data, but each application may have a different emphasis. One of the most powerful features of SQL is its capability to display views of the data that are structured differently from how the database tables store the data. The tables you use as sources for columns and rows in a view are the base tables. Chapter 3 discusses views as part of the Data Definition Language (DDL); this section looks at views in the context of retrieving and manipulating data.
A SELECT statement always returns a result in the form of a virtual table. A view is a special kind of virtual table. You can distinguish a view from other virtual tables because the database's metadata holds the definition of a view. This distinction gives a view a degree of persistence that other virtual tables don't possess.
 You can manipulate a view just as you can manipulate a real table. The difference is that a view’s data doesn’t have an independent existence. The view derives its data from the table or tables from which you draw the view’s columns. Each application can have its own unique views of the same data.
You can manipulate a view just as you can manipulate a real table. The difference is that a view’s data doesn’t have an independent existence. The view derives its data from the table or tables from which you draw the view’s columns. Each application can have its own unique views of the same data.
Consider the VetLab database that I describe in Chapter 5. That database contains five tables: CLIENT, TESTS, EMPLOYEE, ORDERS, and RESULTS. Suppose the national marketing manager wants to see from which states the company’s orders are coming. Some of this information lies in the CLIENT table; some lies in the ORDERS table. Suppose the quality-control officer wants to compare the order date of a test to the date on which the final test result came in. This comparison requires some data from the ORDERS table and some from the RESULTS table. To satisfy needs such as these, you can create views that give you exactly the data you want in each case.
From tables
For the marketing manager, you can create the view shown in Figure 6-1.

Figure 6-1: The ORDERS_BY_STATE view for the marketing manager.
The following statement creates the marketing manager’s view:
CREATE VIEW ORDERS_BY_STATE
(ClientName, State, OrderNumber)
AS SELECT CLIENT.ClientName, State, OrderNumber
FROM CLIENT, ORDERS
WHERE CLIENT.ClientName = ORDERS.ClientName ;
The new view has three columns: ClientName, State, and OrderNumber. ClientName appears in both the CLIENT and ORDERS tables and serves as the link between the two tables. The new view draws State information from the CLIENT table and takes the OrderNumber from the ORDERS table. In the preceding example, you declare the names of the columns explicitly in the new view.
Note that I prefixed ClientName with the table that contains it, but I didn't do that for State and OrderNumber. That is because State appears only in the CLIENT table and OrderNumber appears only in the ORDERS table, so there is no ambiguity. However, ClientName appears in both CLIENT and ORDERS, so the additional identifier is needed.
You don't need this declaration if the names are the same as the names of the corresponding columns in the source tables. The example in the following section shows a similar CREATE VIEW statement, except that the view column names are implied rather than explicitly stated.
With a selection condition
The quality-control officer requires a different view from the one that the marketing manager uses, as shown by the example in Figure 6-2.

Figure 6-2: The REPORTING_LAG view for the quality-control officer.
Here’s the code that creates the view in Figure 6-2:
CREATE VIEW REPORTING_LAG
AS SELECT ORDERS.OrderNumber, OrderDate, DateReported
FROM ORDERS, RESULTS
WHERE ORDERS.OrderNumber = RESULTS.OrderNumber
AND RESULTS.PreliminaryFinal = 'F' ;
This view contains order-date information from the ORDERS table and final-report-date information from the RESULTS table. Only rows that have an 'F' in the PreliminaryFinal column of the RESULTS table appear in the REPORTING_LAG view. Note also that the column list in the ORDERS_BY_STATE view is optional. The REPORTING_LAG view works fine without such a list.
With a modified attribute
The SELECT clauses in the examples in the two preceding sections contain only column names. You can include expressions in the SELECT clause as well. Suppose VetLab's owner is having a birthday and wants to give all his customers a 10-percent discount to celebrate. He can create a view based on the ORDERS table and the TESTS table. He may construct this table as shown in the following code example:
CREATE VIEW BIRTHDAY
(ClientName, Test, OrderDate, BirthdayCharge)
AS SELECT ClientName, TestOrdered, OrderDate,
StandardCharge * .9
FROM ORDERS, TESTS
WHERE TestOrdered = TestName ;
Notice that the second column in the BIRTHDAY view — Test — corresponds to the TestOrdered column in the ORDERS table, which also corresponds to the TestName column in the TESTS table. Figure 6-3 shows how to create this view.

