
10
Benefits of cloud thinking
This chapter covers
- How externalizing configuration improves security
- Structure as separate, stateless processes
- How centralized logging improves security
- Structuring admin functionality
- The three R’s of enterprise security
To successfully run applications in a cloud environment, you need to design them in a way that enables you to fully take advantage of the possibilities the cloud can give you. This means your applications are required to adhere to certain principles and display certain properties, such as being stateless or environment-agnostic. Cloud environments bring a new set of standards for building applications. An interesting observation is that this new way of building applications and systems has proven to be beneficial regardless of whether you’re running them in the cloud or not. Even more interesting is that we’ve found there are also benefits from a security perspective.
This chapter starts by introducing the twelve-factor app and cloud-native concepts. We’ll then go on to show you cloud design concepts for handling things such as logging, configuration, and service discovery. Moreover, you’ll learn why and how they improve security. What you’re not going to learn about in this chapter is how to manage security on cloud platforms, how to harden cloud platforms, or whether a public cloud environment is more secure than an on-premise setup (or vice versa). Those are all interesting topics, but they are topics for another book. The focus here is design concepts with security benefits.
Once you’ve learned about the fundamental cloud concepts with security benefits, you’ll see how they all come together and work as enablers for something called the three R’s of enterprise security. The three R’s —rotate, repave, repair—is an approach for creating secure systems that is radically different from traditional approaches but will allow you to (equally) radically improve your security to a level where only the cloud—sorry, the sky—is the limit.
10.1 The twelve-factor app and cloud-native concepts
If you’re new to building and designing software for the cloud, there are two concepts we recommend looking at: the twelve-factor app methodology and cloud-native development. Together, these provide a condensed, easy-to-consume compilation of several design concepts that have turned out to be important and useful in the cloud era. In this chapter, we’ll use the twelve-factor app methodology and the cloud-native concepts as a base for discussing the security benefits you can gain by applying cloud design concepts to your software, regardless of whether you’re running it in the cloud or on-premise. We’re not going to give you a full explanation of these concepts, because that would be beyond the scope of this book, but in order to understand where the topics in this chapter come from, you’ll get a brief introduction here.
The twelve-factor app is “a methodology for building software-as-a-service” applications.1 It was first published somewhere around 2011, and its main purpose was to provide guidance to avoid common problems in modern application development, as well as providing a shared terminology.2 The twelve factors include3
- Codebase—One codebase tracked in revision control, many deploys
- Dependencies—Explicitly declare and isolate dependencies
- Config —Store configuration in the environment
- Backing services—Treat backing services as attached resources
- Build, release, run —Strictly separate build and run stages
- Processes—Execute the app as one or more stateless processes
- Port binding—Export services via port binding
- Concurrency—Scale out via the process model
- Disposability—Maximize robustness with fast startup and graceful shutdown
- Dev/prod parity —Keep development, staging, and production as similar as possible
- Logs—Treat logs as event streams
- Admin processes—Run admin/management tasks as one-off processes
These twelve factors are all interesting design concepts in and of themselves, and if you aren’t familiar with them, we recommend taking the time to read up on them to fully understand them. But there are some that we’ve found are of special interest from a security perspective because they promote the security of a system when applied correctly (even if that’s not why they were chosen to be one of the twelve factors). You’ll learn exactly how they relate to security later in this chapter.
The twelve-factor app methodology provides easy-to-follow guidelines for building applications that behave well in the cloud. The twelve factors are good design practices, but they aren’t all-encompassing. Because of this, there was a need for a more general term to describe applications that are designed to behave well in the cloud, and that term is cloud-native. You’d be hard-pressed to find one single definition of this term, because it can mean slightly different things to different people. We think the definition put forward by Kevin Hoffman in his book Beyond the Twelve-Factor App (O’Reilly, 2016, p. 52) is a reasonable one:
A cloud-native application is an application that has been designed and implemented to run on a Platform-as-a-Service installation and to embrace horizontal elastic scaling.
From the perspective of this chapter, the interesting part of this definition is that a cloud-native application is designed to be run on a Platform-as-a-Service (PaaS).4 The implication of this is that, as a developer, you’re focusing on functional requirements and leaving the nonfunctional ones to the platform. As you’ll see in this chapter, a good PaaS provides you with tools you can use to create a higher level of security when designing your systems. Once you understand the concepts behind these tools, you can apply those concepts to your design regardless of whether you’re using a PaaS or running on barebone hardware.
Now that you understand the background of the topics in this chapter, let’s start by looking at how the design practice of moving application configuration to the environment can help promote better security.
10.2 Storing configuration in the environment
Most applications depend on some sort of configuration to run properly, such as a DNS name or a port number. Although configuration management is important, it’s often seen as trivial compared to writing code. But if you consider it from a security perspective, it suddenly becomes a challenge. This is because configuration isn’t always about nonsensitive data. Sometimes you need to include secrets as well—for example, credentials, decryption keys, or certificates—and that’s a lot more complicated.
In the cloud, it’s recommended to externalize configuration because an application often needs to be deployed in different environments, like development, user acceptance testing, or production. Unfortunately, externalizing configuration increases the overall complexity of a system because it needs to dynamically load configuration at runtime. Consequently, not many use this pattern for applications running on-premise, because the environments seldom change. But seen from a security perspective, code and configuration should always be separated, regardless of whether you’re running on-premise or not. This makes it possible to automatically rotate keys and apply the concept of ephemeral secrets. To visualize this, it’s important to understand why configuration that varies between deployments belongs to the environment and not in code. Let’s look at an example where the anti-pattern of storing environment configuration in code is used.
10.2.1 Don’t put environment configuration in code
Picture an application connected to a database. (It’s not important what the application does—it could be anything from a full-blown webshop to a microservice. What’s important is that it uses the anti-pattern of storing environment configuration in code, which becomes a security issue if you store sensitive data.) The application is a prototype, but the code is in pretty good shape, and management decides to proceed with a full-scale project. There’s no time to redo all the work, and the team is instructed to polish things up to ensure it’s ready for production. Because the application is a prototype and only deployed in the development environment, configuration data has been implemented as hardcoded constants all over the codebase.
The strategy of placing environment configuration in code sounds naive, but in our experience, many developers choose this approach, especially when prototyping, because it’s easy to start with. The problem is that when things get more complicated (for example when adding secrets), the strategy tends to remain. In listing 10.1, you see an example of how credentials have been added as constants in code. This should raise a warning flag, because it allows anyone with access to the codebase to read the secrets. But it follows the same pattern as other configuration values, so why bother to do anything different?
Listing 10.1 Content management system connector class with secret values
public class CMSConnector {
private static int PORT_NUMBER = 34633;
private static long CONNECTION_TIMEOUT = 5000;
private static String USERNAME = "service-A"; ①
private static String PASSWORD = "yC6@SX5O"; ②
...
