
![]()
Data Cleansing with Data Quality Services
Data Quality Services (DQS) is a new product in SQL Server 2012 that provides data cleansing functionality – a key component for most ETL processes. This chapter describes how DQS integrates with SSIS, and provides patterns that enable you to achieve reliable, low effort data cleansing within your ETL packages.
![]() Note The Data Quality Services product requires some manual steps post-installation to create the DQS databases, and set default permissions. See the “Installing Data Quality Services” page in books online for more information: http://msdn.microsoft.com/en-us/library/gg492277(v=SQL.110).aspx
Note The Data Quality Services product requires some manual steps post-installation to create the DQS databases, and set default permissions. See the “Installing Data Quality Services” page in books online for more information: http://msdn.microsoft.com/en-us/library/gg492277(v=SQL.110).aspx
Overview of Data Quality Services
The data cleansing and matching operations you perform with DQS revolve around the use of a Knowledge Base. A Knowledge Base (or KB) is made up of one or more Domains. An example Domain for doing address cleansing would be City, State, or Country. Each of these fields would be a separate Domain. Two or more related domains can be grouped together to form a Composite Domain (or CD). Composite Domains allow you to validate multiple fields as a single unit. For example, a Company composite domain could be made up of Name, Address, City, State, and Country domains. Using a Composite Domain would allow you to validate that “Microsoft Corporation” (Name) exists at “One Redmond Way” (Address), “Redmond” (City), “WA” (State), “USA” (Country). If the DQS KB has all of the relevant knowledge, it would be able to flag the entry as incorrect if you had “Las Vegas” as the City – even though “Las Vegas” is a valid city name, the knowledge base has defined that the Microsoft office is located in “Redmond”.
Data Quality Services has three main components: the client utility (shown in Figure 5-1), which allows you to build and manage your knowledge bases; an SSIS Data Flow transform for bulk data cleansing; and a server component where the actual cleansing and matching takes place. The DQS server is not a standalone instance – is it essentially a set of user databases (DQS_MAIN, DQS_PROJECTS, DQS_STAGING_DATA) with a stored procedure based API - much like the SSIS Catalog in SQL Server 2012.
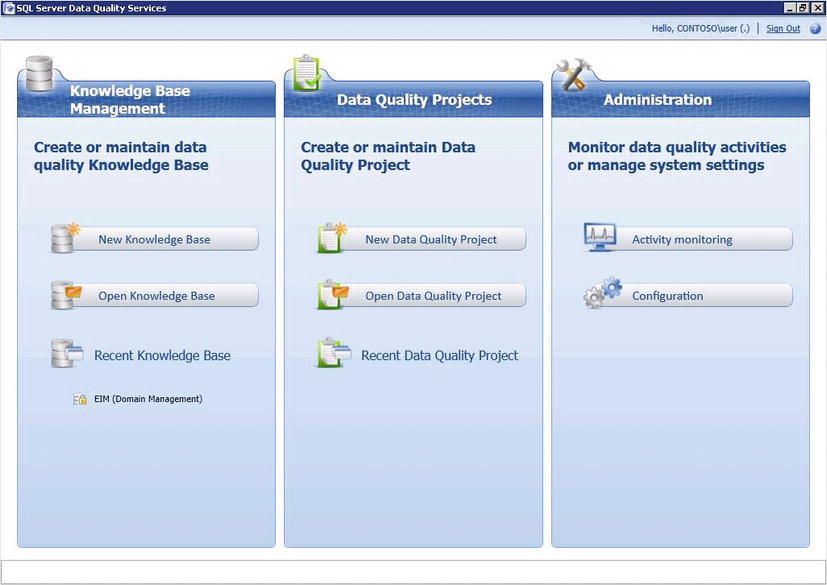
Figure 5-1. The Data Quality Client application
The Data Quality Client application is used to build and manage your knowledge bases. It can also be used as a standalone tool for cleansing data. The tool is targeted towards Data Stewards and IT Professionals who own and manage data within your organization. Users of the tool will fall into three different roles (shown in Table 5-1), which map to roles within the main DQS database. The functionality you can access through the tool will depend on what role you are currently assigned to.
Table 5-1. Data Quality Services Roles
| Name | SQL Role | Description |
|---|---|---|
| DQS KB Operator | dqs_kb_operator | User can edit and execute an existing data quality project. |
| DQS KB Editor | dqs_kb_editor | User can perform project functions, and create and edit knowledge bases. |
| DQS Administrator | dqs_administrator | User can perform project and knowledge functions, as well as administer the system. |
![]() Note Members of the sysadmin role on the SQL Server instance on which DQS is hosted have the same level of permissions as a DQS Administrator by default. It is recommended that you still associate users with one of the three DQS roles.
Note Members of the sysadmin role on the SQL Server instance on which DQS is hosted have the same level of permissions as a DQS Administrator by default. It is recommended that you still associate users with one of the three DQS roles.
The options under the Knowledge Base Management section allow you to create and maintain your knowledge bases. When creating a new knowledge base, you have the option to create an empty knowledge base, or to base it on an existing knowledge base, which will prepopulate the new knowledge base with the domains from the original. Knowledge bases can also be created from a DQS file (.dqs extension), allowing you to back up or share knowledge bases across systems.
You’ll perform three main activities when interacting with your knowledge bases through this UI (shown in Figure 5-2). These activities are available after you’ve created a new knowledge base, or have opened an existing one.
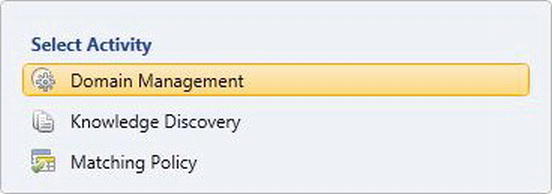
Figure 5-2. Knowledge base management activities
When doing Domain Management, you can verify and modify the domains within the knowledge base. This includes changing domain properties (shown in Figure 5-3), configuring online reference data, as well as viewing and modifying rules and values. You also have the option to export the knowledge base or individual domains to a DQS file, as well as import new domains from a DQS file.