Figure 6-3: The view created to show birthday discounts.
You can build a view based on multiple tables, as shown in the preceding examples, or you can build a view based on a single table. If you don’t need some of the columns or rows in a table, create a view to remove these elements from sight and then deal with the view rather than the original table. This approach ensures that users see only the parts of the table that are relevant to the task at hand.
Another reason for creating a view is to provide security for its underlying tables. You may want to make some columns in your tables available for inspection while hiding others. You can create a view that includes only those columns that you want to make available and then grant broad access to that view while restricting access to the tables from which you draw the view. (Chapter 14 explores database security and describes how to grant and revoke data-access privileges.)
Updating Views
After you create a table, that table is automatically capable of accommodating insertions, updates, and deletions. Views don’t necessarily exhibit the same capability. If you update a view, you’re actually updating its underlying table. Here are a few potential problems you may encounter when you update views:
![]() Some views may draw components from two or more tables. If you update such a view, the underlying tables may not be updated properly.
Some views may draw components from two or more tables. If you update such a view, the underlying tables may not be updated properly.
![]() A view may include an expression in a
A view may include an expression in a SELECT list. Because expressions don't map directly to rows in tables, your DBMS won't know how to update an expression.
Suppose you create a view by using the following statement:
CREATE VIEW COMP (EmpName, Pay)
AS SELECT EmpName, Salary+Comm AS Pay
FROM EMPLOYEE ;
You may think you can update Pay by using the following statement:
UPDATE COMP SET Pay = Pay + 100 ;
Unfortunately, this approach doesn't make any sense. That's because the underlying table has no Pay column. You can't update something that doesn't exist in the base table.
Keep the following rule in mind whenever you consider updating views: You can’t update a column in a view unless it corresponds to a column in an underlying base table.
Adding New Data
Every database table starts out empty. After you create a table, either by using SQL’s DDL or a RAD tool, that table is nothing but a structured shell containing no data. To make the table useful, you must put some data into it. You may or may not have that data already stored in digital form. Your data may appear in one of the following forms:
![]() Not yet compiled in any digital format: If your data is not already in digital form, someone will probably have to enter the data manually, one record at a time. You can also enter data by using optical scanners and voice-recognition systems, but the use of such devices for data entry is relatively rare.
Not yet compiled in any digital format: If your data is not already in digital form, someone will probably have to enter the data manually, one record at a time. You can also enter data by using optical scanners and voice-recognition systems, but the use of such devices for data entry is relatively rare.
![]() Compiled in some sort of digital format: If your data is already in digital form — but perhaps not in the format of the database tables you use — you have to translate the data into the appropriate format and then insert the data into the database.
Compiled in some sort of digital format: If your data is already in digital form — but perhaps not in the format of the database tables you use — you have to translate the data into the appropriate format and then insert the data into the database.
![]() Compiled in the correct digital format: If your data is already in digital form and in the correct format, you’re ready to transfer it to a new database.
Compiled in the correct digital format: If your data is already in digital form and in the correct format, you’re ready to transfer it to a new database.
The following sections address adding data to a table when it exists in each of these three forms. Depending on the current form of the data, you may be able to transfer it to your database in one operation, or you may need to enter the data one record at a time. Each data record you enter corresponds to a single row in a database table.
Adding data one row at a time
Most DBMSs support form-based data entry. This feature enables you to create a screen form that has a field for every column in a database table. Field labels on the form enable you to determine easily what data goes into each field. The data-entry operator enters all the data for a single row into the form. After the DBMS accepts the new row, the system clears the form to accept another row. In this way, you can easily add data to a table one row at a time.
Form-based data entry is easy and less susceptible to data-entry errors than using a list of comma-delimited values. The main problem with form-based data entry is that it is nonstandard; each DBMS has its own method of creating forms. This diversity, however, is not a problem for the data-entry operator. You can make the form look generally the same from one DBMS to another. (The data-entry operator may not suffer too much, but the application developer must return to the bottom of the learning curve every time he or she changes development tools.) Another possible problem with form-based data entry is that some implementations may not permit a full range of validity checks on the data that you enter.