}
From a development perspective, it makes sense to add credentials the same way as other configuration values, because a username or password isn’t much different from a port number; it’s just a configuration value. But from a security perspective, it’s a disaster, because placing credentials in code makes them more or less public. Unfortunately, the security aspect isn’t what tends to trigger the need for a redesign. Instead, it’s the need to deploy to multiple environments, because each environment has a different configuration. Consequently, many choose to group configuration values by environment and move them into resource files—a strategy that works but makes things worse from a security perspective because now secrets also end up on disk.
10.2.2 Never store secrets in resource files
By placing configuration in resource files, you allow code and configuration to be separated. This turns out to be a key component in allowing deployment to multiple environments without changing any code, because an application can then load environment-specific configuration data like an IP address or port number at runtime. But although this sounds great, it’s unfortunately an anti-pattern from a security perspective because it yields the same problems as storing secrets in code. The only difference is that sensitive data now also ends up on disk, which means that anyone with server access could potentially access the information—not good! But nevertheless, this pattern is a common choice in many applications, so let’s have a deeper look at it.
In listing 10.2, you see a resource file (written in YAML) with two environments, dev and prod, where each has a unique set of configuration values for the content management system (CMS).5 This file is bundled with the application, and the appropriate set of configuration values is loaded at runtime. This way, the same codebase can be deployed in dev and prod without the need to rebuild the application.
Listing 10.2 Resource file with configuration for all environments
environments:
dev: ①
cms:
port: 34633 ②
connection-timeout: 5000 ②
username: dev-service-A ②
password: spring2019 ②
prod: ③
cms:
port: 34633 ④
connection-timeout: 1000 ④
username: service-A ④
password: yC6@SX5O ④
At first glance, this makes perfect sense because it separates the environments, but it makes the security situation worse. To start with, as with storing secrets in code, anyone with access to the codebase is able to read the sensitive data without creating an audit trail. This sounds like a small problem, but accessing sensitive data without creating an audit trail makes it impossible to know how data has been shared—and that’s certainly a big problem! Unfortunately, this can’t be addressed adequately when storing secrets in code or in resource files, and the problem is therefore often ignored.
Another security problem with storing sensitive data in resource files is that data is stored on disk while the application is running. Secrets such as passwords and decryption keys can then become accessible outside of the application, regardless of whether the application is running or not, which requires you to encrypt all resource data. This seems acceptable at first, but it does add significant complexity; for example, where do you store the decryption key, and how do you provide it to the application? It almost sounds like the chicken-and-egg problem, doesn’t it?
A third issue, which is less obvious, is that secrets are shared with everyone in the development team, regardless of whether they’re stored in code or in resource files. Ideally, you shouldn’t need to care about credentials, certificates, or other sensitive information when designing an application. Secrets should be provided at runtime, and the responsibility for managing them should rest with a limited set of people, not everyone with access to the codebase. Unfortunately, not many developers realize the problems with this approach until the day they need to share code with an external party or choose to go open source, then it suddenly becomes extremely important that secrets aren’t leaked. But addressing this at a late stage could be a costly operation. Let’s see how you can solve this and the other problems up front by using a better design.
10.2.3 Placing configuration in the environment
The security problems discussed so far have in common that code and configuration values haven’t been fully separated, which becomes a problem when dealing with secrets—so what’s the best way to separate code and configuration? Well, the idea is simple. Any configuration value that changes between deployments should be provided by the environment instead of placed in source code or in resource files. This makes your application environment-agnostic and facilitates deployments in different environments without changing any code.
There are several ways to do this, but a common practice used in the cloud and suggested by the twelve-factor app methodology is to store configuration data in environment variables; for example, in env variables if you’re using UNIX. That way, an application only needs to depend on a well-defined set of environment variables that exists in all environments to retrieve the necessary configuration values at runtime (figure 10.1).
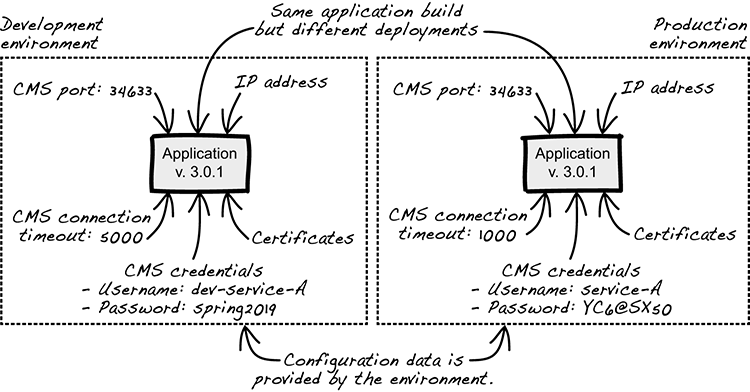
Figure 10.1 Configuration data provided by the environment
The concept is indeed elegant, but how does it affect the security issues identified earlier: audit trail, sharing secrets, and the need for encryption?
Audit trail
Moving sensitive data into the environment doesn’t solve the problem of change management per se. But from a development perspective, using this pattern makes life a whole lot easier because it reduces implementation complexity. This is because the responsibility of creating audit trails shifts from the application code to the infrastructure layer, which means it becomes an identity and access management (IAM) problem. For example, only authorized accounts are allowed to access the environment, and doing so should create an audit trail that contains every operation performed.
Sharing secrets
The strategy of storing secrets in environment variables is an interesting alternative to placing them in code or in resource files. This is because development and configuration management can be separated by design, which in turn allows secrets to be shared only among those responsible for an environment. Application developers can then focus on using secrets rather than managing them, which definitely is a step forward. But unfortunately, this doesn’t solve the security problem completely. In most operating systems, a process’s environment variables can be flushed out, which becomes a security problem if secrets are stored in clear text. For example, in most Linux systems, it’s possible to inspect environment variables using cat /proc/$PID/environ (where $PID is your process ID). The question is, therefore, how to address this—perhaps using encryption is a way forward?
Encryption
Storing encrypted secrets in environment variables certainly minimizes the risk of leaking sensitive data, but the general problems with decryption remain. For example, how do you provide the decryption key to the application? Where do you store it? And how do you update it? These are questions that must be considered when choosing this design. Another strategy, which we prefer, is to use ephemeral secrets that change frequently in an automatic fashion, but this requires a different mindset—we’ll get back to this at the end of the chapter, where we talk about the three R’s of enterprise security.
You’ve now learned why code and configuration should be separated and why secrets shouldn’t be stored in environment variables. But what about building and running an application—are there any security benefits you can learn from the cloud? There certainly are, so let’s see why you should run your application as separate stateless processes in your execution environment.
10.3 Separate processes
One of the main pieces of advice on how to run your application in a cloud environment is to run it as a separate stateless process. To our delight, this design guideline has security benefits as well.
