
Chapter 7. Using implicits and types together
- Introduction to implicit type bounds
- Type classes and their applications
- Type level programming and compile time execution
The type system and the implicit resolution mechanism provide the tools required to write expressive, type-safe software. Implicits can encode types into runtime objects and can enable the creation of type classes that abstract behavior from classes. Implicits can be used to directly encode type constraints and to construct types recursively. Combined with some type constructors and type bounds, implicits and the type system can help you encode complex problems directly into the type system. Most importantly, you can use implicits to preserve type information and delegate behavior to type-specific implementations while preserving an abstract interface. The ultimate goal is the ability to write classes and methods that can be reused anytime they’re needed.
To start, let’s look at some type bounds that we didn’t cover in chapter 6.
7.1. Context bounds and view bounds
Scala supports two types of type constraint operators that aren’t type constraints but are implicit lookups—context bounds and view bounds. These operators allow us to define an implicit parameter list as type constraints on generic types. This syntax can reduce typing in situations where implicit definitions must be available for lookup but don’t need to be directly accessed.
View bounds are used to require an available implicit view for converting one type into another type. Implicit views look like the following:
def foo[A <% B](x: A) = x
The foo method defines a constraint A <% B. This constraint means that the parameter x is of type A and there must be an implicit conversion function A => B available at any call site. The preceding code can be rewritten as the following:
def foo[A](x: A)(implicit $ev0: A => B) = x
This foo method is also defined with a type parameter A that has no constraints. Two parameter lists exist: one that accepts an A type and one that requires the implicit conversion function. Although this second form requires more typing, it places a user-defined label on the implicit conversion function.
When should you choose to use view/context bounds vs. directly writing an implicit parameter list? A simple convention is to use view/context bounds in these two scenarios:
- The code within the method doesn’t need to access the implicit parameter directly, but relies on the implicit resolution mechanism. In this situation, we must require an implicit parameter be available to call another function that requires that implicit parameter, or the implicit is automatically used. This is most common when using view bounds.
- The meaning conveyed by the type parameter is more clear using context/view bounds than an implicit parameter list. See section 7.3 on type classes for examples of this scenario.
Context bounds, similar to view bounds, declare that there must be an implicit value available with a given type. Context bounds look like the following:
def foo[A : B](x: A) = x
The foo method defines a constraint A : B. This constraint means that the parameter x is of type A and there must be an implicit value B[A] available when calling method foo. Context bounds can be rewritten as follows:
def foo[A](x: A)(implicit $ev0: B[A]) = x
This foo method defines two parameter lists, with the implicit parameter list accepting a value of type B[A]. The key difference between the two foo versions is that this one gives an explicit label to the B[A] parameter that can be used within the function.
Context bounds are extremely useful in helping provide implicit values in companion objects. This naturally leads to type classes, shown in section 7.3. Type classes are a means of encoding behavior into a wrapper or accessor for another type. They are the most common use of context bound constraints.
7.1.1. When to use implicit type constraints
Scala’s implicit views are often used to enrich existing types, where enrich means adding additional behavior that doesn’t exist on the raw type (see Odersky’s paper “Pimp My Library”: http://mng.bz/86Qh). Implicit type constraints are used when we want to enrich an existing type while preserving that type in the type system. For example, let’s write a method that will return the first element of a list and the list itself:
scala> def first[T](x : Traversable[T]) =
| (x.head, x)
first: [T](x: Traversable[T])(T, Traversable[T])
scala> first(Array(1,2))
res0: (Int, Traversable[Int]) = (1,WrappedArray(1, 2))
The method defines a type parameter T for the element of the collection. It expects a variable of type Traversable[T]. It then returns the head of the traversable and the traversable itself. When calling this method with an array, the resulting type is a Traversable[Int] and the runtime type is WrappedArray. This method has lost the original type information about the array.
Context bounds and view bounds allow developers to enforce complex type constraints in a simple fashion. They are best applied when we do not need to access the captured implicit by name, but the method requires the implicit to be available in its scope.
One of the key tenants of object-oriented programming is polymorphism: the ability of a complex type to act as a simple type. In the absence of generic types and bounds, polymorphism usually results in a loss of type information. For example, in Java’s java.util.Collections class, there are two methods: List synchronizedList(List) and Collection synchronizedCollection(Collection). In Scala, utilizing some advanced implicit concepts, we can accomplish the same feat with one method: def synchronizedCollection[A, CC <: Traversable[A] : Manifest](col : CC) : CC.
One of the biggest benefits of using Scala is the ability to preserve specific types across generic methods. The entire collections API is designed such that methods defined in the lower level types preserve the original types of the collections as much as possible.
For example, a method that works with types that could be serialized but doesn’t serialize them might look something like this:
def sendMsgToEach[A : Serializable](receivers : Seq[Receiver[A]],
a : A) = {
receivers foreach (_.send(a))
}
The sendMsgToEach accepts any type that has a serializable implicit context (that is, the compiler can find the type Serializable[A] on the implicit scope—and a sequence of receivers of type a. The method implementation calls send on each receiver, passing the message to each. But the implementation of the send method on the Receiver type would need to use the Serializable value, so it’s better to explicitly specify the implicit argument list in that method.
Context bound and view bound constraints are used to clarify the intent of an implicit argument. Implicit arguments can be used to capture a relationship from the type system.
7.2. Capturing types with implicits
Scala 2.8 formalized the ability to encode type information into implicit parameters. It does this through two mechanisms: Manifests and implicit type constraints.
A Manifest for a type is generated by the compiler, when needed, with all the known information for that type at that time. Manifests were added specifically to handle arrays and were generalized to be useful in other situations where the type must be available at runtime.
Implicit type constraints are direct encoding of supertype and equivalence relationships between types. These can be useful to restrict a generic type further within a method. These constraints are static—that is, they happen at compile time.
The runtime counterpart of a type is the Manifest.
7.2.1. Manifests
As stated earlier, Manifests were first introduced into Scala to help deal with arrays. They capture types for runtime evaluation. In Scala, an array is a class with a parameter. An array of integers has the type Array[Int]. On the JVM, however, there are different types of arrays for every primitive type and one for objects. Examples include int[], double[], and Object[]. The Java language distinguishes between these types and requires programs to do so as well. Scala allows code to be written for generic Array[T] types. But because the underlying implementation must know whether the original array was an int[], a double[], or one of the other array types, Scala needed a way to attach this information to the type so that generic array implementations would know how to treat the array, and so the birth of Manifests.