The best way to maintain a high level of data integrity in a database is to keep bad data out of the database. You can prevent the entry of some bad data by applying constraints to the fields on a data-entry form. This approach enables you to make sure that the database accepts only data values of the correct type and within a predefined range. Such constraints can’t prevent all possible errors, but they can catch some errors.
If the form-design tool in your DBMS doesn't let you apply all the validity checks that you need to ensure data integrity, you may want to build your own screen, accept data entries into variables, and check the entries by using application program code. After you're sure that all the values entered for a table row are valid, you can then add that row by using the SQL INSERT command.
If you enter the data for a single row into a database table, the INSERT command uses the following syntax:
INSERT INTO table_1 [(column_1, column_2, ..., column_n)]
VALUES (value_1, value_2, ..., value_n) ;
As indicated by the square brackets ([ ]), the listing of column names is optional. The default column list order is the order of the columns in the table. If you put the VALUES in the same order as the columns in the table, these elements go into the correct columns — whether you specify those columns explicitly or not. If you want to specify the VALUES in some order other than the order of the columns in the table, you must list the column names in the same order as the list of values in the VALUES clause.
To enter a record into the CUSTOMER table, for example, use the following syntax:
INSERT INTO CUSTOMER (CustomerID, FirstName, LastName,
Street, City, State, Zipcode, Phone)
VALUES (:vcustid, 'David', 'Taylor', '235 Loco Ave.',
'El Pollo', 'CA', '92683', '(617) 555-1963') ;
The first VALUE in the third line, vcustid, is a variable that you increment with your program code after you enter each new row of the table. This approach guarantees that you have no duplication of the CustomerID (which is the primary key for this table and must be unique). The rest of the values are data items rather than variables that contain data items. Of course, you can hold the data for these columns in variables, too, if you want. The INSERT statement works equally well whether you use variables or an explicit copy of the data itself to form the arguments of the VALUES keyword.
Adding data only to selected columns
Sometimes you want to note the existence of an object even if you don’t have all the facts on it yet. If you have a database table for such objects, you can insert a row for the new object without filling in the data in all the columns. If you want the table in first normal form, you must insert enough data to distinguish the new row from all the other rows in the table. (For the intricacies of the normal forms, including first, see Chapter 5.) Inserting the new row’s primary key is sufficient for this purpose. In addition to the primary key, insert any other data that you have about the object. Columns in which you enter no data contain nulls.
The following example shows such a partial row entry:
INSERT INTO CUSTOMER (CustomerID, FirstName, LastName)
VALUES (:vcustid, 'Tyson', 'Taylor') ;
You insert only the customer’s unique identification number and name into the database table. The other columns in this row contain null values.
Adding a block of rows to a table
Loading a database table one row at a time by using INSERT statements can be tedious, particularly if that's all you do. Even entering the data into a carefully human-engineered ergonomic screen form gets tiring after a while. Clearly, if you have a reliable way to enter the data automatically, you'll find occasions in which automatic entry is better than having a person sit at a keyboard and type.
Automatic data entry is feasible, for example, if the data exists in electronic form because somebody has already entered the data manually. If so, there’s no reason to repeat history. Transferring data from one data file to another is a task that a computer can perform with minimal human involvement. If you know the characteristics of the source data and the desired form of the destination table, a computer can (in principle) perform the data transfer automatically.
Copying from a foreign data file
Suppose you’re building a database for a new application. Some data that you need already exists in a computer file. The file may be a flat file or a table in a database created by a DBMS different from the one you use. The data may be in ASCII or EBCDIC code or in some arcane proprietary format. What do you do?
The first things you do are hope and pray that the data you want is in a widely used format. If the data is in a popular format, you have a good chance of finding a format-conversion utility that can translate the data into one or more other popular formats. Your development environment can probably import at least one of these formats; if you’re really lucky, your development environment can handle the current data format directly. On personal computers, the Access, xBASE, and MySQL formats are the most widely used. If the data you want is in one of these formats, conversion should be easy. If the format of the data is less common, you may have to put it through a two-step conversion.
If the data is in an old, proprietary, or defunct format, as a last resort, you can turn to a professional data-translation service. These businesses specialize in translating computer data from one format to another. They deal with hundreds of formats — most of which nobody has ever heard of. Give one of these services a tape or disk containing the data in its original format, and you get back the same data translated into whatever format you specify.