The main direct security advantage is improving the availability of the service; for example, by easily spinning up new service instances when needed to meet a rise in client traffic. You also get some improvement in integrity because you can easily decommission a service instance with a problem, be it memory leakage or a suspect infection. Later in this chapter, you’ll see how this ability also lays the foundation for other designs that improve confidentiality, integrity, and availability. The three R’s of enterprise security use this ability to its pinnacle, as you’ll see in the closing section of this chapter.
Let’s elaborate a little about the practice of separate processes. A cloud application should be run as a specific process (or processes), separated from the activity of building it or deploying it to the execution environment. These processes shouldn’t keep the client state between requests and should only communicate via backing services, like a database or a distributed cache, that are plugged in. Let’s dive a little deeper into what that means.
10.3.1 Deploying and running are separate things
First, let’s consider the separation of deploying the service and running the service. Deploying the service is most often done by an operating system user with high privileges, enough to install dependent packages or reconfigure directories. Root access (or similar) can even be needed for deploying new versions of the software. Most of these privileges aren’t needed to run the application. A web application might only need privileges for opening a socket for incoming HTTP requests, opening a socket to connect to the database, and writing to some temporary directory it uses while processing requests. The system user running the web application doesn’t need to have the broad privileges required for deployment and installation.
10.3.2 Processing instances don’t hold state
Second, an application process shouldn’t depend on state from one request being available to another. Sometimes applications assume that two requests from the same client end up at the same server process. For example, in an online bookstore application, the customer might first add a copy of Hamlet to the shopping cart and later add a copy of Secure by Design. The requests are handled by a set of active instances. In figure 10.2, you can see some ways they are handled and end up in the database.
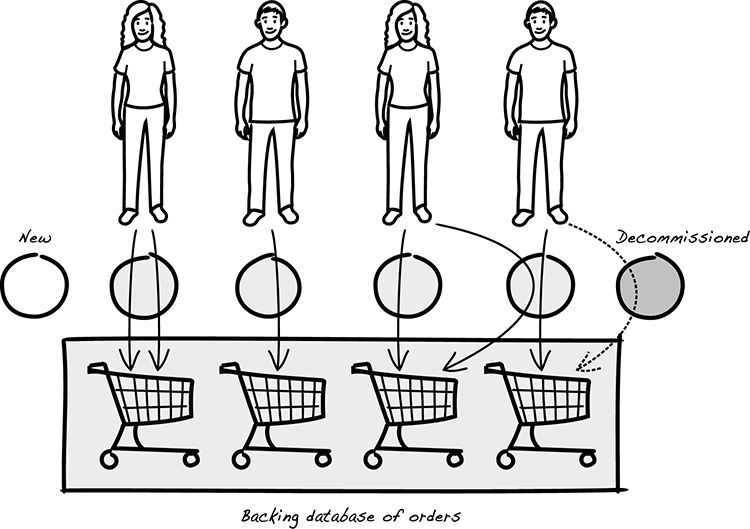
Figure 10.2 Processes serving stateless requests, only communicating via backing services
As you see in the figure, a well-designed cloud application shouldn’t assume a specific instance is linked to a specific client. Each and every call from each client should end up at any of the instances that are on duty at the moment.
Let’s think about those two consecutive requests from the same customer: one for Hamlet and the other for Secure by Design. These two requests might be served by the same instance, but a well-designed cloud application shouldn’t rely on that. The second request might be served by another instance, and it should work equally well. The second instance might not have even existed when the first request was processed; it might be a new instance that has been spun up to meet a surge in load. Similarly, the instance that served the request for Hamlet might not still be around when the request for Secure by Design comes in. That first instance might have been killed in the meantime because of some administrative routine. Whatever happens to the instances, it shouldn’t matter which route the request takes—the result should be the same. For this reason, the processes shouldn’t save any client conversation state between calls. Any result of processing a client request must either be sent back to the client or stored in a stateful backing service, usually a database.
If the process is doing some heavy or long-running processing, we advise you to split the work into smaller steps and keep a status flag that says something to the effect of “This piece of work has been imported but not structured or analyzed yet.” Also, the flag should be updated by each process that advances the computation a step.
A process might well use a local filesystem to temporarily save a result during its processing, but the filesystem should be treated as ephemeral and unreliable as primary memory. You can’t consider the work permanently saved before the processing is completed and the result committed to the backing database. At that point, it’s advisable to update any status flag about how far the processing has proceeded (for example, “Imported and structured, but not analyzed”). Bear in mind that a process might be interrupted or killed at any moment, even in the middle of long-running processing.
The filesystem shouldn’t be relied on as a safe, longtime storage in the way you’re used to from computing on a machine with a local filesystem. Some cloud environments even forbid using local files, and any attempt to use APIs to reach them throws an exception.
10.3.3 Security benefits
Separating installation and deployment from running the application works well with the principle of least privilege. We’ve too often seen applications running client requests in a process where the system user has root privileges. If an intruder is able to compromise such a process, it can cause severe damage. But if the process can do only what the application is intended to do—contact the database or write to a log file, for example—the effects will be contained. The attacker can’t compromise the integrity of the system itself.
When processes are stateless and share nothing (except backing services), it’s easy to scale capacity up or down according to need. Obviously, this is good for availability: fire up a few more servers, and they immediately share the load. You can even do zero-downtime releases by starting servers with a new version of the software at the same time you kill the old servers.
The ability to kill any server at any time is also good for protecting the integrity of the system. If there’s any suspicion that a specific server has been infected, it can immediately be killed and replaced. Any work in progress on the server will be lost, but the data will still be in a consistent state, and the new server will be able to redo the work. In the section on the three R’s of enterprise security, you’ll see how to elevate this ability to effect a drastic increase in security.
Now that you’ve seen the security benefits of running an application as separate processes and having resources as attached backing services, let’s have a closer look at one of those resources—logging.
10.4 Avoid logging to file
Logging is a fundamental part of most applications because it helps in understanding why something has happened. Logs can contain anything from user interactions to debug information to audit data, information that most people would consider boring and irrelevant but that, from a security perspective, is like El Dorado.6 This is because log data tends to include invaluable information, like sensitive data and technical details that could be useful when exploiting a system.
From a security perspective, logs should be locked away and never looked at; but in practice, logs are consumed in a completely different way. For example, when unexpected behavior or bugs are analyzed, logs are used as the primary source of information. This means logs must be accessible at all times, but the data they contain must also be locked away because of its sensitive nature—a contradiction in terms, it seems.
But great security and high accessibility aren’t mutually exclusive features. In fact, there’s a design pattern used by cloud-native applications that addresses this dichotomy; it’s called logging as a service. Not many see it as a universal pattern though, and people often choose to log to a file on disk, favoring the needs of development and failure investigation only. Before learning more about why logging as a service is preferable, you need to understand what security issues logging to a file on disk brings, so let’s analyze it from a CIA perspective.7
10.4.1 Confidentiality
Many choose to log to a file on disk for several reasons. One is reduced code complexity: logging can be implemented using standard output stream (stdout) or your favorite logging framework. Another is the ease of access during development or failure investigation, because logs can be accessed via remote login to a server. The first reason, in fact, yields better security, because reduced complexity is always good, but the latter is where the security problems start. Allowing logs to be easily fetched is the key to high accessibility, but it also introduces the problem of confidentiality.
