
3
Core concepts of Domain-Driven Design
This chapter covers
- The parts of Domain-Driven Design (DDD) most important for security
- Models as strict simplifications of the domain
- Value objects, entities, and aggregates
- Domain models as ubiquitous language
- Bounded contexts and semantic boundaries
During the years that we’ve been developing software, we’ve found inspiration from many sources—some different, some shared. One of the biggest sources of inspiration we have in common is Domain-Driven Design, often abbreviated as DDD.
DDD sets the bar a little higher in regards to most system development. We’ve seen a lot of system development where the attitude “just make it work” has been the guiding principle. When a bug was found, the solution was to just add an if clause. Although seldom a local programming mistake, the problem was poorly understood, and the solution was built on a model that was incomplete or inconsistent.
Domain-Driven Design is an approach to the development of complex software in which we:
- Focus on the core domain.
- Explore models in a creative collaboration of domain practitioners and software practitioners.
- Speak a ubiquitous language within an explicitly bounded context.
—Eric Evans, Domain-Driven Design Reference (Dog Ear Publishing, 2014)
DDD says we don’t just want our systems to work, we want to truly understand what we’re building. Let’s stress the word what in this context. What DDD emphasizes is a deep understanding of the problem domain, not just an understanding of the solution. The beauty we see in DDD is that it also insists on capturing that understanding in code—it makes the code speak the language of the problem you’re solving. We find that a focus on deep understanding helps us become better developers. It was much later that we realized this approach also has a profound effect on security.
This chapter is about DDD, but not all aspects of it. DDD is in itself a huge and multifaceted subject. It spans from crafting code to system integration, from requirement analysis to testing. It links into other agile-minded methodologies and processes. You’ll find multiple books and an overwhelming number of articles about DDD, so covering it comprehensively in one chapter would be impossible. We’ll instead focus on those parts of DDD that we’ve found can drive security.
If you’re unfamiliar with DDD, this chapter gives you the understanding of DDD that we’ll use in later chapters. This chapter is also here as a reference. In later chapters, we use parts of DDD to promote security, so come back here when you need a refresher about value objects, aggregates, context maps, or any other DDD concept.
As a side note, we recommend you dig deeper into this subject, as there is a lot more to it beside the security aspects. The mini-book Domain-Driven Design Quickly is a good starting point.1 Patterns, Principles, and Practices of Domain-Driven Design (Wrox, 2015), by Scott Millett, is also an easygoing start. If you want to dig deeply into the subject, then Eric Evans’s seminal book Domain-Driven Design: Tackling Complexity in the Heart of Software (Addison-Wesley, 2003) is the definitive read.
If you’re somewhat familiar with DDD, read this chapter as a refresher. If you’re a proficient Domain-Driven Designer, read this chapter anyway, as there are some aspects we want to stress—those aspects that we’ll use later for promoting security. Also, be aware that we might express some ideas in a somewhat compressed fashion, and they might seem somewhat distorted. We’re not aiming for completeness, but for an understanding that’s enough to talk about its relationship to security.
We’ll cover domain models, which form the foundation of system development à la DDD. Domain models provide an unambiguous, strict foundation for what the system does. From a security perspective, this is interesting. When you define what the system should do, it also gives you a powerful tool to say what the system shouldn’t do.
When modeling, and implementing that model as code, it’s handy to have some building blocks. Domain models are usually based on value objects and entities. Larger structures are usually represented through aggregates. Using these elements makes the code more precise and less prone to vulnerabilities.
When zooming out from a single system to the integration level, DDD gives you the tools of bounded contexts and context mappings. These tools give you a better possibility to ensure that integration between systems is tight so that it’s easier to hold up security across several systems. As DDD is founded on domain models, let’s start with creating strict models to capture a deep understanding about the problems you can solve with your software.
3.1 Models as tools for deeper insight
Let’s start with explaining what DDD models mean, as they are at the center of DDD. In system development, the word model is used for many things: flow diagrams in UML, how data is laid out in the tables of a database, and more. In DDD, the model explains how you’ve captured your essential understanding of the business-at-hand as a selected set of concepts. Why do you need such models, and what should they look like?
We all know that there are no silver bullets, and DDD is no exception. To stay intellectually honest, it’s important to point out when a technique or methodology doesn’t yield a significant benefit, as well as under what circumstances it has its sweet spot. If you’re designing a network router or a baggage-handling system, the circumstances differ wildly. DDD won’t help much in the first case, but will help you in the second case.
In the case of a network router, the most important problem is technical: getting high enough I/O throughput and low enough network latency, which is a really complex problem. Should you fail to master this complexity, you’ll get a product that no one wants to buy. Network performance is the critical complexity for your router. DDD can aid you in modeling the package queues and routing tables, but it won’t address the throughput and latency.
In contrast, let’s think about the case of the baggage system that handles checked-in baggage at an airport. In its technical implementation, it will use the same databases, message queues, and GUI frameworks as most other systems. There will be a lot of complexity to handle, but this is probably not the critical problem. For the baggage system, you need to represent how baggage is routed from check-in counters to airplanes via conveyor belts and loading trucks. If the representation is flawed, then the bags might not make it in time for the right flight or might end up on the wrong one. Passengers will be angry, and the business will lose goodwill, confidence, and money. Even worse, there are important security aspects at stake. For obvious security reasons, a bag is only allowed on the plane if the passenger is on the plane. If a bag is checked, but the passenger doesn’t show up at the gate, then the baggage system must ensure the baggage is unloaded. If the system isn’t properly crafted, it might be possible to trick it into loading a bag onto a specific flight or not unloading it—something that could have severe security consequences.
If you fail to capture a deep and precise understanding of baggage handling, you’ll build a flawed system. But the greater risk is that it’s harmful to the business and potentially dangerous to the customers. It might even be so bad it makes the system meaningless. The airport might be better off closed with such a flawed system in place. This isn’t a hypothetical example; the opening of the Denver Airport in the 1990s was delayed a year-and-a-half because of deficiencies in the baggage system, resulting in heavy economic loss.2 In cases like this, understanding and modeling the domain of baggage handling should be the focus of your work. Spending time on optimizing your database connection pool would be a bad choice. The critical complexity is the domain.
DDD is at its best when your system handles a problem domain that’s hard to understand. In these cases, the most critical problem is understanding the complexity of the domain. Then understanding and modeling that domain should be your main focus. If you fail to master the complexity of various technical aspects, you get a system that’s less useful. But, if you fail to master the complexity of the domain, you get a system that’s doing the wrong thing. In that regard, the domain is the critical complexity. In our experience, most business applications fall into this category. Understanding the domain and crafting a purposeful model targets the core of solving the business logic problems.
It might be tempting to think that the domain isn’t technical. However, that would be a mistake. Sometimes the critical complexity is understanding the domain, but the domain is technical. Consider writing an optimizing compiler. It transforms source code to highly optimized machine code that can be executed and, in doing so, applies peephole optimizations, performs dead-code elimination, evaluates subexpressions at compile time, and so on. The tricky part isn’t the read/write performance of files, it’s ensuring that all these optimizations result in a program that does the same thing as defined by the source code. The main effort should be to represent the source code and all transformations in a strict way that enables the optimizations but still guarantees that the resulting program is the same. Here it’s the domain that’s the critical complexity, but the domain is technical!
Now the connection to security. It’s hard to capture enough understanding to make a system that behaves well in all possible cases. It’s hard enough to do it for benevolent, normal data with all the weird cases that can occur. It’s even harder to do it in a way that’s resistant to malevolent data. Someone might try to attack your system by sending bizarre data to it, manipulating it into doing something unpleasant. The system still needs to respond in a sound and safe way. We saw an example of this in the case study of the online bookstore in chapter 2. No normal business procedure results in an anti-book (quantity -1) being placed in a shopping cart. Still, a dishonest customer might do so to manipulate the system (in that example, to avoid paying the full price for an order).
We’ve found that for security, it’s essential to focus on building domain models. A lot of security problems are avoided as a side effect, especially business integrity problems. Domain models to a certain extent also shield your code from some technical attacks. What you need are domain models that support development in a stable and secure way. For a domain model to be effective, it needs to
- Be simple so you focus on the essentials
- Be strict so it can be a foundation for writing code
- Capture deep understanding to make the system truly useful and helpful
- Be the best choice from a pragmatic viewpoint
- Provide you with a language you can use when you talk about the system
DDD isn’t a silver bullet; its value depends on the context. There are situations where a main focus on modeling the domain isn’t the right choice. For example, if you write software for a network router, then I/O throughput will be the most critical thing. Your critical complexity is technical in this case. But even here, you should consider whether a sloppy domain model might be a security issue.