Transferring all rows between tables
A less severe problem than dealing with foreign data is taking data that already exists in one table in your database and combining that data with compatible data in another table. This process works great if the structure of the second table is identical to the structure of the first table — that is, every column in the first table has a corresponding column in the second table, and the data types of the corresponding columns match. In that case, you can combine the contents of the two tables by using the UNION relational operator. The result is a virtual table (that is, one that has no independent existence) that contains data from both source tables. I discuss the relational operators, including UNION, in Chapter 11.
Transferring selected columns and rows between tables
Generally, the structure of the data in the source table isn't identical to the structure of the table into which you want to insert the data. Perhaps only some of the columns match, and these are the columns that you want to transfer. By combining SELECT statements with a UNION, you can specify which columns from the source tables to include in the virtual result table. By including WHERE clauses in the SELECT statements, you can restrict the rows that you place into the result table to those that satisfy specific conditions. (I cover WHERE clauses extensively in Chapter 10.)
Suppose that you have two tables, PROSPECT and CUSTOMER, and you want to list everyone living in the state of Maine who appears in either table. You can create a virtual result table that contains the desired information; just use the following command:
SELECT FirstName, LastName
FROM PROSPECT
WHERE State = 'ME'
UNION
SELECT FirstName, LastName
FROM CUSTOMER
WHERE State = 'ME' ;
Here’s a closer look:
![]() The
The SELECT statements specify that the columns included in the result table are FirstName and LastName.
![]() The
The WHERE clauses restrict the rows included to those with the value 'ME' in the State column.
![]() The
The State column isn't included in the results table but is present in both the PROSPECT and CUSTOMER tables.
![]() The
The UNION operator combines the results of the SELECT statement on PROSPECT with the results of the SELECT on CUSTOMER, deletes any duplicate rows, and then displays the result.
Another way to copy data from one table in a database to another is to nest a SELECT statement within an INSERT statement. This method (known as a subselect and detailed in Chapter 12) doesn't create a virtual table; instead, it duplicates the selected data. You can take all the rows from the CUSTOMER table, for example, and insert those rows into the PROSPECT table. Of course, this works only if the structures of the CUSTOMER and PROSPECT tables are identical. If you want to place only those customers who live in Maine into the PROSPECT table, a simple SELECT with one condition in the WHERE clause does the trick, as shown in the following example:
INSERT INTO PROSPECT
SELECT * FROM CUSTOMER
WHERE State = 'ME' ;
 Even though this operation creates redundant data (you're now storing customer data in both the PROSPECT table and the CUSTOMER table), you may want to do it anyway to improve the performance of retrievals. Beware of the redundancy, however! To maintain data consistency, make sure that you don't insert, update, or delete rows in one table without inserting, updating, or deleting the corresponding rows in the other table. Another potential problem is the possibility that the
Even though this operation creates redundant data (you're now storing customer data in both the PROSPECT table and the CUSTOMER table), you may want to do it anyway to improve the performance of retrievals. Beware of the redundancy, however! To maintain data consistency, make sure that you don't insert, update, or delete rows in one table without inserting, updating, or deleting the corresponding rows in the other table. Another potential problem is the possibility that the INSERT statement might generate duplicate primary keys. If even one pre-existing prospect has a primary key of ProspectID that matches the corresponding primary key (CustomerID) of a customer you're trying to insert into the PROSPECT table, the insert operation will fail. If both tables have autoincrementing primary keys, you don't want them to start with the same number. Make sure the two blocks of numbers are far apart from each other.
Updating Existing Data
You can count on one thing in this world — change. If you don’t like the current state of affairs, just wait a while. Before long, things will be different. Because the world is constantly changing, the databases used to model aspects of the world also need to change. A customer may change her address. The quantity of a product in stock may change (because, you hope, someone buys an item now and then). A basketball player’s season performance statistics change each time he plays in another game. If your database contains such items, you have to update it periodically.
