
14
A final word: Don’t forget about security!
This chapter covers
- Code security reviews
- Vulnerabilities in a large-scale tech stack
- Running security penetration tests from time to time
- Following security breaches and attack vectors
- Incident handling and the team’s role
By now, you’ve been with us throughout the course of a pretty long book. We’ve spent much time talking about how to not think about security, but still get security anyway. Surprising as it might seem, we’d like to close this book by talking about how important it is to think about security. We started this book by noting a few things:
- Developers find it difficult and distracting to explicitly think about security while coding.
- Developers like and find it natural to think about design while coding.
- Many security problems arise from bugs, misbehaving code that happens to open up security vulnerabilities.
- Good design reduces bugs; some designs prevent some kinds of bugs, while other designs prevent other bugs.
In our approach, we suggest thinking more about design, thereby gaining security as a side benefit. In this book, we’ve presented a collection of designs that, in our experience, work well to counter weak security, making the code secure by design. Even if you use all the design patterns in this book and come up with a few yourself, there’s still a need for explicitly thinking about security. The secure by design approach certainly reduces a lot of the cumbersome security work, but there’ll still be aspects that are best addressed by explicit security work.
A detailed account of security practices is outside the scope of this book, but it wouldn’t do to completely leave out a discussion of some things that we’ve found are pretty effective in lowering the security risk. These things are close to the development work that you do by yourself or with your team and have a positive impact on security, compared to the effort required. And that’s what this chapter is about. Unfortunately, a detailed account would fill a book in and of itself. We’ll keep our discussion brief and focus on the what and why, rather than digging into the details of how to do it.
Not that long ago, there was a deep divide between coders and testers. That divide has now been bridged, and we think of both coding and testing as natural parts of development. We have testers together with coders on our development team, and we perform testing during the run of a sprint, not as a separate phase after. In the same way, the historical divide between developers and operations has been bridged in many organizations with the advent of the DevOps culture, where teams work with both development and operational aspects in mind. Extending the idea of DevOps, we’d like the whole team to embrace the security aspects of their products and services as well. Most probably, there’ll still be external security experts, but we’d like to sketch out how to get your existing team to become more self-supporting when it comes to security.
With security, there are no guarantees, and following the practices in this chapter won’t get you 100% secure. But the secure by design approach takes you most of the way, and the tips here will get you close to where you need to be. Let’s start with something close to the code and related to something you hopefully already do to some degree: code security reviews.
14.1 Conduct code security reviews
Code reviews are an effective way to get feedback on solutions, find possible design flaws, and spread knowledge about the codebase. If you aren’t already conducting code reviews, we recommend you try it.
The exact format of the code review (what to focus on, which people should participate, and so on) depends on your specific needs, and there are many resources available to guide you in getting started. Just as regular code reviews are beneficial for the software development process, in both the short and the long run, code security reviews are equally beneficial, especially from a security perspective.
Code security reviews are much like regular code reviews, but with the purpose of reviewing the security properties of the code. A code security review helps you find possible security flaws, share knowledge of how to design secure code, and improve the overall design. Because a code security review is, by definition, performed after the code has been written, it complements all the other techniques and tools you use to make your software secure, including the ones you’ve learned in this book. Keep in mind that there’s no reason to wait until the entire application is finished before conducting code reviews. Instead, it’s usually more beneficial to perform code reviews continuously and often while developing your code.
There’s more than one way of doing a code security review. You can, for example, choose to focus primarily on the overall design of the code, while paying extra attention to things like the implementation or absence of secure code constructs. This approach works well with the concepts in this book. Another option could be to focus on more explicit security aspects, such as the choice of hash algorithms and encodings or how HTTP headers are used. You could also use a combination of different approaches. Which approach you choose depends largely on what type of application you’re building and the dynamics of your team and organization. Pick an approach you feel comfortable with and then evaluate, refine, and experiment. Eventually, you’ll find a way that suits your specific needs.