Many choose to log massive amounts of data when the trace or debug logging level is enabled. This certainly helps during failure investigations, but the logged information could be sensitive and be used to identify someone; for example, it might reveal a person’s political standpoint, geographical location, or financial situation.8 This certainly isn’t acceptable, and implementing an audit trail and restricting access to log data is a must, but applying this process to a file on disk is difficult, if not impossible.
Another issue along the same lines is the need to prevent illegal access. Storing log data on disk and accessing it using remote login makes log access an IAM problem. At first this sounds like a good strategy, because it lets you apply authorization roles and limit overall access, but the strategy only holds as long as no one is able to download any files. If logs can be downloaded, it becomes extremely difficult to uphold access rights, which more or less defeats the purpose of IAM.
10.4.2 Integrity
Maintaining the integrity of log files is extremely important, but this requirement is often forgotten when discussing logging strategies. One reason could be that logs are typically only used to help out during development or failure investigations. Preventing modification of log data isn’t then a top priority, because why would you modify log data in the first place? A system behaves the same way no matter what you write in the logs.
This certainly makes sense, but if you consider logs as evidence or proof, then integrity suddenly becomes important. For example, if logs are used in a court case claiming that a transaction has been made, then you want to be sure the logs haven’t been tampered with. This becomes important when logging to a file. If you allow remote access, you need to ensure that no one other than the application is able to write to the log files. Otherwise, you could end up in a difficult situation the day you need to prove log integrity.
10.4.3 Availability
It seems that guaranteeing the availability of log data should be an easy task when logging to a file on disk, but there are, in fact, several implicit problems that emerge. Storing data on disk is convenient, but it introduces the problem of state. For example, when a server needs to be decommissioned and replaced by a new instance, you need a process to ensure logs are preserved and moved to the new server. Otherwise, critical log data can be lost, and you’ll have a gap in the transaction timeline—and that’s not good if your logs contain audit data.
Another subtle issue relates to limited disk size. When logging to a file on disk, you need to ensure that the log file doesn’t become too large, or you might run out of disk space. A classic dilemma is when the logging process of your application crashes due to lack of available disk space and fails to report it in the logs because there’s no space. A common way to mitigate this is to have an admin process that automatically rotates logs. This adds some complexity that we’ll get back to in section 10.5, but let’s take a quick look at how log rotation works.
Suppose you have a log file called syslog. When that file reaches a certain size or age, the rotation process renames it (say, syslog.1) and creates a new log file called syslog. This way, syslog.1 can be moved, stored, and analyzed without affecting the current log file. This sounds easy, but a common pitfall is that the rotated logs aren’t moved and fill up the disk anyway.
You do, indeed, need to consider several security issues when logging to a file on disk. Some are harder and some are easier to resolve than others, but one can’t help thinking that there must be a better way to do this—and there is. The solution is found in the cloud, and it involves logging as a service rather than logging to a file on disk.
10.4.4 Logging as a service
When running an application in the cloud, you can’t depend on external infrastructure, such as a local server disk. This is because a server instance can be replaced at any time, which makes logging to a file on disk problematic. Figure 10.3 illustrates a logging strategy that takes this into account by centralizing all logging to a backing service.
From a code perspective, logging to a service rather than a file doesn’t make much difference; you’re still able to use your favorite logging framework, but instead of writing to a local disk, data is sent over the network. Conceptually this makes sense, but it’s not clear why using a centralized logging service is preferable from a security standpoint—so let’s put our CIA glasses on again.
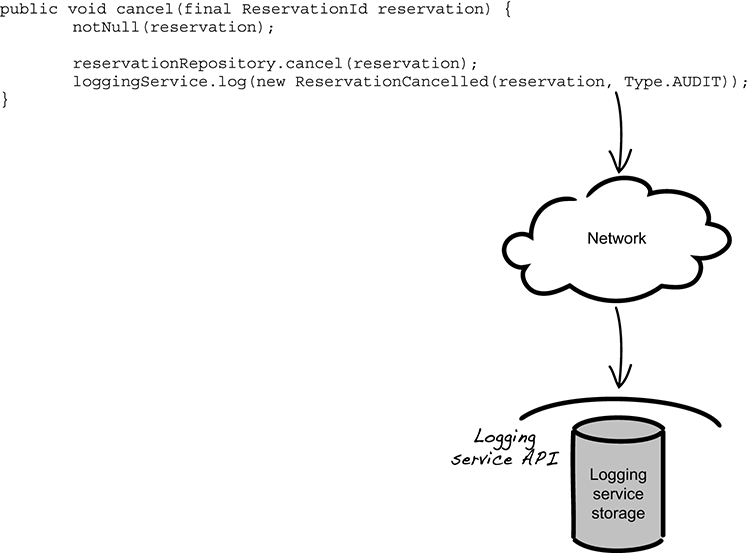
Figure 10.3 Every log call is sent over the network to the logging service.
Confidentiality
From a confidentiality perspective, you want to ensure that only authorized consumers get access to log data. This is a challenge when logging to a file on disk, mostly because it’s difficult to restrict access to specific data, but also because it’s hard to create an audit trail of what data was accessed when and by whom. Using a centralized logging service lets you address this, but only if you choose the proper design. For example, restricting access to the logging system isn’t enough on its own to solve the sensitive data access problem, but if you choose to separate log data into different categories, such as Audit, System, and Error, then the logging system could easily restrict users to seeing only log data of a certain category. And, as a developer, this makes perfect sense, because you’re probably interested in technical data only (for example, debug or performance data) and not sensitive audit information. How to do this in practice is a topic of its own though, so we’ll get back to this in chapter 13.
Another interesting challenge is how to establish a proper audit trail. In comparison to file-based logging, establishing an audit trail is a whole lot easier when using service-based logging. Each time you access log data, the system registers your actions and fires an alarm if you’re trying to do anything illegal. This in turn improves the overall credibility of how log data is handled and consumed, even after an application has terminated or been decommissioned.
As a final note, there’s one more significant distinction between file-based and service-based logging to remember. When logging to disk, you might consider the disk to be within the same trust boundary as your application. If so, you don’t need to worry about protecting data while in transit (from your application to the disk). But if you use a logging service, data is sent over a network, which opens up the possibility of eavesdropping on log traffic. This means that using service-based logging requires data protection while in transit, which is often done using TLS (Transport Layer Security) or end-to-end encryption.