In our opinion, the main benefit of domain modeling is that it works as a vehicle for learning at a deeper level—and learning at that level is crucial. It’s not hard to “catch the lingo” of businesspeople, and you can use that same language to write a requirements document that looks good. But without deep learning, such a document will contain subtle misunderstandings, inconsistencies, and logical loopholes. These flaws make it impossible to build a solid system that does the right thing in tricky situations, with security vulnerabilities as the worst consequence. Working in collaboration with domain experts to create a domain model fuels that learning.
3.1.1 Models are simplifications
A model is a simplified version of reality where you’ve removed irrelevant parts. For example, when you check in a bag at the airport, there’s no need for the system to represent your shoe size. On the other hand, it’s probably relevant to represent how heavy the bag is. To make it easier to understand and code the system, you create a model that contains the weight of the bag (but not the shoe size of the passenger), keeping just the details you think are relevant.
To be clear, models aren’t diagrams. In many other contexts, model means a specific diagram type, like an entity-relationship model often used for database design or the class diagram from UML. These diagrams are representations of the model, but the model itself is the conceptual understanding of how our simplified view of reality works.
The use of “model” in DDD is closer to another use of the word, as in the phrase “model train.” When building model trains, the builders put much effort into keeping some aspects of reality, while totally ignoring others (figure 3.1). Knowing what details to keep and what details to distort is key to building train models, as well as domain models.
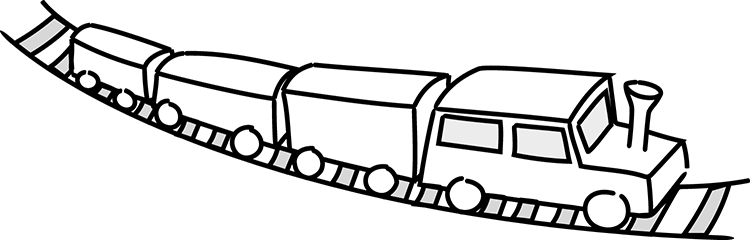
Figure 3.1 A model train looks like the real, original train.
Figure 3.1 shows a model train. It looks like a train and moves around on rails, but it’s not a real train. We consider it a model because it has kept some important attributes while disregarding others. Let’s list some attributes the model has in common with real trains:
- Color —We think that the model of a specific train should have the same colors as the original train.
- Relative size —We expect the proportions to be maintained. If the doors are twice as high as they are wide in reality, we expect the same ratio on the model train.
- Shape —We expect the model train and its details to have the same shape, such as the curvature of the front window.
- Movement —We expect the model train to move along rails in the same way as a real train does.
Let’s also list some attributes where the model differs from reality and where we think the difference is fine:
- Material —It’s OK that the model train is made out of plastic or tin when the original is built from other materials.
- Absolute size —If the real cars were 30 meters long, it’s fine that they are much smaller in the model.
- Weight —The model is much lighter, which is OK.
- Method of propulsion —The model doesn’t have a steam engine; it runs on electricity.
- Rail curvature —The curves in the model are much tighter than in reality, which we accept.
Strangely enough, it’s easier to find differences between the model train and a real train than it is to find things they have in common. Still, we have a firm opinion that this is a proper model of a train. Clearly this specific model has managed to capture the essentials of our understanding of a train.
It seems like color, relative size, and movement are enough for us to understand that the model is a train. These three attributes are necessary; if the model doesn’t fulfill these attributes, we won’t play along and pretend it’s a train. And these three are sufficient. If the model fails to fulfill some other expectation, such as material, we’ll still play along and pretend it’s a train.
We’ll now leave the realm of toys and take with us the idea that a model is a simplified understanding of the real thing. This goes for the models you use in system development as well. If you model a person, you might choose to grab onto a few attributes: a person has a name, is of a certain age, has a specific shoe size, and optionally has a pet. Agreed, this is a crude model, but a model nevertheless (figure 3.2).

Figure 3.2 One possible model of people and pets
A model is a simplification, but it must still be general enough so that you can capture some variations that you think are interesting. In our example, we want to allow different names, different ages, and different shoe sizes, and we allow people to have pets or not. All these differences we allow to show up in the model. We don’t make any distinctions between people of different height or pay any attention to their hairdo (figure 3.3).
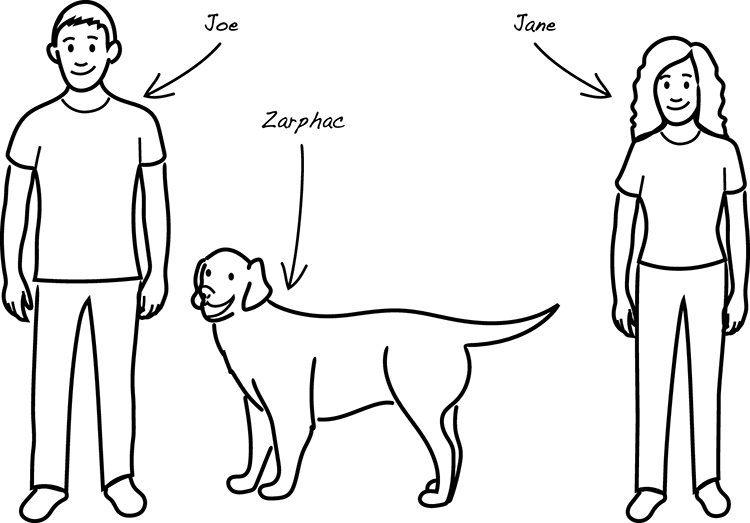
Figure 3.3 Joe, age 34, shoe size 9, and his dog Zarphac, together with Jane, age 28, shoe size 6, no pet
You can represent this model in many different ways. You can use plain text to explain what you mean. You can use different kinds of diagrams to illustrate it (for example, compare figures 3.2 and 3.4). You can use code (pseudocode or actual code from a programming language). The important point here is that none of these representations is the model. Class diagrams in particular are often confused with being the model, but the model, as such, isn’t any of the representations. The model is the conceptual understanding of what you consider as essential in your modeling—in this case, name, age, shoe size, and pet.
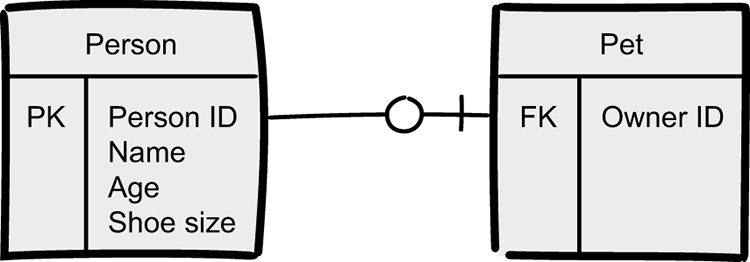
Figure 3.4 The same model as before, but another representation
The main benefit of keeping models as really simplified versions of reality is that simple models are easier to make strict. This is something that’s essential when you later build software from them.
3.1.2 Models are strict
The domain model isn’t just a watered-down version of reality; what it has lost in richness, it has gained in strictness. When we talk about a model being strict, we mean it in the mathematical sense of “exact, precise,” that the concepts, attributes, relations, and behaviors are unambiguous.
People are really complex beings with lots of attributes and lots of relationships. When you decide to focus on name, age, shoe size, and pets, you lose a lot of richness. But you gain precision in what you mean by “a person,” a precision that makes it possible to represent this entity in software. Knowing what to sacrifice in richness to gain in precision is hard work, and you need access to people with deep domain knowledge to do this well.
Writing software is a collaboration between two kinds of professionals who come from different directions and who need to meet in a productive way: the businesspeople and the developers. Each has different needs that have to be fulfilled to create great software. Businesspeople need to see the terminology they’re used to, not some quasi-technical mumbo-jumbo. If they don’t recognize their domain, you’ve failed them.
It’s not enough to just have some familiar words as labels in the user interface or in the headers of printed reports. The system must also behave in a way that businesspeople think is reasonable, consistent, and understandable. For this to happen, the domain model has to be strict. If the model isn’t strict and contains ambiguities, then one part of the system might behave in one way and another part in another way.
For example, a screen at the check-in counter might talk about “number of bags,” another at the gate might say “baggage count,” and the tablet used by loading staff might say “luggage.” To make things worse, some of these terms might count the carry-on as part of the number, while others don’t. When the personnel speak to each other, they each have to remember what screen the other person is seeing and whether to add or subtract the carry-on from the number they’re seeing. Sometimes there are misunderstandings, and bags are lost. The system fails the business, and not even the domain experts think it makes sense.
Another shameful variant is when a model is consistent in the terminology but too lenient in its constraints and relationships. This is often the result of using a standard system and configuring it to the domain, which is the usual way of working with, for example, Enterprise Resource Planning (ERP) products.
