
Chapter 9. Actors
Actors are an abstraction on a synchronous processes. They communicate to the external world by sending and receiving messages. An actor will process received messages sequentially in the order they’re received, but will handle only one message at a time. This is critical, because it means that actors can maintain state without explicit locks. Actors can also be asynchronous or synchronous. Most actors won’t block a thread when waiting for messages, although this can be done if desired. The default behavior for actors is to share threads among each other when handling messages. This means a small set of threads could support a large number of actors, given the right behavior.
In fact, actors are great state machines. They accept a limited number of input messages and update their internal state. All communication is done through messages and each actor stands alone.
But actors won’t solve all issues your system faces. You have to know how to use them.
9.1. Know when to use actors
Actors aren’t parallelization factories; they process their messages in single-threaded fashion. They work best when work is conceptually split and each actor can handle a portion of the work. If the application needs to farm many similar tasks out for processing, this requires a large pool of actors to see any concurrency benefits.
Actors and I/O should be interleaved carefully. Asynchronous I/O and actors are a natural pairing, as the execution models for these are similar. Using an actor to perform blocking I/O is asking for trouble. That actor can starve other actors during this processing. This can be mitigated, as we’ll discuss in section 9.4.
Although many problems can be successfully modeled in actors, some will benefit more. The architecture of a system designed to use actors will also change fundamentally. Rather than relying on classic Model-View-Controller and client-based parallelism, an actors system parallelizes pieces of the architecture and performs all communication asynchronously.
Let’s look at a canonical example of a good system design using actors. This example uses several tools found in the old Message Passing Interface (MPI) specification used in supercomputing. MPI is worth a look, as it holds a lot of concepts that have naturally translated into actor-based systems.
9.1.1. Using actors to search
Let’s design a classic search program. This program has a set of documents that live in some kind of search index. Queries are accepted from users and the index is searched. Documents are scored and the highest scored documents are returned to the users. To optimize the query time, a scatter-gather approach is used.
The scatter-gather approach involves two phases of the query: scatter and gather (see figure 9.1).
Figure 9.1. Scatter phase
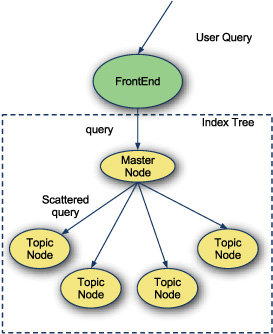
The first phase, scatter, is when the query is farmed out to a set of subnodes. Classically, these subnodes are divided topically and store documents about their topic. These nodes are responsible for finding relevant documents for the query and returning the results, as shown in figure 9.2.
Figure 9.2. Gather phase
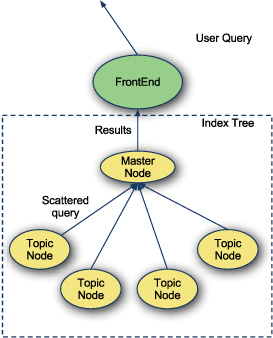
The second phase, gather, is when all the topic nodes respond to the main node with their results. These are pruned and returned for the entire query.
Let’s start by creating a SearchQuery message that can be sent among the actors.
case class SearchQuery(query : String, maxResults : Int)
The SearchQuery class has two parameters. The first is the actual query, and the second is the maximum number of results that should be returned. We’ll implement one of the topic nodes to handle this message.
trait SearchNode extends Actor {
type ScoredDocument = (Double, String)
val index : HashMap[String, Seq[ScoredDocument]] = ...
override def act = Actor.loop {
react {
case SearchQuery(query, maxResults) =>
reply index.get(query).getOrElse(Seq()).take(maxResults)
}
}
}
The Search node defines the type Scored Document to be a tuple of a double score and a string document. The index is defined as a HashMap of a query string to scored documents. The index is implemented such that it pulls in a different set of values for each SearchNode created. The full implementation of the index is included in the source code for the book.
The act method on SearchNode contains its core behavior. When it receives a SearchQuery message, it looks for results in its index. It replies to the sender of the SearchQuery all of these results in a truncated manner so that only maxResults are returned.
React Versus Receive
The SearchNode actor uses the react method for accepting messages. The actors library also supports a receive method. These methods differ in that react will defer the execution of the actor until there is a message available. The receive method will block the current thread until a message is available. Unless absolutely necessary, receive should be avoided to improve the parallelism in the system.