Integrity
Preventing unauthorized access to data is indeed important, but so is ensuring its integrity, especially if you view logs as evidence or proof. Many logging strategies struggle with this, but if you choose service-based logging, the task becomes more or less trivial. This is because the logging system can easily be designed to separate read and write operations, where writes are only performed by trusted sources. For example, if you set up your application to be the only one authorized to write data and give all other consumers read access, then your logs can only contain data written by your application. If you also choose an append-only strategy, then you ensure that log data is never updated, deleted, or overwritten, but only appended to the logs. This way, you can easily ensure a high level of integrity at a low cost.
The need for log aggregation is also an aspect to consider when running a system with multiple instances. When logging to a file on each server instance, logs become separated, and you need to aggregate them manually or run them through a processing tool to get a complete picture of a transaction. This opens up the risk of integrity problems if the aggregation process allows modification—how do you know that data hasn’t changed in the aggregated view compared to its individual parts? The solution lies in using a centralized logging service that appends and aggregates data by design. (We’ll get back to this when covering logging in a microservice architecture in chapter 13.)
Availability
Availability is perhaps the most interesting security aspect to analyze. When you introduce the idea of using a logging service, you’re most likely going to be asked, “What if the logging service is down or can’t be accessed over the network?” This is a fair question that sounds complex, but the answer is surprisingly easy.
The way to address access failures of the logging service is the same as how you’d deal with disk failures. For example, if transaction rollback is your preferred strategy to handle disk failures, then you’d do the same when failing to access the logging service—it’s as simple as that. But if the network is less reliable than disk access and the service can’t be accessed, then log data might need to be buffered in local memory to minimize rollbacks if the risk of losing data is acceptable.
Another interesting aspect is the ability to scale. When logging to a file on disk, you’re bounded by disk size, and logging can’t scale beyond the disk storage capacity. For example, if you need to log a massive amount of data over a long period of time, chances are you’ll run out of disk space at some point. But if you choose to use a logging service, then you can adapt the storage capacity based on need and improve overall availability. This is particularly easy if the service is running in the cloud.
A final important comment is that when using a central logging service, you implicitly know where all your log data is; it isn’t spread out over hundreds of servers, where some have been decommissioned and some are up and running. This might sound irrelevant, but in a situation where you need to retrieve or remove all the data that you’ve stored about a person or when you need to run advanced analysis algorithms, it becomes invaluable to know where all your log data is.
10.5 Admin processes
A system is not complete without administrative tasks, such as running batch imports or triggering a resend of all messages from a specific time interval. Unfortunately, these admin tasks are often treated as second-class citizens compared to what is seen as the real functionality that customers directly interface with. Sometimes the admin functionality isn’t even given the basic standards of version control or controlled deploys, but exists as a collection of SQL and shell command snippets in a file somewhere that’s copied over to the server when needed and executed in an ad hoc manner.
Admin functionality should be treated as a first-class citizen; it should be developed together with the system, version controlled on par with the rest of the functionality, and deployed to the live system as a separate interface (API or GUI). You get several security benefits from this (we’ll elaborate on how these benefits manifest themselves later in this section):
- You get better confidentiality, because the system can be locked down.
- Integrity is improved, because the admin tools are ensured to be well synchronized with the rest of the system.
- Availability of admin tasks is improved even under system stress.
Administration tasks can be understood as the functionality that isn’t the primary purpose of the system but is needed to fulfill that purpose over time. You might have a system whose primary purpose is to sell items to customers over the web. But in doing so, the system interacts with the product catalogue, warehouse, pricing, and so forth. Admin tasks that need to be done might include:
- Auditing the number of warehouse updates that have been executed
- Rerunning failed imports of pricing updates
- Triggering a resend of all messages to the warehouse
Unfortunately, such functionality is often forgotten or overlooked during system development. This might be because these tasks aren’t often perceived as value-adding user stories, at least not if you restrict user to mean only customer end users, and they aren’t given priority.
10.5.1 The security risk of overlooked admin tasks
Overlooking admin tasks often opens up security vulnerabilities. All these tasks need to be done anyway, and if there aren’t built-in tools for this, the system administrator is forced to use other tools (perhaps overgeneral ones) to get the job done.
To perform admin tasks, the sysadmin might use ssh to log on to the server or to connect directly to the database using a GUI. The tasks might be performed directly in bash using UNIX/Linux commands or SQL commands sent to the database. Some of these scripts and commands will be used more often, and after a while, there will emerge some file of usable scripts, command lines, and SQL that’s maintained as part of the sysadmin lore—but those handy scripts won’t be maintained together with the rest of the codebase. The security risk is twofold.
First, having such a means of general access as ssh opens up the attack surface more than is necessary. If ssh access is allowed, there’s a risk of it being used by the wrong people for the wrong reasons. An attacker that happens to get their hands on root-level ssh access can do almost unlimited harm. The risk might be reduced by closing down access to the machines and only allowing it via bastion hosts or jump hosts that are set up with more strict auditing and so forth. But the risk is further reduced if you have no ssh access at all. Problems might also happen by mistake; for example, during a system emergency, a sysadmin might attempt to clear up space on a partition that becomes full but accidentally erase important data.
The second risk is that if (or rather when) the system and the admin scripts get out of sync, bad things can happen. For example, if the development team refactors the database structure, and the sysadmin SQL commands aren’t updated accordingly, applying the old SQL commands on the new table structure can cause havoc and potentially destroy data.
Actually, there’s a third risk. Having system code maintained separately from system admin scripts by different groups of people tends to contribute to a strained diplomatic relationship between the two groups of people—something that’s not beneficial in the long run.
We’d rather keep the use of such general-purpose and highly potent system administration tools as a last resort. Root-level ssh access or SQL GUIs can definitely get the job done, but they can be used to do almost anything. Explicitly providing the administration functionality that’s needed ensures that the attack surface is kept minimal and that the functionality is available when needed.
10.5.2 Admin tasks as first-class citizens
The functionality needed for administrative tasks should be developed and deployed as part of the rest of the system. It will reside on the nodes, ready to be called via its API, as seen in figure 10.4.
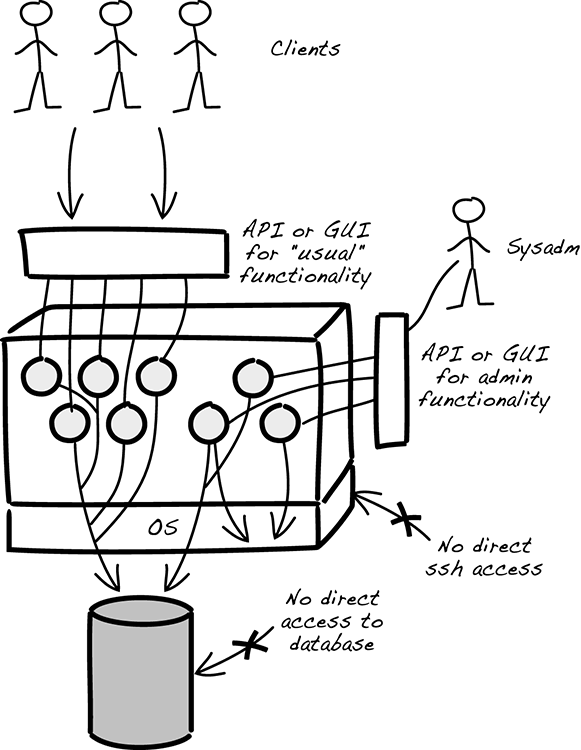
Figure 10.4 Administrative tasks deployed to the server, ready to run via a separate API
In the figure, note how the admin functionality exists on the nodes already; you have to trigger it from the outside. Even if an attacker gains access to the admin API, they’ll only be able to trigger the predefined functionality, not any general OS or SQL command—the attack surface is kept low.