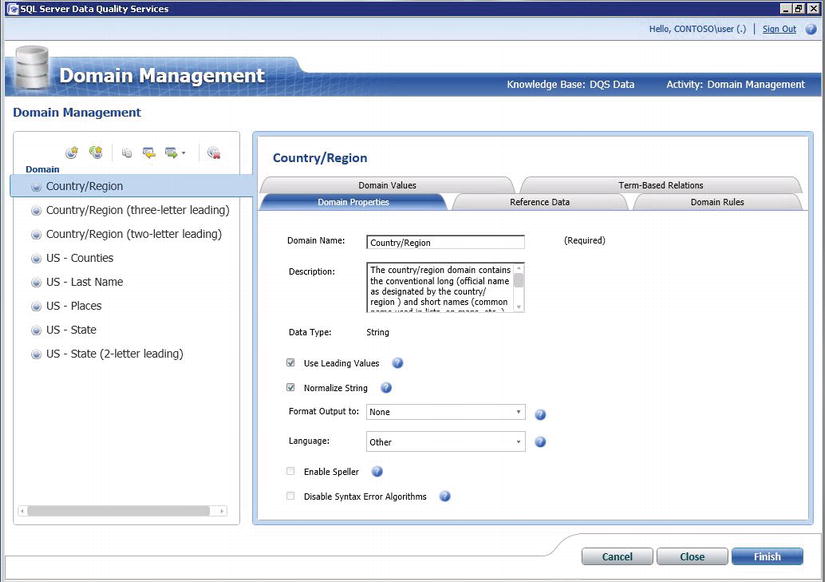
Figure 5-3. The Domain Properties tab of the Domain Management activity in the DQS Client
The Matching Policy activity is used to prepare DQS for the data de-duplication process. From this UI, a data steward can create a policy that contains one or more matching rules that DQS will use to determine how rows of data should be compared. DQS Matching functionality is not currently available through SSIS. You can perform this type of work using the DQS Client, and it is also available through the Excel add-in for noun phrases Services.
Knowledge Discovery is a computer-assisted process to build knowledge base information. You supply source data (from a SQL Server table or view, or Excel file), and map the input columns to knowledge base domains. This data will be imported into DQS, and stored as a set of known Domain Values.
A data quality project is one where you interactively cleanse or match your data. You’ll select the source of your data (SQL Server or an Excel file, which you can upload through the client), and then map source columns to domains within your knowledge base. Figure 5-4 shows a data quality project that will attempt to cleanse the EnglishCountryRegionName and CountryRegionCode columns against domains from the default DQS knowledge base.
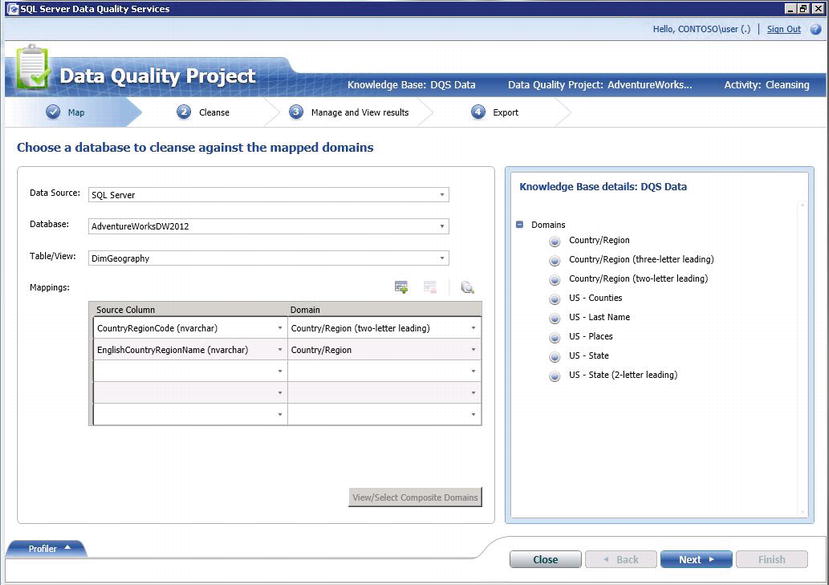
Figure 5-4. Creating a new data cleansing project
After you’ve mapped your columns to domains, DQS will process your data and provide you with the results of the cleansing operation. When you review the results, you have the option to approve or reject certain corrections, add new values to the list of known domain values, and specify correction rules. For example, as the data steward for your organization, you know that “Jack Ryan” and “John Ryan” is the same person. After approving the corrections, you can export the results to a SQL Server table, Excel file, or CSV file. DQS does not give you the option to correct the value in-place – you will need a separate process to update the original source data you examined.
At various times during the process you can save your data quality project. The project status is saved to the DQS server, allowing you to resume at a later point. This is especially useful when working with large sets of data that can take a while to scan. It also allows you to come back to the correction results in case you need to do some research on what the correct values should be for a particular domain.
To manage your active data quality projects, click on the Open Data Quality Project button on the home page of the client. From here, you can see all projects that are currently in progress. Right clicking on a project gives you management options, such as renaming the project or deleting it if it is no longer needed.
The Administration section is available to users in the DQS Administrator’s role. From here, you can monitor all activity on the DQS server (such as Domain Management, and Cleansing projects), and set system wide configuration options. From these pages, you can set logging levels for various operations, as well as set the minimum confidence scores for suggestions, and automatic corrections. If you are using online reference data from the Azure DataMarket, you’d configure your account information and service subscriptions from this page as well (as shown in Figure 5-5). More information about online reference data providers can be found later in this chapter.
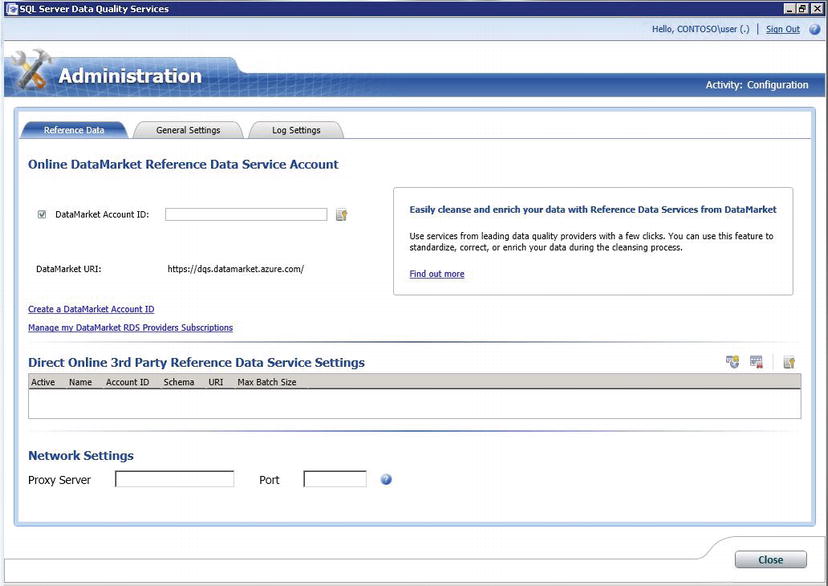
Figure 5-5. Configuration for online reference data in the SQL Azure DataMarket
Using the Default Knowledge Base
DQS comes with a default knowledge base containing domains related to cleansing and validation of Countries and locations within the United States. Figure 5-6 shows the Domain Values for the “US – State” domain. In this figure, you can see that “Alabama” has synonyms defined for it – it will automatically correct “AL” to “Alabama,” and mark “Ala.” as an error.