Now let’s implement the HeadNode actor that’s responsible for scattering queries and gathering results.
trait HeadNode extends Actor {
val nodes : Seq[SearchNode] = ...
override def act = Actor.loop {
react {
case s @ SearchQuery(_, maxResults) =>
val futureResults = nodes map (n => n !! s)
def combineResults(current : Seq[(Double, String)],
next : Seq[(Double, String)]) =
(current ++ next).view sortBy (_._1) take maxResults force
reply futureResults.foldLeft(Seq[ScoredDocument]()) {
(current, next) =>
combineResults(current,
next().asInstanceOf[Seq[ScoredDocument])
}
}
}
}
The HeadNode actor is a bit more complicated. It defines a member containing all the SearchNodes that it can scatter to. It then defines its core behavior in the act method. The HeadNode waits for SearchQuery messages. When it receives one, it sends it to all the SearchNode children awaiting a future result. The !! method on actors will send a message and expect a reply at some future time. This reply is called a Future. The HeadNode can block until the reply is received by calling the apply method on the Future. This is exactly what it does in the foldLeft over these futures. The HeadNode is aggregating the next future result with the current query results result to produce the final result list. This final result list is sent to the original query sender using the reply method.
Using View to Combine Results
In the example the view and force methods are used around a set of collection methods. Although they offer no benefit for the sortBy method, in practice the take method is usually used, and the view and force methods can help improve efficiency by avoiding the creation of intermediate collections.
The system now has a scatter-gather search tree for optimal searching. But there’s still a lot to be desired. The casting of the result type in the HeadNode actor is less than ideal in a statically typed language like Scala. Also, the HeadNode blocks for an entire SearchQuery. This means that the amount of parallelism in the system could be expanded so that slow-running queries don’t starve faster queries. Finally, the search tree has no failure handling. If a bad index or query string occurs, the whole system will crash.
Actors can improve these downsides. Let’s start with fixing the type-safety issues.
9.2. Use typed, transparent references
One of the biggest dangers in the Scala standard actors library is to give actors references to each other. This can lead to accidentally calling a method defined on another actor instead of sending a message to that actor. Although that may seem innocuous to some, this behavior can break an actors system, especially if you use locking. Actors are optimized by minimizing locking to a few minor locations, such as when scheduling and working with a message buffer. Introducing more locking can easily lead to deadlocks and frustration.
Another disadvantage to passing direct references to actors is transparency, where the location of an actor is tied in to another actor. This locks them in place where they are. The actors can no longer migrate to other locations, either in memory or on the network, severely limiting the system’s ability to handle failure. We’ll discuss this in detail in section 9.3.
Another downside to sending actors directly in the Scala standard library is that actors are untyped. This means that all the handy type system utilities you could leverage are thrown out the window when using raw actors. Specifically, the compiler’s ability to find exhausting pattern matches using sealed traits.
Using Sealed Traits for Message Apis
It’s a best practice in Scala to define message APIs for actors within a sealed trait hierarchy. This has the benefit of defining every message that an actor can handle and keeping them in a central location for easy lookup. With a bit of machinery, the compiler can be coerced to warn when an actor doesn’t handle its complete messaging API.
The Scala standard library provides two mechanisms for enforcing type safety and decoupling references from directly using an actor: the InputChannel and Output-Channel traits.
The OutputChannel trait is used to send messages to actors. This is the interface that should be passed to other actors, and it looks like this:
trait OutputChannel[-Msg] {
def !(msg: Msg @unique): Unit
def send(msg: Msg @unique, replyTo: OutputChannel[Any]): Unit
def forward(msg: Msg @unique): Unit
def receiver: Actor
}
The OutputChannel trait is templatized by the type of messages that can be sent to it. It supports sending messages via three methods: !, send, and forward. The ! method sends a message to an actor and doesn’t expect a reply. The send method sends a message to an actor and attaches an output channel that the actor can respond to. The forward method is used to send a message to another actor such that the original reply channel is preserved.
The receiver method on OutputChannel returns the raw actor used by the Output-Channel. You should avoid this method.
Notice the methods that OutputChannel doesn’t have: !! and !?. In the Scala standard library, !! and !? are used to send messages and expect a reply in the current scope. This is done through the creation of an anonymous actor that can receive the response. This anonymous actor is used as the replyTo argument for a send call. The !? method blocks the current thread until a response is received. The !! method creates a Future object, which stores the result when it occurs. Any attempt to retrieve the result blocks the current thread until the result is available. Futures do provide a map method. This attaches a function that can be run on the value in the future when it’s available without blocking the current thread.
In general, using !! and !? is discouraged. The potential for deadlocking a thread is great. But when used lightly or with caution, these methods can be helpful. It’s important to understand the size and scope of the project and the type of problem being solved. If the problem is too complex to ensure !! and !? behave appropriately, avoid them altogether.
Let’s modify the scatter-gather example to communicate using OutputChannels.
9.2.1. Scatter-Gather with OutputChannel
The scatter-gather example requires two changes to promote lightweight typesafe references: removing the direct Actor references in HeadNode and changing the query responses to go through a collection channel. The first change is simple.
/** The head node for the scatter/gather algorithm. */
trait HeadNode extends Actor {
val nodes : Seq[OutputChannel[SearchNodeMessage]]
override def act : Unit = {
...