Another consideration is that even if admin functionality is part of the deployed system, you’ll still want it as a separate process. In particular, you’ll probably want to have the admin parts available when things are getting slow and unresponsive. If the admin functionality is embedded in the same process as the usual functionality, there’s a risk that it’ll become unavailable at the wrong time. For example, if your web server is clogged down by lots of queued-up and waiting requests, you don’t want to put your admin requests into the same queue. The solution to this, as indicated in figure 10.4, is to have admin functionality run as a separate process, called via a separate API. One way of doing this is to put it in a separate runtime container.
If you’re developing in Java, the admin functionality could be put in a separate JVM of its own, or your admin might be written in Python and deployed separately. If you want to increase availability further, you can put the sysadmin API on a separate network, making it completely independent from what happens with the usual clients.
If you structure your admin functionality according to the guidelines in this section, you get all three kinds of security benefits:
- Confidentiality increases because the system is locked down to only provide specific admin tasks and not, for example, a general SQL prompt.
- Integrity is better because you know that the administration tools are in sync with the application, so there’s no risk of those tools working on old assumptions and causing havoc.
- Availability is higher because it’s possible to launch administration tasks even under high load.
The ability to dynamically launch new instances is a key feature both for admin tasks and the usual functionality. To make this work, clients need to be able to access those new instances. Also, you need to ensure that instances that have been decommissioned don’t get client calls. For this, you need some kind of service discovery and load balancing, so let’s continue on with how to do that.
10.6 Service discovery and load balancing
Service discovery and load balancing are two central concepts in cloud environments and PaaS solutions. They also share a common trait in that they both enable continuous change in an environment. It might not be obvious at first, but service discovery can improve security, because it can be used to increase the availability of a system. As you learned in chapters 1 and 9, availability is part of the CIA triad and is an important security property for a system.
Service discovery also increases security by allowing a system to stay less static, which is a topic we’ll talk about in more detail in the next section. Let’s start by looking at some common patterns for implementing load balancing with and without service discovery.
10.6.1 Centralized load balancing
Although load balancing in itself is an old concept, it’s performed on a different scale in cloud environments. The basic purpose of load balancing is to distribute workloads across multiple instances of an application. Traditionally, this was commonly done by using dedicated load-balancing hardware, configured to spread requests across a set number of IP addresses (see figure 10.5). Configuring such load balancers is more often than not a manual and brittle process that also involves the risk of downtime if something goes wrong. This approach of spreading load doesn’t always work well in a cloud environment.
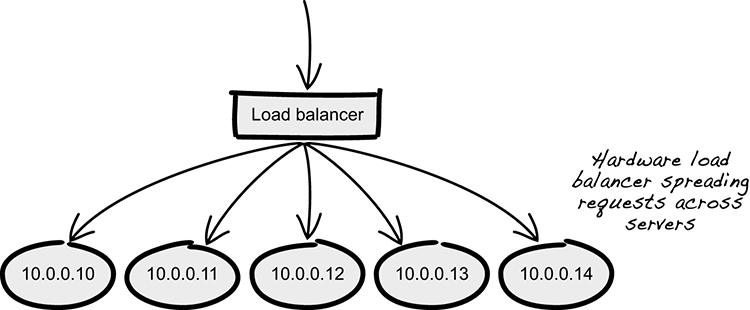
Figure 10.5 Centralized load balancing
Cloud-native applications are stateless and elastic by definition, which means individual instances come and go, and they should be able to do so without the consumer of a service being affected. The number of instances and the IP addresses and ports used by each instance are constantly changing. Because of this, the management of load balancing is transferred to the PaaS you deploy your applications on. The platform is then responsible for constantly keeping track of what instances it should use to spread the workload. This turns load balancing management into a fully automated and more robust task.
When you’re using centralized load balancing, the consumer, or the caller, is unaware of how many instances of an application are sharing the load and which instance will receive a specific request. The distribution of the load is managed centrally.
10.6.2 Client-side load balancing
An alternative approach to centralized load balancing is client-side load balancing (figure 10.6). As the name implies, this puts the decision of which instance to call on the caller.
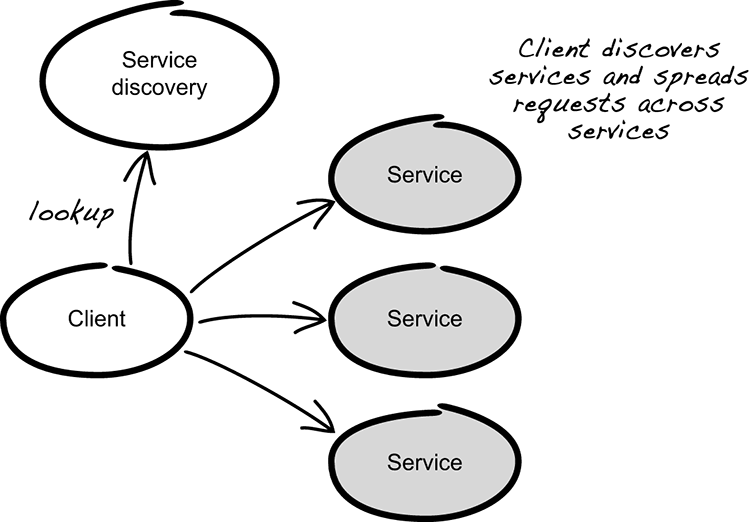
Figure 10.6 Client-side load balancing using service discovery
You might want to use client-side load balancing instead of centralized load balancing for several reasons, one being that it can simplify your architecture and deployment processes. Another reason is that it allows the caller to make informed decisions on how to distribute the load. In order to do client-side load balancing, you need something called service discovery. Service discovery allows one application (the client) to discover, or look up, where the instances of another application are located. Once the client knows about the instances, it can use that information to perform load balancing. Because the discovery is performed at runtime, service discovery works well in ever-changing cloud environments.
10.6.3 Embracing change
If you can deploy your application in an environment that supports dynamic load balancing and service discovery, be it a PaaS or a homegrown infrastructure, you’ll have the basic tools to support an environment that’s constantly changing and where individual instances come and go. Change can happen because of elasticity (increasing or decreasing the number of instances), application updates, infrastructure changes, or changes in operating systems.