14.1.1 What to include in a code security review
If you’re unsure what to include in a security review, an approach that can be helpful is to use a checklist as a guide. Write down a list of things you want to include in the review, then each person performing the review can check off the items they complete. If all items in the list have been checked, you know you’ve at least achieved a baseline.
The following list is an example of how a checklist for code security reviews might look. We’ve tried to include items with different perspectives to inspire you about what to include in your own checklist.
- Is proper encoding used when sending/receiving data in the web application?
- Are security-related HTTP headers used properly?
- What measures have been taken to mitigate cross-site scripting attacks?
- Are the invariants checked in domain primitives strict enough?
- Are automated security tests executed as part of the delivery pipeline?
- How often are passwords rotated in the system?
- How often are certificates rotated in the system?
- How is sensitive data prevented from accidentally being written to logs?
- How are passwords protected and stored?
- Are the encryption schemes used suitable for the data being protected?
- Are all queries to the database parameterized?
- Is security monitoring performed and is there a process for dealing with detected incidents?
Remember that this is just an example of what to include in a checklist. There’s no be-all, end-all checklist for us to present. When creating your own list, you should focus on including the things that are most important and beneficial for you. It might also be that you start out with a long list to make sure you cover everything, and after a while, you remove items that are nonissues, making the list more concise and relevant for your particular team.
14.1.2 Whom to include in a code security review
Another aspect to think about is which people should take part in the code security review. Should you only involve people within the team, or should you also include people from outside the team? We think it’s good to include both because they’ll bring slightly different perspectives when performing the review. Outside developers, testers, architects, or product owners will all have slightly different views on security, and it can all be valuable input.
One thing to watch out for is that because people from outside the team can bring such different feedback, it might become difficult to keep the review focused and efficient. If that’s the case, you can try to split the process up and conduct two separate reviews: one with team members only and one with external reviewers. Experiment and find out what works best for you.
14.2 Keep track of your stack
In chapter 8, you learned how to use your delivery pipeline to automatically check for vulnerabilities in third-party dependencies. Whenever a vulnerability is found, you can stop the pipeline; the issue then needs to be addressed before the pipeline can be continued or restarted. Chapter 10 talked about the three R’s of enterprise security (rotate, repave, repair) and taught you to repair vulnerable software as soon as possible after a patch is available. The concept of repairing should also be employed when pushing out new versions of your application caused by an update of a vulnerable dependency.
Managing security issues in delivery pipelines and getting security patches out into production quickly is fairly straightforward when dealing with a moderate number of applications. If you operate at a large scale and have hundreds or thousands of applications, you need a strategy for efficiently handling monitoring and management of vulnerabilities in your tech stack. Otherwise, you’ll soon find yourself with more information than you can handle. Some aspects you need to consider are how to aggregate information and how to prioritize work.
14.2.1 Aggregating information
Once you have the tooling to automatically find security vulnerabilities (as discussed in chapter 8), you need to figure out a way to aggregate all that information to create an overarching view of your tech stack. A number of tools can perform such aggregation, both open source and proprietary.1 Keep in mind that if an issue found in an application can be handled directly by the team responsible for that application, it’s usually easier to work with the detailed information generated for that specific application, rather than working with an aggregated view.
Being able to work with aggregated views of information is necessary when dealing with issues that need to be addressed at a company level. Aggregated views are also an indispensable tool for any type of high-level reporting. Setting up the tools and infrastructure to make it effortless and automatic to get a bird’s-eye view of vulnerabilities in your tech stack is a worthwhile investment. As with many other things, it’s usually a good idea to start small and move to more complex tooling as you grow.
14.2.2 Prioritizing work
When you operate at scale, there’ll probably always be multiple known vulnerabilities at any point in time. Most likely, you won’t have the time to address them all at once, so you need to prioritize.
