
Chapter 9
![]()
The performance of any query depends on the effectiveness of the execution plan decided upon by the optimizer, as you learned in previous chapters. Because the overall time required to execute a query is the sum of the time required to generate the execution plan plus the time required to execute the query based on this execution plan, it is important that the cost of generating the execution plan itself is low. The cost incurred when generating the execution plan depends on the process of generating the execution plan, the process of caching the plan, and the reusability of the plan from the plan cache. In this chapter, you will learn how an execution plan is generated and how to analyze the execution plan cache for plan reusability.
In this chapter, I cover the following topics:
- Execution plan generation and caching
- The SQL Server components used to generate an execution plan
- Strategies to optimize the cost of execution plan generation
- Factors affecting parallel plan generation
- How to analyze execution plan caching
- Query plan hash and query hash as mechanisms for identifying queries to tune
- Execution plans gone wrong and parameter sniffing
- Ways to improve the reusability of execution plan caching
Execution Plan Generation
As you know by now, SQL Server uses a cost-based optimization technique to determine the processing strategy of a query. The optimizer considers both the metadata of the database objects and the current distribution statistics of the columns referred to in the query when deciding which index and join strategies should be used.
The cost-based optimization allows a database developer to concentrate on implementing a business rule, rather than on the exact syntax of the query. At the same time, the process of determining the query processing strategy remains quite complex and can consume a fair amount of resources. SQL Server uses a number of techniques to optimize resource consumption:
- Syntax-based optimization of the query
- Trivial plan match to avoid in-depth query optimization for simple queries
- Index and join strategies based on current distribution statistics
- Query optimization in multiple phases to control the cost of optimization
- Execution plan caching to avoid the regeneration of query plans
The following techniques are performed in order, as shown in the flowchart in Figure 9-1.
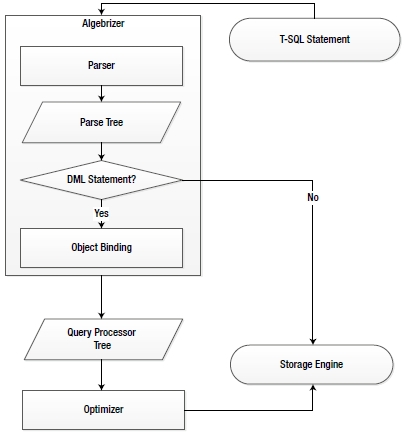
Figure 9-1. SQL Server techniques to optimize query execution
- Parsing
- Binding
- Query optimizer
- Execution plan generation, caching, and hash plan generation
- Query execution
Let’s take a look at these steps in more detail.
When a query is submitted, SQL Server passes it to the algebrizer within the relational engine. (This relational engine is one of the two main parts of SQL Server, with the other being the storage engine, which is responsible for data access, modifications, and caching.) The relational engine takes care of parsing, name and type resolution, and optimization. It also executes a query as per the query execution plan and requests data from the storage engine.
The first part of the algebrizer process is the parser. The parser checks an incoming query, validating it for the correct syntax. The query is terminated if a syntax error is detected. If multiple queries are submitted together as a batch as follows (note the error in syntax), then the parser checks the complete batch together for syntax and cancels the complete batch when it detects a syntax error. (Note that more than one syntax error may appear in a batch, but the parser goes no further than the first one.)
CREATE TABLE dbo.Test1 (c1 INT) ;
INSERT INTO dbo.Test1
VALUES (1) ;
CEILEKT * FROM dbo.t1; --Error: I meant, SELECT * FROM t1
On validating a query for correct syntax, the parser generates an internal data structure called a parse tree for the algebrizer. The parser and algebrizer taken together are called query compilation.
The parse tree generated by the parser is passed to the next part of the algebrizer for processing. The algebrizer now resolves all the names of the different objects, meaning the tables, the columns, and so on, that are being referenced in the T-SQL in a process called binding. It also identifies all the various data types being processed. It even checks for the location of aggregates (such as GROUP BY and MAX). The output of all these verifications and resolutions is a binary set of data called a query processor tree.
To see this part of the algebrizer in action, if the following batch query (--algebrizertest in the download) is submitted, then the first three statements before the error statement are executed, and the errant statement and the one after it are cancelled.
IF (SELECT OBJECT_ID('dbo.Test1')
) IS NOT NULL
DROP TABLE dbo.Test1 ;
GO
CREATE TABLE dbo.Test1 (c1 INT) ;
INSERT INTO dbo.Test1
VALUES (1) ;
SELECT 'Before Error',
c1
FROM dbo.Test1 AS t ;
SELECT 'error',
c1
FROM dbo.no_Test1 ;
--Error: Table doesn't exist
SELECT 'after error' c1
FROM dbo.Test1 AS t ;
If a query contains an implicit data conversion, then the normalization process adds an appropriate step to the query tree. The process also performs some syntax-based optimization. For example, if the following query (--syntaxoptimize in the download) is submitted, then the syntax-based optimization transforms the syntax of the query, as shown in the T-SQL at the top of Figure 9-2, where BETWEEN becomes >= and <=.

Figure 9-2. Syntax-based optimization
SELECT *
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesOrderID BETWEEN 62500 AND 62550 ;
You should also note the Warning indicator on the SELECT operator. Looking at the properties for this operator, you can see that SalesOrderID is actually getting converted as part of the process and the optimizer is warning us:
Type conversion in expression
(CONVERT(nvarchar(23),[soh].[SalesOrderID],0)) may affect
“CardinalityEstimate” in query plan choice
For most Data Definition Language (DDL) statements (such as CREATE TABLE, CREATE PROC, and so on), after passing through the algebrizer, the query is compiled directly for execution, since the optimizer need not choose among multiple processing strategies. For one DDL statement in particular, CREATE INDEX, the optimizer can determine an efficient processing strategy based on other existing indexes on the table, as explained in Chapter 4.
For this reason, you will never see any reference to CREATE TABLE in an execution plan, although you will see reference to CREATE INDEX. If the normalized query is a Data Manipulation Language (DML) statement (such as SELECT, INSERT, UPDATE, or DELETE), then the query processor tree is passed to the optimizer to decide the processing strategy for the query.
Optimization
Based on the complexity of a query, including the number of tables referred to and the indexes available, there may be several ways to execute the query contained in the query processor tree. Exhaustively comparing the cost of all the ways of executing a query can take a considerable amount of time, which may sometimes override the benefit of finding the most optimized query. Figure 9-3 shows that, to avoid a high optimization overhead compared to the actual execution cost of the query, the optimizer adopts different techniques, namely the following:
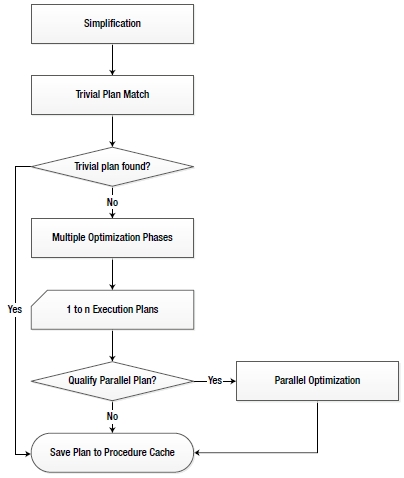
- Trivial plan match
- Multiple optimization phases
- Parallel plan optimization
Sometimes there might be only one way to execute a query. For example, a heap table with no indexes can be accessed in only one way: via a table scan. To avoid the runtime overhead of optimizing such queries, SQL Server maintains a list of patterns that define a trivial plan. If the optimizer finds a match, then a similar plan is generated for the query without any optimization. The generated plans are then stored in the procedure cache.
Multiple Optimization Phases
For a complex query, the number of alternative processing strategies to be analyzed can be very high, and it may take a long time to evaluate each option. Therefore the optimizer goes through three different levels of optimizations. These are referred to as search 0, search 1, and search 2. But it’s easier to think of them as transaction, quick plan, and full optimization. Depending on the size and complexity of the query, these different optimizations may be tried one at a time, or the optimizer might skip straight to full optimization. Each of the optimizations takes into account using different join techniques and different ways of accessing the data through scans, seeks, and other operations.
The index variations consider different indexing aspects, such as single-column index, composite index, index column order, column density, and so forth. Similarly, the join variations consider the different join techniques available in SQL Server: nested loop join, merge join, and hash join. (Chapter 3 covers these join techniques in detail.) Constraints such as unique values and foreign key constraints are also a part of the optimization decision-making process.
The optimizer considers the statistics of the columns referred to in the WHERE clause to evaluate the effectiveness of the index and the join strategies. Based on the current statistics, it evaluates the cost of the configurations in multiple optimization phases. The cost includes many factors, including (but not limited to) usage of CPU, memory, and disk I/O required to execute the query. After each optimization phase, the optimizer evaluates the cost of the processing strategy. If the cost is found to be cheap enough, then the optimizer stops further iteration through the optimization phases and quits the optimization process. Otherwise, it keeps iterating through the optimization phases to determine a cost-effective processing strategy.
Sometimes a query can be so complex that the optimizer needs to extensively iterate through the optimization phases. While optimizing the query, if it finds that the cost of the processing strategy is more than the cost threshold for parallelism, then it evaluates the cost of processing the query using multiple CPUs. Otherwise, the optimizer proceeds with the serial plan.