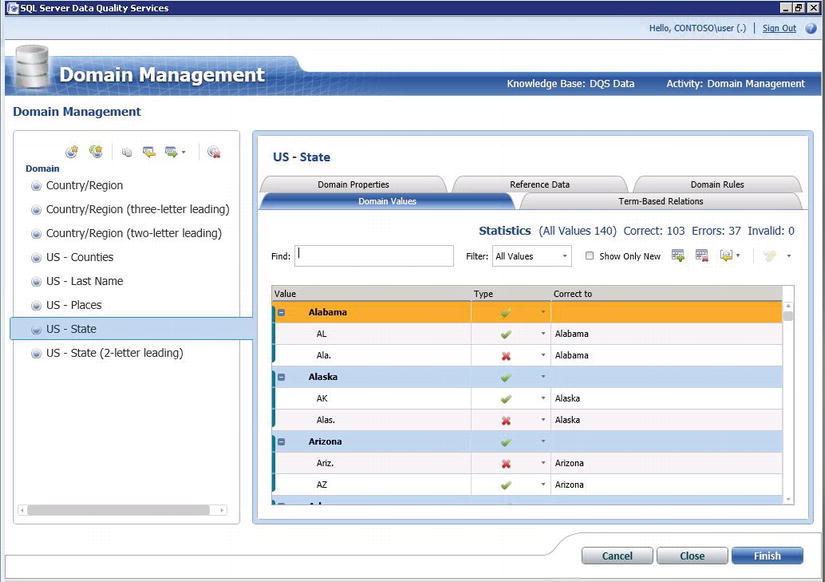
Figure 5-6. The US – State domain from the default DQS knowledge base
Online Reference Data Services
DQS has two types of data it will use to perform cleansing and matching operations; local data, and reference data. Local data make up the values shown on the Domain Values page in the DQS Client – these are known values that are imported into DQS as part of the Knowledge Discovery process. The values are stored along with the knowledge base in the DQS_MAIN database. If these values change, you must update your domain with the new values. Reference data is not stored in the knowledge base – it is queried from an Online Reference Data Service. Using online reference data may impact performance, as your cleansing process will need to call out to an external system, but it requires less maintenance as you don’t need to worry about keeping values in sync.
The Online Reference Data Services (RDS) that can be linked to your domains are configured on the Administration page in the DQS Client. There are two types of data providers: DataMarket providers, and Direct Online 3rd Party providers. DataMarket providers require that you have a DataMarket Account ID and subscription to the data set you wish to use. The Direct Online provider option allows you to point to other 3rd party web services that support the DQS provider interface.
While you can’t use SSIS for DQS Matching, you are able to take advantage of its data correction capabilities through the new DQS Cleansing transform. The DQS Cleansing transform can be found in the Data Flow Toolbox (shown in Figure 5-7). It will appear under the Other Transforms section by default.
Figure 5-7. The DQS Cleansing transform.
After dragging the DQS Cleansing transform onto the designer, you can double click the component to bring up its editor UI.
The first thing you need to set in the DQS Cleansing Transformation Editor is the Data Quality Connection Manager (as shown in Figure 5-8). This will point to a DQS installation residing on a SQL Server instance. Once the connection manager has been created, you select the Knowledge Base you want to use. Selecting the Knowledge Base you want to use will bring up its list of domains.
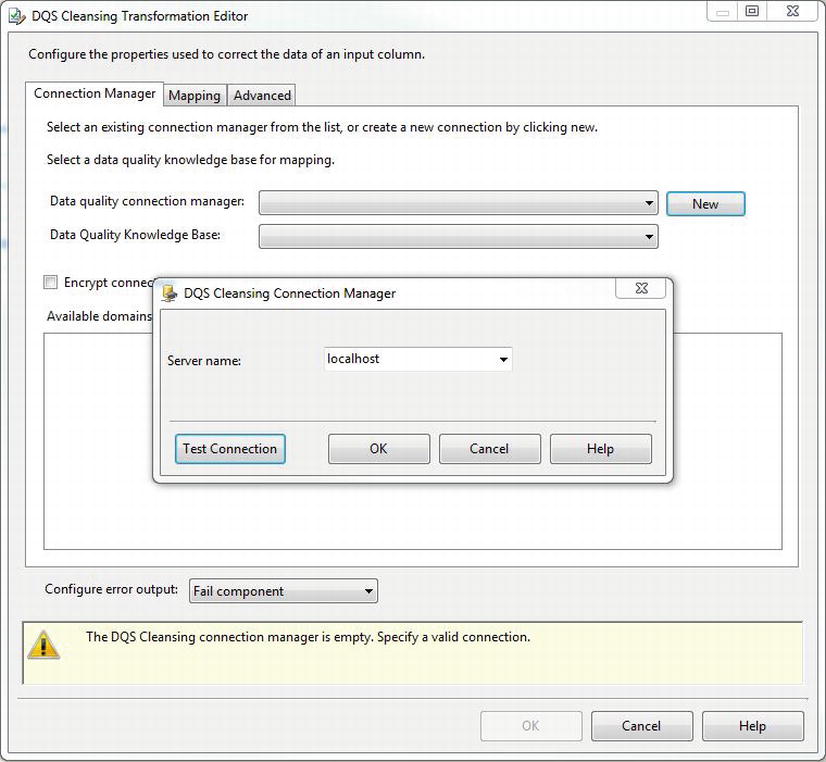
Figure 5-8. The DQS Connection Manager and Cleansing Transformation Editor
As mentioned earlier in the chapter, there are two types of domains in this list; regular Domains (ex. City, State, Zip), and Composite Domains, which are made up of two or more regular domains. When using the DQS Cleansing transform, you can map columns from your data flow to domains in the knowledge base. You can also make use of Composite Domains in two ways:
- A single (string) column – for this to work, all values must appear in the same order as the domains do. So using the “Company” example above, your column values would need to look like this: Microsoft Corporation, One Redmond Way, Redmond, WA, USA.