SQL provides the UPDATE statement for changing data in a table. By using a single UPDATE statement, you can change one, some, or all rows in a table. The UPDATE statement uses the following syntax:
UPDATE table_name
SET column_1 = expression_1, column_2 = expression_2,
..., column_n = expression_n
[WHERE predicates] ;
The WHERE clause is optional. This clause specifies the rows that you're updating. If you don't use a WHERE clause, all the rows in the table are updated. The SET clause specifies the new values for the columns that you're changing.
Consider the CUSTOMER table shown as Table 6-1.

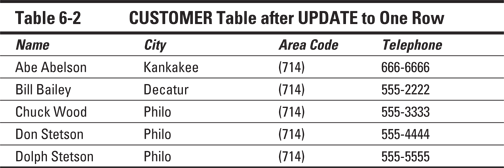
Customer lists change occasionally — as people move, change their phone numbers, and so on. Suppose that Abe Abelson moves from Springfield to Kankakee. You can update his record in the table by using the following UPDATE statement:
UPDATE CUSTOMER
SET City = 'Kankakee', Telephone = '666-6666'
WHERE Name = 'Abe Abelson' ;
This statement causes the changes shown in Table 6-2.
You can use a similar statement to update multiple rows. Assume that Philo is experiencing explosive population growth and now requires its own area code. You can change all rows for customers who live in Philo by using a single UPDATE statement, as follows:
UPDATE CUSTOMER
SET AreaCode = '(619)'
WHERE City = 'Philo' ;
The table now looks like the one shown in Table 6-3.

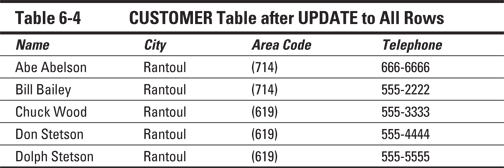
Updating all the rows of a table is even easier than updating only some of the rows. You don't need to use a WHERE clause to restrict the statement. Imagine that the city of Rantoul has acquired major political clout and has now annexed not only Kankakee, Decatur, and Philo, but also all the cities and towns in the database. You can update all the rows by using a single statement, as follows:
UPDATE CUSTOMER
SET City = 'Rantoul' ;
Table 6-4 shows the result.
When you use the WHERE clause with the UPDATE statement to restrict which rows are updated, the contents of the WHERE clause can be a subselect — a SELECT statement, the result of which is used as input by another SELECT statement.
For example, suppose that you're a wholesaler and your database includes a VENDOR table containing the names of all the manufacturers from whom you buy products. You also have a PRODUCT table containing the names of all the products that you sell and the prices that you charge for them. The VENDOR table has columns VendorID, VendorName, Street, City, State, and Zip. The PRODUCT table has ProductID, ProductName, VendorID, and SalePrice.
Your vendor, Cumulonimbus Corporation, decides to raise the prices of all its products by 10 percent. To maintain your profit margin, you must raise your prices on the products that you obtain from Cumulonimbus by 10 percent. You can do so by using the following UPDATE statement:
UPDATE PRODUCT
SET SalePrice = (SalePrice * 1.1)
WHERE VendorID IN
(SELECT VendorID FROM VENDOR
WHERE VendorName = 'Cumulonimbus Corporation') ;
The subselect finds the VendorID that corresponds to Cumulonimbus. You can then use the VendorID field in the PRODUCT table to find the rows that you want to update. The prices on all Cumulonimbus products increase by 10 percent; the prices on all other products stay the same. (I discuss subselects more extensively in Chapter 12.)
Transferring Data
In addition to using the INSERT and UPDATE statements, you can add data to a table or view by using the MERGE statement. You can MERGE data from a source table or view into a destination table or view. The MERGE can either insert new rows into the destination table or update existing rows. MERGE is a convenient way to take data that already exists somewhere in a database and copy it to a new location.
For example, consider the VetLab database that I describe in Chapter 5. Suppose some people in the EMPLOYEE table are salespeople who have taken orders, whereas others are non-sales employees or salespeople who have not yet taken an order. The year just concluded has been profitable, and you want to share some of that success with the employees. You decide to give a bonus of $100 to everyone who has taken at least one order and a bonus of $50 to everyone else. First, you create a BONUS table and insert into it a record for each employee who appears at least once in the ORDERS table, assigning each record a default bonus value of $100.