You can find out some detail of what occurred during the multiple optimization phases via two sources. Take, for example, this query (--nontrivialquery):
SELECT soh.SalesOrderNumber,
sod.OrderQty,
sod.LineTotal,
sod.UnitPrice,
sod.UnitPriceDiscount,
p.[Name] AS ProductName,
p.ProductNumber,
ps.[Name] AS ProductSubCategoryName,
pc.[Name] AS ProductCategoryName
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
JOIN Production.Product AS p
ON sod.ProductID = p.ProductID
JOIN Production.ProductModel AS pm
ON p.ProductModelID = pm.ProductModelID
JOIN Production.ProductSubcategory AS ps
ON p.ProductSubcategoryID = ps.ProductSubcategoryID
JOIN Production.ProductCategory AS pc
ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE soh.CustomerID = 29658 ;
When this query is run, the execution plan in Figure 9-4, a nontrivial plan for sure, is returned.
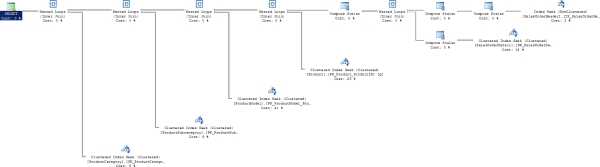
Figure 9-4. Nontrivial execution plan
I realize that this execution plan is hard to read. The important point to take away is that it involves quite a few tables, each with indexes and statistics that all had to be taken into account to arrive at this execution plan. The first place you can go to look for information about the optimizer’s work on this execution plan is the property sheet of the T-SQL SELECT operator at the far left of the execution plan. Figure 9-5 shows the property sheet.
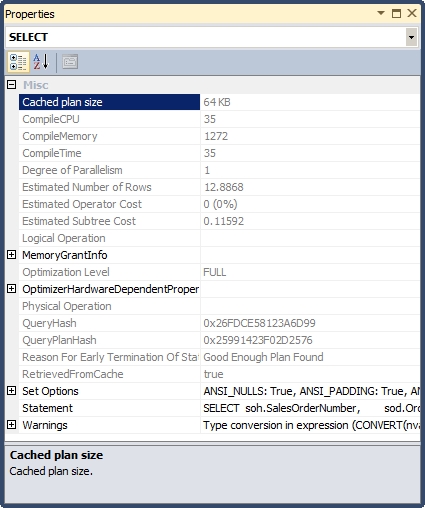
Starting at the top, you can see information directly related to the creation and optimization of this execution plan:
- The size of the cached plan, which is 64 bytes
- The number of CPU cycles used to compile the plan, which is 35 ms
- The amount of memory used, which is 1272KB
- The compile time, which is 35 ms
The Optimization Level property (StatementOptmLevel in the XML plan) shows what type of processing occurred within the optimizer. In this case, FULL means that the optimizer did a full optimization. This is further displayed in the property Reason for Early Termination of Statement, which is Good Enough Plan Found. So, the optimizer took 35 ms to track down a plan that it deemed good enough in this situation. You can also see the QueryPlanHash value, also known as the fingerprint, for the execution plan (you can find more details on this in the section “Query Plan Hash and Query Hash”). The properties of the SELECT (and the INSERT, UPDATE, and DELETE) operators are an important first stopping point when evaluating any execution plan because of this information.
The second source for optimizer information is the dynamic management view sys. Dm_exec_query_optimizer_info. This DMV is an aggregation of the optimization events over time. It won’t show the individual optimizations for a given query, but it will track the optimizations performed. This isn’t as immediately handy for tuning an individual query, but if you are working on reducing the costs of a workload over time, being able to track this information can help you determine whether your query tuning is making a positive difference, at least in terms of optimization time. Some of the data returned is for internal SQL Server use only. Figure 9-6 shows a truncated example of the useful data returned in the results from the following query.
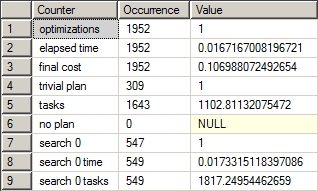
Figure 9-6. Output from sys.dm_exec_query_optimizer_info
SELECT deqoi.counter,
deqoi.occurrence,
deqoi.value
FROM sys.dm_exec_query_optimizer_info AS deqoi ;
Running this query before and after another query can show you the changes that have occurred in the number and type of optimizations completed.
The optimizer considers various factors while evaluating the cost of processing a query using a parallel plan. Some of these factors are as follows:
- Number of CPUs available to SQL Server
- SQL Server edition
- Available memory
- Cost threshold for parallelism
- Type of query being executed
- Number of rows to be processed in a given stream
- Number of active concurrent connections
If only one CPU is available to SQL Server, then the optimizer won’t consider a parallel plan. The number of CPUs available to SQL Server can be restricted using the affinity mask setting of the SQL Server configuration. The affinity mask value is a bitmap in that a bit represents a CPU, with the rightmost bit position representing CPUO. For example, to allow SQL Server to use only CPUO to CPU3 in an eight-way box, execute these statements (--affinity_mask in the download):
USE master ;
EXEC sp_configure
'show advanced option',
'1' ;
RECONFIGURE ;
EXEC sp_configure
'affinity mask',
15 ;
--Bit map: 00001111
RECONFIGURE ;
This configuration takes effect immediately. affinity mask is a special setting, and I recommend that you use it only in instances where taking control away from SQL Server makes sense, such as when you have multiple instances of SQL Server running on the same machine and you want to isolate them from each other. To set affinity past 32 processors, you have to use the affinity64 mask option that is available only in the 64-bit version of SQL Server. You can also bind I/O to a specific set of processors using the affinity mask I/O option in the same way.
Even if multiple CPUs are available to SQL Server, if an individual query is not allowed to use more than one CPU for execution, then the optimizer discards the parallel plan option. The maximum number of CPUs that can be used for a parallel query is governed by the max degree of parallelism setting of the SQL Server configuration. The default value is 0, which allows all the CPUs (availed by the affinity mask setting) to be used for a parallel query. You can also control parallelism through the Resource Governor. If you want to allow parallel queries to use no more than two CPUs out of CPUO to CPU3, limited by the preceding affinity mask setting, execute the following statements (--parallelism in the download):
USE master ;
EXEC sp_configure
'show advanced option',
'1' ;
RECONFIGURE ;
EXEC sp_configure
'max degree of parallelism',
2 ;
RECONFIGURE ;
This change takes effect immediately, without any restart. The max degree of parallelism setting can also be controlled at a query level using the MAXD0P query hint:
SELECT *
FROM dbo.t1
WHERE C1 = 1
OPTION (MAXDOP 2) ;
Changing the max degree of parallelism setting is best determined by the needs of your application and the workloads on it. I will usually leave the max degree of parallelism set to the default value unless indications arise that suggest a change is necessary. I will usually adjust the cost threshold for parallelism up from its default value of 5.
Since parallel queries require more memory, the optimizer determines the amount of memory available before choosing a parallel plan. The amount of memory required increases with the degree of parallelism. If the memory requirement of the parallel plan for a given degree of parallelism cannot be satisfied, then SQL Server decreases the degree of parallelism automatically or completely abandons the parallel plan for the query in the given workload context. You can see this part of the evaluation in the SELECT properties of Figure 9-5.
Queries with a very high CPU overhead are the best candidates for a parallel plan. Examples include joining large tables, performing substantial aggregations, and sorting large result sets, all common operations on reporting systems (less so on OLTP systems). For simple queries usually found in transaction-processing applications, the additional coordination required to initialize, synchronize, and terminate a parallel plan outweighs the potential performance benefit.
Whether a query is simple is determined by comparing the estimated execution time of the query with a cost threshold. This cost threshold is controlled by the cost threshold for parallelism setting of the SQL Server configuration. By default, this setting’s value is 5, which means that if the estimated execution time of the serial plan is more than 5 seconds, then the optimizer considers a parallel plan for the query. For example, to modify the cost threshold to 35 seconds, execute the following statements (--parallelismthreshold in the download):
USE master ;
EXEC sp_configure
'show advanced option',
'1'; ;
RECONFIGURE ;
EXEC sp_configure
'cost threshold for parallelism',
35 ;
RECONFIGURE ;
This change takes effect immediately, without any restart. If only one CPU is available to SQL Server, then this setting is ignored. I’ve found that OLTP systems suffer when the cost threshold for parallelism is set this low. Usually increasing the value to somewhere between 30 and 50 will be beneficial. Be sure to test this suggestion against your system to ensure it works well for you.
The DML action queries (INSERT, UPDATE, and DELETE) are executed serially. However, the SELECT portion of an INSERT statement and the WHERE clause of an UPDATE or a DELETE statement can be executed in parallel. The actual data changes are applied serially to the database. Also, if the optimizer determines that the estimated cost is too low, it does not introduce parallel operators.
Note that, even at execution time, SQL Server determines whether the current system workload and configuration information allow for parallel query execution. If parallel query execution is allowed, SQL Server determines the optimal number of threads and spreads the execution of the query across those threads. When a query starts a parallel execution, it uses the same number of threads until completion. SQL Server reexamines the optimal number of threads before executing the parallel query the next time.
Once the processing strategy is finalized by using either a serial plan or a parallel plan, the optimizer generates the execution plan for the query. The execution plan contains the detailed processing strategy decided by the optimizer to execute the query. This includes steps such as data retrieval, result set joins, result set ordering, and so on. A detailed explanation of how to analyze the processing steps included in an execution plan is presented in Chapter 3. The execution plan generated for the query is saved in the plan cache for future reuse.
Execution Plan Caching
The execution plan of a query generated by the optimizer is saved in a special part of SQL Server’s memory pool called the plan cache or procedure cache. (The procedure cache is part of the SQL Server buffer cache and is explained in Chapter 2.) Saving the plan in a cache allows SQL Server to avoid running through the whole query optimization process again when the same query is resubmitted. SQL Server supports different techniques such as plan cache aging and plan cache types to increase the reusability of the cached plans. It also stores two binary values called the query hash and the query plan hash.