}
}
The nodes member of the HeadNode actor is changed to be a Seq[OutputChannel [SearchNodeMessage]]. This change ensures that the HeadNode will only send SearchNodeMessage messages to SearchNodes. The SearchNodeMessage type is a new sealed trait that will contain all messages that can be sent to SearchNodes.
The second change is a bit more involved. Rather than directly responding to the sender of the SearchQuery, let’s allow an output channel to be passed along with the SearchQuery that can receive results.
sealed trait SearchNodeMessage
case class SearchQuery(query : String,
maxDocs : Int,
gatherer : OutputChannel[QueryResponse])
extends SearchNodeMessage
The SearchQuery message now has three parameters: the query, the maximum number of results, and the output channel that will receive the query results. The Search-Query message now extends from the SearchNodeMessage. The new SearchNodeMessage trait is sealed, ensuring that all messages that can be sent to the SearchNode are defined in the same file. Let’s update the SearchNodes to handle the updated SearchQuery message.
trait SearchNode extends Actor {
lazy val index : HashMap[String, Seq[(Double, String)]] = ...
override def act = Actor.loop {
react {
case SearchQuery(q, maxDocs, requester) =>
val result = for {
results <- index.get(q).toList
resultList <- results
} yield resultList
requester ! QueryResponse(result.take(maxDocs))
}
}
}
The SearchNode trait is the same as before except for the last line in the react call. Instead of calling reply with the QueryResponse, the SearchNode sends the response to the requestor parameter of the query.
This new behavior means that the head node can’t just send the same SearchQuery message to the SearchNodes. Let’s rework the communication of the system, as shown in figure 9.3.
Figure 9.3. Modified scatter-gather search
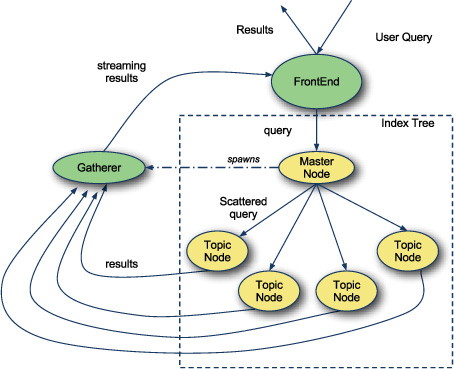
The new design has a Gatherer actor. This actor is responsible for receiving all results from SearchNodes and aggregating them before sending back to the front end. The Gatherer could be implemented in many ways. One advanced implementation could use prediction to stream results to the front end as they’re returned, attempting to ensure high priority results get sent immediately. For now, let’s implement the GathererNode such that it aggregates all results first and sends them to the front end.
trait GathererNode extends Actor {
val maxDocs: Int
val maxResponses: Int
val client: OutputChannel[QueryResponse]
..
}
The GathererNode is defined as an Actor. It has three members. The maxDocs member is the maximum number of documents to return from a query. The maxResponses member is the maximum number of nodes that can respond before sending results for a query. The client member is the OutputChannel where results should be sent. The GathererNode should be tolerant of errors or timeouts in the search tree. To do this, it should wait a maximum of one second for each response before returning the query results. Let’s implement the act method for the GathererNode.
def act = {
def combineResults(current: Seq[(Double, String)],
next: Seq[(Double, String)]) =
(current ++ next).view.sortBy(_._1).take(maxDocs).force
def bundleResult(curCount: Int,
current: Seq[(Double, String)]): Unit =
if (curCount < maxResponses) {
receiveWithin(1000L) {
case QueryResponse(results) =>
bundleResult(curCount+1, combineResults(current, results))
case TIMEOUT =>
bundleResult(maxResponses, current)
}
} else {
client ! QueryResponse(current)
}
bundleResult(0, Seq())
}
The act method defines the core behavior of this actor. The combineResults helper method is used to take two sets of query results and aggregate them such that the highest scored results remain. This method also limits the number of results returned to be the same as the maxDocs member variable.
The bundleResult method is the core behavior of this actor. The curCount parameter is the number of responses seen so far. The current parameter is the aggregate of all collected query results from all nodes. The bundleResult method first checks to see if the number of responses is less than the maximum expected results. If so, it calls receiveWithin to wait for another response. The receiveWithin method will wait for a given time for messages before sending the special scala.actors.TIMEOUT message. If another query result is received, the method combines the result with the previous set of results and recursively calls itself with bumped values. If receiving the message times out, the bundleResult method calls itself with the number of responses set to the maximum value. If the number of responses is at or above the maximum, the current query results are sent to the client.
Finally, the act method is implemented by calling the bundleResult method with an initial count of zero and an empty Seq of results.
The GathererNode stops trying to receive messages after the query results have been sent. This effectively ends the life of the actor and allows the node to become garbage-collected. The Scala standard actors library implements its own garbage collection routine that will have to remove references to the GathererNode before the JVM garbage collection can recover memory.