Next, you want to use the MERGE statement to insert new records for those employees who have not taken orders, giving them $50 bonuses. Here's some code that builds and fills the BONUS table:
CREATE TABLE BONUS (
EmployeeName CHARACTER (30) PRIMARY KEY,
Bonus NUMERIC DEFAULT 100 ) ;
INSERT INTO BONUS (EmployeeName)
(SELECT EmployeeName FROM EMPLOYEE, ORDERS
WHERE EMPLOYEE.EmployeeName = ORDERS.Salesperson
GROUP BY EMPLOYEE.EmployeeName) ;
You can now query the BONUS table to see what it holds:
SELECT * FROM BONUS ;
EmployeeName Bonus
------------ -------------
Brynna Jones 100
Chris Bancroft 100
Greg Bosser 100
Kyle Weeks 100
Now, by executing a MERGE statement, you can give $50 bonuses to the rest of the employees:
MERGE INTO BONUS
USING EMPLOYEE
ON (BONUS.EmployeeName = EMPLOYEE.EmployeeName)
WHEN NOT MATCHED THEN INSERT
(BONUS.EmployeeName, BONUS.bonus)
VALUES (EMPLOYEE.EmployeeName, 50) ;
Records for people in the EMPLOYEE table that don’t match records for people already in the BONUS table are now inserted into the BONUS table. Now a query of the BONUS table gives the following result:
SELECT * FROM BONUS ;
EmployeeName Bonus
-------------- -----------
Brynna Jones 100
Chris Bancroft 100
Greg Bosser 100
Kyle Weeks 100
Neth Doze 50
Matt Bak 50
Sam Saylor 50
Nic Foster 50
The first four records, which were created with the INSERT statement, are in alphabetical order by employee name. The rest of the records, added by the MERGE statement, appear in whatever order they were listed in the EMPLOYEE table.
The MERGE statement is a relatively new addition to SQL and may not yet be supported by some DBMS products. Even newer is an additional capability of MERGE added in SQL:2011, paradoxically enabling you to delete records with a MERGE statement.
Suppose, after doing the INSERT, you decide that you do not want to give bonuses to people who have taken at least one order after all, but you do want to give a $50 bonus to everybody else. You can remove the sales bonuses and add the non-sales bonuses with the following MERGE statement:
MERGE INTO BONUS
USING EMPLOYEE
ON (BONUS.EmployeeName = EMPLOYEE.EmployeeName)
WHEN MATCHED THEN DELETE
WHEN NOT MATCHED THEN INSERT
(BONUS.EmployeeName, BONUS.bonus)
VALUES (EMPLOYEE.EmployeeName, 50);
The result is
SELECT * FROM BONUS;
EmployeeName Bonus
-------------- -----------
Neth Doze 50
Matt Bak 50
Sam Saylor 50
Nic Foster 50
Deleting Obsolete Data
As time passes, data can get old and lose its usefulness. You may want to remove this outdated data from its table. Unneeded data in a table slows performance, consumes memory, and can confuse users. You may want to transfer older data to an archive table and then take the archive offline. That way, in the unlikely event that you ever need to look at that data again, you can recover it. In the meantime, it doesn't slow down your everyday processing. Whether or not you decide that obsolete data is worth archiving, you eventually come to the point where you want to delete that data. SQL provides for the removal of rows from database tables by use of the DELETE statement.
You can delete all the rows in a table by using an unqualified DELETE statement, or you can restrict the deletion to only selected rows by adding a WHERE clause. The syntax is similar to the syntax of a SELECT statement, except that you don't need to specify columns. After all, if you want to delete a table row, you probably want to remove all the data in that row's columns.
For example, suppose that your customer, David Taylor, just moved to Switzerland and isn’t going to buy anything from you anymore. You can remove him from your CUSTOMER table by using the following statement:
DELETE FROM CUSTOMER
WHERE FirstName = 'David' AND LastName = 'Taylor';
Assuming that you have only one customer named David Taylor, this statement makes the intended deletion. If you have two or more customers who share the name David Taylor (which, after all, is a fairly common name in English-speaking countries), you can add more conditions to the WHERE clause (such as STREET or PHONE or CUSTOMER_ID) to make sure that you delete only the customer you want to remove. If you don't add a WHERE clause, all customers named David Taylor will be deleted.