- Multiple columns – Individual columns are always cleansed by the knowledge and rules stored within the DQS knowledge base. If you map a column to each domain of a composite domain, the row will also be cleansed using the composite domain logic.
![]() Note There is currently no indicator in the DQS Cleansing transform UI to show when you’ve mapped columns to all domains within a composite domain. You need to double check that each domain is mapped; otherwise, each column will be validated and cleansed individually.
Note There is currently no indicator in the DQS Cleansing transform UI to show when you’ve mapped columns to all domains within a composite domain. You need to double check that each domain is mapped; otherwise, each column will be validated and cleansed individually.
The Mapping tab (Figure 5-9) allows you to select the columns you want to cleanse, and map them to domains in your knowledge base. Note that the Domain dropdown will automatically filter out columns with incompatible data types. For example, it won’t show domains with a String data type if you are using a DT_I4 (four-byte signed integer) column. A domain can only be mapped once – if you have multiple columns for the same domain, you’ll need to use two separate DQS Cleansing transforms in your data flow.
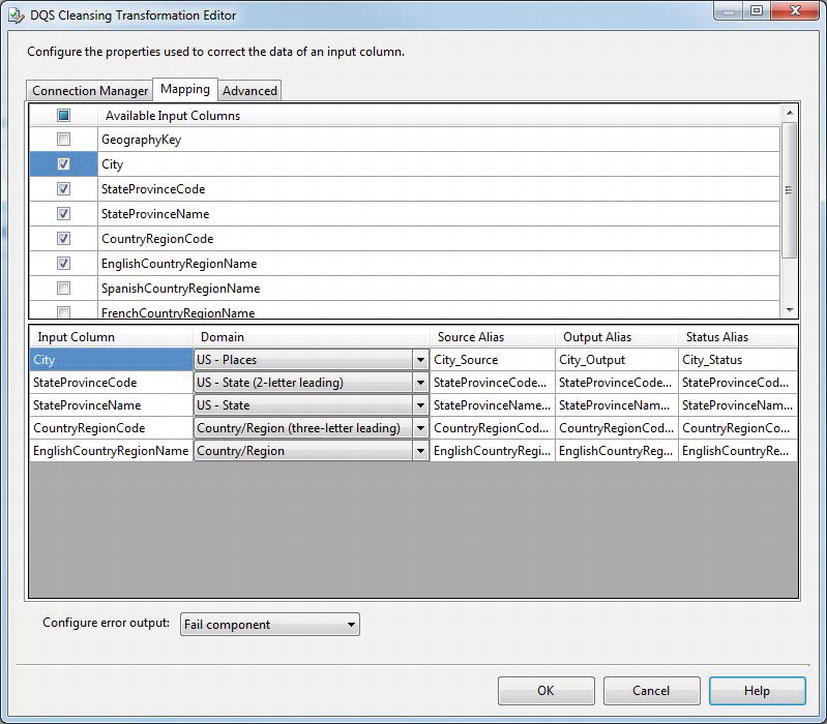
Figure 5-9. Mapping DQS knowledge base domains to columns in your data flow
![]() Note If your data contains multiple columns with values from the same domain, consider using the Linked Domain feature when creating your knowledge base. For more information, see the “Create a Linked Domain” page in books online: http://msdn.microsoft.com/en-us/library/hh479582(v=SQL.110).aspx
Note If your data contains multiple columns with values from the same domain, consider using the Linked Domain feature when creating your knowledge base. For more information, see the “Create a Linked Domain” page in books online: http://msdn.microsoft.com/en-us/library/hh479582(v=SQL.110).aspx
Each column you map causes at least three additional columns to be added to your data flow – Source, Output, and Status. More columns may be added, depending on the advanced options you select (more on that to follow). The list of columns created by the DQS Cleansing transform can be found in Table 5-2. Each additional column will be prefixed with the name of the original column by default, and can be renamed on the Mapping tab. In addition to the columns that are prefixed with the name of the original, a Record Status column is added to record the overall status of the row. Details on how to handle the columns added by the DQS Cleansing transform are covered later in this chapter.
Table 5-2. Additional Columns Created by the DQS Cleansing Transform
| Column | Default | Description | ||
|---|---|---|---|---|
| Record Status | Yes | The overall status of the record, based on the status of each mapped column. The overall status is based on the following algorithm: | ||
| If one or more columns is: | ||||
|
||||
|
||||
|
||||
| If all columns are Correct or New, then the record status will be Correct. | ||||
| If all columns are New, then the record status will be New. | ||||
| See Table 5-3 for possible Status values. | ||||
| _Source | Yes | This column contains the original value passed to the transform. | ||
| _Output | Yes | If the original value was modified during the cleansing process, this column contains the corrected value. If the value was not modified, this column contains the original value. When doing bulk cleansing through SSIS, downstream components will typically make use of this column. | ||
| _Status | Yes | The validation or cleansing status of the value. | ||
| See Table 5-3 for possible values of the Status column. | ||||
| _Confidence | No | This column contains a score that is given to any correction or suggestion. The score reflects to what extent the DQS server (or the relevant Reference Data Source) has confidence in the correction/suggestion. Most ETL packages will want to include this field, and use a conditional split to redirect values that do not meet the minimum confidence threshold so they can be manually inspected. | ||
| _Reason | No | This column explains the reason for the column’s cleansing status. For example, if a column was Corrected, the reason might be due to the DQS Cleansing algorithm, knowledge base rules, or a change due to standardization. | ||
| _Appended Data | No | This column is populated when there are domains attached to a Reference Data Provider. Certain reference data providers will return additional information as part of the cleansing– not only values associated with the mapped domains. For example, when cleansing an address, the reference data provider might also return Latitude and Longitude values. | ||
| _Appended Data Schema | No | This column is related to the Appended Data setting (above). If the RDS returned additional information in the Appended Data field, this column contains a simple schema which can be used to interpret that data. |
Table 5-3. Column Status Values
| Option | Description |
|---|---|
| Correct | The value was already correct, and needs no further modification. The Corrected column will contain the original value. |
| Invalid | The domain contained validation rules that marked this value as invalid. |
| Corrected | The value was incorrect, but DQS was able to correct it. The Corrected column will contain the modified value. |
| New | The value wasn’t in the current domain, and did not match any domain rules. DQS is unsure whether or not it is valid. The value should be redirected, and manually inspected. |
| Auto suggest | The value wasn’t an exact match, but DQS has provided a suggestion. If you include the Confidence field, you could automatically accept rows above a certain confidence level, and redirect others to a separate table for later review. |
The Advanced tab (as shown in Figure 5-10) has number of different options, most of which add new columns to the data flow when selected. The Standardize output option is an exception to this. When enabled, DQS will modify the output values according to the domain settings defined in the DQS client application. You can see how the standardization settings are defined in the DQS Client on the Domain Management | Domain Properties tab (shown earlier in Figure 5-3).