![]() Note I discuss the techniques supported by SQL Server for improving the effectiveness of execution plan reuse later in this chapter.
Note I discuss the techniques supported by SQL Server for improving the effectiveness of execution plan reuse later in this chapter.
Components of the Execution Plan
The execution plan generated by the optimizer contains two components:
- Query plan: This represents the commands that specify all the physical operations required to execute a query.
- Execution context: This maintains the variable parts of a query within the context of a given user.
I will cover these components in more detail in the next sections.
Query Plan
The query plan is a reentrant, read-only data structure, with commands that specify all the physical operations required to execute the query. The reentrant property allows the query plan to be accessed concurrently by multiple connections. The physical operations include specifications on which tables and indexes to access, how and in what order they should be accessed, the type of join operations to be performed between multiple tables, and so forth. No user context is stored in the query plan.
Execution Context
The execution context is another data structure that maintains the variable part of the query. Although the server keeps track of the execution plans in the procedure cache, these plans are context neutral. Therefore, each user executing the query will have a separate execution context that holds data specific to their execution, such as parameter values and connection details.
Aging of the Execution Plan
The procedure cache is part of SQL Server’s buffer cache, which also holds data pages. As new execution plans are added to the procedure cache, the size of the procedure cache keeps growing, affecting the retention of useful data pages in memory. To avoid this, SQL Server dynamically controls the retention of the execution plans in the procedure cache, retaining the frequently used execution plans and discarding plans that are not used for a certain period of time.
SQL Server keeps track of the frequency of an execution plan’s reuse by associating an age field to it. When an execution plan is generated, the age field is populated with the cost of generating the plan. A complex query requiring extensive optimization will have an age field value higher than that for a simpler query.
At regular intervals, the current cost of all the execution plans in the procedure cache is examined by SQL Server’s lazy writer process (which manages most of the background processes in SQL Server). If an execution plan is not reused for a long time, then the current cost will eventually be reduced to 0. The cheaper the execution plan was to generate, the sooner its cost will be reduced to 0. Once an execution plan’s cost reaches 0, the plan becomes a candidate for removal from memory. SQL Server removes all plans with a cost of 0 from the procedure cache when memory pressure increases to such an extent that there is no longer enough free memory to serve new requests. However, if a system has enough memory and free memory pages are available to serve new requests, execution plans with a cost of 0 can remain in the procedure cache for a long time so that they can be reused later, if required.
As well as changing the costs downward, execution plans can also find their costs increased to the max cost of generating the plan every time the plan is reused (or to the current cost of the plan for ad hoc plans). For example, suppose you have two execution plans with generation costs equal to 100 and 10. Their starting cost values will therefore be 100 and 10, respectively. If both execution plans are reused immediately, their age fields will be set back to that maximum cost. With these cost values, the lazy writer will bring down the cost of the second plan to 0 much earlier than that of the first one, unless the second plan is reused more often. Therefore, even if a costly plan is reused less frequently than a cheaper plan, because of the effect of the initial cost, the costly plan can remain at a nonzero cost value for a longer period of time.
Analyzing the Execution Plan Cache
You can obtain a lot of information about the execution plans in the procedure cache by accessing various dynamic management objects. The initial DMO for working with execution plans is sys.dm_exec_cached_plans:
SELECT *
FROM sys.dm_exec_cached_plans ;
Table 9-1 shows some of the useful information provided by sys.dmexeccachedplans (this is easier to read in Grid view).
Table 9-1. sys.dm_exec_cached_plans
|
Column Name |
Description |
|
refcounts |
Represents the number of other objects in the cache referencing this plan |
|
usecounts |
The number of times this object has been used since it was added to the cache |
|
size_in_bytes |
The size of the plan stored in the cache |
|
cacheobjtype |
What type of plan this is; there are several, but of particular interest are these: |
|
Compiled plan: A completed execution plan |
|
|
Compiled plan stub: A marker used for ad hoc queries (you can find more details in the “Ad Hoc Workload” section of this chapter) Parse tree: A plan stored for accessing a view |
|
|
Objtype |
The type of object that generated the plan. Again, there are several, but these are of particular interest: |
|
Proc Prepared Ad hoc View |
|
|
Plan_handle |
The identifier for this plan in memory; it is used to retrieve query text and execution plans. |
Using the DMV sys.dm_exec_cached_plans all by itself gets you only a very small part of the information. DMOs are best used in combination with other DMOs and other system views. For example, using the dynamic management function sys.dm_exec_query_plan(plan_handle) in combination with sys.dm_exec_cached_plans will also bring back the XML execution plan itself so that you can display it and work with it. If you then bring in sys.dm_exec_sql_text(plan_handle), you can also retrieve the original query text. This may not seem useful while you’re running known queries for the examples here, but when you go to your production system and begin to pull in execution plans from the cache, it might be handy to have the original query. To get aggregate performance metrics about the cached plan, you can use sys.dm_exec_query_stats to return that data. Among other pieces of data, the query hash and query plan hash are stored in this DMF. Finally, to see execution plans for queries that are currently executing, you can use sys.dm_exec_requests.
In the following sections, I’ll explore how the plan cache works with actual queries of these DMOs.
Execution Plan Reuse
When a query is submitted, SQL Server checks the procedure cache for a matching execution plan. If one is not found, then SQL Server performs the query compilation and optimization to generate a new execution plan. However, if the plan exists in the procedure cache, it is reused with the private execution context. This saves the CPU cycles that otherwise would have been spent on the plan generation.
Queries are submitted to SQL Server with filter criteria to limit the size of the result set. The same queries are often resubmitted with different values for the filter criteria. For example, consider the following query:
SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID = 29690
AND sod.ProductID = 711 ;
When this query is submitted, the optimizer creates an execution plan and saves it in the procedure cache to reuse in the future. If this query is resubmitted with a different filter criterion value—for example, soh.CustomerlD = 29500—it will be beneficial to reuse the existing execution plan for the previously supplied filter criterion value. But whether the execution plan created for one filter criterion value can be reused for another filter criterion value depends on how the query is submitted to SQL Server.
The queries (or workload) submitted to SQL Server can be broadly classified under two categories that determine whether the execution plan will be reusable as the value of the variable parts of the query changes:
- Ad hoc
- Prepared
![]() Tip To test the output of sys.dm_exec_cached_plans for this chapter, it will be necessary to remove the plans from cache on occasion by executing DBCC FREEPROCCACHE. Do not run this on your production server since flushing the cache will require all execution plans to be rebuilt as they are executed, placing a serious strain on your production system for no good reason. You can use DBCC FREEPROCCACHE(plan_handle) to target specific plans. Retrieve the plan_handle using the DMOs we’ve already talked about.
Tip To test the output of sys.dm_exec_cached_plans for this chapter, it will be necessary to remove the plans from cache on occasion by executing DBCC FREEPROCCACHE. Do not run this on your production server since flushing the cache will require all execution plans to be rebuilt as they are executed, placing a serious strain on your production system for no good reason. You can use DBCC FREEPROCCACHE(plan_handle) to target specific plans. Retrieve the plan_handle using the DMOs we’ve already talked about.
Queries can be submitted to SQL Server without explicitly isolating the variables from the query. These types of queries executed without explicitly converting the variable parts of the query into parameters are referred to as ad hoc workloads (or queries). For example, consider this query (adhoc.sql in the download):
SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderlD = sod.SalesOrderlD
WHERE soh.CustomerlD = 29690
AND sod.productid = 711
If the query is submitted as is, without explicitly converting either of the hard-coded values to a parameter (that can be supplied to the query when executed), then the query is an ad hoc query.
In this query, the filter criterion value is embedded in the query itself and is not explicitly parameterized to isolate it from the query. This means that you cannot reuse the execution plan for this query unless you use the same values and all the spacing and carriage returns are identical. However, the places where values are used in the queries can be explicitly parameterized in three different ways that are jointly categorized as a prepared workload.
Prepared workloads (or queries) explicitly parameterize the variable parts of the query so that the query plan isn’t tied to the value of the variable parts. In SQL Server, queries can be submitted as prepared workloads using the following three methods:
- Stored procedures: Allows saving a collection of SQL statements that can accept and return user-supplied parameters
- Sp_executesql: Allows executing a SQL statement or a SQL batch that may contain user-supplied parameters, without saving the SQL statement or batch
- Prepare/execute model: Allows a SQL client to request the generation of a query plan that can be reused during subsequent executions of the query with different parameter values, without saving the SQL statement(s) in SQL Server
For example, the SELECT statement shown previously can be explicitly parameterized using a stored procedure as follows (--spBasicSalesInfo in the download):
IF (SELECT OBJECT_ID('spBasicSalesInfo')
) IS NOT NULL
DROP PROC dbo.spBasicSalesInfo ;
GO
CREATE PROC dbo.spBasicSalesInfo
@ProductID INT,
@CustomerID INT
AS
SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID = @CustomerID
AND sod.ProductID = @ProductID ;
The plan of the SELECT statement included within the stored procedure will embed the parameters
(@ProductID and @Customerld), not variable values. I will cover these methods in more detail shortly.
Plan Reusability of an Ad Hoc Workload
When a query is submitted as an ad hoc workload, SQL Server generates an execution plan and stores that plan in the cache, where it can be reused if exactly the same ad hoc query is resubmitted. Since there are no parameters, the hard-coded values are stored as part of the plan. In order for a plan to be reused from the cache, the T-SQL must match exactly. This includes all spaces and carriage returns plus any values supplied with the plan. If any of these change, the plan cannot be reused.