ClassManifest provides the smallest runtime overhead for the greatest benefit. While Manifests are extremely useful, any advanced type checking should still be performed by the compiler and not at runtime. Usually ClassManifest is good enough when reified types are required.
You can use Manifests to pass along more specific type information with a generic type parameter. In Scala, all methods involving Arrays require an appropriate Manifest for the array’s type parameter. This was done because although Scala treats Arrays as generic classes, they are encoded differently by type on the JVM. Rather than encode these differently in Scala, for example int[] and double[], Scala chose to hide the runtime behavior behind the Array[T] class and associated methods. Because different bytecode must be emitted for Array[Int] and Array[Double], Scala uses Manifests to carry around the type information about arrays. This is done through Manifests.
Scala provides several types of Manifests:
- Manifest— This Manifest stores a reflective instance of the class associated with a type T as well as Manifest values for each of T’s type parameters. A reflective instance of a class is a reference to the java.lang.Class object for that class. This allows reflective invocations of methods defined on that class. A good example is the type List [Int]. A Manifest[List[Int]] allows access to the java.lang.Class for the scala.List type. It also contains a Manifest[Int] that would allow access to the java.lang.Class for the scala.Int type.
- OptManifest— Require an OptManifest for a type makes the Manifest requirement optional. If there’s one available, then the OptManifest instance will be the Manifest subclass. If none can be provided, then the instance will be the NoManifest class.
- ClassManifest— This class is similar to Manifest except that it only stores the erased class of a given type. This erased class of a type is associated with the type without any type parameters. For example, the type List[Int] would have the erased class List.
The Manifest class can be expensive to store/compute, as it must have access to the java.lang.Class object for every type and type parameter. For a type with a lot of nesting, this can be quite deep, and methods on the Manifest may traverse the entire depth. The ClassManifest is designed for scenarios where type parameters don’t need to be captured. The OptManifest is designed for situations where a Manifest isn’t needed for runtime behavior, but can be used for runtime improvements if it’s available.
7.2.2. Using Manifests
Manifests are useful in Scala to create abstract methods whose implementations diverge based on the types they work on, but the resulting outputs don’t. A good example of this is any method using generic arrays. Because Scala must use different bytecode instructions depending on the runtime array type, it requires a ClassManifest on the Array element.
scala> def first[A](x : Array[A]) = Array(x(0)) <console>:7: error: could not find implicit value for evidence parameter of type scala.reflect.ClassManifest[A] def first[A](x : Array[A]) = Array(x(0))
The first method is defined as taking a generic Array of type A. It attempts to construct a new array containing only the first element of the old array. But because we haven’t captured a Manifest, the compiler can’t figure out which runtime type the resulting Array should have.
scala> def first[A : ClassManifest](x : Array[A]) =
| Array(x(0))
first: [A](x: Array[A])(implicit evidence$1: ClassManifest[A])Array[A]
scala> first(Array(1,2))
res1: Array[Int] = Array(1)
Now the A type parameter also captures the implicit ClassManifest. When called with an Array[Int], the compiler constructs a ClassManifest for the type Int, and this is used to construct a runtime array of the appropriate type.
Classmanifest and Arrays
The ClassManifest class directly contains a method to construct new arrays of the type it’s captured. This could be used directly instead of delegating to Scala’s generic Array factory method.
Using Manifests requires capturing the Manifest when a specific type is known before passing to a generic method. If the type of an array were “lost,” the array couldn’t be passed into the first method.
scala> val x : Array[_] = Array(1,2)
x: Array[_] = Array(1, 2)
scala> first(x)
<console>:10: error: could not find implicit value for
evidence parameter of type ClassManifest[_$1]
first(x)
The value x is constructed as an Array with existential type. The first method can’t be called with the value x because a ClassManifest can’t be found for the array’s type. Although this example is contrived, the situation itself occurs when working with Arrays in nested generic code. We solve this by attaching Manifests to types all the way down the generic call stack.
Runtime Versus Compile Time
Manifests are captured at compile time and encode the type known at the time of capture. This type can then be inspected and used at runtime, but the Manifest can only capture the type available when the Manifest is looked for on the implicit scope.
Manifests are useful tools for capturing runtime types, but they can become viral in code, needing to be specified in many different methods. Use them with caution and in situations where they’re required. Don’t use them to enforce type constraints when the type is known by the compiler; instead these can be captured with another implicit at compile time.
7.2.3. Capturing type constraints
The intersection of type inference and type constraints sometimes causes issues where you need to use reified type constraints. What are reified type constraints? These are objects whose implicit existence verifies that some type constraint holds true. For example, there’s a type called <:<[A,B] that, if the compiler can find it on the implicit scope, then it must be true that A <: B. The <:< class is the reification of the upper bound constraint.
What Does Reification Mean?
Think of reification as the process of converting some concept in a programming language to a class or object that can be inspected and used at runtime. A Function object is a reification of a method. It’s an object that you can call methods on at runtime. In this same vein, other things can be reified.
Why do we need reified type constraints? Sometimes it can help the type inferencer automatically determine types for a method call. One of the neat aspects of the type inferencing algorithm is that implicits can defer the resolution of types until later in the algorithm. Scala’s type inferencer works in a left-to-right fashion across parameter lists. This allows the types inferred from one parameter list to affect the types inferred in the next parameter list.
A great example of this left-to-right inference is with anonymous functions using collections. Let’s take a look:
scala> def foo[A](col: List[A])(f: A => Boolean) = null
foo: [A](col: List[A])(f: (A) => Boolean)Null
scala> foo(List("String"))(_.isEmpty)
res1: Null = null
The foo method defines two parameter lists with one type parameter: one that takes a list of the unknown parameter and another that takes a function using the unknown parameter. When calling foo without a type parameter, the call succeeds because the compiler is able to infer the type parameter A as equal to String. This type is then used for the second parameter list, where the compiler knows that the _ should be of type String. This doesn’t work when we combine the parameter lists into one parameter list.
scala> def foo[A](col: List[A], f: A => Boolean) = null
foo: [A](col: List[A],f: (A) => Boolean)Null
scala> foo(List("String"), _.isEmpty)
<console>:10: error: missing parameter type for expanded
function ((x$1) => x$1.isEmpty)
foo(List("String"), _.isEmpty)
In this case, the compiler complains about the anonymous function _.isEmpty because it has no type. The compiler has not inferred that A = String yet, so it can’t provide a type for the anonymous function.
This same situation can occur with type parameters. The compiler is unable to infer all the parameters in one parameter list, so the implicit parameter list is used to help the type inferencer.