One of the first business uses of computers in the 1940s and 1950s was to plan the use of machines and raw materials in manufacturing industry, which provided huge benefits compared to paperwork and manual routines. In the 1980s, material requirements planning (MRP) expanded into manufacturing resources planning (sometimes called MRP II) to include finance, personnel, marketing, and other so-called resources. But the underlying domain still used resources from a bill-of-material to produce products to sell. Because factories differ, these MRPs were highly configurable.
In the 1990s, these processes evolved into ERP systems, planning the work of entire enterprises and becoming even more configurable to support any enterprise in any kind of business. They were often described and sold as standard systems, which could be configured to handle any domain; whereas, under the hood, they were still the same flow-of-materials systems. This line of business has successfully sold such systems to handle customer complaints, police investigations, or other completely different domains. Unfortunately, successfully selling is one thing and successfully delivering value is another. If you want to configure a flow-of-materials system to handle police investigations, you need to do some very nonintuitive abstractions: police can be seen as a machine, and a report about a burglary can be seen as a pile of raw material that is refined by the (police) machine during its investigation.
In order to shoehorn one domain into another, you need to be less and less specific, and less and less precise. The result is often a general object management system where everything is an object. Through the user interface, you can update the attributes of the objects, but this watered-down model carries little understanding of what those objects actually represent. Often you can fill in any combination of attributes and relationships. A system that is so lenient is of course prone to mistakes, and as you saw in the case study of the online bookstore, such lenience can result in security flaws.
Obviously, it’s important to pay attention to the businesspeople. They need to recognize the domain they’re used to working in, so you should choose terminology that’s familiar to them. And it’s a big mistake to fail to meet the needs of the domain professionals. It’s an equally big mistake to fail to meet the needs of the other professionals: the developers.
As developers, at the end of the day, we write code. And that code is mathematically strict—it tells the computer how to execute based on the data at hand, according to the rules we code. This is why we need strictness. Either we get that strictness from our conversations with the domain experts or we invent that strictness ourselves by filling in the gaps with educated guesses.
It isn’t good enough to say that “most people just have one pet.” Developers need to know if having a pet is strictly restricted to having just one. This is where it takes some courage to be a developer. You need to ask the questions that make the model strict without ambiguities. If you ask if there can be more than one pet, you might get the answer, “Oh, that’s really unusual.” This leaves you with two options: either you think, “Then I need to allow for a list of pets,” or you think, “Just one pet allowed.” In the first case, you end up writing a system with possibly more complexity than necessary, and sooner or later some weird combination occurs. In the second case, you disallow multiple pets, just to get hammered a few months later when it turns out that there are some customers (perhaps customers you get when acquiring another company) who actually have two or more pets. To add insult to injury, this can turn into blame-shifting towards you, with businesspeople saying unfairly, “We told you it could happen,” when all you did was make a decent assumption to keep complexity at bay. You need to be able to make decisions to move development forward.
The way out of this dilemma is to actively ask what should be in the model: “Shall we allow for multiple pets, or shall we place a restriction on having just one?” Deciding whether the unusual multipet people should be covered or not isn’t a technical decision, it’s a business decision. If you don’t have system support for multiple pets, then they have to be handled through a separate manual routine. On the other hand, providing scope for lots of diversity doesn’t come for free either. It’s tempting to allow for more and more general models, but sooner or later everything is in a many-to-many relationship with everything else. That doesn’t make anything better in the long run. It can be hard to foresee and get an overview of the ramifications of a general model.
Say there’s a function that allows one person to swap pets with another person. If you also allow for multiple pets per person, then you need to figure out what it means to swap pets. Does that mean person A gets all of the pets of person B, and vice versa? Or do you just swap one pet? If you don’t let the model reflect the business domain, you let the businesspeople down. If you don’t create a strict model, you let the development people down.
When you design software, you make similar choices; you make simple representations of complex phenomena. Let’s have a look at a schoolbook example of object orientation, shown in the following code snippet, where lots of attributes and relationships are ignored and only a narrow view of a person is left:
class Person { ①
private String name;
private int age;
private int shoeSize;
private Animal pet;
void growOlder() {
this.age++;
}
void swapPetWith(Person other) {
...
}
}
In this design, you’ve removed tons of attributes and behaviors that a person might have, reducing it to four attributes that are essential for the context and purpose at hand. The model has a purpose, a scope of behavior you want to describe. Leaving out details might seem to make the system poorer, but it provides a great benefit—what you gain by leaving out details is the possibility to be precise.
In the domain of people, a person is a complex being with complex interactions. But in our model of the domain, a Person is something that has a name, an age, a shoe size, a pet, and the ability to grow older. Period. That’s exactly what you mean when you use the word person. What you lose in richness, you gain in precision.
3.1.3 Models capture deep understanding
The previous example of modeling a person is of course laughingly simplistic. Real-world problems are much more intricate, as is the case of airport baggage handling. The strict understanding that you capture in a domain model is deeper than what most people think. In fact, the knowledge you need to capture is even deeper than the understanding most domain experts exercise in their day-to-day work when they handle situations on a case-by-case basis. The reason for this is that you not only need enough understanding to work in the domain, you need an understanding deep enough to build a machine. Let’s compare this with the challenge of riding a bike.
Most of us are experts at riding a bike in the sense that we can do it without actively thinking about what we do.3 We can prove this by taking a bike and riding it even in pretty challenging conditions, such as on a bumpy road and in windy weather, and, perhaps, even while carrying a large package under one arm. That takes expertise. Compare that with the difficulties faced by a child who’s just learning to ride on flat ground on a nice sunny summer day. This expertise is comparable to the proficiency of a domain expert; they know how the domain works. For example, a shipping expert knows how to route cargo containers even when conditions get tough, such as when a container is mistakenly unloaded from a ship and there’s no other ship leaving for the same destination for a substantial amount of time. The domain expert is able to handle even tricky cases, taking each case on its own.
Unfortunately, the understanding you need to write a software system goes even deeper. You don’t have the luxury of being “at the site” to handle any situation that arises, of being able to assess and improvise to resolve a situation on the spot. You’re writing a program that should do this without your being at the site in human form. The challenge you face isn’t so much like a youngster riding a bike, but is more like building a bike-riding robot.
If you’re to build a bike-riding robot, the understanding of bike riding needed is much deeper than most experts possess, even professional bicycle messengers or BMX pros. For example, how do you turn right while riding a bike? Think about it for a few seconds; you’ve probably done it a thousand times. Most people spontaneously answer, “I pull on the right handlebar.” Unfortunately, doing so would cause you to fall to the left, down onto the asphalt, due to centrifugal force.4
What you actually subconsciously do when turning right is to turn the handlebars left, causing you to fall to the right for a very short period of time. After a few milliseconds, you’ve tilted right just to the appropriate angle, and then you turn the handlebars to the right, taking you into a right turn. Your leaning to the right will be exactly what’s needed to compensate for centrifugal force, and you’ll turn right, safe and stable (figure 3.5). You do this without thinking and without understanding the subtle kinematics mechanics. If you want to build a bike-riding robot, this is the depth of understanding that you need to have.

Figure 3.5 To build a bike-riding robot, you need a deep understanding of how to make a right turn.
This bike-riding robot story provides some bad news and some good news. The bad news is that if you look inside the head of a domain expert, you find no ready-to-go model. There’s no true model inside. You can’t simply ask the domain experts and expect to get all the answers you need. The good news is that working together with domain experts to craft a model is fun and rewarding. Doing so is an iterative process of exploring lots of possible models and choosing one that is appropriate for solving the problems you have at hand.
3.1.4 Making a model means choosing one
One of the usual myths of modeling is that there’s a true model somewhere, often thought to be embedded inside the head of the domain expert. This isn’t the case. Making a model involves an active choice among many possible models, and you need to choose the one that best suits your needs—that which defines the purpose of the model.
DDD practitioners sometimes use the phrase “distilling a model.” Let’s compare ourselves for a while with a whiskey distiller. Somewhat simplified, the whiskey distiller starts with a large batch of fermented wort, something basically undrinkable, then adds some heat and collects the vapors.5 The distiller throws away the first part, which contains acetone. The middle part consists of most of the alcohol, some of the water, and the natural flavors that are dissolved. This is considered the good part and is kept. The last part consists of some alcohol, a lot of water, and some less attractive flavors. This is also discarded. What is kept is what we call whiskey. Your personal attitude toward whiskey or your tastes might vary, but you get the point. When distilling, we actively keep some parts we want and throw away parts we don’t want. In the same way, when you distill a model, you throw away some parts of reality and keep others.
The important point here is that there are many ways for distillers to do their job. They have a choice. Keeping the middle part is a choice because the objective for the distiller is to get a high-alcohol result with some specific flavors. The purpose is to distill something that is pleasurable to drink. The purpose directs how we distill.