As early as possible, figure out a process for dealing with vulnerabilities. Decide how to prioritize vulnerabilities against each other and against other development activities. You also need to decide who should perform the work of fixing a vulnerability and how to prioritize the work against other types of development activities. Thinking through a process or strategy for dealing with prioritization might seem like overkill, but security work usually competes with regular development work. Having a clear strategy for how to balance security work against other work can help speed up the process, as well as avoiding potential heated discussions and possible hurt feelings.
The process doesn’t need to be complex and rigid. Sometimes it’s more appropriate to have a lightweight and adaptable process, if that fits your way of working better. The takeaway is that it’s better to have thought about how to handle vulnerabilities before they happen.
14.3 Run security penetration tests
As you’ve learned by reading this book, security weaknesses can reside anywhere in a system; for example, in the deployment pipeline, in the operating system, or in the application code itself. Consequently, many choose to run security penetration tests (pen tests) to identify weaknesses such as injection flaws, sensitive data leakage, or broken access control.
You might have wondered whether the secure by design approach renders pen tests obsolete, because good design should have taken care of all the security problems. This certainly is an appealing thought, but good design isn’t a substitute for pen tests. In fact, the idea of using secure by design as an argument to cut pen tests out of the loop reveals an underlying misconception about the purpose of pen tests.
Many believe pen tests should be used to prove whether a system is hackable or not, but that’s not their purpose. The main objective is to help developers build and design the best possible software without security flaws. Regardless of what design principles you follow, running pen tests from time to time is a good practice to challenge your design and prevent security bugs from slipping through.
14.3.1 Challenging your design
When designing software, you always end up making trade-offs. These could be in anything from how you interact with legacy systems to how you design your service APIs, or whether domain primitives are used or not. Regardless, there’s always a chance that your design contains flaws you might have missed or that overall domain evolution has caused exploitable microlesions in your code, similar to what you learned in chapter 12, where you learned how sensitive data leaked through logging caused by an evolving domain model.
Effective pen testing should therefore include the technical aspects of a system (such as authentication mechanism and certificates), as well as focusing on the business rules of a domain. This is because security weaknesses can be caused by a combination of design flaws and valid business operations.
In general, business rules are meant to be used with good intentions. For example, if you make a table reservation at a restaurant, you intend to show up. But if the same reservation rules are used together with a too generous cancellation policy (for example, cancellation without charge), then it’s possible for someone with malicious intent to craft a denial-of-service attack, as we talked about in chapter 8. Although this might seem unlikely, there are, in fact, lots of businesses suffering from this without even realizing it. This is because logs and monitoring show normal usage and nothing is out of the ordinary, except that financial reports might indicate a drop in revenue or market share. Understanding how to attack a system using business rules is therefore an important part of system design and something you should encourage in a pen test. Unfortunately, not many pen testers realize this because they’re not trained in exploiting domain rules, but our experience is that pen tests that include this are far more efficient at identifying weaknesses in a system than tests only focusing on technical aspects.
14.3.2 Learning from your mistakes
Challenging your design using pen tests is certainly important, but there’s another side to running these tests on a regular basis. Every time you receive feedback from a pen test team (this could be in a formal report or just when talking by the coffee machine), you have the opportunity to see it as a learning experience. It doesn’t matter how big the findings are; what’s important is that you see it as a chance to improve your design and not as criticism of what you’ve built. Our experience is that security flaws often can be addressed as normal bugs, which means it should be possible to add tests in your delivery pipeline that fail if you ever introduce the same problem again. This makes your system robust and secure over time.
Another aspect of pen test feedback is the chance to discuss it within your team and learn from your mistakes. Unfortunately, not many organizations reason this way: they think security flaws should be kept secret and be handled by as few individuals as possible. This means that most developers don’t get a chance to address security flaws or learn why certain design choices open up exploitable weaknesses. Analyzing results together is therefore a good opportunity to raise overall security awareness, as well as a chance for developers to learn how to address security in code. Also, if you don’t run pen tests on a regular basis, there’s often lots of ceremony associated with a test, similar to what you get when only releasing to production a few times a year. By discussing results within your team and seeing it as a chance to learn, you reduce overall anxiety about finding serious flaws or that someone has made a mistake.