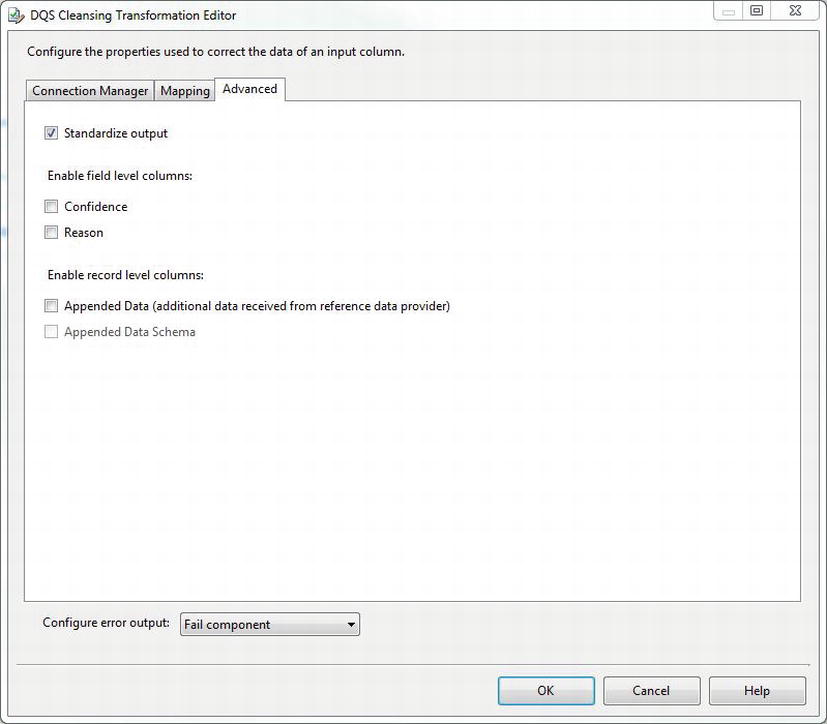
Figure 5-10. Advanced tab of the DQS Cleansing Transformation Editor
There are two kinds of standardization:
- Reformatting operations. These include operations such as conversion to uppercase, to lowercase, and to capitalized words in a string.
- Correction to a leading value. For example, if multiple values (or synonyms) are defined for a term, the current value will be replaced with the leading term (as defined in the KB).
The DQS Cleansing transformation logs Information events that indicate when it sends rows to the DQS server. There will be one event for each batch, and one event at the end, with a summary for all records. The messages contain details about how long the cleansing process took to process the batch, and the counts for each status. Listing 5-1 shows an example of what these messages look like. The transform processes data in 1000 row chunks. The chunk size is currently hardcoded – there is no way to configure the size of the batch sent to the DQS server.
![]() Note The default chunk size for data sent from the DQS Cleansing transform to the DQS server was changed from 1,000 rows to 10,000 rows in SQL Server 2012 CU1.
Note The default chunk size for data sent from the DQS Cleansing transform to the DQS server was changed from 1,000 rows to 10,000 rows in SQL Server 2012 CU1.
Listing 5-1. DQS Cleansing Transform Log Messages
[DQS Cleansing] Information: The DQS Cleansing component received 1000 records from the DQS server. The data cleansing process took 7 seconds.
[DQS Cleansing] Information: DQS Cleansing component records chunk status count - Invalid: 0, Autosuggest: 21, Corrected: 979, Unknown: 0, Correct: 0.
[DQS Cleansing] Information: DQS Cleansing component records total status count - Invalid: 0, Autosuggest: 115, Corrected: 4885, Unknown: 0, Correct: 0.
Cleansing Data in the Data Flow
The following section contains design patterns for cleansing data in the SSIS data flow using the DQS Cleansing transform. There are two key issues to keep in mind when cleansing data:
- The cleansing process is based on the rules within your knowledge base. The better the cleansing rules are, the more accurate your cleansing process will be. You may want to reprocess your data as the rules in your knowledge base improve.
- Cleansing large amounts of data can take a long time. See the Performance Considerations section below for patterns which can be used to reduce overall processing time.
Handling the Output of the DQS Cleansing Transform
The DQS Cleansing transform adds a number of new columns to the data flow (as described earlier in this chapter). The way you’ll handle the processed rows will usually depend on the status of the row, which is set in the Record Status column. A Conditional Split transformation can be used to redirect rows down the appropriate data flow path. Figure 5-11 shows what the Conditional Split transformation would look like with a separate output for each Record Status value. Table 5-3 contains a list of possible status values.