To understand this, consider the ad hoc query we've used before (-adhoc in the download):
SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID = 29690
AND sod.ProductID = 711 ;
The execution plan generated for this ad hoc query is based on the exact text of the query, which includes comments, case, trailing spaces, and hard returns. You’ll have to use the exact text to pull the information out of sys.dm_exec_cached_plans:
SELECT c.usecounts
,c.cacheobjtype
,c.objtype
FROM sys.dm_exec_cached_plans c
CROSS APPLY sys.dm_exec_sql_text(c.plan_handle) t
WHERE t.text = 'SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID = 29690
AND sod.ProductID = 711 ;' ;
Figure 9-7 shows the output of sys.dm_exec_cached_plans.
![]()
Figure 9-7. sys.dm_exec_cached_plans output
You can see from Figure 9-7 that a compiled plan is generated and saved in the procedure cache for the preceding ad hoc query. To find the specific query, I used the query itself in the WHERE clause. You can see that this plan has been used once up until now (usecounts = 1). If this ad hoc query is reexecuted, SQL Server reuses the existing executable plan from the procedure cache, as shown in Figure 9-8.
![]()
Figure 9-8. Reusing the executable plan from the procedure cache
In Figure 9-8, you can see that the usecounts for the preceding query’s executable plan has increased to 2, confirming that the existing plan for this query has been reused. If this query is executed repeatedly, the existing plan will be reused every time.
Since the plan generated for the preceding query includes the filter criterion value, the reusability of the plan is limited to the use of the same filter criterion value. Reexecute adhocl.sql, but change son.CustomerlD to 29500:
SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID = 29500
AND sod.ProductID = 711 ;
The existing plan can’t be reused, and if the sys.dmexeccachedplans is rerun as is, you’ll see that the execution count hasn’t increased (Figure 9-9).
![]()
Figure 9-9. sys.dm_exec_cached_plans shows that the existing plan is not reused.
Instead, I’ll adjust the query against sys.dm_exec_cached_plans:
SELECT c.usecounts,
c.cacheobjtype,
c.objtype,
t.text,
c.plan_handle
FROM sys.dm_exec_cached_plans c
CROSS APPLY sys.dm_exec_sql_text(c.plan_handle) t
WHERE t.text LIKE 'SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID%' ;
You can see the output from this query in Figure 9-10.

Figure 9-10. sys.dm_exec_cached_plans showing that the existing plan can’t be reused
From the sys.dm_exec_cached_plans output in Figure 9-8, you can see that the previous plan for the query hasn’t been reused; the corresponding usecounts value remained at the old value of 2. Instead of reusing the existing plan, a new plan is generated for the query and is saved in the procedure cache with a new plan_handle. If this ad hoc query is reexecuted repeatedly with different filter criterion values, a new execution plan will be generated every time. The inefficient reuse of the execution plan for this ad hoc query increases the load on the CPU by consuming additional CPU cycles to regenerate the plan.
To summarize, ad hoc plan caching uses statement-level caching and is limited to an exact textual match. If an ad hoc query is not complex, SQL Server can implicitly parameterize the query to increase plan reusability by using a feature called simple parameterization. The definition of a simple query for simple parameterization is limited to fairly simple cases such as ad hoc queries with only one table. As shown in the previous example, most queries requiring a join operation cannot be autoparameterized.
Optimize for an Ad Hoc Workload
If your server is going to primarily support ad hoc queries, it is possible to achieve a degree of performance improvement. One server option is called optimize for ad hoc workloads. Enabling this for the server changes the way the engine deals with ad hoc queries. Instead of saving a full compiled plan for the query the first time it’s called, a compiled plan stub is stored. The stub does not have a full execution plan associated, saving the storage space required for it and the time saving it to the cache. This option can be enabled without rebooting the server:
sp_configure
'optimize for ad hoc workloads',
1 ;
GO
RECONFIGURE ;
After changing the option, flush the cache, and then rerun the query --adhoc. Modify the query against sys.dm_exec_cached_plans so that you include the size_in_bytes column, and then run it to see the results in Figure 9-11.
![]()
Figure 9-11. sys.dm_exec_cached_plans showing a compiled plan stub
Figure 9-11 shows in the cacheobjtype column that the new object in the cache is a compiled plan stub. Stubs can be created for lots more queries with less impact on the server than full compiled plans. But the next time an ad hoc query is executed, a fully compiled plan is created. To see this in action, run the query --adhoc, and check the results in sys.dm_exec_cachedplans, as shown in Figure 9-12.
![]()
Figure 9-12. The compiled plan stub has become a compiled plan.
Check the cacheobjtype value. It has changed from Compiled Plan Stub to Compiled Plan. Finally, to see the real difference between a stub and a full plan, check the sizeinbytes column in Figure 9-11 and Figure 9-12. The size changed from 272 in the stub to 57344 in the full plan. This shows precisely the savings available when working with lots of ad hoc queries. Before proceeding, be sure to disable optimize for ad hoc workloads:
sp_configure
'optimize for ad hoc workloads',
0 ;
GO
RECONFIGURE ;
Simple Parameterization
When an ad hoc query is submitted, SQL Server analyzes the query to determine which parts of the incoming text might be parameters. It looks at the variable parts of the ad hoc query to determine whether it will be safe to parameterize them automatically and use the parameters (instead of the variable parts) in the query so that the query plan can be independent of the variable values. This feature of automatically converting the variable part of a query into a parameter, even though not parameterized explicitly (using a prepared workload technique), is called simple parameterization.
During simple parameterization, SQL Server ensures that if the ad hoc query is converted to a parameterized template, the changes in the parameter values won’t widely change the plan requirement. On determining the simple parameterization to be safe, SQL Server creates a parameterized template for the ad hoc query and saves the parameterized plan in the procedure cache.
The parameterized plan is not based on the dynamic values used in the query. Since the plan is generated for a parameterized template, it can be reused when the ad hoc query is reexecuted with different values for the variable parts.
To understand the simple parameterization feature of SQL Server, consider the following query (--simple_parameterization in the download):
SELECT a.*
FROM Person.Address AS a
WHERE a.AddressID = 42 ;
When this ad hoc query is submitted, SQL Server can treat this query as it is for plan creation. However, before the query is executed, SQL Server tries to determine whether it can be safely parameterized. On determining that the variable part of the query can be parameterized without affecting the basic structure of the query, SQL Server parameterizes the query and generates a plan for the parameterized query. You can observe this from the sys.dm_exec_ cached_plans output shown in Figure 9-13.

Figure 9-13. sys.dm_exec_cached_plans output showing an autoparameterized plan
The usecounts of the executable plan for the parameterized query appropriately represents the number of reuses as 1. Also, note that the objtype for the autoparameterized executable plan is no longer Adhoc; it reflects the fact that the plan is for a parameterized query, Prepared.
The original ad hoc query, even though not executed, gets compiled to create the query tree required for the simple parameterization of the query. The compiled plan for the ad hoc query will be saved in the plan cache. But before creating the executable plan for the ad hoc query, SQL Server figured out that it was safe to autoparameterize and thus autoparameterized the query for further processing. This is visible as the highlighted line in Figure 9-13.
Since this ad hoc query has been autoparameterized, SQL Server will reuse the existing execution plan if you reexecute simpleparameterization.sql with a different value for the variable part:
SELECT a.*
FROM Person.Address AS a
WHERE a.[AddressID] = 52 --previous value was 42
Figure 9-14 shows the output of sys.dm_exec_cached_plans.

Figure 9-14. sys.dm_exec_cached_plans output showing reuse of the autoparameterized plan
From Figure 9-14, you can see that although a new plan has been generated for this ad hoc query, the ad hoc one using an Addressld value of 52, the existing prepared plan is reused as indicated by the increase in the corresponding usecounts value to 2. The ad hoc query can be reexecuted repeatedly with different filter criterion values, reusing the existing execution plan—all this despite the fact that the original text of the two queries does not match. The parameterized query for both would be the same, so it was reused.
There is one more aspect to note in the parameterized query for which the execution plan is cached. In Figure 9-10, observe that the body of the parameterized query doesn’t exactly match with that of the ad hoc query submitted. For instance, in the ad hoc query, the words from and where are in lowercase, and the AddressID column is enclosed in square brackets.
On realizing that the ad hoc query can be safely autoparameterized, SQL Server picks a template that can be used instead of the exact text of the query.
To understand the significance of this, consider the following query:
SELECT a.*
FROM Person.Address AS a
WHERE a.AddressID BETWEEN 40 AND 60 ;
Figure 9-15 shows the output of sys.dm_exec_cached_plans.

Figure 9-15. sys.dm_exec_cached_plans output showing plan simple parameterization using a template
From Figure 9-15, you can see that SQL Server put the query through the simplification process and substituted a pair of >= and <= operators, which are equivalent to the BETWEEN operator. Then the parameterization step modified the query again. That means instead of resubmitting the preceding ad hoc query using the BETWEEN clause, if a similar query using a pair of >= and <= is submitted, SQL Server will be able to reuse the existing execution plan. To confirm this behavior, let’s modify the ad hoc query as follows:
SELECT a.*
FROM Person.Address AS a
WHERE a.AddressID >= 40
AND a.AddressID <= 60 ;
Figure 9-16 shows the output of sys.dm_exec_cached_plans.

Figure 9-16. sys.dm_exec_cached_plans output showing reuse of the autoparameterized plan
From Figure 9-16, you can see that the existing plan is reused, even though the query is syntactically different from the query executed earlier. The autoparameterized plan generated by SQL Server allows the existing plan to be reused not only when the query is resubmitted with different variable values but also for queries with the same template form.