But the distiller could have made other choices, if the purpose had been different. Had the distiller wanted acetone instead, then the distillation would have looked different. The distiller would have kept the first part and thrown away the rest. In the same way, you can distill different models from the same reality depending on what you intend to use the models for.
Our model describing a person with name, age, shoe size, and pet is just one model. Another model could be to describe a person by date of birth, place of birth, mother’s name, and father’s name. Neither of these two models is more correct than the other (figure 3.6). They’re different, and they’re good for different purposes. If you’re keeping a registry for a dog owners’ club, the first model is clearly superior to the second. If you’re studying how a family has spread across the world through migration, the first model is worthless, and the second excellent.

Figure 3.6 Two different models of people—good for different things
When modeling, actively find different models that express your domain. Try to find three different models and compare how good they are at expressing your domain problems. Finding a good model is important because it makes it possible to talk about the domain in an efficient and unambiguous way. A good model forms a language.
3.1.5 The model forms the ubiquitous language
An interesting aspect of modeling is that the model creates a language—the language we speak about the system. To start with, realize that when domain experts speak with each other, they use a language of their own. This is the domain language. In an English-speaking country, this language might sound like English. But there are subtle differences. There are a lot of words in English that are simply never used in this domain-expert language (for example, chervil will seldom be used in a discussion about accounting). The other way around, the domain-expert language contains domain-specific terms and idioms that aren’t used in common English (accrual, for example). What domain experts speak to one another is simply a language that’s geared to enabling effective communication.
Take a moment to consider the domain-expert language of system developers. Among ourselves, we easily throw around terminology that makes perfect sense to us but is completely impossible to understand for nondevelopers; for example, we might “pool the connections” or “make that a strategy.” And the domain experts of finance, logistics, or healthcare have their own lingo too.
If you’re building a logistics system, it seems like a logical approach to take the terminology from logistics and just encode that as a software system. This is a wonderful idea, but unfortunately flawed. The language used by logistics experts isn’t logically consistent. This isn’t because they’re particularly sloppy with terminology. We software developers are equally sloppy with our terminology. Listen in on any two seasoned developers talking, and you’ll find that they might use the words object, instance, and class interchangeably, as if they were synonyms. And you know they aren’t, because when you explain object orientation to beginners, you’re careful to distinguish between classes and objects. But when two experts communicate, they can be sloppy because they understand each other, and the real discussion is elsewhere on a higher level.
If you’re building a logistics system, wouldn’t it be wonderful if you could form a language where you can talk about the system in a precise way without the risk of misunderstanding? This is exactly what a model is. If you jointly (between logistics experts and developers) decide that a leg means transport from one place to another using the same vehicle all the way, and you decide that “terminating a leg” means that the cargo is unloaded at the destination, then you can use those terms and make yourselves understood. If you say, “If two transports terminate a leg at the same dock, then they can be cotransported on the next leg,” then that phrase can be unambiguously understood, and the functionality can be implemented (figure 3.7).
Figure 3.7 The domain model forms a language in common.
When discussing the functionality of a system, use the words and phrasings that are part of the model. By doing so, you’ll quickly realize whether the functionality can be implemented or not. If it’s awkward to express the functionality using the terms from the model, this is a sure sign that it’ll be awkward to implement. It might be a sign that the model needs to be extended to contain a new term and the system refactored for consistency.
Using the terminology of DDD, you want the model to become the ubiquitous language when talking about the system. By ubiquitous, in this case we mean that the terminology should be used everywhere you talk about the system (figure 3.8). The same terms should be used in the user interface, in the manuals, in the requirements or user stories, in the code, and in the database tables. There’s simply no point in calling something a quantity in the user interface, referring to it as an amount in the manual, and naming the database column Volume. Insisting on using the same language across disciplines helps in finding ambiguities that could manifest as bugs or security flaws later.
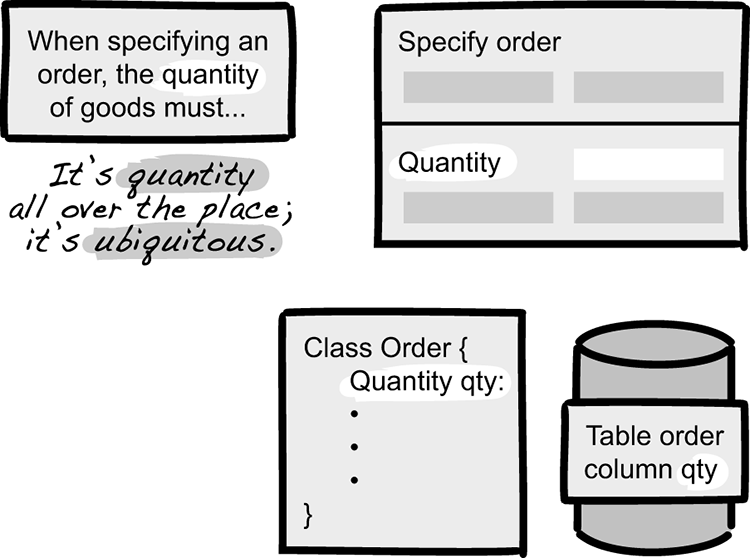
Figure 3.8 The model is ubiquitous; it uses “quantity” consistently all over the place.
It’s worth pointing out that, of course, the persistence model might be slightly different from the conceptual model. For example, you might have to split concepts into different tables, and you might need to join tables or synthetic keys that aren’t part of the conceptual model. In the same way, the classes in the code might be slightly different from the terms used in the conceptual model for implementation-specific reasons. Nevertheless, the understanding you capture is still the same, and you should use terminology from the ubiquitous language as much as possible when you name your constructs (classes or database tables).
This doesn’t mean you’re turning into a language police force. The model or the domain model language is the ubiquitous language when talking about the system. The domain experts are still allowed to use their ambiguous domain language among themselves in the same way developers are allowed to be sloppy about objects versus classes in discussions with other developers.
The important point about being precise in the ubiquitous language is that when you talk about the system, you need to be precise. This is especially important when business experts and developers interact and the risk of misunderstanding is the highest. In these situations, you should insist on using the terminology of the ubiquitous language.
It’s also worth pointing out that just because language is ubiquitous doesn’t mean that it’s universal. It’s the ubiquitous language when talking about this specific system, not when talking about other systems (even other logistics systems). Different systems have different needs and different focuses. These will have different models and, thus, different languages. Each domain model language will be the ubiquitous language within its realm but not outside that domain.
The context for the language has an outer bound. In DDD, we refer to this as the bounded context for the model. Within the bounded context, each word in the model has a well-defined meaning, but outside the bounded context, words can mean something completely different. We’ll cover bounded contexts more deeply later on in this chapter. Understanding more about models and their purpose, you can now move on to some more pragmatic aspects. You need to actually build those models, so some typical building blocks are handy to have.
3.2 Building blocks for your model
In order to express your domain model in code, you need a set of building blocks. These building blocks should be well defined, and their purpose is to bring order and structure to complex models. They provide a framework that allows you to keep your domain logic clearly separated from the rest of your code and guides you through the technical difficulties in doing so.
The building blocks from DDD that are of special interest in this book are entities, value objects, and aggregates, as shown in figure 3.9. These are interesting because, used in a certain way, they can also be building blocks for software security.
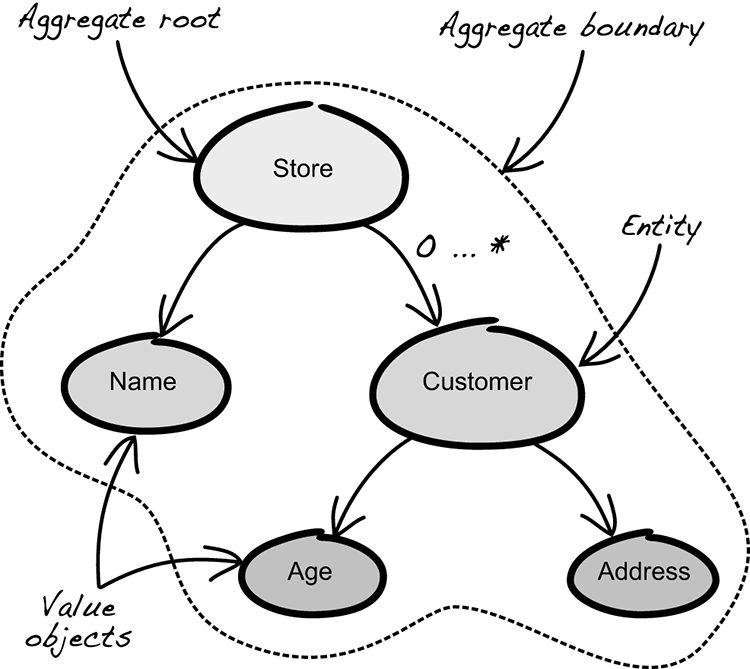
Figure 3.9 Fundamental building blocks of a domain model
Understanding the meaning of these building blocks will help you understand the concepts discussed in the rest of this book. In this section, you’ll learn the meaning of each of these terms, the details that define them, and how they are used.