Let’s create a method peek that will return a tuple containing a collection and its first element. This method should be able to handle any collection from the Scala library, and it should retain the original type of the method passed in:
scala> def peek[A, C <: Traversable[A]](col : C) =
| (col.head, col)
foo: [A,C <: Traversable[A]](col: C)(A, C)
The method will have two type parameters: one to capture the specific type of the collection, called C, and another to capture the type of elements in the collection, called A. The type parameter C has a constraint that it must be a subtype of Traversable[A], where Traversable is the base type of all collection in Scala. The method returns types A and C, so specific types are preserved. But the type inferencer can’t detect the correct types without annotations.
scala> peek(List(1,2,3))
<console>:7: error: inferred type arguments [Nothing,List[Int]] do
not conform to method peek's type parameter
bounds [A,C <: Traversable[A]]
peek(List(1,2,3))
The call to peek with a List[Int] type fails because the type inferencer is unable to find both types C and A using only one parameter. To solve this, let’s make a new implementation of peek that defers some type inference for the second parameter list:
scala> def peek[C, A](col: C)(implicit ev: C <:< Traversable[A]) =
| (col.head, col)
foo: [C,A](col: C)(implicit ev: <:<[C,Traversable[A]])(A, C)
This peek method also has two type parameters but no type constraints on the C parameter. The first argument list is the same as before, but the second argument list takes an implicit value of type C <:< Traversable[A]. This type is taking advantage of Scala’s operator notation. Just as methods named after operators can be used in operator notation, so can types with type parameters. The type C <:< Traversable[A] is a shorthand notation for the type <:< [C, Traversable[A]]. The <:< type provides default implicit values in scala.Predef for any two types A and B that have the relationship A <: B. Let’s look at the code for the <:< type found in scala.Predef:
Listing 7.1. The <:< type
sealed abstract class <:<[-From, +To] extends
(From => To) with Serializable
implicit def conforms[A]: A <:< A = new (A <:< A) {
def apply(x: A) = x
}
The first line declares the <:< class. It extends from Function1 and Serializable. This means that <:< can be used in any context where Java serialization may be used. Next, the conforms method takes a type parameter A and returns a new <:< type such that it converts from type A to A. The trick behind <:< is the variance annotations. Because From is contravariant, if B <: A then <:<[A,A] conforms to the type <:<[B,A] and the compiler will use the implicit value <:<[A,A] to satisfy a lookup for type <:<[B,A].
Now when using the peek method without type parameters, the type inferencer succeeds:
scala> peek(List(1,2,3)) res0: (Int, List[Int]) = (1,List(1, 2, 3))
Calling the peek method with a List[Int] correctly returns an Int and a List[Int] type. Capturing type relationships can also be used to restrict an existing type parameter at a later time.
7.2.4. Specialized methods
Sometimes a parameterized class allows methods if the parameter supports a set of features, or extends a class. I call these specialized methods—that is, the method is for a specialized subset of a generic class. These methods use the implicit resolution system to enforce the subset of the generic class for which they’re defined. For example, the Scala collections have a specialized method sum that works only for numerical types.
Listing 7.2. TraversableOnce.sum method
def sum[B >: A](implicit num: Numeric[B]): B = foldLeft(num.zero)(num.plus)
The sum method, defined in TraversableOnce.scala, takes a single type parameter B. This type is any supertype of the type of elements in the collection. The parameter num is an implicit lookup for the Numeric type class. This type class provides the implementation of zero and plus, as well as other methods, for a given type. The sum method uses the methods defined on numeric to fold across the collection and “plus” all the elements together.
This method can be called on any collection whose type supports the Numeric type class. This means that if we desired, we could provide our own type class for types that aren’t normally considered numeric. For example, let’s use sum on a collection of strings:
scala> implicit object stringNumeric extends Numeric[String] {
| override def plus(x : String, y : String) = x + y
| override def zero = "
|
| ... elided other methods ...
| }
defined module stringNumeric
scala> List("One", "Two", "Three").sum
res2: java.lang.String = OneTwoThree
The first REPL line constructs an implicitly available Numeric[String] class. The zero method is defined to return an empty string and the plus method is defined to aggregate two strings together. Next, when calling sum on a List of strings, the result is that the strings are all appended together. The sum method used the Numeric type class we provided for the String type.
Methods can also be specialized using the <:< and =:= classes. For example, a method that compressed a Set, if that set was of integers, could be written like this:
trait Set[+T] {
...
def compress(implicit ev : T =:= Int) =
new CompressedIntSet(this)
}
The Set trait is defined with a type parameter representing the elements contained in the set. The compress function will take the current set and return a compressed version of it. But the only implementation of a compressed set available is the CompressedIntSet, is a Set[Int] that optimizes storage space using compression techniques. The implicit ev parameter is used to ensure that the type of the original set is exactly Set[Int] such that a CompressedIntSet can be created.
Specialized methods are a great way to provide a rich API and enforce type safety. They help smooth out some rough edges between generalized classes and specific use cases for those generalized classes. In the Scala core library, they’re used to support numerical operations within the collection framework. They pair well with type classes, which provide the most flexibility for users of a class.
7.3. Use type classes
A type class is a mechanism of ensuring one type conforms to some abstract interface. The type class pattern became popular as a language feature within the Haskell programming language. In Scala, the type class idiom manifests itself through higher-kinded types and implicit resolution. We’ll cover the details of defining your own type class, but initially let’s look at a motivating example for why you should use type classes.
Let’s design a system that synchronizes files and directories between various locations. These files could be local, remote, or located in some kind of version control system. We’d like to design some form of abstraction that can handle synchronizing between all the different location possibilities. Using our object-oriented hats, we start with trying to define an abstract interface that we can use of. Let’s call our interface FileLike, and define what methods we need for synchronization.
To start, we know that we need a method of determining whether a FileLike object is an aggregate of other FileLike objects. We’ll call this method isDirectory. When the FileLike object is a directory, we need a mechanism to retrieve the FileLike objects it contains. We’ll call this method children. We need some way of determining if a directory contains a file we see in another directory.