Simple Parameterization Limits
SQL Server is highly conservative during simple parameterization, because the cost of a bad plan can far outweigh the cost of generating a new plan. The conservative approach prevents SQL Server from creating an unsafe autoparameterized plan. Thus, simple parameterization is limited to fairly simple cases, such as ad hoc queries with only one table. An ad hoc query with a join operation between two (or more) tables (as shown in the early part of the “Plan Reusability of an Ad Hoc Workload” section) is not considered safe for simple parameterization.
In a scalable system, do not rely on simple parameterization for plan reusability. The simple parameterization feature of SQL Server makes an educated guess as to which variables and constants can be parameterized. Instead of relying on SQL Server for simple parameterization, you should actually specify it programmatically while building your application.
If the system you’re working on consists of primarily ad hoc queries, you may want to attempt to increase the number of queries that accept parameterization. You can modify a database to attempt to force, within certain restrictions, all queries to be parameterized just like in simple parameterization.
To do this, you have to change the database option PARAMETERIZATION to FORCED using ALTER DATABASE like this:
ALTER DATABASE AdventureWorks2008R2 SET PARAMETERIZATION FORCED ;
(--forcedparameterization in the download):
SELECT ea.EmailAddress,
e.BirthDate,
a.City
FROM Person.Person AS p
JOIN HumanResources.Employee AS e
ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress AS bea
ON e.BusinessEntityID = bea.BusinessEntityID
JOIN Person.Address AS a
ON bea.AddressID = a.AddressID
JOIN Person.StateProvince AS sp
ON a.StateProvinceID = sp.StateProvinceID
JOIN Person.EmailAddress AS ea
ON p.BusinessEntityID = ea.BusinessEntityID
WHERE ea.EmailAddress LIKE 'david%'
AND sp.StateProvinceCode = 'WA' ;
When you run this query, simple parameterization is not applied, as you can see in Figure 9-17.
![]()
Figure 9-17. A more complicated query doesn’t get parameterized.
No prepared plans are visible in the output from sys.dmexeccachedplans. But if you use the previous script to set PARAMETERIZATION to FORCED, clear the cache, and rerun the query, the output from sys.dmexeccachedplans changes so that the output looks different, as shown in Figure 9-18.

Figure 9-18. Forced parameterization changes the plan.
Now a prepared plan is visible in the third row. However, only a single parameter was supplied, @0 varchar(8000). If you get the full text of the prepared plan out of sys.dm_exec_ querytext and format it, it looks like this:
(@0 varchar(8000))
SELECT ea.EmailAddress,
e.BirthDate,
a.City
FROM Person.Person AS p
JOIN HumanResources.Employee AS e
ON p.BusinessEntityID = e.BusinessEntityID
JOIN Person.BusinessEntityAddress AS bea
ON e.BusinessEntityID = bea.BusinessEntityID
JOIN Person.Address AS a
ON bea.AddressID = a.AddressID
JOIN Person.StateProvince AS sp
ON a.StateProvinceID = sp.StateProvinceID
JOIN Person.EmailAddress AS ea
ON p.BusinessEntityID = ea.BusinessEntityID
WHERE ea.EmailAddress LIKE 'david%'
AND sp.StateProvinceCode = @0
Because of its restrictions, forced parameterization was unable to substitute anything for the string 'david%', but it was able to for the string 'WA'. Worth noting is that the variable was declared as a full 8,000-length VARCHAR instead of the three-character NCHAR like the actual column in the Person.StateProvince table. Although you have a parameter, it might lead to implicit data conversions that could prevent the use of an index.
Before you start using forced parameterization, the following list of restrictions may give you information to help you decide whether forced parameterization will work in your database. (This is a partial list; for the complete list, please consult “Books Online.”)
- INSERT … EXECUTE queries
- Statements inside procedures, triggers, and user-defined functions since they already have execution plans
- Client-side prepared statements (you’ll find more detail on these later in this chapter)
- Queries with the query hint RECOMPILE
- Pattern and escape clause arguments used in a LIKE statement (as shown earlier)
This gives you an idea of the types of restrictions placed on forced parameterization. Forced parameterization is really going to be potentially helpful only if you are suffering from large amounts of compiles and recompiles because of ad hoc queries. Any other load won’t benefit from the use of forced parameterization.
Before continuing, change the database back to SIMPLE PARAMETERIZATION:
ALTER DATABASE AdventureWorks2008R2 SET PARAMETERIZATION SIMPLE;
Plan Reusability of a Prepared Workload
Defining queries as a prepared workload allows the variable parts of the queries to be explicitly parameterized. This enables SQL Server to generate a query plan that is not tied to the variable parts of the query, and it keeps the variable parts separate in an execution context. As you saw in the previous section, SQL Server supports three techniques to submit a prepared workload:
- Stored procedures
- sp_executesql
- Prepare/execute model
In the sections that follow, I cover each of these techniques in more depth and point out where it’s possible for parameterized execution plans to cause problems.
Stored Procedures
Using stored procedures is a standard technique for improving the effectiveness of plan caching. When the stored procedure is compiled, a combined plan is generated for all the SQL statements within the stored procedure. The execution plan generated for the stored procedure can be reused whenever the stored procedure is reexecuted with different parameter values.
In addition to checking sys.dm_exec_cached_plans, you can track the execution plan caching for stored procedures using the Extended Events tool. Extended Events provides the events listed in Table 9-2 to track the plan caching for stored procedures.
Table 9-2. Events to Analyze Plan Caching for the Stored Procedures Event Class
|
Event |
Description |
|
sp_cache_hit |
Plan is found in the cache. |
|
sp_cache_miss |
Plan is not found in the cache. |
To track the stored procedure plan caching using Profiler, you can use these events along with the other stored procedure events and data columns shown in Table 9-3.
Table 9-3. Data Columns to Analyze Plan Caching for Stored Procedures Event Class
|
Event |
Data Column |
|
SP:CacheHit |
EventClass |
|
SP:CacheMiss |
TextData |
|
SP:Completed |
LoginName |
|
SP:ExecContextHit |
SPID |
|
SP:Starting |
StartTime |
|
SP:StmtCompleted |
To understand how stored procedures can improve plan caching, reexamine the procedure created earlier called spBasicSalesInfo. The procedure (spBasicSalesInfo.sql) is repeated here for clarity:
IF (SELECT OBJECT_ID('spBasicSalesInfo')
) IS NOT NULL
DROP PROC dbo.spBasicSalesInfo ;
GO
CREATE PROC dbo.spBasicSalesInfo
@ProductID INT,
@CustomerID INT
AS
SELECT soh.SalesOrderNumber,
soh.OrderDate,
sod.OrderQty,
sod.LineTotal
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.CustomerID = @CustomerID
AND sod.ProductID = @ProductID ;
To retrieve a result set for soh.Customerld = 29690 and sod.ProductId=711, you can execute the stored procedure like this:
EXEC dbo.spBasicSalesInfo
@CustomerID = 29690,
@ProductID = 711 ;
Figure 9-19 shows the output of sys.dm_exec_cached_plans.
![]()
Figure 9-19. sys.dm_exec_cached_plans output showing stored procedure plan caching
From Figure 9-19, you can see that a compiled plan of type Proc is generated and cached for the stored procedure. The usecounts value of the executable plan is 1 since the stored procedure is executed only once.
Figure 9-20 shows the Extended Events output for this stored procedure execution.
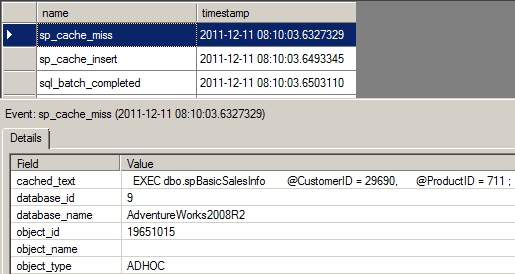
Figure 9-20. Extended Events output showing that the stored procedure plan isn’t easily found in the cache
From the Extended Events output, you can see that the plan for the stored procedure is not found in the cache. When the stored procedure is executed the first time, SQL Server looks in the procedure cache and fails to find any cache entry for the procedure sp_BasicSalesInfo, causing an sp_cache_miss event. On not finding a cached plan, SQL Server makes arrangements to compile the stored procedure. Subsequently, SQL Server generates and saves the plan and proceeds with the execution of the stored procedure. You can see this in the sp_cache_insert event. Figure 9-21 shows the details:
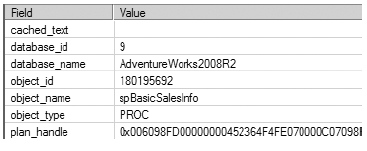
Figure 9-21. Details of the sp_cache_hit extended event
If this stored procedure is reexecuted to retrieve a result set for @Productld = 777, then the existing plan is reused, as shown in the sys.dmexeccachedplans output in Figure 9-22.
![]()
Figure 9-22. sys.dm_exec_cached_plans output showing reuse of the stored procedure plan
EXEC dbo.spBasicSalesInfo
@CustomerID = 29690,
@ProductID = 777 ;
You can also confirm the reuse of the execution plan from the Extended Events output, as shown in Figure 9-23.
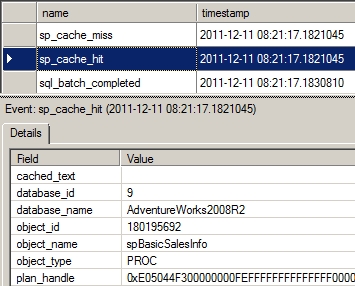
Figure 9-23. Profiler trace output showing reuse of the stored procedure plan
From the Extended Events output, you can see that the existing plan is found in the procedure cache. On searching the cache, SQL Server finds the executable plan for the stored procedure spBasicSalesInfo causing an sp_cache_hit event. Once the existing execution plan is found, SQL reuses the plan to execute the stored procedure. One interesting note: The sp_cache_miss event just prior is for the SQL batch calling the procedure. Because of the change to the parameter value, that statement was not found in the cache, but the procedure’s execution plan was. This apparently “extra” cache miss event can cause confusion.