What’s interesting is that from a security perspective, change is good for several reasons. From a pure load balancing point of view, spreading load across multiple instances can increase the availability of a system, and, therefore, it’ll also increase the security of the system. Another aspect is that a system, application, or environment that’s constantly changing is far more difficult to exploit than one that stays static. Taking advantage of continuous change to improve security is what the three R’s of enterprise security are all about.
10.7 The three R’s of enterprise security
If you design your applications and systems based on the twelve-factor app and cloud-native ideas, you’ll not only be able to run them in a cloud environment, but they’ll also behave well. Once you’re able to run your systems on a cloud platform, you can use the tools provided by the platform to take the security of those systems to the next level. The way to do this is by using the three R’s of enterprise security.
The tools and possibilities available to you in a cloud environment are often radically different from those in traditional infrastructure and applications. It shouldn’t seem too far-fetched that the approach used to create secure systems in the cloud is equally different from the more traditional approaches of enterprise security. Justin Smith took some of the most important concepts of enterprise security in cloud environments and summarized them in what he called the three R’s:9
- Rotate secrets every few minutes or hours
- Repave servers and applications every few hours
- Repair vulnerable software as soon as possible (within a few hours) after a patch is available
In this section, you’ll learn what these concepts mean and how they improve security. You’ll also see how the concepts discussed previously in this chapter work as enablers for the three R’s.
10.7.1 Increase change to reduce risk
Applying the three R’s to create secure systems is in many aspects fundamentally different from the traditional approaches used to mitigate security risk in IT systems. One common traditional rationale is that change increases risk. Therefore, in order to reduce risk, rules are made to prevent change in systems or in software in various ways. For example, limitations are put on how often new versions of applications are allowed to be released. Protocols and processes are introduced that turn the cycle time for getting new updates and patches on the OS level out to production into months. Secrets such as passwords, encryption keys, and certificates are rarely or never changed, because the risk of something breaking when doing so is considered to be too high. Reinstalling an entire server is almost unheard of, because not only would it take weeks to get all the necessary configuration in place, it’d also take a significant amount of testing to verify that everything was done correctly. Suffice it to say that this traditional approach to IT security is largely based on preventing change.
The purpose of the three R’s is the total opposite—reduce risk by increasing change. The observation that Justin Smith makes is that many attacks on IT systems have a greater chance of succeeding on systems that rarely change. A system that stays largely static is also the perfect target for advanced persistent threat (APT) attacks, which usually result in significant damage and data loss. If your system is constantly changing, you effectively reduce the time an attacker will have to inflict any significant damage.
Now that you’re familiar with the general concept, let’s take a closer look at each of the three R’s.
10.7.2 Rotate
Rotate secrets every few minutes or hours. If your application is using passwords to access various systems, make sure they’re changed every few minutes and that every application has its own user to access the system with. This might sound like something that’s complicated to set up, but if you’ve designed your application in line with the twelve-factor app methodology and placed your configuration in the environment, your application can remain unaware of the rotation. All it needs to know is how to read the password from the environment.
The PaaS running the application will take care of rotating the passwords on a regular basis and injecting the new values into the environment for the application to consume (figure 10.7). Most solutions for cloud environments, both public and private, have the ability to perform these tasks, and, if not, it’s usually not that hard to set up.
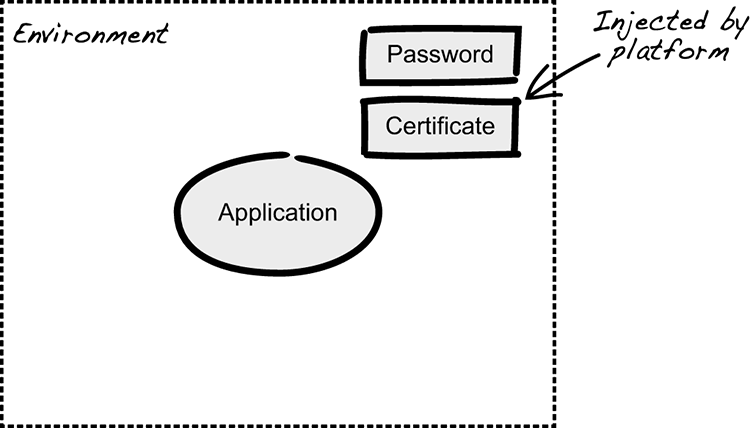
Figure 10.7 The platform injecting ephemeral secrets into the environment
Another benefit of this practice is that passwords can be treated as ephemeral by the platform. They’re generated on demand and then injected directly into the environment of a running container or host. They will only ever live in nonpersistent RAM. This helps reduce possible attack vectors, because they’re not placed in some file or central configuration management tool that can be more easily compromised. You also don’t have to deal with the hassle of encrypting the passwords placed in the configuration file.
Once you understand this concept of ephemeral credentials and how the cloud platform enables you to use unique passwords that don’t live for more than a couple of minutes, there’s no reason why you shouldn’t do the same with other types of secrets. Certificates, for example, can be rotated in a similar fashion. Because you can rotate them instead of renewing them, you’re reducing the time frame for which a certificate is valid. If someone were to steal it, they wouldn’t have much time to use it. In addition, you’ll never again have a problem with a certificate expiring because you forgot to renew it. (Expired certificates are an all too common reason for security issues caused by system unavailability.) The same goes for API tokens used to access various services and any other type of secret used.
Sometimes the application needs to be aware of how the credentials are being rotated, perhaps because it involves details better encapsulated in the application rather than making the platform aware of application-specific details. In these cases, the application itself will receive the ephemeral secrets by directly interacting with a service providing these features (figure 10.8).
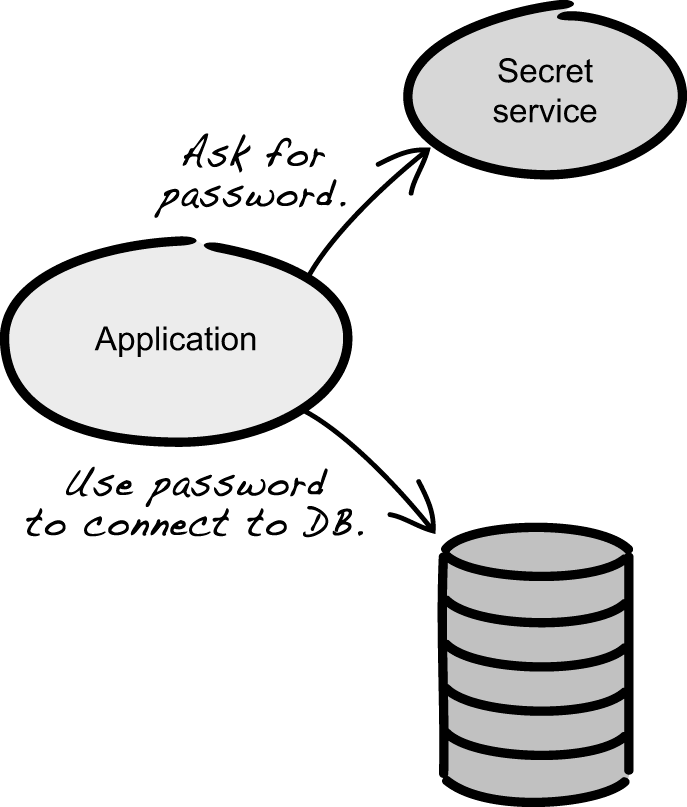
Figure 10.8 The client retrieves secrets from a dedicated service.