14.3.3 How often should you run a pen test?
A question that often comes up when discussing pen testing is whether there’s a best practice to follow regarding how often you should run a test. The short answer is no, because it all depends on the current situation and context. But from our experience, a good interval tends to be as often as you think it brings value to your design. For example, if you’ve added several new business features, changed your external APIs, or integrated with a new system, then it’s probably a good idea to run a pen test, but there’s no best practice dictating this. Instead, let the current situation and context determine whether it makes sense to run a pen test or not, like in context-driven testing, where the current situation and context guide you in choosing a testing strategy. This might seem more complex than just coming up with a fixed schedule, but our experience is that this lets you establish a good rhythm that makes pen testing a natural part of your design process.
14.3.4 Using bug bounty programs as continuous pen testing
One issue with pen testing is that it’s often carried out during a limited period of time. This opens up the possibility of sophisticated vulnerabilities going undetected, which makes it difficult to trust the pen test report—how do you know if you’ve tested enough? There’s no way to know, but the use of bug bounty programs or vulnerability reward programs allows you to increase your confidence by simulating a continuous, never-ending pen test. There are, however, significant differences between bug bounty programs and pen tests.
A pen test is normally conducted by a highly trained pen test team, whereas a bug bounty program can be seen as a challenge to the community to find weaknesses in a system. The length of the challenge can vary, but it’s not uncommon to have programs running without an end date, which makes them similar to eternal pen tests. Anyone can join the program and take on the challenge, as long as they follow certain rules—for example, you can’t interrupt normal usage or damage user data, because all testing is carried out in production. Findings are then usually rewarded by a monetary amount that varies by severity level. For example, identifying a way to extract credit card numbers or personal data is probably worth a lot more than spotting a misconfigured HTTP header or cookie. It’s also important to follow the rules of disclosure, because many companies don’t want vulnerabilities to be publicly announced before having a chance to address them.
As you probably agree, the idea behind bug bounty programs certainly makes sense, but one thing many forget is that running such a program requires a great deal from an organization. For example, you need to handle enrollment, provide feedback, and properly document how to reproduce a problem. You also need a mechanism to assess the value of a finding:
- How serious is it?
- How much is it worth?
- How soon do you need to address it?
All these questions need answers before you can start a bug bounty program. Because of this, we recommend that you don’t fire up a challenge without properly analyzing what it requires of your company. A good starting point might be to look at existing programs to get an idea of what they entail from an organizational point of view. For example, look at Hack the Pentagon by the U.S. Department of Defense or at a program hosted by the Open Bug Bounty Community. This way, you might be able to take inspiration from someone else’s rule book and learn what it’ll mean for your organization.
Using pen tests to improve your design and make software robust over time is definitely a good idea. But reacting to the result of a pen test can be reacting too late, because the field of security is constantly changing. This brings us to the next topic: why it’s important to study the field of security.
14.4 Study the field of security
Security is a field in constant motion: new vulnerabilities, attack vectors, and data breaches are discovered at a pace that makes it hard to keep up as a developer. As you know, addressing security issues with proper design is an efficient way to achieve implicit security benefits, but this doesn’t mean you can forget about security as a field. In fact, learning about the latest security breaches and attack vectors is as important as studying new web frameworks or programming languages. Unfortunately, not many developers realize this, probably because they’re interested in building software rather than breaking it, which makes it important for security to be a natural part of development.