3.2.1 Entities
Every part of your domain model has certain characteristics and a certain meaning. Entities are one type of model object that have some distinct properties. What makes an entity special is that
- It has an identity that defines it and makes it distinguishable from others.
- It has an identity that’s consistent during its life cycle.
- It can contain other objects, such as other entities or value objects.
- It’s responsible for the coordination of operations on the objects it owns.
What this means is that if you need to know if two entities are the same, you look at their identities instead of their attributes. It’s the identity of the entity that defines it, regardless of its attributes, and the identity is consistent over time. During the life cycle of an entity, it can transform and take on many different attributes and behaviors, but its identity will always remain the same.
Let’s consider a car, for example. Many attributes of a car can change during its lifetime. It can change owners, have parts replaced, or be repainted. But it’s still the same car. In this case, the identity of the car can be defined by its vehicle identification number (VIN), which is a unique 17-character identifier given to every car when it’s manufactured.
Sometimes an entity’s identity is unique within the system, but sometimes its uniqueness is constrained to a certain scope. In certain cases, the identity of an entity can even be unique and relevant outside of the current system. The identity is also what’s used to reference an entity from other parts of the model.
Another important trait of an entity is that it’s responsible for the coordination of the objects it owns, not only in order to provide cohesion, but also to maintain its internal invariants. The ability to identify information in a precise manner and to coordinate and control behavior is crucial if you want to avoid security bugs sneaking into your code. In upcoming chapters, you’ll see that this is what makes entities an important tool for designing secure code.
The continuity of identity
Sometimes a domain object is defined by its attributes, but sometimes those attributes change over time without implying a change of identity of the domain object. For example, a representation of a customer can be defined by its attributes: name, age, and address. Most of these attributes can change during the time the customer exists in the system, but it’s still the same customer with the same trail of history, so its identity shouldn’t change (figure 3.10). It would quickly become quite messy if the system were to create a new customer every time an address got updated.

Figure 3.10 The attributes of the customer change, but the identity remains the same.
The customer isn’t defined by its attributes but rather by its identity and should therefore be modeled as an entity. That way, the customer’s identity will stay consistent for as long as the customer exists in the system, regardless of how many state changes it goes through during that existence.
Choosing the right way to define an entity’s identity is essential and should be done carefully. The result of that definition will typically be in the form of an identifier. This means that the identity and uniqueness of an entity is determined by its identifier. Sometimes the identifier can be a generated unique ID, and sometimes it can be the result of applying some function to a selected set of attributes of the entity. In the latter case, you need to pay careful attention to not include any attributes that can change over time. This can be tricky because it’s hard to know which attributes might change in the future, even though they seem fixed right now. Therefore, it’s generally better to use generated unique IDs for identity.
It’s also important to note that what we mean by identity in DDD isn’t the same concept of identity, or equality, that’s built into many programming languages. In Java, for example, object equality is by default the same as instance equality. Unless you explicitly define your own method for equality, two object instances representing the same customer won’t be equal. That’s to say, the identity isn’t dependent on a specific representation of the entity. Regardless of whether the customer is represented as an object instance, a JSON document, or binary data, it’s still the same entity.
Local, global, or external uniqueness
The identity of an entity is important, but the scope in which its identity is unique can vary. Consider, for example, our customer entity. A system could use an identifier that’s unique not only to the current system but also outside of the system. This is an externally unique identifier. An example of this would be a national identifier like those used by many countries as a means to identify their citizens. In the United States, this would be the Social Security number. Using an externally defined identifier can, however, come with certain drawbacks, one of which is security implications, as you’ll see in later chapters.
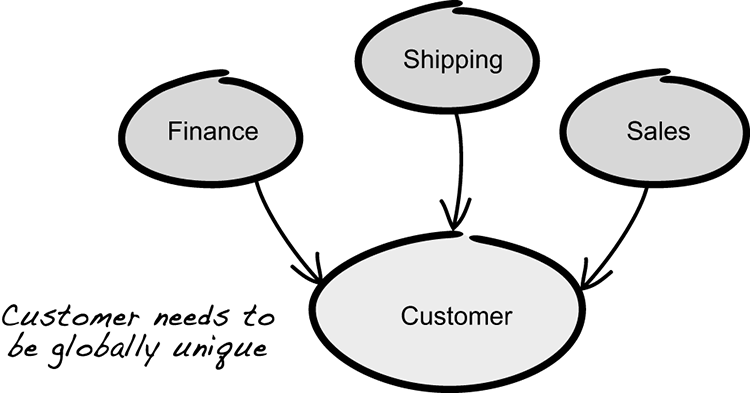
Figure 3.11 Some entities need to be globally unique.
Perhaps more common than externally unique identifiers are identities made to be unique within the scope of the system or within the boundaries of the current model. Such identifiers can be referred to as being globally unique. An example of this is a unique ID generated by the system when a new customer is created (figure 3.11). There can be some interesting technical challenges involved here that are worth pointing out. If you’re dealing with a distributed system and you need the IDs to not only be unique but also sequential, then generating them can be a technical feat in itself.
Some entities will be contained within another entity. Because such encapsulated entities are managed by the entity that holds them, it’s usually enough if they have an identity that’s only unique inside the owning entity. This identity is said to be local to the owning entity (figure 3.12). To go back to our customer entity, say your system is a customer management system for retail stores, and every customer belongs to one, and only one, store. In this case, the identity only needs to be unique within the store the customer belongs to. Modeling an identity to have local uniqueness can simplify the ID generation function. It also makes it clearer that the responsibility for managing those entities lies with the encapsulating entity.

Figure 3.12 Some entities only have local identities.
Keep entities focused
One thing to keep in mind when you’re modeling entities is to try to only add attributes and behaviors that are essential for the definition of the entity or help to identify it. Other attributes and behaviors should be moved out of the entity itself and put into other model objects that can then be part of the entity. These model objects can be other entities, or they can be value objects, which we’ll look at in the next section.
Entities are concerned with the coordination of operations on not only themselves, but also on the objects they own (figure 3.13). This is important because there can be certain invariants that apply to a certain operation, and because the entity is responsible for maintaining its internal state and encapsulating its behavior, it must also own the operations on the internals. Moving the operations outside of the entity would make it anemic.6
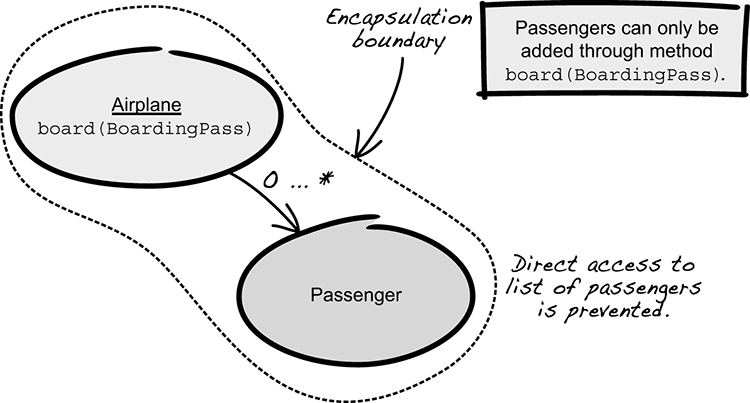
Figure 3.13 Entities coordinate operations.
When boarding an airplane, each passenger must present a boarding pass in order to verify that they’re about to enter the correct plane, which makes it easy to keep track of whether anyone is missing when the plane is about to depart. If passengers were allowed to freely walk in and out of the airplane, airline personnel would need to check all the boarding passes after everyone was seated. This would be a lot more time-consuming and possibly cause confusion if passengers had taken seats in the wrong plane. With this in mind, it makes sense to control and coordinate the boarding of passengers. The same goes for the software model to handle this.
If you model the airplane as an entity with a list of boarded passengers, then other parts of the system shouldn’t be allowed to freely add passengers to that list, as it would be too easy to bypass the invariants. A passenger should be added by a method board(BoardingPass) on the airplane entity. This way, the airplane entity controls the boarding of passengers and can maintain a valid state. It only allows boarding of passengers with a boarding pass that matches the current flight.
Entities play a central role in representing concepts in a domain model, but not everything in a model is defined by its identity. Some concepts are instead defined by their values. We use value objects to model such concepts.
