
7
Reducing complexity of state
This chapter covers
- Making entities partially immutable
- Using entity state objects
- Looking at entities through entity snapshots
- Modeling changes as a relay of entities
If mutable state isn’t handled properly, bad things happen. For example, a flight taking off with a bag in the hold belonging to a passenger who never showed up for boarding might be a security risk. But keeping the state of entities controlled becomes hard when entities become complex, especially when there are lots of states with complex transitions between them. We need patterns to deal with this complexity, to reduce it in a manageable way.
On top of the problems with complex mutable states, entities are also hard to code. This is because they represent data with a long lifespan, during which they are changed. The problem occurs if two different agents try to change the same entity at the same time. Technically, this boils down to two threads trying to change the same object simultaneously. The patterns you use to control complexity need to handle this situation as well. We’ll look more closely at this to distinguish between single-threaded environments, such as the inside of an EJB container, and multithreaded environments.
In this chapter, we’ll cover four patterns that can reduce complexity. We’ll start with two patterns that are useful in single-threaded environments: partially immutable entities and state objects. Later, we’ll look at the entity snapshot pattern that’s well-suited to multithreaded environments. Finally, we’ll explore the large-scale design pattern of entity relay as a way to reduce overall conceptual complexity in both single-threaded and multithreaded environments.
When first learning about object orientation, students are taught to implement entities using an object with mutable data fields. In the following listing, for example, you can see how the account balance is updated and how the update is protected by a check to see that there are sufficient funds in the account.
Listing 7.1 Naive implementation of withdraw in class Account
void withdraw(Money amount) {
if(this.balance.moreThan(amount)) { ①
Money newBalance = this.balance.subtract(amount); ②
this.balance = newBalance; ③
} else {
throw new InsufficientFundsException();
}
}
But this code isn’t safe in a multithreaded environment. Imagine the account balance is $100, and there are two different withdrawals that accidentally happen at the same time: one ATM withdrawal of $75 and an automatic transfer of $50. The second withdrawal might reach the balance check before the first withdrawal has reached the stage of reducing the balance. Consider this sequence of events:
- ATM withdrawal checks balance ($100 > $75): OK, proceed.
- Automatic transfer checks balance ($100 > $50): OK, proceed.
- ATM withdrawal calculates new balance: $100 - $75 = $25.
- ATM withdrawal updates balance: $25.
- Automatic transfer calculates new balance: $25 - $50 = -$25.
- Automatic transfer updates balance: -$25.
Because the two threads weren’t executed consecutively (one after the other) but concurrently, the balance check was circumvented. The balance check for the second transaction was performed before the first transaction was completed, so it made no difference—it didn’t protect from overdraft.
This is an example of a so-called race condition. Things can be even worse: if the events happen in the order 1, 2, 3, 5, 4, 6, then the ending balance would be wrong. In that scenario, the final balance would be $50. Even though $125 has been transferred from an account holding $100, a credit remains in the account. (Walk through the scenario if you like.)
To handle this situation, you need to either build a shielding environment to ensure each entity is only accessed by one thread at a time or design your entities so that they handle multiple concurrent threads well. There are many approaches to creating a single-threaded shielding environment. One of the simplest is having each client request run in a separate thread, then loading an entity object separately in each thread. This way, you’re guaranteed to have only one thread accessing each entity instance. But if two threads are working on the same entity (the same data), then two entity instances change simultaneously, one in each thread. In that situation, it’ll be the database transaction engine that resolves what happens.
Another approach is to use a framework, such as Enterprise JavaBeans (EJB), that handles the load/store cycle of the entity. In this case, it’ll be the framework that ensures only one thread at a time accesses the entity, while minimizing the traffic to the database. Whether an entity instance is shared or not is up to the configuration. Perhaps the most up-to-date way of creating a single-threaded environment is to use an actor framework like Akka. In Akka, an entity might reside inside an actor that guarantees that only one transaction thread at a time touches the entity.
Multithreaded environments are typical when you want to avoid communication with the database and, instead, keep entity instances in a shared cache, such as Memcached. When a thread wants to work with an entity, it first looks up the entity in the cache. In this scenario, your entities need to be designed to work correctly even with multiple concurrent threads. The traditional—ancient and error-prone—way of doing this is to add semaphores in the code to synchronize the threads with each other. In Java, the most low-level way of doing this is through the keyword synchronized.