To do this, we’ll provide a child method that attempts to discover a FileObject contained in the current FileLike object with a given relative filename. If there’s no object, we’ll provide a null object. That is, a FileLike object that is a placeholder for a real file. We can use the null object to write data into new files. We’d like a mechanism to check whether the FileLike object exists, so we’ll make a method called exists. Finally we need mechanisms to generate content. In the case of directories, we add the mkdirs method to create a directory at the path defined by a null FileLike object. Next we supply the content and writeContent methods as a mechanism to retrieve content from FileLike objects and to write content to FileLike objects. For now, we’ll assume that we always write file contents from one side to another, and there’s no optimizations for files that might exist on both sides and be equivalent. Let’s look at our interface:
Listing 7.3. Initial FileLike interface
trait FileLike {
def name : String
def exists : Boolean
def isDirectory : Boolean
def children : Seq[FileLike]
def child(name : String) : FileLike
def mkdirs() : Unit
def content : InputStream
def writeContent(otherContent : InputStream) : Unit
}
The FileLike interface is defined with the methods described earlier. The method name returns the relative name of the FileLike object. The method exists returns whether or not the file has been created on the filesystem. The method isDirectory returns whether the class is an aggregate of other files. The children method returns a sequence containing all the FileLike objects that are contained in the current FileLike object, if it is a directory. The child method returns a new FileLike object for a child file below the current file. This method should throw an exception if the current file isn’t a directory. The mkdirs method creates directories required to ensure the current file is a directory. The content method returns an InputStream containing the contents of the file. Finally, the writeContent method accepts an InputStream and writes the contents to the file.
Now, let’s write the synchronizing code.
Listing 7.4. File synchronization using FileLike


The synchronize function contains two helper methods, one for directory like objects and another for FileLike objects. The synchronize method then delegates to these two helper functions appropriately. There’s only one problem: a subtle bug is in the code! In the synchronizeDirectory helper method, the argument ordering is mixed up when recursively calling the synchronize method! This is the kind of error you can avoid by using the type system more. Let’s try to capture the fromFileLike type separate from the toFileLike type. These can ensure the method arguments have the correct order. Let’s try it out:
Listing 7.5. Enforcing To/From types with type arguments

The synchronize method now captures the from type in the type parameter F and the to type in the type parameter T. Great! Now there’s a compilation failure on the synchronize call. But the exception isn’t quite what’s desired. In fact, if the arguments are reordered, the exception remains.
synchronize.scala:47: error: type mismatch;
found : file1.type (with underlying type FileLike)
required: F
synchronize[F,T](file1, file2)
^
synchronize.scala:47: error: type mismatch;
found : file2.type (with underlying type FileLike)
required: T
synchronize[F,T](file1, file2)
The compiler is complaining that the types returned from the FileLike.children method are not the captured type F. The FileLike interface doesn’t preserve the original type when getting children! One fix would be to modify the FileLike interface to be higher-kinded, and use the type parameter to enforce the static checks. Let’s modify the original FileLike interface to take a type parameter:
Listing 7.6. Higher-kinded FileLike

This new definition of FileLike uses a recursive type constraint in its type parameter. The captured type T must be a subtype of FileLike. This type T is now returned by the child and children methods. This interface works great for the synchronization method, except it suffers from one problem: the need to create FileLike wrappers for every FileLike object passed to the method. When synchronizing java.io.File and java.net.URL instances, a wrapper must be provided. There’s an alternative. Instead of defining the type FileLike[T <: FileLike[T]], we can define FileLike[T]. This new trait would allow interacting with any T as if it were a file and doesn’t require any inheritance relationship. This style of trait is called a type class.
7.3.1. FileLike as a type class
The type class idiom, as it exists in Scala, takes this form: (1) a type class trait that acts as the accessor or utility library for a given type; (2) an object with the same name as the trait (this object contains all default implementations of the type class trait for various types); and (3) methods with context bounds where the type trait need to be used. Let’s look at the type class trait for our file synchronization library:
Listing 7.7. FileLike type class trait
trait FileLike[T] {
def name(file : T) : String
def isDirectory(file : T) : Boolean
def children(directory : T) : Seq[T]
def child(parent : T, name : String) : T
def mkdirs(file : T) : Unit
def content(file : T) : InputStream
def writeContent(file : T, otherContent : InputStream) : Unit
}
The FileLike type class trait looks similar to the higher-kinded FileLike trait, except for two key points. First, it doesn’t have any restriction on type T. The FileLike type class works for a particular type T and against it. This brings us to the second difference: All the methods take a parameter of type T. The FileLike type class isn’t expected to be a wrapper around another class, but instead it’s an accessor of data or state from another class. It allows us to keep a specific type, while treating it generically. Let’s look at what the synchronization method becomes using the FileLike type class trait.
Listing 7.8. Synchronize method using type class

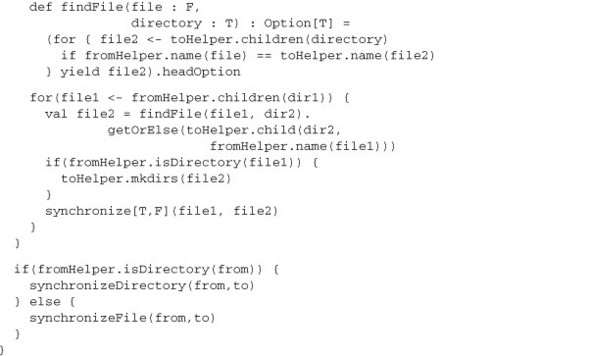
Notice the use of the context bounds syntax for FileLike. As described in section 7.1, this is equivalent to defining an implicit parameter for the FileLike on a given type. The next thing to notice is the implicitly method lookup of the FileLike parameters. Finally, every call made that utilizes type F or T uses the FileLike type class. The synchronize method can now work across many different types. Let’s see what happens when we use it on two java.io.File objects.
scala> synchronize(
| new java.io.File("tmp1"),
| new java.io.File("tmp2"))
<console>:12: error: could not find implicit value for
evidence parameter of type FileLike[java.io.File]
synchronize(new java.io.File("tmp1"), new java.io.File("tmp2"))
The compiler now complains that there’s no implicit value for FileLike [java.io.File]. This is the error message provided if we attempt to use a type that doesn’t have a corresponding type trait in the implicit scope. The error message isn’t quite what we want, and may be improved later, but it’s important to understand what this message means.