The last piece of implementation required is to adapt the HeadNode to use the GathererNode instead of collecting all the results in futures.

The HeadNode has been changed so that when it receives a SearchQuery, it constructs a new GathererNode. The gatherer is instantiated using the parameters from the SearchQuery. The gatherer must also be started so that it can receive messages. The last piece is to send a new SearchQuery message to all the SearchNodes with the OutputChannel set to the gatherer.
Splitting the scatter and gather computations into different actors can help with throughput in the whole system. The HeadNode actor only has to deal with incoming messages and do any potential preprocessing of queries before scattering them. The GathererNode can focus on receiving responses from the search tree. A Gatherer node could even be implemented such that it stopped SearchNodes from performing lookups if enough quality results were received. Most importantly, if there’s any kind of error gathering the results of one particular query, it won’t adversely affect any other query in the system.
This is a key design issue with actors. Failures should be isolated as much as possible. This can be done through the creation of failure zones.
9.3. Limit failures to zones
Architecting and rationalizing distributed architecture can be difficult. Joe Armstrong, the creator of Erlang, popularized the notion of actors and how to handle failure. The recommended strategy for working with actors is to let them fail and let another actor, called a supervisor handle that failure. The supervisor is responsible for bringing the system it manages back into a working state.
Looking at supervisors and actors from a topological point of view, supervisors create zones of failure for the actors they manage. The actors in a system can be partitioned by the supervisors such that if one section of the system goes down, the supervisor has a chance to prevent the failure from reaching the rest of the system. Each supervisor actor can itself have a supervisor actor, creating nested zones of failure.
The error handling of supervisors is similar to exception handling. A supervisor should handle any failure that it knows how to, and bubble up those it doesn’t to outer processes. If no supervisor can handle the error, then this would bring down the entire system, so bubbling up errors should be done carefully!
Supervisors can be simpler to write than exception handling code. With exception handling, it’s difficult to know if a try-catch block contained any state-changing code and whether it can be retired. With supervisors, if an actor is misbehaving, it can restart the portion of the system that’s dependent on that actor. Each actor can be passed an initial good state and continue processing messages.
Notice the relationship between the supervisor of an actor and the creator of the actor. If the supervisor needs to recreate an actor upon destruction, the supervisor is also the ideal candidate to start the actor when the system initializes. This allows all the initialization logic to live in the same location. Supervisors may also need to act as proxy to the subsystem they manage. In the event of failure, the supervisor may need to buffer messages to a subsystem until after it has recovered and can begin processing again.
Supervisors are created differently in the various Scala actor libraries. In the core library, supervisors are created through the link method. The Akka actors library provides many default supervisor implementations and mechanisms of wiring actors and supervisors together. One thing that’s common across actor libraries is that supervisors are supported and failure zones are encouraged.
9.3.1. Scatter-Gather failure zones
Let’s adapt the scatter-gather example to include failure zones. The first failure zone should cover the HeadNode and SearchNode actors. Upon failure, the supervisor can reload a failing search node and wire it back into the head node. The second failure zone should cover the FrontEnd actor and the supervisors of the first failure zone. In the event of failure in this outer zone, the supervisor can restart any failed inner zones and inform the front end of the new actors. A topological view of this failure handling is shown in figure 9.4.
Figure 9.4. Failure zones for scatter-gather example

When designing with actors, it’s important to prepare what zones are allowed to fail separately. The system should be designed such that any one zone does not take down the entire application.
Failure Zones 1 and 2 in the diagram show the HeadNode and SearchNode failure zones for two parallel search hierarchies. The supervisor for these zones is responsible for restarting the entire tree, or a particular SearchNode, on failure. Zones 1 and 2 are each encompassed in Zone 3. This zone manages the search on the front end. In the event of failure, it restarts the underlying search trees or the front end as needed.
We’ll start by defining the supervisor for the search nodes:
Listing 9.1. Supervisor for search nodes

The SearchNodeSupervisor contains two methods: createSearchTree and act. The create-SearchTree is responsible for instantiating nodes of the search tree and returning the top node. This method iterates over the desired size of the tree and creates the SearchNode class from the previous examples. Remember that each SearchNode uses its assigned ID to load a set of indexed documents and make them available for queries. Each search node created is linked to the supervisor. In the Scala standard library actors, linking is what creates a supervisor hierarchy. Linking two actors means that if one fails, both are killed. It also allows one of them to trap errors from the other. This is done from the call to trapExit = true in the act method.
The link method has two restrictions that simplify its use.
- It must be called from inside a live actor—that is, from the act method or one of the continuations passed to react.
- It should be called on the supervisor with the other actor as the method argument.
Because link alters the behavior of failure handling, it needs to lock both actors it operates against. Because of this synchronization, it’s possible to deadlock when waiting for locks. Ordering the locking behavior can prevent this behavior. The link method also requires, through runtime asserts, that it’s called against the current live actor. The actor must be actively running in its scheduled thread. This means linking should be done internal to the supervisor actor. This is why all the topological code is pushed down into the supervisor and why it acts as a natural proxy to the actors it manages.