You can use many other options and frameworks, but common to all of them is that guaranteeing correct behavior is a challenging task. Let’s start with reducing the complexity of mutable states in single-threaded environments by looking at situations where you can make an entity partially immutable.
7.1 Partially immutable entities
When something is mutable, there’s a risk of some other part of the code changing it. And when something changes in code, there’s a risk of it changing in an unwanted way. Unwanted changes can happen because some other piece of the code is broken or because someone has identified a weakness and used it to launch an attack. If moving parts are dangerous, it makes sense to reduce the number of moving parts. And, even if entities are bearers of change, we’ve found it fruitful to look at parts of entities and ask, “Does this particular part need to change?”
Let’s return to the Order class, and this time let’s take a look at the attribute for customer identity, custid. Customer IDs don’t need to change: why should a shopping cart of books for one customer suddenly be transferred to another customer? That doesn’t make sense, and keeping that possibility open can result in a security issue. Say an order has been paid for but not yet shipped. If an attacker at that moment manages to change the customer ID associated with the order, they’ll have, in effect, kidnapped the order. You don’t need to leave that possibility open.
An effective way to avoid these issues through design is to make entities partially immutable. To do that, ensure that you set the customer ID once and that it isn’t possible to change it thereafter. Listing 7.2 shows an example of this, where the custid attribute of the Order class is set to private final. This enforces that custid must be set in the constructor and isn’t allowed to change after that. The method getCustid returns the same reference every time it’s called—a reference to the same CustomerID object. In this listing, CustomerID is a domain primitive and is designed to be immutable.
Listing 7.2 Order class with an immutable customer identity
class Order {
private final CustomerID custid; ①
Order(CustomerID custid) {
Validate.notNull(custid);
this.custid = custid; ②
}
public CustomerID getCustid() { ③
return custid;
}
}
class SomeOtherPartOfFlow {
void processPayment(Order order) {
registerDebt(order.getCustid(), order.value());
...
}
}
Thinking further about this code, it becomes evident that the method getCustid doesn’t encapsulate anything interesting and can be replaced with direct access to the field. Listing 7.3 shows how custid can be exposed directly, but in a secure way. The reference in the data field can’t be changed, and the CustomerID object the reference points to is immutable and can’t be changed either. Even if processPayment gets direct access to the field order.custid, it can’t do anything insecure with it.
Listing 7.3 Protecting the Order attribute custid at compile time
Order order = ...
order.custid = new CustomerID(...); ①
An interesting feature of this code is that we’ve enlisted the compiler’s help to ensure the integrity of the custid data field. Any attempt to change the attribute will never get to runtime but is caught at compile time.
You’ve seen how data fields can be protected either by encapsulation, as discussed in section 6.3, or by making them partially immutable. Now let’s turn to a trickier aspect of entities: the fact that behavior, or allowed behavior, can change depending on what state entities are in.
7.2 Entity state objects
One thing that makes working with entities difficult is that not all actions are allowed in all states. Figure 7.1 shows two marital states: unmarried and married. Most of us would agree that for someone who’s unmarried, it’s acceptable to date. But after marrying, you’re in the married state, and dating isn’t appropriate behavior (except with your spouse, of course). Someone who’s married can divorce and reenter the unmarried state; at which point, they’re free to date and to marry again. But while you’re married, it isn’t possible to marry again. Similarly, when you’re unmarried, it isn’t possible to divorce.
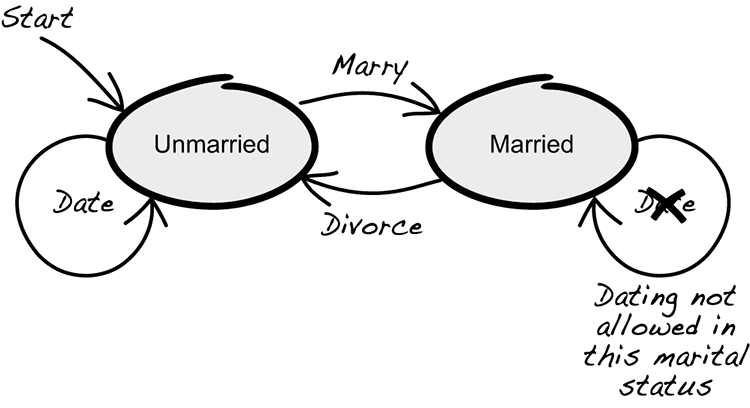
Figure 7.1 Entities should behave in a way that’s appropriate to their state.