The synchronize method requires a type trait implementation for java.io.File. The conventional way to provide default implicit values for a set of types is through a companion object to the type class trait. Let’s look at the following listing:
As of Scala 2.8.1, type classes may be annotated to provide different error messages if the implicit lookup fails. Here’s an example for a Serializable type class:
scala> @annotation.implicitNotFound(msg =
| "Cannot find Serializable type class for ${T}")
| trait Serializable[T]
defined trait Serializable
scala> def foo[X : Serializable](x : X) = x
foo: [X](x: X)(implicit evidence$1: Serializable[X])X
scala> foo(5)
<console>:11: error: Cannot find Serializable type class for Int foo(5) ^
Listing 7.9. Creating default type class implementation for java.io.File
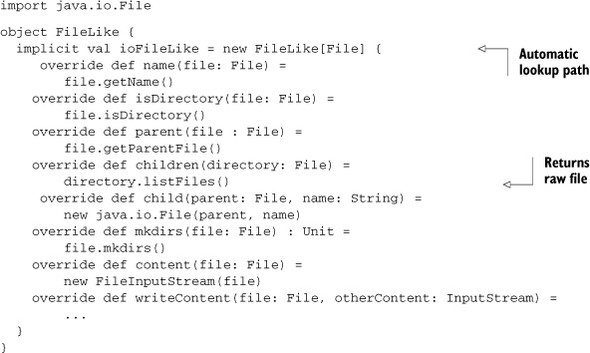
Notice that this implementation of FileLike is simple. Most methods delegate directly to the underlying implementation. The writeClient method is more complex, so you can find the implementation in the source for this book. Now that the implicit FileLike[java.io.File] value is in the FileLike companion object, anytime the compiler needs to find an implicit value of type FileLike[java.io.File], it’ll find one. Remember that the companion object is one of the last places checked for implicit values. This means a user can override the default implementation of Filelike[java.io.File] with their own by importing/defining it at the correct location. The type class pattern also provides many benefits.
7.3.2. The benefits of type classes
Type classes provide you with four primary benefits:
- Separation of abstractions— Type classes create new abstractions and allow other types to adapt, or be adapted, to the abstraction. This is helpful when creating an abstraction that works with preexisting types, and those types can’t be changed.
- Composability— You can use the context bound syntax to specify multiple types. This means you can easily require the existence of several type classes when writing your methods. This is far more flexible than expected for some abstract interface, or a combination of abstract interfaces. Type classes can also use inheritance to compose two type classes together into one implicit variable that provides both. Sometimes this may make sense, but in general type classes retain the most flexibility by avoiding inheritance.
- Overridable— Type classes allow you to override a default implementation through the implicit system. By putting an implicit value higher in the lookup chain, you can completely replace how a type class is implemented. This can be helpful when providing several type classes with various behaviors because the user can select a nondefault type class when needed.
- Type safety— You could use several mechanisms, such as reflection, instead of type classes. The primary reason to prefer type classes over these methods is the guaranteed type safety. When requiring a specific behavior using a type class, the compiler will warn if that behavior isn’t found, or isn’t yet implemented. Although reflection could be used to find methods on any class and call them, its failure occurs at runtime and isn’t guaranteed to occur during testing.
Type classes are a powerful design tool and can greatly improve the composability and reusability of methods and abstractions. These abstractions can also compose into higher-level type classes that are combinations of the lower-level ones.
Here’s an example:
trait Serializable[T] { ... }
object Serializable {
implicit def tuple2[T,V](implicit t : Serializable[T],
v : Serializable[V]) =
new Serializable[(T,V)] { .. }
}
The Serializable type class is defined such that it can serialize a given type T. A Serializable type class for Tuple2 values can be constructed using the Serializable type class against the types of the Tuple2. The method Tuple2 accepts two type parameters, T and V, as well as implicit Serializable type classes associated with these parameters. The Tuple2 method returns a Serializable type class for (T,V) tuples. Now any Tuple2 of types that support the Serializable type class also supports the Serializable class.
Type classes start to show some of the power and complex constraints that can be encoded into the type system. This can be further extended to encode significantly complex type dependent algorithms and type level programming.
7.4. Conditional execution using the type system
There comes a time in an algorithm’s life when it needs to do something rather clever. This clever behavior encodes portions of the algorithm into the type system so that it can execute at compile time. An example of this could be a sort algorithm. The sort algorithm can be written against the raw Iterator interface. But if I call sort against a vector, then I’d like to be able to utilize vector’s natural array separation in my sorting algorithm. Traditionally this has been solved with two mechanisms: overloading and overriding.
Using overloading, the sort method is implemented in terms of Iterable and another is implemented in terms of Vector. The downside to overloading is that it prevents you from using named/default parameters, and it can suffer at compile time due to type erasure.
Type Erasure
Type erasure refers to the runtime encoding of parameterized classes in Scala. The types used in parameters are erased at runtime into a lower type. This means that functions that operate on parameterized types can erase to the same bytecode on the JVM causing conflict. For example:
def sum(x : List[Int]) : Unit
and
def sum(x : List[Double]) : Unit
have the same runtime encoding def sum(x : List[_]) : Unit. The compiler will complain that the overloading isn’t allowed. This is one of the reasons to avoid overloading in Scala.
Using overriding, the sort method is implemented against a base class. Each subclass that wishes to specialize the sort method should override the base class implementation with its own custom sort mechanism. In the case of Iterable and Vector, both would need to define the same sort method. The downside to overriding is that the type signatures must be the same and there must be an inheritance relationship between the classes owning a method.
Overriding seems like a better option than overloading but imposes some strict limitations, especially the inheritance relationship. The inheritance restriction prevents external methods from using overriding behavior, limiting them to overloading and its drawbacks.
The solution is to use the implicit system to associate a type class with the external types. For the sort method, it can be modified to accept an implicit parameter of type Sorter, where the Sorter class contains all the sort logic, as follows:
trait Sorter[A,B] {
def sort(a : A) : B
}
def sort[A,B](col: A)(implicit val sorter: Sorter[A,B]) =
sorter.sort(col)
The Sorter class is defined with a single method sort. The sort method accepts a value of type A and returns type B. It’s assumed that A and B are collections types. The sort method is constructed such that it accepts a collection of type A and an implicit Sorter object and sorts the collection.
The sort algorithm selection has been turned into a type system problem. Each algorithm has been converted into a type and the selection has been encoded into the implicit system. This premise can be generalized to encode other types of problems into the type system.
It’s simple to encode conditional logic into the type system. This can be done by encoding Boolean types into the type system.
sealed trait TBool {
type If[TrueType <: Up, FalseType <: Up, Up] <: Up
}
The TBool trait is defined having one type constructor If. This type constructor can be considered a method working inside the type system with types as its arguments and types as its results. The If type constructor takes three arguments: the type to return if the TBool is true, the type to return if the TBool is false, and an upper bound for the return values. Now let’s encode the true and false types into the type system.
class TTrue extends TBool {
type If[TrueType <: Up, FalseType <: Up, Up] = TrueType
}
class TFalse extends TBool {
type If[TrueType <: Up, FalseType <: Up, Up] = FalseType
}
The TTrue type represents true in the type system. Its If type constructor is overridden to return the first type passed in. The TFalse type represents false in the system. Its If type constructor is overridden to return the second type passed in. Let’s use these types:
scala> type X[T <: TBool] = T#If[String, Int, Any]
defined type alias X
scala> val x : X[TTrue] = 5
<console>:11: error: type mismatch;
found : Int(5)
required: X[booleans.TTrue]
val x : X[TTrue] = 5
^
scala> val x : X[TTrue] = "Hi"
x: X[booleans.TTrue] = Hi
The X type constructor is created to accept an encoding Boolean type and return either the type String or the type Int. In the next line, the value x is defined with a type of X[TTrue], but because the X type constructor is designed to return the type String when passed the TTrue type, compilation fails because the value is of type Int. The next definition of x succeeds because the X type constructor evaluates to String and the value is of type String.