3.2.2 Value objects
As you learned in the previous section, an entity is often made up of other model objects. Attributes and behaviors can be moved out of the entity itself and put into other objects. Some will be other entities, but many will be value objects. The key characteristics of a value object are as follows:
- It has no identity that defines it, but rather it’s defined by its value.
- It’s immutable.
- It should form a conceptual whole.
- It can reference entities.
- It explicitly defines and enforces important constraints.
- It can be used as an attribute of entities and other value objects.
- It can be short-lived.
As you’ll see in upcoming chapters, these properties are part of what gives value objects an important role to play when it comes to writing code that’s secure by design.
Defined by its value
Because a value object is defined by its value rather than its identity, two value objects of the same type are said to be equal if they have the same value. You only care about what they are, not who or which they are.7 Value objects have no identity. This is the total opposite of how we define entities.
Say you have the concept of money in your domain model. You can choose to model money as a value object because you don’t distinguish between different coins or bills. A $5 bill is worth as much as another $5 bill. It’s the value of the bill that matters, not which bill it is.
If you were modeling the domain of a central bank, then you probably would choose to model money as an entity, because in the view of a central bank, which is responsible for not only creating banknotes but also keeping track of them and eventually destroying them, each $5 bill is unique. It’s created and given a unique serial number that identifies it so it can be distinguished from other $5 bills. It remains in use until one day it’s time to destroy it (perhaps to be replaced by a new type of bill with a new identity). In the view of the central bank, money has an identity and a life cycle.
Immutable
Because a value object is defined by its value, it’s important to make sure that the value can’t be changed—if the value is changed, it’s no longer the same value object. This is why a value object must be immutable. If a value object were mutable, then changing its value could break the invariants of some other object containing the value object. Having immutable value objects also means it’s safe to pass them around as arguments and allows for various technical optimizations, such as reusing objects if memory is scarce and ease of use in multithreaded solutions.
Conceptual whole
A value object can consist of one or more attributes or other value objects. It can also reference, but not contain, entities. The reason for this is that the value of an entity can change. If the value object contained the entity rather than referencing it, then the value object itself would change whenever the entity changed. This would in turn break the immutability of the value object.
When modeling a value object and deciding what it should contain, it’s important that it forms a conceptual whole. In other words, it should be a whole value.8 This means that a value object shouldn’t be just a convenient grouping of attributes, objects, and references but should form a well-defined concept in the domain model (figure 3.14). This is true even if it contains only one attribute. When your value object is modeled as a conceptual whole, it carries meaning when passed around, and it can uphold its constraints.

Figure 3.14 A value object should form a well-defined concept.
In figure 3.14, you can see two different ways to model a customer and its related attributes. In the model on the left, all the attributes have been grouped together in a model object called CustomerInfo. In the model on the right, the attributes have been modeled so that they are grouped to form well-defined concepts: street, zip, and city have been grouped together in a value object called Address. Phone number and email have been put in a value object called ContactInfo. Age becomes its own value object.
It’s also important to understand that a value object isn’t just a data structure that holds values. It can also encapsulate (sometimes nontrivial) logic associated with the concept it represents. For example, a value object representing a GPS point could have a method that calculates the distance between itself and another GPS point using nontrivial numerical calculations.9
Defines and enforces invariants
Let’s say you have a value object Age that has one integer value, as seen in figure 3.15. In Java, for example, an integer can by default take the values from -231 to 231-1. You’d probably not consider that range to be typical for a person’s age. Therefore, you should model age as a value object with proper constraints or invariants so that its definition becomes clear (figure 3.15).

Figure 3.15 Value objects should enforce their own invariants.
You could during your modeling come to the conclusion that the age of a person should be between 0 and 150 years.10 Or maybe your domain doesn’t allow for young children, so the minimum age might be 18. Whatever range you choose, it’ll be a lot stricter than allowing the full range of a Java integer.
It’s also worth noting that the types of invariants we’re talking about aren’t the types of checks that are commonly referred to as validation. Validation checks are typically performed when asserting that a domain object is valid for a certain operation; it’s possible to perform a specific action on it. An example of validation would be to check if an order is ready to be sent to the shipping system. The validation could include verifying that the order has been paid for and that it contains the necessary address information. This type of validation often involves multiple domain objects and is generally performed as late as possible.11
3.2.3 Aggregates
When dealing with a model object that has a life cycle, such as an entity, it’s important to make sure that its state remains valid throughout its entire life cycle. This can require quite a bit of logic to implement and can involve code to handle locking mechanisms to support concurrent operations and managed updates to persistent storage. Regardless of whether the entity is being persisted or not, the state change can be said to take place within a transaction.12
Transaction management is usually feasible when it comes to a single entity. In reality, your domain model is typically not that simple and involves many connections between various entities and value objects. This means the consistency you need to manage spans over multiple domain objects. Once faced with such a situation, the question quickly arises of how to manage transactions that span multiple elements in the model. This is where the aggregate comes in.
An aggregate is a conceptual boundary that you use to group parts of the model together. The purpose of this grouping is to let you treat the aggregate as a unit during state changes; it’s the boundary within which transactions must be managed. The boundary that’s defined by the aggregate isn’t randomly chosen or chosen from a technical point of view. It’s carefully selected based on deep insights of the model.
When modeling an aggregate, it must follow a strict set of rules for it to work as intended and to fulfill its purpose. The following lists these rules as put forward by Eric Evans:13
- Every aggregate has a boundary and a root.
- The root is a single, specific entity contained in the aggregate.
- The root is the only member of the aggregate that objects outside the boundary can hold references to. Thus
- The root has global identity.
- The root controls all access to the objects within the boundary.
- Entities other than the root have local identity. Their identities don’t have to be known outside of the aggregate.
- The root can pass references to internal entities to other objects, but those references can only be used transiently and can never be held onto.
- The root can pass references of value objects to other objects.
- Invariants between the members of the aggregate are always enforced within each transaction.
- Invariants that span multiple aggregates can’t be expected to be consistent all the time, but they can eventually become consistent.
- Objects within the aggregate can hold references to other aggregates.
This is quite a comprehensive set of rules, and you might want to go through them again and think about their meaning and the implications each of them will bring to the design of not only your model but also your code. There are, however, a couple of traits that we’d like to expand on to make things clearer.
The aggregate is a conceptual boundary, and it contains an entity that’s the root of the aggregate. In general, when implementing aggregates, the root entity and the aggregate will be the same object. Reasoning about them might become easier if you think of them as being the same.
The root of the aggregate is the only point of reference outside of the boundary. The root also controls all access to everything within the boundary. This makes the root the perfect place for upholding all the invariants that span across the objects within the boundary. And it can’t be bypassed, as long as you stick to the rules on how to model aggregates. Another implication of the root being the only point of reference is that the root is the only thing that can be accessed through a repository (see sidebar). This again is a way to control how an aggregate is accessed and to make sure an entity within the aggregate can’t be manipulated directly by objects outside of the aggregate.
Aggregates, with their boundaries and upholding of consistent state, turn out to be of importance when you start looking at how to use them to drive security in your code. Let’s take a look at an example of how you could model a simple aggregate next.
Our example model consists of a company and its employees. We’ll make the company an entity because it has a clear identity and, because our system can handle many companies, it also needs to be globally identifiable. The company has a name, but the name is merely a value, so we’ll make it a value object. It also has employees who work at the company. An employee definitely has an identity, so it’s also modeled as an entity. An employee always belongs to a company, so it becomes a child entity of the company. Each employee will have a specific role, but that’s also a value, so it becomes a value object. The resulting model can be seen in figure 3.16.

Figure 3.16 The company domain model
After discussing the nature of an employee together with the domain experts, you realize that an employee doesn’t have to be identifiable outside of the company. The employee object can have local identity. You also realize that when roles are assigned to employees within the company, there are certain roles that can only be held by one person at a time. There can, for example, only be one CTO at any given point. The same goes for many other roles. To uphold these required invariants, the company entity should control the assignment of roles to employees. This leads you to the insight that the company, together with its child objects, should be modeled as an aggregate. You make the company the root of the aggregate. You can see the result in figure 3.17.

Figure 3.17 The company modeled as an aggregate
This means that the company, which is globally identifiable, can be referenced and looked up by others, but the only way to get to an employee is to go through the aggregate root, the company. The same goes for assigning new roles to employees. The role assignment is handled by a method on the company. Because all operations on the aggregate are controlled by the root, it becomes a straightforward task to uphold the invariants regarding the employees.
In this section, you’ve learned the basics about the fundamental building blocks used to create domain models in DDD. We’ve gone through a lot of material so far, and it might take some time to digest all this information properly. But if you stay with us, you’ll learn about bounded contexts—the next important concept from DDD that you need to be familiar with before you get into the remaining chapters of this book.