A few other aspects of stored procedures are worth considering:
- Stored procedures are compiled on first execution.
- Stored procedures have other performance benefits, such as reducing network traffic.
- Stored procedures have additional benefits, such as the isolation of the data.
Stored Procedures Are Compiled on First Execution
The execution plan of a stored procedure is generated when it is executed the first time. When the stored procedure is created, it is only parsed and saved in the database. No normalization and optimization processes are performed during the stored procedure creation. This allows a stored procedure to be created before creating all the objects accessed by the stored procedure. For example, you can create the following stored procedure, even when table NotHere referred to in the stored procedure does not exist:
IF(SELECT OBJECT_ID('dbo.MyNewProc')) IS NOT NULL
DROP PROCEDURE dbo.MyNewProc
GO
CREATE PROCEDURE dbo.MyNewProc
AS
SELECT MyID
FROM dbo.NotHere ; --Table no_tl doesn't exist
The stored procedure will be created successfully, since the normalization process to bind the referred object to the query tree (generated by the command parser during the stored procedure execution) is not performed during the stored procedure creation. The stored procedure will report the error when it is first executed (if table NotHere is not created by then), since the stored procedure is compiled the first time it is executed.
Other Performance Benefits of Stored Procedures
Besides improving the performance through execution plan reusability, stored procedures provide the following performance benefits:
- Business logic is close to the data: The parts of the business logic that perform extensive operations on data stored in the database should be put in stored procedures, since SQL Server’s engine is extremely powerful for relational and set theory operations.
- Network traffic is reduced: The database application, across the network, sends just the name of the stored procedure and the parameter values. Only the processed result set is returned to the application. The intermediate data doesn’t need to be passed back and forth between the application and the database.
Additional Benefits of Stored Procedures
Some of the other benefits provided by stored procedures are as follows:
- The application is isolated from data structure changes: If all critical data access is made through stored procedures, then when the database schema changes, the stored procedures can be re-created without affecting the application code that accesses the data through the stored procedures. In fact, the application accessing the database need not even be stopped.
- There is a single point of administration: All the business logic implemented in stored procedures is maintained as part of the database and can be managed centrally on the database itself. Of course, this benefit is highly relative, depending on whom you ask. To get a different opinion, ask a non-DBA!
- Securitycan be increased: User privileges on database tables can be restricted and can be allowed only through the standard business logic implemented in the stored procedure. For example, if you want user UserOne to be restricted from physically deleting rows from table RestrictedAccess and to be allowed to mark only the rows virtually deleted through stored procedure spMarkDeleted by setting the rows’ status as 'Deleted', then you can execute the DENY and GRANT commands as follows:
IF (SELECT OBJECT_ID('dbo.RestrictedAccess')
) IS NOT NULL
DROP TABLE dbo.RestrictedAccess ;
GO
CREATE TABLE dbo.RestrictedAccess (ID INT, Status VARCHAR(7)) ;
INSERT INTO t1
VALUES (1, 'New') ;
GO
IF (SELECT OBJECT_ID('dbo.spuMarkDeleted')
) IS NOT NULL
DROP PROCEDURE dbo.spuMarkDeleted ;
GO
CREATE PROCEDURE dbo.spuMarkDeleted @ID INT
AS
UPDATE dbo.RestrictedAccess
SET Status = 'Deleted'
WHERE ID = @ID ;
GO
--Prevent user u1 from deleting rows
DENY DELETE ON dbo.RestrictedAccess TO UserOne ;
--Allow user u1 to mark a row as 'deleted'
GRANT EXECUTE ON dbo.spuMarkDeleted TO UserOne ;
This assumes the existence of user UserOne. Note that if the query within the stored procedure spMarkDeleted is built dynamically as a string (@sql) as follows, then granting permission to the stored procedure won’t grant any permission to the query, since the dynamic query isn’t treated as part of the stored procedure:
CREATE PROCEDURE dbo.spuMarkDeleted
@ID INT
AS
DECLARE @SQL NVARCHAR(MAX);
SET @SQL = 'UPDATE dbo.RestrictedAccess
SET Status = ''Deleted''
WHERE ID = ' + @ID ;
EXEC sys.sp_executesql @SQL;
GO
GRANT EXECUTE ON dbo.spuMarkDeleted TO UserOne ;
Consequently, user UserOne won’t be able to mark the row as 'Deleted' using the stored procedure spMarkDeleted. (I cover the aspects of using a dynamic query in the stored procedure in the next chapter.)
Since stored procedures are saved as database objects, they add maintenance overhead to the database administration. Many times, you may need to execute just one or a few queries from the application.
If these singleton queries are executed frequently, you should aim to reuse their execution plans to improve performance. But creating stored procedures for these individual singleton queries adds a large number of stored procedures to the database, increasing the database administrative overhead significantly. To avoid the maintenance overhead of using stored procedures and yet derive the benefit of plan reuse, submit the singleton queries as a prepared workload using the sp_executesql system stored procedure.
sp_executesql
sp_executesql is a system stored procedure that provides a mechanism to submit one or more queries as a prepared workload. It allows the variable parts of the query to be explicitly parameterized, and it can therefore provide execution plan reusability as effective as a stored procedure. The SELECT statement from spBasicSalesInfo can be submitted through sp_ executesql as follows (--executesql in the download):
DECLARE @query NVARCHAR(MAX),
@paramlist NVARCHAR(MAX) ;
SET @query = N';SELECT soh.SalesOrderNumber ,soh.OrderDate
,sod.OrderQty ,sod.LineTotal FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID =
sod.SalesOrderID WHERE soh.CustomerID = @CustomerID
AND sod.ProductID = @ProductID';
SET @paramlist = N'@CustomerID INT, @ProductID INT' ;
EXEC sp_executesql
@query,
@paramlist,
@CustomerID = 29690,
@ProductID = 711 ;
Note that the strings passed to the spexecutesql stored procedure are declared as NVARCHAR and that they are built with a prefix of N. This is required since spexecutesql uses Unicode strings as the input parameters.
The output of sys.dm_exec_cached_plans is shown next (see Figure 9-24).
![]()
Figure 9-24. sys.dm_exec_cached_plans output showing a parameterized plan generated using sp_executesql
SELECT c.usecounts,
c.cacheobjtype,
c.objtype,
t.text
FROM sys.dm_exec_cached_plans c
CROSS APPLY sys.dm_exec_sql_text(c.plan_handle) t
WHERE text LIKE '(@CustomerID%';
In Figure 9-24, you can see that the plan is generated for the parameterized part of the query submitted through sp_executesql, line 2. Since the plan is not tied to the variable part of the query, the existing execution plan can be reused if this query is resubmitted with a different value for one of the parameters (d.ProductID=777) as follows:
EXEC sp_executesql
@query,
@paramlist,
@CustomerID = 29690,
@ProductID = 777 ;
Figure 9-25 shows the output of sys.dm_exec_cached_plans.
![]()
Figure 9-25. sys.dm_exec_cached_plans output showing reuse of the parameterized plan generated using sp_executesql
From Figure 9-25, you can see that the existing plan is reused (usecounts is 2 on the plan on line 2) when the query is resubmitted with a different variable value. If this query is resubmitted many times with different values for the variable part, the existing execution plan can be reused without regenerating new execution plans.
The query for which the plan is created (the text column) matches the exact textual string of the parameterized query submitted through sp_executesql. Therefore, if the same query is submitted from different parts of the application, ensure that the same textual string is used in all places. For example, if the same query is resubmitted with a minor modification in the query string (where in lowercase instead of uppercase letters), then the existing plan is not reused, and instead a new plan is created, as shown in the sys. dm_exec_cached_plans output in Figure 9-26.
![]()
Figure 9-26. sys.dm_exec_cached_plans output showing sensitivity of the plan generated using sp_executesql
SET @query = N'SELECT soh.SalesOrderNumber ,soh.OrderDate
,sod.OrderQty ,sod.LineTotal FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID =
sod.SalesOrderID where soh.CustomerID = @CustomerID AND
sod.ProductID = @ProductID' ;
Another way to see that there are two different plans created in cache is to use additional dynamic management objects to see the properties of the plans in cache:
SELECT decp.usecounts,
decp.cacheobjtype,
decp.objtype,
dest.text,
deqs.creation_time,
deqs.execution_count,
deqs.query_hash,
deqs.query_plan_hash
FROM sys.dm_exec_cached_plans AS decp
CROSS APPLY sys.dm_exec_sql_text(decp.plan_handle) AS dest
JOIN sys.dm_exec_query_stats AS deqs
ON decp.plan_handle = deqs.plan_handle
WHERE dest.text LIKE '(@CustomerID INT, @ProductID INT)%' ;
The results from this query can be seen in Figure 9-27.
![]()
Figure 9-27. Additional output from sys.dm_exec_query_stats
The output from sys.dm_exec_query_stats shows that the two versions of the query have different creation_time values. More interestingly, they have identical query_hashs, but different query_plan_hashs (more on the hash values in that section later). All this shows that changing the case resulted in differing execution plans being stored in cache.