14.4.1 Everyone needs a basic understanding about security
Over the years, we’ve seen many organizations that treat security as a separate activity that doesn’t fall within the normal development process. This division is unfortunate because it makes it difficult to promote security in depth. Luckily, the secure by design mindset mitigates this to some extent, but to make security part of your daily work, you also need to ensure everyone has a basic understanding of security. For example, when developing a web application and onboarding a new team member, you could make learning about the OWASP Top 10 a requirement.2 This way, it becomes natural to talk about new findings and how to address weaknesses like SQL injection or cross-site scripting in your codebase.
Learning how to exploit weaknesses in a system is also important to gain a deeper understanding about security as a whole. Our experience is that many developers never get the chance to attack a system, which might explain why sometimes it’s difficult for developers to see weaknesses in their designs. To mitigate this, we’ve seen several examples where organizations encourage developers and other team members to attend basic pen test training. This can be overkill, but developers often get a real eye-opener about the consequences of designing insecure software—and that’s worth a lot. In addition, learning more about pen testing and understanding its purpose makes it easier to establish a culture where pen tests are seen as a vital part of the development process.
14.4.2 Making security a source of inspiration
In figure 14.1, you see an illustration of how input from various security sources (for example, conferences, meetups, and blog posts) is used together with knowledge from other domains to inspire solutions that address security problems by design. As it turns out, this strategy has been one of our main drivers to find new patterns that address security problems by design.
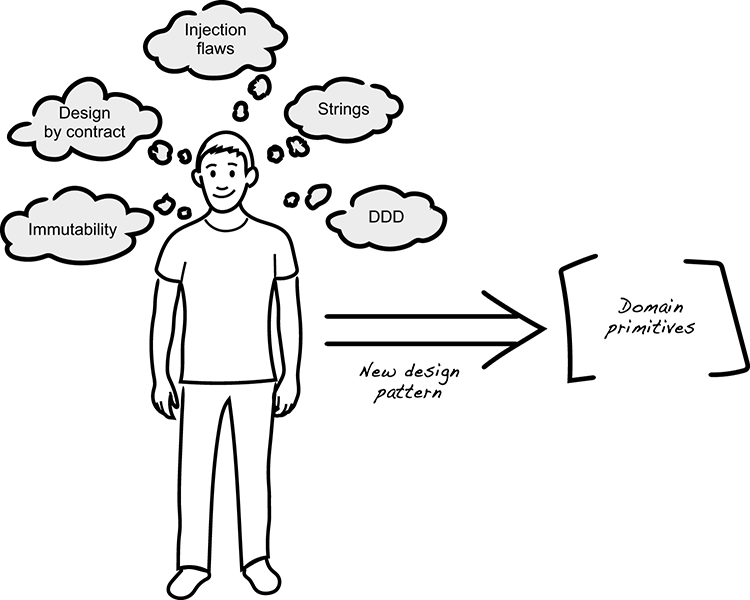
Figure 14.1 Combining knowledge from different sources yields new solutions.
For example, think about the general problem of an injection attack. The reason why it’s possible to trick an application is because the type of the input argument is too generic: if it’s a String, then it can be anything! The classic way to address this is to apply input validation, but it doesn’t solve the problem completely because it brings up the issues of separating data and validation logic, plus the need for defensive code constructs. This made us combine knowledge from Domain-Driven Design, functional programming, and Design by Contract to establish the design pattern called domain primitives (see chapter 5). Attending conferences and meetups and reading about the latest findings in the security industry are therefore important activities in learning more about how to develop secure software.
14.5 Develop a security incident mechanism
Whether we like it or not, security incidents happen. When they do, someone will have to clean up the mess—that’s what a security incident mechanism is all about. Let’s discuss what needs to be done, and how you and your team are involved.
First, it pays to reason that the development team should be involved when there are security incidents, because no one better knows the intricate details of how the system might behave or misbehave. Some organizations have separate units for handling security incidents. In those cases, it’s important that the security incident unit closely cooperate with the developers, as well as with operations people.