Obviously, this is a coarse model. It doesn’t take into account polygamy or that you might be unmarried but still not free to date (for example, when you’re engaged or in a committed relationship). Still, it serves the purpose as an example of when actions aren’t allowed at all times for entities.
7.2.1 Upholding entity state rules
Moving over to software, the design must ensure that these rules on entity states are upheld. Failing to do so can lead to security problems; for example, a bookstore providing goods without payment. And this isn’t an uncommon problem. Missing, incomplete, or broken management of entity state is something we encounter often in almost every codebase of significant size.
The cause of this security problem is that the state rules are often not designed at all or are implicit and vague. It’s often obvious that there’s no conscious effort at design; rather, the rules have gradually appeared in the codebase, most probably on a case-by-case basis.
The manifestation in code is often one of two variants: rules embedded in service methods or if statements in entity methods. In listing 7.4, you see the first variant. There’s a rule that states if the person boss is married, then it’s not appropriate for them to turn an after work chat into a date. That rule is upheld by the afterwork method in the class Work, not by the class Person.
Listing 7.4 Entity state rule upheld by a service method
public class Person {
private final boolean married;
public Person(boolean married) {
this.married = married;
}
public boolean isMarried() {
return married;
}
public void date(Person datee) {} ①
}
public class Work {
private Person boss;
private Person employee;
void afterwork() {
// boss attempts to date
if (!boss.isMarried()) { ②
boss.date(employee);
} else { ③
logger.warn("bad egg");
}
}
}
Looking at the code once again, you realize something odd. The rule about not dating when married is a general rule. But in the codebase, it appears as a rule that specifically applies to the afterwork scenario. This would better fit as a rule about when a person is allowed to date. In that case, it would better reside inside the date method of Person.
In real-life codebases, we regularly see entities that are just structs (classes with private data fields, setters, and getters). The rules for how entities can behave must then be upheld by service methods. Practically, this might be possible to start with when the system is small. But as code evolves over time, upholding rules becomes inconsistent. Some parts of the system uphold some rules, whereas others don’t. Also, it’s hard to get an overview of what rules apply. To do so, you must mine all the code where the entity is used and search for guarding if statements. In short, there’s no practical way to audit what rules apply to the entity.
Closely related to how hard it is to audit is how hard it is to test. Imagine that you want to write a unit test that checks that the boss isn’t allowed to date when married. To do so, you need to test the conditional inside the afterwork method, which means you have to mock any dependencies it might have, such as a connection to the database. You also need to craft test data: both the boss itself and the dating object, employee, must be provided. Finally, you need to ensure that the afterwork method does the right thing to report an inappropriate dating attempt, so you’ll need to mock the logging framework and scan the log for bad egg. And, should there be a coffeeBreak method somewhere else in the codebase, you’ll need to do the same thing there to ensure no attempts to initiate dating are made during coffee breaks. This isn’t an easy way to test the rule “a married boss isn’t allowed to date.”
A somewhat better version is when entity methods uphold the state rules. But even this approach might lead to exploitable inconsistencies. Listing 7.5 shows another version of the dating code. Here it’s the responsibility of the Person class to check that the person boss isn’t married before proceeding with dating. (Note the if statement in the method date.)
Listing 7.5 Entity state rule upheld by entity method
public class Person {
private boolean married;
public Person(boolean married) {
this.married = married;
}
public boolean isMarried() {
return married;
}
public void date(Person datee) { ①
if (!isMarried()) { ②
dinnerAndDrinks();
} else { ③
logger.warn("bad egg");
}
}
private void dinnerAndDrinks() {}
}
public class Work {
Person boss = new Person(true);
Person employee = new Person(false);
void afterwork() {
// boss attempts to date
boss.date(employee);
}
}
This approach is definitely a step in the right direction. Business rules are at least inside the Person class. If dating can be initiated both after work and during coffee breaks, then at least it’s the same code that does the checking, which means there’s less risk of inconsistencies that can lead to security flaws.
Unfortunately, the state handling is still implicit, or at least convoluted. We’ve often seen these if statements sprinkled around deep inside the entity methods. When digging through the history of the code, it often becomes clear that they have been added one by one to handle some special cases. Sometimes the big picture of all the rules isn’t even a logically consistent model.
Obviously, having a state implemented as if statements in service methods or entity methods isn’t good design, but is it a security problem? Well, yes. If an entity leaves an opening for using a method that shouldn’t be open in that state, then that opening can potentially be used as the starting point of an attack that exploits the mistake. For example, a mistake that makes it possible to add items to an order after it has been paid might be exploited by an attacker to get goods without paying.