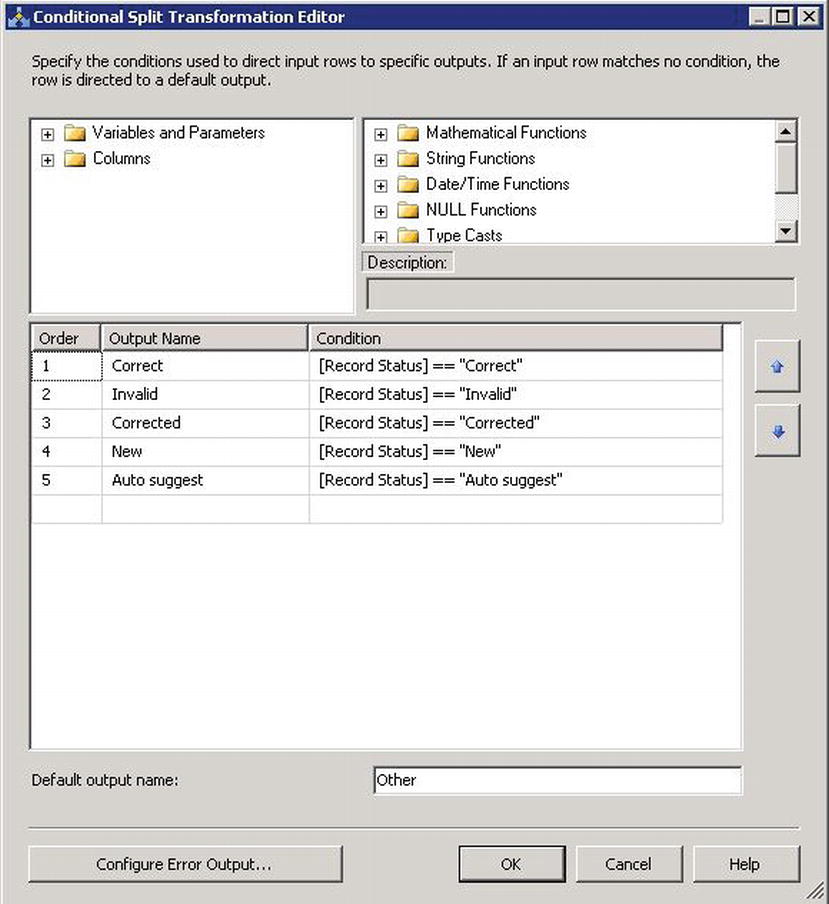
Figure 5-11. Conditional Split transformation configured to process the DQS Record Status
![]() Note The column status values are localized - they actual string will change depending on the language of your SQL Server installation. This might require you to add additional processing logic to your Conditional Split expressions if you expect your packages to run under different system locales. For more information about the status values, see the Data Cleansing (DQS) page in books online: http://msdn.microsoft.com/en-us/library/gg524800(v=SQL.110).aspx
Note The column status values are localized - they actual string will change depending on the language of your SQL Server installation. This might require you to add additional processing logic to your Conditional Split expressions if you expect your packages to run under different system locales. For more information about the status values, see the Data Cleansing (DQS) page in books online: http://msdn.microsoft.com/en-us/library/gg524800(v=SQL.110).aspx
The status values you handle and downstream data flow logic you use will depend on the goals of your data cleansing process. Typically, you will want to split your rows into two paths. Correct, Corrected, and Auto suggest rows will go down a path that will update your destination table with the cleansed data values (found in the < column_name > _Output column). New and Invalid rows will usually go into a separate table so someone can examine them later on, and either correct the data (in the case of Invalid rows), or update the Knowledge Base (in the case of New rows) so that these values can be handled automatically in the future. You may wish to include a check against the confidence level (<column_name > _Confidence) of the Auto suggest rows to make sure it meets a minimum threshold. Figure 5-12 shows an SSIS data flow with logic to process rows from the DQS Cleansing transform.
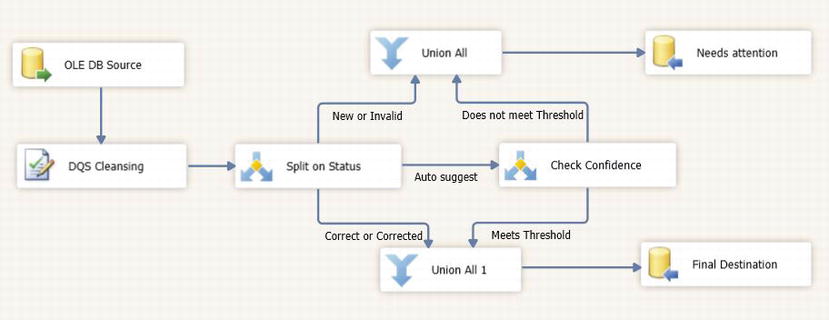
Figure 5-12. Data Flow processing logic following a DQS Cleansing transform
![]() Note Although the Confidence columns output by the DQS Cleansing transforms are numeric, they are output as DT_WSTR(100) columns (strings). To check the confidence level against a minimum threshold, you’ll need to cast the value to a DT_R4 (float) or DT_R8 (double).
Note Although the Confidence columns output by the DQS Cleansing transforms are numeric, they are output as DT_WSTR(100) columns (strings). To check the confidence level against a minimum threshold, you’ll need to cast the value to a DT_R4 (float) or DT_R8 (double).
Performance Considerations
Data cleansing can be a CPU and memory intensive operation, and may take some time to complete. Domains that rely on online reference data services may round trip incoming data to the Azure Data Marketplace, which will have a further impact on the time it takes to cleanse your data. As a result, when processing large amounts of data, you will typically want to reduce your dataset before passing it through the DQS Cleansing transform.
The DQS Cleansing transform sends incoming data to the DQS server (running within a SQL Server instance), where the actual cleansing operations are performed. While this may offload a lot of the work being done by the SSIS machine, there may be some overhead in sending the data across the network to another server. Another thing to note is that the DQS Cleansing transform is an Asynchronous component, which means it makes copies of data flow buffers at runtime. This can further impact the performance of your data flow, and is another reason for only passing through the rows that need to be cleansed.
The following sections describe some package design tips that can be used to improve overall performance when cleansing data with the DQS Cleansing transform.
The DQS Cleansing transform sends its rows to the DQS server one batch at a time. This single threaded approach isn’t ideal if you have a lot of spare CPU power on your system, so designing your packages in a way that allows DQS to send multiple batches to the server in parallel will give you a performance boost. You have two main options for parallel processing. First, you can split the incoming rows down multiple paths, and have a separate DQS Cleansing transform on each path, performing the same set of work. If your data set has a key or row that can be easily split using SSIS Expressions, you can use a Conditional Split transform. Otherwise, you can consider using a third party component like the Balanced Data Distributor. The second approach is to design your data flow in such a way that multiple instances of your package can be run in parallel. For this approach to work, you will need to partition your source query so that it pulls back a certain key range, and each instance of the package will work on a different range. This approach gives you a bit more flexibility, as you can dynamically control how many package instances you run in parallel by playing with the key ranges.
![]() Note You might find that the DQS Client performs its cleansing operations faster than the DQS Cleansing transform in SSIS. This is because the client processes multiple batches in parallel by default, while the DQS Cleansing transform processes them one at a time. To get the same performance in SSIS as you do in the DQS Client, you’ll need to add your own parallelism.
Note You might find that the DQS Client performs its cleansing operations faster than the DQS Cleansing transform in SSIS. This is because the client processes multiple batches in parallel by default, while the DQS Cleansing transform processes them one at a time. To get the same performance in SSIS as you do in the DQS Client, you’ll need to add your own parallelism.
Tracking Which Rows Have Been Cleansed
You can track which rows have already been cleansed, and when the cleansing operation was performed. This allows you to filter-out rows that have already been cleansed, so you don’t need to process them a second time. By using a date value for this marker, you can also determine which rows need to be reprocessed if your knowledge base gets updated. Remember, as your knowledge base changes and your cleansing rules improve, you will get more accurate results each time data is processed by the DQS Cleansing transform.