This mechanism of encoding logic into the type system can be useful at times. One example is heterogeneous lists.
7.4.1. Heterogeneous typed list
One feature that’s lacking in the Scala standard library but that’s available in the Meta-Scala library is a heterogeneous typed list—that is, a type-safe list of values with unbounded size. This is similar to Scala’s TupleN classes, except that a heterogeneous typed list supports append operations to grow the list with additional types. The key to a type-safe list is encoding all the types of the list into the type system and preserving them throughout the usage of the list.
Here’s an example of a heterogeneous list instantiation:
scala> val x = "Hello" :: 5 :: false :: HNil x: HCons[java.lang.String,HCons[Int,HCons[Boolean,HNil]]] = Hello :: 5 :: false :: Nil
The preceding line constructs a heterogeneous list comprising of a string, an integer, and a Boolean value. HNil is considered the terminating point of the list, similar to Nil for scala.immutable.List. The return type is interesting. It contains each of the types in the list embedded within HCons types, ending with HNil. The structure of the heterogeneous list is shown in the type. It’s a linked list of cons cells, holding a single value type and the rest of the list. There’s a special list called HNil, which represents the termination of a list or an empty list.
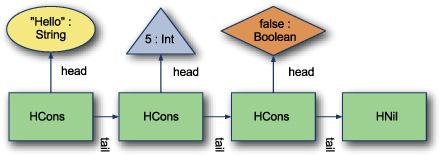
Figure 7.1 is of the heterogeneous list "Hello" :: 5 :: false :: Nil. The HCons rectangles represent each instance of HCons. The HCons cells are links in the linked list. They also carry around the current type of the head and the remaining type of the list. HCons is a linked list both in physical memory and in the type system. The HNil type represents the termination of the list and is similar to using Nil to terminate reference/pointer based linked lists. HNil will also represent empty in the type system.
Figure 7.1. Sample heterogeneous list
Type Level Programming
The key to writing programs that partially execute within the type system is to encode all the required information into the type system. This is the same for creating if/else type constructs or heterogeneous lists.
Let’s look at the implementation:
Listing 7.10. Basic HList implementation

This HList trait is a marker trait for constructing HLists. The HCons type encodes a link in a linked list. The value for the head is parameterized and can be any type. The tail is another HList but is parameterized as T. This is how the type system can capture the complete types of the heterogeneous list. The types are encoded in a linked list of HCons types as the values are stored in a linked list of HCons values. The HNil class also extends HList and represents an empty list or the end of list. Finally, the object HList is used to provide convenience aliases for the HCons and HNil types.
Why the Duplicated :: Method?
You may be wondering why, in the simple HList implementation, the :: method is defined in both the HCons and HNil classes with the same definition. The answer is the full type of the list is required when constructing a new HCons cell. If you placed this definition on HList, the captured type T in any new HCons cell would always be only HList. This negates the desired effect of preserving the type information in the list. The source code we include in this book, and describe later, has a solution to the problem by using a secondary trait, HListLike[FullListType], that captures the complete type of the current list and defines the :: method using this type.
The :: and HNil types are encoded as a class with corresponding value because they must be used in type signatures and expressions. The class types allow them to be directly referenced in type signatures, and the values allow them to be used as expressions. Let’s look at an example:
scala> val x : ( String :: Int :: Boolean :: HNil) =
"Hi" :: 5 :: false :: HNil
x: HList.::[String,HList.::[Int,HList.::[Boolean,HNil]]] =
Hi :: 5 :: false :: Nil
The val x is defined with type String :: Int :: Boolean :: HNil and the expression "Hi" :: 5 :: false :: HNil. If we made HNil an object, the type would instead be String :: Int :: Boolean :: HNil.type.
The HCons class was defined as a case class. Combined with the HNil value, this enables us to extract typed values from a list using pattern matching. Let’s pull the values out of the x list constructed earlier:
scala> val one :: two :: three :: HNil = x one: java.lang.String = Hi two: Int = 5 three: Boolean = false
The first line is a pattern match value assignment from list x. The resulting types of one, two, and three are String, Int, and Boolean respectively, and the values are extracted correctly. You can also use this extraction to pull out portions of the list; for example, let’s pull the first two elements from the x list:
scala> val first :: second :: rest = x first: String = Hi second: Int = 5 rest: HList.::[Boolean,HNil] = false :: Nil
This line extracts the first and second value into variables called first and second. The rest of the list is placed into a variable called rest. Notice the types of each: first and second have the correct types from the portion of the list, and the rest variables is of type ::[Boolean,HNil] or Boolean :: HNil. This mechanism of extracting typed values from the list is handy, but it’d be nice to have an indexing operation.
The indexing operation can be encoded directly into the type system using functions. Let’s take a look at the following listing:
scala> def indexAt2of3[A,B,C]( x : (A :: B :: C :: HNil)) =
| x match {
| case a :: b :: c :: HNil => b
| }
indexAt2of3: [A,B,C](x: HList.::[A,HList.::[B,HList.::[C,HNil]]])B
scala> indexAt2of3( 1 :: false :: "Hi" :: HNil )
res5: Boolean = false
The indexAt2of3 method takes a heterogeneous list of three elements and returns the second element. The next call shows that the method works and will infer the types from the heterogeneous list.
This direct encoding of indexing operations is less than ideal. An explosion of methods is required to index elements into lists of various sizes. The heterogeneous list would also have support methods like insert into index and remove from index. These operations would have to be duplicated if we used this style of direct encoding. Instead, let’s construct a general solution to the problem.