Let’s return to the online bookstore. In the webshop, it’s important that you ensure that an order has been paid for before you ship it. The following listing shows what that would look like if the logic were upheld in the service method processOrderShipment outside the Order class.
Listing 7.6 Business rule upheld by a service method
class Order {
final public CustomerID custid;
Order(CustomerID custid) {
Validate.notNull(custid);
this.custid = custid;
}
...
}
class SomeOtherPartOfFlow {
void processOrderShipment(Order order) {
if(order.getPaid()) { ①
warehouse.prepareShipment(order.custid, order.getOrderitems());
} else {
... ②
}
...
}
}
There’s one small if statement in processOrderShipment that protects goods that haven’t been paid for from being shipped—and that small if statement resides in some other class. It’s easy to imagine such checks being missed or gradually undermined as more and more code is added over time. If you omit to check that an order is paid for before it’s shipped, you get a loophole for customers not paying for their goods. If that loophole becomes known, you might start losing big money as unpaid-for goods suddenly start streaming out of your warehouse. Missing entity state handling is indeed a security issue.
7.2.2 Implementing entity state as a separate object
We suggest that entity state be explicitly designed and implemented as a class of its own. With this approach, the state object is used as a delegated helper object for the entity. Every call to the entity is first checked with the state object.
Returning to the example of marital status, you can see in listing 7.7 what a MaritalStatus helper object looks like. It encapsulates the rules around marital status, but nothing else. For example, you see in the method date how a call to the Validate framework helps to uphold the rule about not dating when married.
Listing 7.7 MaritalStatus helper object encapsulating the rules of marital status
import static org.apache.commons.lang3.Validate.validState;
public class MaritalStatus {
private boolean married = false; ①
public void date() { ②
validState(!married, ③
"Not appropriate to date when married");
}
public void marry() {
validState(!married); ③
married = true;
}
public void divorce() {
validState(married); ④
married = false;
}
}
The code of the helper object is concise. The married versus the unmarried examples are almost the simplest state graph possible. The state graph would be slightly more complicated if you introduce support for the state dead by adding a private boolean variable alive, which initially would be set to true. When the person dies, the flag would be switched to false, and at that point, the value of the flag married would be meaningless.
Having logic for dead or alive in the entity would probably result in a couple of if statements that would decrease both readability and testability and, over time, lead to less secure code. Alternatively, you could add the same logic in the helper class MaritalStatus, and the code would still be manageable. A direct effect of the conciseness of the helper object’s code is that the code is also testable. In the following listing, you see a few possible tests that check that the rules are upheld by MaritalStatus.
Listing 7.8 Some test cases for MaritalStatus
public class MaritalStatusTest {
@Test
public void should_allow_dating_when_unmarried() {
MaritalStatus maritalStatus = new MaritalStatus();
maritalStatus.date();
}
@Test(expected = IllegalStateException.class)
public void should_not_allow_dating_when_married() {
MaritalStatus maritalStatus = new MaritalStatus();
maritalStatus.marry();
maritalStatus.date();
}
@Test
public void should_allow_dating_after_divorces() {
MaritalStatus maritalStatus = new MaritalStatus();
maritalStatus.marry();
maritalStatus.divorce();
maritalStatus.date();
}
}
Note how well the code reads. The code of the test should_allow_dating_after_divorces clearly states that if you marry and then divorce, then you’re free to date. Naming your classes after concepts that exist in the domain, such as marital status, helps.
It’s time now to look at how to weave this state representation into the entity. In the following listing, we let the entity Person consult its helper object MaritalStatus at the beginning of every public method to detect whether the call is legal.
Listing 7.9 The class Person aided by the class MaritalStatus
public class Person {
private MaritalStatus maritalStatus =
new MaritalStatus();
public void date(Person datee) {
maritalStatus.date(); ①
buydrinks();
offerCompliments();
}
public void divorce() {
maritalStatus.divorce(); ②
...
}
...
} ②
Extracting your state management into a separate object makes your entity code much more robust and much less prone to subtle business integrity problems like customers avoiding to pay for their orders before they’re shipped. We recommend using a separate state object when there are at least two states with different rules and when the transitions between them aren’t completely trivial. We would probably not use a separate state object to represent the state of a light bulb (on/off, and where switch is always allowed and always switches to the other state). But for anything more complicated than that, we recommend you consider using a separate state object.