With this approach, the application is now responsible for retrieving updated secrets before they expire. In terms of responsibility, this approach is similar to client-side load balancing in that it puts more responsibility on the application.
Rotating secrets doesn’t improve the security of the secrets themselves, but it’s an effective way of reducing the time during which a leaked secret can be misused—and, as you’ve learned, time is a prerequisite for APTs to succeed. Reduce the time a leaked secret can be used, and you’ve made it a lot harder for such an attack to be successful.
10.7.3 Repave
Repave servers and applications every few hours. Recreating all servers and containers and the applications running on them from a known good state every few hours is an effective way of making it hard for malicious software to spread through the system. A PaaS can perform rolling deployments of all application instances, and if the applications are cloud-native, you can do this without any downtime.
Instead of only redeploying when you’re releasing a new version of your application, you can do this every other hour, redeploying the same version. Rebuild your virtual machine (VM) or container from a base image and deploy a fresh instance of your application on it. Once this new instance is up and running, terminate one of the older ones (see figure 10.9). By terminate, we mean burn it down to the ground and don’t reuse anything. This includes erasing anything put on a file mount used by the server instance. (This is where it comes in handy that you learned not to put logs on disk earlier in this chapter.) By repaving all your instances, you not only erase your server and application but also any possible malicious software placed on the instance, perhaps as part of an ongoing APT attack.
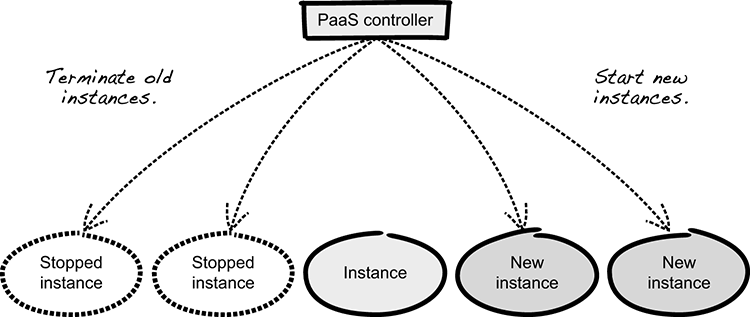
Figure 10.9 Repaving instances by rolling deployment
Repaving server instances can be difficult if you’re running on bare-metal servers, but if you’re using VMs, you can do this even if you’re not using a PaaS. If you’re running containers, it becomes even easier to spin up a new instance from a base image. If you can, consider repaving both the containers and the host running the containers. The application deployed must also be a completely fresh instance, so don’t reuse any application state from a previous instance.
10.7.4 Repair
Repair vulnerable software as soon as possible after a patch is available. This goes for both operating systems and applications. What this means is that as soon as a patch is available, you start the process of rolling out the new software into production. When you do this, you don’t incrementally apply the patch to an existing server; instead, you create a new known good state and then repave the server and application instances from the new state.
Again, this might sound like an incredibly difficult thing to do, but it’s not if your platform and applications are designed for it. All the tools and technologies needed to do this are already available and widely adopted, so there’s nothing stopping you from doing so. To give you an idea of what’s needed, if you’re not running in a cloud environment, you probably need to at least be running virtual servers, and it’ll be even easier if you’re using containers (although it’s not necessary). If you’re running on a cloud platform, you should already have all the tools at your disposal.
You should also apply the repair concept to your own software. When there’s a new version of your application ready to be released, it should be deployed as soon as possible. You should make new versions available as often as you can. If you’re familiar with continuous delivery and continuous deployment, you might already be applying the repair concept on your own applications, even if you don’t know it.
The reason for repairing as often as you can is that for every new version of the software, something will have changed. If you’re constantly changing your software, an attacker constantly needs to find new ways to break it. Say you have a vulnerability in your software that you’re unaware of. If you rarely change your software, the vulnerability remains for a long time, allowing for an APT to continue to do its job. But if you’re continuously making small changes to your software and deploying it often, you might remove the vulnerability—again, without knowing it.
Don’t forget to also repair your application any time a new security patch for a third-party dependency you use becomes available. To keep track of vulnerable dependencies efficiently, you should make it part of your delivery pipeline (go back to chapter 8 for tips on how to leverage your delivery pipeline for security).
In order to deploy new versions of operating systems and applications soon after a patch is available without causing downtime, your applications need to adhere to the twelve-factor app methodology and be cloud-native. Your processes and procedures for releasing updates also need to be streamlined. If they aren’t, you’ll most likely struggle to smoothly repair servers and applications.
Setting up everything needed to start applying the three R’s is a lot easier if you’re running on a cloud platform, whether it’s a public cloud or a PaaS hosted in-house. But even if you’re running on dedicated servers, you can still make the three R’s a reality with tools already available to you. It all starts by creating applications that are cloud-native and follow the twelve-factor app methodology. Then you can learn from the design ideas used when architecting for the cloud and apply them in your own environment to reap the same benefits.
If you’re working with existing applications and can’t start from scratch, a step-by-step process of slowly transforming your applications toward the twelve factors is usually a viable approach. When working with existing IT systems, the biggest challenge is often coming to terms with a completely new way of handling enterprise security.
Summary
- The twelve-factor app and cloud-native concepts can be used to increase the security of applications and systems.
- You should run your application as stateless processes that can be started or decommissioned for any occasion.
- Any result of processing should be stored to a backing service, such as a database, log service, or distributed cache.
- Separating code and configuration is the key to allowing deployment to multiple environments without rebuilding the application.
- Sensitive data should never be stored in resource files, because it can be accessed even after the application has terminated.
- Configuration that changes with the environment should be part of the environment.
- Administration tasks are important and should be part of the solution; they should be run as processes on the node.
- Logging shouldn’t be done to a local file on disk, because it yields several security issues.
- Using a centralized logging service yields several security benefits, regardless of whether you’re running an application in the cloud or on-premise.
- Service discovery can increase security by improving availability and promoting an ever-changing system.
- Applying the concept of the three R’s—rotate, repave, and repair—significantly improves many aspects of security. Designing your applications for the cloud is a prerequisite for doing this.