The second method is the standard library actor’s act method. This defines the core behavior of the supervisor actor. The first line here is the trapExit = true, which allows this actor to catch errors from others. The next line is a helper function called run, which accepts one parameter, the current head actor, and calls react, which will block waiting for messages. The first message it handles is the special Exit message. An Exit message is passed if one of the linked actors fails. Notice the values that come with an Exit message: deadActor and reason. The deadActor link allows the supervisor to attempt to pull any partial state from the deadActor if needed, or remove it from any control structures as needed. Note that the deadActor is already gone and won’t be scheduled anymore at the time of receiving this message.
For the SearchNodeSupervisor, when handling errors, the entire search tree is reconstructed and passed back into the run method. This may not be ideal in a real-life situation because reconstructing the entire tree could be expensive or the tree might be sprawled over several machines. In that case, the SearchNodeSupervisor could restart the failed node and notify the search tree of the replacement.
If the SearchNodeSupervisor encounters any other message, it’s forwarded to the current HeadNode. This means that the supervisor can block incoming messages when restarting the system. When the main node crashes, the supervisor receives the Exit message and stops processing messages while it fixes the system. After restoring things, it will again pull messages from its queue and delegate them down to the search tree.
9.3.2. General failure handling practices
The supervisor for the scatter-gather search system demonstrates ways to handle the issues of failure in an actors system. When designing an actors-based system and outlining failure zones, table 9.1 helps make decisions appropriate for that module.
Table 9.1. Actor design decisions
|
Decision |
Scatter-Gather example |
Other options |
|---|---|---|
| Providing transparent way to restart failed components | Forward messages through the supervisor. If supervisor fails, restart outer failure zone. | Update name service with references to actors. Directly communicate new location to connected components. |
| Granularity of failure zones | The entire search tree fails and restarts. | Single Search node inner failure zone with Search Tree outer failure zone. |
| Recovery of failed actor state | Actor data is statically pulled from disk. Doesn’t change during its lifetime. | Periodic snapshotting to persistent store Pulling live state from dead actor and sanitizing Persisting state after every handled message |
These three decisions are crucial in defining robust concurrent actor systems. The first point is the most important. Creating a fail-safe zone implies ensuring that if that zone crashes and restarts, it won’t affect external zones. The Scala actors library makes it easy to lose transparency for actors. This can be done by passing the reference to a specific actor rather than a proxy or namespace reference.
The second decision can affect the messaging API for actors. If a subsystem needs to tolerate failure of one of its actors, the other actors need to be updated to communicate with the replacement actor. Again, transparent actor references can be a boon here. For the Scala standard library, using the supervisors as proxies to sub-components is the simplest way to provide transparency. This means that for fine-grained failure zones, many supervisors must be created, possibly one per actor.
The third decision is one not discussed in the example—that of state recovery. Most real-life actors maintain some form of state during their lifetimes. This state may or may not need to be reconstructed for the system to continue functioning. Although not directly supported in the Scala standard library, one way to ensure state sticks around is to periodically snapshot the actor by dumping its state to a persistent store. This could then be recovered later.
A second method of keeping state would be to pull the last known state from a dead actor and sanitize it for the reconstructed actor. This method is risky, as the state of a previous actor isn’t in a consistent state and the sanitization process may not be able to recover. The sanitization process could also be hard to reason through and write. This mechanism isn’t recommended.
Another mechanism for handling state is to persist the state after every message an actor receives. Although not directly supported by the Scala standard library, this could easily be added through a subclass of actor.
Akka Transactors
The Akka actors library provides many ways to synchronize the state of live actors, one of which is transactors. Transactors are actors whose message handling functions are executed within a transactional context.
One item not on this list is threading strategies. Because actors share threads, an actor that fails to handle its incoming messages could ruin the performance of other actors that share the same threading resources. The solution to this is to split actors into scheduling zones, similar to splitting them into failure zones.
9.4. Limit overload using scheduler zones
One type of failure that a supervisor can’t handle well is thread starvation of actors. If one actor is receiving a lot of messages and spending a lot of CPU time processing them, it can starve other actors. The actor schedulers also don’t have any notion of priority. Maybe a high-priority actor in the system must respond as quickly as possible, and could get bogged down by lower priority actors stealing all the resources.
Schedulers are the solution to this problem. A scheduler is the component responsible for sharing actors among threads. The scheduler selects the next actor to run and assigns it to a particular thread. In the Scala actors library, a scheduler implements the IScheduler interface.
A variety of scheduling mechanisms are available for the standard library actors, as shown in table 9.2.