This kind of entity representation as a mutable object works well in single-threaded environments as mentioned. But in multithreaded environments, you’d need to have lots of synchronized keywords in your code to stop threads from thrashing the state. Unfortunately, that leads to other problems, such as limited capacity and potential deadlocks. Next, we look at a different design that works well in multithreaded environments.
7.3 Entity snapshots
Let’s turn now to multithreaded environments, where the same entity instance can be accessed by multiple threads. In a high-performance solution where response times are critical, you want to avoid hitting the database. This is usual in financial trading, streaming, and multiuser gaming applications, as well as highly responsive websites. The round-trip time to fetch data from the database would kill the quick responses you’re after in these situations. Instead, you might hold your entities in memory as much as possible; for example, using a shared cache (such as Memcached). All threads that need to work with an entity fetch the data from the cache, and the entity representation becomes shared between threads. This results in fast response times and high capacity, but it puts an additional burden on the design of entities: they must live well in an environment with multiple threads.
One way of handling this situation would be to add a lot of synchronized keywords to the code, but that would result in lots of threads waiting for each other and would reduce capacity drastically. Even worse, it might cause a deadlock, where two threads wait for each other indefinitely. Instead, let’s take a look at another design pattern for handling this situation—representing entities as entity snapshots.
7.3.1 Entities represented with immutable objects
When designing with entity snapshots, you have an entity, but that entity isn’t represented in code through a mutable entity class. Instead, there are snapshots of the entity that are used to look at that entity and take action. This is most easily described through a metaphor.
Imagine an old friend who you haven’t seen in a while. You live in separate cities, but you keep in contact by following each other on a photo-sharing site. On a regular basis, you see photos of your friend, and you can follow how they change over time. Perhaps they try out a new hairstyle or move to a new house, and they certainly slowly grow older, as we all do. No doubt your friend is someone with an identity that transcends all these attribute changes. You see the changes and you stay in touch, although you never meet up in person (see figure 7.2).

Figure 7.2 A series of photos gives an impression of a real person, even if you never meet up in real life.
What about the photos? Are those your friend? Of course not. Those are snapshots of your friend. Each photo is a representation of your friend at a particular point in time. The photo can be copied and disposed of, the copy replacing the original, without you caring. Your friend will still be there, in the far-away city, living their life.
The entity snapshot pattern follows the same idea. In an online webshop, orders are created when customers purchase products. Each order has a significant lifespan and evolves as the customer adds items, selects a payment method, and so on. Technically, the state might be kept in the database. But when it’s time for the code to look at the state, you take a snapshot of it and represent it in a class OrderSnapshot, which is an immutable representation of the underlying entity as shown in the following listing. It provides a snapshot of what the order looks like at the moment you ask for it.
Listing 7.10 Class OrderSnapshot
import static org.apache.commons.lang3.Validate.*;
public class OrderSnapshot { ①
public final OrderID orderid;
public final CustomerID custid;
private final List<OrderItem> orderItemList;
public OrderSnapshot(OrderID orderid;
CustomerID custid,
List<OrderItem> orderItemList) {
this.orderid = notNull(orderid);
this.custid = notNull(custid);
this.orderItemList =
Collections
.unmodifiableList(
notNull(orderItemList)); ②
checkBusinessRuleInvariants();
}
public List<OrderItem> orderItems() {
return orderItemList; ②
}
public int nrItems() { ③
...
}
private void checkBusinessRuleInvariants() {
validState(nrItems() <= 38, "Too large for ordinary shipping");
}
} ④
public class OrderService {
public OrderSnapshot findOrder(OrderID orderid) ...
public List<OrderSnapshot> findOrdersByCustomer(CustomerID custid) ...
}
Even if the order entity still exists conceptually, it doesn’t manifest itself as a mutable entity class in the code. Instead, the OrderSnapshot class does the job of bringing you the information you need about the entity, probably to visualize it in the webshop GUI. The idea behind the snapshot metaphor is that the domain service goes down to the database, bringing a camera with it, and brings back a snapshot photo of what the order looked like. OrderSnapshot isn’t just a dumb reporting object, it contains interesting domain logic like a classical entity. For example, it’s able to compute the total number of items in the order and ensure that the number stays within the prescribed range for shipping.
But what about the underlying entity? Does it exist when there isn’t a mutable entity class? Well, the entity order does still exist, conceptually, in the same way as your faraway friend. Like your friend, you never see the order entity directly but only see snapshots of its state. The only place where the order is represented as a mutable state is in the database: the row in the Orders table and the corresponding rows in the OrderLines table.