Preferably, security issues should be as instinctive a part of the development team’s work as operational aspects are. Cooperation and cross-pollination between development and operations has made DevOps something that feels natural today. We hope that security will merge into that in the same way—that we’ll see SecDevOps as an in-team practice for a lot of things and a heartfelt cooperation between development teams and specialists.
14.5.1 Incident handling
Your system is under attack. Someone is stealing the data out of the database. Should someone do something? Certainly! That’s why you need incident handling. The question is rather in what way the team should be involved and why.
The development and operations team (or teams) are those with the best insights into the details of how the system works. In our experience, you get the best results from incident handling when developers are directly involved in the process. During an attack, you typically want to find out:
- What channel are the attackers using to get access to the system? How can you shut that channel? For example, you might be able to cut a database connection or shut a port.
- What further assets (databases, infrastructure, and so on) are at risk? What can the attackers do with the assets they have gained access to? For example, can they elevate their privileges on the machine or use credentials they’ve obtained to reach a new machine?
- What data did the attackers get access to—customer records, financial information?
- Can you limit the amount of data the attacker has access to? For example, you might empty a database while leaving it open, giving the attacker the impression that they’ve gotten all there is to get.
- Can you limit the value of the data; for example, by mixing it with false data?
- Can you limit the damage of the data loss; for example, by notifying or warning customers, partners, agencies, or the public?
The development team gives deep and important insights when considering these and similar questions. The most important task at hand is to stop the bleeding, but stopping the attack doesn’t mean the incident is over. Investigation and damage control are part of handling the incident, so you should also capture forensic evidence to be used after the fact. During a security incident, you should focus on what needs to be done to handle the immediate situation, but later on, you can dig deeper to fix the underlying problems.
The rest of the organization must be prepared too. A security incident is by its nature unplanned and gets the highest priority. No one can assume that the team will continue to work as planned at the same time as they’re saving the business assets of the company. No stakeholder should complain that their favorite feature was delayed because the team was preoccupied with a security incident.
14.5.2 Problem resolution
When the emergency phase of the incident is over, it’s time to resolve the underlying problem. Problem resolution is the work that’s done to understand why the incident occurred and to fix it so that it can’t happen again (or at least make it more unlikely). The questions the team asks itself during problem resolution are slightly different:
- What vulnerability did the attacker exploit? For example, was there a bug in the code or a weakness in a library that was used?
- Were there several vulnerabilities that, when taken together, made the attack possible? For example, one machine with a weakness might have been protected by another mechanism until a vulnerability was found in the other mechanism.
- How could the attacker have gained information about the existence of the vulnerabilities? For example, they got information about the infrastructure because of exceptions carrying unnecessary details being exported to the caller.
- How did the vulnerabilities end up in the code? For example, a vulnerability in a third-party library might have gone unnoticed, so the version wasn’t patched.
Problem resolution should cover both product and process. It should fix the problem in the product (for example, patching a broken version of a third-party library), but it should also address the problem in the process (for example, reasoning around why the team didn’t know the version was broken and how they could have avoided the situation by patching earlier).
The work of resolving the problem differs a little from incident handling. In incident handling, the situation is most often drop everything else. Even if it’s not all hands on deck, for those that are involved, there’s nothing more important. In problem resolution, this isn’t always the case. Once you’ve identified what the problem is, it’s back to assigning priorities. For every feature you normally develop, there’s a business value that motivates it. That value might be the mitigation of a risk. The same goes for problem resolution; you spend effort on mitigating a risk and securing a business asset, but the value of that effort must be weighed against all other efforts that could be expended instead. You’re back to good old-fashioned priorities.
Exactly how problem resolution gets prioritized in the backlog is outside the scope of our discussion. The backlog might reside in a digital tool or be represented by sticky notes on a physical wall. Regardless, this is where the problem resolution goes—into the backlog to compete with everything else.