7.4.2. IndexedView
Let’s construct a type that looks at a particular index and can perform various operations like adding, retrieving, or removing the element at the index. This type is called an IndexedView as it represents a view of the heterogeneous list at a given index into the list. To be able to append or remove elements from the list, the view must have access to the types preceding the current index and the types after the current index. The basic trait looks like this:
Listing 7.11. IndexedView
sealed trait IndexedView {
type Before <: HList
type After <: HList
type At
def fold[R](f : (Before, At, After) => R) : R
def get = fold( (_, value, _) => value)
}
The IndexedView trait defines three abstract types. Before is the types of all the elements in the list before the current index. After is the types of all elements in the list after the current index. At is the type at the current index of the list. The IndexedView trait defines two operations: fold and get. Fold is used to look at the entire list and return a given value. Fold takes a function that will look at the before, at and after portions of the list. This allows us to use fold to perform operations centered at this current index.
The get method is implemented in terms of fold to return the value at the current index.
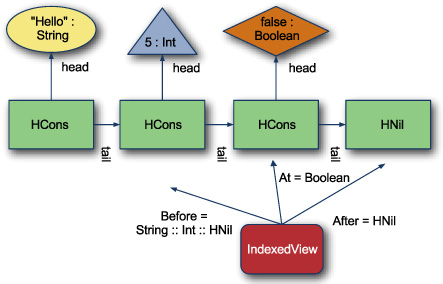
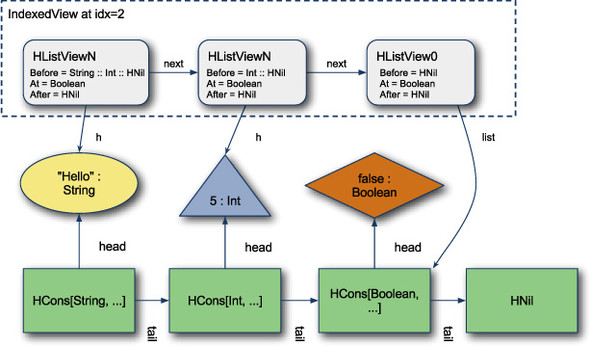
Figure 7.2 shows the IndexedView at the third index of heterogeneous list "Hello" :: 5 :: false :: Nil. At this index, the Before type would be String :: Int ::HNil. Notice that the Before type isn’t exactly the same as the previous HCons cell, because it’s terminated with HNil after the previous two types. The important aspect of the IndexedView is that it gives us direct access to the type of the current value—that is, we can name the current type using the type parameter At. It also preserves the types preceding and following the current type such that we can use them with aggregate functions.
Figure 7.2. IndexedView
Constructing an IndexedView at an index in the list is done recursively. Let’s start with the base case of defining an IndexedView at the first index of a list.
class HListView0[H, T <: HList](val list : H :: T)
extends IndexedView {
type Before = HNil
type After = T
type At = H
def fold[R](f : (Before, At, After) => R): R =
f(HNil, list.head, list.tail)
}
We can use the fold operation on IndexedView to implement many methods that need an index, including remove, append, and split. These methods require a join operation to join two heterogeneous lists. If this join method was called :::, similar to normal list joins, we could implement these methods on IndexedView as:
def remove = fold {
(before, _, after) => before ::: after
}
def insertBefore[B](x : B) = fold {
(before, current, after) =>
before ::: (x :: current :: after)
}
def replace[B](x : B) = fold {
(before, _, after) => before ::: (x :: after)
}
def insertAfter[B](x : B) = fold {
(before, current, after) => before ::: (current :: x :: after)
}
The ::: method isn’t covered in this book and left as an exercise for the reader. For implementation help, see the Meta-Scala library at http://mng.bz/Zw9w.
The class HListView0 accepts a list of head type H and a tail type of T. The Before type is an empty list, as there are no elements before for the first index. The After type is the same as the captured type of the list’s tail, T. The At type is the type of the current head of the list, H. The fold method is implemented such that it calls the function f with an empty list, the head and the tail of the list.
The next case of IndexedView is the recursive case. Let’s create an instance of IndexedView that delegates to another IndexedView. The idea is that for index N, there are N-1 classes that deconstruct the HList’s type to the point where the HListView0 class can be used. Let’s call this recursive class HListViewN.
final class HListViewN[H, NextIdxView <: IndexedView](
h : H, next : NextIdxView) extends IndexedView {
type Before = H :: NextIdxView#Before
type At = NextIdxView#At
type After = NextIdxView#After
def fold[R](f : (Before, At, After) => R) : R =
next.fold( (before, at, after) =>
f(HCons(h, before), at, after) )
}
The HListViewN class has two type parameters: H and NextIdxView. H is the type at the current head of the list. NextIdxView is the type of the next IndexedView class used to construct an IndexedView. The Before type is the current type parameter H appended to the next indexer’s HList. The At type is deferred to the next indexer. The After type is also deferred to the next indexer. The side effect of this is that the At and After types will be determined by an HListView0 and carried down the recursive chain by the HListViewN classes. Finally, the fold operation calls fold on the next IndexedView and wraps the before list with the current value. The HListViewN expands the previous types of an IndexedView.
Figure 7.3 shows the recursive nature of HListViewN. To construct an IndexedView at the third element of an HList requires two HListViewN classes linked to an HListView0 class. The HListView0 class points directly at the cons cell, which holds the third element of the HList. Each instance of the HListViewN class appends one of the previous types of the list to the original HListView0 class. The outer HListViewN class holds the correct types for an IndexedView of the original list at element 2.
Figure 7.3. Recursive HListViewN
One important piece to mention about the HListViewN classes is that they retain references to the elements of the list and recursively rebuild portions of the list in their fold method. You can see this in the diagram with the arrows labeled “h”. The runtime performance implications are that the farther down a list an index goes, the more recursion required to perform operations.
Now that there’s a mechanism to construct IndexedView classes at arbitrary depths of the HList, there must be a method of constructing these classes. Let’s split this process into two. The first will be a mechanism that takes a list and builds a type for the view at index N of that list. The second mechanism is a way of constructing the recursive IndexedView types if the final type is known.
For the first mechanism, let’s add a type to the HList class that will construct an IndexedView at a given index value for the current list.
sealed trait HList {
type ViewAt[Idx <: Nat] <: IndexedView
}
The ViewAt type constructor is defined as constructing a subclass of IndexedView. The full value will be assigned in the HCons and HNil classes respectively. The ViewAt type constructor takes a parameter of type Nat. Nat is a type that we create for this purpose representing natural numbers encoded into the type system. Nat is constructed the same way naturally numbers are constructed in mathematical proofs, by building from a starting point.
Listing 7.12. Natural numbers encoded into types

The trait Nat is used to mark natural number types. The trait _0 is used to denote the starting point for all natural numbers, zero. The Succ trait isn’t directly referenced but is used to construct the rest of the natural number set (or at least as many as we wish to type). The types _1 through _22 are then defined using the Succ trait applied to the previously defined type.