3.3 Bounded contexts
Another interesting concept is the bounded context pattern, which defines the applicability of the domain model. As it turns out, it’s not only essential in DDD, it’s also important from a security perspective. Some complex attacks are easier to understand when using bounded contexts as a basis for the analysis. To see this, you need to fully understand the concept, and therefore we’ll start by diving into the semantics of the ubiquitous language.
3.3.1 Semantics of the ubiquitous language
Ubiquitous is defined as “existing or being everywhere at the same time.”14 In DDD, this translates to a language spoken everywhere at all times, by everyone, to promote clarity and common understanding—a ubiquitous language as illustrated in figure 3.18.
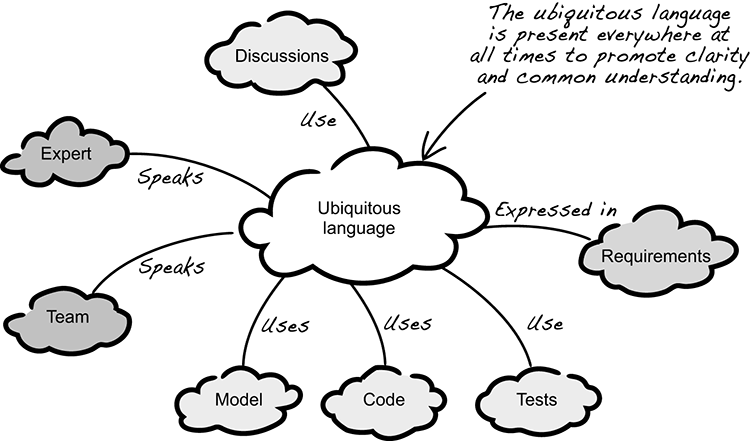
Figure 3.18 Ubiquitous language is present everywhere, at all times, to promote clarity and common understanding.
It’s easy to think that everywhere, at all times, by everyone means there should be a unified language with terms, operations, and concepts that capture the entire business, but that’s a huge misunderstanding. Anyone who has tried this knows it’s doomed to fail because it’s too complex. And the reason is semantics.
A term or concept can have the same name in various parts of the business, but each usage can have a different meaning. For example, consider the word package. If you ask someone in the shipping department, they’ll say that it’s a box, but in the IT department, they’ll say that it’s a logical grouping of files in the codebase—both departments use the term package, but with different semantics. Trying to capture this in a unified language is probably not a good idea because it requires a new term that captures both meanings. The obvious conclusion is to allow two coexisting languages instead of a unified language with imprecise semantics. With this in mind, let’s see how the ubiquitous language relates to the model and the bounded context.
3.3.2 The relationship between language, model, and bounded context
The relationship between language, model, and bounded context becomes clear when you see it from a semantic point of view. A model is an abstraction of the domain in which concepts, relationships, and terms of the ubiquitous language are found. This makes the language and model tightly coupled, not only through the terms and relationships but also through semantics—a concept found in the model must have the same meaning in the language and vice versa.
As long as the semantics of terms, operations, and concepts remain the same, the model holds. But as soon as the semantics change, the model breaks, and the boundary of the context is found. Realizing this is important because this is where the meaning of a term could change, only because it crossed the boundary. That means that everything within the context adheres to the semantics of the model, but outside the boundary, the same term can have different semantics. This certainly makes sense, but it feels a bit theoretical.
Let’s dive into an example where we define the ubiquitous language, create a model, and use it to identify the semantic boundary of a context.
3.3.3 Identifying the bounded context
When identifying a bounded context, a good starting point is to analyze the ubiquitous language. For example, let’s consider the following conversation between a developer and a domain expert in the Shipping Department:
Developer: “What characterizes an order?”
Expert: “Well, an order contains products that are sellable and nonsellable items.”
Developer: “Not sure I understand. What do you mean by nonsellable products?”
Expert: “Nonsellable products are items that are bundled with sellable products when shipped as a package to their destination.”
Developer: “Oh, I see. Nonsellable items are products without a price?”
Expert: “No no, all products have a value, but bundled products have a price of zero, so they get included for free.”
Developer: “Hmm, OK, I guess that makes sense.”Up to this point, lots of confusion exists, but it’s possible to identify significant terms and manifest them as a raw version of a domain model, as seen in figure 3.19.

Figure 3.19 Raw domain model
One of the core principles of the ubiquitous language is to avoid ambiguities, because they create a lot of confusion and misunderstanding. We see this in figure 3.19, where the model has lots of ambiguity and duplicated concepts. Let’s get back to the conversation and see how the language and model evolve:
Developer: “I’m a bit confused about the terminology. Could we agree on using some of the terms?”
Expert: “Sure, any particular ones in mind?”
Developer: “It seems we only have products—is it OK to stop using words like items, things, nonsellable, and sellable?”
Expert: “OK, that makes sense. From now on, we’ll use the term product for all of these.”
Developer: “Included and bundled mean the same thing, right?”
Expert: “Yes, so let’s only use bundled.”
Developer: “What about price and value?”
Expert: “Same thing. Let’s use price.”
Developer: “Why do we need to care whether a product is free or not?”Expert: “You’re right. We don’t. Let’s not use free.”
This distillation process results in a much tighter language and a refined domain model, as seen in figure 3.20.
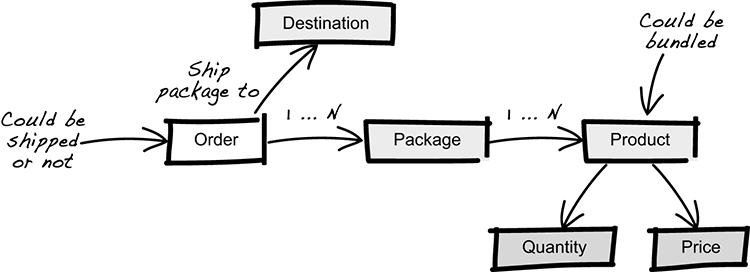
Figure 3.21 Final domain model
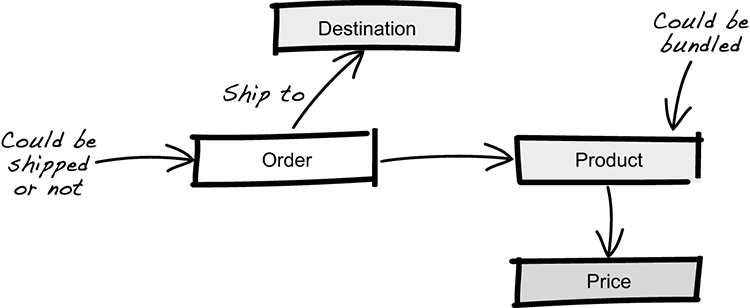
Figure 3.20 A refined domain model with less redundancy
But sometimes, distilling also uncovers missing terms, and this is the case here as well:
Developer: “An order can have one or more products?”
Expert: “Yes, that’s correct. But an order without products isn’t much of a package.”
Developer: “Package?”
Expert: “Oh, sorry. Yes, a 'package' is what we call the box in which we ship everything.”
Developer: “OK, makes sense. But how do we know how many products we need to ship in a package?”
Expert: “Well, the quantity of each product is specified in the order.”
Developer: “Ah, I see. Let’s introduce 'quantity' and 'package' in our ubiquitous language and add them to the model.”
After this last revision (figure 3.21), the developer and expert are quite confident that they share the same view and understanding of an order.
But how far does the model reach into the organization? When does the model no longer hold? Determining this is the key to finding the boundary of the context. The developer starts asking around, and everyone in the Shipping Department seems to have a common understanding. But when talking to an expert in the Finance Department, the model suddenly breaks:
Developer: “Could you please have a look at our model of an order?”
Finance Expert: “Sure. The model makes sense, but you seem to miss a lot of important concepts.”
Developer: “Really? Please explain.”
Finance Expert: “The payment information and due date are missing. Also, the reserved amount doesn’t seem to be represented.”
Developer: “Aha. We seem to have a different definition of an order. Thanks for your time.”
As soon as the semantics of the model no longer hold, the boundary of the context is found. Finding where the model’s semantics didn’t hold, the developer quickly realizes that an order in the Finance domain is something different than in the Shipping domain. This tells us where the context boundary is. This can be illustrated as two separate contexts, where an order is present in both but with different meanings, as seen in figure 3.22.