7.3.2 Changing the state of the underlying entity
We’ve shown how a mutable entity can be represented through immutable snapshots. But if this is a true entity, it needs to be able to change its state. How do you achieve this if the representation is immutable?
There needs to be a mechanism to mutate the entity (by which we mean the underlying entity data). To this end, you can provide a domain service to which you send updates. In the following listing, you can see that the domain service OrderService has been given another method, addOrderItem, to provide such updates.
Listing 7.11 OrderService with methods for updating the order in the database
class OrderService {
public void addOrderItem(OrderID orderid,
ProductID pid, Quantity qty) {
//... ①
//... ②
}
}
The method addOrderItem validates the conditions to ensure the change is allowed and then performs an update of the underlying data, either through SQL commands sent directly to the database or via the persistence framework you use. With this approach, you get high availability because you avoid locks when reading, which is assumed to be much more common than writing (in the form of changing data). Writing, which might require locks, is separated from the reads, and you avoid the security problem of not having data available.
A drawback of this approach is that it violates some of the ideas of object orientation—especially the guideline to keep data and its accompanying behavior close together, preferably in the same class. Here, you’ve ripped the entity apart, putting the read side in a value object in one class and the write side in a domain service in another class. Architecture often involves trade-offs. In cases like this, you might value availability so highly that you’re willing to sacrifice other things, like certain principles of object-oriented code.
The idea isn’t as strange as it might sound. Similar approaches have been suggested elsewhere, sometimes in slightly different settings. The pattern of Command Query Responsibility Segregation (CQRS), suggested by Greg Young, and the Single Writer Principle, proposed by Martin Thompson, both bear similar signs.
Apart from availability, the entity snapshot pattern also supports integrity. Because the snapshot is immutable, there’s no risk at all of the representation mutating to a foul state. An ordinary entity with methods that change its state is vulnerable to bugs of that kind, but the snapshot isn’t. There’s code that changes the state of the underlying data, and that code can contain bugs, but at least the snapshot that’s used to show the state of the entity can’t change.
Implementing entities using the entity snapshot pattern makes it possible for them to live well in a multithreaded environment without causing the drawbacks you get if you sprinkle your code with synchronized. You also avoid contention by letting the database handle the transaction synchronization, with all the locking issues involved.
7.3.3 When to use snapshots
No doubt, the idea of having an entity without an entity class doesn’t follow ordinary schoolbook patterns for object orientation, and it might seem counterintuitive. To the object-oriented mind, it might also be disturbing to have the data definition of an entity in one place and the mechanics for updating the same data in another place. Nevertheless, there are situations with tough capacity and availability requirements—be it a high-traffic website or a hospital, where medical staff need to get immediate access to a patient’s notes—where we think the entity snapshot pattern is well worth taking into account.
Another interesting security benefit of the entity snapshot design is in situations where different privileges are needed for reading data and for changing and writing data. For user scenarios where you only want to display the state of the data (looking at the cart), there need to be methods for fetching that data. And for user scenarios where you change the data (adding items to the cart), there need to be methods for changing that data. In classical object orientation, the entity will have methods to support both reading and writing. During a user scenario where you display data, the client code has access to those methods for writing as well. There’s a need for some other kind of security mechanism that controls changes to the entity object, making sure there are none during read scenarios.
With the entity snapshot design, read scenarios only have access to the immutable snapshot, and it’s impossible for them to call a mutating method. Only the clients that are allowed to make changes will have access to the domain service used for updating the underlying entity. In this way, the entity snapshot pattern also supports integrity for some common scenarios. In an environment where multiple threads access the same entity, perhaps at the same time, using entity snapshots is therefore an effective design to ensure high availability together with integrity.
Now you’ve studied two designs: one that works well in single-threaded environments and one that works well in multithreaded environments. But there’s another way complexity might arise: when an entity has a lot of different states. Handling more than 10 states in an entity can get awkward, but often it’s possible to apply an alternative design—splitting the complex states into an entity chain.
7.4 Entity relay
Many entities have a reasonably low number of separate states, and they are fairly easy to grasp. For example, the civil status of an individual in the marital status example has few states and transitions among them, as figure 7.3 shows.

Figure 7.3 Civil status: single, married, divorced, widow/er, dead
A state graph of this size is easy to understand. It’d also be easy to implement using the state object pattern from section 7.2 for example.