The Nat types _0 through _22 can now be used to denote indexes into an HList. The next step is to use these index values to construct the IndexedView type for an HList at that index. To do so, let’s construct a mechanism to pass type lambdas into natural numbers and build complete types.
sealed trait Nat {
type Expand[NonZero[N <: Nat] <: Up, IfZero <: Up, Up] <: Up
}
The Nat trait is given a new type called Expand. Expand takes three type parameters. The first is a type lambda that’s applied against the previous natural number if the Nat isn’t _0. The second is the type returned if the natural number is _0. The third type is an upper bound for the first two types to avoid compilation type inference issues. Let’s implement this type on the _0 and Succ traits:
sealed trait _0 extends Nat {
type Expand[NonZero[N <: Nat] <: Ret, IfZero <: Ret, Ret] =
IfZero
}
sealed trait Succ[Prev <: Nat] extends Nat {
type Expand[NonZero[N <: Nat] <: Ret, IfZero <: Ret, Ret] =
NonZero[Prev]
}
The _0 trait defines its Expand type to be exactly the second parameter. This is similar to a method call that returns its second parameter. The Succ trait defines its expand method to call the type constructor passed into the first parameter against the previous Nat type. This can be used to recursively build a type by providing a type that uses itself in the NonZero type attribute. Let’s use this trick and define the ViewAt type on HList.

The ViewAt type is defined as an expansion against the natural number parameter N. The first type parameter to Expand is the recursive type constructor. This type constructor is defined as HListViewN[H, T#ViewAt[P]]. Deconstructing, the type is an HListViewN comprised of the current head type and the tail’s ViewAt type applied to the previous natural number (or N-1). Eventually, there will be a ViewAt called for _0 that will return the second parameter, HListView0[H,T]. If a Nat index is passed into the ViewAt type that goes beyond the size of the list, it will fail at compile time with the following message:
scala> val x = 5 :: "Hi" :: true :: HNil
x: HCons[Int,HCons[java.lang.String,HCons[Boolean,HNil]]] =
5 :: Hi :: true :: HNil
scala> type X = x.ViewAt[Nat._11]
<console>:11: error: illegal cyclic reference involving type ViewAt
type X = x.ViewAt[Nat._11]
The compiler will issue an illegal cyclic reference in this instance. Although not exactly the error message desired in this situation, the compiler prevents the invalid index operation.
Now that the indexed type can be constructed for a given index and a given HList, let’s encode the construction of the IndexedView into the implicit system. We can do this with a recursive implicit lookup against the constructed IndexedView type.
object IndexedView {
implicit def index0[H, T <: HList](list : H :: T) : HListView0[H,T] =
new HListView0[H,T](list)
implicit def indexN[H, T <: HList, Prev <: IndexedView](
list: (H :: T))(
implicit indexTail: T => Prev): HListViewN[H,Prev] =
new HListViewN[H, Prev](list.head, indexTail(list.tail))
}
The IndexedView companion object is given two implicit functions: index0 and indexN. The function index0 takes an HList and constructs an indexed view of index_0 on that list. The function indexN takes an HList and an implicit conversion of the tail of the HList into an IndexedView and returns a new IndexedView of the complete list. The type parameters on indexN preserve the types of the head and tail of the list as well as the full type of the IndexedView used against the tail of the list.
Now when the compiler looks for a type Function1[Int :: Boolean :: Nil, HListViewN[Int, HListView0[Boolean, HNil]]], the indexN function will be called with H = Int and T = Boolean :: HNil and Prev = ?. The compiler will then look for an implicit Function1[Boolean :: Nil, ? <: IndexedView]. This is satisfied by the index0 implicit, and the Prev type is filled in as HListView0[Boolean, HNil]. The full implicit value is found, and a constructor of an IndexedView from a HList is available. Now let’s write the indexing method itself:
trait HCons[H, T <: HList] extends HList {
type FullType = HCons[H,T]
def viewAt[Idx <: Nat](
implicit in: FullType => FullType#ViewAt[Idx]) =
in(this.asInstanceOf[FullType])
...
}
The viewAt method is defined as taking a type parameter of the Nat index and an implicit function that constructs the IndexedView from the current list. Now the heterogeneous lists support indexing.
scala> val x = 5 :: "Hi" :: true :: HNil
x: HCons[Int,HCons[java.lang.String,HCons[Boolean,HNil]]] =
5 :: Hi :: true :: HNil
scala> x.viewAt[Nat._1].get
res3: java.lang.String = Hi
The first line in the example constructs a heterogeneous list and the second shows how to use a natural number to index into the list (assuming _0 is the first element of the list).
The heterogeneous list demonstrates the power of Scala’s type system. It encodes an arbitrary sequence of types and allows type-safe indexing of this sequence. Most type-level programming problems within Scala can be handled using the mechanisms seen with heterogeneous lists, in particular:
- Divide and Conquer: Use recursion to loop over types
- Encode Boolean and integer logic into types
- Use implicit lookup to construct recursive types or return types
This type-level programming is the most advanced usage of the Scala type system that may be required for general development. The simple build tool (SBT) is used to build Scala code that utilizes a different form of the HList presented earlier. Although HLists are complicated, the SBT tool introduces them in a way that’s simple and elegant for the user. It’s worth going to http://mng.bz/Cdgl and reading how they’re used.
7.5. Summary
In this chapter, you learned the advanced techniques for utilizing Scala’s type system. Implicits allow the capturing of runtime and compile time type constraints. You can use type classes as a general purpose abstraction to associate types with functionality. They are one of the most powerful forms of abstraction within Scala. Finally, we explored in depth the conditional execution and type level programming. This advanced technique tends to be used in core libraries and not as much in user code.
The main theme in all of these sections is that Scala allows developers to preserve type information while writing low-level generic functions. The more type information that can be preserved, the more errors the compiler can catch. For example, the synchronize method defined in section 7.3 was able to prevent accidental argument reversal by capturing the from and to types. The HList class allows developers to create arbitrarily long typed lists of elements that can be modified directly rather than passing around a List[Any] and having to determine the types of each element at runtime. This also prevents users from placing the wrong type at a given index.
Writing low-level generic functions is also important. The less a method or class assumes about its arguments or types, the more flexible it is and the more often it can be reused. In section 7.2, the implicit available of the <:< class was used to add a convenience method directly on the Set class.
The next chapter covers the Scala collections library, and we make heavy use of the concepts defined in this chapter. In particular, the collections library attempts to return the most specific collection type possible after any method call. This has some interesting consequences, as you’ll see.