Table 9.2. Schedulers
|
Scheduler |
Purpose |
|---|---|
| ForkJoinScheduler | Parallelization optimized for tasks that are split up, parallelized, and recovered—that is, things that are forked for processing, then joined together. |
| ResizableThreadPoolScheduler | Starts up a persistent thread pool for actors. If load is increased, it’ll automatically create new threads up to an environment-specified limit. |
| ExecutorScheduler | Uses a java.util.concurrent.Executor to schedule actors. This allows actors to use any of the standard Java thread pools and is the recommended way to assign fixed size thread pool. |
The ForkJoinScheduler is the default scheduler for Scala actors. This is done through a nifty work-stealing algorithm where every thread has its own scheduler. Tasks created in a thread are added to its own scheduler. If a thread runs out of tasks, it steals work from another thread’s scheduler. This provides great performance for a lot of situations. The scatter-gather example is a perfect fit for the fork join parallel executor. Queries are distributed to each SearchNode for executions, and results are aggregated to create the final query results. The work-stealing pulls and distributes the forked work for a query. If the system is bogged down, it could degrade to performing similarly to a single-threaded query engine. Although generally efficient, the ForkJoinScheduler isn’t optimal in situations where task sizes are largely variable.
The ResizableThreadPoolScheduler constructs a pool of threads that share the processing of messages for a set of actors. Scheduling is done on a first-come, firstserve basis. If the workload starts to grow beyond what the current thread pool can handle, the scheduler will increase the available threads in the pool up until a maximum pool size. This can help a system handle a large increase in messaging throughput and back off resources during downtime.
The ExecutorScheduler is a scheduler that defers scheduling actors to a java.util.Executor service. There are many implementations of java.util.Executor in the Java standard library as well as common alternatives. One of these, from my own codebases, was an Executor that would schedule tasks on the Abstract Windows Toolkit (AWT)-rendering thread. Using this scheduler for an actor guarantees that it handles messages within a GUI context. This allowed the creation of GUIs where actors could be used to respond to backend events and update UI state.
Each of these schedulers may be appropriate to one or more components in a system. Some components scheduling may need to be completely isolated from other components. This is why scheduling zones are important.
9.4.1. Scheduling zones
Scheduling zones are groupings of actors that share the same scheduler. Just as failure zones isolate failure recovery, so do scheduling zones isolate starvation and contention of subsystems. Scheduling zones can also optimize the scheduler to the component.
Figure 9.5 shows what a scheduling zone design might be for the scatter-gather example.
Figure 9.5. Scatter-gather scheduling zones
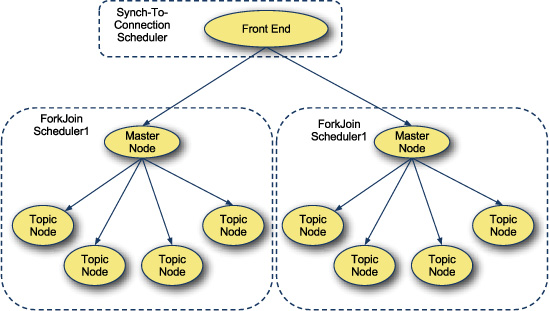
Prevent low-latency services from getting clobbered by low-priority processes using scheduling zones to carve out dedicated resources.
The scatter-gather search service can be split into four scheduling zones: Search Tree 1, Search Tree 2, Front End, and Supervisor.
The first scheduling zone handles all actors in a search tree. The ForkJoin-Scheduler is optimized for the same behavior as the scatter-gather algorithm, so it makes an ideal choice of scheduler for this zone. The replicated Search tree uses its own ForkJoinScheduler to isolate failures and load between the two trees.
The front end scheduling zone uses a customized scheduler that ties its execution to an asynchronous HTTP server; the handling of messages is done on the same thread as input is taken, and the results are streamed back into the appropriate socket using one of the front-end threads. These actors could also use their own thread pool. This would be ideal if the HTTP server accepting incoming connections used a thread pool of the same size.
The last scheduling zone, not shown, is the scheduling of error recovery. Out of habit, I tend to place these on a separate scheduling routine so they don’t interfere with any other subcomponent. This isn’t strictly necessary. Error recovery, when it happens, is the highest priority task for a given subcomponent and shouldn’t steal more important work from other threads. But if more than one subcomponent is sharing the same scheduling zone, then I prefer to keep recovery work separate from core work.
Let’s add scheduling zones to the scatter-gather search tree example. The only changes required are in the constructor function defined on the supervisor, as shown in the following listing:
Listing 9.2. SearchTree factory

The original code has two new additions. The first is the creation of the ForkJoin-Scheduler. This scheduler takes four arguments. The initCoreSize and maxSize arguments are the minimum and maximum number of threads it should store in its thread pool. The daemon argument specifies whether threads should be constructed as daemons. This scheduler can shut itself down if the actors within are no longer performing any work. The last argument is whether or not the scheduler should attempt to enforce fairness in the work-stealing algorithm.