We are aware of the problem that not all product owners have a broad view of the product and the priorities around it. Too many product owners are stakeholders who only see one perspective—often, what’s directly facing the customer or the user. A good product owner should balance features and quality work, ensuring capabilities such as response time, capacity, and security. We all know that security has a hard time getting to the top of the priorities list, but at least a backlog item that’s about fixing a security problem that has already caused an incident has a somewhat better chance of getting to the top.
14.5.3 Resilience, Wolff’s law, and antifragility
Earlier in this book, we talked about the resilience of software systems; for example, how a system that loses its connection to the database recovers by polling and reconnecting. After a while, the system is healed and is back to its normal operation as if the disturbance hadn’t occurred. This is a desirable system property, but with security, you’ll want to take it one step further.
We’d like to see systems that not only resume normal operation after an attack but actually grow stronger after recovering from one. That kind of phenomenon is nothing new to humanity; in medicine, it’s well known and goes under the name Wolff’s law. The nineteenth-century German surgeon Julius Wolff studied how the bones of his patients adapted to mechanical load by growing stronger. Later, Henry Gassett Davis did similar studies on soft tissues, like muscles and ligaments. Just as muscles and bones grow stronger when they’re put under load, we’d like our systems to grow stronger when put under attack.
Even if it would be cool to have software that automatically adapted to and evolved after attacks, this isn’t what we’re after. We need to change what we mean by system, moving away from the computer science sense to what it means in system theory; we need to zoom out a little and talk about the system that consists of the software, the production environment, and the team developing the software.
Unfortunately, many systems grow weaker after attacks, when problem resolution consists of making a quick patch (as small as possible) before the team goes back to developing the next story from the backlog. The system over time becomes a patchwork of inconsistent design and becomes more vulnerable to attacks. But with insightful product ownership that also takes security seriously, the team and the system have the potential to improve after attacks. If each attack is met with incident handling, a postmortem analysis, learning, and structured problem resolution of both the product and the processes, it’s possible for a system to follow Wolff’s law and grow stronger when attacked. In 2012, Nassim Taleb coined the term antifragile to describe this phenomenon in the field of software development.3
One specific example of how the system grows stronger is through the security code review checklist that we mentioned earlier. The power of checklists has been proven by professionals in many fields. For example, the World Health Organization’s Surgical Safety Checklist was shown to reduce complications by 40%,4 and aviation preflight checklists have been used to improve safety since the 1930s. If you’re interested, take a deeper look in The Checklist Manifesto: How to Get Things Right by Atul Gawande (Henry Holt, 2009). By adding carefully crafted checks to your list, you’re using this power.
Making systems grow stronger when attacked is hard, but not impossible. The aviation industry through structured learning has increased the security of air travel by over a thousandfold.5 Their methods are not rocket science: structured incident investigations and reports that are shared within the profession—an impressive case of group learning. Structural engineers have done similarly with the design of elevators.
If the engineering branch of computer science is immature in any regard with respect to other disciplines, it’s in our lack of structured learning and sharing with our peers. But there’s hope. The OWASP Builders’ community focuses on shared learning on security among software builders, and you can do a lot for your system with your peers on your team.6
Summary
- You should use code security reviews as a recurring part of your secure software development process.
- As your technology stack grows, it becomes important to invest in tooling that provides quick access to information about security vulnerabilities across the entire stack.
- It can be beneficial to proactively set up a strategy for dealing with security vulnerabilities as part of your regular development cycle.
- Pen tests can be used to challenge your design and detect microlesions caused by evolving domain models.
- Feedback from a pen test should be used as an opportunity to learn from your mistakes.
- Bug bounty programs can be used to simulate a continuous, never-ending pen test, but bug bounty programs are complex and require a great deal from an organization.
- It’s important to study the field of security.
- Knowledge from different domains can be used to solve security problems.
- Incident handling and problem resolution have different focuses.
- Incident handling needs to involve the whole team.
- The security incident mechanism should focus on learning to become more resistant to attack.