In general, use sp_executesql to explicitly parameterize queries to make their execution plans reusable when the queries are resubmitted with different values for the variable parts. This provides the performance benefit of reusable plans without the overhead of managing any persistent object as required for stored procedures. This feature is exposed by both ODBC and OLEDB through SOLExecDirect and ICommandWithParameters, respectively. As .NET developers or users of ADO.NET (ADO 2.7 or higher), you can submit the preceding SELECT statement using ADO Command and Parameters. If you set the ADO Command Prepared property to FALSE and use ADO Command ('SELECT * FROM “Order Details” d, Orders o WHERE d.OrderID=o.OrderID and d.ProductID=?') with ADO Parameters, ADO.NET will send the SELECT statement using sp_executesql.
Along with the parameters, sp_executesql sends the entire query string across the network every time the query is reexecuted. You can avoid this by using the prepare/execute model of ODBC and OLEDB (or OLEDB .NET).
Prepare/Execute Model
ODBC and OLEDB provide a prepare/execute model to submit queries as a prepared workload. Like sp_executesql, this model allows the variable parts of the queries to be parameterized explicitly. The prepare phase allows SQL Server to generate the execution plan for the query and return a handle of the execution plan to the application. This execution plan handle is used by the execute phase to execute the query with different parameter values. This model can be used only to submit queries through ODBC or OLEDB, and it can’t be used within SQL Server itself—queries within stored procedures can’t be executed using this model.
The SQL Server ODBC driver provides the SOLPrepare and SOLExecute APIs to support the prepare/execute model. The SQL Server OLEDB provider exposes this model through the ICommandPrepare interface. The OLEDB .NET provider of ADO.NET behaves similarly.
![]() Note For a detailed description of how to use the prepare/execute model in a database application, please refer to the MSDN article “Preparing SQL Statements” (http://msdn.microsoft.com/en-us/llibrary/ms175528.aspx).
Note For a detailed description of how to use the prepare/execute model in a database application, please refer to the MSDN article “Preparing SQL Statements” (http://msdn.microsoft.com/en-us/llibrary/ms175528.aspx).
Although the goal of a well-defined workload is to get a plan into the cache that will be reused, it is possible to get a plan into the cache that you don’t want to reuse. The first time a procedure is called by SQL Server, the values of the parameters used are included as a part of generating the plan. If these values are representative of the data and statistics, then you’ll get a good plan that will be beneficial to most executions of the stored procedure. But if the data is skewed in some fashion, it can seriously impact the performance of the query.
For example, take the following stored procedure (--spAddressByCity in the download):
IF (SELECT OBJECT_ID('dbo.spAddressByCity')
) IS NOT NULL
DROP PROC dbo.spAddressByCity
GO
CREATE PROC dbo.spAddressByCity @City NVARCHAR(30)
AS
SELECT a.AddressID,
a.AddressLine1,
AddressLine2,
a.City,
sp.[Name] AS StateProvinceName,
a.PostalCode
FROM Person.Address AS a
JOIN Person.StateProvince AS sp
ON a.StateProvinceID = sp.StateProvinceID
WHERE a.City = @City ;
After creating the procedure, run it with this parameter:
EXEC dbo.spAddressByCity @City = N'London'
This will result in the following I/O and execution times as well as the query plan in Figure 9-28.

Figure 9-28. Execution plan of spAddressByCity
Table 'Address'. Scan count 1, logical reads 216
Table 'StateProvince'. Scan count 1, logical reads 3
CPU time = 0 ms, elapsed time = 245 ms.
If the stored procedure is run again but this time with a different parameter, then it returns with a different set of I/O and execution times but the same execution plan:
EXEC dbo.spAddressByCity @City = N';Mentor';
Table 'Address'. Scan count 1, logical reads 216
Table 'StateProvince'. Scan count 1, logical reads 3
CPU time = 16 ms, elapsed time = 75 ms.
The I/O looks roughly the same since the same execution plan is reused. The execution time is much faster because fewer rows are being returned. You can verify that the plan was reused by taking a look at the output from sys.dm_exec_query_stats (in Figure 9-29).
![]()
Figure 9-29. Output from sys.dm_exec_query_stats verifies procedure reuse.
SELECT dest.text,
deqs.execution_count,
deqs.creation_time
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) AS dest
WHERE dest.text LIKE 'CREATE PROC dbo.spAddressByCity%';
To show how parameters affect execution plans, you can reverse the order of the execution of the procedures. First flush the buffer cache by running DBCC FREEPROCCACHE. Then rerun the queries in reverse order. The first query, using the parameter Mentor, results in the following I/O and execution plan (Figure 9-30).
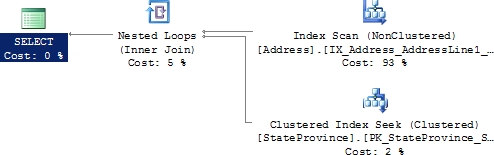
Figure 9-30. The execution plan changes.
Table 'StateProvince'. Scan count 0, logical reads 2
Table 'Address'. Scan count 1, logical reads 216
CPU time = 0 ms, elapsed time = 63 ms
Figure 9-30 is not the same execution plan as that shown in Figure 9-28. The number of reads drops slightly, but the execution time stays roughly the same. The second execution, using London as the value for the parameter, results in the following I/O and execution times:
Table 'StateProvince'. Scan count 0, logical reads 868
Table 'Address'. Scan count 1, logical reads 216
CPU time = 0 ms, elapsed time = 283 ms.
This time the reads are radically higher, and the execution time was increased. The plan created in the first execution of the procedure with the parameter London created a plan best suited to retrieve the 1,000+ rows that match those criteria in the database. Then the next execution of the procedure using the parameter value Mentor did well enough using the same plan generated by the first execution. When the order is reversed, a new execution plan was created for the value Mentor that did not work at all well for the value London. This behavior is caused by the optimizer “sniffing” the parameters, actually sampling these values and using them to do precise lookups against the statistics used in the query. Normally this process is extremely beneficial, but when it isn’t, it’s referred to as “bad parameter sniffing.”
This is a case where having an execution plan in the cache can hurt the performance of your queries. Once you identify the issue for a plan that works well some of the time but doesn’t others, you avoid or fix this problem in a number of ways:
- You can force a recompile of the plan either at the time of execution by running sp_ recompile against the procedure prior to executing it or by getting the statement to recompile each time it executes by using the WITH RECOMPILE hint.
- You can reassign input parameters to local parameters. This popular fix forces the optimizer to make a best guess at the values likely to be used by looking at the statistics of the data being referenced, which can and does eliminate the values being taken into account. The problem with the solution is it eliminates the values being taken into account. You may get worse performing procedures overall.
- You can use a query hint, OPTIMIZE FOR, when you create the procedure and supply it with known good parameters that will generate a plan that works well for most of your queries. You can specify a value that generates a specific plan, or you can specify UNKNOWN to get a generic plan based on the average of the statistics. However, understand that some percentage of the queries won’t work well with the parameter supplied.
- You can use a plan guide, which is a mechanism to get a query to behave a certain way without making modifications to the procedure. This will be covered in detail in Chapter 10.
- You can disable parameter sniffing for the server by setting traceflag 4136 to on. Understand that this beneficial behavior will be turned off for the entire server, not just one problematic query.
Just remember that most of the time parameterized queries and plan reuse are not a problem.
Query Plan Hash and Query Hash
With SQL Server 2008, new functionality around execution plans and the cache was introduced called the query plan hash and the query hash. These are binary objects using an algorithm against the query or the query plan to generate the binary hash value. These are useful for a very common practice in developing known as copy and paste. You will find that very common patterns and practices will be repeated throughout your code. Under the best circumstances, this is a very good thing, because you will see the best types of queries, joins, set-based operations, and so on, copied from one procedure to another as needed. But sometimes, you will see the worst possible practices repeated over and over again in your code. This is where the query hash and the query plan hash come into play to help you out.
You can retrieve the query plan hash and the query hash from sys.dm_exec_query_stats or sys.dm_exec_requests. Although this is a mechanism for identifying queries and their plans, the hash values are not unique. Dissimilar plans can arrive at the same hash, so you can’t rely on this as an alternate primary key.
To see the hash values in action, create two queries (--queryhash in the download):
SELECT *
FROM Production.Product AS p
JOIN Production.ProductSubcategory AS ps
ON p.ProductSubcategoryID = ps.ProductSubcategoryID
JOIN Production.ProductCategory AS pc
ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE pc.[Name] = 'Bikes'
AND ps.[Name] = 'Touring Bikes' ;
SELECT *
FROM Production.Product AS p
JOIN Production.ProductSubcategory AS ps
ON p.ProductSubcategoryID = ps.ProductSubcategoryID
JOIN Production.ProductCategory AS pc
ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE pc.[Name] = 'Bikes'
AND ps.[Name] = 'Road Bikes' ;
Note that the only substantial difference between the two queries is that ProductSubcategory.Name is different, Touring Bikes in one and Road Bikes in the other. However, also note that the WHERE and AND keywords in the second query are lowercase. After you execute each of these queries, you can see the results of these format changes from sys.dm_exec_query_stats in Figure 9-31 from the following query:

Figure 9-31. sys.dm_exec_query_stats showing the plan hash values
SELECT deqs.execution_count,
deqs.query_hash,
deqs.query_plan_hash,
dest.text
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) dest
WHERE dest.text LIKE 'SELECT *
FROM Production.Product AS p%' ;
Two different plans were created because these are not parameterized queries; they are too complex to be considered for simple parameterization, and forced parameterization is off. These two plans have identical hash values because they varied only in terms of the values passed. The differences in case did not matter to the query hash or the query plan hash value. If, however, you changed the SELECT criteria in queryhash, then the values would be retrieved from sys.dm_exec_query_stats, as shown in Figure 9-32, and the query would have changes.