The second additions are the overridden scheduler member of the SearchNode and HeadNode actors. This override causes the actor to use the new scheduler for all of its behavior. It can do this only at creation time, so the scheduling zones must be known a-priori.
The actors are now operating within their own fork-join pool, isolated from load in other actors.
9.5. Dynamic actor topology
One of the huge benefits of using actors is that the topology of your program can change drastically at runtime to handle load or data size. For example, let’s redesign the scatter-gather search tree so that it can accept new documents on the fly and add them to the index. The tree should be able to grow in the event that a specific node gets to be too large. To accomplish this, we can treat an actor as a state machine.
Akka is the most performant actors framework available on the JVM. It’s designed with actor best practices baked into the API. Writing efficient, robust actors systems is simplest in the Akka framework.
The entire scatter-gather tree is composed of two node types: search (leaves) and head (branches). A search node holds an index, like the previous topic nodes. It’s responsible for adding new documents to the index and for returning results to queries. A head node holds the number of children. It’s responsible for delegating queries to all children and setting up a gatherer to aggregate the results.
Using Akka
The following examples will use the Akka actors library. Although the Scala standard library is elegant, the Akka library makes the robust usage of actors easy. Akka builds in the notion of transparent actor references, while providing a good set of useful supervisors and schedulers. Creating failure zones and scheduling zones is much easier in Akka, and the library is standalone. In general, there’s little reason not to use Akka, especially when attempting to design a distributed topology, as shown in the following listing:
Listing 9.3. AdaptiveSearchNode
trait LeafNode { self: AdaptiveSearchNode =>
...
def leafNode: PartialFunction[Any, Unit] = {
case SearchQuery(query, maxDocs, handler) =>
executeLocalQuery(query, maxDocs, handler)
case SearchableDocument(content) =>
addDocumentToLocalIndex(content)
}
...
}
The LeafNode trait is defined with a single PartialFunction[Any,Unit] named leafNode. This function contains the message handling behavior for the adaptive search nodes when the node is a leaf. When the node receives a SearchQuery it executes that query against the local index. When the node receives a Searchable-Document, it adds that document to the local index:
Listing 9.4. LeafNode.executeLocalQuery
trait LeafNode { self: AdaptiveSearchNode =>
var documents: Vector[String] = Vector()
var index: HashMap[String, Seq[(Double, String)]] = HashMap()
...
private def executeLocalQuery(query: String,
maxDocs: Int,
handler: ActorRef) = {
val result = for {
results <- index.get(query).toList
resultList <- results
} yield resultList
handler ! QueryResponse(result take maxDocs)
}
}
The executeLocalQuery function extracts all the results for a given word. These are then limited by the desired maximum number of results in the query and sent to the handler. Note that the handler is of type ActorRef not Actor. In Akka, there’s no way to gain a direct reference to an actor. This prevents accessing its state directly from a thread. The only way to talk with an actor is to send a message to it using an ActorRef, which is a transparent reference to an actor. Messages are still sent to actors using the ! operator. The executeLocalQuery function didn’t change from the Scala actors version to the Akka actors version besides the use of ActorRef:
Listing 9.5. LeafNode.addDocumentToLocalIndex
trait LeafNode { self: AdaptiveSearchNode =>
private def addDocumentToLocalIndex(content: String) = {
documents = documents :+ content
if (documents.size > MAX_DOCUMENTS) split()
else for( (key,value) <- content.split("\s+").groupBy(identity)) {
val list = index.get(key) getOrElse Seq()
index += ((key, ((value.length.toDouble, content)) +: list))
}
}
protected def split(): Unit
}
After updating the index, the document is added to the list of stored documents. Finally, if the number of documents in this node has gone above the maximum desired per node, the split method is called. The split method should split this leaf node into several leaf nodes and replace itself with a branch node. Let’s defer defining the split method until after the parent node is defined. If the index doesn’t need to be split, the index is updated.
To update the index, the document string is split into words. These words are grouped together such that the key refers to a single word in a document and the value refers to a sequence of all the same words in the document. This sequence is later used to calculate the score of a given word in the document. The current index for a word is extracted into the term list. The index for the given word is then updated to include the new document and the score for that word in the document.
Let’s first define the branch node functionality before defining the split method:
Listing 9.6. BranchNode
trait ParentNode { self: AdaptiveSearchNode =>
var children = IndexedSeq[ActorRef]()
def parentNode: PartialFunction[Any, Unit] = {
case SearchQuery(q, max, responder) =>
val gatherer: ActorRef = Actor.actorOf(new GathererNode {
val maxDocs = max
val maxResponses = children.size
val query = q
val client = responder
})
gatherer.start
for (node <- children) {
node ! SearchQuery(q, max, gatherer)
}
case s @ SearchableDocument(_) => getNextChild ! s
}
...