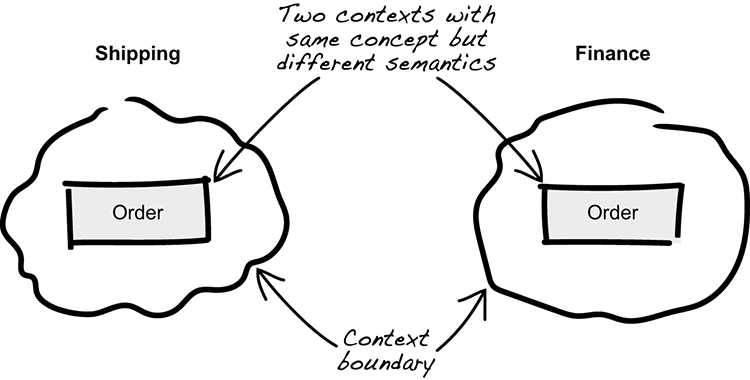
Figure 3.22 Two contexts with the same concept but with different semantics
But what happens if you need to communicate and pass an order between the contexts? Are there any other concepts that are similar but with different semantics? This brings us to the next topic: interactions between contexts.
3.4 Interactions between contexts
The context boundary is interesting from a security perspective when you start thinking about interactions between contexts. When data crosses a boundary, it implicitly accepts the semantics of the receiving context’s ubiquitous language and model. This implies that every time no action is taken, a potential security vulnerability opens. Although this might be obvious, problems of this kind are surprisingly common. Ironically, the root cause might be the attempt to satisfy DRY—Don’t Repeat Yourself. Andrew Hunt and David Thomas defined the principle as:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
—Andrew Hunt and David Thomas, The Pragmatic Programmer (Addison-Wesley, 2003)
Many interpret this as avoiding syntactic duplication (for example, the result of copying and pasting code), but the principle is about semantics. And this brings us back to the ubiquitous language.
The ubiquitous language requires the semantics of the domain model to be unambiguous throughout the context. But if you apply a syntactic interpretation of DRY, the method of how you share data between contexts suddenly becomes a technical matter rather than semantic. And this is a huge problem, because if models are shared to reduce syntactic duplication, but certain concepts mean different things, it opens the door to all sorts of craziness—including security weaknesses. To illustrate this, let’s revisit the example with a Shipping and a Finance context, but this time with a shared model to reduce syntactic duplication.
3.4.1 Sharing a model in two contexts
Both Shipping and Finance use concepts such as order, product, and price. Having a shared model is indeed compelling, as it minimizes duplication. But to do this, you need a few more concepts from the Finance domain, as seen in figure 3.23.
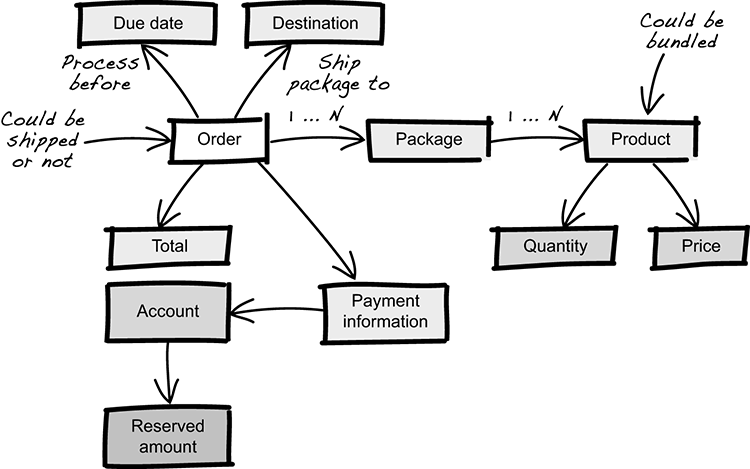
Figure 3.23 A unified order model that’s shared between the Shipping context and the Finance context
At first, having a unified model is a great success; the only apparent downside is a rich model with some unused concepts. But let’s see what happens when a new business requirement is introduced in the Shipping context:
Expert: “To simplify customs declarations for international shipments, we need to list the actual value of a package.”
Developer: “OK. So how should we treat bundled products?”
Expert: “Well, previously we made the product free by faking the price by setting it to zero, but that’s no longer OK.”
Developer: “Right, so is it OK to just remove the faked price?”
Expert: “Yes, the sum of all prices is the actual value of the package, so that should work.”
Developer: “And then we deduct the bundle prices from the total, right?”
Expert: “No, the reserved amount is what’s charged by Finance, so we don’t need to deduct anything.”
Developer: “OK, that makes sense. I’ll only remove the faked price then.”
Making the changes doesn’t require much effort, and initially everything works fine, but after a while, strange behaviors start to emerge in Finance. For some reason, every now and then the invariant reserved amount ≥ sum of all prices is false. This seems like a minor problem because it only happens when the products are bundled. But it does, in fact, start a full-blown security investigation. A violation of the invariant is the same as order tampering, and that’s a serious security problem!
The investigation doesn’t show any security breach, but it’s interesting how a simple change could lead to all of this. Analyzing it further shows that the root cause is, in fact, having one model to represent two conceptual views of an order. The invariant reserved amount ≥ sum of all prices only makes sense in the Finance context. But as a direct consequence of sharing a model, the Shipping context is forced to respect the invariant, even though it doesn’t make sense. Obviously, this isn’t a good thing, because it prevents each context from being independent and the master of its own model. But if you don’t share a model, how do you know what concepts need special attention when communicating across context boundaries? The solution is to draw a context map.
3.4.2 Drawing a context map
A context map is a conceptual view of how different contexts interact. This could be a graphical drawing described in text or simply an understanding communicated between teams. Regardless of how it’s manifested, the key point is that it helps identify concepts that cross semantic boundaries.
An incorrect mapping is often the root cause of misunderstandings that can become exploitable. Identifying the context boundary is of great importance therefore, but it can be easier said than done. If you don’t know where to start, a good strategy is to use Conway’s Law as a starting point.15 Mel Conway published the paper “How Do Committees Invent?” in 1968 with the thesis:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
—Mel Conway, “How Do Committees Invent?” (Datamation, 1968)
The implication of the thesis is that the communication structures that exist in the organization are often reflected in the architectural design of the system. This also seems to apply to how bounded contexts are defined. As many teams tend to organize around subsystems, bounded contexts often follow the same rules. Laying out the teams is therefore a good starting point when trying to identify the bounded contexts for your map.
To illustrate what a graphical representation of a context map might look like, we need to revisit the Shipping and Finance contexts one more time. To gain deeper insight, a good starting point is to draw a simple, high-level picture of the system interactions when a new order is processed (figure 3.24).

Figure 3.24 Interaction between Finance and Shipping
Here’s the interaction between Finance and Shipping:
- Finance receives a new order.
- The total value of the order is reserved on the account specified by the payment information.
- Finance sends the order to Shipping for processing.
- Shipping processes the order and ships it.
- Shipping notifies Finance with an updated status.
- Finance completes the financial transaction.
The interaction flow diagram is easily converted into a context map where it becomes clear that the Shipping context is downstream of the Finance context (figure 3.25). This might seem obvious, but the mere understanding that a Finance order must be translated to a Shipping order makes a huge difference. The relationship makes it clear that explicit mapping is required and that communication between the teams is needed to ensure success.

Figure 3.25 The Shipping context is downstream of the Finance context.
You have now gained a conceptual view of why bounded contexts are important and how context maps are created, but we still need to show you how they relate to security. In the upcoming chapters, you’ll see how bounded contexts help when analyzing code from a security point of view; for example, in chapter 9, when looking at failure handling, or in chapters 12 and 13, when working with legacy code.
In the next chapter, you’ll learn about code constructs that promote security by using ideas from this chapter combined with concepts from other fields. As a result, you’ll be able to immediately apply them in your everyday work and learn how to spot exploitable weaknesses in your existing codebase.
Summary
- Building domain models is a good way to promote deep learning about the domain.
- A domain model should be a strict and unambiguous representation of the domain that captures only the most important aspects.
- When creating a domain model, you make a choice among many possible models.
- The domain model forms a language for communicating about the system.
- Entities, value objects, and aggregates are the basic building blocks for your domain model.
- Entities have an identity that’s consistent during their life cycle and can contain other entities or value objects.
- The uniqueness of entities always has a scope, and that scope depends on your model.
- A value object doesn’t have an identity but rather is defined by its value.
- A value object must always be immutable and should form a conceptual whole.
- An aggregate is a conceptual boundary that groups together other model objects and is responsible for upholding invariants among those objects.
- An aggregate always has an aggregate root and, in code, that root is typically the same as the aggregate.
- The aggregate root has global identity because this is the only part of the aggregate that other parts of the model can hold a reference to.
- The ubiquitous language is spoken by everyone on the team, including domain experts, to ensure a common understanding.
- The domain model is bound by the semantics of the ubiquitous language.
- The bounded context is the context in which the semantics of the model hold. As soon as the semantics change, the model breaks and the boundary of the context is found.
- Using Conway’s Law is a good starting point when trying to find the boundary of a context.
- Data crossing a semantic boundary is of special interest from a security perspective because this is where the meaning of a concept could implicitly change.