SELECT p.ProductID
FROM Production.Product AS p
JOIN Production.ProductSubcategory AS ps
ON p.ProductSubcategoryID = ps.ProductSubcategoryID
JOIN Production.ProductCategory AS pc
ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE pc.[Name] = 'Bikes'
AND ps.[Name] = 'Touring Bikes' ;

Figure 9-32. sys.dm_exec_query_stats showing a different hash
Although the basic structure of the query is the same, the change in the columns returned was enough to change the query hash value and the query plan hash value.
Because differences in data distribution and indexes can cause the same query to come up with two different plans, the query_hash can be the same, and the query_plan_hash can be different. To illustrate this, execute two new queries (--queryplanhash in the download):
SELECT p.[Name],
tha.TransactionDate,
tha.TransactionType,
tha.Quantity,
tha.ActualCost
FROM Production.TransactionHistoryArchive tha
JOIN Production.Product p
ON tha.ProductID = p.ProductID
WHERE p.ProductID = 461 ;
SELECT p.[Name],
tha.TransactionDate,
tha.TransactionType,
tha.Quantity,
tha.ActualCost
FROM Production.TransactionHistoryArchive tha
JOIN Production.Product p
ON tha.ProductID = p.ProductID
WHERE p.ProductID = 712 ;
Like the original queries used earlier, these queries vary only by the values passed to the ProductID column. When both queries are run, you can select data from sys.dm_exec_query_ stats to see the hash values (Figure 9-33).

You can see the queryhash values are identical, but the query_plan_hash values are different. This is because the execution plans created, based on the statistics for the values passed in, are radically different, as you can see in Figure 9-34.
Figure 9-34. Different parameters result in radically different plans
The query plan hash and the query hash values can be useful tools for tracking down common issues between disparate queries, but as you’ve seen, they’re not going to retrieve an accurate set of information in every possibility. They do add yet another useful tool in identifying other places where query performance could be poor. They can also be used to track execution plans over time. You can capture the query_plan_hash for a query after deploying it to production and then watch it over time to see whether it changes because of data changes. With this you can also keep track of aggregated query stats by plan, referencing sys.dm_exec_ querystats, although remember that the aggregated data is reset when the server is restarted or the plan cache is cleared in any way. Keep these tools in mind while tuning your queries.
Execution Plan Cache Recommendations
The basic purpose of the plan cache is to improve performance by reusing execution plans. Thus, it is important to ensure that your execution plans actually are reusable. Since the plan reusability of ad hoc queries is inefficient, it is generally recommended that you rely on prepared workload techniques as much as possible. To ensure efficient use of the plan cache, follow these recommendations:
- Explicitly parameterize variable parts of a query.
- Use stored procedures to implement business functionality.
- Use sp_executesql to avoid stored procedure maintenance.
- Use the prepare/execute model to avoid resending a query string.
- Avoid ad hoc queries.
- Use sp_executesql over EXECUTE for dynamic queries.
- Parameterize variable parts of queries with care.
- Avoid modifying environment settings between connections.
- Avoid the implicit resolution of objects in queries.
Let’s take a closer look at these points.
Explicitly Parameterize Variable Parts of a Query
A query is often run several times, with the only difference between each run being that there are different values for the variable parts. Their plans can be reused, however, if the static and variable parts of the query can be separated. Although SQL Server has a simple parameterization feature and a forced parameterization feature, they have severe limitations. Always perform parameterization explicitly using the standard prepared workload techniques.
Create Stored Procedures to Implement Business Functionality
If you have explicitly parameterized your query, then placing it in a stored procedure brings the best reusability possible. Since only the parameters need to be sent along with the stored procedure name, network traffic is reduced. Since stored procedures are precompiled, they run faster than ad hoc queries. And stored procedures can also maintain a single parameterized plan for the set of queries included within the stored procedure, instead of maintaining a large number of small plans for the individual queries. This prevents the plan cache from being flooded with separate plans for the individual queries.
Like anything else, it is possible to have too much of a good thing. There are business processes that belong in the database, but there are also business processes that should never be placed within the database.
Code with sp_executesql to Avoid Stored Procedure Maintenance
If the object maintenance required for the stored procedures becomes a consideration or you are using client-side generated queries, then use sp_executesql to submit the queries as prepared workloads. Unlike the stored procedure model, sp_executesql doesn’t create any persistent objects in the database. sp_executesql is suited to execute a singleton query or a small batch query.
The complete business logic implemented in a stored procedure can also be submitted with sp_executesql as a large query string. However, as the complexity of the business logic increases, it becomes difficult to create and maintain a query string for the complete logic.
Implement the Prepare/Execute Model to Avoid Resending
a Query String
sp_executesql requires the query string to be sent across the network every time the query is reexecuted. It also requires the cost of a query string match at the server to identify the corresponding execution plan in the procedure cache. In the case of an ODBC or OLEDB (or OLEDB .NET) application, you can use the prepare/execute model to avoid resending the query string during multiple executions, since only the plan handle and parameters need to be submitted. In the prepare/execute model, since a plan handle is returned to the application, the plan can be reused by other user connections; it is not limited to the user who created the plan.
Avoid Ad Hoc Queries
Do not design new applications using ad hoc queries! The execution plan created for an ad hoc query cannot be reused when the query is resubmitted with a different value for the variable parts. Even though SQL Server has the simple parameterization and forced parameterization features to isolate the variable parts of the query, because of the strict conservativeness of SQL Server in parameterization, the feature is limited to simple queries only. For better plan reusability, submit the queries as prepared workloads.
There are systems built upon the concept of nothing but ad hoc queries. This is functional and can work within SQL Server, but, as you’ve seen, it carries with it large amounts of additional overhead that you’ll need to plan for.
Prefer sp_executesql over EXECUTE for Dynamic Queries
SQL query strings generated dynamically within stored procedures or a database application should be executed using spexecutesql instead of the EXECUTE command. The EXECUTE command doesn’t allow the variable parts of the query to be explicitly parameterized.
To understand the preceding comparison between sp_executesql and EXECUTE, consider the dynamic SQL query string used to execute the SELECT statement in adhocsproc:
DECLARE @n VARCHAR(3) = '776',
@sql VARCHAR(MAX) ;
SET @sql = 'SELECT * FROM Sales.SalesOrderDetail sod '
+ 'JOIN Sales.SalesOrderHeader soh '
+ 'ON sod.SalesOrderID=soh.SalesOrderID ' + ';WHERE sod.ProductID='''
+ @n + '''' ;
--Execute the dynamic query using EXECUTE statement
EXECUTE (@sql) ;
The EXECUTE statement submits the query along with the value of d.ProductID as an ad hoc query and thereby may or may not result in simple parameterization. Check the output yourself by looking at the cache:
SELECT deqs.execution_count,
deqs.query_hash,
deqs.query_plan_hash,
dest.text,
deqp.query_plan
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_sql_text(deqs.plan_handle) dest
CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp;
For improved plan cache reusability, execute the dynamic SQL string as a parameterized query using
sp_executesql:
DECLARE @n NVARCHAR(3) = '776',
@sql NVARCHAR(MAX),
@paramdef NVARCHAR(6) ;
SET @sql = 'SELECT * FROM Sales.SalesOrderDetail sod '
+ 'JOIN Sales.SalesOrderHeader soh '
+ 'ON sod.SalesOrderID=soh.SalesOrderID ' + 'WHERE sod.ProductID=@1' ;
SET @paramdef = N'@1 INT' ;
--Execute the dynamic query using sp_executesql system stored procedure
EXECUTE sp_executesql
@sql,
@paramdef,
@1 = @n ;
Executing the query as an explicitly parameterized query using sp_executesql generates a parameterized plan for the query and thereby increases the execution plan reusability.
Parameterize Variable Parts of Queries with Care
Be careful while converting variable parts of a query into parameters. The range of values for some variables may vary so drastically that the execution plan for a certain range of values may not be suitable for the other values. This can lead to bad parameter sniffing. Remember that dealing with bad parameter sniffing can be done by either going for specific plans using things like OPTIMIZE FOR <value> query hints or by going for generic plans by using local variables within the parameterized code. Your data and statistics will drive the best solution.
Do Not Allow Implicit Resolution of Objects in Queries
SQL Server allows multiple database objects with the same name to be created under different schemas. For example, table t1 can be created using two different schemas (u1 and u2) under their individual ownership. The default owner in most systems is dbo (database owner). If user u1 executes the following query, then SQL Server first tries to find whether table t1 exists for user u1’s default schema.
SELECT * FROM tl WHERE cl = 1
If not, then it tries to find whether table t1 exists for the dbo user. This implicit resolution allows user u1to create another instance of table t1under a different schema and access it temporarily (using the same application code) without affecting other users.
On a production database, I recommend using the schema owner and avoiding implicit resolution. If not, using implicit resolution adds the following overhead on a production server:
- It requires more time to identify the objects.
- It decreases the effectiveness of plan cache reusability.
Summary
SQL Server’s cost-based query optimizer decides upon an effective execution plan not based on the exact syntax of the query but by evaluating the cost of executing the query using different processing strategies. The cost evaluation of using different processing strategies is done in multiple optimization phases to avoid spending too much time optimizing a query. Then, the execution plans are cached to save the cost of execution plan generation when the same queries are reexecuted. To improve the reusability of cached plans, SQL Server supports different techniques for execution plan reuse when the queries are rerun with different values for the variable parts.
Using stored procedures is usually the best technique to improve execution plan reusability. SQL Server generates a parameterized execution plan for the stored procedures so that the existing plan can be reused when the stored procedure is rerun with the same or different parameter values. However, if the existing execution plan for a stored procedure is invalidated, the plan can’t be reused without a recompilation, decreasing the effectiveness of plan cache reusability.
In the next chapter, I will discuss how to troubleshoot and resolve unnecessary stored procedure plan recompilations.