}
The ParentNode is also defined with a self type of AdaptiveSearchNode. The parent node also contains a list of children. Again, the reference to child actors is the ActorRef type. The method parentNode defines a partial function that handles incoming messages when an actor is a parent. When the parent receives a SearchQuery it constructs a new gatherer and farms the query down to its children.
Notice the difference from Scala actors. In Akka, an actor is constructed using the Actor.actorOf method. Although the actor is constructed as a gatherer node, the term gatherer is of type ActorRef not GathererNode.
When the ParentNode receives a SearchableDocument it calls getNextChild and sends the document to that child. The getNextChild method, not shown, selects a child from the children sequence in a round-robin fashion. This is the simplest attempt to ensure a balanced search tree. In practice, there would be a lot more effort to ensure the topology of the tree was as efficient as possible (see figure 9.6).
Figure 9.6. Topology state change
The key behavior of the new adaptive search tree is that it should dynamically change shape. Any given node should be able to change its state from being a leaf node to a parent node that has children. Let’s call the new state changing actor an AdaptiveSearchNode.
Listing 9.7. AdaptiveSearchNode
class AdaptiveSearchNode extends Actor with ParentNode with LeafNode {
def receive = leafNode
protected def split(): Unit = {
children = (for(docs <- documents grouped 5) yield {
val child = Actor.actorOf(new AdaptiveSearchNode)
child.start()
docs foreach (child ! SearchableDocument(_))
child
}).toIndexedSeq
clearIndex()
this become parentNode
}
Similar to Scala actors, an Akka actor must extend the Actor trait. The largest difference between Akka and Scala actors is the receive method. In Akka, receive defines the message handle for all messages, not just the next message received. There’s no need to explicitly loop. Also, receive is called via the Akka library when a message is ready, so receive is not a blocking call.
The receive method is defined to return the leafNode behavior by default. This means any AdaptiveSearchNode instantiated will start of as a leaf node. In Akka, to switch the behavior of an actor, there’s a become method that accepts a different message handler.
The split method is defined to:
- Create new AdaptiveSearchNode actors for every five documents in the current index (see listing 9.8. This will begin acting as leaf nodes. These nodes are then sent the portion of documents they will be responsible for.
- The local index is cleared to allow it to be garbage–collected. In a production system, this wouldn’t happen until the children acknowledged that they had received the documents and were ready to begin serving traffic.
- The behavior of the current actor is switched to the parent behavior in the expression this become parentNode.
Listing 9.8. Creating an adaptive scatter-gather tree
def makeTree = {
val searchTree = Actor.actorOf(new AdaptiveSearchNode {
self.dispatcher = searchnodedispatcher
})
searchTree.start()
submitInitialDocuments(searchTree)
searchTree
}
Now, creating a scatter-gather search tree is much easier. Only the root AdaptiveSearchNode needs to be created and the documents sent into the root node. The tree will dynamically expand into the size required to handle the number of documents.
Akka’s Scheduler and Supervisors
Akka provides an even richer set of actor supervisors and schedulers than the Scala actors library. These aren’t discussed in the book, but can be found in Akka’s documentation at http://akka.io/docs/
This technique can be powerful when distributed and clustered. The Akka 2.0 framework is adding the ability to create actors inside a cluster and allow them to be dynamically moved around to machines as needed.
9.6. Summary
Actors provide a simpler parallelization model than traditional locking and threading. A well-behaved actors system can be fault-tolerant and resistant to total system slowdown. Actors provide an excellent abstraction for designing high-performance servers, where throughput and uptime are of the utmost importance. For these systems, designing failure zones and failure handling behaviors can help keep a system running even in the event of critical failures. Splitting actors into scheduling zones can ensure that input overload to any one portion of the system won’t bring the rest of the system down. Finally, when designing with actors, you should use the Akka library for production systems.
The Akka library differs from the standard library in a few key areas:
- Clients of an actor can never obtain a direct reference to that actor. This drastically simplifies scaling an Akka system to multiple servers because there’s no chance an actor requires the direct reference to another.
- Messages are handled in the order received. If the current message handling routine can’t handle an input message, it’s dropped (or handled by the unknown message handler). This prevents out-of-memory errors due to message buffers filling up.
- All core actors library code is designed to allow user code to handle failures without causing more. For example, Akka goes to great lengths to avoid causing out-of-memory exceptions within the core library. This allows user code, your code, to handle failures as needed.
- Akka provides most of the basic supervisor behaviors that can be used as building blocks for complex supervision strategies.
- Akka provides several means of persisting state “out of the box.”
So, while the Scala actors library is an excellent resource for creating actors applications, the Akka library provides the features and performance needed to make a production application. Akka also supports common features out of the box.
Actors and actor-related system design is a rich subject. This chapter lightly covered a few of the key aspects to actor-related design. These should be enough to create a fault-tolerant high-performant actors system.
Next let’s look into a topic of great interest: Java interoperability with Scala.