To track when a row has been cleansed, add a new datetime column to your destination table (DateLastCleansed). A NULL or very early date value can be used to indicate that a row has never been processed. Alternatively, you can track dates in a separate table, linked to the original row with a foreign key constraint. Your SSIS package will contain the following logic:
- Retrieve the date the DQS knowledge base was last updated using an Execute SQL Task. This value should be stored in a package variable (@[User::DQS_KB_Date]).
- Inside of a Data Flow task, retrieve the data to be cleansed with the appropriate source component. The source data should contain a DateLastCleansed column to track when the row was last processed with the DQS Cleansing transform.
- Use a Conditional Split transform to compare the DQS knowledge base date against the date the row was last processed. The expression might look like this: [DateLastCleansed] < @[User::DQS_KB_Date]. Rows matching this expression will be directed to a DQS Cleansing transformation.
- Handle the cleansed rows according to their status.
- Use a Derived Column transform to set a new DateLastCleansed value.
- Update the destination table with any corrected values and the new DateLastCleansed value.
Figure 5-13 shows the data flow for the package logic described in the steps above.
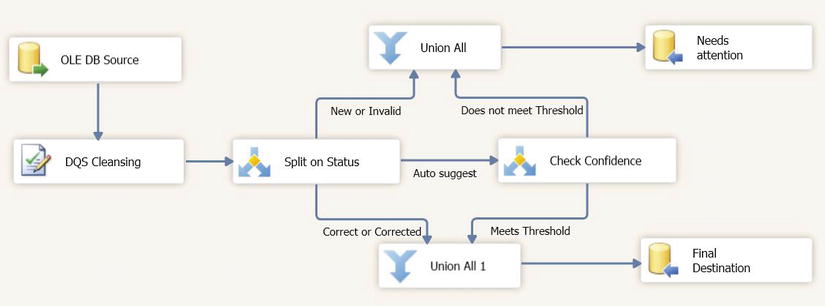
Figure 5-13. Example Data Flow when pre-filtering rows that have already been cleansed
Filtering Rows with the Lookup Transform
You can reduce the number of rows you need to cleanse by validating the data with a faster data flow component, such as the Lookup Transform. Using one or more Lookup Transforms, you can check if values exist in a reference table using quick, in-memory comparisons. Rows that match existing values can be filtered out. Rows with values that aren’t found in the reference table can then be sent to Data Quality Services for cleansing. Pre-filtering rows this way means you won’t be able to take advantage of the standardized formatting that DQS provides, and this makes it difficult to do complex validation that involves relationships between multiple fields. This approach works best when you are working with a small number of unrelated fields that don’t require any special formatting as part of the cleansing process.
To use this pattern, your data flow will use the following logic:
- Retrieve the data containing the fields to be cleansed using a source component.
- Set the component to Ignore failure when there are no matching entries.
- Add a Lookup Transform for each field you are going to cleanse. Each Lookup Transform will use a SQL query that pulls in a unique set of values for that field, and a static Boolean (bit) value. This static value will be used as a flag to determine whether the value was found. Since you are ignoring lookup failures, the flag value will be NULL if the lookup failed to find a match. Listing 5-2 shows what the query would look like for the CountryRegionCode field, coming from the DimGeography table.
Listing 5-2. Sample Lookup Query for the CountryRegionCode Field
SELECT DISTINCT CountryRegionCode, 1 as [RegionCodeFlag] FROM DimGeography - On the Columns tab, map the field to the related lookup column, and add the static flag value as a new column in your data flow (as shown in Figure 5-14).
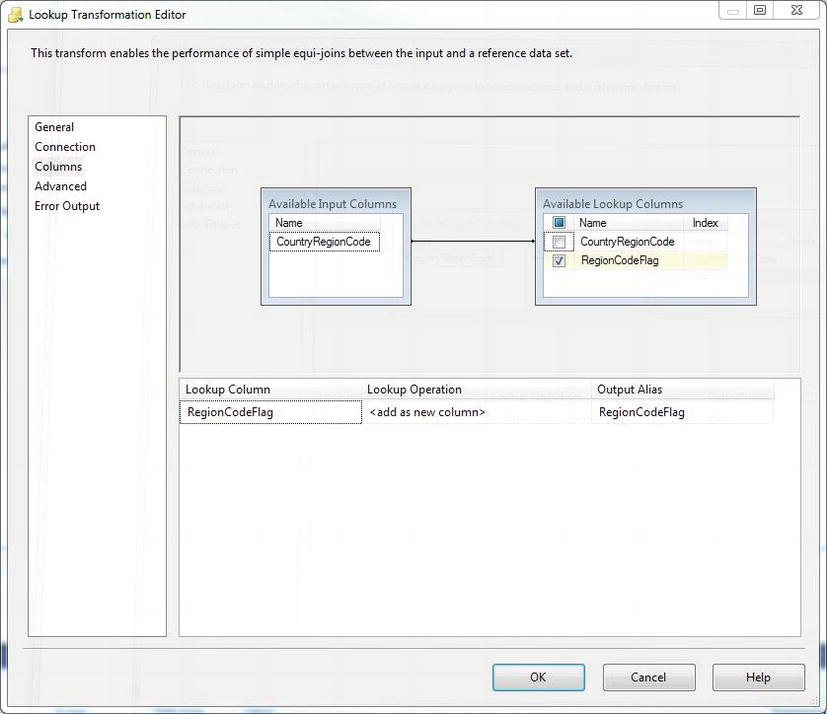
Figure 5-14. Column mapping for the Lookup Transform.
- Repeat steps 2-4 for each field you will be cleansing. The Lookup transforms should be connected using the Lookup Match Outputs.
- Add a Conditional Split transform with a single expression that checks each of the flag fields. If any of the flag fields are NULL, the row should be sent to DQS for proper cleansing. For example, the expression to check the RegionCodeFlag for a NULL value would be: ISNULL([RegionCodeFlag]).
- Connect the Conditional Split output you created to the DQS Cleansing transform. Rows going to the Conditional Split’s default output can be ignored (as their values were successfully validated using the Lookup transforms).
- Complete the rest of the data flow based on the appropriate logic for handling the output of the DQS Cleansing transform.
Figure 5-15 shows a screenshot of a data flow to cleanse a single field using the logic described above.