Sometimes an entity state graph grows and becomes quite large and less easy to grasp. It might well be designed that way from the beginning, but more often, such a design is the result of a long history of many changes. Most of the changes were probably perceived as a small fix at the time they were made, but the accumulative result as time passes is a lot of states. You can imagine that an online bookstore might start out having two states for its orders, received and shipped. After a while, the state graph might look like that shown in figure 7.4.
It can be hard to understand all the possible states and transitions for such an entity, even when you’re looking at the graph. To implement these states in code and to ensure that all the different rules are enforced in all the different states would be a nightmare. When this entity is implemented as one single class, that class becomes so complex that it risks containing hard-to-spot inconsistencies. Something has to be done if you have a state graph like that for the online order in figure 7.4. You need to break it up. Having five states is manageable. Having 10 states is endurable. Having to juggle 15 states is simply too risky. And this is where we suggest entity chaining.

Figure 7.4 The book order can be in a lot of distinct states, each with its own rules and constraints.
The basic idea of entity relay is to split the entity’s lifespan into phases, and let each entity represent its own phase. When a phase is over, the entity goes away, and another kind of entity takes over—like a relay race. As an example, look at figure 7.5, which views the life of a person in two ways: first as one single entity that goes through many states of life, then as a chain of entities.

Figure 7.5 The life of a person viewed in two ways: as a single entity and as a chain of entities.
On the left side of figure 7.5, you see the life of a person viewed as one single entity: a person is born and spends a few years in childhood, then some time in adolescence before shouldering the responsibilities of adulthood, followed by aging, until death. You can view the person as the same entity, which passes through the states of birth, childhood, adolescence, adulthood, aging, and death.
On the right side of the figure, you see the same life viewed as a chain of entities. A child is born and grows. One day, the child is gone, and there’s a youngster standing in its place, taking over the relay baton. A few years later, the youngster is gone and is replaced by an adult. The adult eventually yields to an elder, who finally dies. In this case, you can view this life as a succession of different characters.
We’ve presented two ways of looking at the same thing. Neither representation is more true or better than the other; they focus on different aspects and are good at different things. Shifting focus from one to the other might help you sometimes—when you have an entity with a lot of states is one such occasion. We’ve found that this design shift can be a powerful way to handle entities that have far too many states. You split the too large state graph into phases, model each phase with an entity of its own, and let these entities form a relay chain. Each entity in the relay has a few states to manage, and you’ve overcome risky complexity.
The power of entity relay comes from the ability to split the overall lifespan of the entity into phases and instead model the phases as one entity following another. For this to work well, there should be no looping back to a previous phase. If there are loopbacks, then you can still apply the same idea, but the simplicity of the relay metaphor is lost, as well as much of the gain. Next, we’ll return to the scary state graph of the book order and show how you can turn it into a more manageable relay chain.
7.4.1 Splitting the state graph into phases
Let’s take another look at the overcomplex entity in figure 7.4 and see how you can remodel it as a relay race of entities. Look for places where one group of states leads to another group of states. Preferably, there should be no way back to the first group once you’ve left it. Figure 7.6 shows one way to partition the states.

Figure 7.6 A book order passes through different phases during its lifespan.
Now you see that the complex graph of the online order can be viewed as two phases: up until payment and after payment. Call the first phase a preliminary order and the second phase a definitive order. These are the phases that you want to redesign to be separate entities instead. The runners that make up the relay race include the first entity (or preliminary order), which starts the race, and the second entity (or definitive order), which takes over when the first entity completes. When a preliminary order is paid for, a definitive order is born as a result.
If you take another look at the state graph in figure 7.6, you’ll see that there’s one more place that meets these requirements—when the delivered package is rejected by the receiver. The difference here is that not all delivered orders give rise to a rejected order, just some. It’s still a good place to split the state graph. You need to remember that the birth of a rejected order isn’t automatic, it’s conditioned on the recipient not accepting the delivery.
After these transformations, you now have a simpler setup. As you can see in figure 7.7, you no longer have one entity with an overwhelming amount of states. Instead, you have three entities, each of which is reasonably simple.

Figure 7.7 A book order as a chain of three entities
The three entities (preliminary order, definitive order, and rejected order) have four or five possible states each, so implementing them on their own is pretty straightforward. Using the previous design of state objects, you’ll be able to implement all three entities in a secure way.