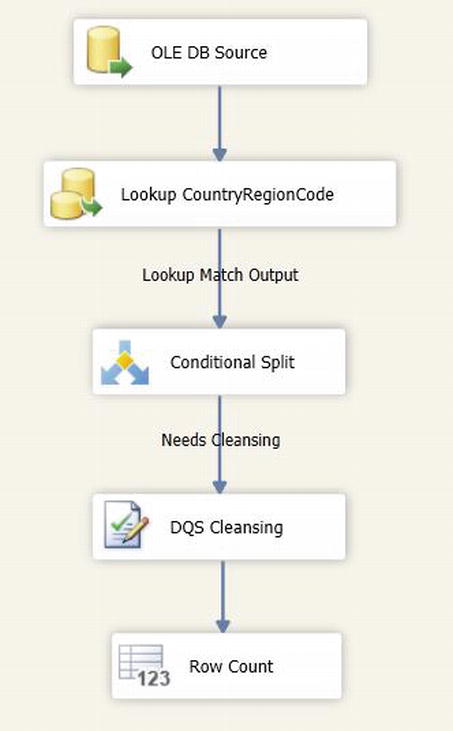
Figure 5-15. Completed Data Flow using Lookup transforms to pre-filter rows
![]() Note This approach works especially well when looking up key fields that are part of an entity in Master Data Services (MDS), another product that ships with SQL Server 2012. Using an MDS Subscription View, you can expose your dimension as a view that can be queried by a Lookup Transform. For more information about Master Data Services, see the books online entry: http://msdn.microsoft.com/en-us/library/ee633763.aspx
Note This approach works especially well when looking up key fields that are part of an entity in Master Data Services (MDS), another product that ships with SQL Server 2012. Using an MDS Subscription View, you can expose your dimension as a view that can be queried by a Lookup Transform. For more information about Master Data Services, see the books online entry: http://msdn.microsoft.com/en-us/library/ee633763.aspx
Approving and Importing Cleansing Rules
When a data flow with a DQS Cleansing transform is run, a cleansing project is created on the DQS Server. This allows the KB editor to view the corrections performed by the transform, and approve or reject rules. A new project is created automatically each time the package is run, and can be viewed using the DQS Client. When performing parallel cleansing with multiple DQS Cleansing transforms in a single data flow, a project will be created for each transform you are using.
Once correction rules have been approved by the KB editor, they can be imported into the knowledge base so they can be automatically applied the next time cleansing is performed. This process can be done with the following steps:
- Run the SSIS package containing the DQS Cleansing transform.
- Open the DQS Client, and connect to the DQS server used by the SSIS package.
- Click on the Open Data Quality Project button.
- The newly created project will be listed on the left hand pane (as shown in Figure 5-16). The project’s name will be generated using the name of the package, the name of the DQS Cleansing transform, a timestamp of when the package was executed, the unique identifier of the Data Flow Task which contained the transformation, and another unique identifier for the specific execution of the package.
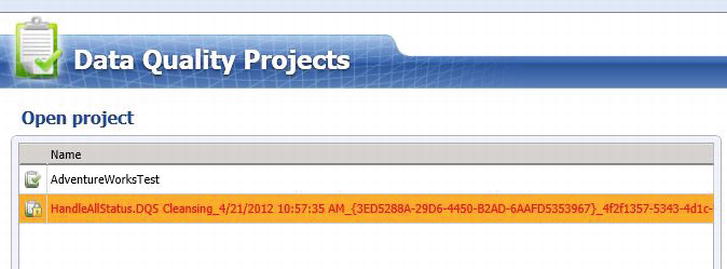
Figure 5-16. Running the DQS Cleansing transform will create a project on the DQS server
- Selecting the project name will display details in the right hand pane (shown in Figure 5-17), such as the domains that were used in this cleansing activity.
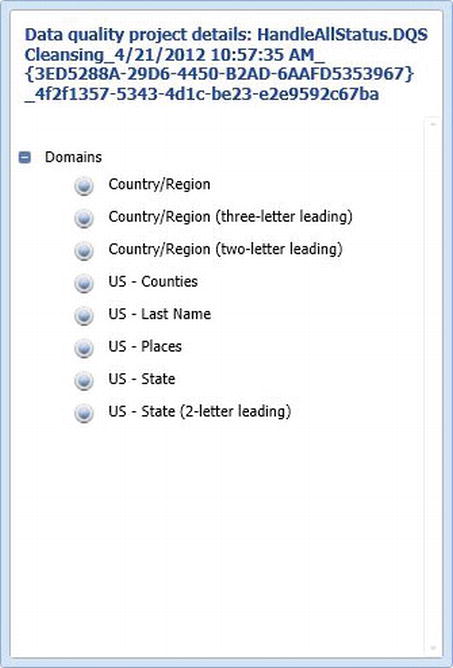
Figure 5-17. Selecting the project will display the domains used in this activity
- Click Next to open the project.
- Select the domains you would like to review the corrections for.
- Click the Approve or Reject radio buttons for each correction, or change the “Correct to” value for the entry.
- Click the Next button when you have finished with the rules.
- (Optional) Export the corrected data to SQL Server, CSV or Excel. You will be able to skip this step in most scenarios, as your SSIS package will be responsible for handling the corrected data.
- Click the Finish button to close the project.
- From the home screen, select your knowledge base, and choose the Domain Management activity.
- Select the domain you have defined new rules for.
- Click the Domain Values tab.
- Click the Import Values button, and select Import project values (as shown in Figure 5-18).
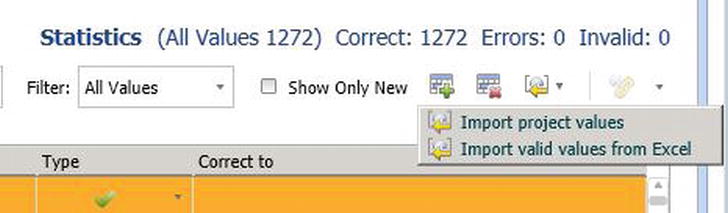
Figure 5-18. Importing domain values from an existing project
- Repeat steps 13-15 for each domain you wish to update.
- Click the Finish button to publish your knowledge base changes.
- If you have modified any of the correction rules, you may want to re-run your SSIS package to pick up the new values.
Summary
This chapter described the new DQS Cleansing transform, and how you can use it to take advantage of the advanced data cleansing functionality provided by Data Quality Services in SQL Server 2012. The design patterns detailed in this chapter will help you get the best possible performance while doing data cleansing with SSIS.