Let’s briefly look at the transitions, the baton handovers between the entities in the relay. When a preliminary order is finally configured completely and paid for, it moves into the state paid, which is its end state. At that time, a definitive order is born in its start state, paid. The baton is handed from the preliminary order, which has reached its goal, to the definitive order, which starts its run. This is the same situation as when a youngster entity moves into the state no longer youngster and, at the same time, an adult entity arises. In the same way, as an adult can’t move back and become a youngster again, a preliminary order can’t move back before its start state, paid.
The transition between definitive order (paid for and shipped to the customer) and rejected order works almost the same way, but with a small twist. When a definitive order reaches its end state, delivered, that doesn’t always cause a next entity to arise. A rejected order only arises if the definitive order is rejected on delivery (no one was willing to sign for it, or the address couldn’t be found, for example). In most cases, the delivery of a definitive order won’t give rise to a rejected order.
With this design, you’ve greatly simplified the task of writing code and made your code much less susceptible to mistakes. With a large and complex state graph, like that in figure 7.4, you’ll have a hard time guaranteeing that there are no strange, esoteric paths that break intended business rules. With a simpler design of three entities, each with four or five states, as in figure 7.7, you can more easily validate and test that the code does what it should. You have drastically lowered the risk of security vulnerabilities. Let’s now zoom out and think about when to apply this pattern or not.
7.4.2 When to form an entity relay
For this pattern to be valuable, you want to see three factors in place:
- Too many states in an entity
- Phases where you never go back to an earlier phase
- Simple transitions from one phase to another and few transition points (preferably only one)
If the number of states in your entity is manageable as it is, there’s no reason to bring in the complexity of several entities with different names. Unless you have at least 10 states, we don’t recommend splitting your entity into a relay. Similarly, if there are ways for an entity to go from a later phase back to an earlier one, we don’t recommend splitting it into two entities. The power of entity chaining comes from the simplicity that once an earlier entity is finished, you’re done with it. In our order example, this is the case when a preliminary order (still under configuration) is paid for. Then that turns into a definitive order, and there’s no way it can go back and become preliminary again.
If it’s possible to reopen an earlier entity, that would be comparable to having one runner hand the baton over to an earlier runner. Now, you no longer have the simple succession of one runner handing the baton on to the next until the relay race is over. Instead, you get some kind of directed graph where entities of different phases can be revived. The simplicity of a relay race is lost.
If there are many ways that an earlier entity can give rise to a later entity, you should consider whether the benefits of entity relay outweigh the costs. There’s a simplicity in having only one place where the next entity is born. If there are several, consider remodeling. Perhaps you can add an end state for the phase? If not, perhaps the two phases should be seen as one.
Finally, sometimes you get a huge state graph with a lot of states and where the transitions look like a tangled ball of yarn. Don’t even try to resolve that by creating relays. No amount of effort to design it nicely will help. A mess like that continues to be a mess, even if you pull a few threads. Instead, we recommend that you take the model back to the drawing table. Sit down with the domain experts and talk it over:
- What are the real drivers for the model being this complex?
- Is all that complexity really needed?
- Is there a valid business driver for each part of the complexity?
- Is that business driver so valuable that it justifies the cost of such complexity and, perhaps, an insecure system?
We’ve covered a few ways of reducing complexity in this chapter. Table 7.1 provides a concise summary of the central aim of each pattern and the security concerns it addresses.
| Pattern | Purpose | Security concern |
| Partially immutable entity | Locks down parts of entities that shouldn’t change anyway | Integrity |
| Entity state object | Makes it easier to grasp what states the entity can have | Integrity |
| Entity snapshot | Supports high capacity and fast response times by avoiding locking | Availability, integrity |
| Entity relay | Makes it easier to handle large and complex state graphs | Integrity |
The first pattern we looked at was minimizing the number of moving parts by making the entity partially immutable where possible. The next pattern, the entity state object, focused on capturing state transitions of one entity and worked well in single-threaded environments. In multithreaded environments, it becomes more feasible to represent the entity through entity snapshots to avoid threading issues. Finally, for a complex entity with lots of states, an alternative design is to model it as an entity relay, reducing the number of states you need to keep in mind at the same time.
Summary
- Entities can be designed to be partially immutable.
- State handling is easier to test and develop when extracted to a separate object.
- Multithreaded environments for high capacity require a careful design.
- Database locking can put a limit on availability of entities.
- Entity snapshots are a way to regain high availability in multithreaded environments.
- Entity relay (when fulfillment of one entity gives rise to another) is an alternative way to model an entity that has lots of different states.